51
Information Retrieval and Web Search (Web IR) Introduction Seyed Mohammad Bidoki Persian Gulf University [email protected] www.smbidoki.ir

Information Retrieval and Web Search (Web IR)
Introduction
Seyed Mohammad BidokiPersian Gulf University
www.smbidoki.ir

2
Outline
• Information Retrieval
• Web challenges
• Search engines
• Web crawling
• Web ranking– Ranking algorithms
– Ranking challenges
Information Retrieval & Web Search: Introduction, S.M.Bidoki

Information Retrieval (IR)
• The indexing and retrieval of textual documents.
• Concerned firstly with retrieving relevantdocuments to a query.
• Concerned secondly with retrieving from largesets of documents efficiently.
3Information Retrieval & Web Search: Introduction, S.M.Bidoki

4
Information Retrieval Definition
• IR deals with the representation, storage, organization of, and access to information items (relevant to user query)
• Information retrieval (IR) is the science of searching for documents, for information within documents, and for metadata about documents
• An information retrieval process begins when a user enters a query into the system. Queries are formal statements of information needs, for example search strings in web search engines.
• In information retrieval a query does not uniquely identify a single object in the collection. Instead, several objects may match the query, perhaps with different degrees of relevancy.
Information Retrieval & Web Search: Introduction, S.M.Bidoki

Comparing IR to databases (vs data retrieval)
Databases IR
Data Structured Unstructured
FieldsClear semantics (SSN, age)
No fields (other than text)
QueriesDefined (relational algebra, SQL)
Free text (“natural language”), Boolean
Query specification
Complete Incomplete
MatchingExact (results are always “correct”)
Imprecise (need to measure effectiveness)
Error response Sensitive Insensitive
Information Retrieval & Web Search: Introduction, S.M.Bidoki
5

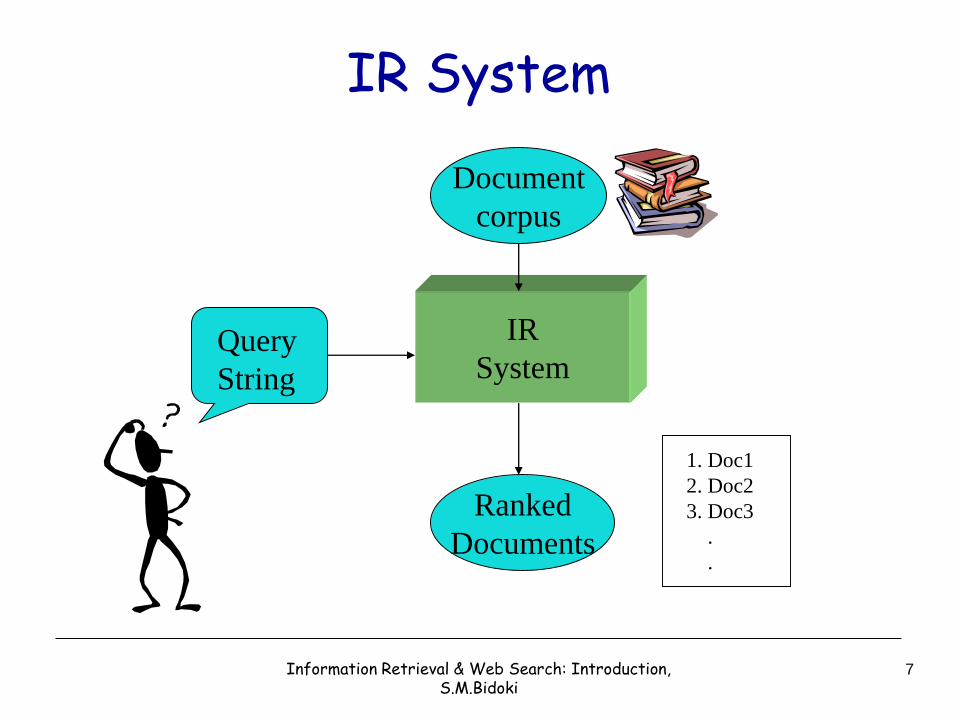
Typical IR Task
• Given:– A corpus of textual natural-language documents.
– A user query in the form of a textual string.
• Find:– A ranked set of documents that are relevant to
the query.
6Information Retrieval & Web Search: Introduction, S.M.Bidoki
IR System
7
IR
SystemQuery
String
Document
corpus
Ranked
Documents
1. Doc1
2. Doc2
3. Doc3
.
.
Information Retrieval & Web Search: Introduction, S.M.Bidoki

