23
Introduction to Databases Vetle I. Torvik
| Date post: | 02-Jan-2016 |
| Category: |
Documents |
| Upload: | derick-emory-payne |
| View: | 214 times |
| Download: | 0 times |

Introduction to Databases
Vetle I. Torvik

DNA was the 20th century - Databases are the 21st century
Quantum leaps in the evolution of human brain power– Way-back-when: information in books - phone books,
dictionaries, lab notebooks, journals– Recently: information at your fingertips– Now: scientific discovery at your fingertips
• data mining bio-informatics databases
• data mining text data bases

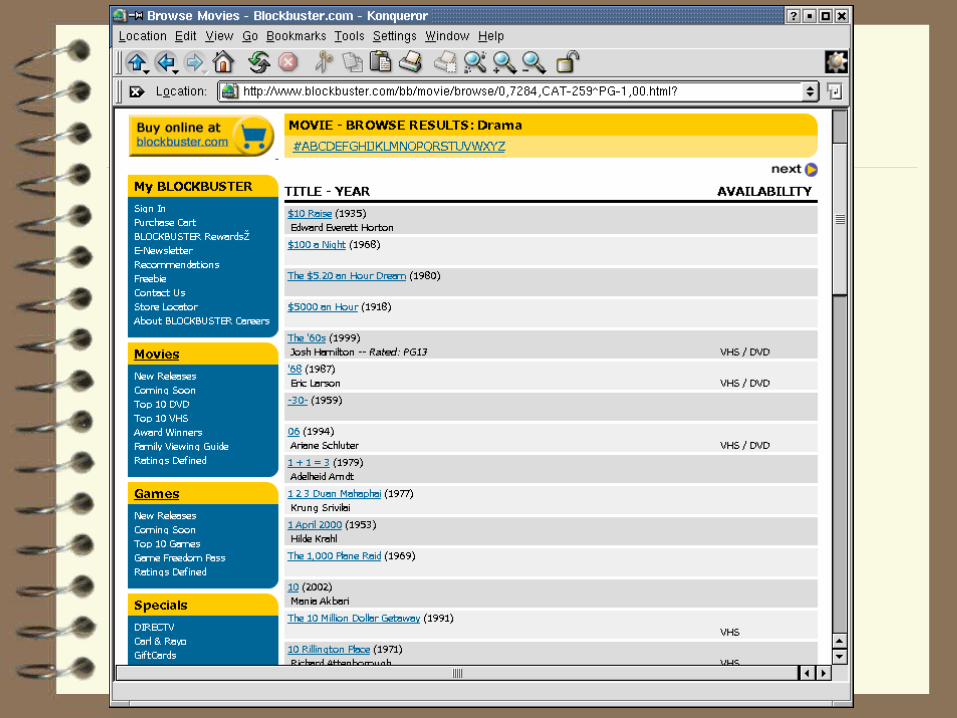
How do you find a good movie?
New releases only? Browsing shelves by category (comedy,
action, drama, foreign, etc.)? Browsing through a book at blockbuster
– by titles alphabetically?– by actors alphabetically?– by category?– by year?
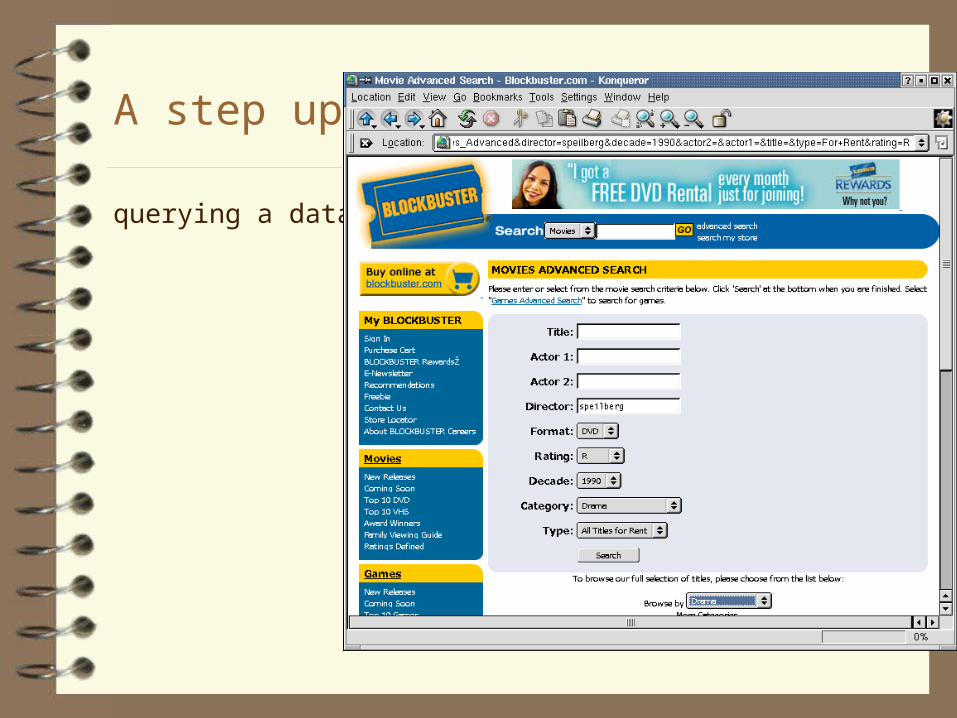
A step up...
querying a database

