57
Introduc)on to MPI Programming – Part 1 Wei Feinstein, Le Yan HPC@LSU 5/30/2016 LONI Parallel Programming Workshop 2016 1

Introduc)ontoMPIProgramming–Part1
WeiFeinstein,LeYan
HPC@LSU
5/30/2016 LONIParallelProgrammingWorkshop2016 1

Outline
• Introduc)on• MPIprogrambasics• Point-to-pointcommunica)on
5/30/2016 LONIParallelProgrammingWorkshop2016 2

WhyParallelCompu)ng
Ascompu)ngtasksgetlargerandlarger,mayneedtoenlistmorecomputerresources• Bigger:morememoryandstorage• Faster:eachprocessorisfaster• More:domanycomputa)onssimultaneously
5/30/2016 LONIParallelProgrammingWorkshop2016 3

Memorysystemmodelsforparallelcompu)ng
Differentwaysofsharingdataamongprocessors– SharedMemory– DistributedMemory– Othermemorymodels
• Hybridmodel• PGAS(Par))onedGlobalAddressSpace)
5/30/2016 LONIParallelProgrammingWorkshop2016 4
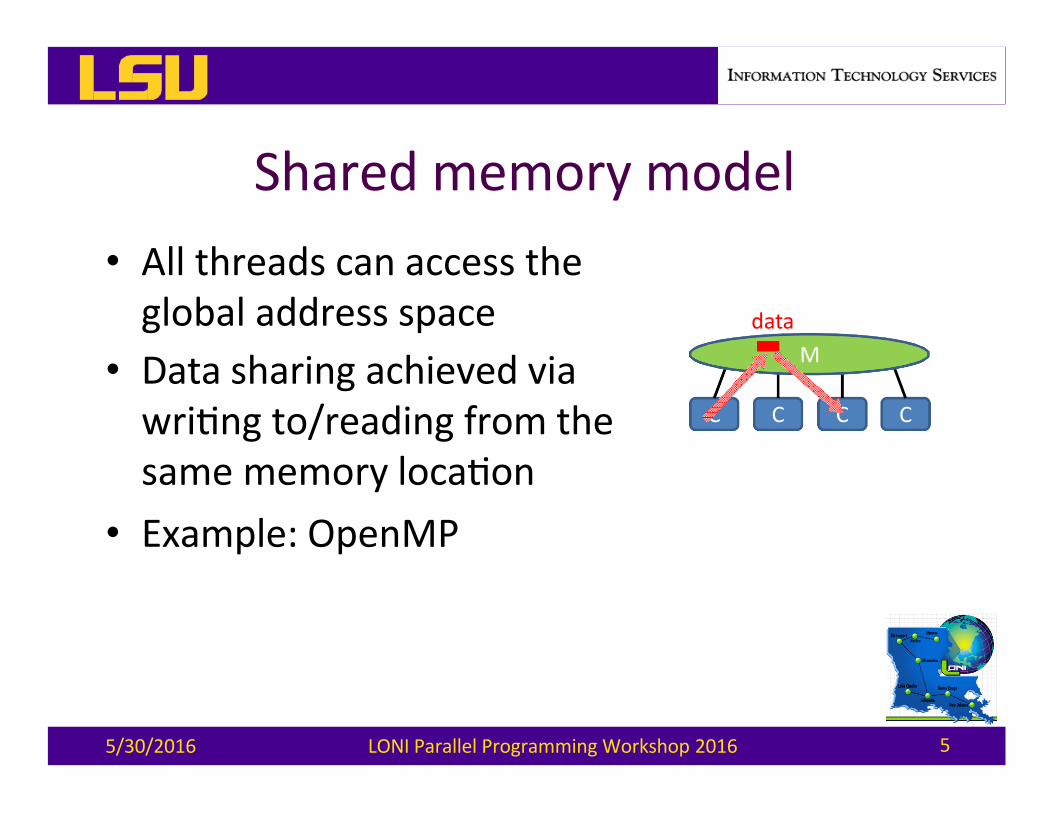
Sharedmemorymodel• Allthreadscanaccesstheglobaladdressspace
• Datasharingachievedviawri)ngto/readingfromthesamememoryloca)on
• Example:OpenMP
C C C C
Mdata
5/30/2016 LONIParallelProgrammingWorkshop2016 5

