44
Big Data: Business, not as usual Dr. Ir. Patrick A. De Mazière
| Date post: | 23-Jan-2017 |
| Category: |
Business |
| Upload: | ikinnoveer |
| View: | 302 times |
| Download: | 0 times |

Big Data: Business, not as usualDr. Ir. Patrick A. De Mazière

QUADRI
Structuur Workshop
• 1.5u Big Data: Ex Cathedra wat, spelers en analysetechnieken big data analyses at your service…
• 30’ Pauze• 1.5u Nu is het aan jullie Q & A Tips & tricks ivm the dark side of the net Weetjes

QUADRI
Bio• Patrick De Mazière, °1973
• Burg. Ir. Computerwetenschappen, Programmatuur (KU Leuven, 1998)
• PhD Biomedische wetenschappen (KU Leuven, 2007)
• Masterclass High-Tech Entrepreneurship (KU Leuven-LRD, 2010)
• Postdoc, Neurofysiologie/Fac. Geneeskunde (KU Leuven, 2007 -)
Lid stuurgroep KU Leuven HPC (2005 - 2010)
Data/Text Mining (~ HPC)
Hersenonderzoek via mathematische modellen (~ HPC + Data Mining)
Statistiek
Onderwijsprojecten
• Onderzoekscoördinator ITech & Lector TI (UCLL, 2012 -)

QUADRI
Terminologie: big, deep, broad data• Big Data ~ data wetenschap:
Gigantische datasets (on)gestructureerd en bijhorende algoritmes om patronen, trends etcte detecteren in die datasets. Meestal gerelateerd aan het menselijke gedrag. Big data is om anderen te observeren
• Deep Data: Combinatie van een expert zijn domeinkennis met data wetenschap. Gevorderde interpretaties en pre-processing mogelijkheden. Deep data is meestal ook gecollecteerd met een bepaalde bedoeling/analyse in het achterhoofd. Deep data is om te reflecteren
• Broad data: Niet noodzakelijk big data, maar eerder gestratificeerde & diverse data (bronnen). Zoveel mogelijk weten vanuit verschillende standpunten, invalshoeken in plaats van veel te weten vanuit 1 invalshoek. Is dus om bestaande data te verrijken.

QUADRI
Big Data
Refereert aan 3,5 zaken• Big• Data
• Analyse
• Interpretatie resultaten

QUADRI
Wat is BigSchaal: Byte Kb Mb Gb Tb Pb Exab Zettab Yottab
• 8 keer 0 of 1 8 bit of 1 byte
• Deze presentatie ± 15 Megabyte
• DVD (= ± 6.5CDs) 4.5 Gigabyte
• Een doorsnee univ-bib 1 Terabyte of 3j lang muziek aan CD kwaliteit
• Ons menselijk functionele geheugen ± 1.25 Tb
• UZ Leuven, PACS systeem (2015) 1.6 Petabyte
Anno 2014: Rijstkorrels / jaar opgegeten = 27.5 quadriljoen (27.5 peta korrels)
Wereldwijd data-verbruik / 30 minuten = 40.4 petabytes

QUADRI
Wat is DataAlles wat ge kunt “bedenken”• Hopen cijfertjes (CERN, bevolkingsdata, …)• Gouden Gids• Medisch (fMRI, MRI, PET, CT scanners, EMD/GMD, …)• Biomedisch (omeomics: genomics, proteomics, ….)• Verkeersinformatie (~ Google Maps + traffic info)• Social Media Interacties (FB, Google+, Twitter, LinkedIn, …)• …

QUADRI
Wie is/levert Big Data (2012)fMRI data (hersenscan /1u @ 1.5M res/2s) 80 Gb
Database Google Earth (2014) > 20 Pb
Dropbox > 50 Pb
Facebook Cloud > 300 Pb
Microsoft Cloud (Azure + Hotmail) > 300 Pb
CERN Data cloud (Budapest + Geneva) 340 Pb
Google Cloud > 600 Pb
Amazon’s cloud > 900 Pb
Bronnen: http://www.extremetech.com/computing/129183-how-big-is-the-cloud, 2012
Kostprijs voor 40Pb /maand = ± $100.000Google betaalde in 2007 2.4 mia$ voor zijn datacenters
Big data = big business

QUADRI
FB in detail (2012)• 9% dagelijkse internet-verkeer
• > 1 000 000 000 000 (1T) webpage views/maand
• 300 miljoen foto’s extra /dag
• > 1 miljoen websites
• > 550 000 applicaties gelinkt aan FB (Candy Crush, Farmville, ….)
• > 10 data centers; 60.000 servers
• 845 miljoen gebruikers / maand
• De echte grootte ? Company secret
FB Data center in North Carolina; 2.8 hectare; 60 MegaWatt
Bron: http://www.datacenterknowledge.com/the-facebook-data-center-faq/

