59
Dr. Sandeep G. Deshmukh DataTorrent 1 Introduction to
| Date post: | 23-Feb-2017 |
| Category: |
Software |
| Upload: | apache-apex |
| View: | 376 times |
| Download: | 0 times |

Dr. Sandeep G. Deshmukh
DataTorrent
1
Introduction to

Contents
Motivation
Scale of Cloud Computing
Hadoop
Hadoop Distributed File System (HDFS)
MapReduce
Sample Code Walkthrough
Hadoop EcoSystem
2
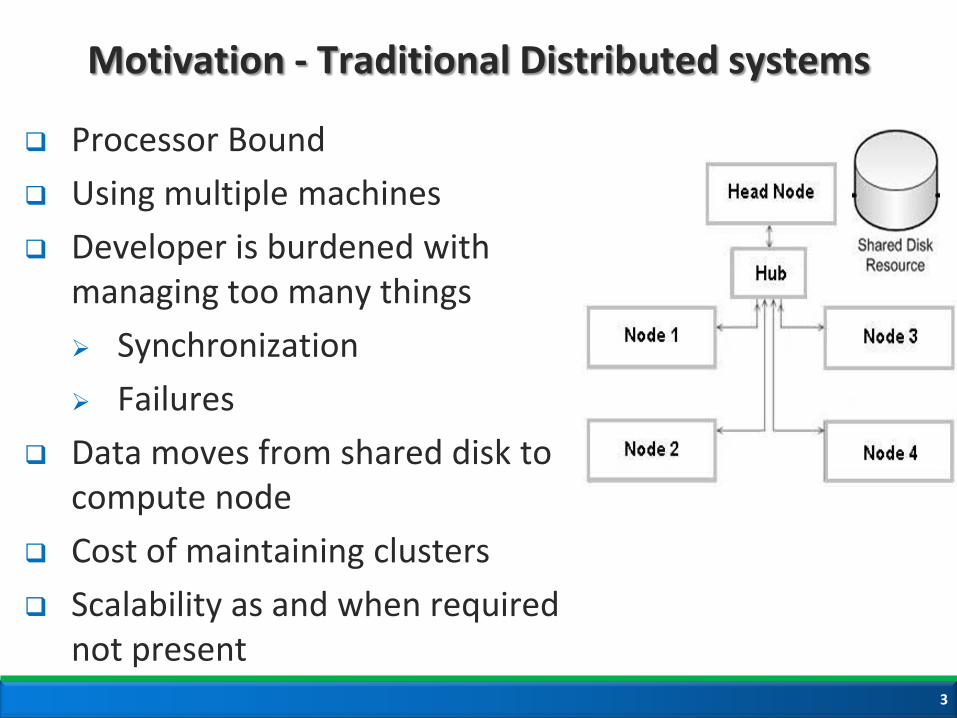
Motivation - Traditional Distributed systems
Processor Bound
Using multiple machines
Developer is burdened with managing too many things
Synchronization
Failures
Data moves from shared disk to compute node
Cost of maintaining clusters
Scalability as and when required not present
3

What is the scale we are talking about?
100s of CPUs?
Couple of CPUs?
10s of CPUs?
4

5

Hadoop @ Yahoo!
6

7

What we need
Handling failure
One computer = fails once in 1000 days
1000 computers = 1 per day
Petabytes of data to be processed in parallel
1 HDD= 100 MB/sec
1000 HDD= 100 GB/sec
Easy scalability
Relative increase/decrease of performance depending on increase/decrease of nodes
8

What we’ve got : Hadoop!
Created by Doug Cutting
Started as a module in nutch and then matured as an apache project
Named it after his son's stuffed
elephant
9

What we’ve got : Hadoop!
Fault-tolerant file system Hadoop Distributed File System (HDFS) Modeled on Google File system
Takes computation to data Data Locality
Scalability: Program remains same for 10, 100, 1000,… nodes Corresponding performance improvement
Parallel computation using MapReduce Other components – Pig, Hbase, HIVE, ZooKeeper
10

HDFS Hadoop distributed File System
11

How HDFS works
NameNode - Master
DataNodes - Slave
Secondary NameNode
12

Storing file on HDFS
Motivation Reliability, Availability, Network Bandwidth
The input file (say 1 TB) is split into smaller chunks/blocks of 64 MB (or multiples
of 64MB) The chunks are stored on multiple nodes as independent files on slave nodes To ensure that data is not lost, replicas are stored in the following way:
One on local node One on remote rack (incase local rack fails) One on local rack (incase local node fails) Other randomly placed Default replication factor is 3
13