Distributedmemorymodel
• Datasharingachievedviaexplicitmessagepassing(throughnetwork)
• Example:MPI(MessagePassingInterface)
Nodeinterconnect
C
M M M M C C C
• EachprocesshasitsownaddressspaceDataislocaltoeachprocess
data
5/30/2016 LONIParallelProgrammingWorkshop2016 6

MPIProgrammingModels
• Distributed
• Distributed+shared
5/30/2016 LONIParallelProgrammingWorkshop2016 7

MessagePassingAnydatatobesharedmustbeexplicitlytransferredfromonetoanother
i
m
k
l
Communication medium: concrete
network,…
5/30/2016 LONIParallelProgrammingWorkshop2016 8
Entities: MPI processes
j

WhyMPI?• Therearealreadynetworkcommunica)onlibraries• Op)mizedforperformance• Takeadvantageoffasternetworktransport
• Sharedmemory(withinanode)• Fasterclusterinterconnects(e.g.InfiniBand)• TCP/IPifallelsefails
• Enforcescertainguarantees• Reliablemessages• In-ordermessagearrival
• Designedformul)-nodetechnicalcompu)ng
5/30/2016 LONIParallelProgrammingWorkshop2016 9

MPIHistory
• 1980-1990
• 1994:MPI-1• 1998:MPI-2
• 2012:MPI-3
5/30/2016 LONIParallelProgrammingWorkshop2016 10

MessagePassingInterface• MPIdefinesastandardAPIformessagepassing
– Thestandardincludes• Whatfunc)onsareavailable• Thesyntaxofthosefunc)ons• Whattheexpectedoutcomeiswhencallingthosefunc)ons
– ThestandarddoesNOTinclude• Implementa)ondetails(e.g.howthedatatransferoccurs)• Run)medetails(e.g.howmanyprocessesthecoderunwithetc.)
• MPIprovidesC/C++andFortranbindings
5/30/2016 LONIParallelProgrammingWorkshop2016 11

VariousMPIImplementa)ons• OpenMPI:opensource,portabilityandsimpleinstalla)onandconfig
• MPICH:opensource,portable• MVAPICH2:MPICHderiva)veInfiniBand,iWARPandotherRDMA-enabled interconnects(GPUs)
• IntelMPI(IMPI):vendor-supportedMPICHfromIntel
5/30/2016 LONIParallelProgrammingWorkshop2016 12

Highorlowlevelprogramming?
• Highlevelcomparedtoothernetworklibraries• Abstracttransportlayer• Supplyhigher-levelopera)ons
• Lowlevelforscien)sts• Handleproblemdecomposi)on• Manuallywritecodeforeverycommunica)onsamongprocesses
5/30/2016 LONIParallelProgrammingWorkshop2016 13

MoreaboutMPI
• MPIprovidesinterfacetolibraries• APIsandconstants• BindingtoFortran/C• Severalthird-partybindingsforPython,Randmoreotherlanguages
• RunMPIprograms(e.g.mpiexec)
5/30/2016 LONIParallelProgrammingWorkshop2016 14

Let’stryit• $whoami
• $mpiexec –np 4 whoami
5/30/2016 LONIParallelProgrammingWorkshop2016 15

Whatjusthappened?• mpiexeclaunched4processes• Eachprocessran`whoami`• Eachranindependently• UsuallylaunchnomoreMPIprocessesthan#processors
• Usemul)plenodes:mpiexec –hostfile machine.lst –np/-npp 4 app.exe
5/30/2016 LONIParallelProgrammingWorkshop2016 16

OutlineofaMPIProgram1. Ini)alizecommunica)ons
MPI_INITini)alizestheMPIenvironmentMPI_COMM_SIZEreturnsthenumberofprocessesMPI_COMM_RANKreturnsthisprocess’sindex(rank)
2. Communicatetosharedatabetweenprocesses
MPI_SENDsendsamessageMPI_RECVreceivesamessage
3. Exitina“clean”fashionwhenMPIcommunica)onisdoneMPI_FINALIZE
5/30/2016 LONIParallelProgrammingWorkshop2016 17

