Abstract Many-task computing is a well-established paradigm for implementing looselycoupled applications (tasks) on large-scale com-puting systems. However, few of the model’s existingimplementations provide efficient, low-latencysupport for executing tasks that are tightly coupledmultiprocessing applications. Thus, a vast arrayof parallel applications cannot readily be usedeffectively within many-task workloads. In thiswork, we present JETS, a middleware componentthat provides high performance support for many-parallel-task computing (MPTC). JETS is basedon a highly concurrent approach to parallel taskdispatch and on new capabilities now available inthe MPICH2 MPI implementation and the ZeptoOSLinux operating system. JETS represents anadvance over the few known examples ofmultilevel many-parallel-task scheduling systems:it more efficiently schedules and launches manyshort-duration parallel application invocations;it overcomes the challenges of coupling the userprocesses of each multiprocessing applicationinvocation via the messaging fabric; and it con-currently manages many application executions invarious stages. We report here on the JETSarchitecture and its performance on both
J. M. Wozniak (B) · M. Wilde · D. S. KatzArgonne National Laboratory, Argonne, IL, USAe-mail: [email protected]
synthetic benchmarks and an MPTC applicationin molecular dynamics.
“What matters is that all of the componentswork together.” [23]
The high-performance computing (HPC) sys-tems of today almost exclusively run Unix andLinux operating systems, yet lack a fundamentalstrength of the Unix philosophy: program com-posability and modularity. HPC systems are con-trolled by schedulers that often greatly restrictthe feature set available to the shell program-mer. Schedulers and resource management sys-tems often enforce multiple policies that limit soft-ware flexibility. As a result, new compositions ofexisting software features in scientific software areoften developed by editing C and Fortran sourcecode, at great effort.
Scheduled systems (PBS, Cobalt) run user pro-grams inside allocations, which grant fixed compu-tational resources to a user for a fixed amount oftime (although programs may exit before the allo-cation expires). The user has little control over ex-actly when a program will start because the time is
342 J.M. Wozniak et al.
determined by other users in the queue. Schedul-ing multiple programs to work together is a com-plex co-scheduling problem that has not caughton with users. Allocation sizes may be restrictedby site policy to minimum processor counts ortimes. Within an allocation, it is typically difficultor impossible to launch multiple processes in suc-cession; if this capability is available, it is typi-cally possible only with trivial control flow andsimple resource usage. Among allocations, someschedulers offer rudimentary workflow function-ality. Since separately allocated jobs are queuedseparately, however, a succeeding allocation isunlikely to start immediately when a precedingallocation exits. Allocations may take on the orderof minutes to boot, making workflows constructedthis way inefficient. Communication among allo-cations may be restricted for security reasons.
Solutions for interacting productively withthese systems is related to problems addressedin Grid computing. Among allocations, advancedworkflow specification languages may be used,and scheduler abstraction interfaces may aid inworkflow deployment. Additionally, within allo-cations, pilot job mechanisms may help in thereuse of allocation resources.
The model of interest to this work combinesseveral of these Grid-based solutions to HPC-specific problems. A model of our problem isshown in Fig. 1. The user starts by creatingone large allocation on the computing system ①.Next, the user provides or generates a (possiblydynamic) set of job definitions ②, which con-tain processor count and run-time requirements,and instantiates the user scheduler. These arelaunched efficiently inside the allocation ③.
Achieving this functionality requires multipletechnical features. First, it requires a full-featuredoperating system on the compute nodes capableof communicating with the user scheduler andmanaging subordinate user properties. Second, itrequires the development of a fast user sched-uler. Third, it requires the ability to remotelyinvoke MPI programs without relying on previousprocess managers, the key contribution of thiswork. Fourth, it requires solutions to many relatedproblems, such as workflow management, faulttolerance, and other systems challenges.
Fig. 1 Model for many-parallel-task computing
1.1 Many-Task Computing
Many-task computing (MTC) [33] has emergedas a powerful concept for the rapid developmentand execution of scalable scientific applications onlarge clusters and leadership-class supercomput-ers. The MTC model consists of many, usually se-quential, individual applications (called tasks) thatare executed on individually addressable systemcomponents, such as processor cores, without in-tertask communication. These tasks communicateonly through the standard filesystem interfaces,although optimizations are possible [52]. MTCallows use of large-scale parallel systems with littleor no explicit parallel programming.
Application developers may wish to build acomposite application comprising an ensemble ofparallel executions, linked together by a workflowor parameter sweep. The results of such a runmay be integrated by statistical or optimization-based methods, such as a Monte Carlo algorithm,a parameter search, or other methods related touncertainty quantification. The model thus is con-ducive to the use of scripting, workflow engines,and other familiar programming models that al-low application developers to efficiently utilizea variety of systems, from single systems wheretasks are executed in sequence, to parallel and
JETS 343
distributed systems, where the number of tasksthat can be executed concurrently is limited by thescale of the system, the efficiency of schedulingand running the tasks, and the implicit parallelismof the application itself.
The MTC model has successfully been appliedto problems in a variety of scientific domains,including computational biochemical investiga-tions, such as protein structure prediction [11, 21,48], molecular dynamics simulations of protein-ligand docking [34] and protein-RNA docking,and searching mass-spectrometry data for post-translational protein modifications [24, 48]; mod-eling of the interactions of climate, energy, andeconomics [39, 48]; postprocessing and analy-sis of climate model results; explorations of thelanguage functions of the human brain [18, 22,38]; creation of general statistical frameworksfor structural equation modeling [4]; and imageprocessing for research in image-guided planningfor neurosurgery [13] and astronomy [48].
Since MTC makes no provisions for intertaskcommunication during a task’s execution, it limitsthe flexibility available to developers who maywish to strike a balance between the MTC andHPC models. It does not make the benefits ofthe high-performance interconnect available tothe application. In this paper, we demonstratethe ability to make the interconnect available byallowing user tasks to use multiple processorsand internally communicate through MPI. Thus,programs built on MPI and related technologiesmay be brought into the MTC model. In a many-core setting, this also enables the use of shared-memory or other hierarchical or node-local com-munication mechanisms, although that is notdeveloped here.
1.2 Many-Parallel-Task Computing
MTC, as a research field, addresses the problemsthat emerge from launching many individual se-quential processes on a large-scale system. Anal-ogously, an application that faces challenges re-sulting from a large number of parallel executionsis an MPTC problem. Systems that enable MPTCprovide a powerful tool for scientific applicationdevelopers.
In addition to the the usability benefits of MTC,MPTC also provides benefits from a systems per-spective, in that it allows many-task applicationsto make good use of HPC interconnects. First, thenative schedulers and application-launch mecha-nisms of today’s supercomputers do not supporta sufficiently fast task scheduling, startup, andshutdown cycle to allow implementations of themany-task computing model to work efficiently,but the development of a specialized, single-userscheduler can allow many task applications to usea high fraction of the system compute resources.Second, MPTC makes the interconnect fabric re-sources available to the tasks in an MTC-likemodel. These constitute a significant portion ofthe expense of the largest of the TOP500 systems[44].
Additionally, MPTC allows tasks to use pow-erful software implementations such as MPI-IO,which aggregate and optimize accesses to distrib-uted and parallel filesystems. The use of thesealgorithms and implementations can greatly in-crease data access rates to available cores, makingbetter use of the storage system than is the casefor today’s MTC applications, which by defaultuse uncoordinated filesystem accesses that aredifficult to manage. For example, given N MTCprocesses, the filesystem would be accessed by Nclients; however, for 16-process MPTC tasks usingMPI-IO, the number of clients would be N/16.
In this work, we present JETS, which is de-signed from the ground up to make good use ofsupercomputer resources to support large batchesof parallel tasks, in which each task executionconsists of tightly coupled processes that use MPIfor communication. The development of JETSinvolved modifications to the MPICH2 [28] pack-age that are now publicly available. JETS runson commodity clusters, optionally through SSHtunnels [31], and on the Blue Gene/P (BG/P)through the use of ZeptoOS functionality. Thus itis applicable to clusters, Grids, clouds, and high-performance systems. JETS is a highly usablesystem in the MTC tradition and is concernedprimarily with dispatching application invocationcommands to available resources. Additionally,JETS has been integrated with the Swift workflowlanguage [53] and Coasters [19] scheduler.
