37
Inspector Joins IC-65 Advances in Data Management Systems 1 Inspector Joins By Shimin Chen, Anastassia Ailamaki, Phillip, and Todd C. Mowry VLDB 2005 Rammohan Narendula
| Date post: | 21-Dec-2015 |
| Category: |
Documents |
| View: | 213 times |
| Download: | 0 times |

Inspector Joins IC-65 Advances in Data Management Systems 1
Inspector Joins
By Shimin Chen, Anastassia Ailamaki, Phillip, and Todd C. Mowry
VLDB 2005
Rammohan Narendula

Inspector Joins IC-65 Advances in Data Management Systems 2
Introduction
Query execution isI/O bound- so most of theresearch concentrateson main memory Goal- reduce no. of pagefaults thus reduce no. of disk I/Os
However, hash join is a special class of techniqueswhere hash-join becomesCPU bound given sufficientI/O bandwidth and employingAdvanced I/O techniques (I/O prefetching)Goal- reduce no. of cache misses

Inspector Joins IC-65 Advances in Data Management Systems 3
Exploiting Information about Data
• Ability to improve query depends on information quality• General stats on relations are inadequate
– May lead to incorrect decisions for specific queries
– Especially true for join queries
• Previous approaches exploiting dynamic information– Collecting information from previous queries
• Multi-query optimization [Sellis’88]
• Materialized views [Blakeley et al. 86]
• Join indices [Valduriez’87]
– Dynamic re-optimization of query plans [Kabra&DeWitt’98] [Markl et al. 04]
This study exploits the inner structure of hash joins

Inspector Joins IC-65 Advances in Data Management Systems 4
Exploiting Multi-Pass Structure of Hash Joins
• Idea: – Examine the actual data in I/O partitioning phase
– Extract useful information to improve join phase
I/O Partitioning Join
Extra information greatly helps phase 2
Inspection

Inspector Joins IC-65 Advances in Data Management Systems 5
Using Extracted Information
• Enable a new join phase algorithm – Reduce the primary performance bottleneck in hash joins
i.e. Poor CPU cache performance– Optimized for multi-processor systems
• Choose the most suitable join phase algorithm for special input cases
I/O Partitioning
decide Cache
PartitioningCache Prefetching
Simple Hash JoinInspection
Join Phase
New AlgorithmExtracted Information

Inspector Joins IC-65 Advances in Data Management Systems 6
Outline
• Motivation• Previous hash join algorithms• Hash join performance on SMP systems• Inspector join• Experimental results• Conclusions
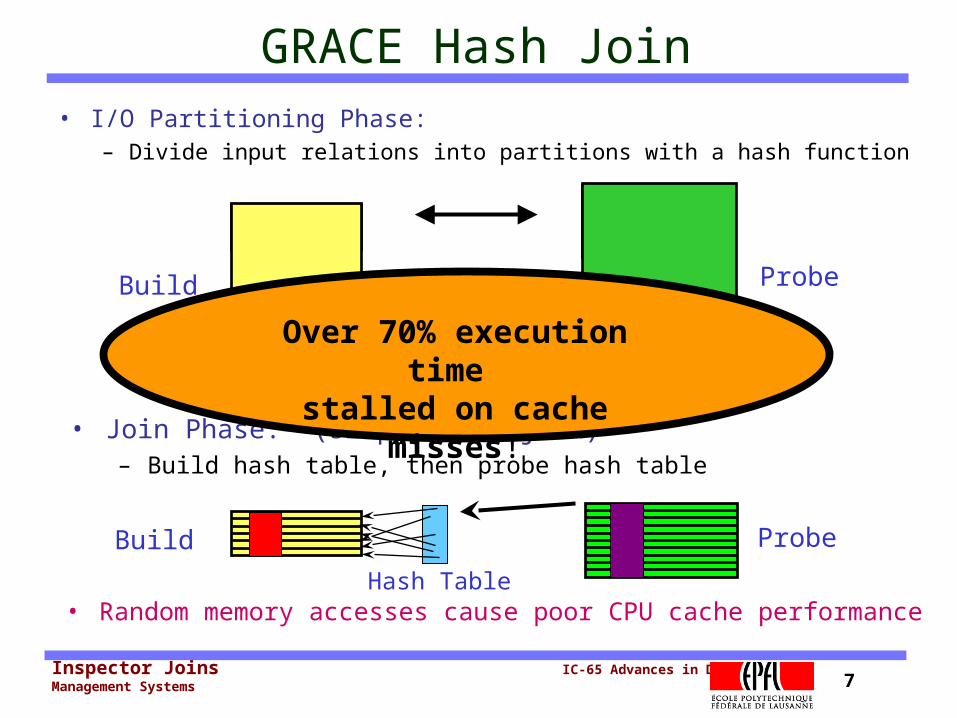
Inspector Joins IC-65 Advances in Data Management Systems 7
Hash Table
• Join Phase: (simple hash join)– Build hash table, then probe hash table
GRACE Hash Join• I/O Partitioning Phase:
– Divide input relations into partitions with a hash function
Build Probe
Build Probe
• Random memory accesses cause poor CPU cache performance
Over 70% execution time
stalled on cache misses!