QUADRI
Google in detail (2014)• 425 mio Gmail gebruikers
• Google (Dremel) scant ±70 mia items/sec; 2 mio zoekopdrachten/sec
• 16 data centers (900k servers): US/EU: 9/7; 260MW of 0.01% wereldverbruik E
• Google zal alle boeken (129 mio) gescand hebben voor 2020
• Slechts 16% van de dagelijkse internet searches zijn nieuw voor Google
• Google int 60 mia$/jaar door zijn advertising in 2014
• Op 16/8/2013 was Google offline gedurende 5 minuten => internet trafiek -40%
• 1 Google zoekopdracht vereist meer rekenkracht > Apollo 11 maanlanding
• Google Maps Traffic info ? Google traceert alle online Android devices continu
Bron: https://storageservers.wordpress.com/2013/07/17/facts-and-stats-of-worlds-largest-data-centers/http://www.factslides.com/s-Google
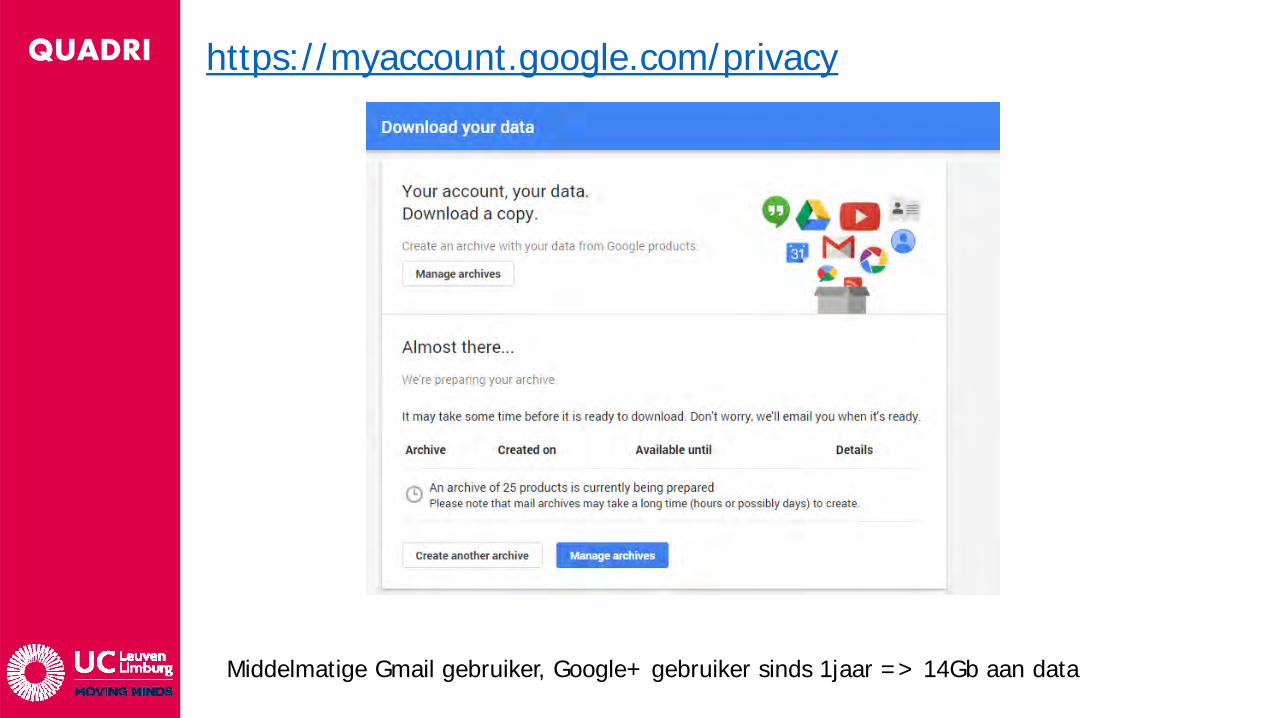
QUADRI https://myaccount.google.com/privacy
Middelmatige Gmail gebruiker, Google+ gebruiker sinds 1jaar => 14Gb aan data
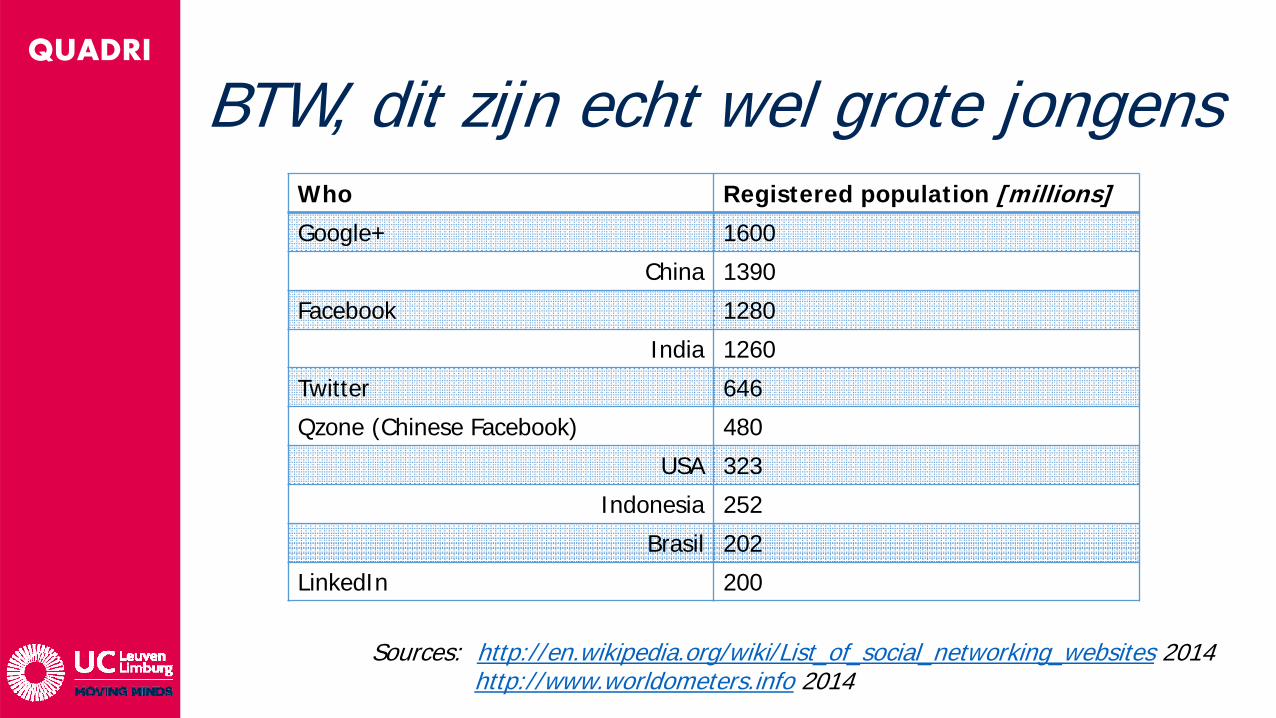
QUADRI
BTW, dit zijn echt wel grote jongensWho Registered population [millions]Google+ 1600
China 1390
Facebook 1280
India 1260
Twitter 646
Qzone (Chinese Facebook) 480
USA 323
Indonesia 252
Brasil 202
LinkedIn 200
Sources: http://en.wikipedia.org/wiki/List_of_social_networking_websites 2014 http://www.worldometers.info 2014
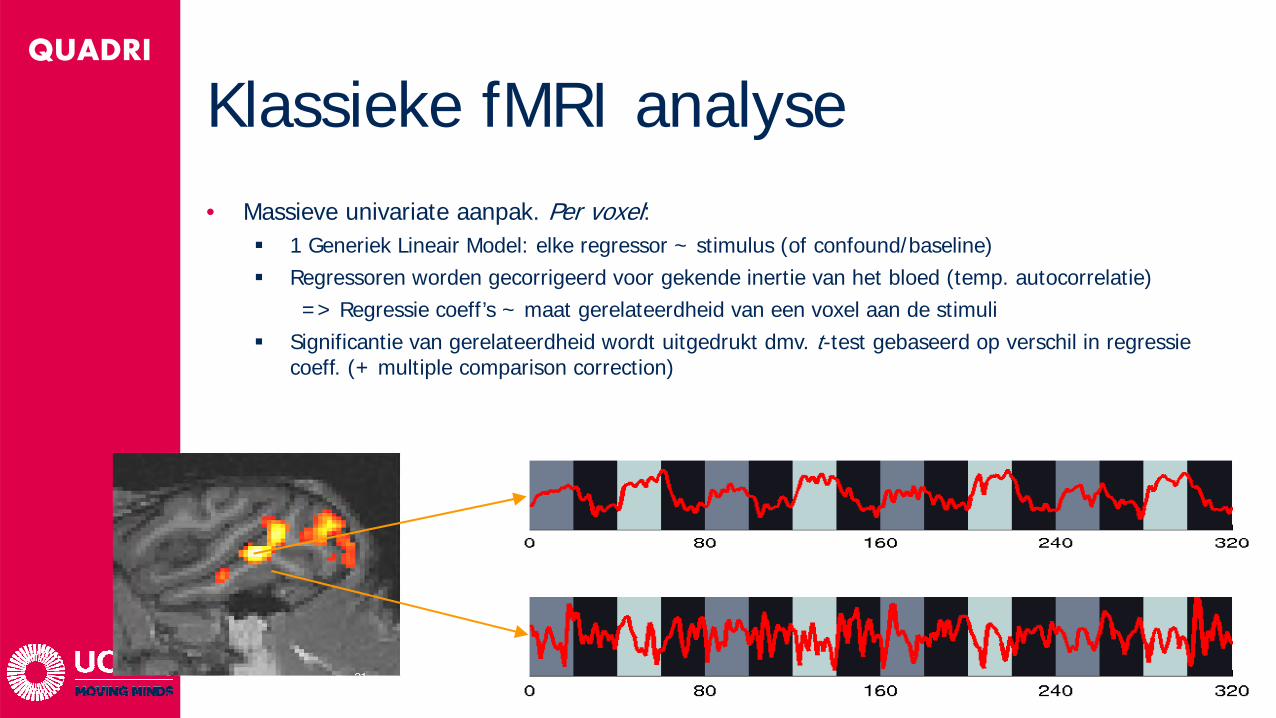
QUADRI
Klassieke fMRI analyse• Massieve univariate aanpak. Per voxel:
1 Generiek Lineair Model: elke regressor ~ stimulus (of confound/baseline) Regressoren worden gecorrigeerd voor gekende inertie van het bloed (temp. autocorrelatie)
=> Regressie coeff’s ~ maat gerelateerdheid van een voxel aan de stimuli Significantie van gerelateerdheid wordt uitgedrukt dmv. t-test gebaseerd op verschil in regressie
coeff. (+ multiple comparison correction)