344 J.M. Wozniak et al.
This paper describes the MPTC problem inmore detail and reports four main technical con-tributions:
1. We have designed, implemented, and demon-strated new MPICH2 features that enable in-dividual MPI processes to be managed by anexternal scheduler.
2. We have designed, implemented, and demon-strated an associated set of external routinesused to control the MPICH2 process manager(the Hydra component), constituting the coreJETS functionality.
3. We have designed, implemented, and demon-strated a stand-alone tool (jets) that pro-vides maximum performance for scripts thatexecute many small MPI task sets. This allowsusers to run simple batches of MPI tasks usinga simple task list produced by hand or byrunning a generator script, assuming all jobspecifications may be determined in advance.
4. We have integrated the core JETS functional-ity with the Swift parallel scripting languagethrough the Swift execution layer. This en-ables a user to compose the application to-gether as a loosely coupled collection of mul-tiprocessor jobs. Such an application is drivenby a high-level, dynamic script that is capableof making branch decisions at run time. Addi-tionally, it may be used on any of the resourcessupported by Swift and Coasters, includingclusters, Grids, clouds, and HPC systems.
1.3 Applications, Including Molecular Dynamics
Many scientific applications have the potential tobenefit from MPTC techniques. The performancecharacteristics of the component jobs in an ap-plication workflow determine the applicability ofMPTC techniques.
For a typical large-scale HPC system, suchan application should necessarily be able to uti-lize O(10, 000) processors or more concurrently,across multiple running jobs. Individual jobsshould run for seconds or minutes and requiretens to hundreds of processors. Jobs that exceedthese parameters in run time or processor countare candidates for using the traditional systemsscheduler, jobs that run for subsecond run times
on single processors are candidates for systemssuch as ADLB [27] or Scioto [12] (libraries thatrequire code modification). Since MPTC logicallyencompasses MTC, it includes application compo-nents from that space as well.
In this work, we focus on replica exchangemolecular dynamics (REM) via NAMD as anexample application. The REM algorithm is de-scribed in more detail below. NAMD jobs forREM fall within the MPTC range. Existing tech-niques for REM in NAMD focus on modifyingthe NAMD codebase and recompiling. NAMDcontains about 30,000 lines of Charm++ andC++ code in addition to Tcl features. Recompil-ing NAMD for the Blue Gene/P with optimiza-tions takes multiple hours. Thus, a lightweighttechnique for recomposing application logic inworkflows from component calls to NAMD jobsis highly desirable.
1.4 Contents
The remainder of this paper is organized as fol-lows. Section 2 describes work related to the topicof MTC. Section 3 contains a motivating casestudy in MPTC, and Sections 4 and 5 describe thecomponents used to build JETS and its systemarchitecture. In Section 6 we measure system per-formance and in Section 7 describe planned futurework. We conclude in Section 8 with comments onpossible new applications built by using the JETSmodel.
2 Background and Related Work
Many-task computing represents the intersec-tion of sequential batch-oriented computing withextreme-scale computational resources. MTC isattractive to developers because of its broadportability and support from many toolkits. Weemphasize that our target systems are single-siteHPC resources; however, much of the founda-tional work in the area is based in Grid and dis-tributed computing.
Grid computing [16] provided an abundanceof computational resources to scientific groups,necessitating the creation of a variety of toolkits to
JETS 345
automate the use of these resources for commonapplication patterns such as parameter sweepsand workflows. Parameter sweeps, supported bysystems such as Nimrod [1] and APST [3], en-able the user to specify a high-level definition ofpossible program inputs to be sampled. The sys-tem then generates the resulting job specificationsand submits them to resources. In comparison,the JETS mechanism rapidly assembles indepen-dent available compute nodes into parallel jobs,without requiring support for such aggregation inthe underlying resource manager. Further, JETShas been integrated with the Swift system for themanagement of jobs and data, and is not linked toa particular higher-level pattern.
An initial pilot job mechanism was the Con-dor Glide-In [17] mechanism that integrated withthe full-featured Condor [42] scheduler. The Con-dor Glide-In mechanism essentially places a fullCondor installation on the target site, includingremote system calls and checkpoint/restart func-tionality. Workflows may be launched inside anCondor allocation with GlideinWMS [37]. PandaPilot factory [7] is a recent development that pro-vides a pilot job wrapper mechanism to managethe distribution of worker agents as well as theinitial data placement. Neither Condor Glide-Innor Panda is capable, however, of aggregatingmultiple independent cluster compute nodes toassemble the resources needed for the executionof parallel MPI jobs.
The SAGA BigJob [26] system enables the useof various underlying job submission mechanismsincluding Condor, Globus [15], and Amazon EC2cloud allocation. SAGA places workers on theresources and coordinates with the BigJob sys-tem to place multiprocessor jobs on distributedresources. In comparison, SAGA is concerned pri-marily with questions regarding the distributed in-frastructure and does not address the performanceregime of many short-duration parallel tasks thatJETS has achieved. SAGA has been used to per-form replica-exchange simulations (see Section 3)with NAMD [43] in an investigation that focusedon coupling the replica exchange trajectories. Re-lated work in a widely distributed context allowedMPI jobs to run across resource managers by usingqueue time estimates provided by a queuing timepredictor [6].
Similarly, the Integrated Plasma Simulator (IPS[14]) is a dataflow-driven workflow specificationsystem that wraps parallel MPI simulation appli-cations into component-oriented Python objects.While originally designed for the specific needs ofthe plasma fusion simulation community, IPS isin fact general purpose. Like JETS, it requests alarge allocation of compute nodes as a single jobfrom the system’s underlying resource manager(such as PBS), and it manages the launching of in-dividual application subtasks within this pool. Be-ing more recent, JETS improves on two of IPS’slimitations. First, to maintain its understandingof the number of free nodes in its compute-nodepool, IPS must accurately predict how the under-lying resource manager will assign nodes to IPStask creation requests. In complex systems suchas the Cray with many NUMA and CPU-affinityissues being handled by the resource manager, thistask can be tricky and requires user error-pronelogic. JETS overcomes this problem by doing itsown node management with a JETS worker agenton each compute node. Second, IPS depends onthe native systems underlying job placement andMPI launching service, such as mpiexec [28] onsimple clusters and ALPS aprun on Cray systems[9]. This does not provide any straightforward wayto run on systems with more complex job launch-ing mechanisms, such as the Blue Gene/P. Again,JETS overcomes this limitation with its workeragents, which are started with simple scripts run-ning under the native resource manager. While fu-ture Blue Gene systems may provide applicationlaunch capabilities similar to the Cray ALPS [5],the latency and performance of these capabilitiesare unknown, whereas the JETS model wouldbe able to readily handle almost any imaginablearchitecture.
The Falkon [34] system enables MTC onBlue Gene/P resources, but only for single-jobexecutions, and does not support the MPTCparadigm. On the Blue Gene/P, Falkon placesworkers on the system’s compute nodes andcommunicates with them through an intermedi-ate scheduler placed on the system’s I/O nodes.Falkon primarily addresses task scheduling, al-though related project work produced Data-Diffusion [35] to cache data for reuse amongcompute processes. In comparison, the JETS
346 J.M. Wozniak et al.
mechanism focuses on the deployment of MPIapplications, which is not addressed by Falkon.
3 Use Case and Requirements
As a canonical example of the motivation formany-parallel-task computing, we consider a clas-sical task and dataflow pattern from molecular dy-namics. The replica exchange method (REM) [40]is a computational method to enhance statisticsabout a simulated molecular system by perform-ing molecular dynamics simulation of the systemat varying temperatures. These simulation tra-jectories, under varying conditions, are regularlystopped (typically at a rather high rate), sampled,and compared for exchange conditions. Data ex-change may be required at each stopping point.The simulation is then restarted under the restartfile of neighboring replica to accomplish the stateexchange.