Inspector Joins IC-65 Advances in Data Management Systems 8
Cache Partitioning• Recursively produce cache-sized partitions after I/O partitioning
• Avoid cache misses when joining cache-sized partitions• Overhead of re-partitioning
BuildProbeMemory-sized
PartitionsCache-sized
Partitions

Inspector Joins IC-65 Advances in Data Management Systems 9
Cache Prefetching• Reduce impact of cache misses
– Exploit available memory bandwidth– Overlap cache misses and computations– Insert cache prefetch instructions into code
• Still incurs the same number of cache misses
Hash Table
ProbeBuild

Inspector Joins IC-65 Advances in Data Management Systems 10
Outline
• Motivation• Previous hash join algorithms• Hash join performance on SMP systems• Inspector join• Experimental results• Conclusions
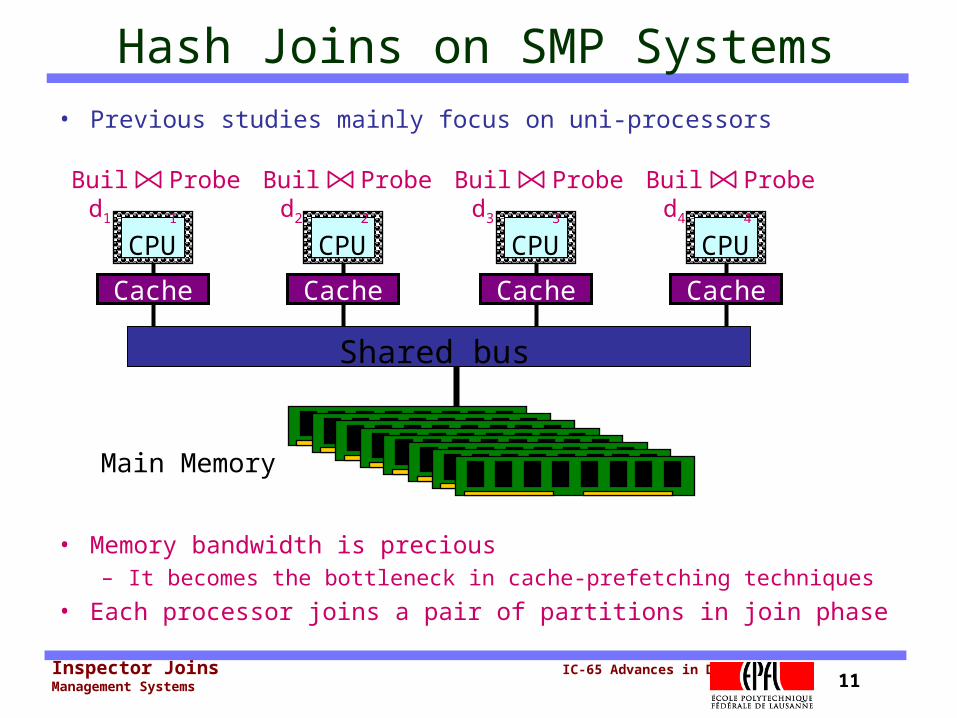
Inspector Joins IC-65 Advances in Data Management Systems 11
Hash Joins on SMP Systems• Previous studies mainly focus on uni-processors
• Memory bandwidth is precious– It becomes the bottleneck in cache-prefetching techniques
• Each processor joins a pair of partitions in join phase
Main Memory
Shared bus
Cache
CPU
Cache
CPU
Cache
CPU
Cache
CPU
Build1
Probe1
Build4
Probe4
Build2
Probe2
Build3
Probe3
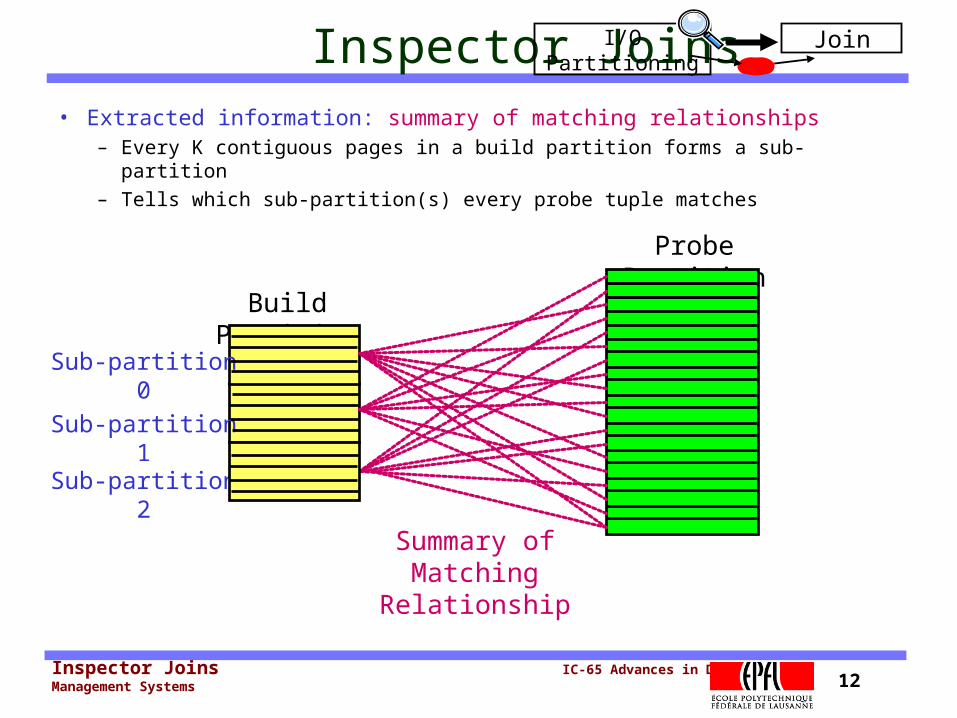
Inspector Joins IC-65 Advances in Data Management Systems 12
Inspector Joins • Extracted information: summary of matching relationships
– Every K contiguous pages in a build partition forms a sub-partition
– Tells which sub-partition(s) every probe tuple matches
Build Partition
Sub-partition 0
Sub-partition 1
Sub-partition 2
Probe Partition
I/O Partitioning Join
Summary of Matching
Relationship