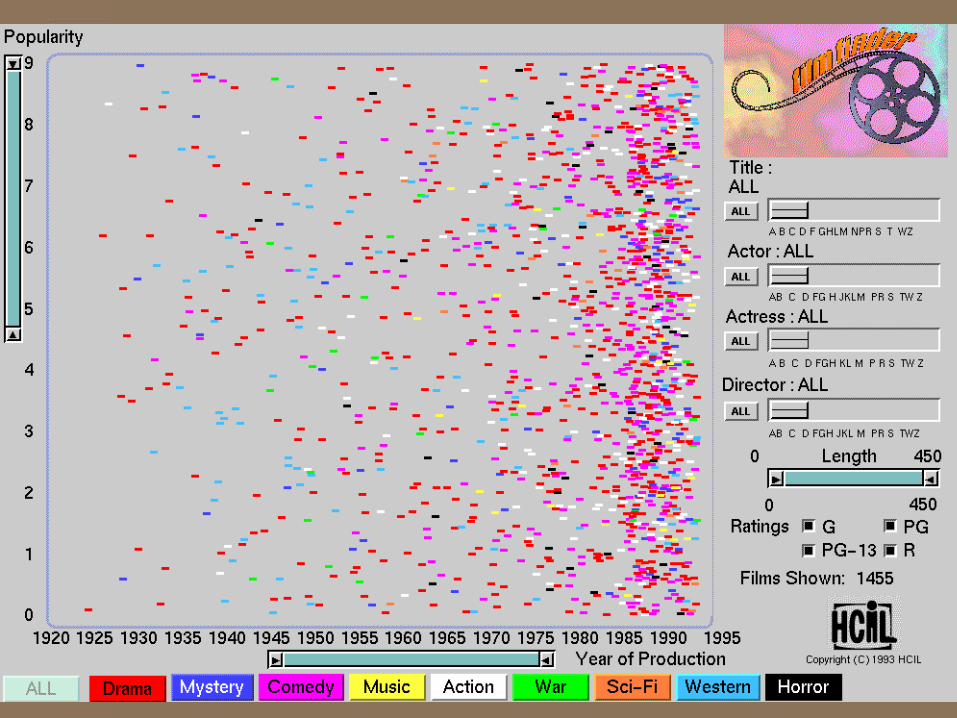
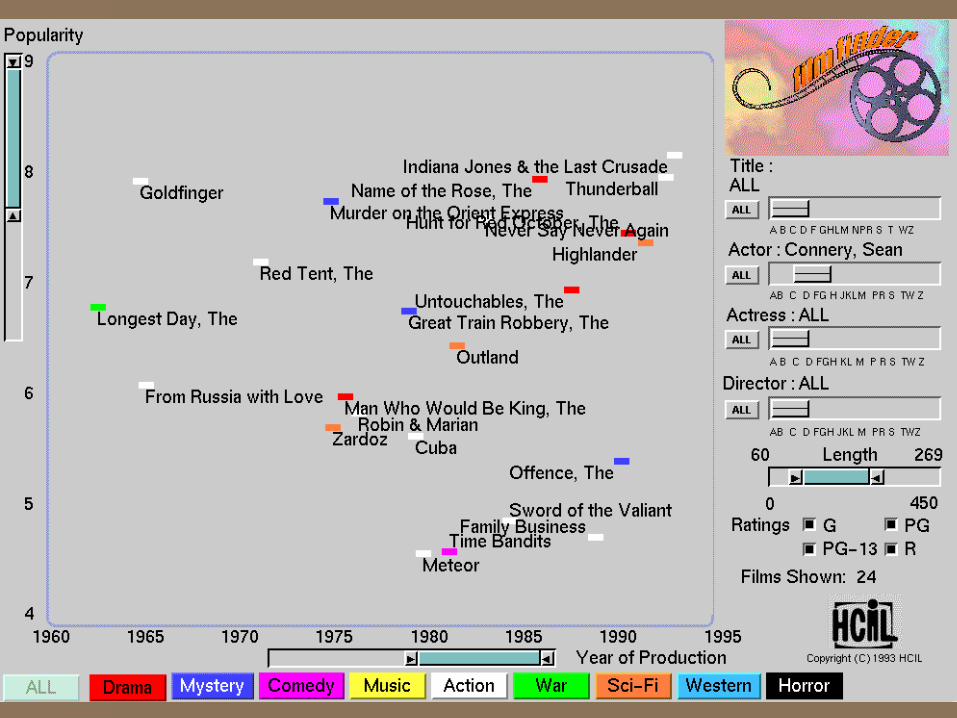
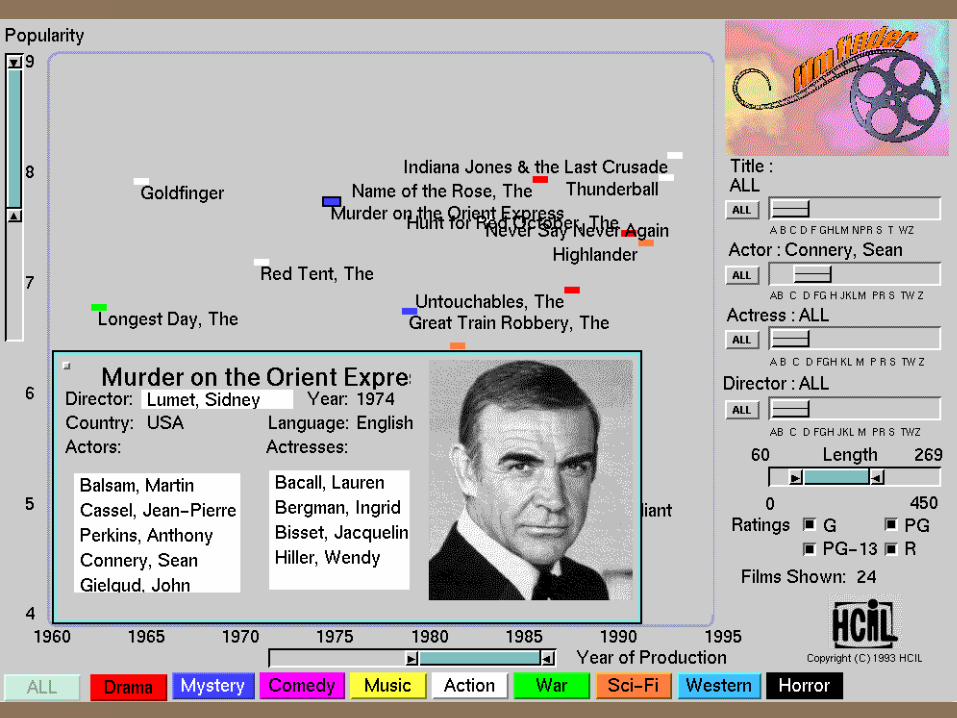
Now imagine this…
Visualizing the entire movie database in ONE figure across ALL dimensions– year, category, actor, director, popularity, rating,