B1
B1
B1
B2
B2
B2
B3 Bn
Hub 1 Hub 2
Data n
od
es File
Master Node
8 gigabit
1 gigabit
Blocks
14

NameNode - Master
The master node: NameNode
Functions:
Manages File System- mapping files to blocks and blocks to data nodes
Maintaining status of data nodes
Heartbeat Datanode sends heartbeat at regular intervals
If heartbeat is not received, datanode is declared dead
Blockreport DataNode sends list of blocks on it
Used to check health of HDFS
15

NameNode Functions
Replication
On Datanode failure
On Disk failure
On Block corruption
Data integrity
Checksum for each block
Stored in hidden file
Rebalancing- balancer tool
Addition of new nodes
Decommissioning
Deletion of some files
NameNode - Master
16

HDFS Robustness
Safemode
At startup: No replication possible
Receives Heartbeats and Blockreports from Datanodes
Only a percentage of blocks are checked for defined replication factor
17
All is well Exit Safemode
Replicate blocks wherever necessary

HDFS Summary
Fault tolerant
Scalable
Reliable
File are distributed in large blocks for
Efficient reads
Parallel access
18

Questions?
19

MapReduce
20

What is MapReduce?
It is a powerful paradigm for parallel computation
Hadoop uses MapReduce to execute jobs on files in HDFS
Hadoop will intelligently distribute computation over cluster
Take computation to data
21

Origin: Functional Programming
map f [a, b, c] = [f(a), f(b), f(c)]
map sq [1, 2, 3] = [sq(1), sq(2), sq(3)]
= [1,4,9]
Returns a list constructed by applying a function (the first argument) to all items in a list passed as the second argument
22

Origin: Functional Programming
reduce f [a, b, c] = f(a, b, c)
reduce sum [1, 4, 9] = sum(1, sum(4,sum(9,sum(NULL))))
= 14
Returns a list constructed by applying a function (the first argument) on the list passed as the second argument
Can be identity (do nothing)
23

Sum of squares example
[1,2,3,4]
Sq (1) Sq (2) Sq (3) Sq (4)
16 9 4 1
30
Input
Intermediate output
Output
MAPPER
REDUCER
M1 M2 M3 M4
R1
24

Sum of squares of even and odd
[1,2,3,4]
Sq (1) Sq (2) Sq (3) Sq (4)
(even, 16) (odd, 9) (even, 4) (odd, 1)
(even, 20) (odd, 10)
Input
Intermediate output
Output
MAPPER
REDUCER
M1 M2 M3 M4
R1 R2
25

Programming model- key, value pairs
Format of input- output
(key, value)
Map: (k1, v1) → list (k2, v2)
Reduce: (k2, list v2) → list (k3, v3)
26

Sum of squares of even and odd and prime
[1,2,3,4]
Sq (1) Sq (2) Sq (3) Sq (4)
(even, 16) (odd, 9)
(prime, 9)
(even, 4)
(prime, 4)
(odd, 1)
(even, 20) (odd, 10)
(prime, 13)
Input
Intermediate output
Output
R2 R1
R3
27