The computational workflow is diagrammed inFig. 2. The initial use case provided by our usergroup is as follows. Each set of CPUs is initializedwith conditions including temperature. Each sim-ulation runs as a NAMD [32] task of 256 computecores. There are 64 concurrent simulations run-ning on a total of 16,384 cores. Each simulationis expected to run for 10–100 simulated timesteps,for approximately 10–60 s of wall time dependingon the configuration. Smaller individual runs pro-duce finer granularity exchanges, which are desir-able. The simulations are then stopped, and anexternal application process performs the replicaexchange among the simulation snapshots. The
Fig. 2 Workflow perspective of replica exchange method
simulations are then restarted from the snapshots,and the process repeats until a termination condi-tion is satisfied approximately 12 h later. Thus, tokeep up with this workload, the scheduler wouldhave to launch 6.4 MPI executions per second,requiring an individual process launch rate of ap-proximately 1,638 processes per second, for a 12-hperiod. The goal of our work is to present a systemthat provides an elegant scripting approach toapplication task management while achieving thislevel of performance.
This process management and aggregation ca-pability is not supported by previous systems andis notably difficult to achieve on our primary pro-duction target, the 160,000-core Blue Gene/P “In-trepid” at Argonne National Laboratory. Passingeach job into a cluster scheduler is dramaticallyless efficient than our use of persistent workeragents, and cluster-specific policies often preventsuch models of many-parallel-task computing byimposing a limit on the number of jobs in thequeue per user or other inhibiting constraints. Forexample, at Argonne, jobs must use a minimumof 512 nodes, whereas our initial application hasan efficiency-based target of 64 nodes (256 cores).Thus, the scientists who motivated the REM usecase above are currently running workloads usingan inferior simulation approach because of thelack of MPTC support on the Blue Gene/P.
Attaining high performance from the central-ized JETS scheduler is critical. Additionally, de-ploying and using JETS could quickly becomecomplex, because JETS involves multiple distrib-uted resources as well as the management of userand system external processes. Thus, the JETSarchitecture observes the following principles:
1. Use simple, reusable threading abstractions.This task is accomplished through the use ofexisting concurrent data structures.
2. Separate service pipeline processes throughsimple interfaces. In JETS, socket manage-ment, handler processing, and external processmanagement connect through obvious mech-anisms and are each arbitrarily concurrent.
3. Support ready composition and decomposi-tion. JETS components are easily composedinto frameworks appropriate for different en-vironments (e.g., for Swift, stand-alone usage,
JETS 347
or use within other frameworks such as IPS).The components can also be decomposed forseparate usage (e.g., the JETS worker agentcan serve as a useful component of a bench-marking test framework).
4. Assume disconnection is likely. The JETS ser-vice and workers can operate independentlyand are individually diagnosable.
4 Technologies
JETS integrates the three technologies describedin the following subsections. Although JETS maybe used as a stand-alone system, its features arealso available in Swift.
4.1 Swift/Coasters
An original design goal of JETS was to sup-port the MPTC model in the Swift system. Swift[49] is a highly concurrent programming modelfor deploying workflows to Grids and clusters.Swift was originally developed for Grid resourcesand is essentially a high-level language to buildworkflows for the Commodity Grid (CoG) Kit[46]. To support fast task scheduling, Swift usesan associated provider, called Coasters, that runsas a network of external services, including aCoasterService and worker scripts. Swift commu-nicates with the CoasterService to schedule jobsand data movement to the distributed resources.The Swift/Coasters system can run directly on anHPC resource, launching sequential MTC tasksat high rates and employing filesystem accessoptimizations.
Swift/Coasters operations is diagrammed inFig. 3. First, the Swift script is compiled ① tothe workflow language Karajan, which contains acomplete library of execution and data movementoperations. Tasks resulting from this workfloware scheduled by well-studied, configurable al-gorithms and distributed to underlying serviceproviders (external schedulers) including local ex-ecution, SSH [31], PBS [20], SGE [41], Globus[10], Condor [25], Cobalt [8], or the Coastersprovider [19]. The Coasters provider consists of aconnection to the CoasterService, which itself isdeployed as a task ②. The CoasterService in turn
Fig. 3 Swift/Coasters architecture
uses task submission to deploy one or more alloca-tions of “pilot jobs” [26], called Coaster Workers,in blocks of varying sizes and durations ③. TheCoasterService schedules user tasks inside theseblocks of available computation time and rapidlylaunches them via RPC-like communication overa TCP/IP socket ④. Data transfer operations mayalso be performed over this connection, removingthe need for a separate data transfer mechanism.On the BG/P, the CoasterService may be placedon a login node, communicating with its workersover the internal BG/P network.
4.2 MPI Process Management: Hydra
The ability to run MPI programs in JETS isbuilt on facilities offered by the MPI implemen-tation. The MPICH2 implementation of the MPIstandard, used in this work, employs a processmanager that is responsible for launching theindividual user processes in coordination with userinput and an existing scheduler such as the localoperating system or a distributed scheduler suchas PBS [20].
The default process manager in MPICH2 is cur-rently Hydra [45]. The MPICH2 process manageris responsible for launching the user processes(“bootstrapping”, in Hydra terminology) on therequested resources through a bootstrap control
348 J.M. Wozniak et al.
interface using an available mechanism such asssh. The user launches MPICH by invokingmpiexec, which is a Hydra component. Subordi-nate to mpiexec, ssh is the launcher that invokesprocesses on remote resources. In Hydra, thelauncher invokes the Hydra proxy, which is givensufficient environment and arguments to connectback to mpiexec and receive control commands.The proxy then launches the user executable;thus commencing user processing and MPIcommunication.
Hydra was modified for this work throughthe addition of a bootstrap mechanism calledlauncher=manual, that employs no existing exter-nal scheduler: it simply reports proxy commandsto its output and performs its ordinary networkservices. Thus, any other controlling process mayuse this specification to bring up the Hydra net-work and launch the MPI application. This workson any system that provides sockets, including theZeptoOS system. Our complete solution uses thismechanism and is described in Section 5.
4.3 ZeptoOS
JETS relies on the ability to dynamically bind MPIprocesses together using the POSIX sockets fa-cility provided by many operating systems. WhileTCP/IP sockets are a typical mechanism for MPIjob coupling on commodity clusters, these APIsare not provided by default on the Blue Gene/P.The ability to perform sockets-based MPI mes-saging on the BG/P is made possible through theuse of functionality provided by ZeptoOS. ThisLinux-based compute node operating system op-tionally replaces the default IBM Compute NodeKernel (CNK) and enables the user processes tocommunicate over the BG/P torus interconnectby using an ethernet network device. This virtualnetwork is then used by the MPI programslaunched by JETS.
5 Design
JETS is based on the basic MTC paradigm ofusers rapidly submitting large batches of ordi-nary command-line program executions to largeresources. JETS assumes that the user can launch
a pilot job on the compute resources (starterscripts are provided with the distribution). Thepilot job requests work from a centralized dis-patcher, which can assign work to given resourcesby using multiple scheduler components calledhandlers. Each handler has a specific input fileformat, which is basically a list of literal commandlines.
JETS orchestrates the systems described inthe previous section into a simple framework forMPTC. It provides the following features:
1. Speed: JETS is designed to outperformprocess launchers such as ssh while enablingsecurity (e.g., OpenSSH tunneling). JETSuses compute sites as they become availableand quickly combines them into MPI-capablegroups.
2. Local storage: JETS can cache libraries andtools (such as the MPICH2 proxy binary) andeven user data on node-local storage, whichboosts startup performance and thus utiliza-tion for ensembles of short jobs. In practice,the files to be stored in this way are simplyprovided to the JETS start-up script as a sim-ple list.
3. Fault tolerance: JETS automatically disre-gards workers that fail or hang, minimizingtheir impact on the overall system.
4. Flexibility: JETS enables fast submission ofjobs to worker nodes unreachable by systemssuch as OpenSSH (e.g., the Blue Gene/P com-pute nodes) and enables the use of smallerMPI sizes than allowed by some site policies.
