Page 1
SOFT AND HARD FAULT DETECTION IN ANALOG CIRCUITS USING E
Register No: 14MAE0
in partial fulfilment
MASTER OF ENGINEERING
APPLIED ELECTRONICS Department of Electronics and Communication Engineering
KUMARAGURU COLLEGE OF TECHNOLOGY (An autonomous institution affiliated to Anna University, Chennai
ANNA UNIVERSITY: CHENNAI 600 025
i
SOFT AND HARD FAULT DETECTION IN ANALOG CIRCUITS USING EXTREME
LEARNING MACHINE
PROJECT REPORT
Submitted by
KALPANA V
Register No: 14MAE007
fulfilment for the requirement of award of the degree
of
MASTER OF ENGINEERING
in
APPLIED ELECTRONICS
Department of Electronics and Communication Engineering
KUMARAGURU COLLEGE OF TECHNOLOGY
An autonomous institution affiliated to Anna University, Chennai
COIMBATORE - 641 049
ANNA UNIVERSITY: CHENNAI 600 025
APRIL-2016
SOFT AND HARD FAULT DETECTION IN XTREME
Department of Electronics and Communication Engineering
An autonomous institution affiliated to Anna University, Chennai)
Page 2
ii
BONAFIDE CERTIFICATE
Certified that this project report titled “SOFT AND HARD FAULT DETECTION IN
ANALOG CIRCUITS USING EXTREME LEARNING MACHINE” is the bonafide
work of KALPANA V [Reg. No. 14MAE007] who carried out the research under my
supervision. Certified further, that to the best of my knowledge the work reported herein
does not form part of any other project or dissertation on the basis of which a degree or
award was conferred on an earlier occasion on this or any other candidate.
SIGNATURE SIGNATURE
Ms. M. SHANTHI, Dr. A.VASUKI,
ASSOCIATE PROFESSOR, HEAD OF THE DEPARTMENT,
Department of ECE, Department of ECE,
Kumaraguru College of Technology, Kumaraguru College of Technology,
Coimbatore-641 049. Coimbatore-641 049.
The Candidate with university Register No.14MAEOO7 is examined by us in the project
viva- voce examination held on.......................................
........................................ ...........................................
INTERNAL EXAMINER EXTERNAL EXAMINER
Page 3
iii
ACKNOWLEDGEMENT
My very first gratitude goes to God Almighty for giving me life, strength and the
enablement to carry out this work.
I wish to express my deep sense of gratitude to Dr.R.S.Kumar PhD, Principal,
Kumaraguru College of Technology, Coimbatore, for providing the facilities to conduct
this study.
I express my humble gratitude to Dr.A.Vasuki PhD, Head of the Department,
Electronics and Communication Engineering, Kumaraguru College of Technology,
Coimbatore, for facilitating conditions for carrying out the research work smoothly.
I am indeed grateful to my project guide, MS. M. Shanthi BE, Ms., (PhD)
Associate Professor, Department of Electronics and Communication Engineering,
Kumaraguru College of Technology, Coimbatore, for her immense contribution, guidance,
support and constructive criticism not only during this project but also during these two
years of my master program.
Finally, I would like to thank my friends and family for standing by me and
encouraging me throughout the project.
Page 4
iv
ABSTRACT
Analog electronic circuits have gained more importance with the recent
advancements in the System-on-Chip (SOC) technology. The advances in the deep
sub-micron level makes IC’s complex and testing on these small IC’s needs complex
functionality ,so testing becomes a very challenging task under the constraints of high
quality and low price. Many automatic testing tools are available for fault diagnosis in
digital circuits but only limited number of fault diagnosis techniques is available for
analog circuits. Fault diagnosis in analog circuit is challenging because of factors like
tolerance effects of analog components, limited number of test nodes, poor fault
models and nonlinearity issues. Accessing of nodes can be eliminated by using
simulation based methods. Parametric faults results in performance degradation and
catastrophic faults will lead to malfunctioning of the circuit, so diagnosis of such
faults based on simulation method is focused in this project.
Fault detection for the benchmark circuits using extreme learning machine
(ELM) and its variants self-adaptive evolutionary extreme learning machine (SaE-
ELM), kernel extreme learning machine (KELM) is proposed in this project. State
variable filter (SVF), Sallen-key band pass filter (SKBPF) and two stage CMOS
operational amplifier are used as benchmark circuits. Fault dictionary is constructed
from the circuit response and the created fault dictionary samples are separated in to
training and testing samples. These samples are normalised within the range -1 to 1
and imported to the algorithms for fault classification.
ELM is a single-hidden layer feed forward neural networks (SLFNs) which
randomly chooses the input nodes and analytically determines the output weights. The
obtained weights are used to detect faults in the benchmark circuits. ELM algorithms
tends to have better scalability and achieves much better generalization performance
at much faster learning speed than the other neural network algorithms.
Page 5
v
SaE-ELM is a variant of ELM and it improves the performance by optimizing
the features. Self adaptive differential evolution is used as the optimization technique
for optimizing the hidden node features. The optimized features are used for
computing the output weight by using the ELM algorithm. SaE-ELM algorithm has
higher classification performance compared to the ELM algorithm.
KELM is an infinite single-hidden layer feedforward neural network (SLFNs).
KELM improves the stability and performance by using kernel matrix instead of
computing the hidden layer matrix. Kernel matrix is a low-rank decomposition matrix
defined on the input features improves the generalization performance. KELM
provides higher classification accuracy and generalization performance than ELM
algorithm by minimizing the training error and output weight. The results of all the
three algorithms are compared and the results prove that KELM algorithm
outperformed other two algorithms in terms of generalization performance and
classification accuracy.
