25
Introduction Introduction to Gaussian Process Regression Hanna M. Wallach [email protected] January 25, 2005 Hanna M. Wallach [email protected] Introduction to Gaussian Process Regression

Introduction
Introduction to Gaussian Process Regression
Hanna M. Wallach
January 25, 2005
Hanna M. Wallach [email protected]
Introduction to Gaussian Process Regression

Introduction
Outline
Regression: weight-space view
Regression: function-space view (Gaussian processes)
Weight-space and function-space correspondence
Making predictions
Model selection: hyperparameters
Hanna M. Wallach [email protected]
Introduction to Gaussian Process Regression

Introduction
Supervised Learning: Regression (1)
−1 −0.5 0 0.5 1−1.5
−1
−0.5
0
0.5
1
1.5
input, x
outp
ut, f
(x)
underlying function and noisy data
training data
Assume an underlying process which generates “clean” data.
Goal: recover underlying process from noisy observed data.
Hanna M. Wallach [email protected]
Introduction to Gaussian Process Regression

Introduction
Supervised Learning: Regression (2)
Training data are D = {x(i), y (i) | i = 1, . . . , n}.Each input is a vector x of dimension d .
Each target is a real-valued scalar y = f (x) + noise.
Collect inputs in d × n matrix, X , and targets in vector, y :
D = {X , y}.
Wish to infer f ? for unseen input x?, using P(f ?|x?,D).
Hanna M. Wallach [email protected]
Introduction to Gaussian Process Regression

Introduction
Gaussian Process Models: Inference in Function Space
0 0.2 0.4 0.6 0.8 1−1
0
1
2
3samples from the prior
input, x
outp
ut, f
(x)
0 0.2 0.4 0.6 0.8 10.4
0.6
0.8
1
1.2
1.4samples from the posterior
input, x
outp
ut, f
(x)
A Gaussian process defines a distribution over functions.
Inference takes place directly in function space.
Hanna M. Wallach [email protected]
Introduction to Gaussian Process Regression

Bayesian Linear Regression
Part I
Regression: The Weight-Space View
Hanna M. Wallach [email protected]
Introduction to Gaussian Process Regression
Bayesian Linear Regression
Bayesian Linear Regression (1)
−1 −0.5 0 0.5 1−1.5
−1
−0.5
0
0.5
1
1.5
input, x
outp
ut, f
(x)
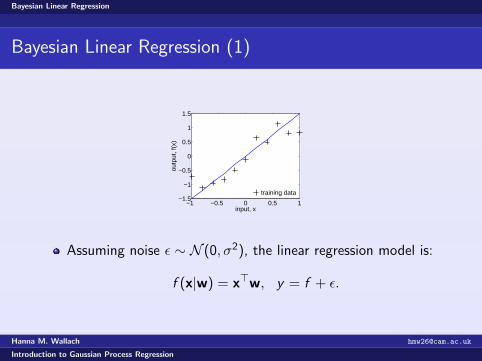
training data
Assuming noise ε ∼ N (0, σ2), the linear regression model is:
f (x|w) = x>w, y = f + ε.
Hanna M. Wallach [email protected]
Introduction to Gaussian Process Regression

Bayesian Linear Regression
Bayesian Linear Regression (2)
Likelihood of parameters is:
P(y|X ,w) = N (X>w, σ2I ).
Assume a Gaussian prior over parameters:
P(w) = N (0,Σp).
Apply Bayes’ theorem to obtain posterior:
P(w|y,X ) ∝ P(y|X ,w)P(w).
Hanna M. Wallach [email protected]
Introduction to Gaussian Process Regression

Bayesian Linear Regression
Bayesian Linear Regression (3)
Posterior distribution over w is:
P(w|y,X ) = N (1
σ2A−1Xy,A−1) where A = Σ−1
p +1
σ2XX>.
Predictive distribution is:
P(f ?|x?,X , y) =
∫f (x?|w)P(w|X , y)dw
= N (1
σ2x?>A−1Xy, x?>A−1x?).
Hanna M. Wallach [email protected]
Introduction to Gaussian Process Regression

Bayesian Linear Regression
Increasing Expressiveness
Use a set of basis functions Φ(x) to project a d dimensionalinput x into m dimensional feature space:
e.g. Φ(x) = (1, x , x2, . . . )
P(f ?|x?,X , y) can be expressed in terms of inner products infeature space:
Can now use the kernel trick.
How many basis functions should we use?
Hanna M. Wallach [email protected]
Introduction to Gaussian Process Regression

