73
Information Retrieval Introduction
| Date post: | 27-Oct-2015 |
| Category: |
Documents |
| Upload: | vijaya-natarajan |
| View: | 91 times |
| Download: | 1 times |

Information RetrievalIntroduction

Information Retrieval

Information Retrieval – PART I
Introduction- Motivation Basic Concepts Past, Present and the Future The Retrieval Process

Motivation
IR: representation, storage, organization of, and access to information items
Focus is on the user information need User information need:
Find all docs containing information on college tennis teams which: (1) are maintained by a USA university and (2) participate in the NCAA tournament.
Emphasis is on the retrieval of information (not data)

Motivation Data retrieval
which docs contain a set of keywords? Well defined semantics a single erroneous object implies failure!
Information retrieval information about a subject or topic semantics is frequently loose small errors are tolerated
IR system: interpret contents of information items generate a ranking which reflects relevance notion of relevance is most important

Motivation IR at the center of the stage
IR in the last 20 years: classification and categorization systems and languages user interfaces and visualization
Still, area was seen as of narrow interest Advent of the Web changed this perception once and for all
universal repository of knowledge free (low cost) universal access no central editorial board many problems though: IR seen as key to finding the
solutions!

Information Retrieval – UNIT I
INTRODUCTION,RETRIEVAL STRATEGIES –I: Introduction- Motivation Basic Concepts Past, Present and the Future The Retrieval Process
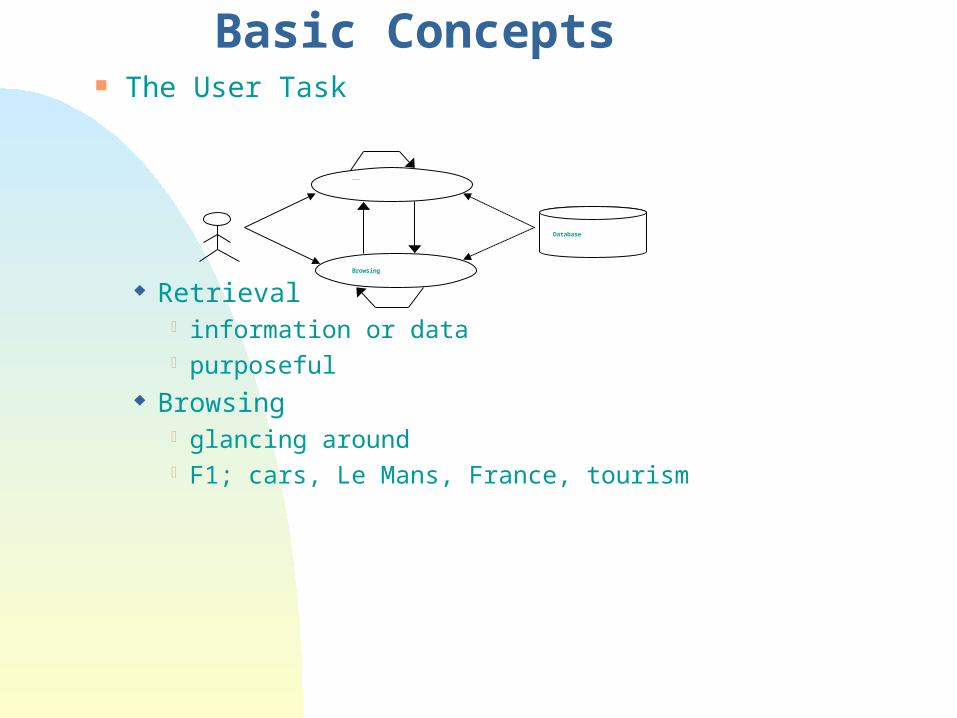
Basic Concepts The User Task
Retrieval information or data purposeful
Browsing glancing around F1; cars, Le Mans, France, tourism
Retrieval
Browsing
Database

Basic Concepts Logical view of the documents
Document representation viewed as a continuum: logical view of docs might shift
structure
Accentsspacing stopwords
Noungroups stemming
Manual indexingDocs
structure Full text Index terms

Information Retrieval – UNIT I
INTRODUCTION,RETRIEVAL STRATEGIES –I: Introduction- Motivation Basic Concepts Past, Present and the Future The Retrieval Process

11
History of IR
• 1960-70’s:– Initial exploration of text retrieval systems for
“small” corpora of scientific abstracts, and law and business documents.
– Development of the basic Boolean and vector-space models of retrieval.
– Prof. Salton and his students at Cornell University are the leading researchers in the area.

