98
Microsoft Deutschland GmbH Olivia Klose, Technical Evangelist Alexei Khalyako, Sr Program Manager Jumpstarting Big Data Projects
| Date post: | 04-Aug-2015 |
| Category: |
Data & Analytics |
| Upload: | olivia-klose |
| View: | 369 times |
| Download: | 0 times |

Microsoft Deutschland GmbHOlivia Klose, Technical Evangelist Alexei Khalyako, Sr Program
Manager
Jumpstarting Big Data Projects

Architectural Considerations in HDInsightMicrosoft Deutschland GmbHOlivia Klose, Technical Evangelist Alexei Khalyako, Sr Program
Manager


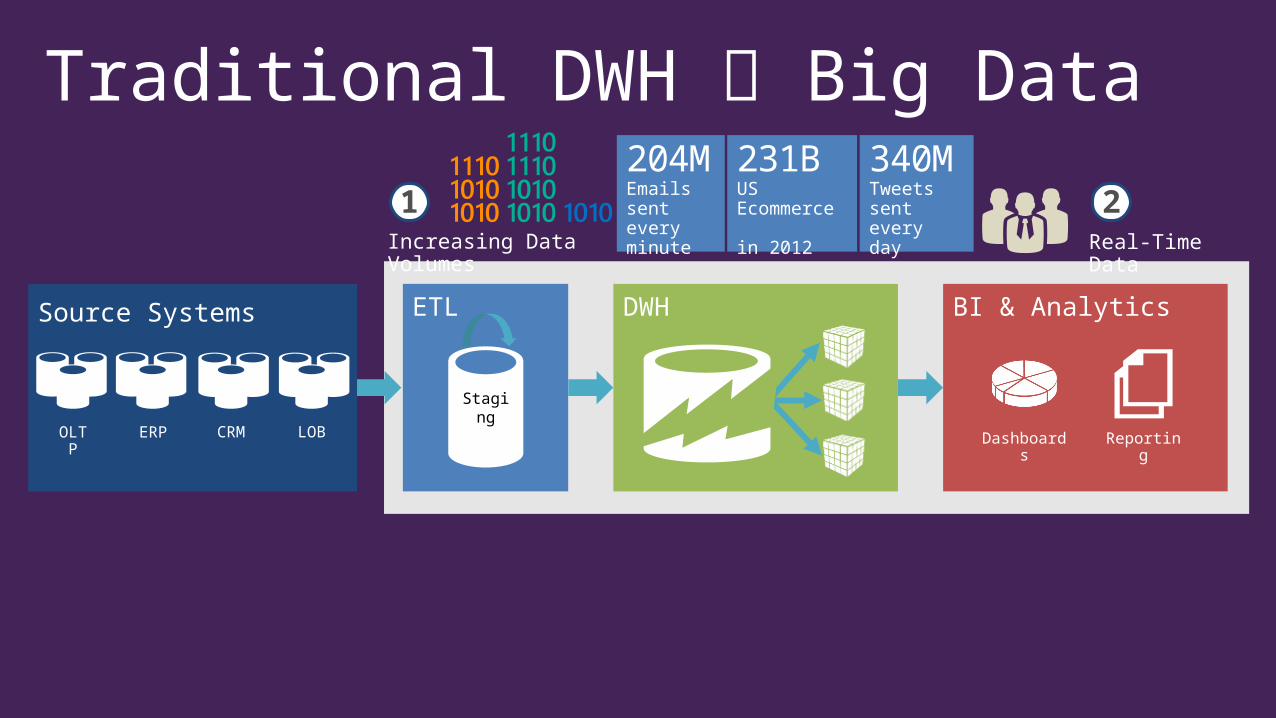
Traditional DWH Big Data
Staging

Traditional DWH Big Data
Staging
150x Data growth 2010-2020
40ZB Digital Universe 2020
1Trillion Web Pages
Traditional DWH Big Data
Staging
1204MEmails sent every minute
340MTweets sent every day
231BUS Ecommerce in 2012
2

Traditional DWH Big Data
Staging
1 2
3 15xMachine generated data 2020
1.3M Hours on Skype per hour
2.4MFacebook content per minute


What New Data Types?
Sentiment Clickstream
Sensors Geographic
Server Logs
Unstructured
Non-relational Data
DevicesWeb
SensorsSocial
HadoopValue

New Data Types: Sensors

New Data Types: Sensors
Up to 75 control units in 1 vehicle
About 1,000 individual possible extra
equipments
1 GB car software, 15 GB data on board
(incl. navi)
2,000 user functions implemented
12,000 types of error stored onboard for
diagnosis
Daily up to 60,000 car diagnosis worldwide