Relevance• Relevance is a subjective judgment
and may include:– Being on the proper subject.
– Being timely (recent information).
– Being authoritative (from a trusted source).
– Satisfying the goals of the user and his/her intended use of the information (information need).
• Evaluation!– Subjective
– Think about Relevance Evaluation: HOW???!!!
8Information Retrieval & Web Search: Introduction, S.M.Bidoki

Keyword Search
• Simplest notion of relevance is that the query string appears verbatim in the document.
• Slightly less strict notion is that the words in the query appear frequently in the document, in any order (bag of words).
9Information Retrieval & Web Search: Introduction, S.M.Bidoki

Problems with Keywords
• May not retrieve relevant documents that include synonymous terms.– “restaurant” vs. “café”
– “PRC” vs. “China”
• May retrieve irrelevant documents that include ambiguous terms.– “bat” (baseball vs. mammal)
– “Apple” (company vs. fruit)
– “bit” (unit of data vs. act of eating)
– Think about Disambiguation: HOW???
10Information Retrieval & Web Search: Introduction, S.M.Bidoki

Intelligent IR
• Taking into account the meaning of the words used.
• Taking into account the order of words in the query.
• Adapting to the user based on direct or indirect feedback.
• Taking into account the authority of the source.
11Information Retrieval & Web Search: Introduction, S.M.Bidoki

IR System Architecture
12
Text
Database
Database
ManagerIndexing
Index
Query
Operations
Searching
RankingRanked
Docs
User
Feedback
Text Operations
User Interface
Retrieved
Docs
User
Need
Text
Query
Logical View
Inverted
file
Information Retrieval & Web Search: Introduction, S.M.Bidoki

IR System Components• Text Operations forms index words (tokens).
– Stopword removal– Stemming
• Indexing constructs an inverted index of word to document pointers.
• Searching retrieves documents that contain a given query token from the inverted index.
• Ranking scores all retrieved documents according to a relevance metric.
13Information Retrieval & Web Search: Introduction, S.M.Bidoki

IR System Components …
• User Interface manages interaction with the user:– Query input and document output– Relevance feedback– Visualization of results
• Query Operations transform the query to improve retrieval:– Query expansion using a thesaurus– Query transformation using relevance feedback
14Information Retrieval & Web Search: Introduction, S.M.Bidoki

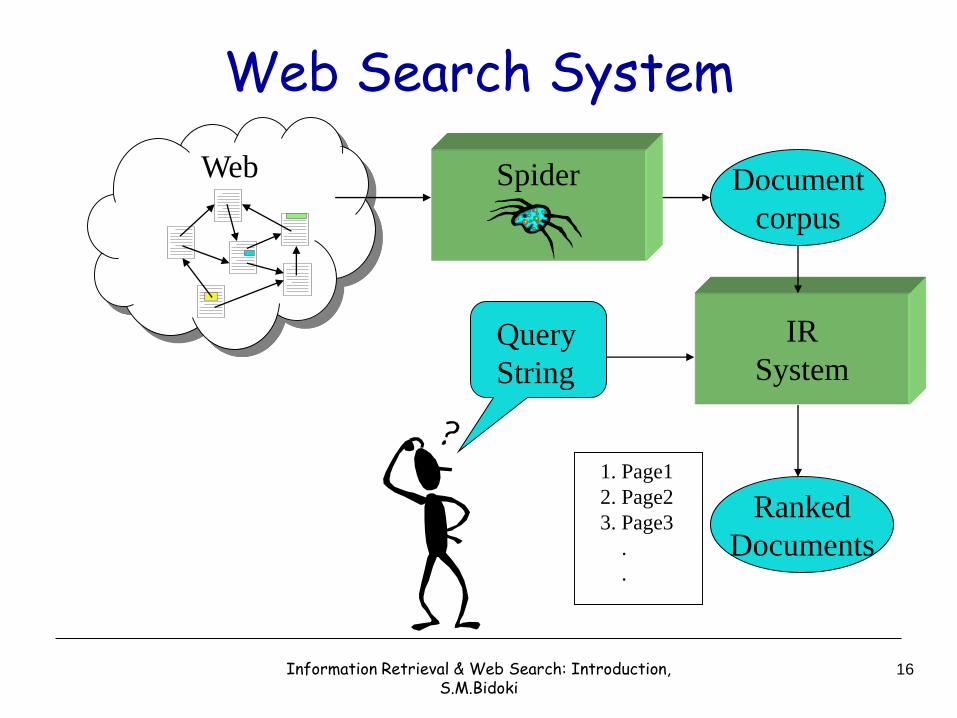
Web Search
• Application of IR to HTML documents on the World Wide Web.
• Searching for pages on the World Wide Web is the most recent “killer application”
• Web search is similar to IR but with some differences.
15Information Retrieval & Web Search: Introduction, S.M.Bidoki
Web Search System
16
Query
String
IR
System
Ranked
Documents
1. Page1
2. Page2
3. Page3
.
.
Document
corpus
Web Spider
Information Retrieval & Web Search: Introduction, S.M.Bidoki

