1 CHAPTER I INTRODUCTION Knowledge discovery in database is becoming more interesting tool and necessary for the people to analyze the long range activities. Knowledge discovery is the nontrivial extraction of implicit, previously unknown, and potentially useful information from data. Mostly the people who use this concept are business analysts, medical scientists, researchers, defense analysts, socialists, medical researchers, economist and so on to make computer based tactical decisions. The discovery of knowledge can be considered as a process which consists of several sub processes termed as stages and these sequence stages are selection, preprocessing, transformation, data mining, and interpretation/Evaluation. Among these process/ stages, data mining is the most significant process and it finds hidden patterns from large voluminous of data. In knowledge discovery system data mining plays a major role in determining useful and uncovers knowledge from enormous amount of database and it can also be the young and interdisciplinary field of computer science such as database systems, artificial intelligence, statistics and machine learning. An overview of steps in knowledge discovery in database [1] is given in Figure 1.1. Now a days, people find data mining is a necessary tool to find knowledge in decision making process to predict the future trends and also helps the companies to take right decisions. Because of this reason the data mining field is getting more attention from many researchers to find useful patterns efficiently and accurately. Figure 1.1: An Overview of the Steps in KDD Process.
Transcript
1
CHAPTER I
INTRODUCTION
Knowledge discovery in database is becoming more interesting tool and
necessary for the people to analyze the long range activities. Knowledge
discovery is the nontrivial extraction of implicit, previously unknown, and
potentially useful information from data. Mostly the people who use this
concept are business analysts, medical scientists, researchers, defense analysts,
socialists, medical researchers, economist and so on to make computer based
tactical decisions. The discovery of knowledge can be considered as a process
which consists of several sub processes termed as stages and these sequence
stages are selection, preprocessing, transformation, data mining, and
interpretation/Evaluation. Among these process/ stages, data mining is the most
significant process and it finds hidden patterns from large voluminous of data.
In knowledge discovery system data mining plays a major role in determining
useful and uncovers knowledge from enormous amount of database and it can
also be the young and interdisciplinary field of computer science such as
database systems, artificial intelligence, statistics and machine learning. An
overview of steps in knowledge discovery in database [1] is given in Figure 1.1.
Now a days, people find data mining is a necessary tool to find knowledge in
decision making process to predict the future trends and also helps the
companies to take right decisions. Because of this reason the data mining field
is getting more attention from many researchers to find useful patterns
efficiently and accurately.
Figure 1.1: An Overview of the Steps in KDD Process.
2
Before taking the database into analysis, data in database has to be
cleaned by removing noise and inconsistency. The second thing to be taken into
consideration is availability of source of data may be at one source or in many
sources since several branches may exist for providing the same services. If data
are at multiple sources data has to be integrated. Once the database is cleaned,
relevant data is extracted by removing relevant data and then data mining
technique is applied to extract useful patterns based on interesting measures.
There are many applications of data mining exist in the real world such as text
mining, web mining, spatial mining, multimedia mining, object mining,
sequence mining and so on. Data mining allows the companies to exploit
information and use this to obtain competitive advantage, also helps the
business people to identify trends such as why the customers buy particular
products, to build strategies for direct marketing, ideas for shelf placement,
training of employees vs employee retention and employee benefits vs
employee retention.
Data Mining has been able to grasp the attention of many in the field of
scientific research, business, banking sector, intelligence agencies and many
others from the early days of its inception. Largely it is used in several
applications such as understanding consumer research marketing, cross selling,
product analysis, demand and supply analysis, e-commerce, investment trend in
stocks & real estates, telecommunications, medical, health care areas,
e-commerce, Customer Relationship Management (CRM), Fast Moving
Consumer Goods (FMCG) industry.
Data Mining is also used by intelligence agencies like Federal Bureau of
Investigation (FBI) and Central Intelligence Agency (CIA) to identify threats of
terrorism. In banking, it is used to detect the credit card frauds by identifying
patterns involved in fraudulent transactions. The following section presents
various data mining techniques.