QUADRI
Alternatieve, geavanceerde aanpak• Onderzoek fMRI metingen mbv. SVMs, i.c., onderzoek van de temporele consistentie van het
antwoord van voxels op de stimulus: Stimulus gevoelige voxels hebben een “identisch” antwoordpatroon over tijd
=> Predictie van accuraatheid van SVM is boven kansniveau Niet-stimulus gevoelige voxels hebben een random antwoordpatroon over tijd
=> Predictie van accuraatheid van SVM is quasi gelijk aan kansniveau
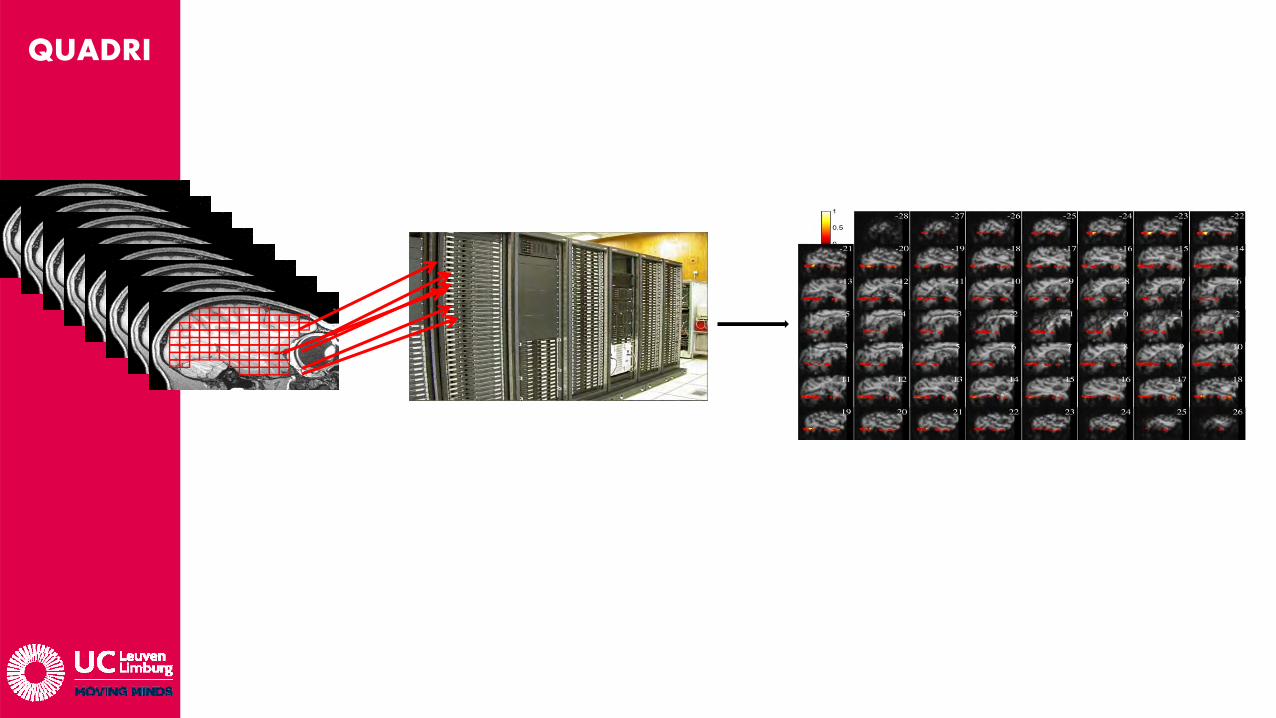
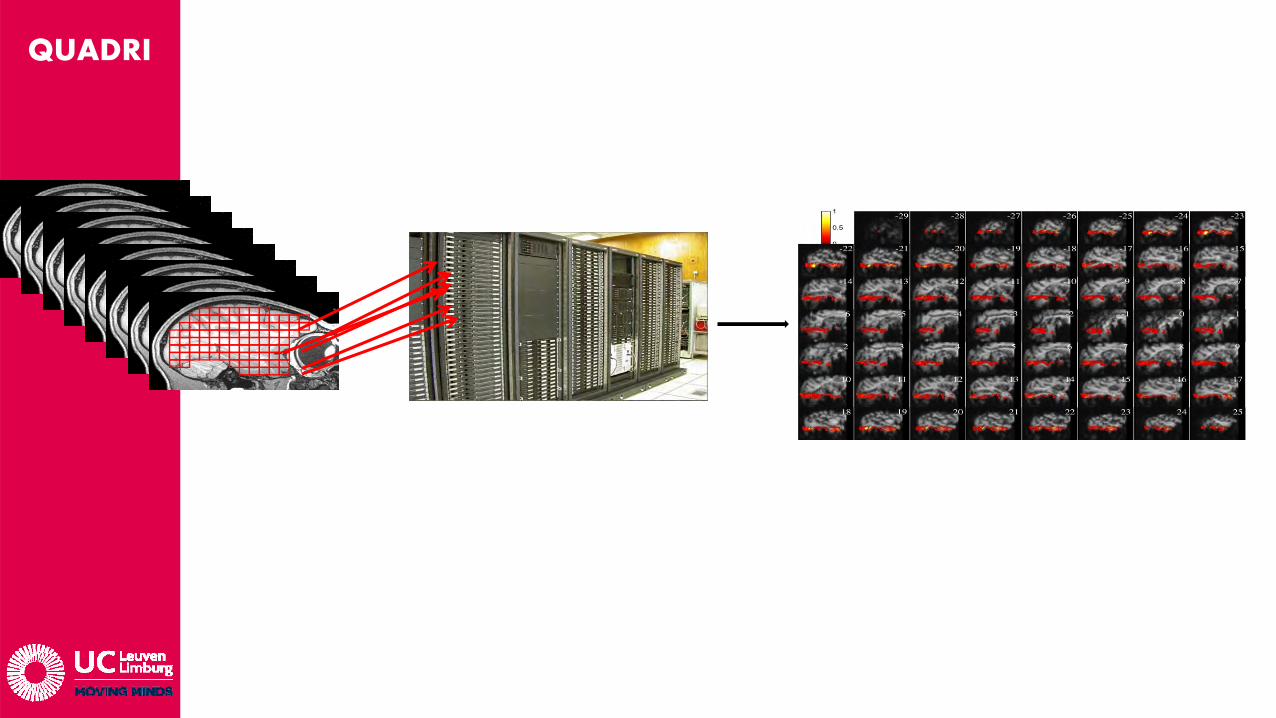
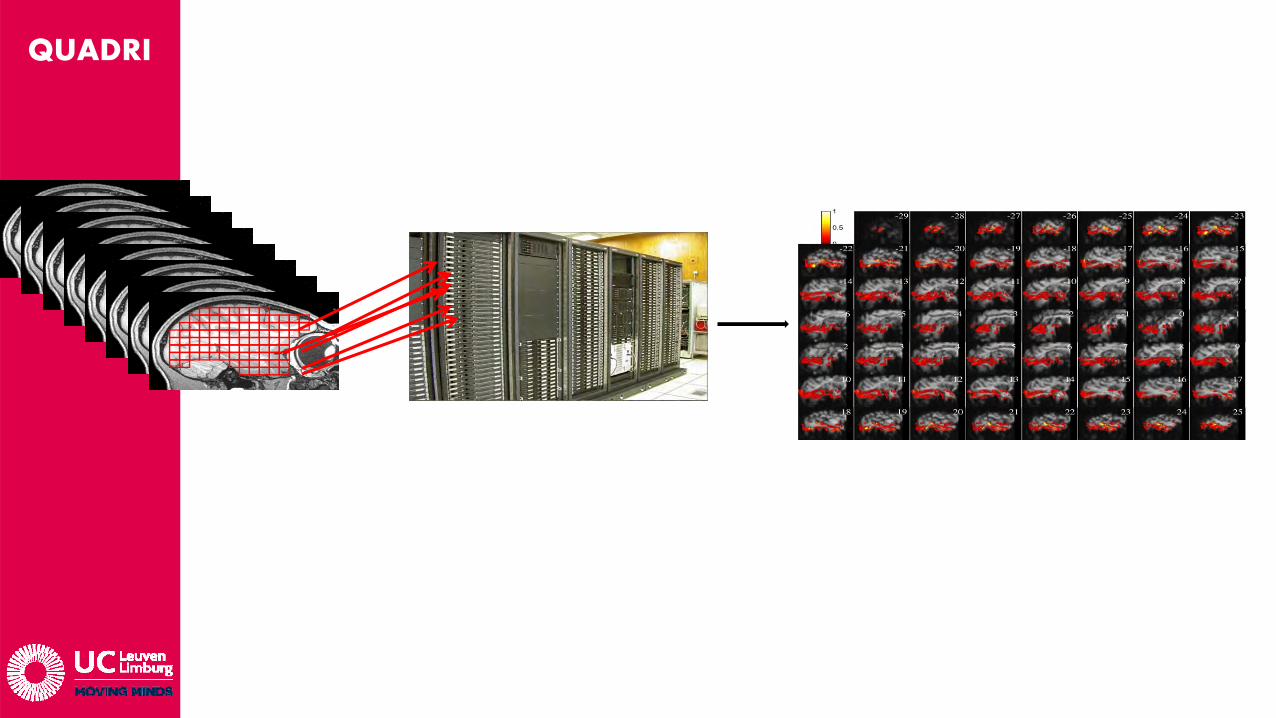