12
IR History Continued
• 1980’s:– Large document database systems, many run by
companies:• Lexis-Nexis
• Dialog
• MEDLINE

13
IR History Continued
• 1990’s:– Searching FTPable documents on the Internet
• Archie
• WAIS
– Searching the World Wide Web• Lycos
• Yahoo
• Altavista

14
IR History Continued
• 1990’s continued:– Organized Competitions
• NIST TREC
– Recommender Systems• Ringo
• Amazon
• NetPerceptions
– Automated Text Categorization & Clustering

15
Recent IR History
• 2000’s– Link analysis for Web Search
– Automated Information Extraction• Whizbang
• Fetch
• Burning Glass
– Question Answering• TREC Q/A track
16
Recent IR History
• 2000’s continued:– Multimedia IR
• Image
• Video
• Audio and music
– Cross-Language IR• DARPA Tides
– Document Summarization

The Seven Ages of Information Retrieval Vannevar Bush's 1945 article set a Vannevar Bush's 1945 article set a
goal of fast access to the contents of goal of fast access to the contents of the world's libraries which looks like the world's libraries which looks like it will be achieved by 2010, sixty-five it will be achieved by 2010, sixty-five years later. years later. Bush’s Prediction

Modern History
The “information overload” problem is much older than you may think
Origins in period immediately after World War II Tremendous scientific progress during the war Rapid growth in amount of scientific publications
available
The “Memex Machine” Conceived by Vannevar Bush, President Roosevelt's
science advisor Outlined in 1945 Atlantic Monthly article titled “As We
May Think” Foreshadows the development of hypertext (the Web)
and information retrieval system

The Memex Machine

Historical aspects
As We May Think'', by Vannevar Bush As We May Think'', by Vannevar Bush
Article was originally published in 1945.
Most have been implemented as of 2005
He imagined that machines would read in visual form
His assertion that logic is suitable for mechanical computation is not yet appreciated
Documents are accessible & viewable from the memex system of Bush
Documents may exist on many media: text, pictures, audio.
The memex can keep the ``trail'' of documents you read while you follow your curiosity(Basically, it's a persistent history of URLs as you surf the web.) You can create associations between documents You can enter original material

IR Childhood (1945-1955)
Ideas conceived Ideas conceived Information explosion after World War IIInformation explosion after World War II Possibility of information processing Possibility of information processing
machinemachine MemexMemex
The hardware seems mostly out of date. The hardware seems mostly out of date. user inserting 5000 pages per day into a user inserting 5000 pages per day into a
personal repository and it taking hundreds personal repository and it taking hundreds of years to fill it up. of years to fill it up.
the software goals have not been achieved.the software goals have not been achieved.

The Schoolboy (1960s)
Many many experimentsMany many experiments Use of Precision and RecallUse of Precision and Recall Use of relevance feedbackUse of relevance feedback

Adulthood (1970s) The invention of The invention of
word processing systemsword processing systems time-sharing systemstime-sharing systems
The beginning of information industryThe beginning of information industry OCLC(Online Computer Library Centre)OCLC(Online Computer Library Centre) DIALOGDIALOG BRS(Bibliographic Retrieval Service)BRS(Bibliographic Retrieval Service)

Maturity (1980s)

Mid-Life Crisis (1990s)• Internet put IR to the test.• Better understanding of the limit of IR.• Large scale evaluations• Digital Libraries projects

Predictions Fulfillment (2000s)Fulfillment (2000s) Retirement (2010)Retirement (2010)

Information Retrieval – PART I
INTRODUCTION,RETRIEVAL STRATEGIES –I: Introduction- Motivation Basic Concepts Past, Present and the Future The Retrieval Process

