33
INTRODUCTION TO HADOOP Brest – 29 octobre 2014 David Morin - @davAtBzh
| Date post: | 27-Jul-2015 |
| Category: |
Technology |
| Upload: | david-morin |
| View: | 1,421 times |
| Download: | 0 times |

INTRODUCTION TO HADOOP
Brest – 29 octobre 2014David Morin - @davAtBzh

Me
Solutions Engineer at
@davAtBzhDavid Morin

3
What is Hadoop ?

4
An elephant – This one ?

5
No, this one !

6
The father

7
Let's go !

8
Let's go !

9
Timeline

10
Hadoop fundamentals
● Distributed FileSystem for high volume of data● Use of common servers (limit costs)● Scalable / fault tolerance

11
Hadoop Distributed FileSystem

12
Hadoop Distributed FileSystem

13
Mapreduce

14
Mapreduce : word count
Map Reduce

15
Data Locality Optimization

16
Mapreduce in action

17
Hadoop v1 : drawbacks
– One Namenode : SPOF – One Jobtracker : SPOF and un-scalable (nodes
limitation)– MapReduce only : open this platform to non MR
applications

18
Hadoop v2
Improvements :– HDFS v2 : Secondary namenode– YARN (Yet Another Resource Negociator)
● JobTracker => Resource Manager + Applications Master (more than one)
● Can be used by non MapReduce applications– MapReduce v2 : uses Yarn

19
Hadoop v2

20
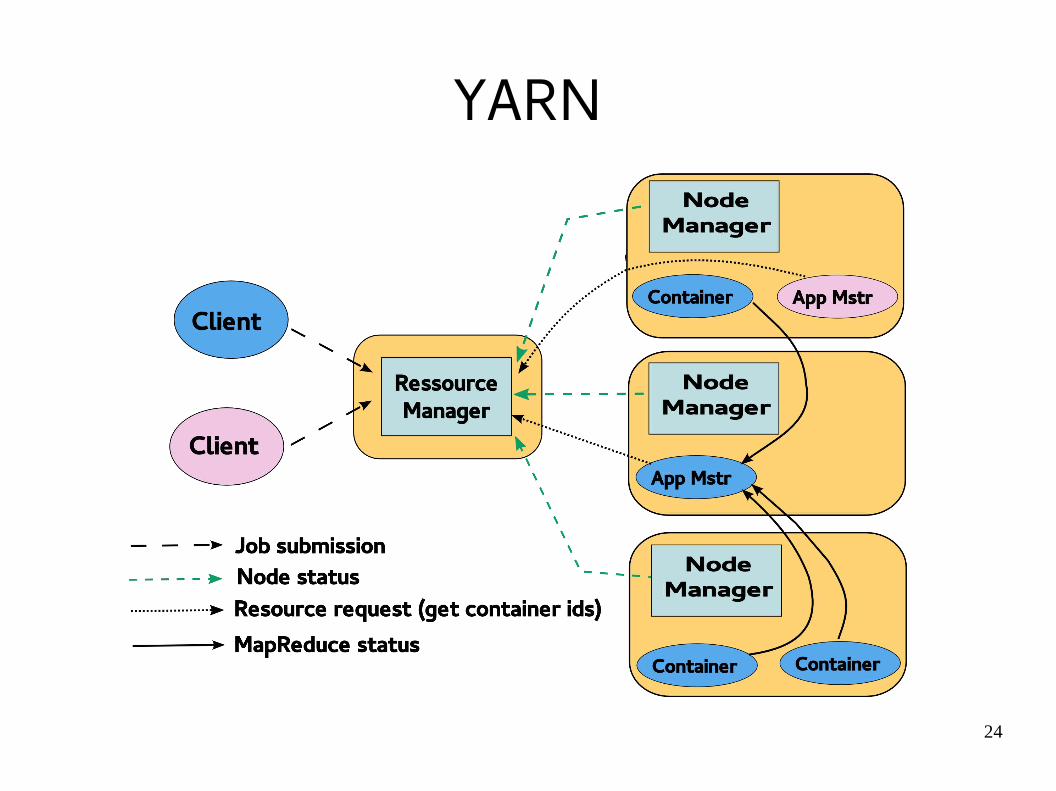
YARN

21
YARN

22
YARN

23
YARN
24
YARN

25
YARN

26

27
Pig
● With Pig write MR Jobs becomes easy● Dataflow model : data is the key !● Langage : PigLatin● No limit : Used Defined Functions
http://pig.apache.org/docs/r0.13.0/

28
● Pig-Wordcount
lines = LOAD '/user/XXX/file.txt' AS (line:chararray);words = FOREACH lines GENERATE FLATTEN(TOKENIZE(line)) AS word;grouped = GROUP words BY word;wordcount = FOREACH grouped GENERATE group, COUNT(words);DUMP wordcount;
Pig

29
=> 130 lines of code !
Import …
public class WordCount2 {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{
static enum CountersEnum { INPUT_WORDS }
private final static IntWritable one = new IntWritable(1); private Text word = new Text();
private boolean caseSensitive; private Set<String> patternsToSkip = new HashSet<String>();
private Configuration conf; private BufferedReader fis;
...
Pig

30
● Hive-Wordcount
CREATE TABLE docs (line STRING);LOAD DATA INPATH 'text' OVERWRITE INTO TABLE docs;CREATE TABLE word_counts ASSELECT word, count(1) AS count FROM(SELECT explode(split(line, '\s')) AS word FROM docs) wGROUP BY wordORDER BY word;
● SQL like : HQL● UDFs
Hive

31
Zookeeper
● Distributed coordination service● Dynamic configuration● Distributed locking

32
Batch but not only..

33
??

















