62
INTRODUCTION TO HEURISTIC SEARCH

INTRODUCTION TO
HEURISTIC SEARCH

What is heuristic search?
Given a problem in which we must make a series of
decisions, determine the sequence of decisions which
provably optimizes some criterion.

What is NOT heuristic search?
Any algorithm which cannot produce a provably
correct (globally optimal) solution
Greedy hill climbing
Simulated annealing
Genetic algorithms
Gradient descent
EM
...

Overview
Basics
Brute force search
Depth-first search
Breadth-first search
Heuristic search
Heuristic function
Best-first search (A*)
Other details
Conclusions

What is a state space search problem?
State: a node in a graph
Start state: where we begin our search
Goal state(s): where we want to go
Operators: how we move from one node to the next
Typical problem: What is the minimum cost sequence of operators to move from start to a goal? What is the shortest path from start to a goal?
Common variant: does there exist a path from the start to any goal?
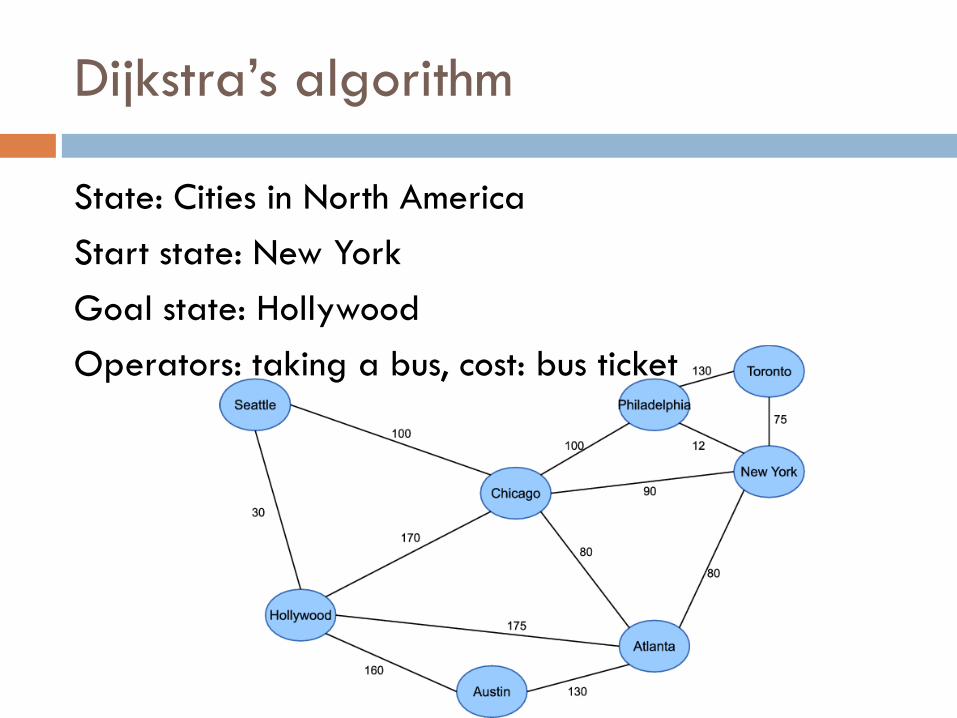
Dijkstra’s algorithm
State: Cities in North America
Start state: New York
Goal state: Hollywood
Operators: taking a bus, cost: bus ticket
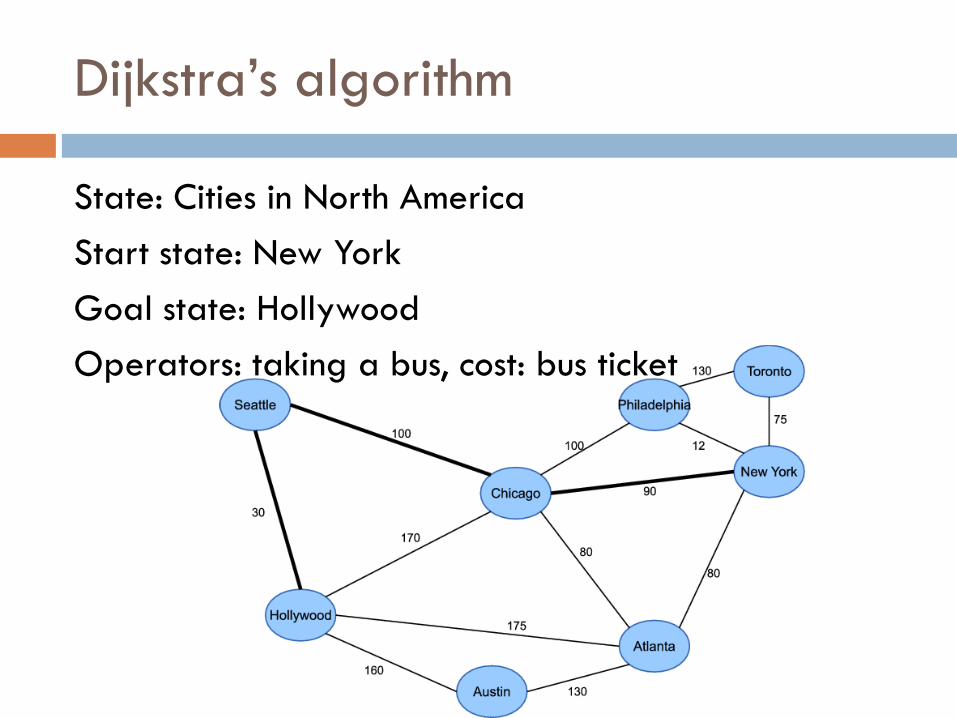
Dijkstra’s algorithm
State: Cities in North America
Start state: New York
Goal state: Hollywood
Operators: taking a bus, cost: bus ticket
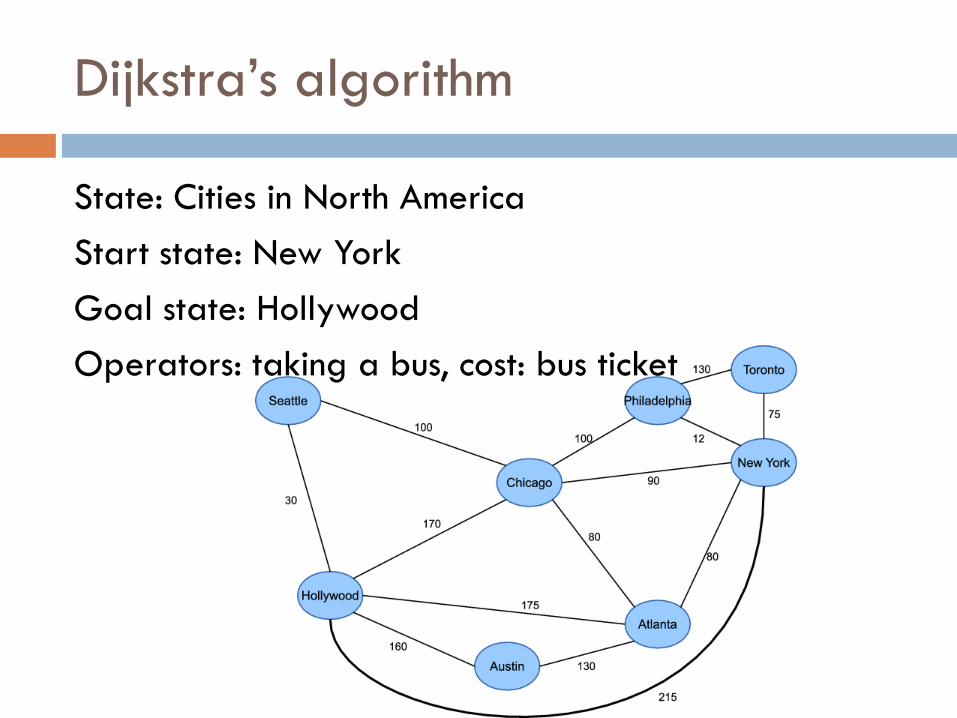
Dijkstra’s algorithm
State: Cities in North America
Start state: New York
Goal state: Hollywood
Operators: taking a bus, cost: bus ticket
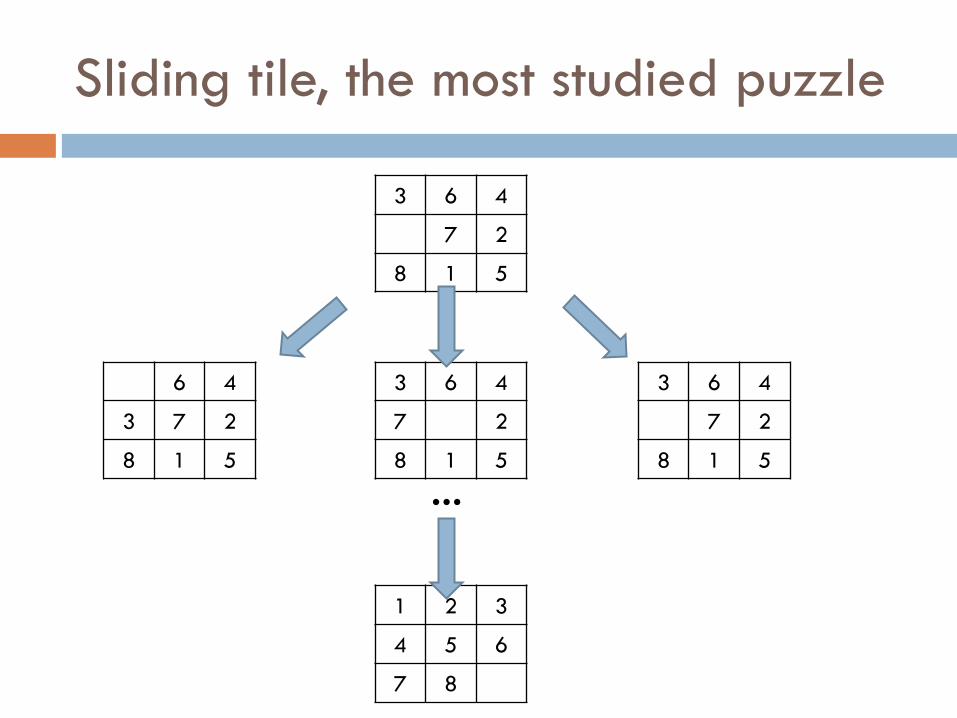
Sliding tile, the most studied puzzle
3 6 4
7 2
8 1 5
3 6 4
7 2
8 1 5
3 6 4
7 2
8 1 5
6 4
3 7 2
8 1 5
1 2 3
4 5 6
7 8
...