HelloWorld(C)HeaderfileIni)aliza)onComputa)onandcommunica)on
Termina)on
include “mpi.h”
int main(int argc, char* argv[]){int nprocs, myid;MPI_Status status;
MPI_Init(&argc, &argv);MPI_Comm_size(MPI_COMM_WORLD, &nprocs); MPI_Comm_rank(MPI_COMM_WORLD, &myid);printf("Hello World from process %d/%d \n", myid, nprocs);
MPI_Finalize();…}
5/30/2016 LONIParallelProgrammingWorkshop2016 18

include “mpi.h”
int main(int argc, char* argv[]){int nprocs, myid;MPI_Status status;
MPI_Init(&argc, &argv);MPI_Comm_size(MPI_COMM_WORLD, &nprocs); MPI_Comm_rank(MPI_COMM_WORLD, &myid);printf("Hello World from process %d/%d \n", myid, nprocs);
MPI_Finalize();…}
HelloWorld(C)
5/30/2016 LONIParallelProgrammingWorkshop2016
HeaderfileIni)aliza)onComputa)onandcommunica)on
Termina)on
19
[wfeinste@shelob1hello]$mpicchello.c[wfeinste@shelob1hello]$mpirun-np4./a.outHelloWorldfromprocess3/4HelloWorldfromprocess0/4HelloWorldfromprocess2/4HelloWorldfromprocess1/4

HelloWorld(Fortran)include"mpif.h"integer::nprocs,ierr,myidinteger::status(mpi_status_size)callmpi_init(ierr)callmpi_comm_size(mpi_comm_world,nprocs,ierr)callmpi_comm_rank(mpi_comm_world,myid,ierr)write(*,'("HelloWorldfromprocess",I3,"/",I3)')myid,nprocscallmpi_finalize(ierr)
….
HeaderfileIni)aliza)on
Computa)onandcommunica)on
Termina)on
5/30/2016 LONIParallelProgrammingWorkshop2016 20

include"mpif.h"integer::nprocs,ierr,myidinteger::status(mpi_status_size)callmpi_init(ierr)callmpi_comm_size(mpi_comm_world,nprocs,ierr)callmpi_comm_rank(mpi_comm_world,myid,ierr)write(*,'("HelloWorldfromprocess",I3,"/",I3)')myid,nprocscallmpi_finalize(ierr)
….
HeaderfileIni)aliza)on
Computa)onandcommunica)on
Termina)on
[wfeinste@shelob1hello]$mpif90hello.f90[wfeinste@shelob1hello]$mpirun-np4./a.outHelloWorldfromprocess3/4HelloWorldfromprocess0/4HelloWorldfromprocess1/4HelloWorldfromprocess2/4
HelloWorld(Fortran)
5/30/2016 LONIParallelProgrammingWorkshop2016 21

• Func)onnameconven)on– C:MPI_Xxxx(arg1,…) – Fortran:mpi_xxx (notcasesensi)ve)
• ErrorhandlesIfrc/ierr==MPI_SUCCESS,thenthecallissuccessful.
• C:int rc = MPI_Xxxx(arg1,…) • Fortran:call mpi_some_function(arg1,…,ierr)
NamingSignature(C/Fortran)
5/30/2016 LONIParallelProgrammingWorkshop2016 22

Communicators(1)
5/30/2016 LONIParallelProgrammingWorkshop2016 23
• Acommunicatorisaniden)fierassociatedwithagroupofprocesses
MPI_Comm_size(MPI_Com MPI_COMM_WORLD, int &nprocs) MPI_Comm_rank(MPI_Com MPI_COMM_WORLD, int &myid)

Communicators(2)• Acommunicatorisaniden)fierassociatedwithagroupofprocesses– Canberegardedasthenamegiventoanorderedlistofprocesses
– Eachprocesshasauniquerank,whichstartsfrom0(usuallyreferredtoas“root”)
– ItisthecontextofMPIcommunica)onsandopera)ons• Forinstance,whenafunc)oniscalledtosenddatatoallprocesses,MPIneedstounderstandwhat“all”means
5/30/2016 LONIParallelProgrammingWorkshop2016 24

Communicators(3)• MPI_COMM_WORLD:thedefaultcommunicatorcontainsallprocessesrunningaMPIprogram
• Therecanbemanycommunicatorse.g., MPI_Comm_split(MPI_Comm comm, int color, int, kye, MPI_Comm* newcomm)
• Aprocesscanbelongtomul)plecommunicators– Therankisusuallydifferent
5/30/2016 LONIParallelProgrammingWorkshop2016 25

CommunicatorInforma)on• Rank:uniqueidofeachprocess
– C:MPI_Comm_Rank(MPI_Comm comm, int *rank)
– Fortran:MPI_COMM_RANK(COMM,RANK,ERR) • Getthesize/processesofacommunicator
comm, int – C:MPI_Comm_Size(MPI_Comm *size)
– Fortran:MPI_COMM_SIZE(COMM,SIZE,ERR)
5/30/2016 LONIParallelProgrammingWorkshop2016 26