UserInterface
Text Operations
Query Operations Indexing
Searching
Ranking
Index
Text
query
user need
user feedback
ranked docs
retrieved docs
logical viewlogical view
inverted file
DB Manager Module
4, 10
6, 7
5 8
2
8
Text Database
Text
The Retrieval Process

Information Retrieval – PART I
INTRODUCTION,RETRIEVAL STRATEGIES –I: Introduction- Motivation Basic Concepts Past, Present and the Future The Retrieval Process Other Related Slides – not part of the book

30
Information Retrieval(IR)
• The indexing and retrieval of textual documents.
• Searching for pages on the World Wide Web is the most recent “killer app.”
• Concerned firstly with retrieving relevant documents to a query.
• Concerned secondly with retrieving from large sets of documents efficiently.

31
Typical IR Task
• Given:– A corpus of textual natural-language
documents.– A user query in the form of a textual string.
• Find:– A ranked set of documents that are relevant to
the query.

32
IR System
IRSystem
Query String
Documentcorpus
RankedDocuments
1. Doc12. Doc23. Doc3 . .

33
Relevance
• Relevance is a subjective judgment and may include:– Being on the proper subject.– Being timely (recent information).– Being authoritative (from a trusted source).– Satisfying the goals of the user and his/her
intended use of the information (information need).

34
Keyword Search
• Simplest notion of relevance is that the query string appears verbatim in the document.
• Slightly less strict notion is that the words in the query appear frequently in the document, in any order (bag of words).

35
Problems with Keywords
• May not retrieve relevant documents that include synonymous terms.– “restaurant” vs. “café”– “PRC” vs. “China”
• May retrieve irrelevant documents that include ambiguous terms.– “bat” (baseball vs. mammal)– “Apple” (company vs. fruit)– “bit” (unit of data vs. act of eating)

36
Beyond Keywords
• We will cover the basics of keyword-based IR, but…
• We will focus on extensions and recent developments that go beyond keywords.
• We will cover the basics of building an efficient IR system, but…
• We will focus on basic capabilities and algorithms rather than systems issues that allow scaling to industrial size databases.

37
Intelligent IR
• Taking into account the meaning of the words used.
• Taking into account the order of words in the query.
• Adapting to the user based on direct or indirect feedback.
• Taking into account the authority of the source.

38
IR System Architecture
TextDatabase
DatabaseManager
Indexing
Index
QueryOperations
Searching
RankingRanked
Docs
UserFeedback
Text Operations
User Interface
RetrievedDocs
UserNeed
Text
Query
Logical View
Inverted file

39
IR System Components
• Text Operations forms index words (tokens).– Stopword removal– Stemming
• Indexing constructs an inverted index of word to document pointers.
• Searching retrieves documents that contain a given query token from the inverted index.
• Ranking scores all retrieved documents according to a relevance metric.

40
IR System Components (continued)
• User Interface manages interaction with the user:– Query input and document output.– Relevance feedback.– Visualization of results.
• Query Operations transform the query to improve retrieval:– Query expansion using a thesaurus.– Query transformation using relevance feedback.

41
Web Search
• Application of IR to HTML documents on the World Wide Web.
• Differences:– Must assemble document corpus by spidering
the web.– Can exploit the structural layout information
in HTML (XML).– Documents change uncontrollably.– Can exploit the link structure of the web.

42
Web Search System
Query String
IRSystem
RankedDocuments
1. Page12. Page23. Page3 . .
Documentcorpus
Web Spider

43
Other IR-Related Tasks
• Automated document categorization• Information filtering (spam filtering)• Information routing• Automated document clustering• Recommending information or products• Information extraction• Information integration• Question answering

44
Related Areas
• Database Management
• Library and Information Science
• Artificial Intelligence
• Natural Language Processing
• Machine Learning

45
Database Management
• Focused on structured data stored in relational tables rather than free-form text.
• Focused on efficient processing of well-defined queries in a formal language (SQL).
• Clearer semantics for both data and queries.
• Recent move towards semi-structured data (XML) brings it closer to IR.