“We have structured data”</meldungText><antwort>False</antwort><wert>na</wert></meldung><steuergeraet sgbdVariante="SMG_60"><steuergeraeteFunktion zeitstempel="2013-04-30T09:00:37.9926171-04:00" endDate="2013-04-30T09:00:38.1158609-04:00" jobName="STATUS_FAHRZEUGTESTER"><datensatz satzNr="1"><result name="JOB_STATUS">OKAY</result><result name="_TEL_ANTWORT">80 F1 18 70 70 02 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 82 6B 00 6D 6B 39 CD 14 00 14 00 00 0E 00 15 00 0A 00 19 00 0C 00 12 00 15 85 57 71 88 81 C0 7D 73 C2 08 01 05 02 F7 00 FF FF 01 73 00 00 02 A8 00 C2 00 01 E0 00 00 00 00 00 00 3D 01 00 00 00 01 03 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 01 FD 01 E1 02 05 01 F8 03 4F FF AD 04</result><result name="_TEL_AUFTRAG">83 18 F1 30 02 01</result><result name="STAT_KL15_ROH">0</result><result name="STAT_KLR_EIN_ROH">0</result><result name="STAT_WAKE_UP_ROH">1</result><result name="STAT_ISTGANG_TEXT">Neutral</result><sgFunktion zeitstempel=“2013-04-30T10:33:37.0834084+02:00" endDate="2013-04-30T10:33:37.9310504+02:00" jobName="_FLM_LESEN_BOSCH"><datensatz satzNr="1"><result name="FLM_DATEN_1">00 00 00 03 02 08 C6 56 46 4C 4D 39 00 16 4B B2 00 00 00 32 00 00 06 99 00 00 00 65 00 00 18 6E 00 00 00 73 00 00 00 20 00 00 00 73 00 00 00 00 00 00 10 69 00 00 0F 53 00 00 00 2C 00 00 00 0A 00 00 79 6D 00 00 B7 34 00 00 D3 9E 4A 4C 41 52 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 2C 00 00 00 00 00 00 1A 5C 00 15 4B CA 00 00 44 08 00 00 2D 39 00 00 1E 45 00 00 26 89 00 00 1E EB 00 00 0C 65 00 00 04 47 00 00 00 00 00 00 00 00 00 00 00 04 00 00 00 27 00 00 01 1E 00 00 02 AB 00 00 07 71 00 00 13 D7 00 00 36 48 00 15 91 AD 00 00 3F 97 00 00 19 C1 00 00 07 F9 00 00 02 D4 00 00 00 BD 00 00 00 20 00 16 1C 42 00 00 18 B1 00 00 09 40 00 00 08 9F 00 00 04 3A 00 00 01 3E 00 01 8C D7 00 00 61 A3 00 00 37 9D 00 00 1E 78 00 00 14 96 00 00 0A 71 00 00 05 49 00 00 02 B1 00 00 00 A7 00 00 00 1D 00 00 00 09 00 00 00 05 00 00 00 00 00 00 00 00 00 00 23 BB 00 00 2F 84 00 00 14 EF 00 00 09 40 00 00 04 71 00 00 03 34 00 00 02 12 00 00 01 AC 00 00 01 59 00 00 0B C4 00 00 00 06 00 00 00 38 00 00 00 19 00 00 00 01 00 00 00 00 00 00 00 04 00 00 00 01 00 00 00 00 00 00 00 01 00 00 00 00 00 00 00 03 00 00 00 00 00 00 00 00 52 4F 54 48 00 00 00 00 00 00 00 07 00 00 00 00 00 00 00 01 00 00 00 00 00 00 00 01 00 00 00 00 00 00 00 04 00 00 00 00 00 00 00 00 56 30 00 00 00 03 00 11 00 01 01 06 00 00 00 00 00 00 00 00 00 01 00 00 00 0E 00 05 00 1A 00 12 00 00 00 26 00 00 00 00 00 0B 00 00 00 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 44 44 00 43 00 16 00 08 00 0D 00 04 00 02 00 00 00 02 00 11 00 20 00 1A 00 0A 00 15 00 0F 00 1B 00 13 00 08 00 08 00 00 00 00 00 07 00 0E 00 08 00 04 00 02 00 01 00 00 00 6D 00 03 00 02 00 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0A 00 21 00 15 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0B 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 18 05 1F 00 00 00 00 00 00 00 00 00 1F 00 03 00 02 00 00 00 00 00 00 00 20 00 05 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 62 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 2E 00 00 1B 00 19 00 18 00 0D 00 00 00 00 00 00 00 01 00 01 00 02 00 00 06 00 01 E6 00 00 12 00 03 00 02 00 07 00 00 00 00 00 00 00 00 00 00 00 00 00 04 00 02 01 BA 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 24 00</result><result name="FLM_DATEN_2">08 00 00 00 00 00 00 00 00 00 00 0C 00 80 1B 00 45 10 00 A6 0D 00 51 16 00 59 44 00 00 EB 00 00 CA 00 00 49 00 00 17 00 10 00 0C 00 05 00 04 00 06 00 02 00 01 00 00 00 00 12 00 00 3A…
Here!

New Data Types: Clickstream

Problems with Traditional DWHExpensive hardwareNo experiments permissableETL costly, slow and complex


Why Hadoop such a good fit?Volume: hugeVelocity: highVariety: semi-structuredHere: existing expertise in open source technologies
But: commodity hardware vs. specialised hardware?

HDInsight vs. Hadoop on Azure

Hadoop Deployment Options in AzureHDInsight Hadoop on Azure

Automated Deployment in AzureHDInsight
Need to KNOW configuration BEFORE deploying clusterPowerShellhttp://aka.ms/HDIpowershell
Azure Data Factory
Azure Automation
Hadoop on Azure
Hortonworks or Clouderahttps://github.com/lararubbelke/Azure-DDP/
on

Architecture

Requirements
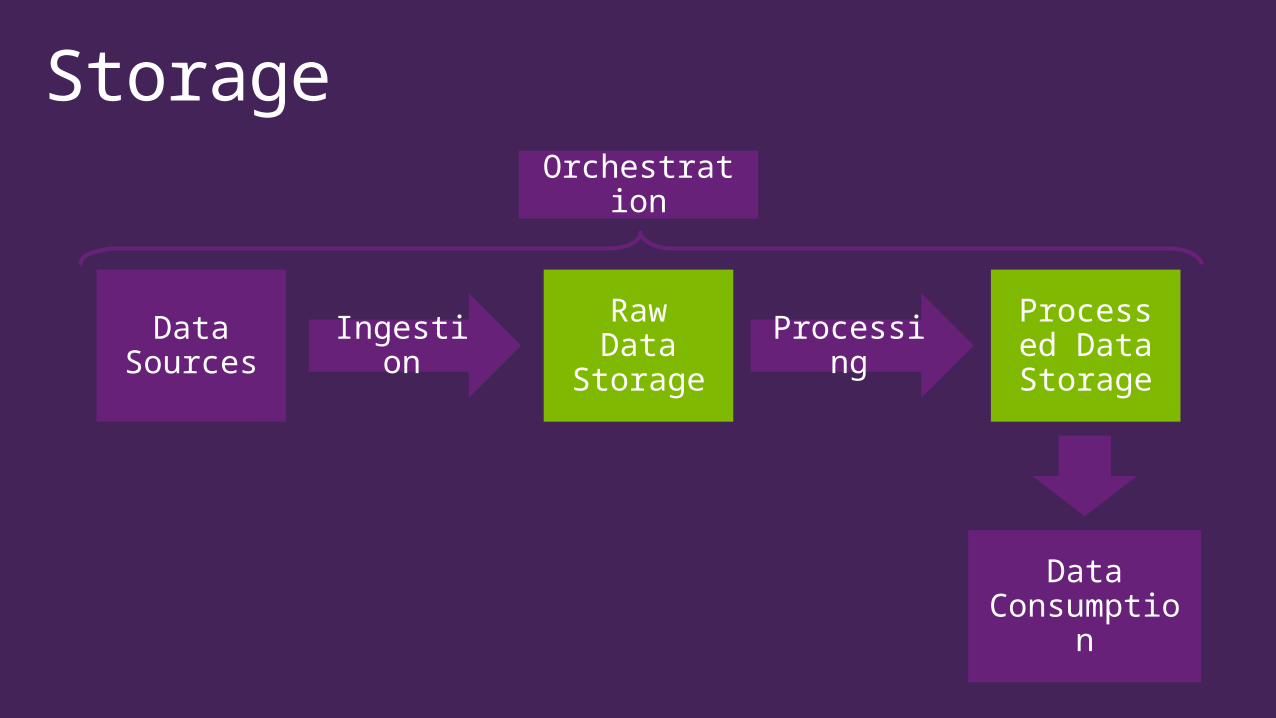
Data Sources Ingestion
Raw Data
Storage
Processing
Processed Data Storage
Data Consumptio
n
Orchestration

