39
Jan. 2009 (C)RG@SERC,IISc Programming Models for Accelerator-Based Architectures R. Govindarajan HPC Lab,SERC, IISc [email protected] et.in

Jan. 2009(C)RG@SERC,IISc
Programming Models for Accelerator-Based Architectures
R. GovindarajanHPC Lab,SERC, IISc

Jan. 2009 © RG@SERC,IISc 2
HPC Design Using Accelerators
• High level of performance from Accelerators• Variety of general-purpose hardware accelerators
– GPUs : nVidia, ATI,– Accelerators: Clearspeed, Cell BE, …– Plethora of Instruction Sets even for SIMD
• Programmable accelerators, e.g., FPGA-based• HPC Design using Accelerators
– Exploit instruction-level parallelism – Exploit data-level parallelism on SIMD units– Exploit thread-level parallelism on multiple units/multi-cores
• Challenges– Portability across different generation and platforms– Ability to exploit different types of parallelism

Jan. 2009 © RG@SERC,IISc 3
Accelerators – Cell BE

Jan. 2009 © RG@SERC,IISc 4
Accelerators - 8800 GPU

Jan. 2009 © RG@SERC,IISc 5
The Challenge

Jan. 2009 © RG@SERC,IISc 6
Programming in Accelerator-Based Architectures
• Develop a framework – Programmed in a higher-level language, and is
efficient – Can exploit different types of parallelism on
different hardware– Parallelism across heterogeneous functional
units – Be portable across platforms – not device
specific!
Jointly with Prof. Matthew JacobArchitecture Lab., SERC, IISc

Jan. 2009 © RG@SERC,IISc 7
Existing Approaches
StreaMIT
RAW CellBE
Compiler
Accelerator
GPUs
Runtime System
Brooks
GPUs
Compiler
C/C++
SSE/Altivec
Autovectorizer

Jan. 2009 © RG@SERC,IISc 8
What is needed
Compiler/Runtime System

Jan. 2009 © RG@SERC,IISc 9
Two-Pronged Approach
CUDA
Profile-basedCompiler
GPUs Multicore
PLASMA: High-Level Intermediate Representation
Compiler and Runtime System

Jan. 2009 © RG@SERC,IISc 10
Two-Pronged Approach
CUDA
Profile-basedCompiler
GPUs Multicore
PLASMA: High-Level Intermediate Representation
Compiler and Runtime System
StreaMIT

Jan. 2009 © RG@SERC,IISc 11
Stream Programming Model
• Higher level programming model where nodes represent computation and channels communication (producer/consumer relation) between them.
• Exposes Pipelined parallelism and Task-level parallelism
• Temporal streaming of data• Synchronous Data Flow (SDF), Stream Flow Graph,
StreamMIT, Brook, … • Compiling techniques for achieving rate-optimal,
buffer-optimal, software-pipelined schedules • Mapping applications to Accelerators such as GPUs
and Cell BE.

Jan. 2009 © RG@SERC,IISc 12
The StreamIt Language
• Streamit programs are a hierarchical composition of three basic constructs:– Pipeline– SplitJoin
• Round-robin or duplicate splitter
– Feedback Loop
• Stateful filters• Peek values
...
Splitter
Filter Filter Filter
Stream
Stream
Joiner
Joiner Body Splitter
Loop

Jan. 2009 © RG@SERC,IISc 13
StreaMIT
• No. of Push/Pop values fixed and known at compile-time
• Multi-rate firing Dup. Splitter
Bandpass Filter+
Amplifier
Combiner
Signal Source
Bandpass Filter+
Amplifier
2 – Band Equalizer

Jan. 2009 © RG@SERC,IISc 14
Multi-Rate Firing
• Consistent firing rate of nodes to ensure no data accumulation on channels
• If node A fires 3 times, B should fire twice, and C should fire 4 times
• Solving a set of linear equations!
NA * 2 = NB * 3
NB * 4 = NC * 2
• Multiple solutions possible• Primitive steady-state solution
(firing rates)
B
A
C
2
3
4
2

Jan. 2009 © RG@SERC,IISc 15
StreamIt on GPUs
• StreamIt provides a convenient way of programming GPUs
• More ”natural” than frameworks like CUDA or CTM for most domains
• Easier learning curve than CUDA, programmer does not need to think of the program in terms of ”threads” or blocks, but only as a set of communicating filters
• StreamIt programs are easier to verify, since the I/O rates of each filter are static, and hence the schedule can be determined entirely at compile time.