Gaussian Process Regression
Part II
Regression: The Function-Space View
Hanna M. Wallach [email protected]
Introduction to Gaussian Process Regression

Gaussian Process Regression
Gaussian Processes: Definition
A Gaussian process is a collection of random variables, anyfinite number of which have a joint Gaussian distribution.
Consistency:
If the GP specifies y (1), y (2) ∼ N (µ,Σ), then it must alsospecify y (1) ∼ N (µ1,Σ11):
A GP is completely specified by a mean function and apositive definite covariance function.
Hanna M. Wallach [email protected]
Introduction to Gaussian Process Regression

Gaussian Process Regression
Gaussian Processes: A Distribution over Functions
e.g. Choose mean function zero, and covariance function:
Kp,q = Cov(f (x(p)), f (x(q))) = K (x(p), x(q))
For any set of inputs x(1), . . . , x(n) we may compute K whichdefines a joint distribution over function values:
f (x(1)), . . . , f (x(n)) ∼ N (0,K ).
Therefore a GP specifies a distribution over functions.
Hanna M. Wallach [email protected]
Introduction to Gaussian Process Regression

Gaussian Process Regression
Gaussian Processes: Simple Example
Can obtain a GP from the Bayesin linear regression model:
f (x) = x>w with w ∼ N (0,Σp).
Mean function is given by:
E[f (x)] = x>E[w] = 0.
Covariance function is given by:
E[f (x)f (x′)] = x>E[ww>]x′ = x>Σpx′.
Hanna M. Wallach [email protected]
Introduction to Gaussian Process Regression

Gaussian Process Regression
Weight-Space and Function Space Correspondence
For any set of m basis functions, Φ(x), the correspondingcovariance function is:
K (x(p), x(q)) = Φ(x(p))>ΣpΦ(x(q)).
Conversely, for every covariance function k, there is a possiblyinfinite expansion in terms of basis functions:
K (x(p), x(q)) =∞∑i=1
λiΦi (x(p))Φi (x
(q)).
Hanna M. Wallach [email protected]
Introduction to Gaussian Process Regression

Gaussian Process Regression
The Covariance Function
Specifies the covariance between pairs of random variables.
e.g. Squared exponential covariance function:
Cov(f (x(p)), f (x(q))) = K (x(p), x(q)) = exp (−1
2|x(p) − x(q)|2).
0 2 4 6 8 100
0.2
0.4
0.6
0.8
1K(x(p) = 5, x(q)) as a function of x(q)
Hanna M. Wallach [email protected]
Introduction to Gaussian Process Regression

Gaussian Process Regression
Gaussian Process Prior
Given a set of inputs x(1), . . . , x(n) we may draw samplesf (x(1)), . . . , f (x(n)) from the GP prior:
f (x(1)), . . . , f (x(n)) ∼ N (0,K ).
Four samples:
0 0.2 0.4 0.6 0.8 1−1
0
1
2
3samples from the prior
input, x
outp
ut, f
(x)
Hanna M. Wallach [email protected]
Introduction to Gaussian Process Regression

Gaussian Process Regression
Posterior: Noise-Free Observations (1)
Given noise-free training data:
D = {x(i), f (i) | i = 1, . . . , n} = {X , f}.
Want to make predictions f? at test points X ?.
According to GP prior, joint distribution of f and f? is:[ff?
]∼ N
(0,
[K (X ,X ) K (X ,X ?)K (X ?,X ) K (X ?,X ?)
]).
Hanna M. Wallach [email protected]
Introduction to Gaussian Process Regression

Gaussian Process Regression
Posterior: Noise-Free Observations (2)
Condition {X ?, f?} on D = {X , f} obtain the posterior.
Restrict prior to contain only functions which agree with D.
The posterior, P(f?|X ?,X , f), is Gaussian with:
µ = K (X ,X ?)K (X ,X )−1f, and
Σ = K (X ?,X ?)− K (X ,X ?)K (X ,X )−1K (X ?,X ).
Hanna M. Wallach [email protected]
Introduction to Gaussian Process Regression
Gaussian Process Regression
Posterior: Noise-Free Observations (3)
0 0.2 0.4 0.6 0.8 10.4
0.6
0.8
1
1.2
1.4samples from the posterior
input, x
outp
ut, f
(x)
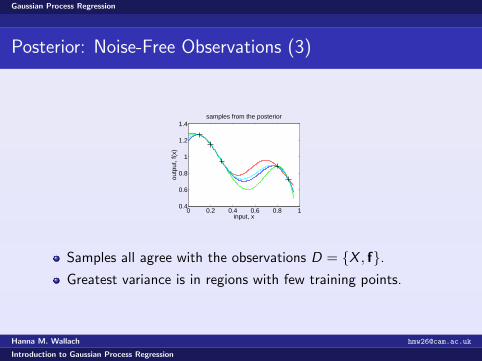
Samples all agree with the observations D = {X , f}.Greatest variance is in regions with few training points.
Hanna M. Wallach [email protected]
Introduction to Gaussian Process Regression

