26
MEMSQL IN-MEMORY DATABASE SYSTEM BUILT FOR SPEED AND SCALE
| Date post: | 28-Jul-2015 |
| Category: |
Data & Analytics |
| Upload: | memsql |
| View: | 223 times |
| Download: | 3 times |

MEMSQLIN-MEMORY DATABASE SYSTEM BUILT FOR SPEED AND SCALE

Nikita’s Background
PhD in CS from St. Petersburg ITMO
Microsoft SQL Server Kernel Engineer
Facebook Performance and Site Cost
Since 2011 MemSQL CTO and co-founder

What will this talk cover
MemSQL workloads
HTAP - Hybrid Transaction/Analytical Processing
MemSQL key innovations
Live demo of MemSQL and Q/A

Why in-memory?OLTP
Improve transactional throughput
Ingest more per second
OLAP
Load data faster
Generate reports faster

Modern Workloads
Ingest and serve data in real-time
Generate reports over changing datasets
Anomaly detection as events occur
Sub-second response for hundreds of users
Integrating with the eco system (Connectivity, Spark, Tableau, Hadoop, Splunk, etc)

Gartner Introduces HTAP
Hybrid Transactional/Analytical Processing
Analytics over concurrently changing data
Predictable performance and scalability
ETL is irrelevant

In-memory Delivers HTAPTransactions
Higher throughput, lower latencies
Predictable SLAs
Analytics
Can access data as it is written (no ETL)
Velocity -> Volume
Columnar format can run on flash

Ankur’s Background
CMU SCS Undergrad
Internships at Microsoft and PDL
MemSQL Employee #5
Director of Engineering

MemSQL Overview
In-memory row store
Distributed
Online operations
Fast ANSI SQL
Agg 1 Agg 2
Leaf 1 Leaf 2 Leaf 3 Leaf 4

Key Innovations
Lock-Free Skip Lists
Code Generation
Durability and Replication
Clustering
Distributed Query Execution

What is a Skip List
Invented in 1990 by William Pugh
Expected O(log(n)) lookup, insert, delete
Much simpler than a balanced tree

Skip List IndexesMemory optimized
Simple
Lock free
Fast
Flexible
Multiversion Concurrency Control

Common Concerns
Memory overhead
CPU cache efficiency
Scan performance
Reverse iteration
struct Table_Row {
int col_a;
char* col_b;
…
Tower* idx_1_ptrs;
Tower* idx_2_ptrs;
};

Code Generation
Inline scans
Expression execution
Need a powerful plan cache
OLTP vs. data exploration

MemSQL Code Generation
Versioning and type-system
Templates
.h file per table
.cpp file per plan
Precompiled headers

Expression Snippetmemsql> select concat("foo", "bar");
+-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐+
| concat("foo", "bar") |
+-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐+
| foobar |
+-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐+
1 row in set (0.81 sec)
memsql> select concat("foo", "bar");
+-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐+
| concat("foo", "bar") |
+-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐+
| foobar |
+-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐-‐+
1 row in set (0.00 sec)
bool overflow = false;
VarCharTemp result1("abc", 3, threadId);
VarCharTemp result2("def", 3, threadId);
opt<TemporaryImmutableString> result3;
op_Concat(result3, result1, result2, overflow, threadId);

Durability
Transaction log
Periodic snapshots
Replay to recover state
Sequential I/O (reads and writes)

Replication
Built on top of durability
Stream snapshot and log files
Slave == continuous recovery
Very simple and robust