JETS may be used to submit single-processjobs (as in Falkon) or to submit MPI jobs. Theessential idea in JETS is to transform an MPIjob specification into a set of MPICH proxyjob specifications by communicating with a back-ground mpiexec process and to rapidly submitthose proxy jobs to the pilot jobs for execution.
Performance benefits are obtained throughthe local, concurrent execution of the mpiexecprocesses and the use of the pilot jobs. Hundredsof mpiexec processes do not place a noticeableload on the submit site. Additional performancebenefits are gained through the deployment ofthe proxy executable, the user executable, andrelated libraries in local storage on the compute
JETS 349
sites. JETS contains features to automate thesefile transfers when resources are allocated by sim-ply copying them to local storage. JETS featuresare available in two software systems: stand-aloneform, which submits jobs given by the user in asimple list, and MPICH/Coasters form, which en-ables MPI executions to operate on the Coastersinfrastructure with job specifications delivered bya Swift workflow.
5.1 Stand-Alone Form
In stand-alone form, the user must know all ofthe job specifications in advance, including thecommand line and node count. This is formulatedin a JETS input file formatted as:
Such an input file executes a wrapper scriptaround NAMD, operating on the given files with4, 8, or 6 nodes allocated to each respective job.Note that the hostnames to be used by each jobare not specified; these are dynamically deter-mined by JETS at run time based on availability.Files are accessed at the given paths directly by theuser application. As an optimization, these pathscould contain local storage paths that refer to filescopied in by JETS.
Stand-alone JETS operation is diagrammed inFig. 4. The input to JETS is a simple text file con-taining command lines to be executed and MPI-specific information such as the number of nodeson which to run ①. The user launches the workerscripts with provided allocation scripts, which usean external system such as ssh or Cobalt ②.Once running, each worker is persistent, capableof executing many tasks as a pilot job. Workersreport readiness to the JETS engine. When theengine has obtained notification from the requi-site number of workers for the next user job inthe user list, it launches the mpiexec binary in thebackground, provides it with the host informationfrom the ready workers, and obtains proxy startupinformation ③. The mpiexec process continuesrunning in the background. The proxy jobs areissued to their respective workers ④, and theproxies connect to the mpiexec process to ne-
Fig. 4 JETS architecture
gotiate the MPI job start ⑤. The MPI applicationprocesses can locate each other to begin MPI com-munication ⑥. On job completion, the mpiexecprocess and its proxies terminate. The mpiexecoutput is checked for errors, and the workersrequest additional work, resuming the cycle.
5.2 MPICH/Coasters Form
Since the essential JETS functionality is to breakMPI executions into composite single-processjobs, it was natural to make JETS functionalityavailable in Coasters and thus to Swift workflowapplications. Running MPI jobs in Swift throughthe JETS framework is performed by combin-ing the advanced dataflow, task generation, datamanagement, and worker management aspects ofthe Swift/Coasters architecture with the mpiexecprocess management of the JETS architecture.
MPICH/Coasters operation is diagrammed inFig. 5. The Swift script executes as normal, withthe addition of configuration settings for MPIprograms ①. These settings are packed with thejob specification and sent to the CoasterService ②.The CoasterService processes the MPI settings,which affects the Coasters allocation strategy. ForMPI jobs, the CoasterService waits for the ap-propriate number of available worker nodes be-
350 J.M. Wozniak et al.
fore launching the mpiexec control mechanism,which is similar to that used in Section 5.1. Whenthe job is ready to run, the mpiexec process islaunched locally (not shown) concurrently withthe Hydra proxies. Proxies launch the Swift wrap-per script, which manages the user job in accor-dance with Swift features. The user executablesare then launched, which are able to locate eachother over sockets ③.
A common practice in workflow design is towrite user wrapper scripts to manage files and setup program executions before calling the appli-cation binary program. This is commonly donein Swift applications as well. This practice isfully compatible with the MPICH/Coasters sys-tem, even though the process tree is deep (5 levelsor more). A PMI_RANK (Process Management In-terface Rank) variable is provided to all levels ofuser programs and may be used to coordinate suchscripts. This value is equivalent to the MPI processrank in MPI_COMM_WORLD. For example, if a userdesires to perform a simple shell command on therank 0 process of a multiprocess job just before jobstart, this could be performed by the wrapper shellscript that could branch to that shell command byreferring to PMI_RANK.
Fig. 5 MPICH/Coasters architecture
6 Performance Results
In this section, we evaluate the many parallel-task computing model by measuring the perfor-mance of its implementations in multiple modes,for synthetic and realistic workloads. Specifically,we characterize performance parameters for usecases on three different computing systems andoffer configuration details. In this section, wedefine a possibly parallel application invocation tobe a single “job”, and use “allocation” in the samesense as the Introduction.
6.1 Stand-Alone JETS
Here, we present performance results obtainedby running stand-alone JETS benchmarks in acluster setting, in a high-performance setting, in afaulty environment, and in a NAMD-like applica-tion. Stand-alone benchmarks avoid the measure-ment complexity in a full Swift-based applicationworkflow. Stand-alone JETS could be used in cer-tain application patterns such as parameter sweep[47], and these results are relevant for that usecase.
6.1.1 Sequential Tasks
Since JETS decomposes user MPI program invo-cations into a set of sequential user program invo-cations, we first measure the JETS performancefor sequential tasks. This test demonstrates thebasic task rate at which JETS can submit indi-vidual sequential tasks to a computing resource.In this series of tests JETS was configured torun on Surveyor, an IBM Blue Gene/P systemat Argonne National Laboratory. Each task con-sisted of an external process that did no work;thus, only the cost of the process startup itself isconsidered. First, we measured the rate at whichthe BG/P compute node can launch processeswithout JETS (no communication), using all fouravailable cores. This is shown as the single-point“ideal” measurement. Then, JETS was used tosubmit jobs to allocations of increasing size.
As shown in Fig. 6, JETS scales well, achievingover 7,000 job launches per second on the fullrack of Surveyor, which consists of 1,024 computenodes containing 4,096 cores. This result indi-
JETS 351
cates that JETS will be capable of submitting theindividual jobs generated by the more complexMPICH2-based mechanism described previouslyfor MPI-based workloads.
6.1.2 MPI Task Launch Performance:Cluster Setting
In our next series of tests JETS was configuredto run on Breadboard, a network of x86-basedcompute servers at Argonne National Laboratory.In this test, a simple MPI application was con-structed for benchmarking purposes that starts up,performs an MPI barrier on all processes, waitsfor a given time, performs a second MPI barrier,and exits. The number of MPI processes in eachinvocation of this application is independent ofthe size of the whole allocation. In this test, eachdata point represents the utilization obtained byrunning a large batch of application invocations ofvarying sizes (shown as n-proc) inside an alloca-tion of the size given on the x-axis. Each job waitduration was 1 s. System utilization is reported as
utilization = duration × jobs × nallocation size × time
, (1)
where time is the total allocation time.The workload was run in each of two modes: a
“shell script” mode, which simply calls mpiexecrepeatedly, and a mode in which JETS was used.The shell script mode can use only the entire
Fig. 6 JETS results for sequential tasks on the BG/P
allocation, whereas the JETS mode may be runat smaller, varying sizes; the size of the MPI jobis shown as either 4-proc or 8-proc, using 4 or8 processes across 4 or 8 nodes, respectively. Asshown in Fig. 7, JETS can achieve approximately90 % system utilization for the extremely short(single-second) tasks submitted. This greatly ex-ceeds the utilization available in an mpiexec-based shell script and indicates that the perfor-mance is capable of scaling to larger resources.