Page 6
vi
TABLE OF CONTENTS
CHAPTER
NO
TITLE PAGE NO
ABSTRACT iv
LIST OF TABLES viii
LIST OF FIGURES xi
LIST OF ABBREVIATION xiii
1 INTRODUCTION
1.1 Significance of Analog Circuits 1
1.2 Fault Diagnosis 2
1.3 Machine Learning 3
1.4 Evolutionary Algorithm 6
1.5 Outline of the Report 8
2 REVIEW OF LITERATURE
2.1Extreme Learning Machine: Theory And Applications 9
2.2 Test Generation Algorithm For Analog Systems Based On
Support Vector Machine
9
2.3 Analog Testing With Time Response Parameters 10
2.4 Analog Circuit Fault Diagnosis Using Support Vector
Machines Classifier
10
2.5 Test Generation For Linear Time Invariant Analog Circuits 10
2.6 Extreme Learning Machine For Regression And Multiclass
Classification
11
2.7 Optimization Method Based Extreme Learning Machine
For Classification
12
2.8 Gene Ranking And Classification Using Extreme Learning
Machine Algorithm
12
2.9 On The Kernel Extreme Machine Classifier 13
2.10 An Improved Kernel Based Extreme Learning Machine
For Robot Execution Failures
13
Page 7
vii
2.11 Self-Adaptive Differential Evolution Extreme Learning
Machine For The Classification Of Hyperspectral Images
13
2.12 Self-Adaptive Evolutionary Extreme Learning Machine 14
2.13 Wavelet Based Fault Detection In Analog VLSI Circuits
Using Neural Networks
14
3 ANALOG CIRCUIT FAULT CLASSIFICATION
3.1 Fault Diagnostic System 15
3.2 Fault Models In Analog And Mixed Signal Systems 16
3.3 Fault Diagnosis Techniques 19
3.4 Benchmark Circuits 22
3.5 CMOS Operational Amplifier 26
3.6 Fault Classification 30
3.7 Benchmark Datasets 32
4 EXTREME LEARNING MACHINE
4.1Mathematical Model 40
4.2 ELM Algorithm 42
4.3 Simulation Results 46
5 SELF ADAPTIVE EVOLUTIONARY EXTREME
LEARNING MACHINE
5.1Differential Evolution 51
5.2 SaE-ELM 54
5.3 Simulation Results 57
6 KERNEL EXTREME LEARNING MACHINE
6.1Extreme Learning Machine 71
6.2 Kernel Extreme Learning Machine 71
6.3 Simulation Results 73
6.4 Performance comparison of proposed methodologies 86
7 CONCLUSION 92
REFERENCES 93
LIST OF PUBLICATIONS 95
Page 8
viii
LIST OF TABLES
TABLE NO. NAME PAGE NO.
3.1 Specifications for CMOS Opamp 27
3.2 Device Sizes for Two stage Opamp 29
3.3 Datasets for benchmark circuits 33
3.4 SVF single fault index 34
3.5 CMOS -Fault model and the fault index 38
3.6 CMOS – sample fault dictionary for stuck
open fault model
38
3.7 CMOS – sample fault dictionary for stuck
short fault model
39
4.1 SVF Double fault- Performance
comparisons for different activation
function
47
4.2 SKBPF Single Fault- Performance
comparisons for different activation
function
49
4.3 CMOS Opamp- Performance comparisons
for different activation function
50
5.1 SVF single Fault -Training data results 61
5.2 SVF single Fault - Testing data results 62
5.3 SVF Double Fault- Training data results 63
5.4 SVF Double Fault- Testing data results 63
5.5 SKBPF Single Fault- Training data results 65
5.6 SKBPF Single Fault- Testing data results 65
Page 9
ix
5.7 SKBPF Double Fault- Training data
results
67
5.8 SKBPF Double Fault - Testing data results 67
5.9 CMOS Opamp- Training Results 69
5.10 CMOS Opamp- Testing Results 70
6.1 SVF Single Fault – Performance measures
for varied Kernel Parameter
75
6.2 SVF single fault- Training data results 76
6.3 SVF single fault- Testing data results 76
6.4 SVF double fault- Training data results 77
6.5 SVF double fault- Testing data results 78
6.6 SKBPF single Fault- Training data results 79
6.7 SKBPF single Fault- Testing data results 80
6.8 SKBPF double Fault- Training data results 82
6.9 SKBPF double Fault- Testing data results 83
6.10 CMOS Opamp- Training Results 84
6.11 CMOS Opamp- Testing Results 85
6.12 Single Fault-Training Results Comparison
with Accuracy and error
87
6.13 Single Fault-Training Results Comparison
with Precision, Sensitivity and Specificity
87
6.14 Single Fault-Testing Results Comparison
with Accuracy and error
89
6.15 Single Fault-Testing Results Comparison 89
Page 10
x
with Precision, Sensitivity and Specificity
6.16 Double Fault-Training Results
Comparison with Accuracy and error
90
6.17 Double Fault-Training Results
Comparison with Precision, Sensitivity
and Specificity
90
6.18 Double Fault-Testing Results Comparison
with Accuracy and error
90
6.19 Double Fault-Training Results
Comparison with Precision, Sensitivity
and Specificity
91
Page 11
xi
LIST OF FIGURES
Figure No Figure Name Page No
1.1 Testing Framework 3
1.2 Supervised Learning Model 4
1.3 Unsupervised Learning Model 5
1.4 Evolutionary Algorithm Structure 6
3.1 Stuck open and stuck short fault models in resistor
and capacitor.