3
1.1 Data Mining Techniques
Data mining techniques are the result of a long process of research and
product development. This evolution started when business data was first stored
on computers, continued with improvements in data access, and more recently,
generated technologies that allow users to navigate through their data in real
time. Data mining takes this evolutionary process beyond retrospective data
access and navigation to prospective and proactive information delivery. Data
mining is ready for application in the business community because it is
supported by three technologies that are now sufficiently mature:
Massive data collection
Powerful multiprocessor computers
Data mining algorithms
Data Mining is currently considered an enabler for business intelligence
systems. Data mining algorithms are available as software packages. Building a
data mining application usually starts with a heavy emphasis on data
warehousing followed by exploratory data mining. The analysis and application
building is typically conducted by consultants or in-house analytic teams. The
key challenges to the successful completion of a data mining project are the data
warehousing requirements, and the sophisticated analytical requirements. When
data mining tools are implemented on high performance parallel processing
systems, they can analyze massive databases in minutes.
Given databases of sufficient size and quality, data mining technology
can generate new business opportunities by providing these capabilities:
Automated prediction of trends and behaviors.
Data mining automates the process of finding predictive information in large
databases. Questions that traditionally required extensive hands on analysis
can now be answered directly from the data.
4
Automated discovery of previously unknown patterns
Data mining tools search through databases and identify previously hidden
patterns in one step. When data mining tools are implemented on high
performance parallel processing systems, they can analyze massive
databases in minutes.
Data mining functionalities are used to specify the kind of patterns to be
found in data mining tasks. Descriptive and predictive are the two basic models
of data mining. Data mining tasks can be classified into two models, which are
descriptive and predictive. Descriptive model discovers patterns or relationships
in data and it serves as a way to explore the properties of the examined data.
Predictive model determines patterns on the existing and/or historical data to
make predictions. Association Rules, clustering, sequence discovery are
descriptive models where as classification, regression analysis, time series
analysis, prediction and so on are predictive models of data mining. Among
these, association rule mining technique is the most essential technique which
helps the people to make right decisions in stabilizing and improving the output.
This technique predicts the knowledge and represents the knowledge as a set of
association rules from large database based on statistical measures given by the
user.
Some of the popularly used data mining techniques are association rule
mining, classification, clustering and sequencing and are as follows:
1.1.1 Association Rule Mining
Given a collection of items and a set of records, each of which contain
some number of items from the given collection, an association discovery
function is an operation against this set of records which return affinities that
exist among the collection of items. These affinities can be expressed by rules
such as “72% of all the records that contain items A, B and C also contain items
D and E”. The specific percentage of occurrences (in the case 72) is called the
confidence factor of the association. Also, in the association, A, B and C are
said to be on an opposite side of the association to D and E. Association
discovery can involve any number of items on either side of the association.
5
A typical application that can be built using association discovery is
supermarket problem. The problem is to analyze customers’ buying habits by
finding associations between the different items that customers place in their
shopping baskets. The discovery of such association rules can help the retailer
to develop marketing strategies, by gaining insight into matters like “which
items are most frequently purchased by customers”. It also helps in inventory
management, sale promotion strategies, etc.
1.1.2 Classification
Classification finds rules that partition the data into disjoint groups. The
input for the classification is the training dataset, whose class labels are already
known. Classification analyzes the training dataset and constructs a model
based on the class label, and aims to assign a class label to the future unlabelled
records. Since the class field is known, this type of classification is known as
supervised learning. A set of classification rules are generated by such a
classification process, which can be used to classify future data and develop a
better understanding of each class in the database.
There are several classification discovery models such as decision trees,
neural networks, genetic algorithms and the statistical models like
linear/geometric discriminates. The applications include the credit card analysis,
banking, medical applications and the like.
Previously, the domestic flights in India were operated only by Indian
Airlines. Recently, many other private airlines have also started their operations
for domestic travel. Some of the customers of Indian Airlines preferred these
private airlines and, as a result, Indian Airlines lost their customers. If the
Indian Airlines wishes to analyze why they have lost some customers, their goal
is to predict what type of customers it is foregoing to its competitors ultimately.