CompilingMPIPrograms• Notapartofthestandard
– Couldvaryfromplavormtoplavorm– Orevenfromimplementa)ontoimplementa)ononthesameplavorm
– mpicc/mpicxx/mpif77/mpif90:wrapperstocompileMPIcodeandautolinktostartupandmessagepassinglibraries.
5/30/2016 LONIParallelProgrammingWorkshop2016 27

MPICompilers
5/30/2016 LONIParallelProgrammingWorkshop2016 28
Language ScriptName UnderlyingCompiler
C mpicc gcc
mpiicc icc
mpipgcc pgcc
C++ mpiCC g++
mpiicpc icpc
mpipgCC pgCC
Fortran mpif90 f90
mpigfortran gfortran
mpiifort ifort
mpipgf90 pgf90

CompilingandRunningMPIPrograms• OnShelob:
– Compile• C:mpicc –o <executable name> <source file> • Fortran:mpif90 –o <executable name> <source file>
– Run• mpirun –hostfile $PBS_NODEFILE –np <number of procs> <executable name> <input parameters>
5/30/2016 LONIParallelProgrammingWorkshop2016 29

AboutExercises• Exercises
– Tracka:Processcolor– Trackb:Matrixmul)plica)on– Trackc:Laplacesolver
• Yourtasks:• FillinblankstomakeMPIprogramsworkunder
/exercisedirectory• Solu)onsareprovidedin/solu)ondirectory
5/30/2016 LONIParallelProgrammingWorkshop2016 30

Exercisea1:ProcessColor
• WriteaMPIprogramwhere– Processeswithoddrankprinttoscreen“Processxhasthecolorgreen”
– Processeswithevenrankprinttoscreen“Processxhasthecolorred”
5/30/2016 LONIParallelProgrammingWorkshop2016 31

Exerciseb1:MatrixMul)plica)onAB C
C1,1=Σ(A1,i×Bi,1)i=1
i=n
5/30/2016 LONIParallelProgrammingWorkshop2016 32

Exerciseb1:MatrixMul)plica)on
for(i=0;i<row;i++){ //rowoffirstmatrix for(j=0;j<col;j++){ //columnofsecondmatrix sum=0; for(k=0;k<n;k++) sum=sum+a[i][k]*b[k][j]; c[i][j]=sum; //finalmatrix }}
5/30/2016 LONIParallelProgrammingWorkshop2016 33

Exerciseb1:MatrixMul)plica)on• Goal:Distributetheworkloadamongprocessesin1-dmanner
• Eachprocessini)alizesitsowncopyofAandB• Thenprocessespartoftheworkload
• Needtodeterminehowtodecompose(whichprocessdealswhichrowsorcolumns)
• AssumethatthedimensionofAandBisamul)pleofthenumberofprocesses
(needtocheckthisintheprogram)• Validatetheresultattheend
5/30/2016 LONIParallelProgrammingWorkshop2016 34

Exercisec1:LaplaceSolverversion1
Px,y=(Dx-1,y+Dx,y-1+Dx+1,y+Dx,y+1)/4
5/30/2016 LONIParallelProgrammingWorkshop2016 35

Exercisec1:LaplaceSolverversion1
• Goal:Distributetheworkloadamongprocessesin1-dmannere.g.4MPIprocesses(colorcoded)tosharetheworkload
5/30/2016 LONIParallelProgrammingWorkshop2016 36

Exercisec1:LaplaceSolverversion1
5/30/2016 LONIParallelProgrammingWorkshop2016 37

Exercisec1:LaplaceSolverversion1
• Goal:Distributetheworkloadamongprocessesin1-dmanner– Findoutthesizeofsub-matrixforeachprocess– Leteachprocessreportwhichpartofthedomainitwillworkon,e.g.“Processxwillprocesscolumn(row)xthroughcolumn(row)y.”
• Row-wise(C)orcolumn-wise(Fortran)
5/30/2016 LONIParallelProgrammingWorkshop2016 38

MPIFunc)ons• Environmentmanagementfunc)ons
– Ini)aliza)onandtermina)on• Point-to-pointcommunica)onfunc)ons
– Messagetransferfromoneprocesstoanother• Collec)vecommunica)onfunc)ons
– Messagetransferinvolvingallprocessesinacommunicator
5/30/2016 LONIParallelProgrammingWorkshop2016 39