17
Web Challenges• Huge size of Distributed information
– 11.5 billions pages (2005)– 64 billions pages (05 June, 2008)
• Proliferation and dynamic nature– New pages are created at the rate of 8% per week– Only 20% of the current pages will be accessible
after one year – New links are created at rate 25% per week– Many documents change or disappear rapidly (e.g.
dead links)
Information Retrieval & Web Search: Introduction, S.M.Bidoki

Growth of Web Pages Indexed
18
Assuming 20KB per page,
1 billion pages is about 20 terabytes of data.
Bil
lions
of
Pag
es
Inktomi
AllTheWeb
Teoma
Altavista
Information Retrieval & Web Search: Introduction, S.M.Bidoki

19
Web Challenges …• Heterogeneous contents
– HTML/Text/Audio/…– Languages– Character sets
• Unstructured and Redundant Data– No uniform structure, HTML errors, up to 30%
(near) duplicate documents.
• Quality of Data– No editorial control, false information, poor quality
writing, typos, etc.
• Users of web are growing exponentially
Information Retrieval & Web Search: Introduction, S.M.Bidoki

20
What is the success reason of the Web?
• A distributed system
• A simple protocol
• Production and generation is very simple
Information Retrieval & Web Search: Introduction, S.M.Bidoki

Web Structure
xxp )(
Information Retrieval & Web Search: Introduction, S.M.Bidoki
21
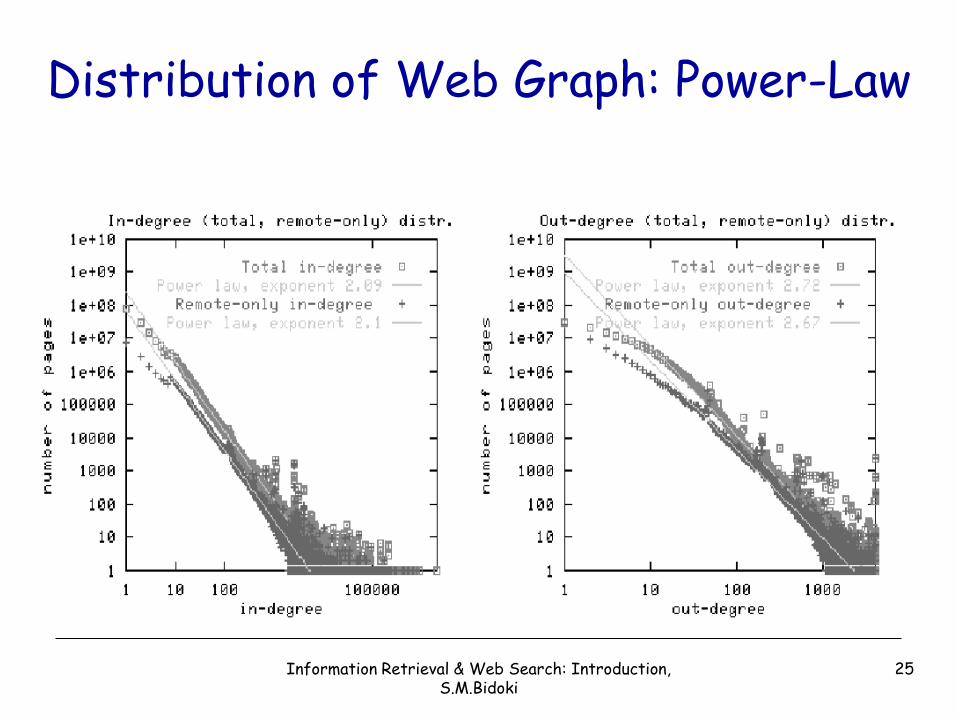
• Web graph has Bow-tie shape
• It has scale-free topology– Many features of graph
follow a power-law distribution
– The core has small-worldproperty
• the shortest directed path from any page in the core to any other page in the core involves 16–20 links on average

22
Web a Scale Free Network
• A scale-free network is characterized by a few highly-linked nodes that act as “hubs” connecting several nodes to the network.
• It follows Power Law– In/out degree of nodes
Information Retrieval & Web Search: Introduction, S.M.Bidoki