length, language, country, awards, etc.
and drilling down to find your movie(s)
PS: You don’t have to imagine...
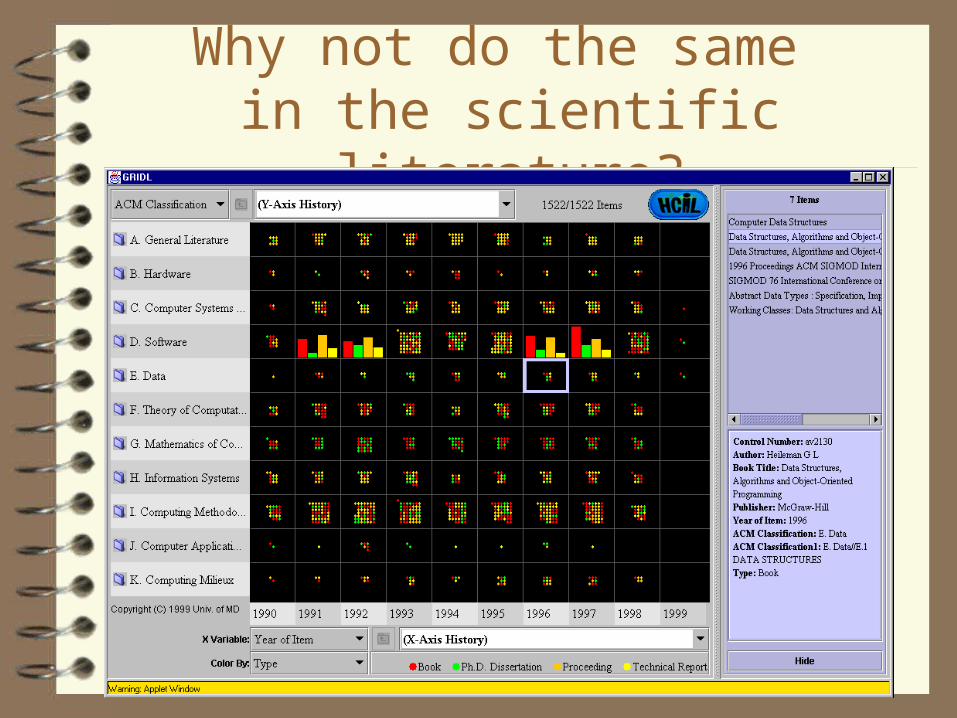
Why not do the same in the scientific literature?