Many keys, many values
Format of input- output
(key, value)
Map: (k1, v1) → list (k2, v2)
Reduce: (k2, list v2) → list (k3, v3)
28
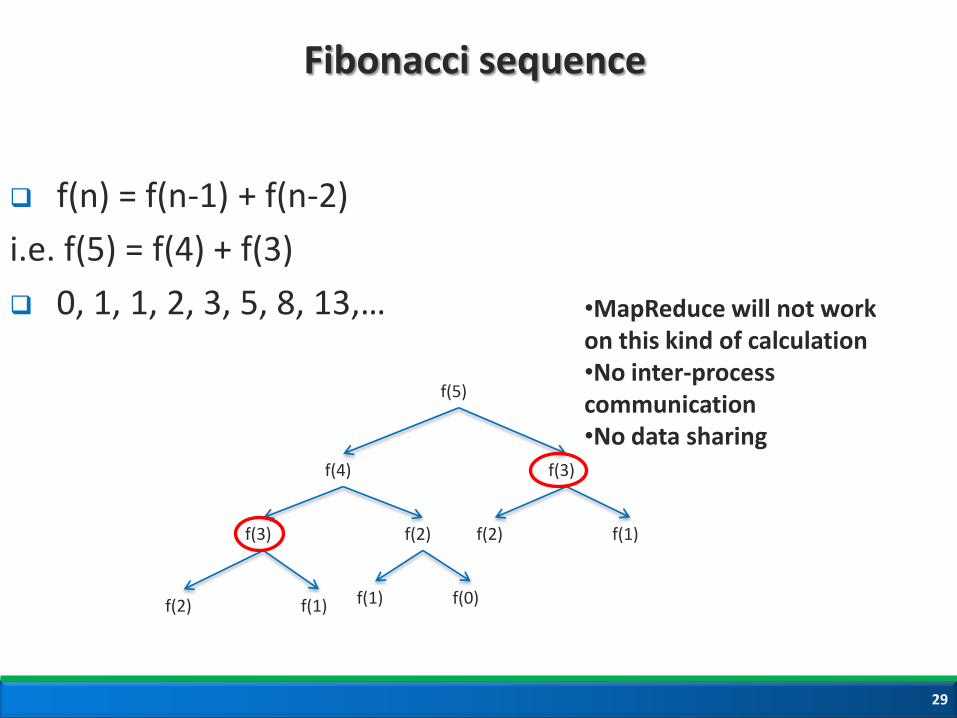
Fibonacci sequence
f(n) = f(n-1) + f(n-2)
i.e. f(5) = f(4) + f(3)
0, 1, 1, 2, 3, 5, 8, 13,…
f(5)
f(4) f(3)
f(2) f(3)
f(1) f(2)
f(2) f(1)
f(0) f(1)
•MapReduce will not work on this kind of calculation •No inter-process communication •No data sharing
29

Input: 1TB text file containing color names- Blue, Green, Yellow, Purple, Pink, Red, Maroon, Grey,
Desired output:
Occurrence of colors Blue and Green
30
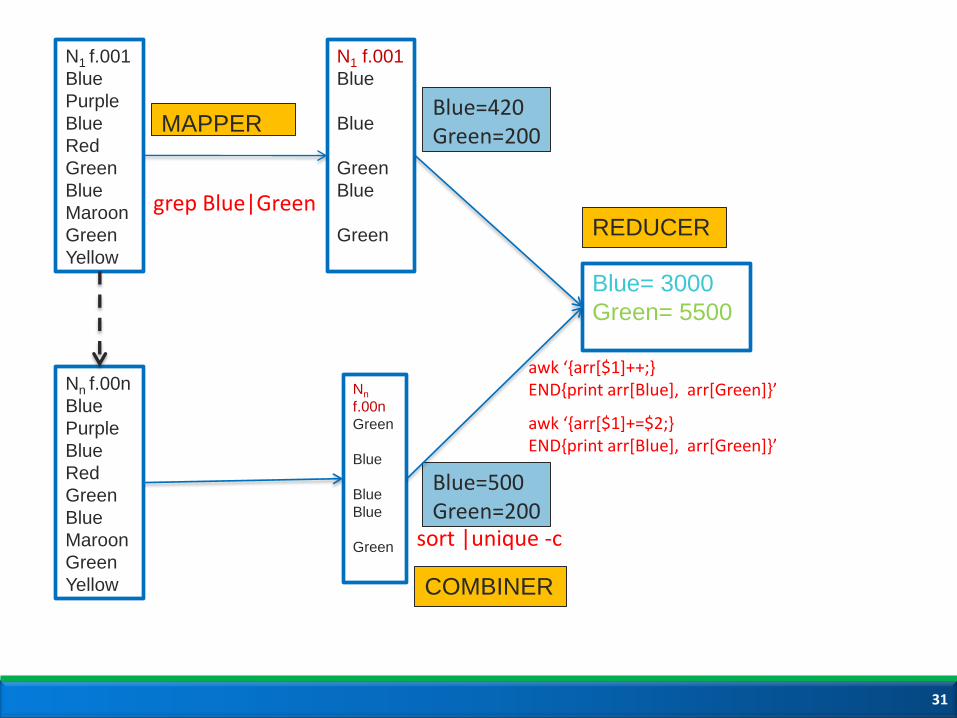
N1 f.001
Blue
Purple
Blue
Red
Green
Blue
Maroon
Green
Yellow
N1 f.001
Blue
Blue
Green
Blue
Green
grep Blue|Green
Nn
f.00n
Green
Blue
Blue
Blue
Green
Blue= 3000
Green= 5500
Blue=500 Green=200
Blue=420 Green=200
sort |unique -c
awk ‘{arr[$1]+=$2;} END{print arr[Blue], arr[Green]}’
COMBINER
MAPPER
REDUCER
awk ‘{arr[$1]++;} END{print arr[Blue], arr[Green]}’
Nn f.00n
Blue
Purple
Blue
Red
Green
Blue
Maroon
Green
Yellow
31