46
Library and Information Science
• Focused on the human user aspects of information retrieval (human-computer interaction, user interface, visualization).
• Concerned with effective categorization of human knowledge.
• Concerned with citation analysis and bibliometrics (structure of information).
• Recent work on digital libraries brings it closer to CS & IR.

47
Artificial Intelligence
• Focused on the representation of knowledge, reasoning, and intelligent action.
• Formalisms for representing knowledge and queries:– First-order Predicate Logic– Bayesian Networks
• Recent work on web ontologies and intelligent information agents brings it closer to IR.

48
Natural Language Processing
• Focused on the syntactic, semantic, and pragmatic analysis of natural language text and discourse.
• Ability to analyze syntax (phrase structure) and semantics could allow retrieval based on meaning rather than keywords.

49
Natural Language Processing:IR Directions
• Methods for determining the sense of an ambiguous word based on context (word sense disambiguation).
• Methods for identifying specific pieces of information in a document (information extraction).
• Methods for answering specific NL questions from document corpora.

50
Machine Learning
• Focused on the development of computational systems that improve their performance with experience.
• Automated classification of examples based on learning concepts from labeled training examples (supervised learning).
• Automated methods for clustering unlabeled examples into meaningful groups (unsupervised learning).

51
Machine Learning:IR Directions
• Text Categorization– Automatic hierarchical classification (Yahoo).– Adaptive filtering/routing/recommending.– Automated spam filtering.
• Text Clustering– Clustering of IR query results.– Automatic formation of hierarchies (Yahoo).
• Learning for Information Extraction• Text Mining
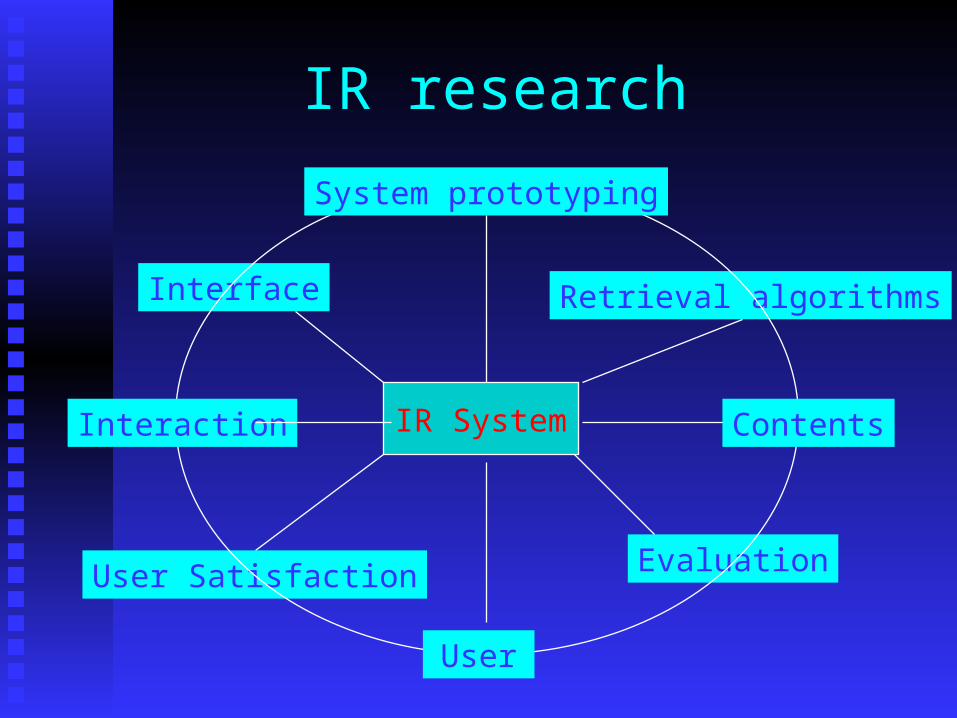
IR research
IR System
Retrieval algorithmsInterface
EvaluationUser Satisfaction
System prototyping
ContentsInteraction
User

Top Ten Research Issues
10. Relevance Feedback.10. Relevance Feedback.
9. Information Extraction.9. Information Extraction.
8. Multimedia Retrieval.8. Multimedia Retrieval.
7. Effective Retrieval.7. Effective Retrieval.
6. Routing and Filtering.6. Routing and Filtering.