In other words, their aim to build a model based on the historical data of loyal
customers versus customers who have left. This becomes a classification
problem. It is a supervised learning task as the historical data becomes the
training set which is used to train the model. The decision tree is the most
popular classification technique.
6
1.1.3 Clustering
Clustering is the process of grouping the data into clusters, so that
objects with in a cluster have high similarity in comparison to one another but
are very dissimilar to objects in other clusters [2]. Dissimilarities are assessed
based on the attribute values describing the objects. Often, distance measures
are used. Clustering has its roots in many areas, including data mining,
statistics, biology, and machine learning.
Cluster analysis is an important human activity. Early in childhood,
human beings learn how to distinguish between cats and dogs, or between
animals and plants, by continuously improving subconscious clustering
schemes. Cluster analysis has been widely used in numerous applications,
including market research, pattern recognition, data analysis, and image
processing. In business, clustering can help marketers discover distinct groups
in their customer bases and characterize customer groups based on purchasing
patterns. In biology, it can be used to derive plant and animal taxonomies,
categorize genes with similar functionality, and gain insight into structures
inherent in populations. Clustering may also help in the identification of areas
of similar land use in the earth observation database and in the identification of
groups of houses in a city according to house type, value, and geographic
location, as well as the identification of groups of automobile insurance policy
holders with a high average claim cost. It can also be used to classify
documents on the Web for information discovery.
Clustering is also called data segmentation in some applications because
clustering partitions large datasets into groups according to their similarity.
Clustering can also be used for outlier detection, where outliers (values that are
“far away” from any cluster) may be more interesting than common cases.
Applications of outlier detection include the detection of credit card fraud and
the monitoring of criminal activities in electronic commerce.
7
1.1.4 Sequence Discovery
A sequence database consists of sequences of ordered elements or
events, recorded with or without a concrete notion of time. There are many
applications involving sequence data. Typical examples include customer
shopping sequences, web click streams, biological sequences etc. Sequential
pattern mining is the mining of frequently occurring ordered events or
subsequences as patterns. An example of a sequential pattern is “Customers
who buy a Canon digital camera are also likely to buy an HP color printer
within a month”. For retail data, sequential patterns are useful for shelf
placement and promotions. This industry, as well as telecommunications and
other businesses, may also use sequential patterns for targeted marketing,
customer retention, and many other tasks. Other areas in which sequential
patterns can be applied include weather prediction, production processes, and
network intrusion detection.
The sequential pattern mining problem was first introduced by Agrawal
and Srikant in 1995 [3] based on their study of customer purchase sequences,
according to them, “Given a set of sequences, where each sequence consists of a
list of events (or elements) and each event consists of a set of items, and given a
user-specified minimum support threshold of minsup, sequential pattern mining
finds all frequent subsequences, that is, the subsequences whose occurrence
frequency in the set of sequences is not less than minsup.”
Though the data mining is well known technique which automatically
and intelligently extracts information from large amount of data, it can also
disclose sensitive information about individuals by compromising the
individual’s right to privacy. Moreover data mining techniques can reveal
critical information about business transactions, compromising the free
competitions in business settings.
Keeping in view of the motivation to incorporate the privacy in data
mining techniques to protect the confidential data of the user, there evolved a
new stream in data mining era that is privacy preserving in data mining. There
8
exists a key difference between regular data mining algorithms under various
data mining techniques like classification, association, clustering and privacy
preserving data mining algorithms that is the formal algorithms deals with how
to analyze the stored raw data and how to extract useful knowledge discovery
patterns from the database whereas in the later one, it mainly deals with the
sensitive information of the user records where privacy factor is the major
concern and it is considered to be the vital issue. The following section
discusses about privacy preserving data mining.
1.2 Privacy Preserving Data Mining (PPDM)
Data mining has been viewed as a threat to privacy because of the
widespread proliferation of electronic data maintained by corporations. This has
lead to increased concerns about the privacy of the underlying data. In recent
years, many organizations often share their information with legitimate parties
to discover more useful information for decision making purposes and to
enhance their competitive spirit. The issue of privacy plays a vital role when
several legitimate people share their resources in order to obtain mutual benefits
but no one is interested to disclose their private data. In the process of data
mining, how to resolve the problem of privacy preserving has become a hot
research topic in data mining field. Hence privacy preserving data mining
research area is evolved.