Input data
Map
Map
Map
Reduce
Reduce
Output
INPUT MAP SHUFFLE REDUCE OUTPUT
Works on a record
Works on output of Map
32
MapReduce Overview

Input data
Combine
Combine
Combine
Map
Map
Map
Reduce
Reduce
Output
INPUT MAP REDUCE OUTPUT
Works on output of Map Works on output of Combiner
33
MapReduce Overview

34
MapReduce Overview

Mapper, reducer and combiner act on <key, value> pairs
Mapper gets one record at a time as an input
Combiner (if present) works on output of map
Reducer works on output of map (or combiner, if present)
Combiner can be thought of local-reducer
Reduces output of maps that are executed on same node
35
MapReduce Summary

What Hadoop is not..
It is not a POSIX file system
It is not a SAN file system
It is not for interactive file accessing
It is not meant for a large number of small files- it is for a small number of large files
MapReduce cannot be used for any and all applications
36

Hadoop: Take Home
Takes computation to data
Suitable for large data centric operations
Scalable on demand
Fault tolerant and highly transparent
37

Questions?
38
Coming up next …
First hadoop program
Second hadoop program

Your first program in hadoop
Open up any tutorial on hadoop and first program you see will be of wordcount
Task: Given a text file, generate a list of words with the
number of times each of them appear in the file Input:
Plain text file Expected Output:
<word, frequency> pairs for all words in the file
hadoop is a framework written in java
hadoop supports parallel processing
and is a simple framework
<hadoop, 2>
<is, 2>
<a , 2>
<java , 1>
<framework , 2>
<written , 1>
<in , 1>
<and,1>
<supports , 1>
<parallel , 1>
<processing. , 1> <simple,1>
39