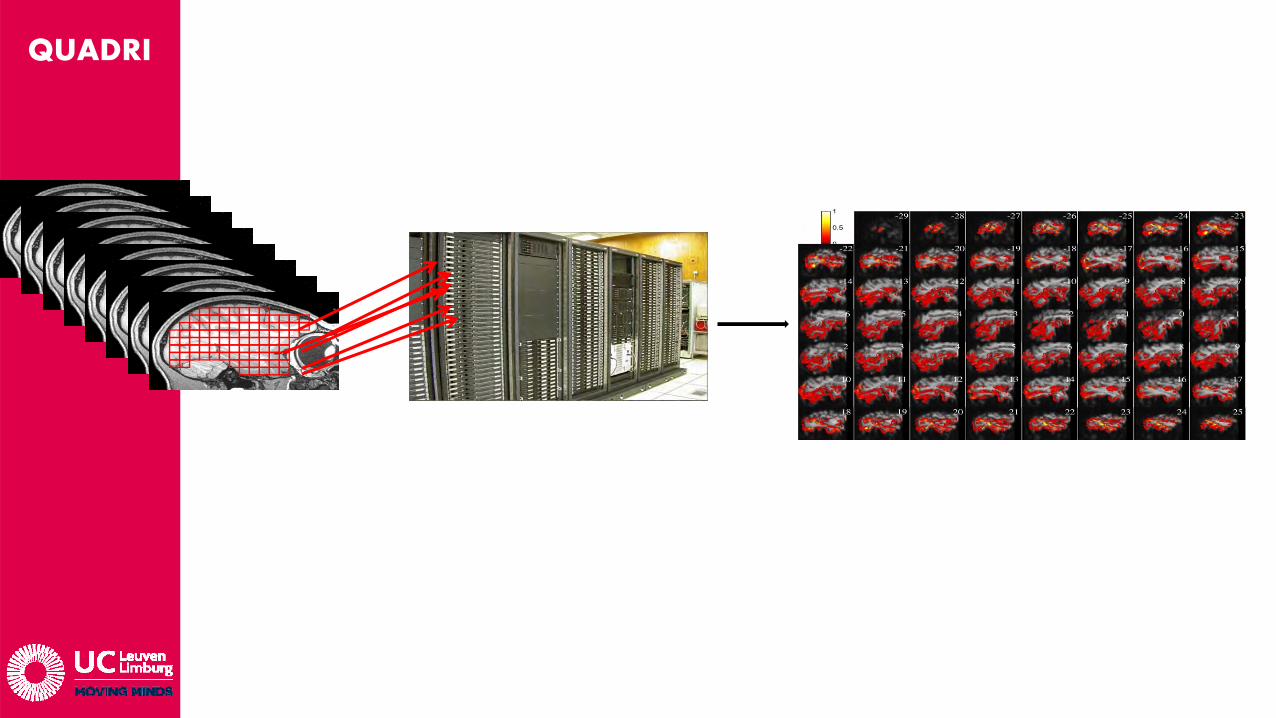
• Probleem:Men moet 500k SVMs berekenen ? Elk met 100x permutaties van de training en test sets om de betrouwbaarheid van de resultaten op een deftig niveau te brengen.Workstation Quad Core Xeon: 2jaar rekentijd ….
Verdeel & heers: Data opsplitsen in blokjes, elk blokje door 1 “computer” laten berekenen ~> HPC.Slechts 2 dagen werk !
QUADRI
QUADRI
QUADRI
QUADRI
QUADRI
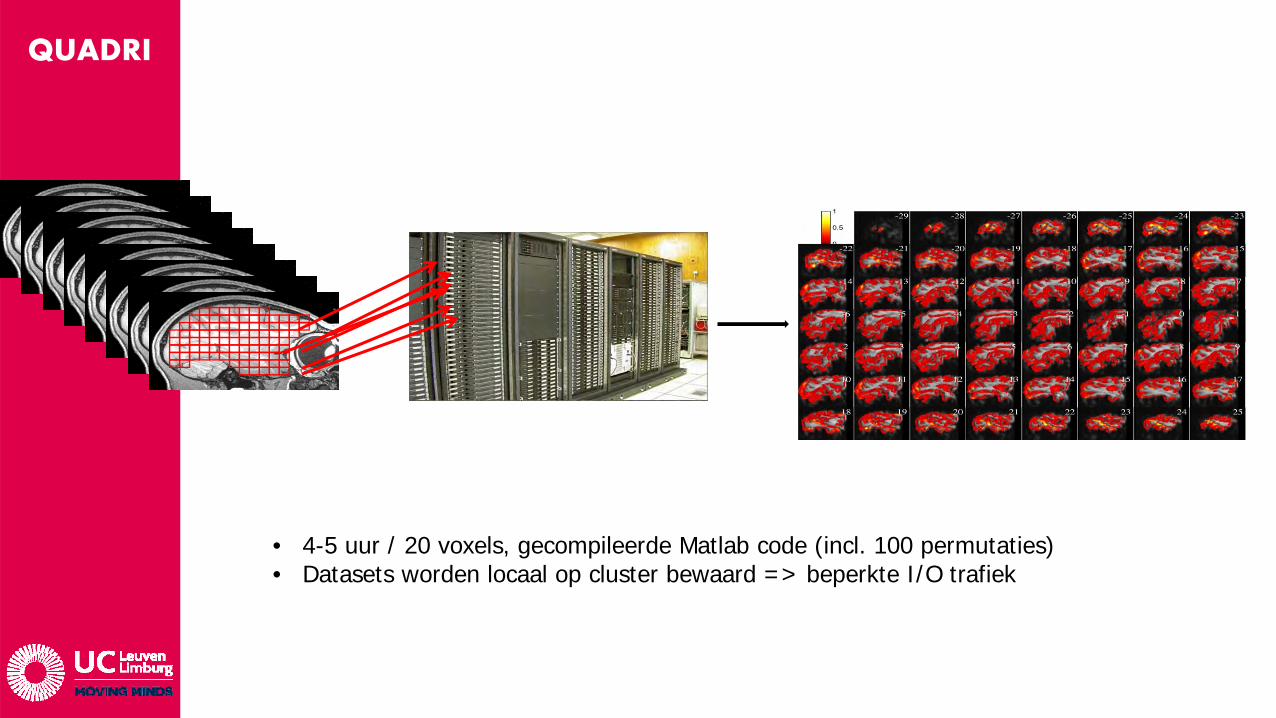
QUADRI
• 4-5 uur / 20 voxels, gecompileerde Matlab code (incl. 100 permutaties)• Datasets worden locaal op cluster bewaard => beperkte I/O trafiek