Point-to-pointCommunica)on
5/30/2016 LONIParallelProgrammingWorkshop2016 40

Point-to-pointCommunica)on• Blockingsend/receive
– ThesendingprocesscallstheMPI_SENDfunc)on• C:int MPI_Send(void *buf, int count, MPI_Datatype dtype, int dest, int tag, MPI_Comm comm);
• Fortran:MPI_SEND(BUF, COUNT, DTYPE, DEST, TAG, COMM, IERR)
– ThereceivingprocesscallstheMPI_RECVfunc)on• C:int MPI_Recv(void *buf, int count, MPI_Datatype dtype, int source, int tag, MPI_Comm comm, MPI_Status *status);
• Fortran:MPI_RECV(BUF, COUNT, DTYPE, SOURCE, TAG, COMM, STATUS, IERR)
5/30/2016 LONIParallelProgrammingWorkshop2016 41

int MPI_Send(void *buf, int count, MPI_Datatype dtype, int dest, int tag, MPI_Comm comm); int MPI_Recv(void *buf, int count, MPI_Datatype dtype, int source, int tag, MPI_Comm comm, MPI_Status *status)
• AMPImessageconsistsoftwoparts– Messageitself:databody– Messageenvelope:rou)nginfo
• status: informa)onofthemessagethatisreceived
Send/Receive
5/30/2016 LONIParallelProgrammingWorkshop2016 42

Example:GatheringArrayData• Gathersomearraydatafromeachprocessandplaceitinthememoryoftherootprocess
P0 0 1 P1 2 3 P2 4 5 P3 6 7
P0 0 1 2 3 4 5 6 7
43
5/30/2016 LONIParallelProgrammingWorkshop2016 43

Example:GatheringArrayData… integer,allocatable :: array(:) ! Initialize MPI call call call
mpi_init(ierr) mpi_comm_size(mpi_comm_world,nprocs,ierr) mpi_comm_rank(mpi_comm_world,myid,ierr)
! Initialize the array allocate(array(2*nprocs)) array(1)=2*myid array(2)=2*myid+1 ! Send data to the root process if (myid.eq.0) then do i=1,nprocs-1
call mpi_recv(array(2*i+1),2,mpi_integer,i, 0,mpi_comm_world,status,ierr) enddo write(*,*) “The content of the array:” write(*,*) array
else call mpi_send(array,2,mpi_integer,0,0, mpi_comm_world,ierr) endif
5/30/2016 LONIParallelProgrammingWorkshop2016 44

BlockingOpera)ons
• MPI_SENDandMPI_RECVareblockingopera)ons
– Theywillnotreturnfromthefunc)oncallun)lthecommunica)oniscompleted
– Whenablockingsendreturns,thevalue(s)storedinthevariablecanbesafelyoverwriWen
– Whenablockingreceivereturns,thedatahasbeenreceivedandisreadytobeused
5/30/2016 LONIParallelProgrammingWorkshop2016 45

Deadlock(1)Deadlockoccurswhenbothprocessesawaitstheothertomakeprogress
// Exchange data between two processes If (process 0)
Receive data from process 1 Send data to process 1
If (process 1) Receive data from process 0 Send data to process 0
• Guaranteeddeadlock!• Bothreceiveswaitfordata,butnosendcanbe
calledun)lthereceivereturns
5/30/2016 LONIParallelProgrammingWorkshop2016 46

Deadlock(2)• Howaboutthisone?
// Exchange data between two processes If (process 0)
Receive data from process 1 Send data to process 1
If (process 1) Send data to process 0 Receive data from process 0
• Nodeadlock!• P0receivesthedatafirst,thensendsthedatatoP1• Therewillbeperformancepenaltydueto
serializa)onofpoten)allyconcurrentopera)ons.
5/30/2016 LONIParallelProgrammingWorkshop2016 47

Deadlock(3)• Andthisone?
// Exchange data between two processes If (process 0)
Send data to process 1 Receive data from process 1
If (process 1) Send data to process 0 Receive data from process 0
• Itdepends• Ifonesendreturns,thenweareOKAY-mostMPI
implementa)onsbufferthemessage,soasendcouldreturnevenbeforethematchingreceiveisposted.
• Ifthemessageistoolargetobebuffered,deadlockwilloccur.
5/30/2016 LONIParallelProgrammingWorkshop2016 48