At present, privacy preserving data mining methods can be roughly
divided from four aspects.
Based on the basic strategy of original data hiding, they can be divided
into data perturbation, query restriction and mixed strategies.
Based on the data mining techniques, they can be divided into
association rules mining classification and clustering etc.
Based on the privacy preserving techniques, they can be divided into
heuristic technique, encryption and reconfigurable technique.
9
Based on the distribution of data resources, they can be divided into
privacy- preserving centralized database mining and privacy-preserving
distributed database mining.
Verykios et al. [4] analyzed the state-of-the-art in the area of PPDM,
classifies the proposed privacy preservation data mining algorithms in
different aspects and is shown in Figure 1.2. The PPDM algorithms are broadly
classified into three categories namely heuristic based, reconstruction based and
cryptography based.
10
Figure 1.2 Taxonomy of Privacy Preserving Data Mining Algorithms
11
Heuristic-Based Techniques
Heuristic-based techniques are to resolve how to select the appropriate
data sets for data modification. Since the optimal selective data modification or
sanitization is an NP-Hard problem, heuristics can be used to address the
complexity issues. The methods of heuristic-based modification include
perturbation, which is accomplished by the alteration of an attribute value by a
new value (i.e., changing a 1-value to a 0- value, or adding noise), and blocking,
which is the replacement of an existing attribute value with a “?”.
Reconstruction-Based Technique
A number of recently proposed techniques address the issue of privacy
preservation by perturbing the data and reconstructing the distributions at an
aggregate level in order to perform the association rules mining. That is, these
algorithms are implemented by perturbing the data first and then reconstructing
the distributions. According to the different methods of reconstructing the
distributions and data types (numerical data, binary data and categorical data),
the corresponding algorithm is not the same.
Cryptographic Techniques
Another branch of privacy preserving data mining by using
cryptographic techniques was developed. This branch became hugely popular
for two main reasons: Firstly, cryptography offers a well-defined model for
privacy, which includes methodologies for proving and quantifying it.
Secondly, there exists a vast tool set of cryptographic algorithms and constructs
to implement privacy-preserving data mining algorithms.
1.2.1 Privacy Preserving in Centralized and Distributed Database
Environment
In large applications the whole data may be in a single location called
centralized or multiple sites called distributed database. Methodologies are
proposed by many authors for both centralized as well as distributed database to
12
protect private data. In centralized database environment, various approaches
are proposed for privacy preserving data mining which can be categorized into
data hiding and knowledge hiding approaches. In data hiding, the main concept
is how the privacy of data/information can be maintained before hiding process
begins. In this approach, removal of private/sensitive information prior to its
disclosure by adopting the techniques such as perturbation, sampling,
generalization etc. to produce a sanitized database of the original database. In
case of knowledge hiding approaches, instead of protecting the raw data,
sensitive information from data mining results are protected by using distortion
and blocking techniques. In distributed environment, database is a collection of
multiple, logically interrelated databases distributed over a computer network
and are distributed among number of sites. As the database is distributed,
different users can access it without interfering with one another. In distributed
environment, database is partitioned into disjoint fragments and each site
consists of only one fragment. Data can be partitioned in different ways such as
horizontal, vertical and mixed mode. In distributed database environment, the
discovered knowledge can be shared to many legitimate people by preserving
the privacy of individual sites.
In general, privacy preservation occurs in two major dimensions: users'
personal information and information concerning their collective activity. The
former one is referred to as data hiding and the latter as knowledge hiding.
The two real-life examples where PPDM poses different constraints are
discussed below.
Scenario 1: A hospital shares some data for research purposes (e.g., concerning
a group of patients who have a similar disease). The hospital's security
administrator may suppress some identifiers (e.g., name, address, phone
number, etc) from patient records to meet privacy requirements. However, the
released data may not be fully protected. A patient record may contain other
information that can be linked with other datasets to re-identify individuals or
entities. How can we identify groups of patients with a similar disease without
revealing the values of the attributes associated with them?