Jan. 2009 © RG@SERC,IISc 16
Challenges on GPUs
• Work distribution between the multiprocessors– GPUs have hundreds of processors (SMs and SIMD units)!
• Exploiting task-level and data-level parallelism– Scheduling across the multiprocessors– Multiple concurrent threads in SM to exploit DLP
• Determining the execution configuration (number of threads for each filter) that minimizes execution time.
• Register constraints (eventhough ~1000s of them)• Lack of synchronization mechanisms between the
multiprocessors of the GPU.• Managing CPU-GPU memory bandwidth efficiently• ”Stateless” filters exploit data parallelism, but ”stateful”
filters require special attention.

Jan. 2009 © RG@SERC,IISc 17
Existing Approaches Single Threaded SIMD Execution

Jan. 2009 © RG@SERC,IISc 18
Existing Approaches (contd.)
Execution on Cell BE Our Approach for GPUs

Jan. 2009 © RG@SERC,IISc 19
Compiling Stream Programs to CUDA for GPUs
• Software Pipeline the execution of the stream program on the GPU– This takes care of synchronization and consistency
issues, since the multiprocessors can execute their work in a decoupled fashion, with kernel invocations being the only synchronization points.
– Work distribution and scheduling are accomplished by formulating the problem as a unified Integer Linear Program and solving it, using standard ILP solvers.
– The ILP formulation is sufficiently simple to be solved in a few seconds on current hardware.

Jan. 2009 © RG@SERC,IISc 24
Stream Graph Execution
Stream Graph
Buffer requirement = 4 x
A
C
D
B
SIMD Execution
A1 A2
SM1 SM2 SM3 SM4
A3 A4
B1 B2 B3 B4
D3
C3
D4
C4
D1
C1
D2
C2
0123
4567

Jan. 2009 © RG@SERC,IISc 25
Stream Graph Execution
Stream Graph Software Pipelined Execution
Buffer requirement = 2 x
A
C
D
B
SM1 SM2 SM3 SM4
A1 A2
A3 A4
B1 B2
B3 B4 D1
C1
D2
C2
D3
C3
D4
C4
0123
4567

Jan. 2009 © RG@SERC,IISc 26
Our Approach
• Good execution configuration determined by using profiling – Identify near-optimal no. of concurrent thread instances per filter.
– Takes into consideration register contrainsts
• Formulate work scheduling and processor (SM) assignment as a unified Integer Linear Program problem.
– Takes into account communication bandwidth restrictions
• Efficient buffer layout scheme to ensure all accesses to GPU memory are coalesced.
• Stateful filters are assigned to CPUs – synergistic execution of CPUs and GPUs is ongoing work!

Jan. 2009 © RG@SERC,IISc 27
ILP Formulation
• Resource Constraints :
wk,v,p = 1 kth instance of filter v mapped to SM p

Jan. 2009 © RG@SERC,IISc 28
ILP Formulation
• Dependence Constraint :
(j,k,v) -- Sched. Time of kth instance of filter v in steady state iteration j
ok,v specifies time within the SWP kernel
fk,v specifies the stage of the SWP kernel
• Filter execution must complete by kernel end

Jan. 2009 © RG@SERC,IISc 29
ILP Formulation
• Dependence Constraint (contd.):
Admissibility of the schedule is given by:
• Constraint solving the above equations gives the schedule!

Jan. 2009 © RG@SERC,IISc 30
Compiler Framework
Jan. 2009 © RG@SERC,IISc 31
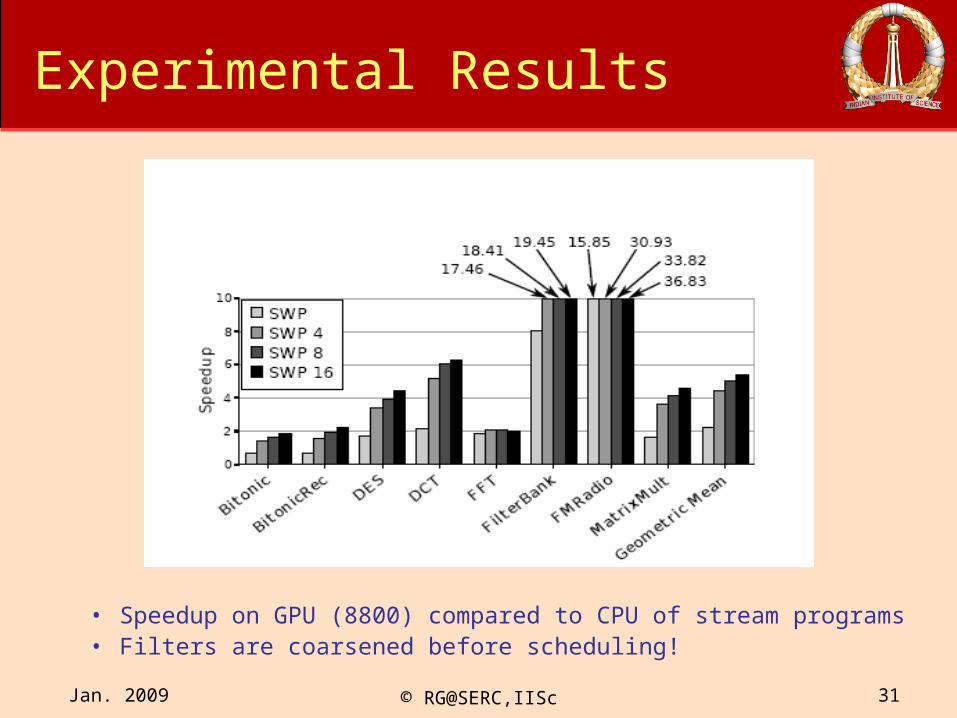
Experimental Results
• Speedup on GPU (8800) compared to CPU of stream programs• Filters are coarsened before scheduling!