What is an implicit state space?
Observation: some state spaces are huge
Problem: we cannot store all nodes
Solution: define start and goals, but implicitly define all other states via operators
Operator moveBlankRight(state)
copy(state, newState)
updateCol(newState, blank, col(state, blank)+1)
updateCol(newState, toRight(state, blank), col(state, blank))

Standard terminology
Expand. apply operators to a state (aka, node)
Generate. create a state by expanding an existing one
Successor. state created when expanding a node
Duplicate. generate a state more than once
OPEN. a sorted ”list” of nodes which have been
generated but not expanded
CLOSED. a ”list” of nodes which have been expanded

Standard notation: successors
distance from start to node n’
(known) distance from start to predecessor n
cost to move from node n to successor n’

Another simple problem
State: a subset of {X0, X1, ..., Xn}
Start state: {}
Goal state: {X0, X1, ..., Xn}
Operators: Add one new Xi, c(n, n’) is given as input

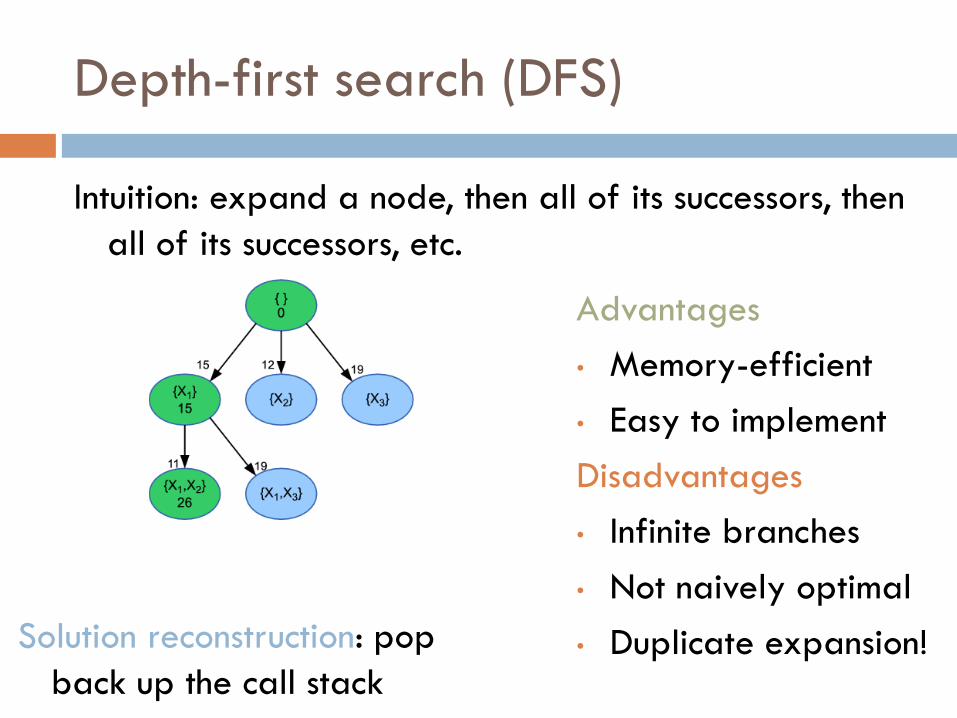
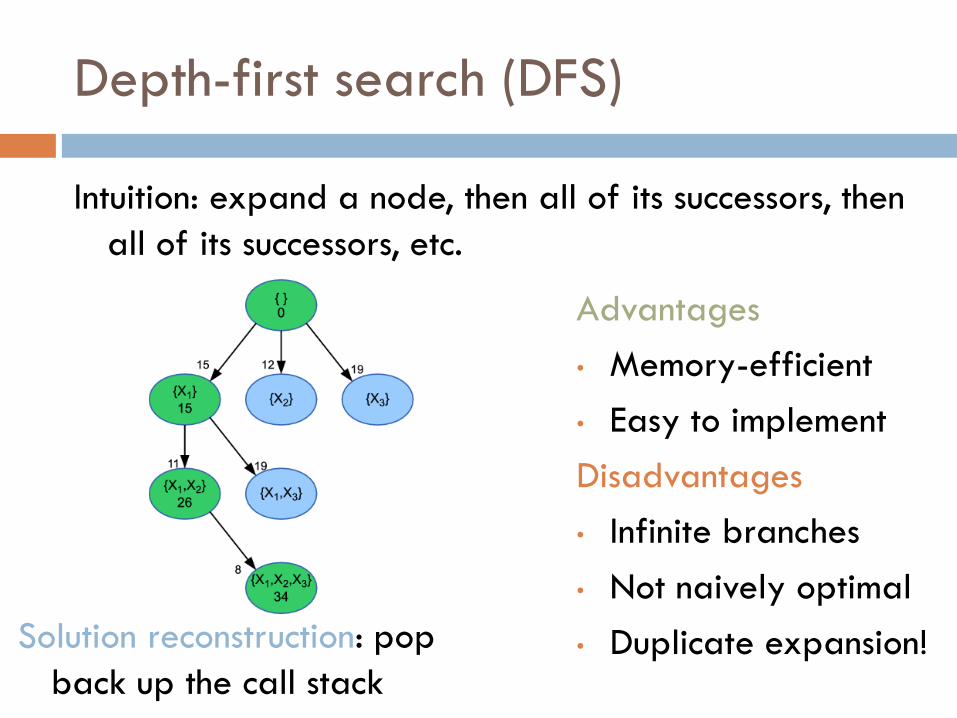
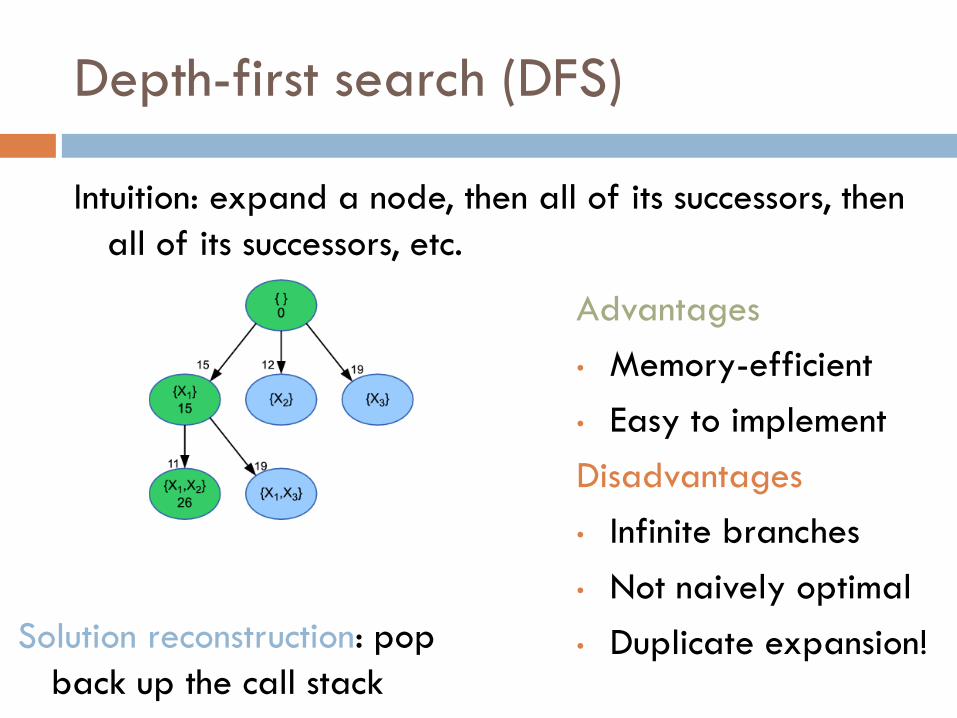
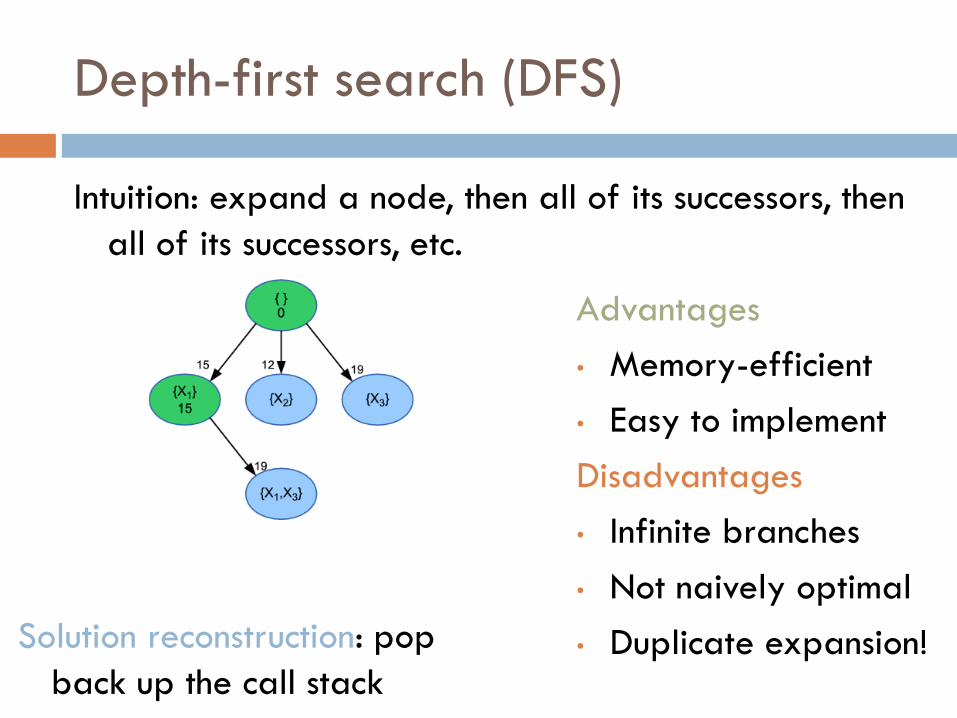
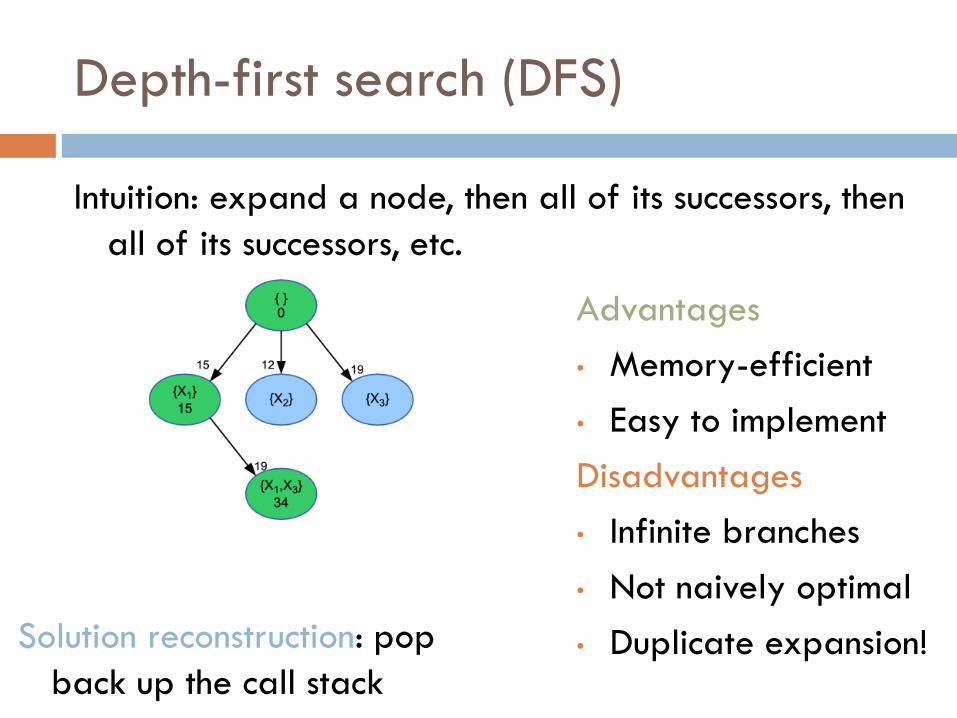
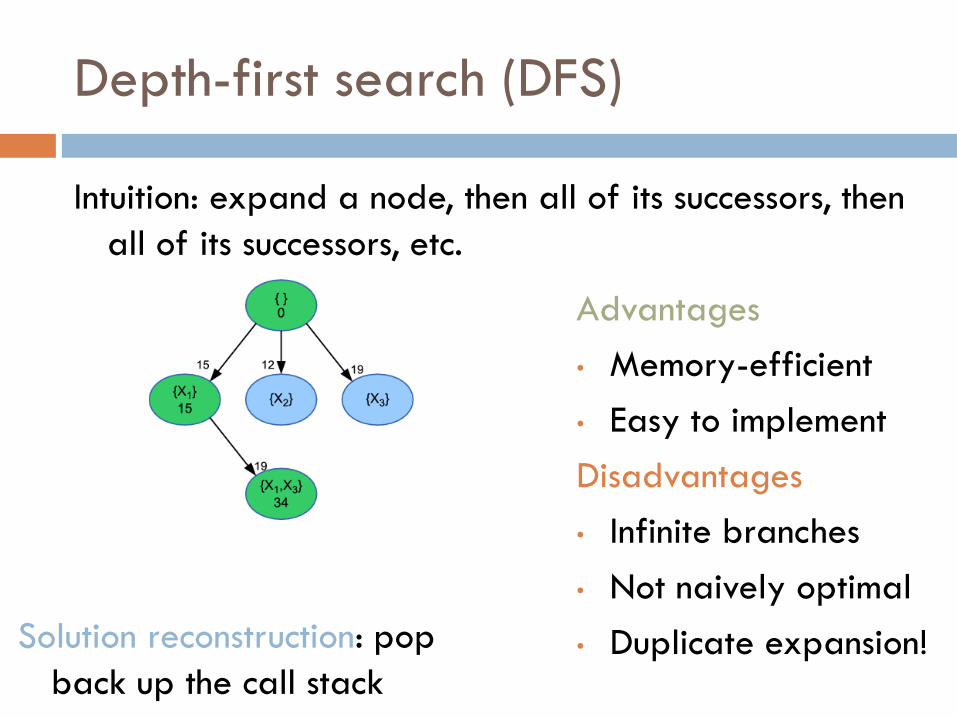
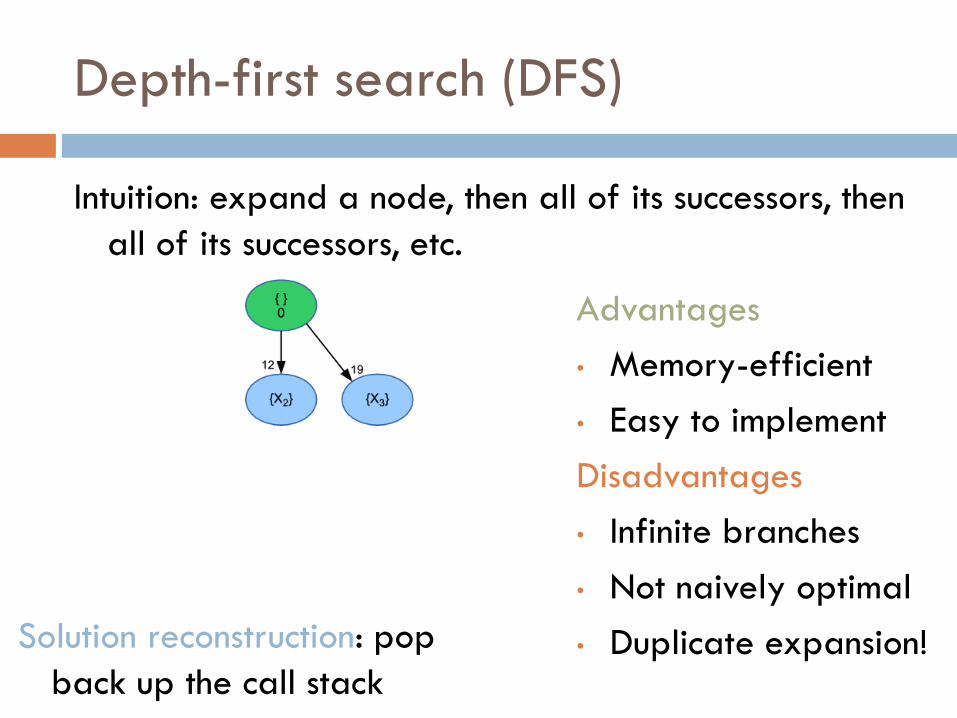
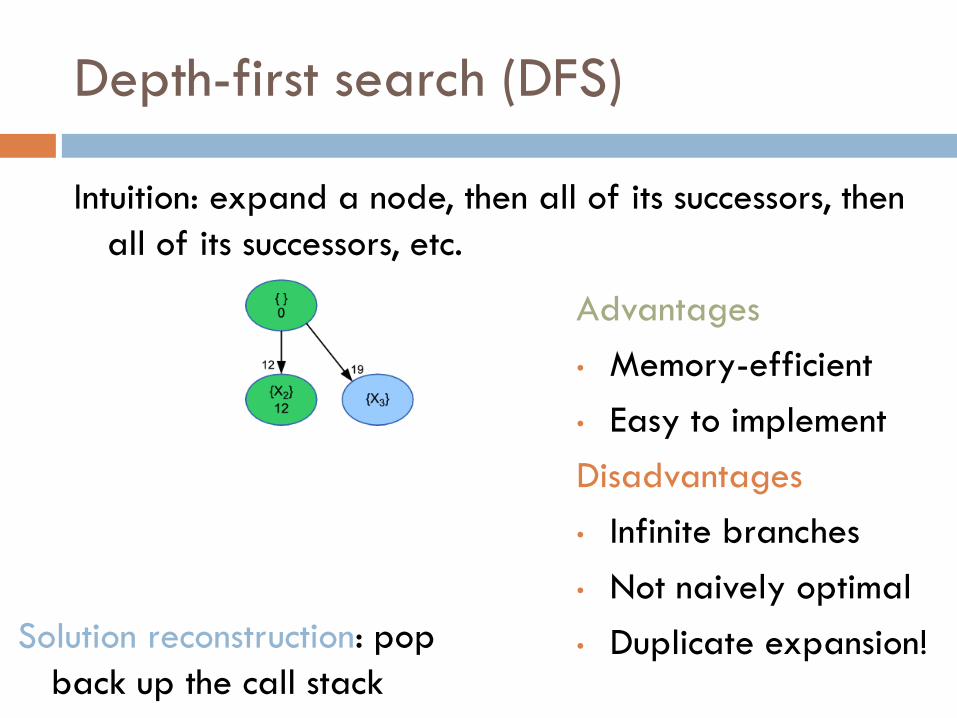
Depth-first search (DFS)
Intuition: expand a node, then all of its successors, then
all of its successors, etc.
Advantages
• Memory-efficient
• Easy to implement
Disadvantages
• Infinite branches
• Not naively optimal
• Duplicate expansion! Solution reconstruction: pop
back up the call stack