18
3.2 stuck open and stuck short fault models for
MOSFET
18
3.3 Fault Diagnosis Techniques 19
3.4 State Variable Filter Circuit 23
3.5 Sallen Key Band Pass Filter Circuit 25
3.6 Two Stage CMOS Opamp 29
3.7 Fault Dictionary Generation-Flow Diagram 31
3.8 CMOS Opamp Fault Dictionary Generation-Flow
Diagram
32
3.9 Two stage opamp fault free response 36
3.10 Two stage opamp- M1 Stuck open fault response 37
3.11 Two stage opamp- M3 Stuck short fault response 37
4.1 ELM Architecture 41
4.2 Sigmoid Activation Function 43
4.3 Sine Activation Function 44
4.4 Hard limit Activation Function 44
4.5 Triangular Basis Activation Function 45
4.6 Radial Basis Activation Function 45
4.7 ELM algorithm Steps 46
4.8 SVF Single -Fault Performance for different
activation function
47
4.9 Training accuracies for different hidden nodes 48
Page 12
xii
4.10 Testing accuracies for different hidden nodes 48
4.11 SKBPF Double -Fault Performance comparison
for different activation functions
50
5.1 General Confusion matrix 58
5.2 SVF Single Fault- Training and Testing
Performances for different MAX-FES
61
5.3 SVF Double Faults- Average Training and Testing
Results
64
5.4 SKBPF Single Fault- Training and Testing
performance for each fault index
66
5.5 SKBPF Double Faults-Training and Testing
Results
68
6.1 KELM and ELM algorithm steps 74
6.2 SVF Single Fault – Training and Testing
accuracies for varied Kernel Parameter
75
6.3 SVF Double Faults- Average Training and Testing
Performance measures
79
6.4 SKBPF Single Fault- Training and Testing
accuracy performances for each fault indexes
81
6.5 SKBPF Double Faults- Average Training and
Testing Performance
83
6.6 SVF Single Fault-Training Results Comparison 87
6.7 SKBPF Single Fault-Training Results Comparison 88
6.8 CMOS Single Fault-Training Results Comparison 88
6.9 SVF Double Faults-Testing Results Comparison 91
6.10 SVF Double Faults-Testing Results Comparison 91
Page 13
xiii
LIST OF ABBREVIATIONS
ABBREVIATIONS
NOMENCLATURE
VLSI
Very Large Scale Integration
AMS
Analog and Mixed Signals
CUT
Circuit Under Test
IC
Integrated Circuits
LPO
Low Pass Output
LS-SVM
Least Square Support Vector Machine
SAT
Simulation After Test
SBT
Simulation Before Test
ELM
Extreme Learning Machine
SaE-ELM
Self adaptive Evolutionary Extreme Learning Machine
KELM
Kernel Extreme Learning Machine
SKBPF
Sallen-Key Band Pass Filter
SVF
State Variable Filter
CMOS
Complementary Metal Oxide Semiconductor
OPAMP
Operational Amplifier
VCVS
Voltage-Controlled Voltage-Source
Page 14
1
CHAPTER 1
INTRODUCTION
Analog circuits have gained more importance with the advancements in
System-On-Chip technology. Testing of analog circuits in the very large scale
integration (VLSI) circuits is a very challenging task. The increasing complexity of
analog circuitry, increase in number of applications of analog circuits and the
integration of analog and digital circuits on a single chip (SOC) has made analog
testing an important process in the design and production in the manufacturing of
integrated circuits. Testing of analog circuit is not fully automated as compared to
digital testing and the cost of analog testing is very high.
The real world signals are analog in nature and there are wide number of
analog applications. The analog testing is costly because the test equipment is quite
expensive and the test development and test production of analog circuits takes long
time. The development and production test time constitute a part of the development
and production costs of integrated circuits respectively. The challenge faced by test
engineer is to develop a test methodology to reduce the test cost and accelerate the
time-to-market without sacrificing integrated circuit (IC) quality. Consequently, the
generation and evaluation of an effective test methodology is a very important issue in
the production of an IC and has direct consequences on the price and quality of the
final product
1.1 SIGNIFICANCE OF ANALOG CIRCUITS
Analog circuits play a vital role in industries. They are used for implementing
controllers, conditioning signals, protecting circuit modules and have gained
popularity. Analog and mixed signals are used in many applications like customer
electronics, biomedical equipments, wireless communications, networking,
multimedia, automotive process control and real-time control system. There are many
automated fault diagnosis methods are available for digital circuits but fault diagnosis
methods for analog and mixed circuits are still underdeveloped. Analog and mixed
signals (AMS) ICs are gaining popularity recently in many applications like customer
Page 15
2
electronics, biomedical equipments, wireless communications, networking,
multimedia, automotive process control and real-time control system. Such
advancements arise testing of analog and digital circuits together. There are very
limited numbers of testing tools available for analog and mixed signal circuits. So
analog testing demands substantial research and needs improved development in the
area of fault diagnosis. There are two methods available for performing testing in
analog circuits, they are Specifications based testing and functional testing. The
specification based testing is performed mainly to check the whether the circuit or
design has met the specifications. The functional testing is performed to check the
functionality of the circuit with the standard input.
1.2 FAULT DIAGNOSIS
Fault diagnosis of analog circuits has been one of the most challenging topics
for researchers and test engineers since the 1970s and it is essential for analog and
mixed systems. Fault diagnosis is the process of obtaining the exact information about
the faulty circuit with the limited measured circuit responses with the given circuit
topology and nominal circuit parameters. There are three distinct stages in the process
of fault diagnosis. They are
Fault detection
Fault identification
Parameter evaluation.
Fault detection is the process to find out if the circuit under test (CUT) is faulty
compared to the fault free circuit. Fault identification is performed to locate the faulty
parameters are inside the faulty circuit and Parameter evaluation is performed to
obtain how much the faulty parameters are deviated from their nominal values. The
bottlenecks of analog circuit fault diagnosis primarily lie in the inherited features of
analog circuits. The main features of analog circuits are non-linearity, parameter
tolerances, limited accessible nodes and lack of efficient models. Several fault
diagnosis methods are available for analog circuits. Parametric faults and catastrophic
faults are the two types of fault classes that widely exist in analog circuit. Among the
Page 16
3
different fault diagnosis methods, Simulation After Test (SAT) and Simulation Before
Test (SBT) approach are the two fault diagnosis approaches are extensively used for
fault diagnosis in analog testing.
Diagnosis of parametric and catastrophic faults using the SBT fault diagnosis
approach for the two filter circuits and CMOS-operational amplifier circuit is carried
out in this project using proposed methodologies. The figure 1.1 shows the various
steps involved in the fault diagnosis. The features are extracted from the benchmark
circuits and the fault classification is performed by the extreme learning machine
(ELM), self-adaptive evolutionary extreme learning machine (SAE-ELM) and kernel
extreme learning machine (KELM) and the performance of all the classifiers are
analysed in this project.
1.3 MACHINE LEARNING
Machine learning is a type of artificial intelligence (AI) used in the field
computer science, probability theory, and optimization theory which allows complex
tasks to be solved for which a logical/procedural approach would not be possible or
feasible. Machine learning focuses on the development of computer programs that can
teach themselves to grow and change when exposed to new data. Machine learning
uses the data to detect patterns in data and adjust program actions
Fault
Dictionary Performance
Evaluation
Feature Extraction
Circuit under
Test
Transfer
function
Induce Fault
Simulation
Fault Classification
Normalise fault
dictionary
Fault
Classification
using ELM
Figure 1.1 Testing Framework
Page 17
4
accordingly. Machine learning algorithms are categorized as supervised or
unsupervised.