6.1.3 MPI Communication Performance
Next, we measure the messaging performancepenalty due to the use of the sockets-basedMPICH2 communication mechanism used by thesystem. On the Blue Gene/P, the vendor-providedcommunication library is expected to be fasterthan the socket abstraction used by our MPICH2library. As described above, the use of theZeptoOS-based messaging abstraction is expectedto increase message latency and reduce transmis-sion bandwidth. In this test, a simple “ping-pong”MPI test was run on two nodes, each of whichalternates between calls to MPI blocking send andreceive functions. The buffer was filled once withrandom data of the given size and sent back andforth the given number of times. The run timewas measured with MPI_Wtime. The programwas compiled and run in each of two modes: “na-tive” mode, which was compiled with bgxlc and
Fig. 7 MPI/JETS results, cluster setting
352 J.M. Wozniak et al.
Fig. 8 MPI messaging performance on BG/P
uses the default system kernel and settings; and“MPICH/sockets” mode, which uses the MPICH2library running on the ZeptoOS sockets layer.
As shown in Fig. 8, using MPICH2 as we doresults in much higher latency for small messagesand slightly slower bandwidth for large messages.This is primarily due to the use of TCP by the Zep-toOS mechanism. While this performance penaltymay be problematic for some applications, it mustbe weighed against the flexibility and function-ality offered by ZeptoOS features and the faultrecoverability offered by TCP-based APIs. Pos-sible network enhancements are considered inSection 7, and the reliability characteristics aredemonstrated in Section 6.1.5.
JETS was again configured to run on Surveyor.The user application in this case is the same appli-cation used in the cluster setting but was run fora 10-s duration. Each node here contains 4 cores.We place only one MPI process per node in thistest case. The n-proc number is as defined in theprevious test.
JETS scripts were used to configure the systemfor compatibility with ZeptoOS and high perfor-mance at this system scale. We used the ZeptoOSnode-local RAM-based filesystem to store the ap-plication binary, the Hydra proxy, and requisitelibraries. The script sets LD_LIBRARY_PATH to
locate the node-local system and user libraries andsuppress any lookups to GPFS, which are muchmore time-consuming than are local lookups. Thescripts also add an entry to /etc/hosts to en-able the Hydra proxy to find the JETS serviceon the login node. The ZeptoOS IP-over-torusfeature was enabled to provide each node withan IP address obtainable through ifconfig. Thisaddress is connectable by all peer nodes in theallocation and was used by the JETS componentsto connect the Hydra processes and thus launchthe MPI program.
We ran the same benchmark application usedin Section 6.1.2 with a 10-s duration. MPI exe-cutions were constructed from nodes in the allo-cation without regard for their relative networkpositions; the default JETS behavior is to groupnodes in first come, first served order.
Results are shown in Fig. 9. Each line shownrepresents one MPI task size: 4, 8, or 64-processortasks. These task sizes were chosen to highlightJETS performance characteristics. Each size taskwas run on allocation sizes of 256, 512, and 1,024nodes, and only one core per node was used. Thenumber of tasks in the batch was selected suchthat each node processed 20 10-s tasks. As shownin the figure, 4-processor tasks at this durationare sustainable up to about 512 nodes, after whichthere is a significant degradation from the utiliza-tion achieved by the 8-processor tasks; this is dueto the load on the central JETS scheduler becom-
Fig. 9 MPI/JETS results, BG/P setting
JETS 353
ing excessive. The 64-process tasks are individu-ally slower to start, resulting in lower utilization insmall allocations. However, this penalty becomessmaller as the task size becomes a smaller fractionof the available nodes.
6.1.5 Task Management: Faulty Setting
In this series of tests, we demonstrate that JETSis capable of maintaining high utilization on theremaining useful compute nodes of a faulty al-location in which worker script processes termi-nate early because of system hardware or soft-ware failure. In this case, JETS was run againon Surveyor and the sequential application fromSection 6.1.1 was used again. A fault injectionscript was run on the submit site that terminatedrandomly selected pilot jobs, one at a time, atregular 10-s intervals. Because of skew among theapplication tasks, this could result in a workerbeing terminated during or between applicationtask executions. The worker and user task startand stop times were recorded, allowing the totalsystem load and worker count to be obtained andplotted over time.
Results are shown in Fig. 10. The number ofworker nodes in operation is shown as “nodesavailable”; the number steadily decreases fromthe original level of 32 workers to zero over aperiod of about 320 s. The number of runningapplication jobs is plotted as “running jobs.” Ini-tially, the jobs execute in lockstep, resulting inlarge utilization dips that become smaller overtime. These large dips are due to congestion onthe JETS scheduler when multiple nodes becomeavailable for work simultaneously. The dips be-come less dramatic as skew reduces the numberof simultaneous work requests. After the 100-smark, the number of running jobs is bounded bythe number of nodes available. The number ofrunning jobs stays close to the number of nodesavailable, indicating that JETS maintains a highutilization rate on the available nodes.
6.1.6 Application: NAMD
In this series of tests, we report utilization re-sults observed when running a bag-of-tasks batchof NAMD executions, with settings similar to
Fig. 10 MPI/JETS results, faulty setting
that of the replica exchange method. JETS wasconfigured to run on Surveyor. The NAMD ap-plication was configured to run one process pernode; the other cores were idle. A batch of 32NAMD runs comparable to those used in an REMrun was provided to us by a NAMD user. We du-plicated those cases and ordered them in a round-robin fashion. For each allocation size from 256to 1,024, we created a batch that would require6 executions per node on average. Each run sim-ulated an NMA [30] system of 44,992 atoms for10 timesteps, which runs in NAMD for approxi-mately 100 s on 4 BG/P processors.
Application I/O is as follows. The applicationreads 5 files totaling 14.8 MB of input and writes3 files totaling 2.2 MB of output, in addition toabout 11 KB on standard output. The I/O timeis contained in the application wall time. TheNAMD application performed I/O directly to thePVFS filesystem available on Surveyor. Standardoutput was directed back to the mpiexec process.In the JETS framework, standard output is di-rected from the application to the Hydra proxy,over the network to the mpiexec process, into theJETS process, and then into a file. For the largestrun, this approach produced 16 MB of output over11 min, which was not enough to cause congestion.
354 J.M. Wozniak et al.
Fig. 11 NAMD wall timedistribution
The full rack (1,024-node) batch consisted of1,536 4-processor jobs. A typical run time distri-bution for these jobs is shown in Fig. 11. (Thisfigure shows the full distribution for the batch thatproduced the 64-node result in Fig. 18b.) Whilethe majority of the tasks fall between 100 and120 s, many tasks exceed this, running up to 160 s.The utilization results (defined in (1)), shown inFig. 12, shows that utilization is near 90 %. Loadlevel for the full rack batch, computed as the num-ber of busy cores at each point in time, is shownin Fig. 13. For a longer run, utilization could behigher as the effect of the ramp-up and long-taileffects are amortized.
6.2 JETS/Swift Integration
Here, we report on the performance of theintegrated JETS/Swift task distribution system.
Fig. 12 NAMD/JETS utilization results
Fig. 13 NAMD/JETS load level results
This allows the execution of complex Swift-basedworkflows. See Section 5.2 for a description of thesoftware used in this section.
6.2.1 Synthetic Workloads
First, we report utilization results observed whenrunning varying MPI configurations. The test suiteconstructed for this case allows us to measureutilization results for various allocation sizes, MPIjob sizes, and MPI job core counts.