Depth-first search (DFS)
Intuition: expand a node, then all of its successors, then
all of its successors, etc.
Advantages
• Memory-efficient
• Easy to implement
Disadvantages
• Infinite branches
• Not naively optimal
• Duplicate expansion! Solution reconstruction: pop
back up the call stack

Depth-first search (DFS)
Intuition: expand a node, then all of its successors, then
all of its successors, etc.
Advantages
• Memory-efficient
• Easy to implement
Disadvantages
• Infinite branches
• Not naively optimal
• Duplicate expansion! Solution reconstruction: pop
back up the call stack

Depth-first search (DFS)
Intuition: expand a node, then all of its successors, then
all of its successors, etc.
Advantages
• Memory-efficient
• Easy to implement
Disadvantages
• Infinite branches
• Not naively optimal
• Duplicate expansion! Solution reconstruction: pop
back up the call stack

Depth-first search (DFS)
Intuition: expand a node, then all of its successors, then
all of its successors, etc.
Advantages
• Memory-efficient
• Easy to implement
Disadvantages
• Infinite branches
• Not naively optimal
• Duplicate expansion! Solution reconstruction: pop
back up the call stack
Depth-first search (DFS)
Intuition: expand a node, then all of its successors, then
all of its successors, etc.
Advantages
• Memory-efficient
• Easy to implement
Disadvantages
• Infinite branches
• Not naively optimal
• Duplicate expansion! Solution reconstruction: pop
back up the call stack