Agony of Choice

Requirements
Data Sources Ingestion
Raw Data
Storage
Processing
Processed Data Storage
Data Consumptio
n
Orchestration

Ingest

Ingest
Data Sources Ingestion
Raw Data
Storage
Processing
Processed Data Storage
Data Consumptio
n
Orchestration
Ingestion

Ingest – Data Sources
IIS Logs

Ingest – Requirements Fast loading performancePartitioningBlock size
TransformationCorrect data format (csv, text)

Ingest – Implementation
IIS Logs
Table Storage
Blob

Storage
Storage
Data Sources Ingestion
Raw Data
Storage
Processing
Processed Data Storage
Data Consumptio
n
Orchestration
Raw Data
Storage
Processed Data Storage

Data Storage – Raw & ProcessedDatabases Storage Account
SQL Azure
SQL IaaS
Table Storagehttp://aka.ms/HDItablestorage
Blob Storage
Others

“Size matters.”
.txt
.csv
.xml
.txt
.csv
.xmlNote: Hadoop does not do well with lots of small fileshttp://aka.ms/HDI_smallfiles

Processing

Processing
Data Sources Ingestion
Raw Data
Storage
Processing
Processed Data Storage
Data Consumptio
n
Orchestration
Processing
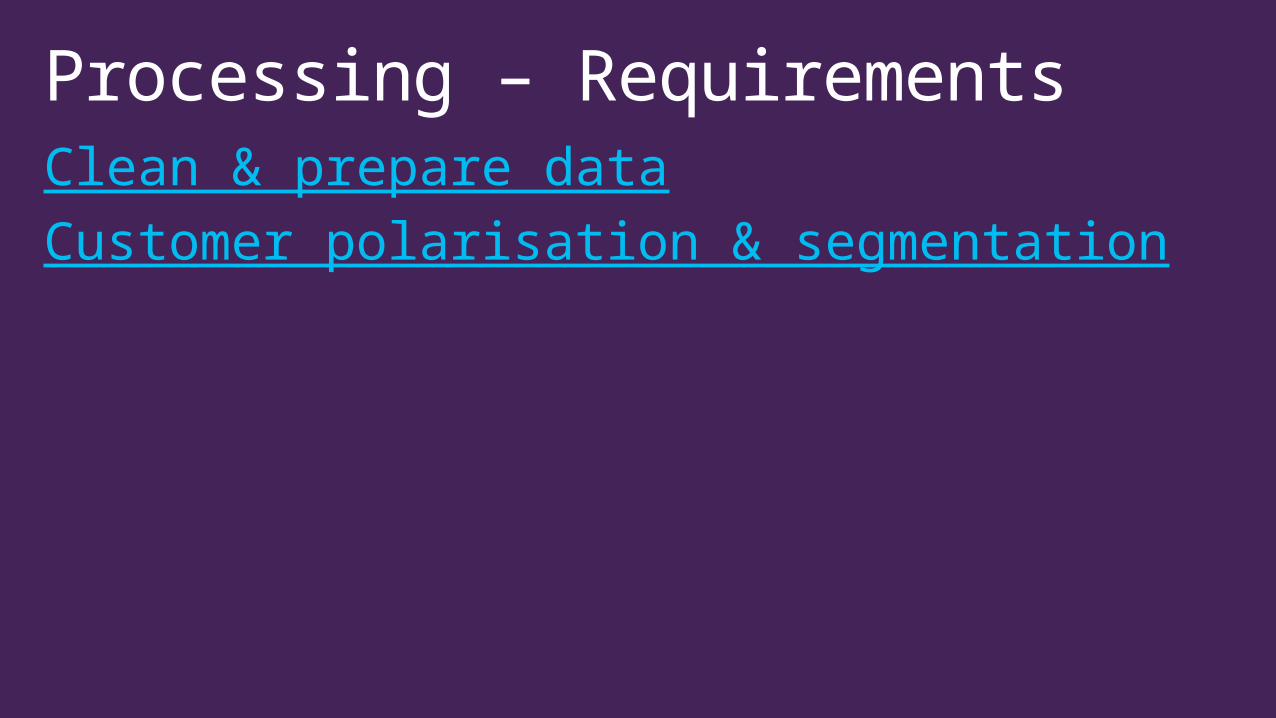
Processing – Requirements Clean & prepare dataCustomer polarisation & segmentation

Processing – Options

Pre-ProcessingClean the data

Hive
- SQL-like abstraction of MapReduce
- Compatible with other RDBMs
- Simple aggregations
- DBAs
- Complex Joins - Unstructured data- UDF is complex

Pig
- Slice & dicing (or complex query)
- Streaming objects- UDF- Software developers
- Integration with analytical tools/RDBMs

Why not combine?
Analytical type of workload
Preparing the data sets
Read and process data for the day
Large & growing fact tablesDWH type of workload
Feature vector per customerScoring and prioritisation

Advanced Processing,i.e. Analytics

Advanced Processing – Requirements

Customer segmentationProduct polarisation
Advanced Processing – Requirements

Analytics Options
MahoutOpen sourceWrite your own codeBy default on HDInsight
Azure Machine LearningVisual Composition: UI, Drag & DropModulesExtensible / Support for RSupport for CollaborationSupport for Data Science Process

Mahout: Similarity – Input

Mahout: Similarity – Job hadoop jar C:\apps\dist\mahout-0.9\mahout-examples-0.x-job.jarorg.apache.mahout.cf.taste.hadoop.similarity.item.
ItemSimilarityJob-s SIMILARITY_LOGLIKELIHOOD-i wasb:///user/hdp/testdata/userPrefs-o wasb:///user/hdp/testdata/output-m 200-mppu 100--tempDir wasb:///user/hdp/testdata/tempDir

Mahout: Similarity – Job hadoop jar C:\apps\dist\mahout-0.9\mahout-examples-0.x-job.jarorg.apache.mahout.cf.taste.hadoop.similarity.item.
ItemSimilarityJob-s SIMILARITY_LOGLIKELIHOOD-i wasb:///user/hdp/testdata/userPrefs-o wasb:///user/hdp/testdata/output-m 200-mppu 100--tempDir wasb:///user/hdp/testdata/tempDir
Distributed similarity measure
Version number of Mahout