13
Scenario 2: Two or more companies have a very large dataset of records on
their customers' buying activities. These companies decide to cooperatively
conduct association rule mining on their datasets for their mutual benefit since
this collaboration brings them an advantage over other competitors. However,
some of these companies may not want to share some strategic patterns hidden
within their own data (also called restrictive association rules) with the other
parties. They would like to transform their data in such a way that these
restrictive association rules cannot be discovered but others can be. Is it possible
for these companies to benefit from such collaboration by sharing their data
while preserving some restrictive association rules?
The above scenarios describe different privacy preservation problems.
Each scenario poses a set of challenges. For instance, Scenario 1 is a typical
example of individual's privacy preservation, while Scenario 2 refers to
collective privacy preservation.
1.2.2 Different Views of Privacy Preservation Data mining
PPDM could be attempted at three levels as shown in Figure-1.3. The
first level is raw data or databases where transactions reside. The second level is
data mining algorithms and techniques that ensure privacy. The third level is the
output of different data mining algorithms and techniques [5].
Figure 1.3: Three Major Levels of PPDM
14
At Level 1, researchers have applied different techniques to raw data or
databases for the sake of protecting the privacy of individuals (by preventing
data miners from getting sensitive data or sensitive knowledge), or protecting
privacy of two or more parties who want to perform some analysis on the
combination of their data without disclosing their data to each other.
At Level 2, privacy-preserving techniques are embedded in the data
mining algorithms or techniques and may allow skillful users to enter specific
constraints before or during the mining process.
Finally, at Level 3, researches have applied different techniques to the
output of data mining algorithms or techniques for the same purpose of Level 1.
Most of the research in the PPDM problems has been performed at Level 1.
A Few researchers applied privacy-preserving techniques at Level 2 or Level 3.
1.2.3 PPDM Applications
A number of diverse application domains where privacy-preserving data
mining methods are useful. Government, Corporations, and individuals have
created tremendous opportunities for knowledge and information based decision
making. Driven by mutual benefits, or by regulations, requires data to be shared,
and demands exchange of data/knowledge among various parties. But original
dataset may contain sensitive information. This sensitive data/knowledge may
contain information about individuals, or some confidential data or significant
information to competitor. Revealing this may lead to loss in business or
reduces the confidentiality to individuals.
The problem of privacy preserving data mining has numerous
applications in customer purchase behavior patterns, customer transactional
analysis, security system, medical research fields, and many research fields.
Some of the applications discussed in [5] are as follows:
Application in Medical Field
A classical example of a privacy-preserving data mining problem of the
first type occurs in the field of medical research. Consider the case of a number
of different hospitals that wish to jointly mine their patient data for the purpose
of medical research. Furthermore, privacy policy and law prevents these
hospitals from ever pooling their data or revealing it to each other, due to the
15
confidentiality of patient records. In such cases, classical data mining solutions
cannot be used. Rather, it is necessary to find a solution that enables the
hospitals to compute the desired data mining algorithm on the union of their
databases, without ever pooling or revealing their data. Privacy-preserving data
mining solutions have the property that the only information learned by the
different hospitals is the output of the data mining algorithm.
The developed scrub system was designed for de-identification of
clinical notes and letters which typically occurs in the form of textual data,
which contains references to patients, family members, addresses, phone
numbers or providers. It has been shown that such a system is able to remove
more than 99% of the identifying information from the data while discovering
knowledge using data mining techniques.
Application in Bioterrorism
Bioterrorism applications provide more identifiable information in
accordance with public health law using privacy-preserving data mining
techniques with medical data. Often a biological agent such as anthrax produces
symptoms which are similar to other common respiratory diseases such as the
cough, cold and the flu. In the absence of prior knowledge of such an attack,
health care providers may diagnose a patient affected by an anthrax attack of
symptoms from one of the more common respiratory diseases. The key is to
quickly identify a true anthrax attack from a normal outbreak of a common
respiratory disease, in many cases, an unusual number of such cases in a given
locality may indicate a bio-terrorism attack. Therefore, in order to identify such
attacks it is necessary to track incidences of these common diseases as well.