Your second program in hadoop
Task: Given a text file containing numbers, one
per line, count sum of squares of odd, even and prime
Input: File containing integers, one per line
Expected Output: <type, sum of squares> for odd, even, prime
1
2
5
3
5
6
3
7
9
4
<odd, 302>
<even, 278>
<prime, 323 >
40
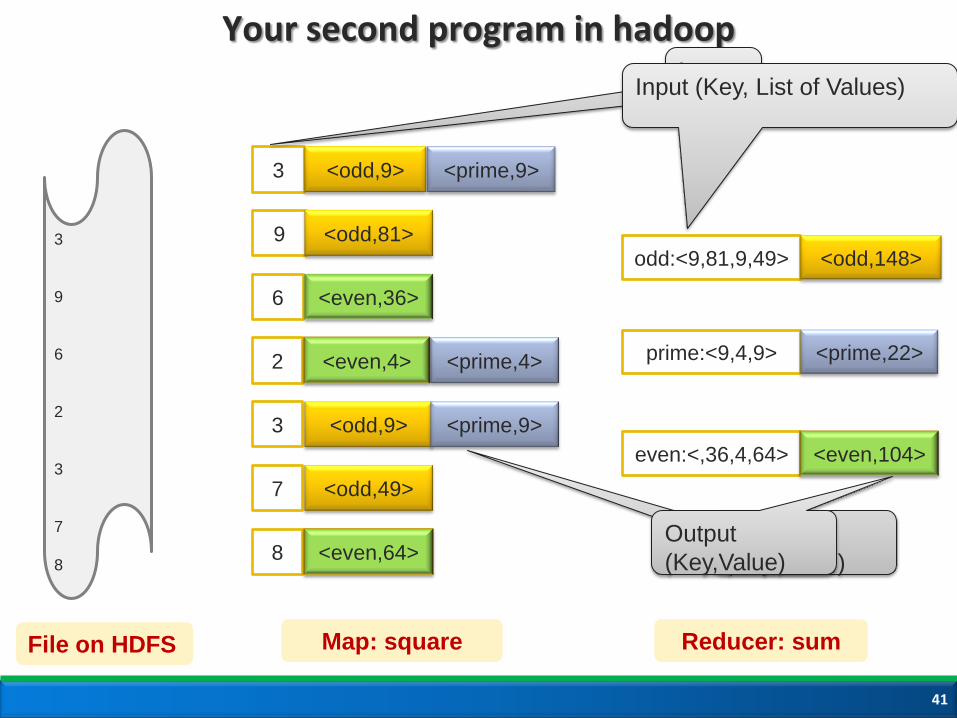
Your second program in hadoop
File on HDFS
41
3
9
6
2
3
7
8
Map: square
3 <odd,9>
7 <odd,49>
2
6 <even,36>
9 <odd,81>
3 <odd,9>
8 <even,64>
<prime,4>
<prime,9>
<prime,9>
<even,4>
Reducer: sum
prime:<9,4,9>
odd:<9,81,9,49>
even:<,36,4,64>
<odd,148>
<even,104>
<prime,22>
Input
Value
Output
(Key,Value)
Input (Key, List of Values)
Output
(Key,Value)
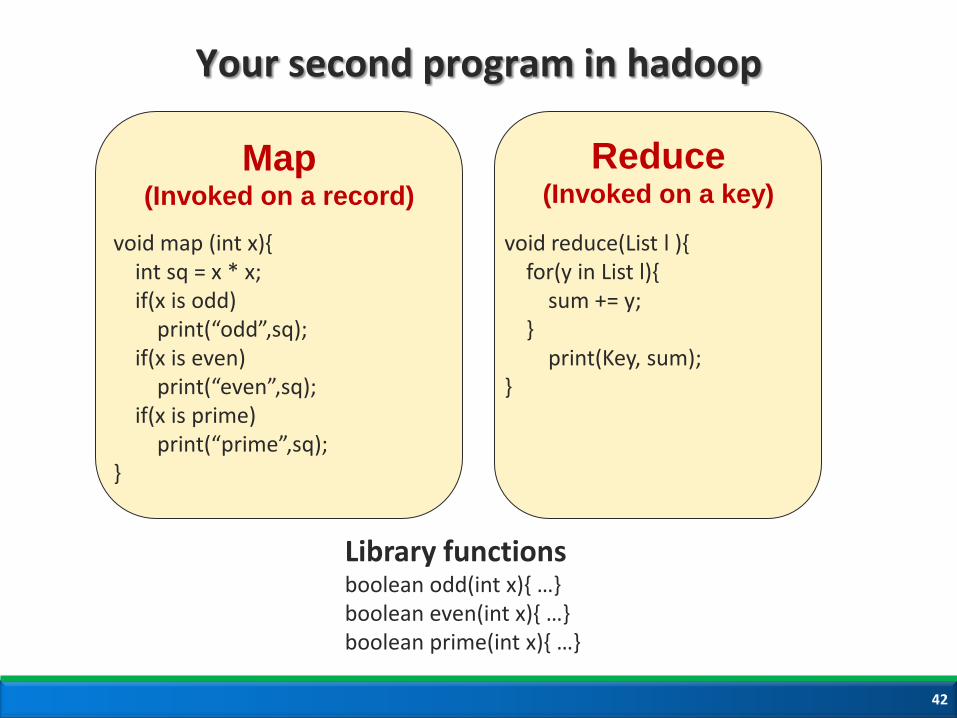
Your second program in hadoop
42
Map (Invoked on a record)
Reduce (Invoked on a key)
void map (int x){ int sq = x * x; if(x is odd) print(“odd”,sq); if(x is even) print(“even”,sq); if(x is prime) print(“prime”,sq); }
void reduce(List l ){ for(y in List l){ sum += y; } print(Key, sum); }
Library functions boolean odd(int x){ …} boolean even(int x){ …} boolean prime(int x){ …}

Your second program in hadoop
43
Map (Invoked on a record)
Map (Invoked on a record)
void map (int x){ int sq = x * x; if(x is odd) print(“odd”,sq); if(x is even) print(“even”,sq); if(x is prime) print(“prime”,sq); }

Your second program in hadoop: Reduce
44
Reduce (Invoked on a key)
Reduce (Invoked on a
key)
void reduce(List l ){ for(y in List l){ sum += y; } print(Key, sum); }

Your second program in hadoop
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, “OddEvenPrime");
job.setJarByClass(OddEvenPrime.class);
job.setMapperClass(OddEvenPrimeMapper.class);
job.setCombinerClass(OddEvenPrimeReducer.class);
job.setReducerClass(OddEvenPrimeReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
45