1.3.1 SUPERVISED LEARNING
Supervised learning algorithm analyzes the training data and produces an
inferred function, which can be used for mapping new examples. The figure 1.2 shows
the typical supervised learning model. The main aim of supervised learning algorithm
is to build a model that makes predictions based on the learning. From the figure, the
known set of inputs (Text, image or any other data) and their responses are given to
the algorithm. The algorithm trains the model to generate reasonable predictions for
the response of new data.
1.3.2 UNSUPERVISED LEARNING
Unsupervised learning algorithm draws inferences from the datasets consisting
of input data without labelled responses. Since the examples given to the learner are
unlabeled, there is no error or reward signal to evaluate the potential solution. The
figure 1.3 shows the unsupervised learning model. The inputs (Text, image, etc) are
given as input to the model without any label. The inputs are grouped in to several
Figure 1.2 Supervised Learning Model
Page 18
5
groups based on some criteria or some learning model and the algorithm adapts to the
data and trains if any new input is given to the algorithm based on the statistical
properties.
There are many machine learning algorithms they are Decision tree learning,
Association rule learning, Artificial neural network or neural network , Support vector
machines, Clustering , Sparse dictionary learning.
Artificial neural networks are computational models inspired by biological
neural networks are used to approximate functions that are generally unknown. A
special type of single layer feed forward neural network called Extreme learning
machines (ELM) and its variants SAE-ELM and KELM is proposed in this work.
ELM is one the recent successful approach in machine learning for
classification because of its low computational time and higher classification
accuracy. ELM is used in varied fields like in image processing for pattern
classification; in medical imaging for the electrocardiogram beat classification, etc.
ELM for analog circuit fault classification is proposed in this project.
Figure 1.3 Unsupervised Learning Model
Page 19
6
1.4 EVOLUTIONARY ALGORITHM
Evolutionary algorithms (EA) are stochastic search methods that mimic the
metaphor of natural biological evolution. In artificial intelligence, EA is a subset of
evolutionary computation, a generic population-based metaheuristic optimization
algorithm. Evolutionary algorithms operate on a population of potential solutions
applying the principle of survival of the fittest to produce better and better
approximations to a solution. At each generation, a new set of approximations is
created by the process of selecting individuals according to their level of fitness in the
problem domain and breeding them together using operators borrowed from natural
genetics. This process leads to the evolution of populations of individuals that are
better suited to their environment than the individuals that they were created from, just
as in natural adaptation.
Evolutionary algorithms model natural processes, such as selection,
recombination, mutation, migration, locality and neighbourhood. Figure 1.4 shows the
structure of a simple evolutionary algorithm. Evolutionary algorithms work on
populations of individuals instead of single solutions. In this way the search is
performed in a parallel manner.
At the beginning of the computation a number of individuals (the population)
are randomly initialized. The objective function is then evaluated for these
Figure1. 4 Evolutionary Algorithm Structure
Page 20
7
individuals. The first/initial generation is produced. If the optimization criteria are not
met the creation of a new generation starts. Individuals are selected according to their
fitness for the production of offspring. Parents are recombined to produce offspring.
All offspring will be mutated with a certain probability. The fitness of the offspring is
then computed. The offspring are inserted into the population replacing the parents,
producing a new generation. This cycle is performed until the optimization criteria are
reached.
Evolutionary algorithms differ substantially from more traditional search and
optimization methods. The most significant differences are:
Evolutionary algorithms search a population of points in parallel, not just a
single point.
Evolutionary algorithms do not require derivative information or other
auxiliary knowledge; only the objective function and corresponding fitness
levels influence the directions of search.
Evolutionary algorithms use probabilistic transition rules, not deterministic
ones.
Evolutionary algorithms are generally more straightforward to apply, because
no restrictions for the definition of the objective function exist.
Evolutionary algorithms can provide a number of potential solutions to a given
problem. The final choice is left to the user. (Thus, in cases where the
particular problem does not have one individual solution, for example a family
of pareto-optimal solutions, as in the case of multi-objective optimization and
scheduling problems, then the evolutionary algorithm is potentially useful for
identifying these alternative solutions simultaneously).
The evolutionary algorithms are used along with machine learning
algorithms to improve the performance of the algorithms by optimizing the
features. There are many evolutionary algorithms like particle swarm
optimization, differential evolution, etc. Self adaptive differential evolution
Page 21
8
(SADE) is a type of evolutionary algorithm used in this project to optimize the
hidden node features to improve the performance of the algorithm.
1.5 OUTLINE OF THE REPORT
The third chapter deals with the fault diagnosis and fault classification
methods, the benchmark circuits and their details and the data sets generated from the
benchmark circuits. Chapter 4 presents the proposed methodology ELM with the
simulation results. Chapter 5 deals with the SAE-ELM along with the simulation
results for the generated data sets. Chapter 6 introduces KELM and this chapter also
contains the result of proposed method KELM and it also includes the comparison
results of all the proposed methodologies. Finally the chapter 7 concludes the project
work with the performance analysis of all the proposed algorithms.
Page 22
9
CHAPTER 2
REVIEW OF LITERATURE
2.1 EXTREME LEARNING MACHINE: THEORY AND APPLICATIONS
This paper proposes a new learning algorithm called extreme learning machine
which overcomes the drawbacks of feed forward neural network [5]. The main
drawback of the feed forward neural is slow gradient-based learning algorithms are
used to train the network and the parameters are tuned using iteratively. Extreme
learning machine for single-hidden layer feed forward neural network (SLFN)
randomly chooses hidden nodes and output weights of SLFN are determined
analytically. This algorithm provides good generalization performance at extremely
fast learning speed. The experimental results based on a few artificial and real
benchmark function approximation and classification problems, including very large
complex applications show that the new algorithm can produce good generalization
performance in most cases and can learn thousands of times faster than conventional
popular learning algorithms for feed forward neural networks. The traditional classic
gradient-based learning algorithms may face several issues like local minima,
improper learning rate and over fitting, etc. In order to avoid these issues, some
methods such as weight decay and early stopping methods may need to be used often
in these classical learning algorithms. The ELM tends to reach the solutions
straightforward without such trivial issues. The ELM learning algorithm looks much
simpler than most learning algorithms for feed forward neural networks. A simple
comparison between the ELM and SVM has also been conducted in our simulations,
showing that the ELM may learn faster than SVM by a factor up to thousands.