Depth-first search (DFS)
Intuition: expand a node, then all of its successors, then
all of its successors, etc.
Advantages
• Memory-efficient
• Easy to implement
Disadvantages
• Infinite branches
• Not naively optimal
• Duplicate expansion! Solution reconstruction: pop
back up the call stack
Depth-first search (DFS)
Intuition: expand a node, then all of its successors, then
all of its successors, etc.
Advantages
• Memory-efficient
• Easy to implement
Disadvantages
• Infinite branches
• Not naively optimal
• Duplicate expansion! Solution reconstruction: pop
back up the call stack
Depth-first search (DFS)
Intuition: expand a node, then all of its successors, then
all of its successors, etc.
Advantages
• Memory-efficient
• Easy to implement
Disadvantages
• Infinite branches
• Not naively optimal
• Duplicate expansion! Solution reconstruction: pop
back up the call stack
Depth-first search (DFS)
Intuition: expand a node, then all of its successors, then
all of its successors, etc.
Advantages
• Memory-efficient
• Easy to implement
Disadvantages
• Infinite branches
• Not naively optimal
• Duplicate expansion! Solution reconstruction: pop
back up the call stack
Depth-first search (DFS)
Intuition: expand a node, then all of its successors, then
all of its successors, etc.
Advantages
• Memory-efficient
• Easy to implement
Disadvantages
• Infinite branches
• Not naively optimal
• Duplicate expansion! Solution reconstruction: pop
back up the call stack

Depth-first search (DFS)
Intuition: expand a node, then all of its successors, then
all of its successors, etc.
Advantages
• Memory-efficient
• Easy to implement
Disadvantages
• Infinite branches
• Not naively optimal
• Duplicate expansion! Solution reconstruction: pop
back up the call stack

Depth-first search (DFS)
Intuition: expand a node, then all of its successors, then
all of its successors, etc.
Advantages
• Memory-efficient
• Easy to implement
Disadvantages
• Infinite branches
• Not naively optimal
• Duplicate expansion! Solution reconstruction: pop
back up the call stack
Depth-first search (DFS)
Intuition: expand a node, then all of its successors, then
all of its successors, etc.
Advantages
• Memory-efficient
• Easy to implement
Disadvantages
• Infinite branches
• Not naively optimal
• Duplicate expansion! Solution reconstruction: pop
back up the call stack

Depth-first search (DFS)
Intuition: expand a node, then all of its successors, then
all of its successors, etc.
Advantages
• Memory-efficient
• Easy to implement
Disadvantages
• Infinite branches
• Not naively optimal
• Duplicate expansion! Solution reconstruction: pop
back up the call stack
Depth-first search (DFS)
Intuition: expand a node, then all of its successors, then
all of its successors, etc.
Advantages
• Memory-efficient
• Easy to implement
Disadvantages
• Infinite branches
• Not naively optimal
• Duplicate expansion! Solution reconstruction: pop
back up the call stack
Depth-first search (DFS)
Intuition: expand a node, then all of its successors, then
all of its successors, etc.
Advantages
• Memory-efficient
• Easy to implement
Disadvantages
• Infinite branches
• Not naively optimal
• Duplicate expansion! Solution reconstruction: pop
back up the call stack

Depth-first search (DFS)
Intuition: expand a node, then all of its successors, then
all of its successors, etc.
Advantages
• Memory-efficient
• Easy to implement
Disadvantages
• Infinite branches
• Not naively optimal
• Duplicate expansion! Solution reconstruction: pop
back up the call stack

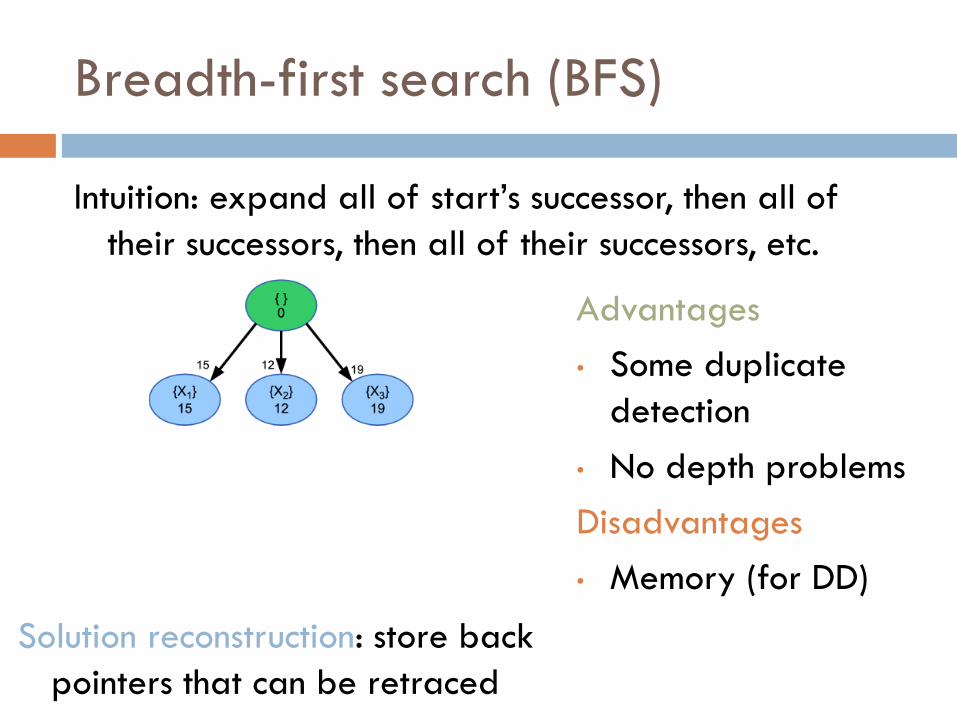
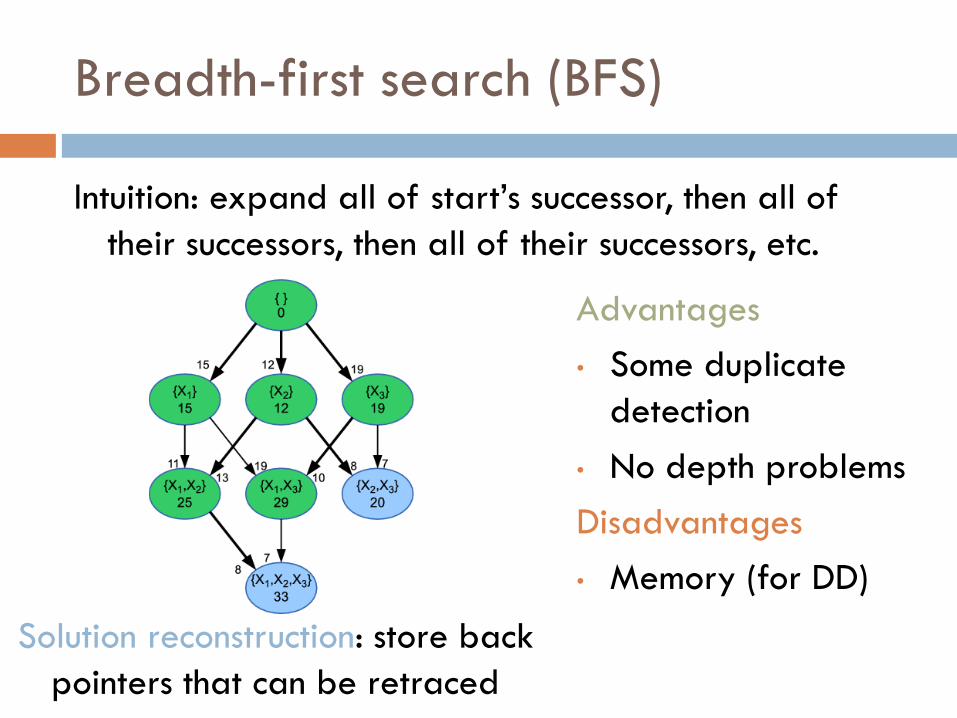
Breadth-first search (BFS)
Intuition: expand all of start’s successor, then all of
their successors, then all of their successors, etc.
Advantages
• Some duplicate
detection
• No depth problems
Disadvantages
• Memory (for DD)
Solution reconstruction: store back
pointers that can be retraced