Mahout: Similarity – Job hadoop jar C:\apps\dist\mahout-0.9\mahout-examples-0.x-job.jarorg.apache.mahout.cf.taste.hadoop.similarity.item.
ItemSimilarityJob-s SIMILARITY_LOGLIKELIHOOD-i wasb:///user/hdp/testdata/userPrefs-o wasb:///user/hdp/testdata/output-m 200-mppu 100--tempDir wasb:///user/hdp/testdata/tempDir
Input
Output

Mahout: Similarity – Job hadoop jar C:\apps\dist\mahout-0.9\mahout-examples-0.x-job.jarorg.apache.mahout.cf.taste.hadoop.similarity.item.
ItemSimilarityJob-s SIMILARITY_LOGLIKELIHOOD-i wasb:///user/hdp/testdata/userPrefs-o wasb:///user/hdp/testdata/output-m 200-mppu 100--tempDir wasb:///user/hdp/testdata/tempDir
Limit of #similar items per item
Max #preferences per user/item

Mahout: Similarity – Output

Mahout: Random Forest

1. Right location for data?2. Generate descriptor file3. Build forest4. Classify test data
Mahout: Random Forest

Mahout: Random Forest – (1) Data Locationhdfs dfs -cp wasb://<container>@<storage_account>.blob.core.windows.net/user/<remote_user>/testdata/KDDTrain+.arffwasb://<container>@<storage_account>.blob.core.windows.net/user/hdp/testdata/KDDTrain+.arff
hdfs dfs -cp wasb://<container>@<storage_account>.blob.core.windows.net/user/<remote_user>/testdata/KDDTest+.arff wasb://<container>@<storage_account>.blob.core.windows.net/user/hdp/testdata/KDDTest+.arff

Mahout: Random Forest – (2) Descriptor

Mahout: Random Forest – (2) Descriptorhadoop jar C:\apps\dist\mahout-0.9\mahout-core-0.9-job.jarorg.apache.mahout.classifier.df.tools.Describe -p wasb:///user/hdp/testdata/KDDTrain+.arff -f wasb:///user/hdp/testdata/KDDTrain+.info -d N 3 C 2 N C 4 N C 8 N 2 C 19 N L
Describing the columns

Mahout: Random Forest – (3) Build Foresthadoop jar
C:\apps\dist\mahout-0.9\mahout-examples-0.xx-job.jarorg.apache.mahout.classifier.df.mapreduce.BuildForest -Dmapred.max.split.size=1874231 -d wasb:///user/hdp/testdata/KDDTrain+.arff -ds wasb:///user/hdp/testdata/KDDTrain+.info -sl 5 -p -t 100 -o /user/hdp/nsl-forest

Mahout: Random Forest – (3) Build Foresthadoop jar
C:\apps\dist\mahout-0.9\mahout-examples-0.xx-job.jarorg.apache.mahout.classifier.df.mapreduce.BuildForest -Dmapred.max.split.size=1874231 -d wasb:///user/hdp/testdata/KDDTrain+.arff -ds wasb:///user/hdp/testdata/KDDTrain+.info -sl 5 -p -t 100 -o /user/hdp/nsl-forest
Leaf size

Mahout: Random Forest – (3) Build Foresthadoop jar
C:\apps\dist\mahout-0.9\mahout-examples-0.xx-job.jarorg.apache.mahout.classifier.df.mapreduce.BuildForest -Dmapred.max.split.size=1874231 -d wasb:///user/hdp/testdata/KDDTrain+.arff -ds wasb:///user/hdp/testdata/KDDTrain+.info -sl 5 -p -t 100 -o /user/hdp/nsl-forest
Data
Data Set

Mahout: Random Forest – (3) Build Foresthadoop jar
C:\apps\dist\mahout-0.9\mahout-examples-0.xx-job.jarorg.apache.mahout.classifier.df.mapreduce.BuildForest -Dmapred.max.split.size=1874231 -d wasb:///user/hdp/testdata/KDDTrain+.arff -ds wasb:///user/hdp/testdata/KDDTrain+.info -sl 5 -p -t 100 -o /user/hdp/nsl-forest
Selection #Trees
Partial
Output

Mahout: Random Forest – (4) Test Foresthadoop jar C:\apps\dist\mahout-0.9\mahout-examples-0.xx-job.jarorg.apache.mahout.classifier.df.mapreduce.TestForest-i wasb:///user/hdp/testdata/KDDTest+.arff-ds wasb:///user/hdp/testdata/KDDTrain+.info-m wasb:///user/hdp/nsl-forest -a -mr -o predictions

Mahout: Random Forest – (4) Test Foresthadoop jar C:\apps\dist\mahout-0.9\mahout-examples-0.xx-job.jarorg.apache.mahout.classifier.df.mapreduce.TestForest-i wasb:///user/hdp/testdata/KDDTest+.arff-ds wasb:///user/hdp/testdata/KDDTrain+.info-m wasb:///user/hdp/nsl-forest -a -mr -o predictions
Test Data
Data Set / Descriptor File
Forest Model

Mahout: Random Forest – (4) Test Foresthadoop jar C:\apps\dist\mahout-0.9\mahout-examples-0.xx-job.jarorg.apache.mahout.classifier.df.mapreduce.TestForest-i wasb:///user/hdp/testdata/KDDTest+.arff-ds wasb:///user/hdp/testdata/KDDTrain+.info-m wasb:///user/hdp/nsl-forest -a -mr -o predictions
Analysing theclassification results
Use MapReduce Jobs
Output

Mahout: Random Forest – (4) Test Forest
9,458 253
8,325
Predicted
4,508
normal anomaly
Actu
alnorm
al
an
om
aly

Mahout: Random Forest – (4) Test Forest
accuracy=#correctly classified instances#classified instances

Mahout: Random Forest – (4) Output
http://aka.ms/mahout

Put Together...