Inspector Joins IC-65 Advances in Data Management Systems 13
Cache-Stationary Join Phase
• Recall cache partitioning: re-partition cost
I/O Partitioning Join
Build PartitionProbe Partition
Hash TableCPU
Cache
• We want to achieve zero copying
Copying cost
Copying cost

Inspector Joins IC-65 Advances in Data Management Systems 14
Cache-Stationary Join Phase
• Joins a sub-partition and its matching probe tuples• Sub-partition is small enough to fit in CPU cache• Cache prefetching for the remaining cache misses
• Zero copying for generating recursive cache-sized partitions
I/O Partitioning Join
Build PartitionProbe Partition
Hash TableCPU
CacheSub-partition 0
Sub-partition 1
Sub-partition 2

Inspector Joins IC-65 Advances in Data Management Systems 15
Filters in I/O Partitioning
• How to extract the summary efficiently?• Extend filter scheme in commercial hash joins• Conventional single-filter scheme
– Represent all build join keys– Filter out probe tuples having no matches
Build Relation
Filter
Mem-sized
PartitionsConstruct Test
I/O Partitioning Join
Probe Relation

Inspector Joins IC-65 Advances in Data Management Systems 16
Background: Bloom Filter• A bit vector
– A key is hashed d (e.g. d=3) times and represented by d bits
• Construct: for every build join key, set its 3 bits in vector• Test: given a probe join key, check if all its 3 bits are 1
– Discard the tuple if some bits are 0– May have false positives
0 0 0 1 1 1 0 0 0 1 1 0 0 1 0 0 0 0 0 1
Bit0=H0(key)
Bit1=H1(key)
Bit2=H2(key)
Filter