2.2 TEST GENERATION ALGORITHM FOR ANALOG SYSTEMS BASED
ON SUPPORT VECTOR MACHINE
Ting Long, Houjun Wang and Bing Long (2010) proposed a test generation
algorithm based on SVM. The test patterns are generated using test generation
algorithm which uses input stimuli and sampled output responses for DUT
classification and fault detection [3]. This approach gives effective results compared
Page 23
10
to traditional algorithms when the response of normal circuit and faulty circuits are
similar. It also proposes an algorithm for calculating test sequence for input stimuli
using the SVM results. Precision of test generation is enhanced using numerical
experiments. SVM method can be used for classification for the problems like mixed
response spaces and non-linear classification problems. The advantage of SVM test
generation method is that the output responses of the DUT can be used directly for
classification and fault detection. Experiments show that the algorithm has good
classification performance compared to other algorithms.
2.3 ANALOG TESTING WITH TIME RESPONSE PARAMETERS
This paper presents a simple test generation algorithm which derives sinusoidal
test waveform [4]. The amplitude and phase errors are obtained from the steady state
time response waveform which helps in the classification of large number of faults.
Parameters like delay, rise-time and overshoot are the criteria for faulty behaviour and
this faulty behaviour is detected using time saturated ramp waveforms as tests and the
use of associated ramp response. All these parameters are computed using simple
algorithms from closed form expressions of the sinusoidal and ramp response.
2.4 ANALOG CIRCUIT FAULT DIAGNOSIS USING SUPPORT VECTOR
MACHINES CLASSIFIER
A novel approach of analog circuit fault diagnosis using support vector
machines classifier is based on constructing dynamic test signals for analog circuits
[8]. The integral measure for characterising time-domain signal of minmax
formulation is used for dynamic test. A sub-optimal strategy is used to construct time
test waveforms. This approach can be used to construct input signals for an on-chip
test scheme or for the selection of an external stimulus applied through an arbitrary
waveform generator.
2.5 TEST GENERATION FOR LINEAR TIME INVARIANT ANALOG
CIRCUITS
Chen-Yang Pan and Kwang-Ting (1999) Cheng proposed a novel and cost
effective testing technique for parametric faults which generates small number of test
patterns in multidimensional space using hyperplanes [2]. Hyperplanes are derived
Page 24
11
using search based heuristic and it defines the acceptance region in the measurement
space. The coefficients of hyperplanes are used as test patterns to classify DUT
whether it is in the acceptance region or not. The major goal of this approach is to find
test sets to achieve desired level of correct classification with minimal test application
time and this objective is achieved by successive application of each test set. Residual
response exists after the application of last pattern in each test because of the finite
bandwidth of DUT. The residual response of previous test might affect the output
response of the current test and may cause measurement errors. Time duration of
residual response is inversely proportional to bandwidth and this causes delay in next
test set. The next test measurement cannot start unless residual response becomes
negligible. This observation implies that the overall test application is reduced which
limits the speed of the approach. This approach generalises that arbitrarily linear
independent vectors can be used as the test sequence. The test sequence using linear
independent vectors have identical ability of classification to that obtained by using
hyperplanes. This approach results less than 10% misclassification using several test
sets from hyperplanes or sampled points on a sinusoidal signal and each consists of a
small number of test patterns.
2.6 EXTREME LEARNING MACHINE FOR REGRESSION AND
MULTICLASS CLASSIFICATION
In this paper a new regression algorithm called ELM (Extreme Learning
Machine) is presented. ELM is a single-hidden-layer feed forward networks (SLFNs),
has hidden layer called feature mapping need not be tuned. This paper describes that
ELM provides a unified learning platform it can be applied for regression and
Multiclass classification applications and it has milder optimization constraints
compared to LS-SVM and PSVM [6]. Compared to ELM, LS-SVM and PSVM
achieve suboptimal solutions and require higher computational complexity and ELM
can approximate any target continuous function and classify any disjoint regions. The
simulation results verifies that ELM has better scalability and achieve similar or better
generalisation performance at much faster learning speed than traditional SVM and
LS-SVM.
Page 25
12
2.7 OPTIMIZATION METHOD BASED EXTREME LEARNING MACHINE
FOR CLASSIFICATION
G.B Huang, X.Ding and H.Zhou (2010) proposed a least square based
approach called extreme learning machine for training feed forward networks [7].
Extreme learning machine (ELM) shows good performance in regression and
classification applications. ELM is a single-hidden layer feed forward networks
(SLFNs), hidden nodes in ELM are randomly generated and universal approximation
capability is guaranteed. This paper shows further studies in ELM and extends it to
specific type of generalised SLFNs called support vector network. This paper shows
that SVM’s maximal margin property and minimal norm of weights theory of feed
forward neural networks are consistent under ELM learning framework and ELM has
special separability feature and it has less optimization constraints compared to SVM.
The simulation results prove that ELM used for classification tends to achieve better
generalization performance than traditional SVM. It is proven that ELM for
classification is less sensitive to user specified parameters and it can be implemented
easily.
In SVM some of the training data may not be linearly separable so it permits
training error. In ELM, all the training data are linearly separable and it also permits
training error to eliminate possible over fitting and to minimize test errors to improve
generalization performance. Thus this paper shows that in ELM to minimize the norm
of output weights in ELM classification is actually to maximize the distance of the
separating margin of two different classes in the ELM feature space and it also shows
that separating hyper plane tends to pass through the origin of ELM feature space
which results in less optimization constraints and better generalization performance
which is less sensitive to learning parameters.
2.8 GENE RANKING AND CLASSIFICATION USING EXTREME
LEARNING MACHINE ALGORITHM
This paper shows the use Extreme Learning Machines (ELM) algorithm for
resolving bioinformatics and biomedical multicategory classification problems [9].