23
Random Vs Scale-Free
Information Retrieval & Web Search: Introduction, S.M.Bidoki

24
Power-Law
xxP )(
)log(log)log()log( xxp
Zipf’s Law
Information Retrieval & Web Search: Introduction, S.M.Bidoki
25
Distribution of Web Graph: Power-Law
Information Retrieval & Web Search: Introduction, S.M.Bidoki

Zipf’s Law on the Web
• Number of in-links/out-links to/from a page has a Zipfian distribution.
• Length of web pages has a Zipfian distribution.
• Number of hits to a web page has a Zipfian distribution.
Information Retrieval & Web Search: Introduction, S.M.Bidoki
26

Zipfs Law and Web Page Popularity
Information Retrieval & Web Search: Introduction, S.M.Bidoki
27

28
Zipfs Law and Content of the web pages
Information Retrieval & Web Search: Introduction, S.M.Bidoki

29
Web Retrieval
User
Space
Information
SpaceMatching
RetrievalBrowsing
Index termsFull text
Full text + Structure (e.g. hypertext)
Search
Engine
Information Retrieval & Web Search: Introduction, S.M.Bidoki
Search engine is an IR system!

30
Web IR (SE) Challenges (1)
• The definition of Relevancy• The connectivity with content in Web
– A huge graph
• Different type of Queries– Narrow
• Needle in a haystack
– Wide• Overlapping with many areas• User have Poor patience: they commonly browse through the
first ten results (i.e. one screen) hoping to find there the “right” document for their query
Information Retrieval & Web Search: Introduction, S.M.Bidoki

31
Web IR (SE) Challenges (2)
• Rich-get-richer problem– It takes a long time for a young high quality web
pages to receive an appropriate quality
– Unfairness
Information Retrieval & Web Search: Introduction, S.M.Bidoki

32
Web IR (SE) Challenges (3)
• Crawling challenges– Huge size of information with dynamic nature
– Freshness & coverage• Google covers only 70% of the Web
– A suitable scheduling policy
– Hidden web (600 times bigger)
• Using meta search engines to increase coverage– Merging and ranking problem
Information Retrieval & Web Search: Introduction, S.M.Bidoki

33
Web IR (SE) Challenges (4)
• User evaluation is subjective and changes in time– Relevancy between a query and document depends on user and
time
– Two users with the same query expect different results
Information Retrieval & Web Search: Introduction, S.M.Bidoki

34
Web IR (SE) Challenges (5)
• Query Ambiguity– Python
– Car & automobile
Information Retrieval & Web Search: Introduction, S.M.Bidoki

35
Web IR (SE) Challenges (6)
• Spamming phenomenon– it is crucial for business sites to be ranked highly by the major
search engines. – There are quite a few companies who sell this kind of expertise
(also known as “search engine optimization”) and actively research ranking algorithms and heuristics of search engines, and know how many keywords to place (and where) in a Web page so as to improve the page’s ranking
• Content & Connectivity Spamming
Information Retrieval & Web Search: Introduction, S.M.Bidoki

36
Search Engines Trends
• 625 million search queries are received by major search engines each day
• 80% of web surfers discover the new sites that they visit through search engines
• Web search currently generates more than 85% of the traffic to most web sites
Information Retrieval & Web Search: Introduction, S.M.Bidoki

37
Components of Search Engines
• Crawling
• Indexing
• Ranking
Information Retrieval & Web Search: Introduction, S.M.Bidoki

38
Architecture of Search Engines
Crawler(s)
Page Repository
Indexer Module
CollectionAnalysis Module
Query Engine
Ranking
Client
Indexes : Text Structure Utility
Queries Results
Web
Information Retrieval & Web Search: Introduction, S.M.Bidoki

39
Web Crawling Issues
• Coverage– Google, the biggest search engine, covers only 70% of
web content
– We must focus on high quality pages
• Freshness– Keep the copy in synchronize with the source pages
• Politeness– Do it without disrupting the web and obeying the
webmasters constrains
Information Retrieval & Web Search: Introduction, S.M.Bidoki

40
Web Crawling Issues
Information Retrieval & Web Search: Introduction, S.M.Bidoki

Web crawling
Information Retrieval & Web Search: Introduction, S.M.Bidoki
41
Crawler

42
Crawling scheduling
Downloader
Web
Repository
Ranking
Algorithm
URLs and Links
Information Retrieval & Web Search: Introduction, S.M.Bidoki