Inspector Joins IC-65 Advances in Data Management Systems 17
Multi-Filter Scheme• Single filter: a probe tuple entire build relation• Our goal: a probe tuple sub-partitions• Construct a filter for every sub-partition
• Replace a single large filter with multiple small filters
Single Filter
Build Relatio
n
Partition 0
Partition 1
Partition 2
Sub0,0Sub0,1Sub0,2
Sub1,0Sub1,1Sub1,2
Sub2,0Sub2,1Sub2,2
Multi-Filter
I/O Partitioning Join

Inspector Joins IC-65 Advances in Data Management Systems 18
Testing Multi-FiltersWhen partitioning the probe relation
• Test a probe tuple against all the filters of a partition
• Tells which sub-partition(s) the tuple may have matches
• Store summary of matching relationships in partitions– This information is used to extract probe tuples in the order of partition IDs. A
special array is constructed using count sort technique for this purpose.
Probe Relation
Partition 0
Partition 1
Partition 2
Multi-Filter
Test
I/O Partitioning Join

Inspector Joins IC-65 Advances in Data Management Systems 19
Cont’d…
• Extracting probe tuple information for every sub-partition using counting sort
– One array for each sub partition. Size of the array is number of matching probe tuples for that partition.
– The tuples are never visited or copied in the coutning sort.
• Joining pair of build and probe sub-partitions

Inspector Joins IC-65 Advances in Data Management Systems 20
Minimizing Cache Misses for Testing Filters
• Single filter scheme: – Compute 3 bit positions– Test 3 bits
• Multi-filter scheme: if there are S sub-partitions in a partition– Compute 3 bit positions– Test the same 3 bits for every filter, altogether 3*S bits
• May cause 3*S cache misses !
Test
Probe Relation
Partition 0
Partition 1
Partition 2
Multi-Filter
001
111
011S filters

Inspector Joins IC-65 Advances in Data Management Systems 21
Vertical Filters for Testing
• Bits at the same position are contiguous in memory• 3 cache misses instead of 3*S cache misses!
• Horizontal vertical conversion after partitioning build relation– Very small overhead in practice
Probe Relation
Partition 0
Partition 1
Partition 2
Test001
111
011
S filters
Contiguous in
memory
I/O Partitioning Join

Inspector Joins IC-65 Advances in Data Management Systems 22
Outline
• Motivation• Previous hash join algorithms• Hash join performance on SMP systems• Inspector join• Experimental results• Conclusions

Inspector Joins IC-65 Advances in Data Management Systems 23
Experimental Setup• Relation schema: 4-byte join attribute + fixed length payload• No selection, no projection• 50MB memory per CPU available for the join phase• Same join algorithm run on every CPU joining different partitions
• Detailed cycle-by-cycle simulations– A shared-bus SMP system with 1.5GHz processors
– Memory hierarchy is based on Itanium 2 processor
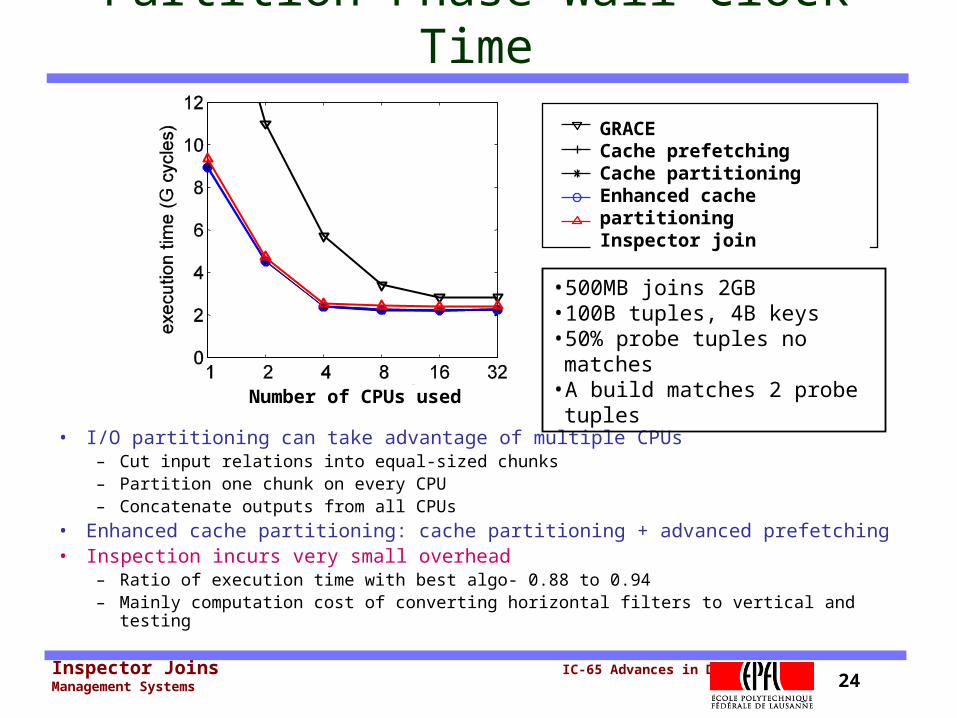
Inspector Joins IC-65 Advances in Data Management Systems 24
Partition Phase Wall-Clock Time
• I/O partitioning can take advantage of multiple CPUs– Cut input relations into equal-sized chunks – Partition one chunk on every CPU– Concatenate outputs from all CPUs
• Enhanced cache partitioning: cache partitioning + advanced prefetching• Inspection incurs very small overhead
– Ratio of execution time with best algo- 0.88 to 0.94– Mainly computation cost of converting horizontal filters to vertical and testing
GRACECache prefetchingCache partitioningEnhanced cache partitioningInspector join
•500MB joins 2GB•100B tuples, 4B keys•50% probe tuples no matches
•A build matches 2 probe tuples
Number of CPUs used

