26
The road to 980Mbps eVLBI The road to 980Mbps eVLBI Harro Verkouter Joint Institute for VLBI in Europe
| Date post: | 27-Mar-2015 |
| Category: |
Documents |
| Upload: | ariana-weeks |
| View: | 215 times |
| Download: | 1 times |

The road to 980Mbps eVLBIThe road to 980Mbps eVLBI
Harro Verkouter
Joint Institute for VLBI in Europe

How to get involved ...How to get involved ...
eVLBI demo at APAN conference 27/28 Aug 2007, in Xi'An
want to include Shanghai LP up but poor TCP/IP performance (2Mbps) lossy + out-of-order reception
investigate possibility of UDP transport suffers from those too
both TCP and UDP based on IP-datagrams
no retransmits/ramp-up/etc (no feedback!)

hacking Mark5A.chacking Mark5A.c
Haystack codebase does TCP reliably
should do UDP but didn't looked like coding was stopped halfway
reasonably easy to get it going revealed coding and UDP issues
race conditions lack of feedback packetloss

<blocksize> bytes
<n> blocks
Mk5 I/O board
while (1) {wait( n_empty>0 );
wait_for_blocksize_bytes();copy_block_to_mem();n_filled++;n_empty--;
}Read thread
Network
Write thread
while (1) {
wait( n_filled>0 );
send_block_chunks();n_empty++;n_filled--;
}
circular buffer in MEM (shared memory + semaphores 'n_empty' and 'n_filled')
indicates settable parametervia net_protocol= ...command

First UDP tests ...First UDP tests ...
unstable datatransfer to Sh LAN worked fine
10% loss at low datarate (≤256Mbps) not quite correlatable :(
packets never get “on the wire” sender doesn't know or care (no feedback!)
overwrites own sendbuffer
1Gbps standard “microbursts” not all equipment can handle this

Ratecontrol/packet spacing ...Ratecontrol/packet spacing ...
known that it was necessary Simon Casey and Richard H. Jones
APAN demo nearing (5 days to go) ... needed to get something, soon!
tried to be smart computing packet spacing t based on
datagramsize + linkrate need few s (MTU 1500, 1Gbps 12s)

t
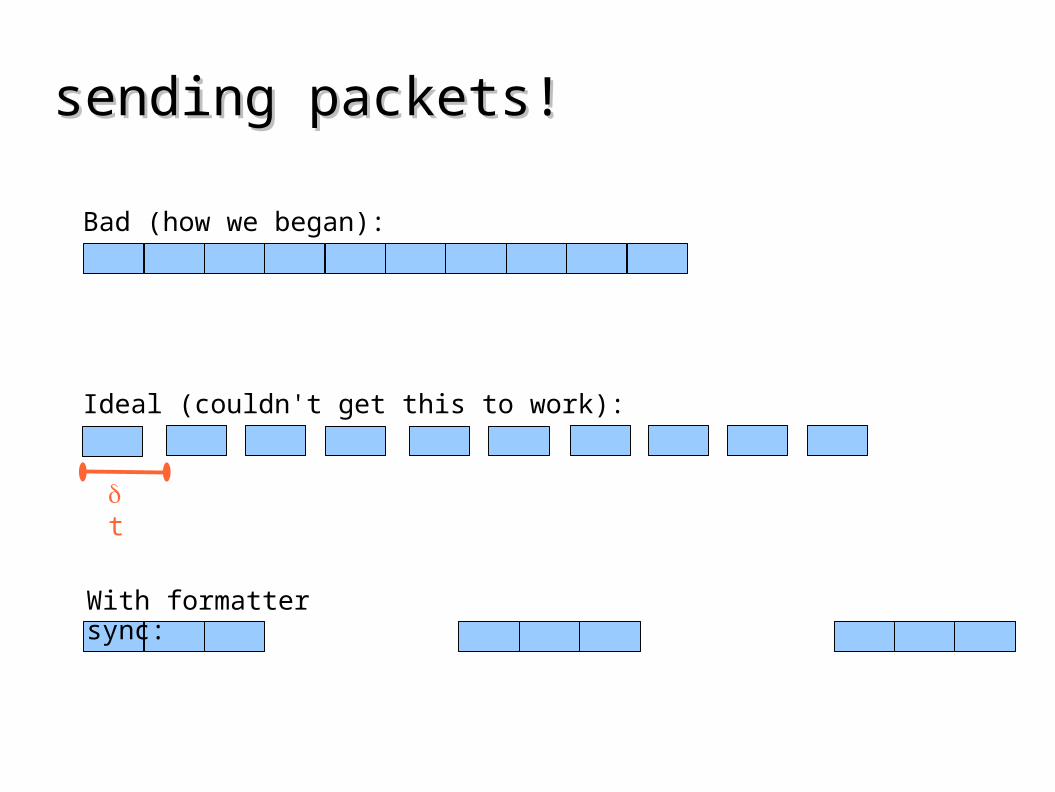
sending packetssending packets
Current:
Ideal:

Ratecontrol?!?Ratecontrol?!?
didn't work at all! Linux 2.4 ...
is not a RealTime OS (...) sleeps() quantized in units of 10ms
threads (==processes) scheduled @ 100Hz
now what?! how to synchronize sender? suddenly realized we have a near perfect
synchronous device ... the formatter + Mk5 I/O board

Ratecontrol?Ratecontrol?
remember the inter-thread circular buffer? n_empty + n_filled = n_total
now imagine ... n_total = 1
buffer degenerates into a mutex ... which means the block is either
filled from the I/O board synchronously at current bitrate!
or sent to the network