QUADRI Analysemethoden in Big Data Teaser• Aandachtspunten• Numerieke & Visuele analysetechnieken
Computerkracht vs realiteit• Wet van Moore: computerkracht x2 / 18 maanden• Wet van Carlson: complexiteit/kost groeit exponentieel

QUADRI
1. Data & Resultaat Integriteit
• Data check = belangrijk ! Volledig ? Representatief ? (!) Outliers
• Controle van vals positieven en negatieven
• Hoogdimensionaal+ veel data uiteraard

QUADRI
2. “Numerieke” analysemethodes• Summatieve statistiek (gemiddelde, variantie, sd, …)• (Multivariate) analyses: ANOVA, MANOVA, ANCOVA, …• Model-gebaseerde technieken
~ Fitten van data aan een functie (rechte, polynoom, …)~ (Lineaire) Regressie modellen
• Unsupervised categorisatie >> predictie• Feature extractie (prototypes)
Vaak weet je op voorhand wat je zoekt, ga je uit van een bepaald model. Bruikbaarheid is beperkt, al levert het indicaties.

QUADRI
3. Visuele analysemethodes
Ook numeriek uiteraard, maar beter interpreteerbaar
• Parallelle coördinaten
• Supervised clustering (k-means, Fuzzy clustering, …)
• Projectie technieken (PCA, MDS, …)
• AI/Machine Learning: Self-organising maps (SOM), U-maps
Meestal vrij complexe berekeningen (die veeeeel tijd & CPU vragen), maar wel zeer verhelderend zijn en meestal niet-model gebaseerd