Therefore, the corresponding data would need to be reported to public health
agencies. However, the common respiratory diseases are not reportable diseases
by law.
In Web Camera Surveillance system, publicly available web cams are
used to detect unusual activities but the problem is that it captures person
specific information which is much invasive approach. This approach
incorporates privacy preserving data mining techniques to extract only facial
counts information from the images captured in webcams. Using facial counts,
it may detect unusual activities. This way, it protects sensitive information.
16
For many recent years, research is going on in the science of DNA
sequencing and forensic analysis with the use of DNA dataset. Great research
work is going on in this field, DNA databases are growing very fast in both
medical and law enforcement communities, but DNA data is considered
sensitive since it consists of unique data/information which may be used to
detect individuals easily. Here, privacy is required to protect uniquely
identifying information about an individual from the DNA database which are
publicly available. The hospitals usually separate out the clinical data from the
genomic and make the genomic data available for research purposes.
1.3 Privacy Preserving Association Rule Mining
In 1993, Agarwal first introduced, association rules for discovering
interesting relationships between products in large scale transaction data
recorded by point-of-sale systems in supermarkets. Each rule has two parts
called antecedent and consequent. The antecedent and consequent are two sets,
consists of items which exist in the transactions. Antecedent is also called rule
head (left hand side of the rule), similarly Consequent is also called rule body
(right hand side of the rule). For example the following association rule is found
in a supermarket shopping transaction with support 50 and confidence 80.
[Tomato, Carrot] → [Orange Juice] .
[Tomato, Carrot] is called antecedent or rule head and [Orange Juice] is called
consequent or rule body. This rule specifies that whenever customer purchases
tomato and carrot, then the same person also purchases orange juice since
interesting relationship between items exist. These interesting purchase
strategies are determined with the help of measures called support and
confidence that is the rule support is greater than or equal to user specified
support and confidence is also greater than or equal to user specified
confidence.
Here support value indicates that the set of items tomato, carrot and
orange juice were purchased by more than or equal to 50% of the customers.
Similarly, the confidence value indicates that in the transactions where the items
17
tomato and carrot are found together, the item orange juice is also present in 80%
of the transactions (that is purchased by the customers).This rule gives
information and can be used as the basis for decisions about marketing activities
such as, e.g., promotional pricing or product placements.
There are many algorithms that exist for finding association rules
employing the given support and confidence. The number of association rules
generated by the algorithm can vary and sometimes it may create too many or
very few rules. So according to the given support and confidence values, rules
are generated. This association rule mining is mainly used for medical research
fields where findings of association between attributes play a vital role in
deciding decisions for diagnosing the patients.
1.3.1 Definition of Association Rule
Let I= {i1,i2,… ,im} be a set of items or attributes and D be a database of
transactions, where each transaction T consists of a set of items so that T I. An
association rule is an implication of the form X→Y, where X I, Y I and
X∩Y=Ø. An association rule X→ Y has support s in D if the probability of a
transaction in D contains both X and Y is s. The association rule X →Y holds in
D with confidence c if the probability of a transaction in D which contains X as
well as Y is c. Association rule mining is originated from Market basket
analysis to discover customer’s buying patterns and preferences to optimize the
sales and profit. Association rule mining are used in many other application
domain, mainly used in Medical field, Financial service Industries,
E-commerce, Sports analysis, Web usage mining, Bio-Informatics and so on.
The algorithm proceeds in two stages. In the first stage, it generates
frequent (large) item sets in the given dataset. In the second stage, it generates
strong association rules from frequent item sets identified in first stage.