Polarisation and
segmentation
Scoring and prioritization
Read & process data for the day
Extract into outputs

Orchestration

Ingest
Data Sources Ingestion
Raw Data
Storage
Processing
Processed Data Storage
Data Consumptio
n
Orchestration
Orchestration

Deploy computeRun workloadMonitoringShut down services
Orchestration – Requirements

Orchestration – Options
PowerShell
AzureAutomation
AzureData Factory

Deploy Compute

PowerShell Deployment

HDInsight Configuration
Supported Configuration
Files(hadoop dist):
core-site.xmlhdfs-site.xmlmapred-site.xmlcapacity-scheduler.xml

HDInsight Configuration – Hive
Supported Configuration
Files(hive dist):
hive-site.xml

PowerShell Deployment – Configuration $coreConfig = @{
"io.compression.codec"="org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.BZip2Codec"; "io.sort.mb" = "1024";} $mapredConfig = new-object 'Microsoft.WindowsAzure.Management.HDInsight.Cmdlet.DataObjects.AzureHDInsightMapReduceConfiguration'$mapredConfig.Configuration = @{ "mapred.tasktracker.map.tasks.maximum"="2";} $clusterConfig = New-AzureHDInsightClusterConfig -ClusterSizeInNodes $numberNodes ` | Set-AzureHDInsightDefaultStorage -StorageAccountName $fqStorageAccountName -StorageAccountKey $storageAccountKey ` -StorageContainerName ($storageContainer.Name) $continueCheck = Read-Host "Attach additional storage accounts? (yes to continue)"
if ($continueCheck -eq "yes"){ foreach($asa in 1..5) { $newStorageAccountName = ($clusterPrefix + [DateTime]::Now.ToString("yyyyMMddHHmmss") + "a" + $asa) New-AzureStorageAccount -StorageAccountName $newStorageAccountName -Location "North Europe" $clusterConfig = $clusterConfig | Add-AzureHDInsightStorage ` -StorageAccountName ($newStorageAccountName + ".blob.core.windows.net") ` -StorageAccountKey (Get-AzureStorageKey $newStorageAccountName).Primary }}
$clusterConfig = $clusterConfig | Add-AzureHDInsightConfigValues -Core $coreConfig -MapReduce $mapredConfig # "At this point we are able to create a hdinsight cluster with a customised configuration"
Changing cluster configuration setting when deploying:
http://aka.ms/HDIconfiguration

Supported Configuration
Files(oozie dist):
oozie-site.xml
HDInsight Configuration – Oozie

Run & Monitor Workload
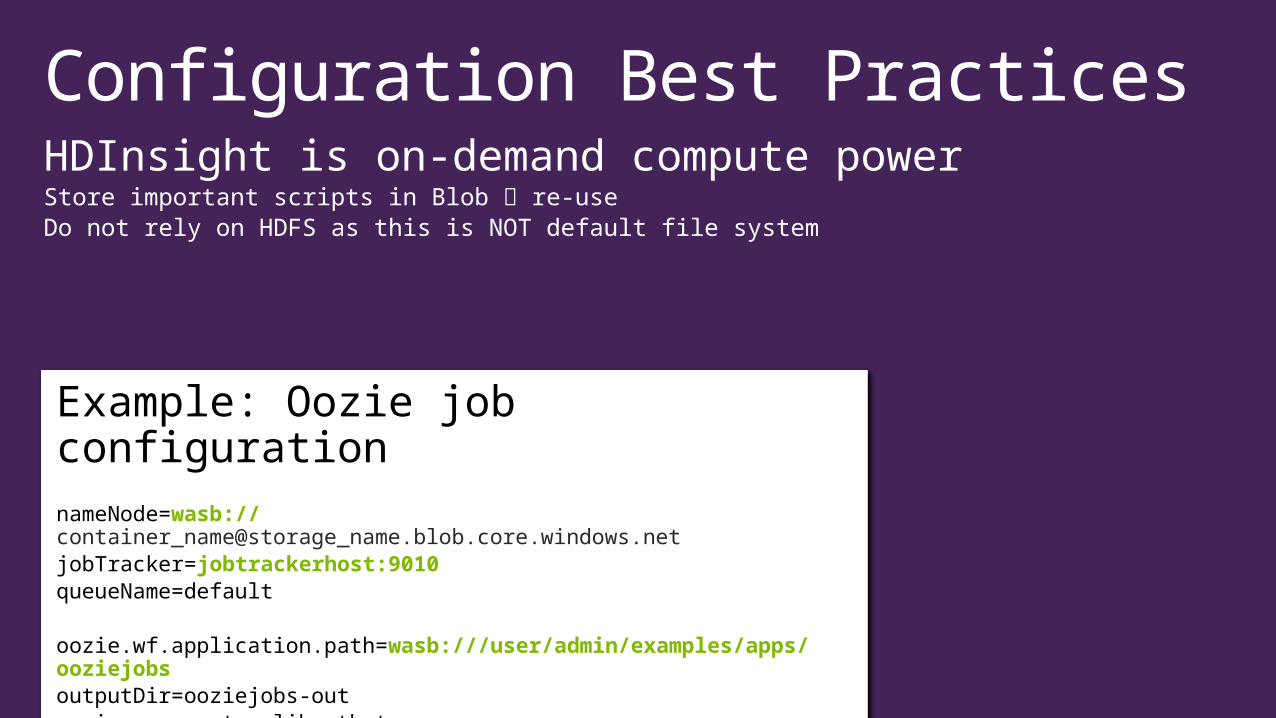
Configuration Best PracticesHDInsight is on-demand compute powerStore important scripts in Blob re-useDo not rely on HDFS as this is NOT default file system
Example: Oozie job configurationnameNode=wasb://container_name@storage_name.blob.core.windows.netjobTracker=jobtrackerhost:9010queueName=default oozie.wf.application.path=wasb:///user/admin/examples/apps/ooziejobsoutputDir=ooziejobs-outoozie.use.system.libpath=true

Automation: Self-Made
Provision Cluster
Run Hive/Pig Script
Shut down Cluster
Challenges
Troubleshooting cluster provisioning failures
Serialized workflow execution
Troubleshooting job failuresOozie or Hive/Pig
Company Infrastructure
HDInsightCluster