Questions?
46
Coming up next …
More examples
Hadoop Ecosystem

Example: Counting Fans
47

Example: Counting Fans
48
Problem: Give Crowd statistics Count fans
supporting India and Pakistan

49
45882 67917
Traditional Way
Central Processing
Every fan comes to the centre and presses India/Pak button
Issues
Slow/Bottlenecks
Only one processor
Processing time determined by the speed at which people(data) can move
Example: Counting Fans

50
Hadoop Way
Appoint processors per block (MAPPER)
Send them to each block and ask them to send a signal for each person
Central processor will aggregate the results (REDUCER)
Can make the processor smart by asking him/her to aggregate locally and only send aggregated value (COMBINER)
Example: Counting Fans
Reducer
Combiner

HomeWork : Exit Polls 2014
51
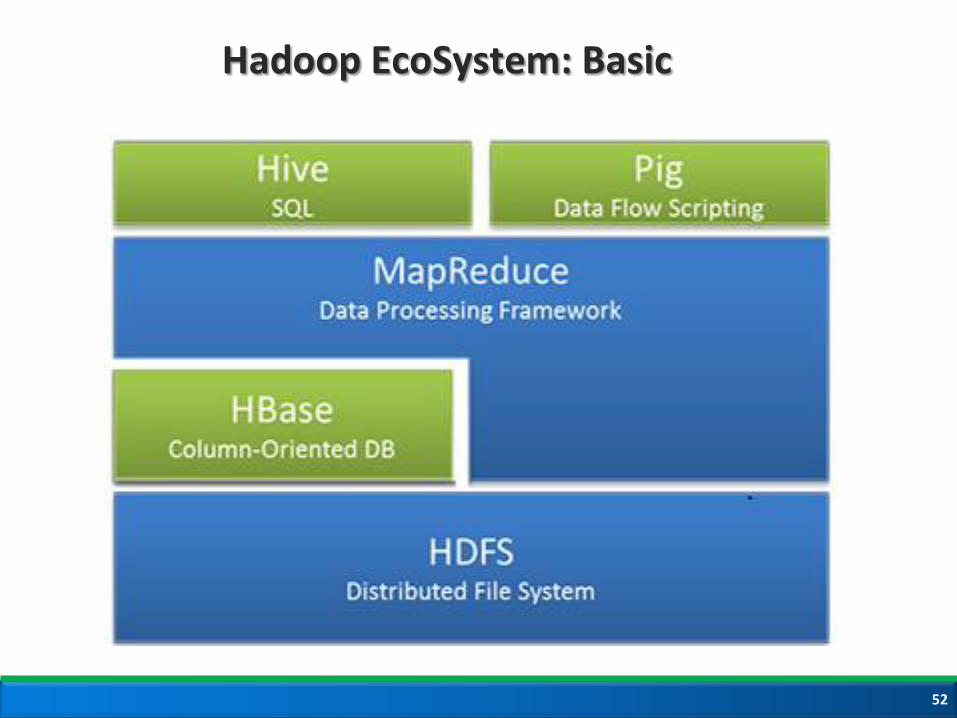
Hadoop EcoSystem: Basic
52

Hadoop Distributions
53

Who all are using Hadoop
54
http://wiki.apache.org/hadoop/PoweredBy

References
For understanding Hadoop
Official Hadoop website- http://hadoop.apache.org/
Hadoop presentation wiki- http://wiki.apache.org/hadoop/HadoopPresentations?action=AttachFile
http://developer.yahoo.com/hadoop/
http://wiki.apache.org/hadoop/
http://www.cloudera.com/hadoop-training/
http://developer.yahoo.com/hadoop/tutorial/module2.html#basics
55

References
Setup and Installation
Installing on Ubuntu
http://www.michael-noll.com/wiki/Running_Hadoop_On_Ubuntu_Linux_(Single-Node_Cluster)
http://www.michael-noll.com/wiki/Running_Hadoop_On_Ubuntu_Linux_(Multi-Node_Cluster)
Installing on Debian
http://archive.cloudera.com/docs/_apt.html
56

Hadoop: The Definitive Guide: Tom White
http://developer.yahoo.com/hadoop/tutorial/
http://www.cloudera.com/content/cloudera-content/cloudera-docs/HadoopTutorial/CDH4/Hadoop-Tutorial.html
57
Further Reading

Questions?
58

59
Acknowledgements
Surabhi Pendse
Sayali Kulkarni
Parth Shah

