QUADRI
Parallelle Coördinaten
• Is ne simpele om zelf te doen als je cat kent
• Beschouw data als Excel bestand: Elke kolom een variabele/eigenschap/parameter Elke rij een voorkomen van je data (sample)
• Herschaal (normaliseer) elke kolom, bijvoorbeeld [min, max] -> [-100, 100]
• Zet uit in een grafiek: elke kolom is 1 as, elk sample teken je op die as met de kleur van zijn cat en volgens schaal
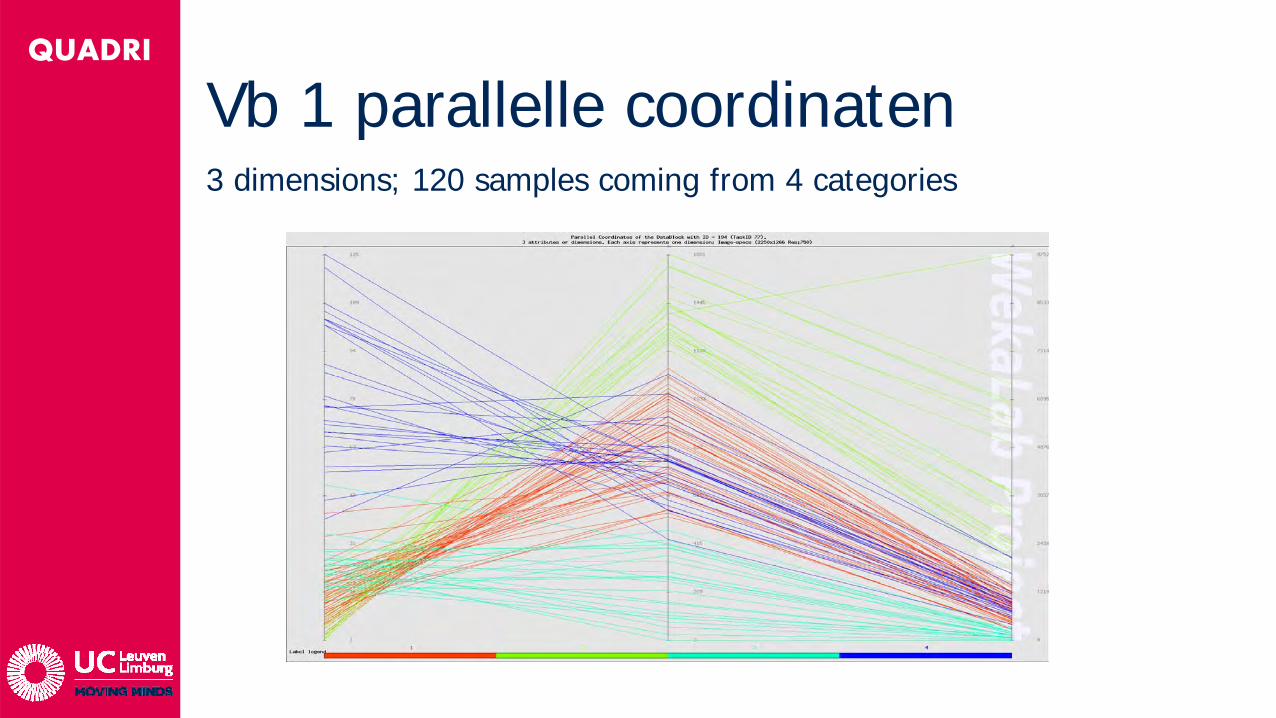
QUADRI
3 dimensions; 120 samples coming from 4 categories
Vb 1 parallelle coordinaten
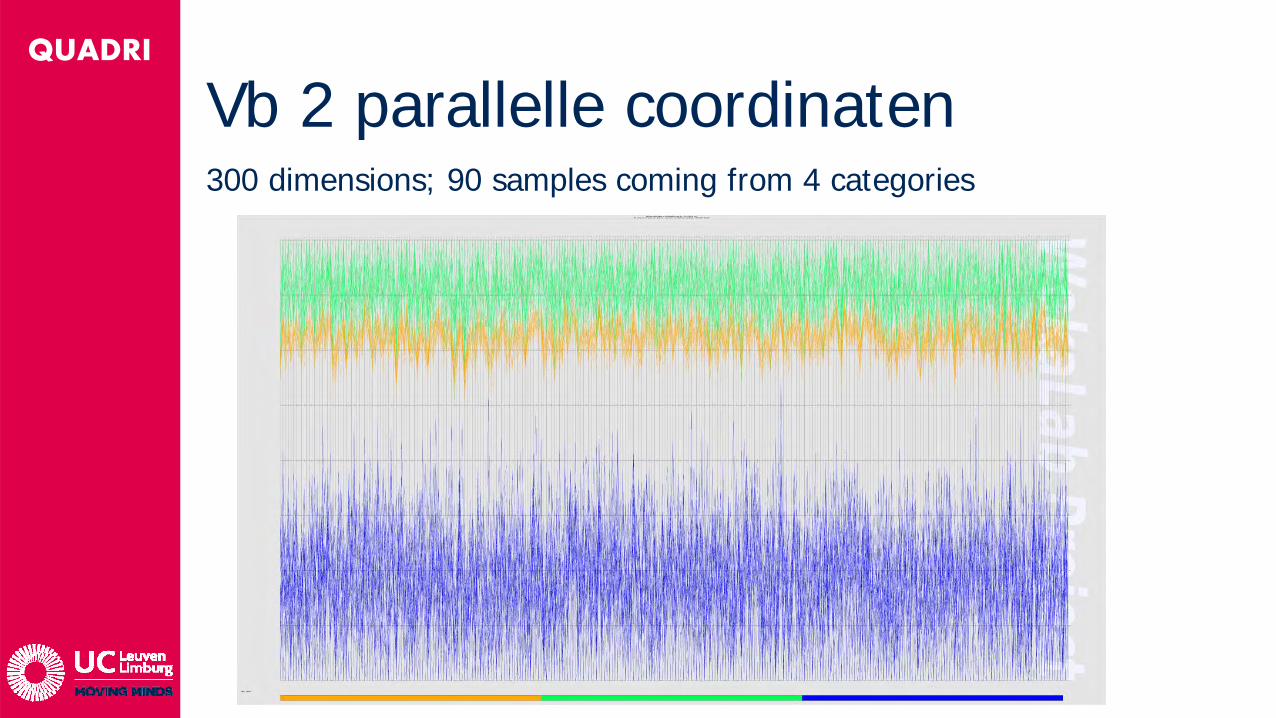
QUADRI
Vb 2 parallelle coordinaten300 dimensions; 90 samples coming from 4 categories

QUADRI
Vb PCA (principale comp analyse)Zelfde 300 dimensions; 90 samples coming from 4 categories

QUADRI
Text mining
• Elk document wordt voorgesteld in functie van aanwezige woorden (elk woord-stam is een dimensie). Aantal voorkomens wordt bijgehouden
• Verzameling documenten kan je dan mappen op de unie van al deze dimensies van de verschillende documenten.
= veel getallekes (teveel om te vatten)=> Visualiseren (MultiDimensional Scaling bijvoorbeeld)

QUADRI
Text Mining – MDS voorbeeld

QUADRI
SOM – U-maps
• Opnieuw startend van text mining resultaat: voorstelling van elk document in extreem hoog-dimensionale ruimte (> 1.5 miljoen dimensies voor zelfstandige naamwoorden en werkwoorden alleen, vertrekkende van 7000 documenten)
• Artificieel Neuraal Network gaat mapping zoeken (niet-lineair, unsupervised). 1 week rekenwerk op workstation
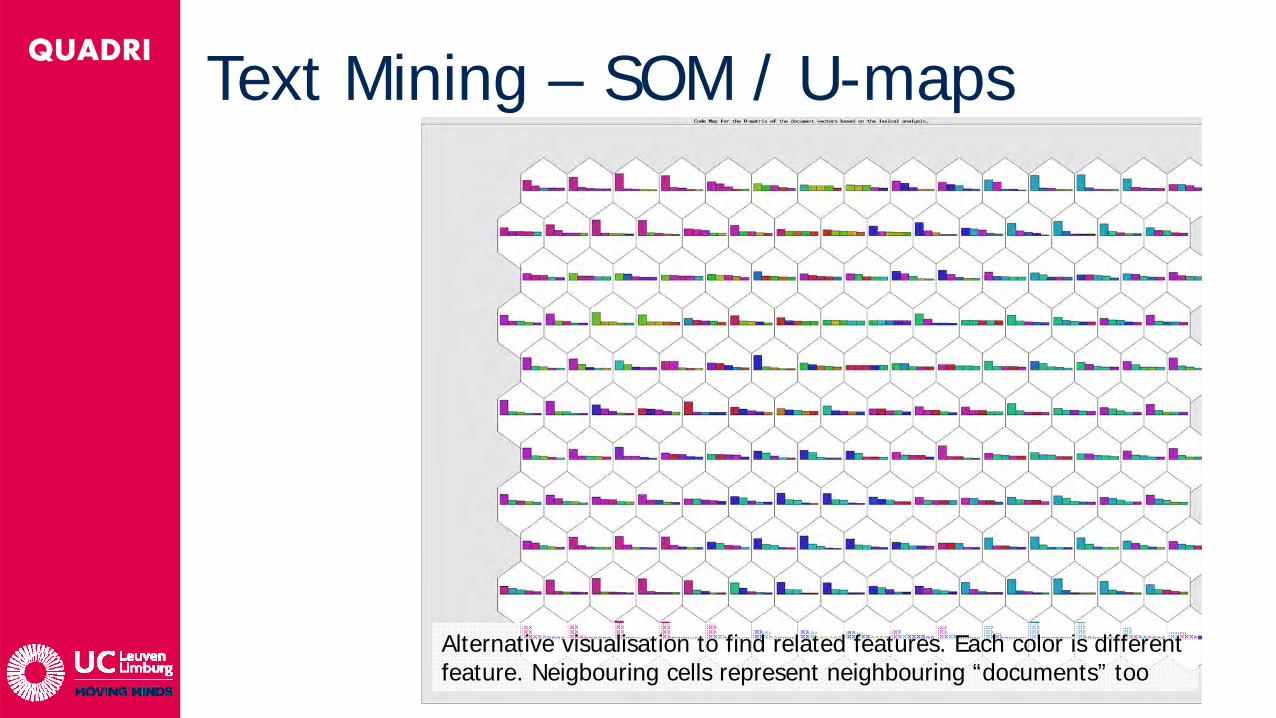
QUADRI Text Mining – SOM / U-maps
Alternative visualisation to find related features. Each color is different feature. Neigbouring cells represent neighbouring “documents” too