Jan. 2009 © RG@SERC,IISc 32
Experimental Results (contd.)
• Improvements due to buffer coalescing• More results in the CGO-09 paper!

Jan. 2009 © RG@SERC,IISc 33
Two-Pronged Approach
Compiler/Runtime System
CUDA
Profile-basedCompiler
GPUs Multicore

Jan. 2009 © RG@SERC,IISc 35
What should a solution provide?
• Rich abstractions for Functionality– Not a lowest common denominator
• Independence from any single architecture• Portability without compromises on efficiency
– Don't forget high-performance goals of the ISA• Scale-up and scale down
– Single core embedded processor to multi-core workstation
• Take advantage of Accelerators (GPU, Cell, etc.)• Transparent Distributed Memory
PLASMA: Portable Programming for PLASTIC SIMD Accelerators

Jan. 2009 © RG@SERC,IISc 36
Our Approach
Stream Program
Intermediate Representation
Cuda, C with Intrinsics,
• Stream or Other high-level program model to a high-level intermediate language
– Perform suitable compiler optimization
– Intermediate representation expressive enough to handle (target) machine specificities
• IR to Target machine – Exploit SIMD and thread-level
parallelism– Agnostic to SIMD width– Manages heterogeneous
memory

Jan. 2009 © RG@SERC,IISc 37
PLASMA Overview

Jan. 2009 © RG@SERC,IISc 38
PLASMA IR
• Operator– Add, Mult, …
• Vector– 1-D bulk data type of base types– E.g. <1, 2, 3, 4, 5>
• Distributor– Distributes operator over vector – Example:
par add <1,2,3,4,5> <10,15,20,25,30> returns <11, 17, 23, 29, 35>
• Vector composition– Concat, slice, gather, scatter, …
Reduce Add
Par Mul
Slice V
M
Matrix-Vector Multiply
par mul, temp, A[i * n:i * n + n:1], Xreduce add, Y[i:i + 1:1], temp

Jan. 2009 © RG@SERC,IISc 39
Our Framework
“CPLASM”, a prototype high-level assembly language
Prototype PLASMA IR Compiler Currently Supported Targets:
C (Scalar), SSE3, CUDA (NVIDIA GPUs) Future Targets:
Cell, ATI, ARM Neon, ... Compiler Optimizations for this “Vector” IR

Jan. 2009 © RG@SERC,IISc 40
Our Framework (contd.)

Jan. 2009 © RG@SERC,IISc 41
Experimental Results
• Kernel programs written in CPLASM • Compiled to C or CUDA, exposing SIMD
parallelism• Execution on SSE2 or GPU• Comparison with hand-optimized library

Jan. 2009 © RG@SERC,IISc 42
Initial Results
Compares well with hand-optimized library kernels
Blocking (tiling) optimization can lead to better performance

Jan. 2009 © RG@SERC,IISc 43
Future Directions
• Synergistic execution of stream program in CPU and GPU.
• Support for multiple heterogeneous functional units
• Retargetting PLASMA for multiple accelerators• Extending the framework beyond Stream
Programming models

Jan. 2009(C)RG@SERC,IISc
Thank You !!









![VTU – IISc Workshop (C)RG@SERC,IISc Compiler, Architecture and HPC Research in Heterogeneous Multi-Core Era R. Govindarajan CSA & SERC, IISc govind@[csa,serc].iisc.ernet.in.](https://static.documents.pub/doc/80x56/56649eeb5503460f94bfc78b/vtu-iisc-workshop-crgserciisc-compiler-architecture-and-hpc-research.jpg)







