20
IR Theory: Web Information Retrieval
| Date post: | 07-Jun-2018 |
| Category: |
Documents |
| Upload: | truongkhuong |
| View: | 218 times |
| Download: | 0 times |

IR Theory: Web Information Retrieval
Web IR Fusion IR
Search Engine 2

Evolution of IR: Phase I
Brute-force Search • User Raw Data
Library • Collection Development
Quality Control Classification Controlled Vocabulary Bibliographical Records
• Browsing User Organized/Filtered Data
• Searching User Intermediary Metadata Organized/Filtered Data
Search Engine 3

Evolution of IR: Phase II
IR System • Automatic Indexing • Pattern Matching • User Computer Inverted Index Raw Data • Move from metadata to content-based search
IR Research • Goal
Rank the documents by their relevance to a given query • Approach
Query-Document Similarity Term-Weights based on term occurrence statistics
• Query Document Term Index Ranked list of matches • Controlled and restricted experiments
with small, homogeneous, and high quality data
Search Engine 4

Evolution of IR: Phase III
World Wide Web • Massive, uncontrolled, heterogeneous, and dynamic environment • Content-based Web Search Engines
Web Crawler + Basic IR technology Matching of query terms to document terms
• Web Directories Browse/Search of Organized Web Manual cataloging of Web subset
• Content- & Link-based Web Search Engines Pattern Matching + Link Analysis
• Renewed interest in metadata and classification approach • Digital Libraries?
Integrated (Content, Link, Metadata) Information Discovery
Search Engine 5

Fusion IR: Overview
Goal • To achieve the whole that is greater than sum of its parts
Approaches • Tag team
Use a method best suited for a given situation Single method, single set of results
• Integration Use a combined method that integrates multiple methods Combined method, single set of results
• Merging Merge the results of multiple methods Multiple methods, multiple sets of results
• Meta-fusion All of the above
Search Engine 6

Fusion IR: Research Areas
Data Fusion • Combining multiple sources of evidence • Single collection, multiple representations, single IR method
Collection Fusion • Merging the results of multiple collection search • Multiple collections, single representation, single IR method
Method Fusion • Combining multiple IR methods • Single collection, single representation, multiple IR methods
Paradigm Fusion • Combining content analysis, link analysis, and classification • Integrating user, system, and data
Search Engine 7

Fusion IR: Research Findings
Findings from content-based IR experiments with small, homogeneous document collections • Different IR systems retrieve
→ different sets of documents
• Documents retrieved by multiple systems → are more likely to be relevant
• Combining different systems → is likely to be more beneficial than combining similar systems
• Fusion is good for IR
Is fusion a viable approach for Web IR?
Search Engine 8

Web Fusion IR: Motivation
Motivation
• Web search has become a daily information access mechanism
3.5 Billion Internet Users (350% growth from 2005) (internet live stats, 2016)
96% of Web users access the Internet daily. (www.internetsociety.org, 2012)
91% of Web users use search engines to find information. (Pew Internet, 2012)
3.5 billion Google searches per day (Internet Live Stats, 2016)
• New Challenges Data: massive, dynamic, heterogeneous, noisy Users: diverse, “transitory”
• New Opportunities Multiple sources of evidence
– content, hyperlinks, document structure, user data, taxonomies Data abundance/redundancy
Review • Yang (2005). Information Retrieval on the Web, ARIST Vol. 39 • http://kiyang.kmu.ac.kr/pubs/webir_arist.pdf
Search Engine 9

Link Analysis: PageRank
PageRank score: R(pi) • Propagation of R(pi) through inlinks of the entire Web
T = total # of pages in the Web d = damping factor pi = inlink of p C(pi) = outdegree of pi
Start w/ all R(pi)=1, repeat computation until convergence
• Global Measure of a page based on link analysis only
• Interpretation Models the behavior of random Web surfer
– A probability distribution/weighting function that estimates the likelihood of arriving at page p by link traversal and random jump (d).
Importance/Quality/Popularity of a Web page – A link signifies recommendation/citation
– aggregate all recommendations recursively over entire Web, where each recommendation is weighted by its importance and normalized by its outdegree
Search Engine 10
( ) ( )( )∑
=
⋅−+⋅=k
i i
i
pCpRd
TdpR
1)1(1

PageRank Simplified
11
( ) ( )( )∑
=
=k
i i
i
pCpRpR
1

Link Analysis: HITS
Hyperlink Induced Topic Search • Consider both inlinks & outlinks
estimates the value of a page based on aggregate value of in/outlinks
• Identify “authority” & “hub” pages authority = a page pointed to by many good hubs
hub = a page pointing to many good authority
• Query-dependent measure hub & authority scores assigned for each query
computed from a small subset of the Web – i.e. top N retrieval results
• Premise Web contains mutually reinforcing communities of hubs & authorities on broad topics
Search Engine 12
∑→
=pq
qhpa )()(
∑→
=qp
qaph )()(

Link Analysis: Modified HITS
HITS-based Ranking
1. Expand a set of Text-based search results Root set S = top N documents (e.g. N=200) Inlinks & Outlinks of S (1 or 2 hops)
– Max. k inlinks per document (e.g. k=50) – Delete intrahost links, stoplist URLs
2. Compute Hub and Authority scores Iterative algorithm Fractional weights to links by same authors
3. Rank documents by Authority/Hub scores
Search Engine 13