Automation: Azure Automation
Provision Cluster
Run Hive/Pig Script
Shut down Cluster
Challenges
Troubleshooting cluster provisioning failures
Serialized workflow execution
Troubleshooting job failuresOozie or Hive/Pig
Azure Automation HDInsightCluster
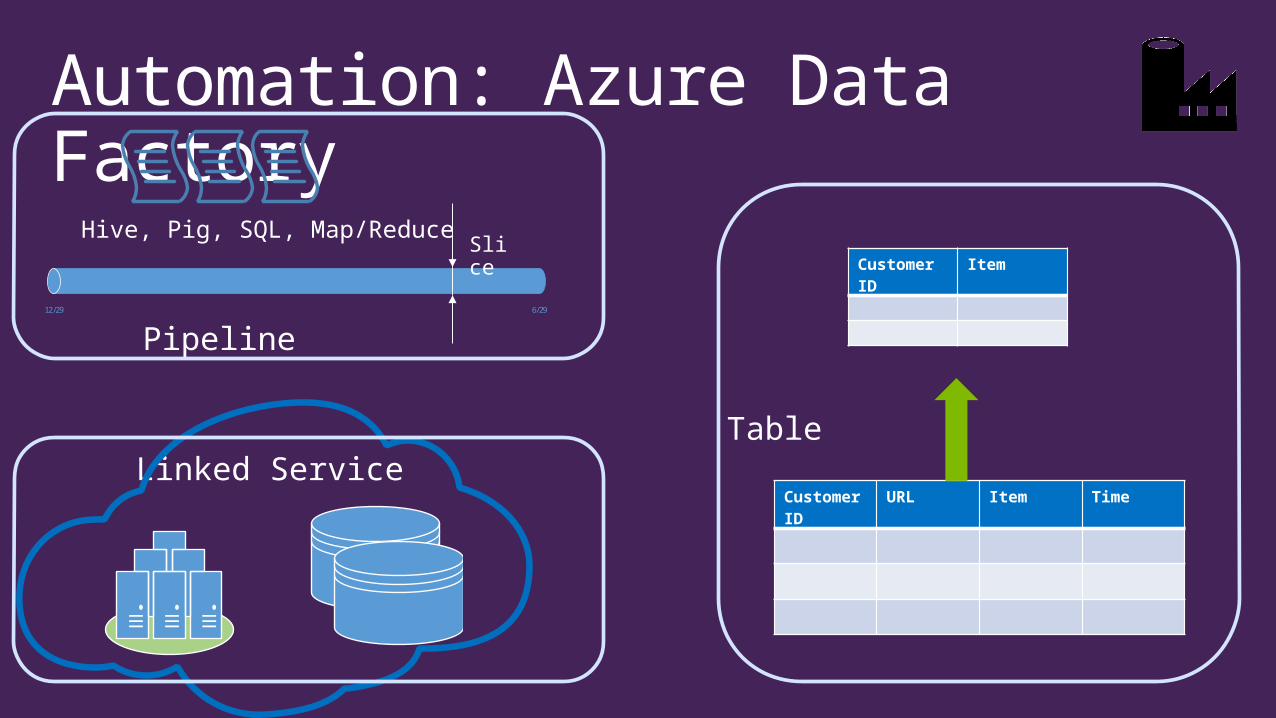
Automation: Azure Data Factory
Linked Service
Hive, Pig, SQL, Map/Reduce
12/29 6/29
Pipeline
Customer ID
URL Item Time
Customer ID
Item
Table
Slice

Automation: Azure Data Factory
Incoming Data
IIS Logs
IIS Logs

Validation & Troubleshooting
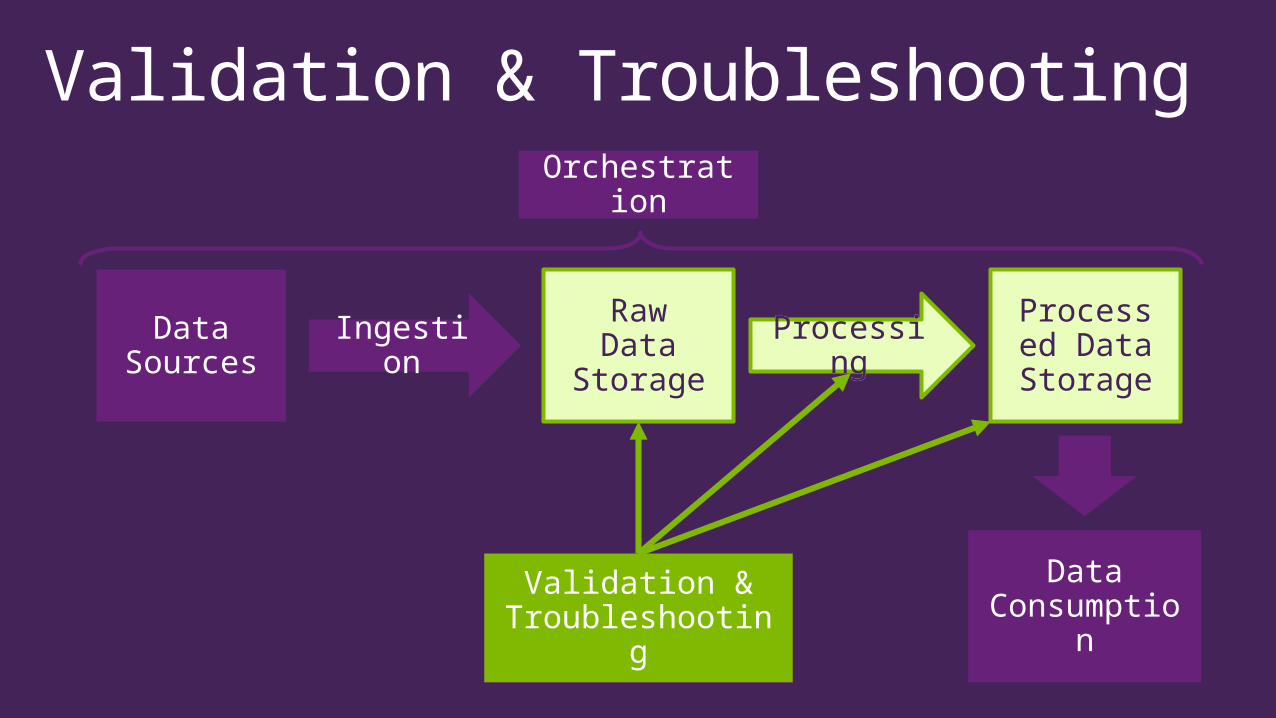
Validation & Troubleshooting
Data Sources Ingestion
Raw Data
Storage
Processing
Processed Data Storage
Data Consumptio
n
Orchestration
Validation & Troubleshooting
Raw Data
Storage
Processing
Processed Data Storage
Validation & Troubleshooting

Architectural Principles
Performance
How many cores does each workload use?
How much data ingested?
Scalability
How do I get more compute/storage?
Does workload utilize the capacities?
Manageability
PaaS almost takes care of itself.
Still needs managing, e.g. storage account

Monitoring and Troubleshooting
Compute
Mahout / Pig Calculations
I/O
HDFSIaaS VM max 16 TB of space
BlobDifferent latency and throughput characteristics

Troubleshooting Pig in Recommender
Data Sources Ingestion
Raw Data
Storage
Processing
Processed Data Storage
Data Consumptio
n
Orchestration
Validation & Troubleshooting