Benefits of DBs
Over paper books… a quantum leap– Speed, space, less drudgery
Over spreadsheets … another quantum leap– Maintenance (less redundancy, etc)– Currency (accuracy, up-to-date, on-demand)– Access (across time and space, sharing)– Security (recovery, restrict others’ access)– Facilitates data mining: encode meaning,
inferences, pooling/sharing, visualization

A Database system to store, retrieve, and manipulate data consists of 4 parts
– Data - collection of linked data files – Hardware - for storage and execution– Software - DB management system (e.g.,
Access, MySQL, Filemaker, Oracle)– Users - DB administrator, data administrator,
application programmers, end users
A Database – an electronic repository for persistent data

Relational DBMSs
Dominates market Data is perceived by users as tables only
• representing, manipulating, and enforcing integrity of data so that operations function correctly
• no duplicate records, rows and columns are unordered, each entry has a single value
SQL = “structured query language”• a standard language for querying databases
• independent of how the data is stored/accessed
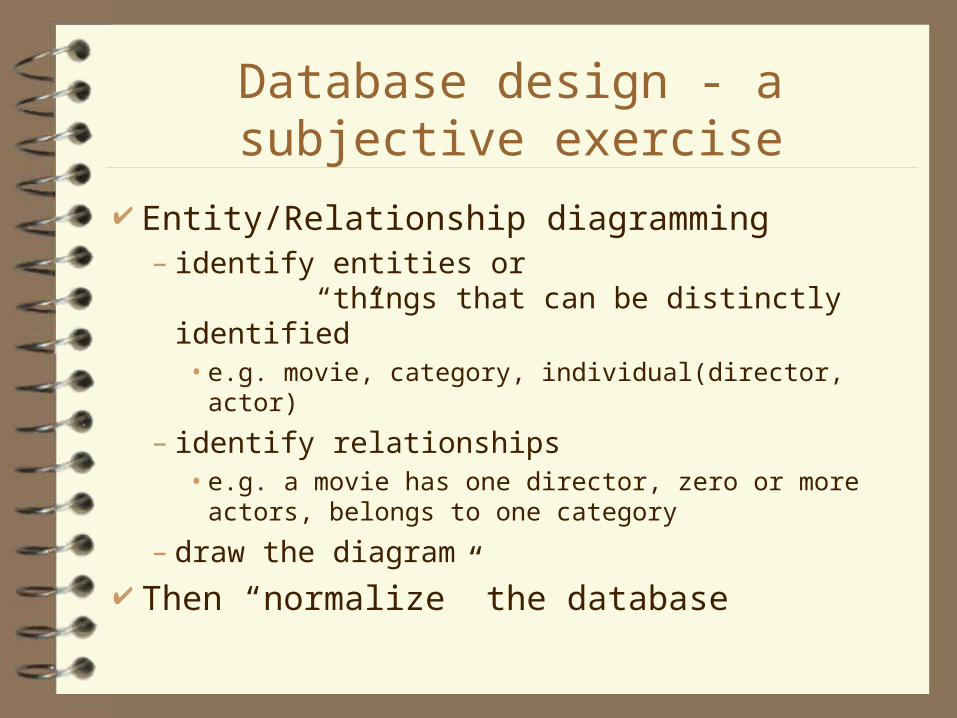
Database design - a subjective exercise
Entity/Relationship diagramming– identify entities or
“things that can be distinctly identified”• e.g. movie, category, individual(director, actor)
– identify relationships • e.g. a movie has one director, zero or more actors,
belongs to one category
– draw the diagram
Then “normalize” the database