Breadth-first search (BFS)
Intuition: expand all of start’s successor, then all of
their successors, then all of their successors, etc.
Advantages
• Some duplicate
detection
• No depth problems
Disadvantages
• Memory (for DD)
Solution reconstruction: store back
pointers that can be retraced
Breadth-first search (BFS)
Intuition: expand all of start’s successor, then all of
their successors, then all of their successors, etc.
Advantages
• Some duplicate
detection
• No depth problems
Disadvantages
• Memory (for DD)
Solution reconstruction: store back
pointers that can be retraced

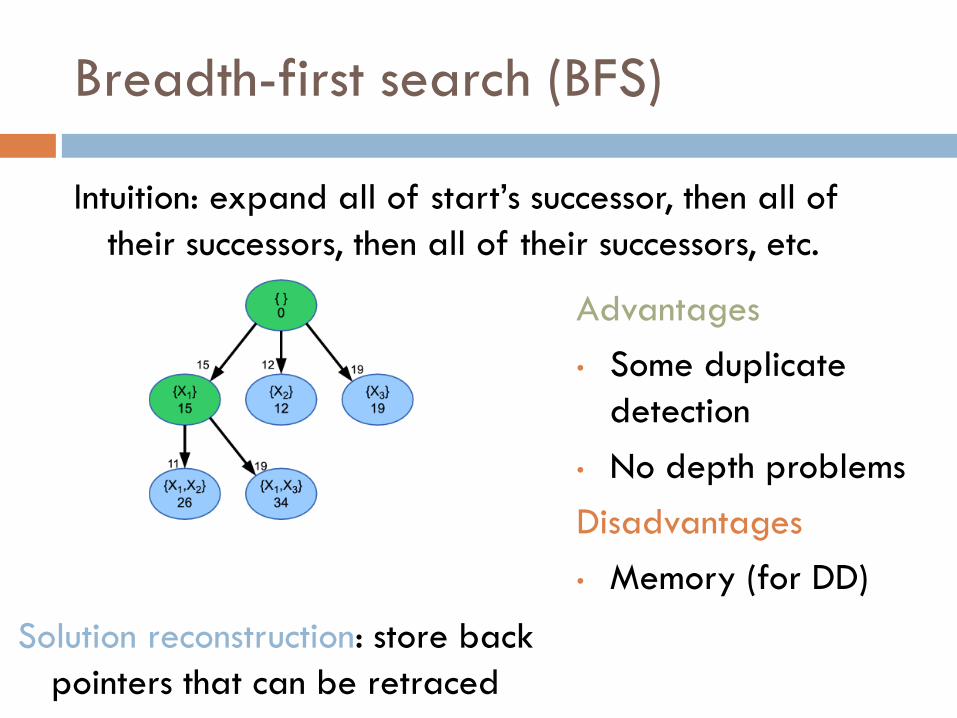
Breadth-first search (BFS)
Intuition: expand all of start’s successor, then all of
their successors, then all of their successors, etc.
Advantages
• Some duplicate
detection
• No depth problems
Disadvantages
• Memory (for DD)
Solution reconstruction: store back
pointers that can be retraced
Breadth-first search (BFS)
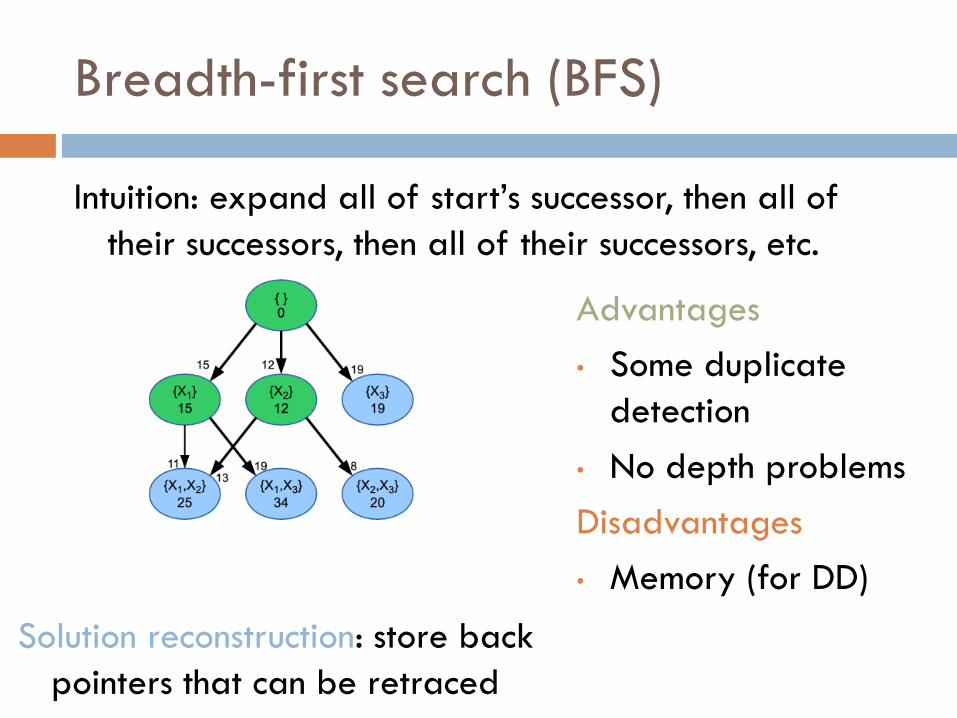
Intuition: expand all of start’s successor, then all of
their successors, then all of their successors, etc.
Advantages
• Some duplicate
detection
• No depth problems
Disadvantages
• Memory (for DD)
Solution reconstruction: store back
pointers that can be retraced
Breadth-first search (BFS)
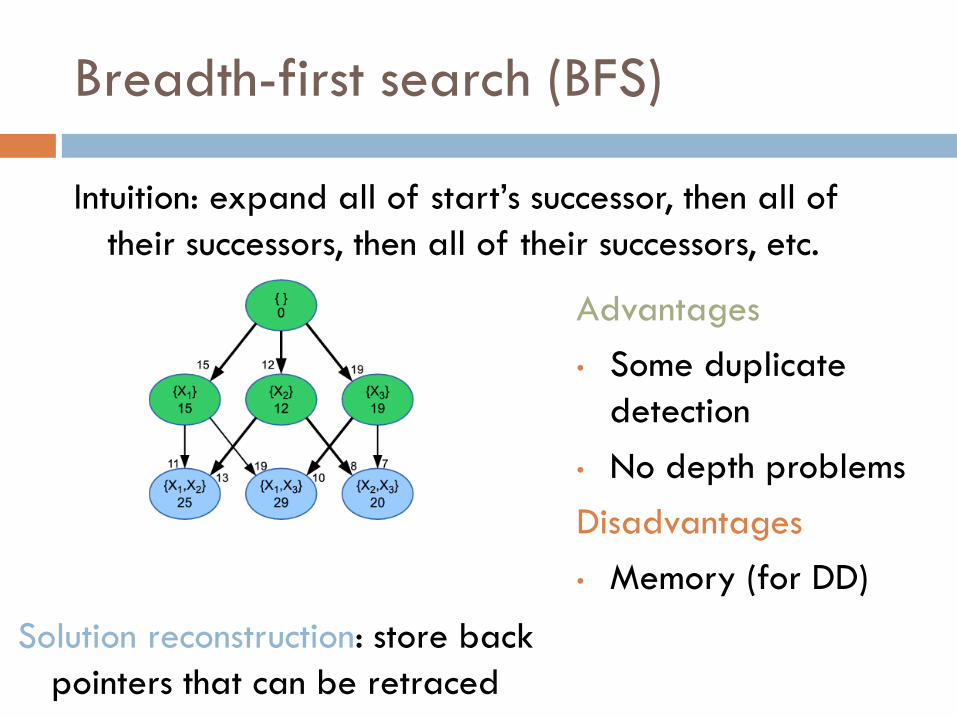
Intuition: expand all of start’s successor, then all of
their successors, then all of their successors, etc.
Advantages
• Some duplicate
detection
• No depth problems
Disadvantages
• Memory (for DD)
Solution reconstruction: store back
pointers that can be retraced
Breadth-first search (BFS)
Intuition: expand all of start’s successor, then all of
their successors, then all of their successors, etc.
Advantages
• Some duplicate
detection
• No depth problems
Disadvantages
• Memory (for DD)
Solution reconstruction: store back
pointers that can be retraced