The three gene microarray data sets are used for multicategory classification using
ELM. The result shows that ELM has good performance with better accuracies and
Page 26
13
produces output in minimum time compared to other artificial neural network methods
and it is less sensitive to parameters.
2.9 ON THE KERNEL EXTREME MACHINE CLASSIFIER
This paper discusses about the kernel version of the ELM classifier with SLFN
of infinite hidden layer [11]. The kernel matrix is computed using the kernel
formulation and the activation function and the obtained kernel matrix is a low –rank
matrix. The algorithm is executed on the different data sets like Libras, Madelon,
Opt.Digits, segmentation and the results indicate that the low-rank decomposition
based ELM space leads to best performance when compared to the standard random
input weights generation.
2.10 AN IMPROVED KERNEL BASED EXTREME LEARNING MACHINE
FOR ROBOT EXECUTION FAILURES
This paper introduces novel KELM algorithm along with particle swarm
optimization approach for the classification or prediction of robot execution failures
[12]. This algorithm produces higher accuracy when the learning samples are very
limited and even with the erroneous data. The higher accuracy of the algorithm is
mainly due to the parameters of the kernel function, these parameters of the neural
network are adjusted for searching the optimal values by particle swarm optimization
technique. The simulation results indicate that the algorithm shows better accuracy
compared to the other traditional neural network and ELM algorithms.
2.11 SELF-ADAPTIVE DIFFERENTIAL EVOLUTION EXTREME
LEARNING MACHINE FOR THE CLASSIFICATION OF
HYPERSPECTRAL IMAGES
In this paper an efficient approach for classification of hyperspectral images
using extreme learning machine (ELM) and differential evolution is proposed[13].
The ELM is used for classification and regression and gives analytical solution in
compact form but the main problem with the ELM is the selection issue associated
with it, to overcome the selection issue differential evolution optimization is
implemented along with the algorithm. The paper uses self adaptive control
mechanism to change the control parameters during the run time. The experimental
Page 27
14
results indicate that the elm along with differential evolution optimization technique
gives better classification accuracy in less time than SVM.
2.12 SELF-ADAPTIVE EVOLUTIONARY EXTREME LEARNING
MACHINE
Self adaptive evolutionary extreme learning machine (SaE-ELM) for single
hidden layer neural network is proposed in this paper which optimizes the hidden
node parameters using self-adaptive differential algorithm [14]. The trial vector
strategies and the control parameters are self adapted from the strategy pool by
learning from the previous experience which generates promising solutions and the
network output weights are calculated using ELM. SaE-ELM outperforms the other
algorithms and it also avoids limitations existed in E-ELM and DE-ELM which
manually chooses the trail vectors and the control parameters. This paper concludes
that it can improve the network generalization performance and it extends the future
work that it can reduce the training time by implementing efficient technique.
2.13 WAVELET BASED FAULT DETECTION IN ANALOG VLSI CIRCUITS
USING NEURAL NETWORKS
This paper uses wavelet transform for analog circuit response and the fault
detection is performed using artificial neural network [15]. The wavelet coefficients
obtained from the two benchmark circuits operational amplifier and state variable
filter for fault free and faulty cases are used for training the neural network. Two
neural network architectures back propagation and probabilistic neural networks are
used for training the data. The neural network architecture is used for fault detection
for both catastrophic faults and parametric faults. The proposed method shows high
performance for both the faults compared to the other methods of neral network.
Page 28
15
CHAPTER 3
ANALOG CIRCUIT FAULT CLASSIFICATION
3.1 FAULT DIAGNOSTIC SYSTEM
Test can be performed at several levels of IC fabrication like wafer level,
package level, module level, and system level. Testing of circuits means the
identification of faults in the circuit. A fault is a change in the value of the component
from the nominal value which results in the failure of the circuit. Every system is
liable to faults. Fault can be identified by fault diagnostic system and it has many
other tasks. The different tasks in fault diagnostic system are
1. Fault detection
2. Fault isolation
3. Fault identification
4. Fault prediction
5. Fault explanation
6. Fault remediation
7. Fault classification.
3.1.1 FAULT DETECTION
Fault detection is the process of detecting the abnormal behaviour of the
circuit. The fault detection is performed by comparing the responses of circuit under
test with the fault free circuit and the result indicates whether the circuit is fault free or
faulty.
3.1.2 FAULT ISOLATION
Fault isolation is used to identify the faulty component and maps it to the
physical region in the circuit.
3.1.3 FAULT IDENTIFICATION
Fault identification is the process of identifying faulty component in the circuit.
Page 29
16
3.1.4 FAULT PREDICTION
Fault prediction is the process of monitoring the circuit’s response continuously
to predict the abnormal behaviour of the circuit and to monitor the circuit parameter.
3.1.5 FAULT EXPLANATION
Fault explanation involves the generation of information which helps the test
engineer to understand the link between the current diagnosis and symptoms of the
circuit.
3.1.6 FAULT SIMULATION
Fault simulation is used to simulate hypothetical fault in the circuit with the
help of fault model output from the fault identification process.
3.2 FAULT MODELS IN ANALOG AND MIXED SIGNAL SYSTEMS
Faults in the analog integrated circuits may occur due to defects in the
manufacturing process which leads to failures. Faults may also occur due to defective
components, breaks in signal lines, lines shortened to ground or power supply, short
circuiting of signal lines, excessive delays, etc. The faults are classified based on the
effect they have on the functionality of the circuit. There are three types of faults.
They are temporary faults, delay faults and permanent faults.
3.2.1 TEMPORARY FAULTS
The temporary faults are those faults which are transient and exist only for a
short duration of time.
3.2.2 DELAY FAULTS
The faults which have impact on the operating speed of the circuit are called
delay faults.
Page 30
17
3.2.3 PERMANENT FAULTS
Permanent faults are those type of faults which are present in the circuit long
enough to be observed during the test time. There are two types of permanent faults,
they are catastrophic faults and parametric faults.