Troubleshooting Pig in Recommender
Product Data
Session Data
Consumer Data Segment
Blob
StorageBlob
Storage
Segment
Job fails after
running for 4
hours

Troubleshooting Pig in Recommender
Intelligent parallelismLogical PlanPhysical Plan
Reduce Plan may limit execution to single node
Product Data
Session Data
Consumer Data Segment
Blob
StorageBlob
Storage
Segment

Troubleshooting Storage
Data Sources Ingestion
Raw Data
Storage
Processing
Processed Data Storage
Data Consumptio
n
Orchestration
Validation & Troubleshooting
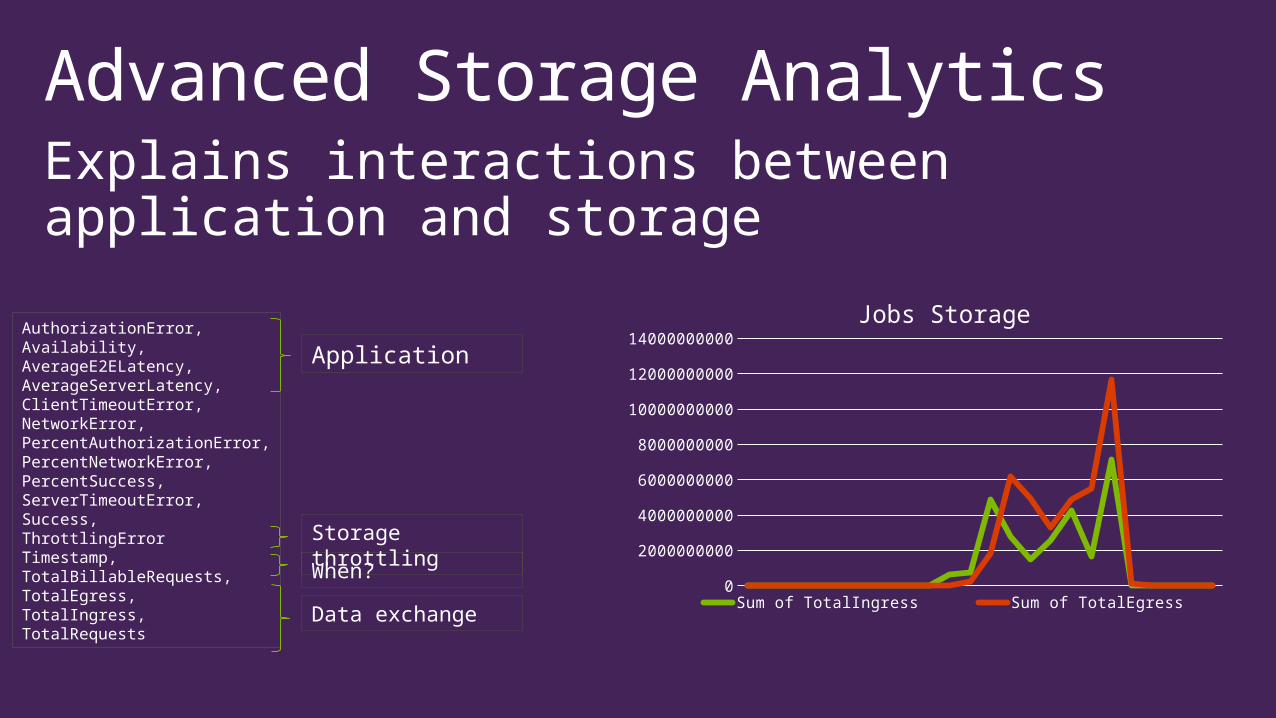
Advanced Storage AnalyticsExplains interactions between application and storage
AuthorizationError,Availability,AverageE2ELatency,AverageServerLatency,ClientTimeoutError,NetworkError,PercentAuthorizationError,PercentNetworkError,PercentSuccess,ServerTimeoutError,Success,ThrottlingErrorTimestamp,TotalBillableRequests,TotalEgress,TotalIngress,TotalRequests
Application
Storage throttling
When?
Data exchange0
2000000000
4000000000
6000000000
8000000000
10000000000
12000000000
14000000000
Jobs Storage
Sum of TotalIngress Sum of TotalEgress

Mapping Application and Storage Logs
0
200
400
600
800
1000
1200 Jobs StorageTotal
2014-03-26 22:28:37,321 INFO CallbackServlet:539 - USER[-] GROUP[-] TOKEN[-] APP[-] JOB[0000000-140326181153083-oozie-hdp-W] ACTION[0000000-140326181153083-oozie-hdp-W@pig-node-01] callback for action [0000000-140326181153083-oozie-hdp-W@pig-node-01]2014-03-26 22:28:37,472 INFO PigActionExecutor:539 - USER[Admin] GROUP[-] TOKEN[] APP[receipts-products-mahout] JOB[0000000-140326181153083-oozie-hdp-W] ACTION[0000000-140326181153083-oozie-hdp-W@pig-node-01] action completed, external ID [job_201403261811_0001]2014-03-26 22:28:37,562 WARN PigActionExecutor:542 - USER[Admin] GROUP[-] TOKEN[] APP[receipts-products-mahout] JOB[0000000-140326181153083-oozie-hdp-W] ACTION[0000000-140326181153083-oozie-hdp-W@pig-node-01]
Launcher ERROR, reason: Main class [org.apache.oozie.action.hadoop.PigMain], exit code [2]2014-03-26 22:28:38,101 INFO ActionEndXCommand:539 - USER[Admin] GROUP[-] TOKEN[] APP[receipts-products-mahout] JOB[0000000-140326181153083-oozie-hdp-W] ACTION[0000000-140326181153083-oozie-hdp-W@pig-node-01] ERROR is considered as FAILED for SLA2014-03-26 22:28:38,228 WARN JPAService:542 - USER[-] GROUP[-] TOKEN[-] APP[-] JOB[-] ACTION[-] JPAExecutor [WorkflowActionGetJPAExecutor]
ended with an active transaction, rolling back2014-03-26 22:28:38,343 INFO ActionStartXCommand:539 - USER[Admin] GROUP[-] TOKEN[] APP[receipts-products-mahout] JOB[0000000-140326181153083-oozie-hdp-W] ACTION[0
High Latency Timeout