Inspector Joins IC-65 Advances in Data Management Systems 25
Join Phase Aggregate Time
• Inspector join achieves significantly better performancewhen 8 or more CPUs are used
– Because of local optimization + catch prefetching– 1.7-2.1X speedups over cache prefetching
• Memory B/W becomes bottleneck when more no of processors are used– 1.6-2.0X speedups over enhanced cache partitioning
•500MB joins 2GB•100B tuples, 4B keys•50% probe tuples no matches
•A build matches 2 probe tuples
Number of CPUs used
GRACECache prefetchingCache partitioningEnhanced cache partitioningInspector join

Inspector Joins IC-65 Advances in Data Management Systems 26
Results on Choosing Suitable Join Phase
• Case #1: a large number of duplicate build join keys– Choose enhanced cache partitioning
– When a probe tuple on average matches 4 or more sub-partitions
• Case #2: nearly sorted input relations– Surprisingly: cache-stationary join is very good
I/O Partitioning
decide Cache
PartitioningCache Prefetching
Simple Hash JoinInspection
Join Phase
Cache StationaryExtracted Info

Inspector Joins IC-65 Advances in Data Management Systems 27
Conclusions• Exploit multi-pass structure for higher quality info about data• Achieve significantly better cache performance
– 1.6X speedups over previous cache-friendly algorithms
– When 8 or more CPUs are used
• Choose most suitable algorithms for special input cases• Idea may be applicable to other multi-pass algorithms

Inspector Joins IC-65 Advances in Data Management Systems 28
Thank You !
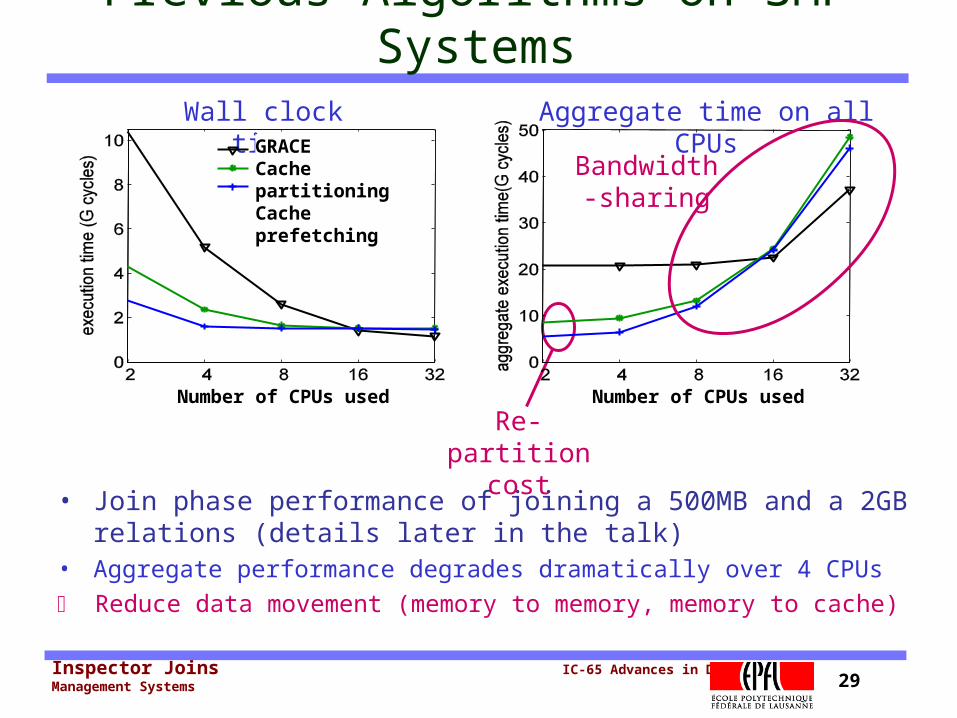
Inspector Joins IC-65 Advances in Data Management Systems 29
Previous Algorithms on SMP Systems
• Join phase performance of joining a 500MB and a 2GB relations (details later in the talk)
• Aggregate performance degrades dramatically over 4 CPUs
Reduce data movement (memory to memory, memory to cache)
Wall clock time Aggregate time on all CPUsGRACE
Cache partitioningCache prefetching
Number of CPUs used
Re-partition
cost
Number of CPUs used
Bandwidth-sharing