Top Ten Research Issues5. Interfaces and Browsing.5. Interfaces and Browsing.4. “Magic” (Vocabulary Mapping).4. “Magic” (Vocabulary Mapping).3. Efficient, Flexible Indexing and 3. Efficient, Flexible Indexing and
Retrieval.Retrieval.2. Distributed IR.2. Distributed IR.1. Integrated Solutions.1. Integrated Solutions.
A new Industry – Content A new Industry – Content ManagementManagement
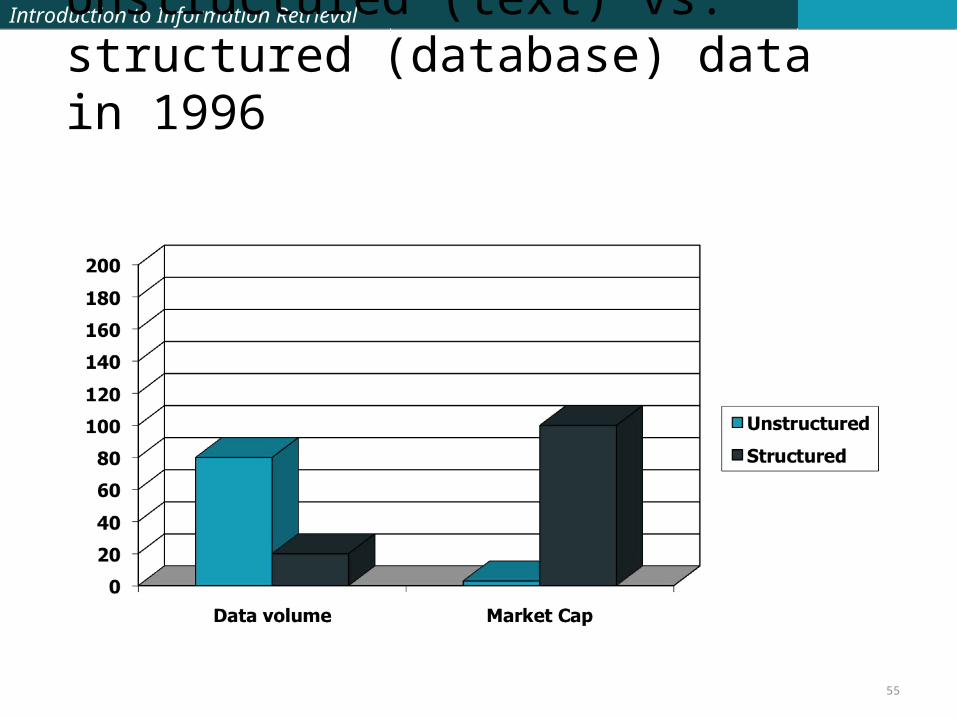
Introduction to Information RetrievalIntroduction to Information Retrieval
Unstructured (text) vs. structured (database) data in 1996
55
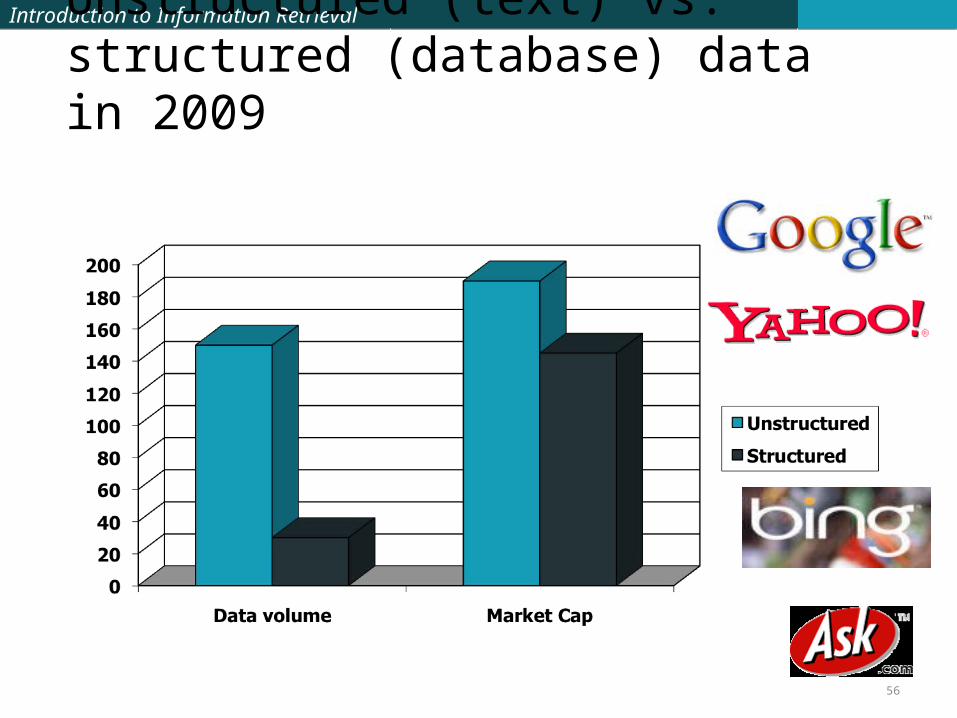
Introduction to Information RetrievalIntroduction to Information Retrieval
Unstructured (text) vs. structured (database) data in 2009
56