Ratecontrol!Ratecontrol!
worked amazingly well APAN demo @256Mbps
also solution for Ar 1Gbps NIC 155Mbps ATM
n_total = 2 blocksize = 1500 bytes
got 64Mbps (previously, with TCP, couldn't do eVLBI)
only good for datarates up to ~256Mbps
t
sending packets!sending packets!
Bad (how we began):
Ideal (couldn't get this to work):
With formatter sync:

Demo ok, UDP looks promising, but!Demo ok, UDP looks promising, but!
we had a bigger problem UDP transfer could not be restarted required killing + restarting Mark5A not suitable for operations
spent few weeks on the issue kept on getting (weird) streamstor failures
DMA errors, memorylock error, ...
made no progress at all

A new beginning?A new beginning?
write testprogram to investigate streamstor behaviour disk2net UDP multithreaded different thread synchronization
queue + condition variable
could not recreate streamstor failures transfers could be started/stopped at will

jive5a jive5a
extending the testprogram want to do in2net rather than disk2net
need to program the Mark5 I/O board mostly copied from Haystack's Mark5A
fairly easy to get it to work primary use eVLBI
needed net2out as well

Early october 2007Early october 2007
jive5a first used for eVLBI want to take it further
512Mbps still not operational switch 'collapsed' (PaulJIVE solved this)
(1) receiving end has to deal with packet loss out-of-order reception
(2) sending end has to space packets as evenly as possible

(1) need protocol for this ...(1) need protocol for this ...
sender + receiver agree on datagramsize added command for this
64bit sequence number in each datagram suffices to
detect + fix out-of-order reception detect + fix loss can do statistics

(2) Spacing the packets(2) Spacing the packets
sleep()'ing between packets not an option
whatever the solution prefer something portable if possible
good enough = good enough for(volatile int i=0; i<ipd; ++i);
does the job surprisingly well ...
gave us reliable 512Mbps allows per n-coreCPU/link finetuning


512? Check! Next stop: 1024512? Check! Next stop: 1024
1000BaseX links effectively ~980Mbps of userdata (UDP)
need to trow away a bit of data simplest approach
do not send a datagram every once in a while implement packet-drop-rate
if 0, drop every 1 in pdr packet too simplistic
correlator had problems staying in sync

1024 (the pdr version) – Dec 20071024 (the pdr version) – Dec 2007
smartened up the sender find headers in datastream on-the-fly
do not drop packet if it contains header drops packet at earliest convenience
worked! correlator stayed in sync with pdr~20 (5%)
does add CPU usage cannot do 1024 on 1CPU/PIII system anyway 2 core/cpu Mk5's can do this


Drawback of dropping randomly Drawback of dropping randomly
dropping not correlated between senders total loss of visibilities ~ twice the amount of
loss per station on the order of 10% ...
start thinking of dropping coherently dropping the same channel at each station
but that requires lot of extra CPU power needed at least 2 CPUs to begin with anyway

1024 by means of channeldropping?1024 by means of channeldropping?
not for the weak at heart ... specify 64bit bitmask
ones for the tracks you want to keep jive5a builds
list of shifts + masks to fill 'holes' in the mask generate c-source for (de)compressionfn invokes compiler to generate object file dynamically loads that back into itself

SRC: 00000000 01110110 01110110 01110110 01110110 01110110
DST: 01110110 00000000 00000000 00000000 00000000 00000000
SRC: 01110110 01110110 01110110 01110110 01110110 01110110
DST: 00000000 00000000 00000000 00000000 00000000 00000000
SRC: 00000000 01010100 01110110 01110110 01110110 01110110
DST: 11111110 00000000 00000000 00000000 00000000 00000000
SRC: 00000000 01110110 01110110 01110110 01110110 01110110 00100010DST: 01110110 00000000 00000000 00000000 00000000 00000000
SRC: 00000000 01010100 01110110 01110110 01110110 01110110 00000100DST: 11111110 00000000 00000000 00000000 00000000 00000000
SRC: 00000000 01010000 01110110 01110110 01110110 01110110 DST: 11111111 00000000 00000000 00000000 00000000 00000000
SRC: 00000000 01010000 01110110 01110110 01110110 01110110 DST: 11111111 00000000 00000000 00000000 00000000 00000000
SRC: 00000000 01010000 00000000 01110110 01110110 01110110 DST: 11111111 01110110 00000000 00000000 00000000 00000000
SRC: 00000000 01010000 00000000 01110110 01110110 01110110 00010000 DST: 11111111 01110110 00000000 00000000 00000000 00000000
SRC: 00000000 01000000 00000000 01110110 01110110 01110110 DST: 11111111 11110110 00000000 00000000 00000000 00000000
SRC: 00000000 01000000 00000000 01110110 01110110 01110110 01000000 DST: 11111111 11110110 00000000 00000000 00000000 00000000
SRC: 00000000 00000000 00000000 01110110 01110110 01110110 DST: 11111111 11111110 00000000 00000000 00000000 00000000

channel dropping resultschannel dropping results
Concept proven to work! requires extra, CPU intensive, thread 3 core/CPU system at minimum
correlates fine @512Mbps dropping 2x 2bits (out of 32) 11111111 11111111 01011111 01011111
at 1024Mbps correlator couldn't sync CPU and network keeping up Just Fine under investigation

Thank you for your patience!

