To generate association rules, frequent item sets along with support
values are to be determined. Many algorithms are exists for generating frequent
item sets in order to generate association rules. Apriori is the best-known classic
algorithm to mine association rules and it is adopted in this paper to generate
18
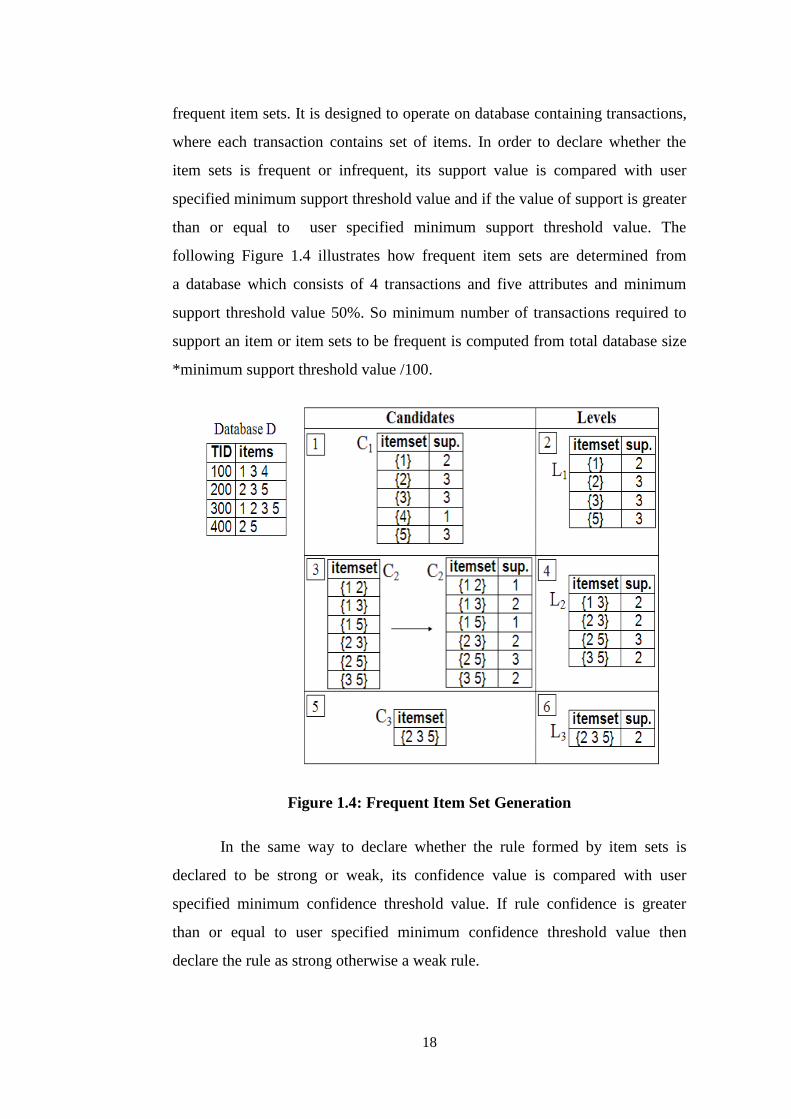
frequent item sets. It is designed to operate on database containing transactions,
where each transaction contains set of items. In order to declare whether the
item sets is frequent or infrequent, its support value is compared with user
specified minimum support threshold value and if the value of support is greater
than or equal to user specified minimum support threshold value. The
following Figure 1.4 illustrates how frequent item sets are determined from
a database which consists of 4 transactions and five attributes and minimum
support threshold value 50%. So minimum number of transactions required to
support an item or item sets to be frequent is computed from total database size
*minimum support threshold value /100.
Figure 1.4: Frequent Item Set Generation
In the same way to declare whether the rule formed by item sets is
declared to be strong or weak, its confidence value is compared with user
specified minimum confidence threshold value. If rule confidence is greater
than or equal to user specified minimum confidence threshold value then
declare the rule as strong otherwise a weak rule.
19
1.3.2 Privacy Preserving Association Rule Mining in Centralized
and Distributed Database
Privacy preserving association rule mining can be defined as the process
of finding association rules from the large database without revealing any
private data or information pertaining to the database. The problem of finding
privacy preserving association rule mining can be solved in different ways for
two different cases such as centralized database environment and distributed
database environment. Even though, the problem in the environments is
different from one another, finding efficient solution in both environments is a
challenging task to the researchers.