Definitions• An Information Retrieval (IR) System• attempts to find relevant documents to respond to a user’s request.• The real problem boils down to matching the language of the query to the language of the document.

What is Information?
What do you think?
There is no “correct” definition
Cookie Monster’s definition: “news or facts about something”
Different approaches: Philosophy Psychology Linguistics Electrical engineering Physics Computer science Information science

Dictionary says…
Oxford English Dictionary information: informing, telling; thing told, knowledge,
items of knowledge, news knowledge: knowing familiarity gained by experience;
person’s range of information; a theoretical or practical understanding of; the sum of what is known
Random House Dictionary information: knowledge communicated or received
concerning a particular fact or circumstance; news

Intuitive Notions
Information must Be something, although the exact nature (substance,
energy, or abstract concept) is not clear; Be “new”: repetition of previously received messages is
not informative Be “true”: false or counterfactual information is “mis-
information” Be “about” something
Robert M. Losee. (1997) A Discipline Independent Definition of Information. Journal of the American Society for Information Science, 48(3), 254-269.

Three Views of Information
Information as process
Information as communication
Information as message transmission and reception

One View
Information = characteristics of the output of a process Tells us something about the process and the input
Information-generating process do not occur in isolation
Ibid.
ProcessInput
Input
Input
Output
Output
Output
Process1 Process2Input Output…

Where’s the human?
If a tree falls in the forest, and no one is around to hear it, is information transmitted?
In the “information as process”: Yes, but that’s not very interesting to us
We’re concerned about information for human consumption Transmission of information from one person to another Recording of information Reconstruction of stored information