Ontologies - the basis upon which the truth of the world is viewed
E.g. a movie has one director, zero or more actors, belongs to one category
makes databases a bit more intelligent
allows for making inferences– “the artist formerly known as Prince” - without an artist
name, nobody can make any name related inferences about him…

Metadata - data about the data
It would be nice if SQL knew that actors and directors are both individuals so that (e.g.) querying movies by actor = director makes sense (and this type of query could be optimized)

Data mining
Searching for novel patterns, rules or relationships in data, e.g.:– correlations– classification– clustering – visualization
Versus traditional statistics: hypothesis testing

Data mining - correlations
Searching through many possible pairs of associations to find novel ones, e.g.:– phenotypes versus genotypes

Data mining - classification
find rules that discriminate between predefined categories– e.g., breast cancer diagnosis– RULE #1: IF the following conditions hold ALL true at the SAME TIME,
THEN the case is: "intra-ductal carcinoma”– CONDITIONS:
• The volume of the calcifications is more than 0.03 cm^3.• AND The total number of calcifications is greater than 10.• AND The variation in shape is moderate or marked.• AND The irregularity in size of calcifications is marked.• AND The variation of the density of calcifications is moderate or marked.• AND There is no ductal orientation.• AND The number of calcifications per cm^3 is less than 20.• AND A comparison with previous exams shows a change in the number or
character of calcifications or it is newly developed.– RULE #2: ...

Data mining - clustering
organizing information by naturally occurring groups, e.g.:– cluster languages by similarity of words to assess
their evolution– organizing webpages into themes by word usage
(e.g., www.vivisimo.com)– grouping genes by expression level in DNA
microarrays to find a subset of differentially expressed genes
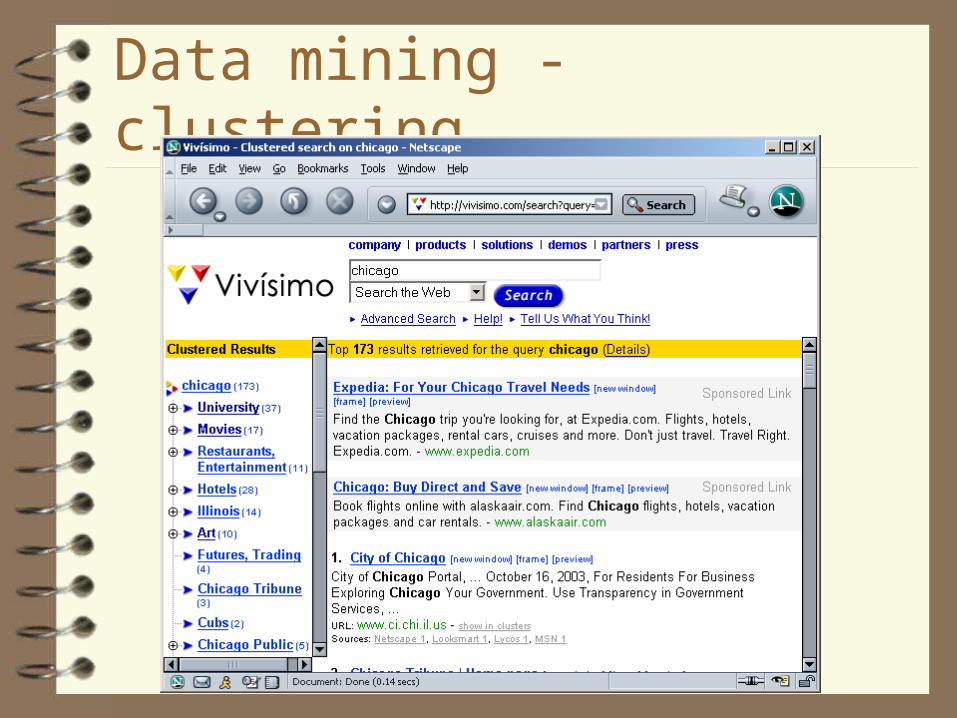
Data mining - clustering

Data mining - visualization
Looking for patterns across multiple dimensions, and levels of resolution e.g.:– scientific collaboration behavior across time
and subjects– map of power outage over time (what was the
chain of events causing a major outage?)

Data mining begins at home
Your lab notebook is a database. Can you data mine your lab notebook?

