Gaussian Process Regression
Prediction: Noisy Observations
Typically we have noisy observations:
D = {X , y}, where y = f + ε
Assume additive noise ε ∼ N (0, σ2I ).
Conditioning on D = {X , y} gives a Gaussian with:
µ = K (X ,X ?)[K (X ,X ) + σ2I ]−1y, and
Σ = K (X ?,X ?)− K (X ,X ?)[K (X ,X ) + σ2I ]−1K (X ?,X ).
Hanna M. Wallach [email protected]
Introduction to Gaussian Process Regression
Gaussian Process Regression
Model Selection: Hyperparameters
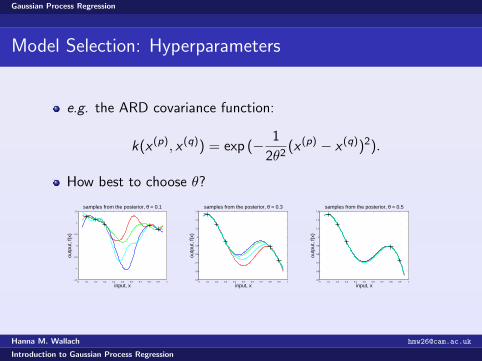
e.g. the ARD covariance function:
k(x (p), x (q)) = exp (− 1
2θ2(x (p) − x (q))2).
How best to choose θ?
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1−1.5
−1
−0.5
0
0.5
1
1.5
samples from the posterior, θ = 0.1
input, x
outp
ut, f
(x)
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10.5
0.6
0.7
0.8
0.9
1
1.1
1.2
1.3
samples from the posterior, θ = 0.3
input, x
outp
ut, f
(x)
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10.5
0.6
0.7
0.8
0.9
1
1.1
1.2
1.3
samples from the posterior, θ = 0.5
input, x
outp
ut, f
(x)
Hanna M. Wallach [email protected]
Introduction to Gaussian Process Regression

Gaussian Process Regression
Model Selection: Optimizing Marginal Likelihood (1)
In absence of a strong prior P(θ), the posterior forhyperparameter θ is proportional to the marginal likelihood:
P(θ|X , y) ∝ P(y|X , θ)
Choose θ to optimize the marginal log-likelihood:
log P(y|X , θ) = −1
2log |K (X ,X ) + σ2I |−
1
2y>(K (X ,X ) + σ2I )−1y − n
2log 2π.
Hanna M. Wallach [email protected]
Introduction to Gaussian Process Regression

Gaussian Process Regression
Model Selection: Optimizing Marginal Likelihood (2)
θML = 0.3255:
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10.5
0.6
0.7
0.8
0.9
1
1.1
1.2
1.3
1.4
samples from the posterior, θ = 0.3255
input, x
outp
ut, f
(x)
Using θML is an approximation to the true Bayesian method ofintegrating over all θ values weighted by their posterior.
Hanna M. Wallach [email protected]
Introduction to Gaussian Process Regression

Gaussian Process Regression
References
1 Carl Edward Rasmussen. Gaussian Processes in Machinelearning. Machine Learning Summer School, T ubingen, 2003.http://www.kyb.tuebingen.mpg.de/~carl/mlss03/
2 Carl Edward Rasmussen and Chris Williams. GaussianProcesses for Machine Learning. Forthcoming.
3 Carl Edward Rasmussen. The Gaussian Process Website.http://www.gatsby.ucl.ac.uk/~edward/gp/
Hanna M. Wallach [email protected]
Introduction to Gaussian Process Regression










![Model Learning with Local Gaussian Process Regressionis.tuebingen.mpg.de/.../files/...ModelLearningLocalGaussianl_6067[0].pdfModel Learning with Local Gaussian Process Regression Duy](https://static.documents.pub/doc/80x56/5e053288be40e6676f79111b/model-learning-with-local-gaussian-process-0pdfmodel-learning-with-local-gaussian.jpg)