Another View
Information science is characterized by “the deliberate (purposeful) structure of the message by the sender in order to affect the image structure of the recipient” This implies that the sender has knowledge of the
recipient's structure
Text = “a collection of signs purposefully structured by a sender with the intention of changing image-structure of a recipient”
Information = “the structure of any text which is capable of changing the image-structure of a recipient”
Nicholas J. Belkin and Stephen E. Robertson. (1976) Information Science and the Phenomenon of Information. Journal of the American Society for Information Science, 27(4), 197-204.
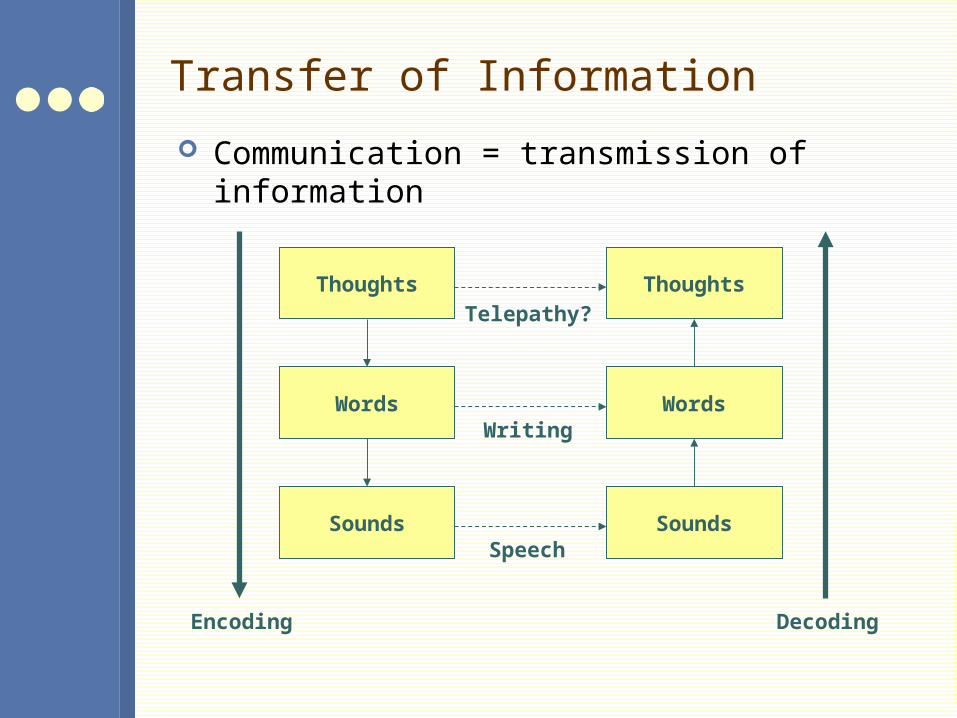
Transfer of Information
Communication = transmission of information
Thoughts
Words
Sounds
Thoughts
Words
Sounds
Encoding Decoding
Speech
Writing
Telepathy?

Information Hierarchy
Data
Information
Knowledge
Wisdom
More refined and abstract

• Simply matching on words is a very brittle approach.• One word can have a zillion different semantic meanings – Consider: Take – “take a place at the table” – “take money to the bank” – “take a picture” – “take a lot of time” – “take drugs”

Difference of IR with rest of CS
What is Different about IR from the rest of Computer Science
Most algorithms in computer science have a “right” answer:
Consider the two problems:
– Sort the following ten integers
– Find the higest integer
Now consider:
– Find the document most relevant to “hippos in the zoo”
Measuring Effectiveness • An algorithm is deemed incorrect if it does not have a “right” answer. • A heuristic tries to guess something close to the right answer. Heuristics are measured on “how close” they come to a right answer. IR techniques are essentially heuristics because we do not know the
right answer. • So we have to measure how close to the right answer we can come.

DOCUMENT RETRIEVAL
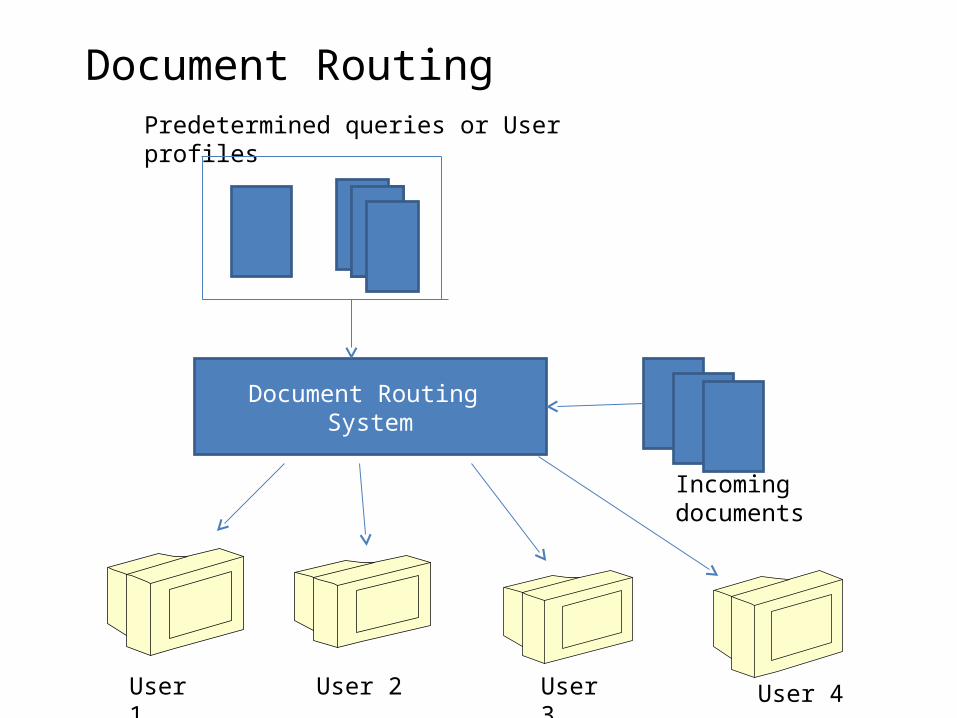
Document RoutingPredetermined queries or User profiles
Document Routing System
Incoming documents
User 1 User 2 User 3 User 4