Clustering
Two-tier architecture
Scalable on both sides
Intra- and inter-datacenter HA
Stays out of the way
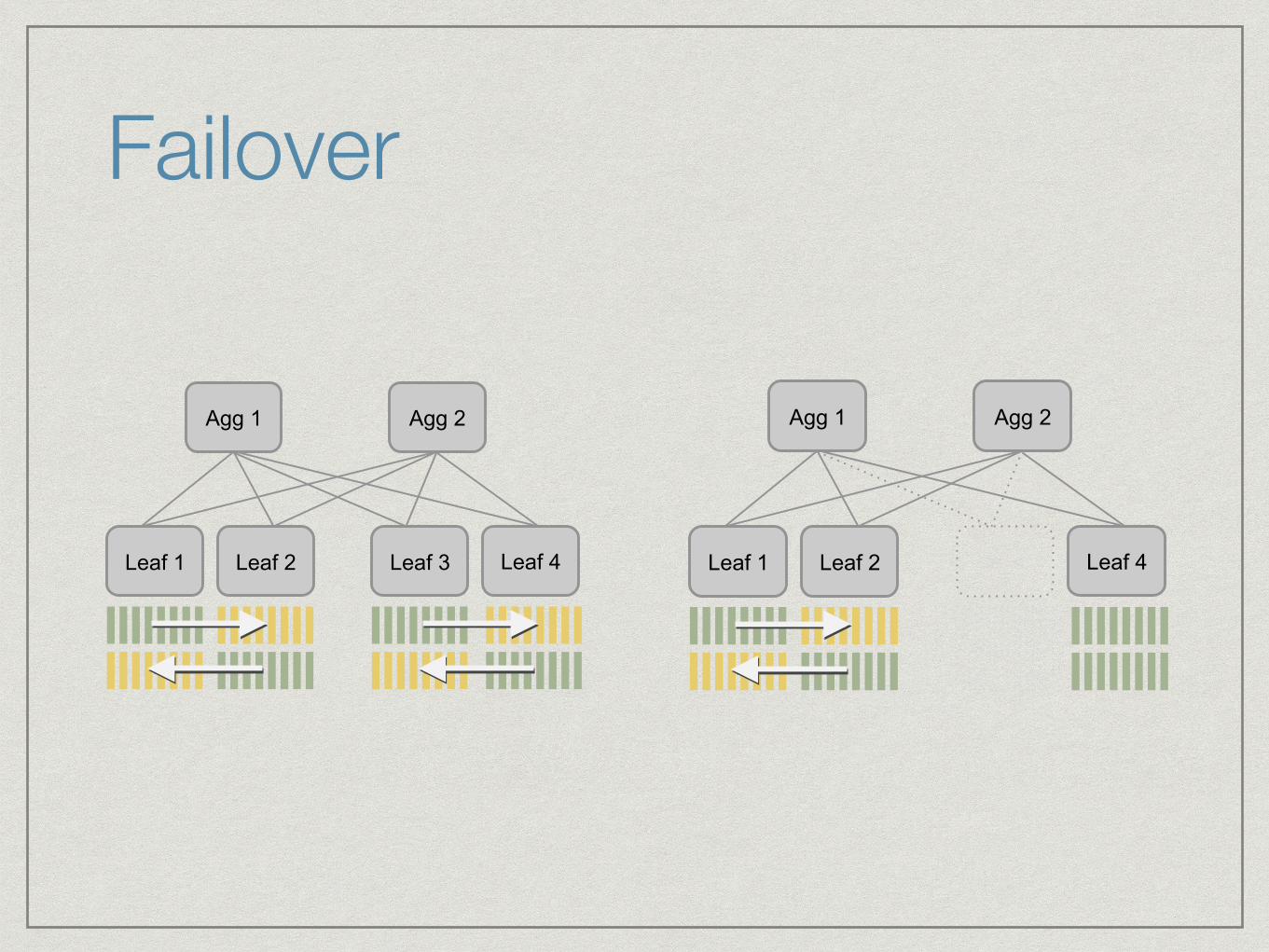
Failover
Leaf 1 Leaf 2 Leaf 4 Leaf 3
Agg 1 Agg 2
Leaf 1 Leaf 2 Leaf 4 >_<
Agg 1 Agg 2

Cluster Replication
Leaf 1
Leaf 2
Agg
Leaf 1
Leaf 2
Agg
Primary Secondary

Query Execution
Shard keys
SQL between nodes
ToSQL()
Reference tables
Foreign shard key joins

Example Query
Agg 1 Agg 2 select&count(1)&from&orders;&
leaf1>&using&memsql_demo_0&select&count(1)&from&orders;&&leaf2>&using&memsql_demo_1&select&count(1)&from&orders;&&leaf3>&using&memsql_demo_2&select&count(1)&from&orders;&...&
Leaf 1 Leaf 2 Leaf 3 Leaf 4

New QE/QO Projects
SQL-based reshuffling
ARRANGE
Remote tables
Optimizer
SQL-SQL tree transforms
Cost-based distributed optimizer
ARRANGE t.a, t.b, SUM(t.price) FROM t GROUP BY t.a, t.b SHARDED BY t.a, t.b AS t_reshuffled

Conclusions
In-memory unlocks new workloads
Old problems with new solutions
Call for Data Structures/Algorithms
Storage systems

DEMO AND Q/A

