These tests were performed on Eureka, a 100-node x86-based cluster at Argonne National Lab-oratory. Each node contains two quad-core IntelXeon E5405 processors running at 2 GHz for a to-tal of 8 cores per node with 32 GB RAM. The sys-tem runs a GPFS [36] filesystem. Test allocationswere started by Cobalt [8] and maintained by apersistent Coasters service [19]. This allowed us to
JETS 355
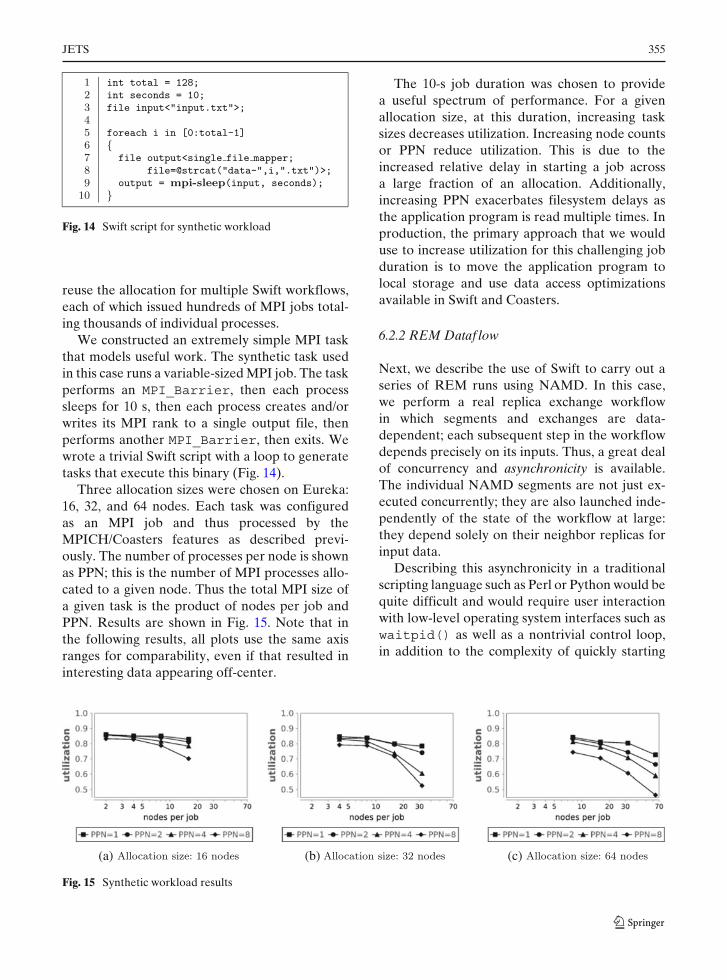
Fig. 14 Swift script for synthetic workload
reuse the allocation for multiple Swift workflows,each of which issued hundreds of MPI jobs total-ing thousands of individual processes.
We constructed an extremely simple MPI taskthat models useful work. The synthetic task usedin this case runs a variable-sized MPI job. The taskperforms an MPI_Barrier, then each processsleeps for 10 s, then each process creates and/orwrites its MPI rank to a single output file, thenperforms another MPI_Barrier, then exits. Wewrote a trivial Swift script with a loop to generatetasks that execute this binary (Fig. 14).
Three allocation sizes were chosen on Eureka:16, 32, and 64 nodes. Each task was configuredas an MPI job and thus processed by theMPICH/Coasters features as described previ-ously. The number of processes per node is shownas PPN; this is the number of MPI processes allo-cated to a given node. Thus the total MPI size ofa given task is the product of nodes per job andPPN. Results are shown in Fig. 15. Note that inthe following results, all plots use the same axisranges for comparability, even if that resulted ininteresting data appearing off-center.
The 10-s job duration was chosen to providea useful spectrum of performance. For a givenallocation size, at this duration, increasing tasksizes decreases utilization. Increasing node countsor PPN reduce utilization. This is due to theincreased relative delay in starting a job acrossa large fraction of an allocation. Additionally,increasing PPN exacerbates filesystem delays asthe application program is read multiple times. Inproduction, the primary approach that we woulduse to increase utilization for this challenging jobduration is to move the application program tolocal storage and use data access optimizationsavailable in Swift and Coasters.
6.2.2 REM Dataf low
Next, we describe the use of Swift to carry out aseries of REM runs using NAMD. In this case,we perform a real replica exchange workflowin which segments and exchanges are data-dependent; each subsequent step in the workflowdepends precisely on its inputs. Thus, a great dealof concurrency and asynchronicity is available.The individual NAMD segments are not just ex-ecuted concurrently; they are also launched inde-pendently of the state of the workflow at large:they depend solely on their neighbor replicas forinput data.
Describing this asynchronicity in a traditionalscripting language such as Perl or Python would bequite difficult and would require user interactionwith low-level operating system interfaces such aswaitpid() as well as a nontrivial control loop,in addition to the complexity of quickly starting
(a) (b) (c)
Fig. 15 Synthetic workload results
356 J.M. Wozniak et al.
each available MPI job on free nodes. In our im-plementation, the dataflow diagrammed in Fig. 16is represented in under 200 lines of Swift scriptincluding comments and data definitions. Notethat although the shapes are drawn to standardsize to make the dependency structure readable,the times actually vary considerably (as illustratedin Fig. 11). The core loop code is shown in Fig. 17;some data definitions and data initializations arenot shown.
The REM dataflow proceeds as follows. InFig. 16, each row from top to bottom repre-sents a replica trajectory and is represented inthe script as variable i. Each column from leftto right represent progress made after exchangecompletion and is represented in the script asvariable j. Each segment (i, j) is associatedwith a segment index; script variables current,previous, neighbor, and total are of thistype. Script variables c, v, and s, represent con-ventional NAMD coordinates, velocities, and ex-tended system files; o represents NAMD standardoutput (which contains application statistics) andx contains output from the exchange script (whichis primarily used as a token for synchronization).These arrays are indexed by the segment indexnumber and are mapped to real disk files throughthe Swift mapping abstraction (details not shown).Thus, segment k is associated with 5 dataflow filesand represents 10 simulated time steps.
Fig. 16 Asynchronous REM dataflow as implemented inSwift
Fig. 17 Swift script for REM core loop
The statements in the Swift script are inter-preted according to Swift semantics: they are allexecuted concurrently, limited by data depen-dencies. Each NAMD execution is handled bythe namd() function which assigns the result ofrunning NAMD on the files from the previoussegment into the current segment. This createsa dataflow dependency from left to right in thediagram.
Similarly, the exchange() function executesthe exchange required for REM. Notably, theexchange record in x is required for each namd()
JETS 357
call in addition to NAMD application data.Certain conventional application data files arereused in each NAMD execution: pdb_file,prm_file, and psf_file. The if control state-ments ensure that the exchange is performed byalternating replicas. In Swift scripts, the %% op-erator represents modulus, allowing for the de-termination of the parity of a number and forthe exchange to wrap around in odd exchanges.The exchange function is implemented as a shellscript that performs file operations to carry outthe exchange. Swift was configured to performthe filesystem-bound exchange operations on thelogin node, freeing the compute nodes for the nextready NAMD segment.
The Swift script implementation is structured toallow maximal concurrency, mitigate the effect ofthe variation in NAMD execution time, and min-imize the effects of the data-dependent synchro-nization. In both measurement series, the numberof replicas in the ensemble is twice the hardwareconcurrency available, thus, when a NAMD invo-cation terminates, another is always ready to run.Additionally, since the performance of the single-process exchange() implementation is bound tofilesystem latency, it is executed on the login node,preventing that process from delaying a readymultiprocess NAMD invocation.
We executed this script on the same infrastruc-ture as in the previous section (Eureka) underidentical settings. In each case, utilization wasmeasured by comparing the wall time reported byNAMD to the wall time in the allocation used bySwift, as calculated in (1). Thus, any long tail effect[2] is charged against the utilization.
We first executed the script with NAMDconfigured to run in a single-process mode foreach segment with up to 64 nodes, each segmentrunning as a single process on a single node. Ineach script execution, the number of replicas inthe dataflow was twice the number of nodes, and4 exchanges were performed. The result of thisseries of measurements is shown in Fig. 18a.
We then executed the script with NAMDconfigured to run as an MPI program for eachsegment with up to 64 nodes. For each allocationsize from 8 to 64, the number of concurrentlyexecuting replicas was 4, and the total number ofreplicas in the dataflow was 8. All 8 cores on eachcore were used. Thus, for the 8-node allocation,each replica segment ran on 2 nodes with 16 MPIprocesses, and so forth. Over the dataflow, 6 ex-changes were performed. The result of this seriesof measurements is shown in Fig. 18b.
Neither case used specialized data managementfunctionality provided by Swift [50] or JETS asused in Section 6.1.4. Available optimizations thatcould be used in a production run include copy-ing programs to local storage on compute nodes,changing operating system settings to prevent un-necessary filesystem accesses to GPFS, or prestag-ing reused data files (e.g. pdb_file) to local stor-age. Thus, all programs and data were read andwritten to GPFS, and our results show what a first-time user would experience in a straightforwarduse case.