3.2.3.1 CATASTROPHIC FAULTS
Catastrophic faults are the changes in the circuit that cause the circuit to fail
catastrophically. They are also called as hard faults and these faults include shorts,
opens or large variations in design parameters. These faults are caused by major
structural deformations or extreme out-of-range parameters and lead to
malfunctioning of the circuit. Electro-migration and particle contamination
phenomena occurring in the conducting and metallisation layers are the major causes
of opens and bridging circuits. Catastrophic faults are further classified in to stuck-
open and stuck-short faults.
3.2.3.1a STUCK-OPEN FAULTS
The stuck open fault is the fault in which the component terminals are out of
contact with the rest of the circuit which creates a high resistance at the incident of the
fault in the circuit. Open faults can be simulated by adding a high resistance in series
(Rs =100 MΩ) with the component to be faulted.
3.2.3.1b STUCK-SHORT FAULTS
The stuck short fault is the short between the terminals of the component. It is
essentially shorting out the component from the circuit. Short faults can be simulated
by adding a small resistance in parallel (Rp =1Ω) with the component.
The stuck-open and stuck-short faults can be simulated in a resistor,
capacitor, MOSFET. The figure 3.1 shows the stuck-open and stuck short faults for
resistor and capacitor.
Page 31
18
The figure 3.2 shows stuck open and short fault models for MOSFET device.
The stuck open fault in MOSFET can be modelled by connecting high resistance in
series either to the drain or source of the component.
3.2.3.2 PARAMETRIC FAULTS
Parametric faults are the statistical variations in the manufacturing process
conditions that cause performance degradation of the circuit. These faults mainly
because of aging, manufacturing tolerances or parasitic effects and they are also called
as soft faults. These faults involve parameters deviations from their nominal value
which exceeds from their tolerance band. These faults result from local and global
defects. Global parametric faults are due to imperfect process control in IC
Figure 3.2 stuck open and stuck short fault models for MOSFET
Figure 3.1 stuck open and stuck short fault models in resistor and capacitor.
Page 32
manufacturing. These defects affect
parametric faults are due to local defect mechanism, like particles that enlarge a
transistor’s channel length.
3.3 FAULT DIAGNOSIS TECHNIQUES
The current approach to detect manufacturing faults in electronic circuit uses
several forms of Automatic Test Equipments (ATE), In
Functional Tester (FT). ICT require physical access to notes or points on the circuit in
order to perform the necessary testing.
generally classified into two types. They are
1. Simulation-After
2. Simulation-Before
Figure 3.
The figure 3.3 shows the various fault diagnosis techniques and the approaches
for fault detection and classification
3.3.1 SIMULATION-AFTER
In SAT approach simulation is performed to identify the network parameters
and it is carried out at the time of testing. The component values are used for fault
SAT
approach
Parameter Identification
Technique
Fault Verfication Technique
19
These defects affect all the transistors and capacitors on a die.
e due to local defect mechanism, like particles that enlarge a
FAULT DIAGNOSIS TECHNIQUES
The current approach to detect manufacturing faults in electronic circuit uses
several forms of Automatic Test Equipments (ATE), In-Circuit Tester (ICT) and
Functional Tester (FT). ICT require physical access to notes or points on the circuit in
order to perform the necessary testing. Analog fault diagnosis approaches are
generally classified into two types. They are
After-Test (SAT)
Before-Test (SBT).
Figure 3.3 Fault Diagnosis Techniques
The figure 3.3 shows the various fault diagnosis techniques and the approaches
classification.
AFTER-TEST (SAT)
In SAT approach simulation is performed to identify the network parameters
and it is carried out at the time of testing. The component values are used for fault
Fault Diagnosis Technique
SAT
approach
Fault Verfication Technique
Optimization Technique
SBT
approach
Fault Dictionary Technique
all the transistors and capacitors on a die. Local
e due to local defect mechanism, like particles that enlarge a
The current approach to detect manufacturing faults in electronic circuit uses
it Tester (ICT) and
Functional Tester (FT). ICT require physical access to notes or points on the circuit in
Analog fault diagnosis approaches are
The figure 3.3 shows the various fault diagnosis techniques and the approaches
In SAT approach simulation is performed to identify the network parameters
and it is carried out at the time of testing. The component values are used for fault
SBT
approach
Statistical Technique
Page 33
20
detection and these values are measured from the voltage and current measurements.
The components are identified as fault components if the range exceeds the tolerance
limit. SAT method is also called as topological method because it uses circuit
topology for fault identification.
There are three methods of SAT used for fault diagnosis. They are
1. Parameter Identification Technique
2. Fault Verification Technique
3. Optimization Technique.
3.3.1.1 PARAMETRIC IDENTIFICATION TECHNIQUES
Parameter identification technique works on the basis that it identifies all the
network parameters from the available independent variables. Parameter identification
technique is classified in to two types based on the nature of diagnosis equations.
They are linear and non-linear techniques. Star-delta transformation and component
simulation techniques are generally used for linear technique and gives globally
unique solution. For non-linear technique methods like DC testing, Time-Domain
testing and Multi-Frequency are generally used and it produces unique solution. The
major problem in parameter identification is the ability to access test points. There are
not enough test points to test all components are each added test points is too
expensive to accept.
3.3.1.2 FAULT VERIFICATION TECHNIQUES
All the parameters cannot be identified if the measurements are limited. Fault
verification techniques assume that only limited number of parameters is faulty and
rest of the parameters are fault free. In this technique the whole circuit is partitioned in
to two groups called group 1 and group 2. This process of grouping is done at each
level of testing. Among the two groups group 1 consists of fault free components
(nominal components) and group 2 consists of faulty components. The measurements
and characteristics of group 1 are used to calculate the input and output from group 2.
If the parameters of both the group are similar then the parameters from the group 2
Page 34
21
are shifted to group 1 and this process is repeated until satisfactory verification is
achieved. Network theory, Graph theory, Mathematical theory are used in this
technique. Rank technique, New Decomposition technique and Failure Bound
technique are the some of the fault verification techniques commonly used.
3.3.1.3 OPTIMIZATION TECHNIQUE
Optimization technique is used to find most likely fault elements. L2
approximation technique, Quadratic approximation technique and L1 are most widely
used optimization techniques for fault classification. The L2 approximation technique
uses weighted base squares criterion to identify the changes in the network by solving
system of linear equations. The L1 approximation uses quadratic optimization and L1
norm technique in identifying the norm of the network elements. The elements are
said to be faulty if the changes from nominal value is large.