Result Set: Relevant Retrieved, Relevant and Retrieved
• Retrieved
Relevant
Relevant Retrieved Precision = Relevant Retrieved Retrieved Recall = Relevant Retrieved Relevant

Precision and Two points of Recall
Answer set in order of
similarity coefficient 1.0 (relevant documents:d5,d2) 0.8
0.6 (0.5,0.5) 0.4 (1.0, 0.4) 0.2 0.2 0.4 0.6 0.8 1.0
d1
d2
d3
d4
d5
d6
d7
d8
d9
d10
100% recall
50% recall
Recall
Pre
cisi
on
Precision at 50% recall = 1/2= 50%Precision at 100% recall = 2/5= 40%
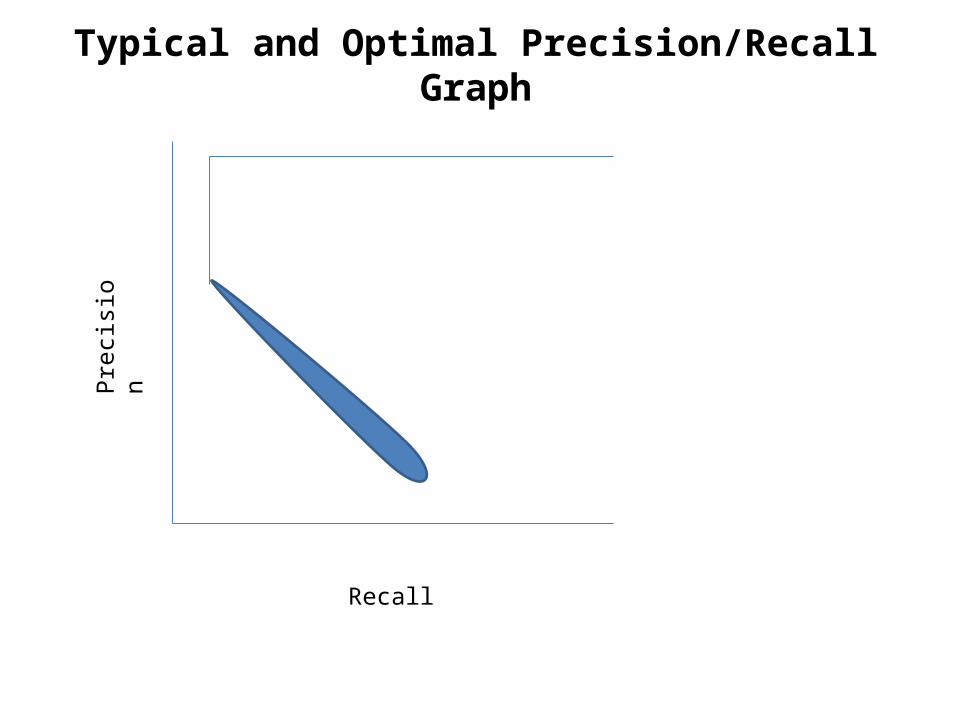
Typical and Optimal Precision/Recall Graph
Recall
Pre
cisi
on

