In the centralized database environment, source of large database is
provided by single person called database owner who has full rights over the
database as well as over the results of the database. In many real life applications,
many people wish to access the database as well as mined results though they are
not actually owner of the database but they are treated as partners or legitimate
people since they may get mutual benefits between themselves. So the database
owner is willing to provide their database to their partners in order to have
goodwill between them. The partners may then allow accessing the database to
find association rules but they should not be allowed to get opportunity to access
confidential data or information. This makes the issue to the researchers how to
design a new database called distorted database based on original database to
preserve private data or information. Many approaches have been developed by
researchers to find distorted database where distorted database is determined by
doing changes in supporting transactions for items or item sets. These changes
makes the database to hide sensitive information but also produces side effects
such as non sensitive information may also be hidden and also spurious
information may be produced in some cases.
In distributed database environment, the main target is finding global
association rules from n (n≥2) number of sites without interfering in any one’s
private data. However every site owner participates in mining process by
providing their partial results in disguised form to protect from one another in
order to find global frequent item sets.
20
Data hiding can be done in different ways in different partitioned
methods which means for horizontally partitioned database model the process of
finding global association rules from n sites is entirely different from finding
global association rules for vertically partitioned databases since the data
schema is different from one another. In many real life applications, different
types of mixed partitioned databases, called hybrid are also exist which are
formed by combining basic partitioned models in different ways according to
organizational structure. Privacy preserving association rule mining is also
required in mixed model.
1.4 Scope of the Investigation
In this thesis, main work is focused on problem of finding privacy
preserving association rule mining from large database efficiently in two
different environments such as centralized and distributed database
environments. A brief account of the methods adopted to solve this problem in
two different environments is given hereunder.
The main thrust of the work, as reported in the dissertation, is the
presentation of methodologies for finding association rules without revealing
any one’s secret data to any other one in centralized as well as distributed
environments. The need of efficient methodologies that would work irrespective
of the number of attributes, number of transactions, size of sensitive data,
number of sensitive rules and number of users.
To protect sensitive data or information in the process of mining
association rules without any side effects makes this research problem a
challenging one.
In this work, in centralized database environment, two approaches namely
heuristic and exact approaches are considered for finding association rules by
preserving sensitive information. A new methodology based on heuristic
approach is proposed to hide the sensitive information in the process of
generating association rules. In another experiment, a modification for the
existing inline algorithm is proposed to minimize the side effects in the process
21
of hiding sensitive information by applying divide and conquer strategy on
constraints. A partition based hybrid hiding methodology is also proposed to
hide the sensitive information for large database in the process of finding
optimum solution efficiently by using the concepts of divide and conquer and
parallelism.
The performance analysis of the above said three proposed methodologies in
case of centralized database environment is discussed.
In this thesis work, the problem of finding privacy preserving association
rule mining in case of distributed database environment is also considered.
The problem of finding privacy preserving association rule mining in
case of horizontally partitioned databases with Trusted Party is discussed with
proposed methodology by adopting cryptography techniques. As another case
how to find the privacy preserving association rule mining for horizontally
partitioned databases when no site can be considered as trusted party is
discussed with proposed cryptography based methodology.
In case of vertically partitioned databases, a methodology which adopts
scalar product is proposed to find global association rules without violating
privacy constraints. A mixed model partitioned database model which consists
of a combination of horizontally and vertically partitioned strategies is
considered in this work to find the global association rules by preserving
privacy of individuals.
The performance of the above proposed methodologies in case of
distributed database environment is analyzed.
1.5 Organization of the Thesis
The entire work in thesis is organized into six chapters.
Chapter I is an introductory part of the thesis, which gives detailed
description of data mining techniques, the need of privacy preservation in data
mining and its applications. The goals and approaches for privacy preserving
data mining are also discussed. The significance of association rule mining and
privacy preserving association rule mining in centralized as well as in
distributed database environment are presented in this chapter.
22
In Chapter II, a review of literature related to sensitive association rule
hiding in centralized database environment is presented. Earlier work on various
approaches for finding association rules while hiding sensitive rules is also
discussed. This chapter further specifies the earlier work which was done for
preserving individual’s sensitive data/database in the process of finding
association rules in distributed environment. Earlier work related to privacy
preserving association rule mining with various partitioning methods such as