Inspector Joins IC-65 Advances in Data Management Systems 30
More Details in Paper• Moderate memory space requirement for filters• Summary information representation in intermediate partitions• Preprocessing for cache-stationary join phase• Prefetching for improving efficiency and robustness

Inspector Joins IC-65 Advances in Data Management Systems 31
Partition Phase Wall-Clock Time
• I/O partitioning can take advantage of multiple CPUs– Cut input relations into equal-sized chunks
– Partition one chunk on every CPU
– Concatenate outputs from all CPUs
• Inspection incurs very small overhead
•500MB joins 2GB•100B tuples, 4B keys•50% probe tuples no matches
•A build matches 2 probe tuples
Number of CPUs used
GRACECache prefetchingCache partitioningInspector join

Inspector Joins IC-65 Advances in Data Management Systems 32
Join Phase Aggregate Time
• Inspector join achieves significantly better performancewhen 8 or more CPUs are used– 1.7-2.1X speedups over cache prefetching
– 1.6-2.0X speedups over enhanced cache partitioning
•500MB joins 2GB•100B tuples, 4B keys•50% probe tuples no matches
•A build matches 2 probe tuples
Number of CPUs used
GRACECache prefetchingCache partitioningInspector join

Inspector Joins IC-65 Advances in Data Management Systems 33
CPU-Cache-Friendly Hash Joins• Recent studies focus on CPU cache performance
– I/O partitioning gives good I/O performance– Random memory accesses cause poor CPU cache performance
• Cache Partitioning [Shatdal et al. 94] [Boncz et al.’99] [Manegold et al.’00]– Recursively produce cache-sized partitions from memory-sized
partitions– Avoid cache misses during join phase– Pay re-partitioning cost
• Cache Prefetching [Chen et al. 04]– Exploit memory system parallelism– Use prefetches to overlap multiple cache misses and computations
Hash Table
ProbeBuild

Inspector Joins IC-65 Advances in Data Management Systems 34
Example Special Input Cases• Example case #1: a large number of duplicate build join keys
– Count the average number of sub-partitions a probe tuple matches
– Must check the tuple against all possible sub-partitions
– If too large, cache stationary join works poorly
• Example case #2: nearly sorted input relations– A merge-based join phase might be better?
Build Partition
Probe Partition
Sub-partition 0
Sub-partition 1
Sub-partition 2
A probe tuple

Inspector Joins IC-65 Advances in Data Management Systems 35
Varying Number of Duplicates per Build Join Key
• Join phase aggregate performance• Choose enhanced cache part
– When a probe tuple on average matches 4 or more sub-partitions

Inspector Joins IC-65 Advances in Data Management Systems 36
Nearly Sorted Cases
• Sort both input relations, then randomly move 0%-5% of tuples• Join phase aggregate performance• Surprisingly: cache-stationary join is very good
– Even better than merge join when over 1% tuples are out-of-order

Inspector Joins IC-65 Advances in Data Management Systems 37
Analyzing Nearly Sorted Case• Partitions are also nearly sorted• Probe tuples matching a sub-partition are almost contiguous• Similar memory behavior as merge join• No cost for sorting out-of-order tuples
Build Partition
Probe Partition
Sub-partition 0
Sub-partition 1
Sub-partition 2
A probe tuple
Nearly Sorted Nearly Sorted

