Wrap Up
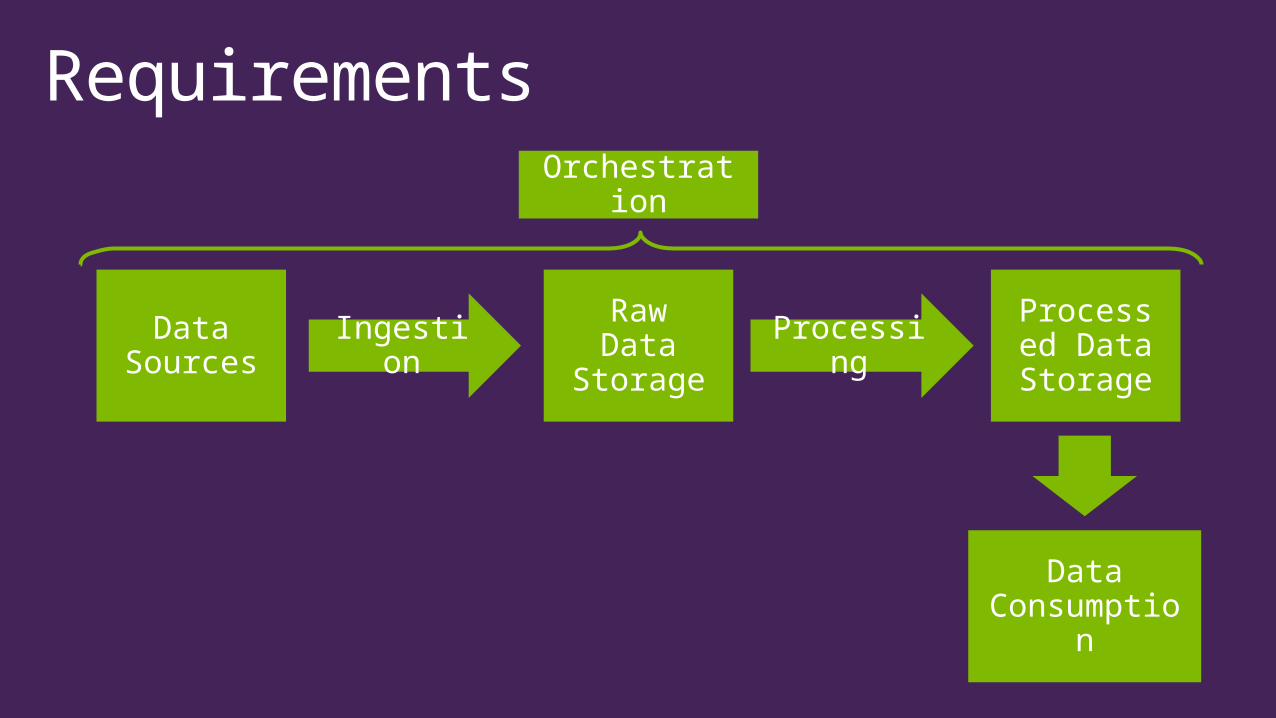
Requirements
Data Sources Ingestion
Raw Data
Storage
Processing
Processed Data Storage
Data Consumptio
n
Orchestration
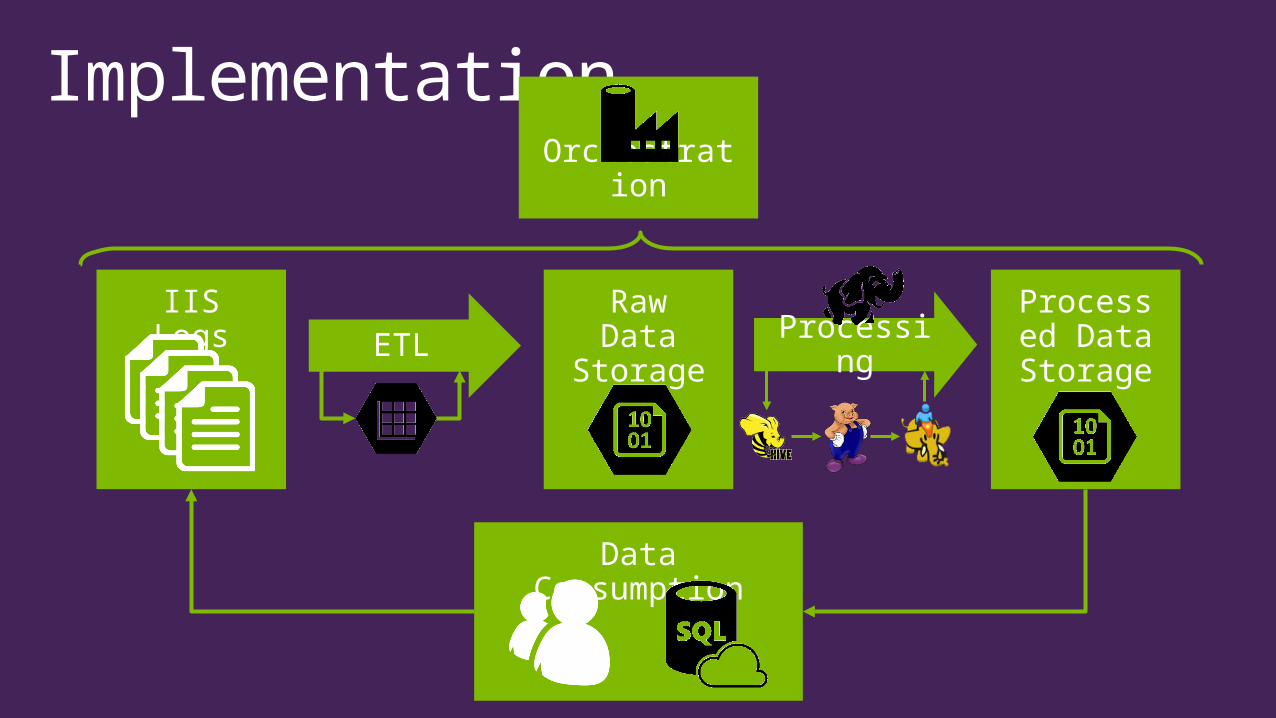
Implementation
IIS LogsETL
Raw Data
StorageProcessin
g
Processed Data Storage
Orchestration
Data Consumption

Olivia Klose http://blogs.technet.com/b/oliviaklose/
Further Information
Alexei Khalyako http://alexeikh.wordpress.com/
Big Data Support http://blogs.msdn.com/b/bigdatasupport/

© 2014 Microsoft Corporation. All rights reserved. Microsoft, Windows, and other product names are or may be registered trademarks and/or trademarks in the U.S. and/or other countries.The information herein is for informational purposes only and represents the current view of Microsoft Corporation as of the date of this presentation. Because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information provided after the date of this presentation. MICROSOFT MAKES NO WARRANTIES, EXPRESS, IMPLIED OR STATUTORY, AS TO THE INFORMATION IN THIS PRESENTATION.

