Genoeg theorie…
Toepassingen nu !

QUADRI
Social Media gebruiken ? Ja, maar…
• FB, Google+, … hebben data zat over jou, je klanten en je concurrenten, maar ze (ver)sturen je die uiteraard niet op (simpel) verzoek
• Oplossing: methodisch, indirect werken en de social media voor jou laten werken en eventueel zelf data verzamelen

QUADRI
Strategie: 1. Definieer InfluencersDefinieer je influencers : zij die jouw kar gaan trekken
1. Relevantie/Context: • In welk domein wil je actief worden ?• Wie is daar nog actief ?
2. Wat is hun bereik ? • Hoeveel followers, readers, likes, connecties moeten ze hebben? • In welk domein moeten die mensen voornamelijk zitten ?
3. Wat moet hun activiteitsgraad/resonantie zijn ?• Followers moeten niet alleen lezen maar ook het product kopen• Zijn het echte beïnvloeders of gewoon goede cursiefjes schrijvers• Zijn het mensen met gezag/aanzien/naam

QUADRI
Strategie: 2. Zoek die InfluencersZoek die influencers
1. Search Engine Optimisation (SEO)• Gewoon goed googlen, bingen, …• Search Engines gebruiken social media invloed in hun pageranks• Google alerts (https://www.google.com/alerts; maar geen SM)
2. Gebruik Social Media crawlers : 1. www.klout.com, 2. www.traackr.com3. www.kred.com4. www.kissmetrics.com5. www.appinions.com6. buzzsumo.com7. www.brandwatch.com
3. Werk je in, in de social media (bijv. hashtag research > hootsuite) om meer van hen te weten
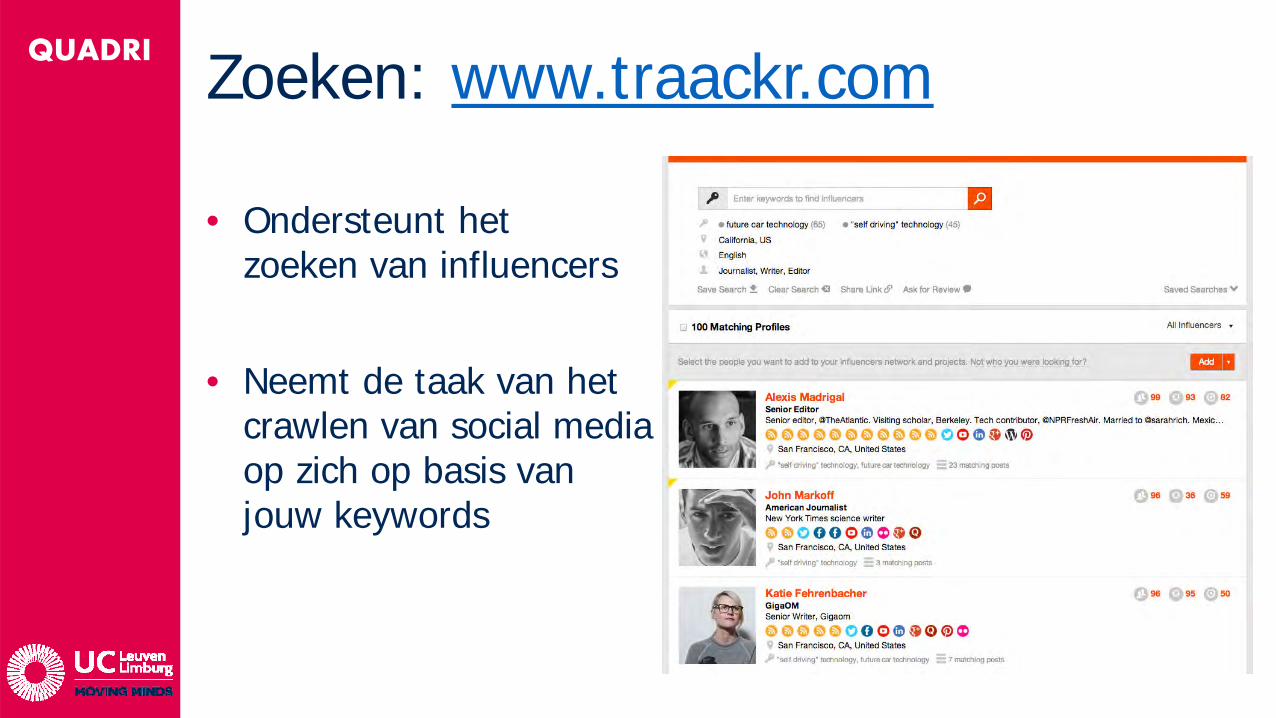
QUADRI Zoeken: www.traackr.com
• Ondersteunt het zoeken van influencers
• Neemt de taak van het crawlen van social mediaop zich op basis van jouw keywords
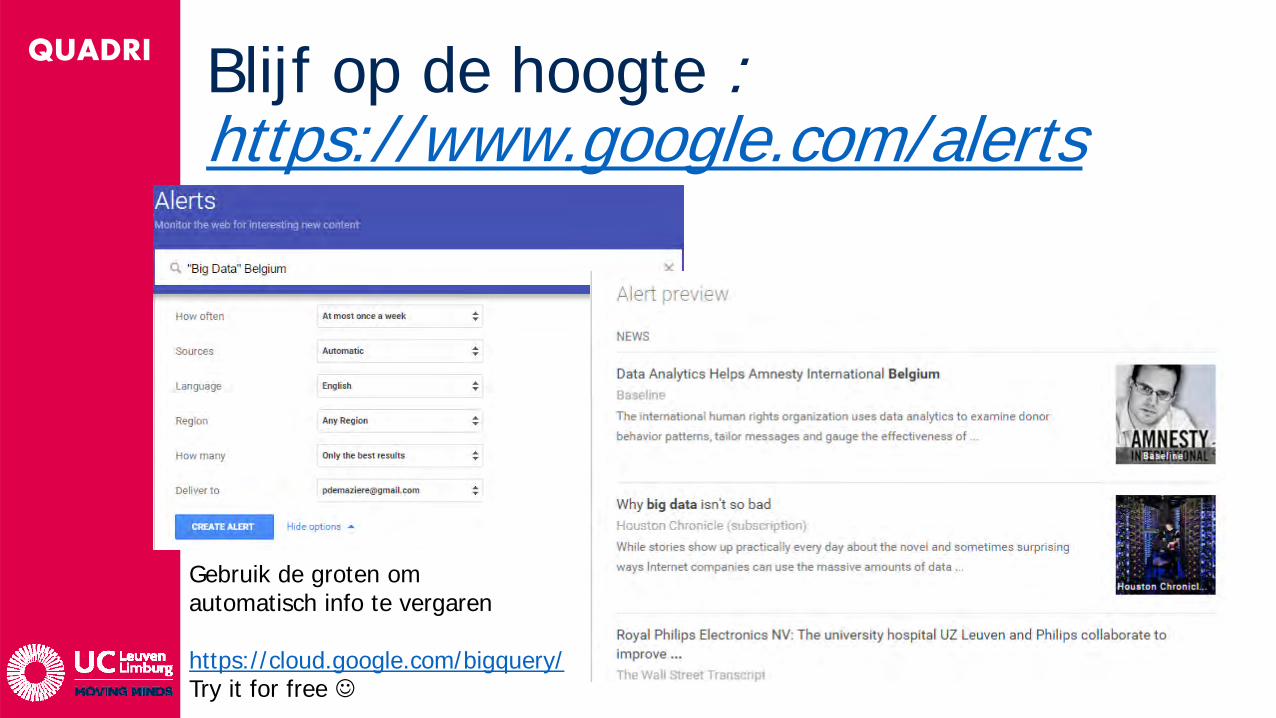