Modified HITS: Scoring Algorithm
1. Initialize all h(p) and a(p) to 1 2. Recompute h(p) and a(p) with fractional weights
- normalize contribution of authorship (assumption: host=author)
a(p)= ∑(h(q)*auth_wt(q,p)) q is a page linking to p auth_wt (q,p) = 1/m for page q, whose host has m documents linking to p
h(p)= ∑(a(q) *hub_wt(p,q)) q is a page linked from p hub_wt(p,q) = 1/n for page q, whose host has n documents linked from p
3. Normalize scores divide score by square root of sum of squared scores (∑a(p)= ∑h(p)=1)
4. Repeat steps 2 & 3 until scores stabilize
Typical convergence in 10 to 50 iterations for 5000 webpages
Search Engine 14

Modified HITS: Link Weighting
Search Engine 15
p
q1 q2
q3
q4
h(p)= a(q1) + a(q2) + a(q3) + a(q4)/6
q1 q2
q3
q4
a(p)= h(q1) + h(q2) + h(q3) + h(q4)/5
p

WIDIT:Web IR System Overview
1. Mine Multiple Sources of Evidence (MSE) Document Content Document Structure Link Information URL information
2. Execute Parallel Search Multiple Document Representations
body text, anchor text, header text Multiple Query formulations
query expansion
3. Combine the Parallel Search Results Static Tuning of fusion formula (QT-independent)
4. Identify Query Types (QT) Combination Classifier
5. Rerank the fusion result with MSE Compute Reranking Feature Scores Dynamic Tuning of reranking formulas (QT-specific)
Search Engine 16
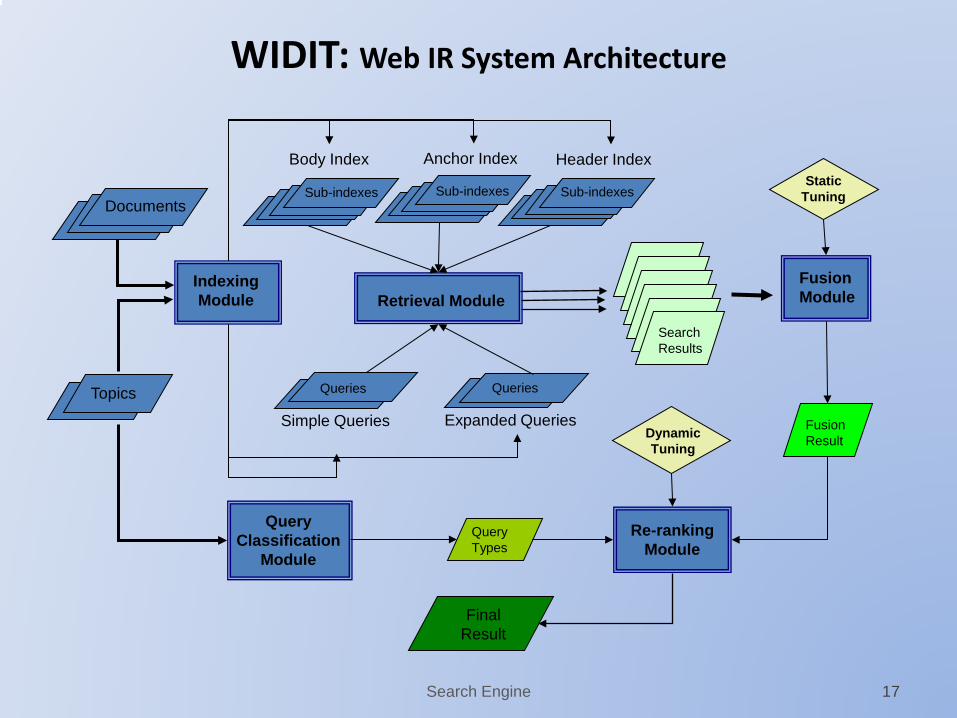
WIDIT: Web IR System Architecture
Search Engine 17
Indexing Module
Sub-indexes
Body Index Anchor Index Header Index
Documents
Topics Queries
Simple Queries
Queries
Expanded Queries
Retrieval Module Fusion Module
Sub-indexes Sub-indexes
Search Results
Re-ranking Module
Fusion Result
Final Result
Static Tuning
Dynamic Tuning
Query Classification
Module
Query Types

WIDIT: Dynamic Tuning Interface
Search Engine 18

SMART
• Length-Normalized Term Weights SMART lnu weight for document terms SMART ltc weight for query terms
where: fik = number of times term k appears in document i idfk = inverse document frequency of term k t = number of terms in document/query
• Document Score inner product of document and query vectors
where: qk = weight of term k in the query dik = weight of term k in document i
t = number of terms common to query & document
Search Engine 19
∑=
+
+=
t
jij
ikik
f
fd
1
2)1)(log(
1)log(
∑=
∗+
∗+=
t
jjj
kkk
idff
idffq
1
2])1)[(log(
)1)(log(
ik
t
kki dq∑
=
=1
Tdq

♦ Document term weight (simplified formula)
♦ Query term weight
Okapi
• Document Ranking
where: Q = query containing terms T
K = k1 ((1-b) + b*(doc_length/avg.doc_length)) tf = term frequency in a document qtf = term frequency in a query k1 , b, k3 = parameters (1.2, 0.75, 7..1000) wRS = Robertson-Sparck Jones weight
N = total number of documents in the collection n = total number of documents in which the term occur R = total number of relevant documents in the collection n = total number of relevant documents retrieved
Search Engine 20
( )qtfk
qtfktfKtfkw
QTRS +
∗+++∑
∈ 3
31)1( )1(1
tfKtf
nnN
+
++−
5.05.0log
( )qtfkqtfk
++
3
3 1
++−−+−+−
+
=
5.05.05.0
5.0
log
rRnNrnrR
r
WRS

