For the single-process case, as theallocation size was increased from 4 to 64,utilization decreased down to 85.4 %. In the MPIcase, utilization did not change substantially over
Fig. 18 REM/Swiftresults
(a) (b)
358 J.M. Wozniak et al.
the measured range of allocation sizes, remainingbetween 92.7 and 95.6 %.
Decreases in utilization comes from three sources:Swift/Coasters processing time, filesystem delays,and executable launch time. Swift/Coastersprocessing time is consumed by the Swift datadependency engine producing the task descriptionand the Coasters system transmitting that task to aworker; however, the task rates in this use case donot approach known Swift/Coasters capabilities[19]. Filesystem accesses to GPFS are the likelycause of lost utilization for the single-processcase, as the large number of independent replicasproduce simultaneous small-file accesses. Mostimportant for this work, the utilization for MPIuse cases exceeds that of single-process use cases,showing that the use of the new JETS-based joblaunch features does not constrain utilization.
7 Future Work
Many improvements and extensions to JETS areplanned, including the following.
In order to simplify its implementation andfocus on algorithms, the initial JETS version usesMPI over standard TCP sockets. To take bet-ter advantage of the native high- performanceinterconnect fabric on petascale systems such asBlue Gene/P and Cray XE, we plan to enhanceJETS with support for vendor-provided MPI overthe native communication fabric libraries (such asBlue Gene DCMF and Cray GNI).
While JETS currently operates at high speedin part because it uses a simple FIFO queu-ing approach, we plan to explore the additionof priority-based scheduling and backfill and tomeasure scheduler performance on workloads ofvarying size tasks. (At the same time, such work-loads seldom occur in typical MPTC applica-tions and are thus of low priority to current userapplications.)
We plan to add the “multiple-job-size spec-trum” allocator of the Coasters mechanism toJETS to enable it to request resources from theunderlying system scheduler in a “spectrum” ofvarious node counts, to enable it to obtain re-sources quickly in the face of unknown queuecompositions and system load conditions.
We will experiment with MPI-IO from JETS-initiated MPTC workloads, and work on opti-mizations for supporting the passing of MPI-IO-written and -read datasets within an MPTCdataflow. Similarly, such high-performance data-passing schemes can also be evaluated usingGlobal Arrays [29] or distributed hash tables [51].
JETS does not currently have a mechanismby which nodes may be grouped with respect tonetwork location. This feature could be importantif given workflow is running on multiple clusterssimultaneously, and joining MPI processes on thesame cluster should be preferred to running MPIjobs across clusters; in fact, some users wouldprobably like to prohibit the latter.
8 Conclusion
“As we’re really not together at all, butparallel.”1
The parallel ensemble application, consistingof the composition of large numbers of many-processor MPI executions, is an increasingly pop-ular paradigm that is poorly supported by existingsystems. In this work, we described a new light-weight mechanism to support MPTC. Our workis focused on gaining high utilization rates forapplications on large-scale HPC resources. Ourwork includes the coordination of large numbersof CPUs, the management of many MPICH2startup processes, the rapid distribution of jobspecifications to workers, and the construction ofapplication scripts through integration with theSwift language and runtime system.
From a performance perspective, we demon-strated that the JETS task scheduler can launchsingle-process jobs at a rate exceeding that ofprevious many-task schedulers, and showed thatmoving to multiple-process MPI jobs does notrestrict performance. Additionally, we providednew mechanisms for the deployment of MPI ap-plications into many-task systems; in particular,the new MPICH functionality could be reused by
1Ted Leo and the Pharmacists. Parallel or Together?, onThe Tyranny of Distance. Lookout! 2001.
JETS 359
other groups developing other novel strategies tolaunch MPI applications.
We expect that JETS and related systems willemerge as powerful tools in important areas, in-cluding rapid prototyping of batches of exist-ing codes and large ensemble studies based onloosely coupled MPI runs. Our system promotesthe rapid development of large runs of exist-ing codes through its simple model and optionalscripting language interface. The system providesa shell script-like model but offers much betterperformance and management capabilities. Newapplications could be designed around the JETSmodel. These applications would benefit from theability of the JETS to manage multiple sched-uler allocations in a fault-tolerant way. Moreover,the software development would benefit from thehigh-level Swift model.
Acknowledgements We thank Wei Jiang of Argonne Na-tional Laboratory for help in constructing the REM usecase, as well as Ray Loy, Kazumoto Yoshii and KamilIskra for support in using the Blue Gene system tools andZeptoOS.
This research is supported by the Office of Ad-vanced Scientific Computing Research, Office of Science,U.S. Department of Energy under Contract DE-AC02-06CH11357. Computing resources were provided by theArgonne Leadership Computing Facility.
References
1. Abramson, D., Giddy, J., Kotler, L.: High performanceparametric modeling with Nimrod/G: killer applicationfor the global Grid. In: Proc. International Parallel andDistributed Processing Symposium (2000)
2. Armstrong, T.G., Zhang, Z., Katz, D.S., Wilde, M.,Foster, I.T.: Scheduling many-task workloads on su-percomputers: dealing with trailing tasks. In: Proc.MTAGS Workshop at SC’10 (2010)
3. Berman, F., Wolski, R., Casanova, H., Cirne, W., Dail,H., Faerman, M., Figueira, S., Hayes, J., Obertelli, G.,Schopf, J., Shao, G., Smallen, S., Spring, N., Su, A.,Zagorodnov, D.: Adaptive computing on the Grid us-ing AppLeS. IEEE Trans. Parallel Distrib. Syst. 14(4),369–382 (2003)
4. Boker, S., Neale, M., Maes, H., Wilde, M., Spiegel, M.,Brick, T., Spies, J., Estabrook, R., Kenny, S., Bates, T.,Mehta, P., Fox, J.: OpenMx: an open source extendedstructural equation modeling framework. Psychome-trika 76(2), 306–317 (2011)
5. Budnik, T., Knudson, B., Megerian, M., Miller, S.,Mundy, M., Stockdell, W.: Blue Gene/Q resource man-
agement architecture. In: Proc. Workshop on Many-Task Computing on Grids and Supercomputers (2010)
6. Chakraborty, P., Jha, S., Katz, D.S.: Novel submissionmodes for tightly coupled jobs across distributed re-sources for reduced time-to-solution. Phil. Trans. R.Soc. A, Math. Phys. Eng. Sci. 367(1897), 2545–2556(2009)
7. Chiu, P.-H., Potekhin, M.: Pilot factory—a Condor-based system for scalable pilot job generation in thePanda WMS framework. J. Phys. Conf. Ser. 219, 062041(2011)
8. Cobalt web site. http://trac.mcs.anl.gov/projects/cobalt.Accessed 30 May 2013
9. Cray Inc. Workload Management and ApplicationPlacement for the Cray Linux Environment: Documentnumber S–2496–3103. Cray Inc., Chippewa Falls, WI,USA (2011)