43
Indexing
• Text Operations forms index words (tokens).– Stopword removal
– Stemming
• Indexing constructs an inverted index of word to document pointers.
Information Retrieval & Web Search: Introduction, S.M.Bidoki

44
Indexing Systems
• Google file system
• MG4J (Managing Gigabytes for Java)
• Lucene (Java-GPL)
• Swish-e (C++-Linux)
Information Retrieval & Web Search: Introduction, S.M.Bidoki

45
Ranking : Definition
• Ranking is the process which estimates the quality of a set of results retrieved by a search engine
• Ranking is the most important part of a search engine
Information Retrieval & Web Search: Introduction, S.M.Bidoki

46
Ranking Types
• Content-based – Classical IR
• Connectivity based (web)– Query independent
– Query dependent
• User-behavior based
Information Retrieval & Web Search: Introduction, S.M.Bidoki

47
• Ranking is a function of query term frequency within the document (tf) and across all documents (idf)
– Vector space
– Probabilistic
Classical Information Retrieval
WordsDocs
1
2
w
1
2
n
Query
Information Retrieval & Web Search: Introduction, S.M.Bidoki

48
Classical Information Retrieval
• This works because of the following assumptions in classical IR:– Queries are long and well specified
– Documents (e.g., newspaper articles) are coherent, well authored, and are usually about one topic
– The vocabulary is small and relatively well understood
Information Retrieval & Web Search: Introduction, S.M.Bidoki

49
Web information retrieval
• Queries are short: 2.35 terms in avg.• Huge variety in documents: language,
quality, duplication• Huge vocabulary: 100s millions terms• Deliberate misinformation• Spamming!
– Its rank is completely under the control of Web page’s author
Information Retrieval & Web Search: Introduction, S.M.Bidoki
50
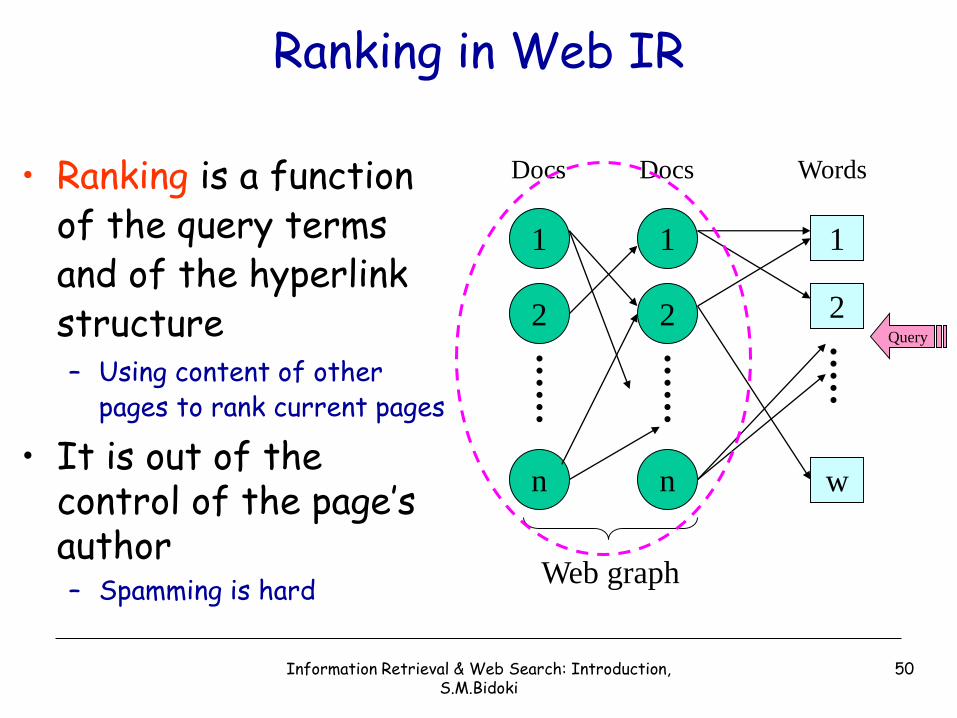
Ranking in Web IR
• Ranking is a function of the query terms and of the hyperlink structure– Using content of other
pages to rank current pages
• It is out of the control of the page’s author– Spamming is hard
WordsDocsDocs
1
2
w
1
2
n
1
2
n
Web graph
Query
Information Retrieval & Web Search: Introduction, S.M.Bidoki

Ref.
• http://ce.yazd.ac.ir/zareh/courses/webir/
Information Retrieval & Web Search: Introduction, S.M.Bidoki
51

