Breadth-first search (BFS)
Intuition: expand all of start’s successor, then all of
their successors, then all of their successors, etc.
Advantages
• Some duplicate
detection
• No depth problems
Disadvantages
• Memory (for DD)
Solution reconstruction: store back
pointers that can be retraced
Breadth-first search (BFS)
Intuition: expand all of start’s successor, then all of
their successors, then all of their successors, etc.
Advantages
• Some duplicate
detection
• No depth problems
Disadvantages
• Memory (for DD)
Solution reconstruction: store back
pointers that can be retraced

Breadth-first search (BFS)
Intuition: expand all of start’s successor, then all of
their successors, then all of their successors, etc.
Advantages
• Some duplicate
detection
• No depth problems
Disadvantages
• Memory (for DD)
Solution reconstruction: store back
pointers that can be retraced

Breadth-first search (BFS)
Intuition: expand all of start’s successor, then all of
their successors, then all of their successors, etc.
Advantages
• Some duplicate
detection
• No depth problems
Disadvantages
• Memory (for DD)
Solution reconstruction: store back
pointers that can be retraced
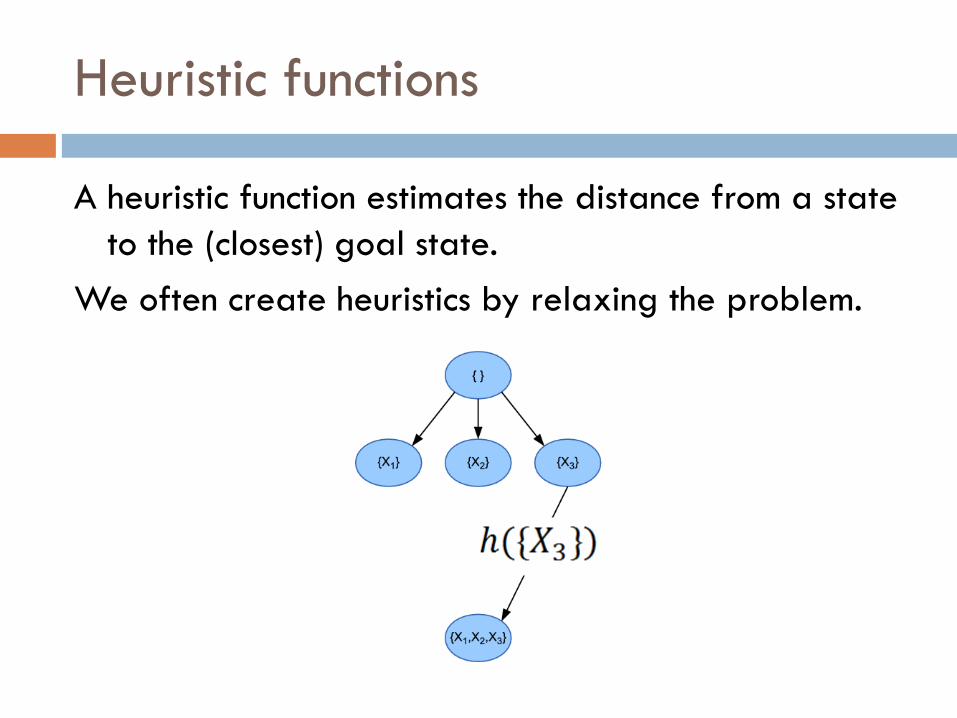
Heuristic functions
A heuristic function estimates the distance from a state
to the (closest) goal state.
We often create heuristics by relaxing the problem.
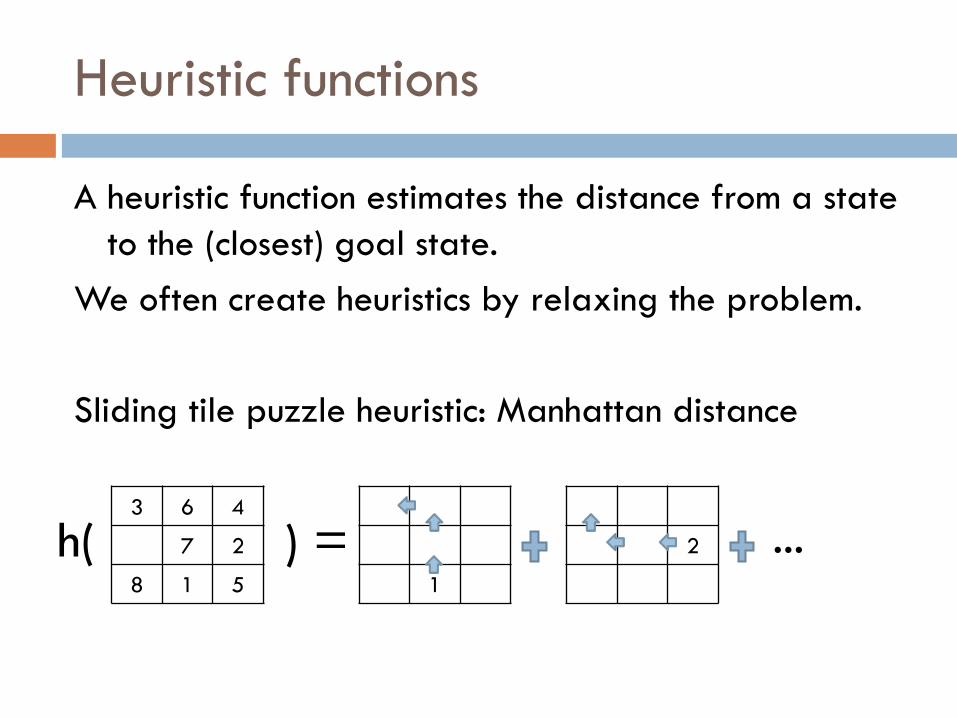
Heuristic functions
A heuristic function estimates the distance from a state
to the (closest) goal state.
We often create heuristics by relaxing the problem.
Sliding tile puzzle heuristic: Manhattan distance
3 6 4
7 2
8 1 5 1
2 ... h( ) =

Standard notation: node priority
(known) distance from start to n
heuristic estimate of the distance
from n to goal
estimate of the cost of a path
from start to goal through n

Admissible heuristic functions
An admissible heuristic function always underestimates
the distance from a state to the goal.
They are sometimes called optimistic.
Theorem: The Manhattan distance heuristic function is
admissible for the sliding tile puzzle.

Consistent heuristic functions
A consistent heuristic function is admissible and
satisfies that .
They are sometimes called monotonic because f costs
cannot decrease on a path from start to goal.

Depth-first branch and bound (DFBnB)
Intuition: perform DFS, but calculate f(n) for each
node. If f(n) is worse than some bound, prune.
Advantages (over DFS): ignores parts of the search
space worse than current known solution
We have found a solution with cost 34.

Depth-first branch and bound (DFBnB)
Intuition: perform DFS, but calculate f(n) for each
node. If f(n) is worse than some bound, prune.
Advantages (over DFS): ignores parts of the search
space worse than current known solution
We have found a solution with cost 34.
We continue to search.

Depth-first branch and bound (DFBnB)
Intuition: perform DFS, but calculate f(n) for each
node. If f(n) is worse than some bound, prune.
Advantages (over DFS): ignores parts of the search
space worse than current known solution
We have found a solution with cost 34.
We continue to search.
The lower bound of the node is 34.