QUADRI Blijf op de hoogte : https://www.google.com/alerts
Gebruik de groten om automatisch info te vergaren
https://cloud.google.com/bigquery/Try it for free
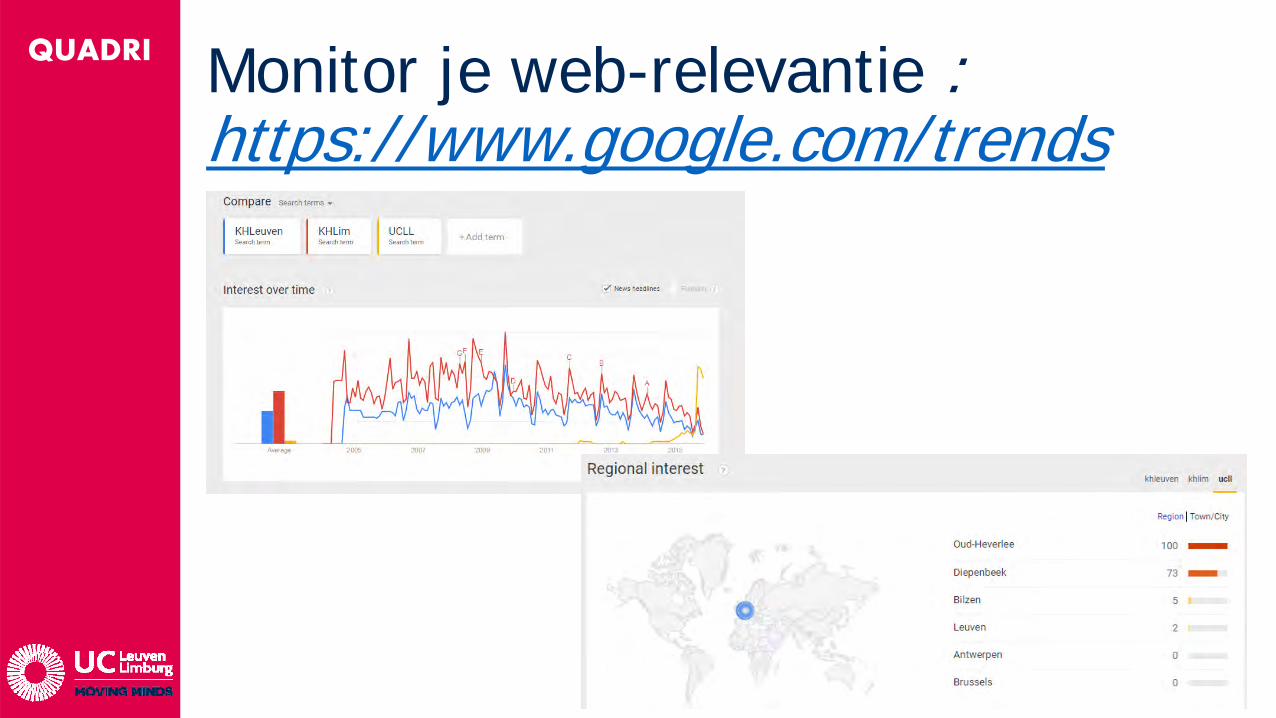
QUADRI Monitor je web-relevantie : https://www.google.com/trends

QUADRI (Eigen) bereik: www.klout.com
• Baseert zich op ± 400 factoren tweets, followers, likes, comments, retweets, mentions, connections,
1+, …
• Geeft een score terug gebaseerd op jouw online profiel tussen 0 en 100.
• Ik heb 40, kies mij dus niet niet actief op Facebook, zelfs geen account Google+, LinkedIn, Twitter, Forums etc

QUADRI
Monitor: http://buzzsumo.com
• Volg hoe jouw content zich waar via wie verspreid<> Google analytics: monitor wie naar jouw site komt
• Duid de influencers aan
• Content alerts ~ Google alerts

QUADRI Activiteit: www.kred.com ~ klout
• Monitoren van wie jou bereikt (0 – 1000) en hoeveel jij er bereikt (0 – 12) dmv hashtags / tweets
Momenteel zit Kredin een transitie

QUADRI
Centraal gebruik SM: distribueer boodschap Rapporteer activiteit per geconnecteerde SM-account “Hootsuite University” how to excel using SM
(Eigen) Bereik/Actie: www.hootsuite.com

QUADRI
Strategie: 3. Bind die Influencers
Bind de gevonden influencers aan jeHoe ?Na de pauze !



![[PPT]Communicatie Handboek · Web viewMarketingcommunicatie Checklist marketingcommunicatieplan 8. Marketingcommunicatie Hoofdstuk 9 Media 9. Media 9. Media Nederlandse persbureaus:](https://static.documents.pub/doc/80x56/5c7465c509d3f28e198c157d/pptcommunicatie-web-viewmarketingcommunicatie-checklist-marketingcommunicatieplan.jpg)