Blockingvs.Non-blocking• Blockingopera)onsaredatacorrup)onproof,but
– Possibledeadlock– Performancepenalty
• Non-blockingopera)onsallowoverlapofcomple)onandcomputa)on– Theprocesscanworkonothertasksbetweentheini)aliza)onandcomple)on
– Shouldbeusedwheneverpossible
5/30/2016 LONIParallelProgrammingWorkshop2016 49

Non-blockingOpera)ons(asynchronous)
• Separateini)aliza)onofasendorreceivefromitscomple)on
• Twocallsarerequiredtocompleteasendorreceive– Ini)aliza)on
• Send:MPI_ISEND • Receive:MPI_IRECV
– Comple)on:MPI_WAIT
5/30/2016 LONIParallelProgrammingWorkshop2016 50

Non-blockingPoint-to-pointCommunica)on• MPI_ISENDfunc)on
• C:int MPI_Isend(void *buf, int count, MPI_Datatype dtype, int dest, int tag, MPI_Comm comm, MPI_Request *request)
• Fortran:MPI_ISEND(BUF, COUNT, DTYPE, DEST, TAG, COMM, REQ, IERR)
• MPI_IRECVfunc)on• C:int MPI_Irecv(void *buf, int count, MPI_Datatype
dtype, int source, int tag, MPI_Comm comm, MPI_Request *request)
• Fortran: MPI_IRECV(BUF, COUNT, DTYPE, SOURCE, TAG, COMM, REQ, IERR)
• MPI_WAIT• C:int MPI_Wait( MPI_Request *request, MPI_Status *status);
• Fortran:MPI_WAIT(REQUEST, STATUS, IERR)
5/30/2016 LONIParallelProgrammingWorkshop2016 51

Example:ExchangeDatawithNon-blockingcalls
integer reqids,reqidr integer status(mpi_status_size) if (myid.eq.0) then
mpi_isend(to_p1,n,mpi_integer,1,100,mpi_comm_world,reqids,ierr) mpi_irecv(from_p1,n,mpi_integer,1,101,mpi_comm_world,reqidr,ierr) (myid.eq.1) then mpi_isend(to_p0,n,mpi_integer,0,101,mpi_comm_world,reqids,ierr) mpi_irecv(from_p0,n,mpi_integer,0,100,mpi_comm_world,reqidr,ierr)
call call
elseif call call
endif
call mpi_wait(status,reqids,ierr) call mpi_wait(status,reqidr,ierr)
5/30/2016 LONIParallelProgrammingWorkshop2016 52

Exercisea2:FindGlobalMaximum• Goal:Findthemaximuminanarray
• Eachprocesshandlepartofthearray• Everyprocessneedstoknowthemaximumatthe
endofprogram• Hints
• Step1:eachprocesssendthelocalmaximumtotherootprocesstofindtheglobalmaximum
• Step2:therootprocesssendtheglobalmaximumtoallotherprocesses
5/30/2016 LONIParallelProgrammingWorkshop2016 53

Exerciseb2:MatrixMul)plica)on
• Modifyb1sothateachprocesssendsitspar)alresultstotherootprocess– Therootprocessshouldhavethewholematrix
• Validatetheresultattherootprocess
5/30/2016 LONIParallelProgrammingWorkshop2016 54

Exercisec2:LaplaceSolver
• Goal:developaworkingMPILaplacesolverusingc1– Distributetheworkloadin1Dmanner– Ini)alizethesub-matrixateachprocessandsettheboundaryvalues
– Attheendofeachitera)on• Exchangeboundarydatawithneighbors• Findtheglobalconvergenceerroranddistributetoallprocesses
5/30/2016 LONIParallelProgrammingWorkshop2016 55

WhyMPI?• Standardized
– Witheffortstokeepitevolving(MPI3.0)• Portability
– MPIimplementa)onsareavailableonalmostallplavorms• Scalability
– Inthesensethatitisnotlimitedbythenumberofprocessorsthatcanaccessthesamememoryspace
• Popularity– DeFactoprogrammingmodelfordistributedmemorymachines
• Nearlyeverybigacademicorcommercialsimula)onordataanalysisrunningonmul)plenodesusesMPIdirectlyorindirectly
5/30/2016 LONIParallelProgrammingWorkshop2016 56

Con)nue…• MPIPart2:Collec)vecommunica)ons• MPIPart3:UnderstandingMPIapplica)ons
5/30/2016 LONIParallelProgrammingWorkshop2016 57

