Depth-first branch and bound (DFBnB)
Intuition: perform DFS, but calculate f(n) for each
node. If f(n) is worse than some bound, prune.
Advantages (over DFS): ignores parts of the search
space worse than current known solution
We have found a solution with cost 34.
We continue to search.
The lower bound of the node is 34.
Since it cannot be optimal, prune.

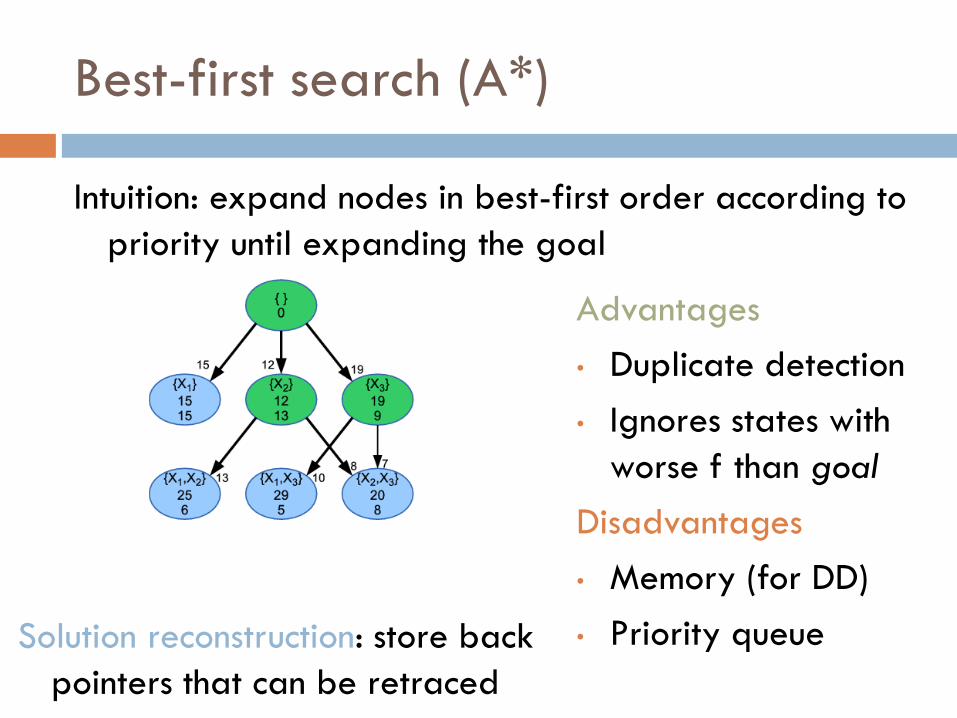
Best-first search (A*)
Intuition: expand nodes in best-first order according to
priority until expanding the goal
Advantages
• Duplicate detection
• Ignores states with
worse f than goal
Disadvantages
• Memory (for DD)
• Priority queue Solution reconstruction: store back
pointers that can be retraced

Best-first search (A*)
Intuition: expand nodes in best-first order according to
priority until expanding the goal
Advantages
• Duplicate detection
• Ignores states with
worse f than goal
Disadvantages
• Memory (for DD)
• Priority queue Solution reconstruction: store back
pointers that can be retraced

Best-first search (A*)
Intuition: expand nodes in best-first order according to
priority until expanding the goal
Advantages
• Duplicate detection
• Ignores states with
worse f than goal
Disadvantages
• Memory (for DD)
• Priority queue Solution reconstruction: store back
pointers that can be retraced

Best-first search (A*)
Intuition: expand nodes in best-first order according to
priority until expanding the goal
Advantages
• Duplicate detection
• Ignores states with
worse f than goal
Disadvantages
• Memory (for DD)
• Priority queue Solution reconstruction: store back
pointers that can be retraced
Best-first search (A*)
Intuition: expand nodes in best-first order according to
priority until expanding the goal
Advantages
• Duplicate detection
• Ignores states with
worse f than goal
Disadvantages
• Memory (for DD)
• Priority queue Solution reconstruction: store back
pointers that can be retraced
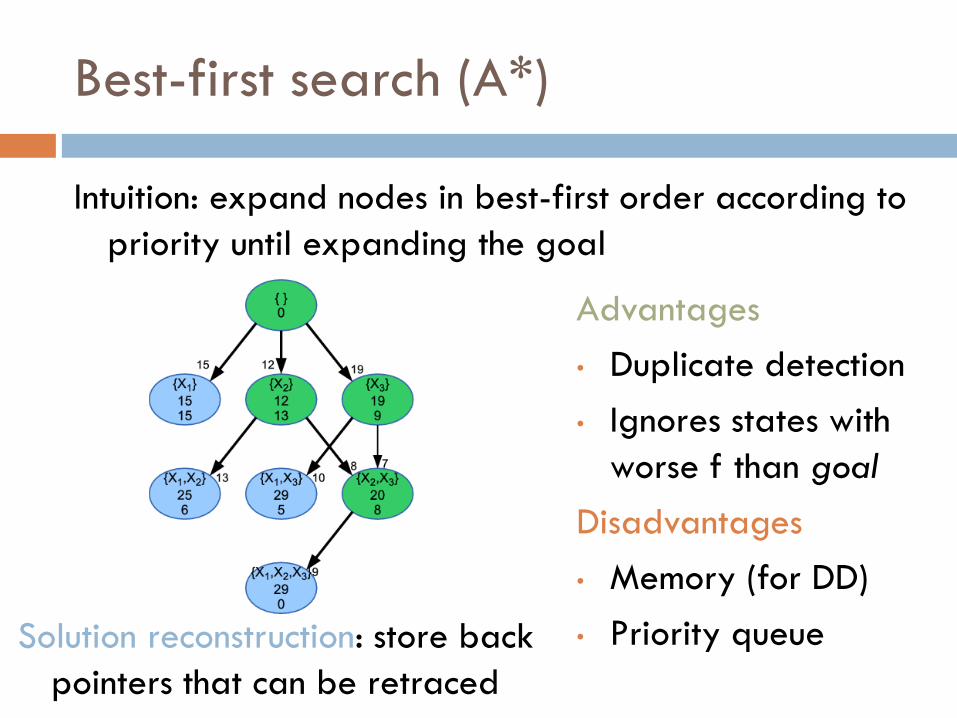
Best-first search (A*)
Intuition: expand nodes in best-first order according to
priority until expanding the goal
Advantages
• Duplicate detection
• Ignores states with
worse f than goal
Disadvantages
• Memory (for DD)
• Priority queue Solution reconstruction: store back
pointers that can be retraced

Best-first search (A*)
Intuition: expand nodes in best-first order according to
priority until expanding the goal
Advantages
• Duplicate detection
• Ignores states with
worse f than goal
Disadvantages
• Memory (for DD)
• Priority queue Solution reconstruction: store back
pointers that can be retraced

A* Theoretical properties
Given an admissible heuristic h...
Upon selecting goal for expansion, the shortest path
has been found.
Given h, no state space search strategy can prove
optimality and expand fewer nodes than A*.
If h is also consistent, no intermediate node will be
re-expanded.

Terminology and data structures
The function of the OPEN ”list” is to determine the
next node to expand.
DFS: stack
BFS: queue (naively) or hash table
A*: priority queue (can also require hash table)
The function of the CLOSED ”list” is to detect nodes
that have already been generated.
BFS: hash table, possibly one layer at a time
A*: hash table

Other search problems
Constraint-satisfaction problems
We specify conditions that goal must satisfy, but there
could be some parts of the state we do not care about.
Games against nature
Operators are not deterministic. Under typical
assumptions, these are called Markov decision processes.
Multi-player games
Other agents apply operators which we cannot control.

Conclusions
Heuristic search algorithms use a heuristic function to guide a search from a start state to a goal state.
A variety of search strategies can leverage the heuristic function in different ways.
Depth-first
Breadth-first
Best-first (A*)
A* has several important theoretical properties.

