10. Czajkowski, K., Foster, I., Karonis, N., Kesselman, C.,Martin, S., Smith, W., Tuecke, S.: A resource manage-ment architecture for metacomputing systems. Lect.Notes Comput. Sci. 1459, 62–82 (1998)
11. DeBartolo, J., Hocky, G., Wilde, M., Xu, J., Freed,K.F., Sosnick, T.R.: Protein structure prediction en-hanced with evolutionary diversity: speed. Protein Sci.19(3), 520–534 (2010)
12. Dinan, J., Krishnamoorthy, S., Larkins, D.B.,Nieplocha, J., Sadayappan, P.: Scioto: a framework forglobal-view task parallelism. In: Intl. Conf. on ParallelProcessing, pp. 586–593 (2008)
13. Fedorov, A., Clifford, B., Warfield, S.K., Kikinis, R.,Chrisochoides, N.: Non-rigid registration for image-guided neurosurgery on the TeraGrid: a case study.Technical Report WM-CS-2009-05, College of Williamand Mary (2009)
15. Foster, I.: What is the Grid? A three point checklist.GRIDToday 1(6) (2002)
16. Foster, I., Kesselman, C. (eds.): The Grid: Blueprintfor a New Computing Infrastructure, 1st edn. MorganKaufmann (1999)
17. Frey, J., Tannenbaum, T., Foster, I., Livny, M., Tuecke,S.: Condor-G: a computation management agent formulti-institutional Grids. Cluster Comput. 5(3), 237–246 (2002)
18. Hasson, U., Skipper, J.I., Wilde, M.J., Nusbaum, H.C.,Small, S.L.: Improving the analysis, storage and shar-ing of neuroimaging data using relational databasesand distributed computing. NeuroImage 39(2), 693–706(2008)
19. Hategan, M., Wozniak, J.M., Maheshwari, K.: Coast-ers: uniform resource provisioning and access for sci-entific computing on clouds and Grids. In: Proc. Utilityand Cloud Computing (2011)
20. Henderson, R.L., Tweten, D.: Portable batch sys-tem: requirement specification. Technical report, NASSystems Division, NASA Ames Research Center(1998)
21. Hocky, G., Wilde, M., DeBartolo, J., Hategan, M.,Foster, I., Sosnick, T.R., Freed, K.F.: Towards petas-cale ab initio protein folding through parallel scripting.Technical Report ANL/MCS-P1612-0409, ArgonneNational Laboratory (2009)
22. Kenny, S., Andric, M., Boker, S.M., Neale, M.C.,Wilde, M., Small, S.L.: Parallel workflows for data-driven structural equation modeling in functionalneuroimaging. Front. Neuroinform. 3(34) (2009).doi:10.3389%2Fneuro.11.034.2009
23. Kernighan, B.W., Pike, R.: The UNIX ProgrammingEnvironment. Prentice Hall (1984)
24. Lee, S., Chen, Y., Luo, H., Wu, A.A., Wilde, M.,Schumacker, P.T., Zhao, Y.: The first global screen-ing of protein substrates bearing protein-bound 3,4-dihydroxyphenylalanine in Escherichia coli and hu-man mitochondria. J. Proteome Res. 9(11), 5705–5714(2010)
25. Litzkow, M., Livny, M., Mutka, M.: Condor—a hunterof idle workstations. In: Proc. International Conferenceof Distributed Computing Systems (1988)
26. Luckow, A., Lacinski, L., Jha, S.: SAGA BigJob: anextensible and interoperable pilot-job abstraction fordistributed applications and systems. In: Proc. CCGrid(2010)
27. Lusk, E.L., Pieper, S.C., Butler, R.M.: More scalability,less pain: a simple programming model and its imple-mentation for extreme computing. SciDAC Rev. 17,992056 (2010)
28. MPICH web site. http://www.mpich.org. Accessed 30May 2013
29. Nieplocha, J., Harrison, R.J., Littlefield, R.J.: Globalarrays: a nonuniform memory access programmingmodel for high-performance computers. J. Supercom-puting 10(2), 1–17 (1996)
30. NMA structure in the Protein Data Bank. http://www.rcsb.org/pdb/ligand/ligandsummary.do?hetId=NMA.Accessed 30 May 2013
31. OpenSSH web site. http://www.openssh.com. Accessed30 May 2013
32. Phillips, J.C., Braun, R., Wang, W., Gumbart, J.,Tajkhorshid, E., Villa, E., Chipot, C., Skeel, R.D., Kalé,L., Schulten, K.: Scalable molecular dynamics withNAMD. J. Comput. Chem. 26(16), 1781–1802 (2005)
33. Raicu, I., Foster, I., Zhao, Y.: Many-task computingfor Grids and supercomputers. In: Proc. Workshop onMany-Task Computing on Grids and Supercomputers(2008)
34. Raicu, I., Zhang, Z., Wilde, M., Foster, I., Beckman,P., Iskra, K., Clifford, B.: Towards loosely-coupled pro-gramming on petascale systems. In: Proc. SC’08 (2008)
35. Raicu, I., Zhao, Y., Foster, I.T., Szalay, A.: Accelerat-ing large-scale data exploration through data diffusion.In: Proc. Workshop on Data-aware Distributed Com-puting (2008)
36. Schmuck, F., Haskin, R.: GPFS: a shared-disk file sys-tem for large computing clusters. In: Proc. USENIXConference on File and Storage Technologies (2002)
37. Sfiligoi, I.: glideinWMS a generic pilot-based workloadmanagement system. J. Phys. Conf. Ser. 119(6), 062044(2008)
38. Stef-Praun, T., Clifford, B., Foster, I., Hasson, U.,Hategan, M., Small, S.L., Wilde, M., Zhao, Y.: Accel-erating medical research using the Swift workflow sys-tem. Stud. Health Technol. Inform. 126, 207–216 (2007)
39. Stef-Praun, T., Madeira, G.A., Foster, I., Townsend,R.: Accelerating solution of a moral hazard prob-lem with Swift. In: e-Social Science 2007, Indianapolis(2007)
40. Sugita, Y., Okamoto, Y.: Replica-exchange molecu-lar dynamics method for protein folding. Chem. Phys.Lett. 314(1–2), 141–151 (1999)
41. Sun Grid Engine web site. http://www.oracle.com/technetwork/oem/grid-engine-166852.html. Accessed30 May 2013
42. Thain, D., Tannenbaum, T., Livny, M.: Distributedcomputing in practice: the Condor experience. Concur-rency Computat. Pract. Exper. 17(2–4), 325–356 (2005)
43. Thota, A., Luckow, A., Jha, S.: Efficient large-scalereplica-exchange simulations on production infrastruc-ture. Phil. Trans. R. Soc. Lond. A 369(1949), 3318–3335(2011)
44. Top 500 web site. http://www.top500.org. Accessed 30May 2013
45. Using the Hydra process manager. https://wiki.mpich.org/mpich/index.php/Using_the_Hydra_Process_Manager.Accessed 30 May 2013
46. von Laszewski, G., Foster, I., Gawor, J., Lane, P.:A Java commodity Grid kit. Concurrency Computat.Pract. Exper. 13(8–9), 645–662 (2001)
47. Wibisono, A., Zhao, Z., Belloum, A., Bubak, M.:A framework for interactive parameter sweep appli-cations. In: Bubak, M., van Albada, G., Dongarra,J., Sloot, P. (eds.) Computational Science—ICCS2008. Lecture Notes in Computer Science, vol. 5103.Springer, Berlin/Heidelberg (2008)
48. Wilde, M., Foster, I., Iskra, K., Beckman, P., Zhang,Z., Espinosa, A., Hategan, M., Clifford, B., Raicu, I.:Parallel scripting for applications at the petascale andbeyond. Computer 42(11), 50–60 (2009)
49. Wilde, M., Hategan, M., Wozniak, J.M., Clifford, B.,Katz, D.S., Foster, I.: Swift: a language for distrib-uted parallel scripting. Parallel Comput. 37(9), 633–652(2011)
50. Wozniak, J.M., Wilde, M.: Case studies in storage ac-cess by loosely coupled petascale applications. In: Proc.Petascale Data Storage Workshop at SC’09 (2009)
51. Wozniak, J.M., Jacobs, B., Latham, R., Lang, S., Son,S.W., Ross, R.: Implementing reliable data structuresfor MPI services in high component count systems.In: Recent Advances in Parallel Virtual Machine andMessage Passing Interface. Lecture Notes in ComputerScience, vol. 5759. Springer (2009)
52. Zhang, Z., Espinosa, A., Iskra, K., Raicu, I., Foster, I.,Wilde, M.: Design and evaluation of a collective I/Omodel for loosely-coupled petascale programming. In:Proc. MTAGS Workshop at SC’08 (2008)
53. Zhao, Y., Hategan, M., Clifford, B., Foster, I., vonLaszewski, G., Raicu, I., Stef-Praun, T., Wilde, M.:Swift: Fast, reliable, loosely coupled parallel compu-tation. In: Proc. Workshop on Scientific Workflows(2007)