3.3.2 SIMULATION-BEFORE-TEST (SBT)
SBT methods are based on building a fault dictionary in which the nominal
circuit behaviours in DC, frequency or time domain are stored. The fault dictionary
also consists of the responses of the circuit for various anticipated faults. There are
two important SBT methods used for fault diagnosis. They are
1. Fault Dictionary Technique
2. The Statistical Approach
3.3.2.1 FAULT DICTIONARY TECCHNIQUE
Fault dictionary technique consists of fault free and anticipated faulty cases of a
circuit under test. The anticipated faulty cases are based on the field experience gained
by the engineer. Fault simulation plays an important role in the construction of fault
dictionary. The efficiency and effectiveness of the technique depends on many factors.
The main factors are proper choice of stimulus, selection of test measurement
optimization and fault isolation. The selection of test node or test frequency is the
important test measurement in this technique. The number of test measurement helps
in isolating the maximum number of faults and this measurement increases the fault
Page 35
22
dictionary size and helps in detecting all types of faults. Optimization is performed in
the test measurement technique to remove the redundant measurement or the
measurement that do not help in fault isolation. This optimization feature helps in
reducing the size of fault dictionary which helps in saving the memory resources and
increasing the speed at which fault isolation takes place. Fault diagnosis is performed
by comparing the actual readings with the values in the fault dictionary.
3.3.2.2 THE STATISTICAL APPROACH
The statistical approach is based on constructing the statistical database or fault
dictionary by performing large number of simulations to characterise the network
statistically. The statistical database helps in obtaining the probability error in each
and every component of the circuit. The component with highest probability is
considered as faulty component.
3.4 BENCHMARK CIRCUITS
Fault diagnosis techniques are applied to the benchmark circuits. State variable
filter, Sallen key band pass filer and CMOS operational amplifier are taken as
benchmark circuits to identify parametric faults and catastrophic faults respectively.
3.4.1 STATE VARIABLE FILTER
3.4.1.1 SVF CIRCUIT
The state variable filter (SVF) is a type of multiple-feedback filter circuit that
can produce all three filter responses, Low Pass, High Pass and Band Pass
simultaneously from the same single active filter design. State variable filters use
three (or more) operational amplifier circuits (the active element) cascaded together to
produce the individual filter outputs but if required an additional summing amplifier
can also be added to produce a fourth Notch filter output response as well.
State variable filters are second-order RC active filters consisting of two
identical op-amp integrators each one acting as a first-order, single-pole low pass
filter, a summing amplifier around which we can set the filters gain and its damping
Page 36
23
feedback network. The output signals from all three op-amp stages are fed back to the
input allowing us to define the state of the circuit. The figure 3.4 shows the schematic
of SVF circuit.
The main advantages of a state variable filter design is that all three of the
filters main parameters, Gain (K), corner frequency ( ƒC ) and the filters selectivity
(Q) can be adjusted or set independently without affecting the filters performance. An
added advantage over bi-quad section filters is that only one coefficient is needed,
rather than their five coefficients.
3.4.1.2 SVF TRANSFER FUNCTION
The transfer function is the ratio of output voltage to the input voltage. Any
Linear time invariant system can be described as a state-space model, with n state
variables for an nth-order system. The low pass and high pass output’s are phase
inverted while the band pass output maintains the in phase. The gain of each output is
independently variable. Due to temperature variation, component value may vary but
must be in tolerance limit.
Figure 3.4 State Variable Filter Circuit
Page 37
24
The nominal values of the circuit components are:
R1 = R2 = R3 = R4 = R5 = 10kΩ;
R6 = 3kΩ;
R7 = 7kΩ;
C1 = C2 = 20nF.
All the parameters were assigned ±10% tolerance.
The voltage transfer function of the second-order SVF (Fig 3.3.), considering its
low-pass output (LPO) is given by
VLPO
Vinput=
−R5
R1
⎣⎢⎢⎢⎢⎢⎡
R2 R5⁄R3C1R4C2
s +1 +
R2R5
+R2R1
s
1 +R7R6
R3C1+
R2 R5⁄R3C1R4C2
⎦⎥⎥⎥⎥⎥⎤
(3.1)
Comparing the equation.5.1 with second order low-pass filter transfer function, we
get the following relations for k, ὠ0 and Q.
Gain, K =R5
R1 (3.2)
Pole frequency, ὠ = R2 R5⁄
R3C1R4C2 (3.3)
Pole selectivity, Q = 31
422
5
1 +76
1 +25
+21
(3.4)
Therefore for the LPO of filter with nominal values of the components yields k= 1.0, Q
= 1.11 and fo = 796HZ.
3.4.2 SALLEN-KEY BANDPASS FILTER
3.4.2.1 SKBPF CIRCUIT
The Sallen–Key filter is also known as voltage control –voltage source (VCVS)
topology. The Sallen-key filter is used to implement second –order active filter and
this filter uses unity gain voltage amplifier with infinite input impedance and zero
output impedance. It can be used to implement low-pass, band-pass and high-pass
Page 38
25
structure. The super-unity-gain amplifier allows for very high Q factor and passes
band gain without the use of inductors. The Sallen-Key band pass filter structure
shown in figure 3.5 is mainly used because the section gain is fixed by the other
design parameters, and there is a wide spread in component values, especially
capacitors.
3.4.2.2 SKBPF Transfer Function
The nominal values of the circuit components are given below:
R1 = 5.6kΩ;
R2 = 1kΩ;
R3 = 2.2kΩ;
R4 = R5 = 3.9kΩ;
C1 = C2 = 10 nF.
All the components were assigned ±5%.
The voltage transfer function of the Sallen- key band pass filter circuit is given
by
Figure 3.5 Sallen Key Band Pass Filter Circuit
~
R1
R4
R2
-5V
R5
+5V
Output
R2
C1
C1 Vinput
1k
5.6
10
2.2
10
3.9
3.9
Page 39
26
21321
21
12132311
2
1
1111
)(
)()(
1
CCRRR
RRs
CR
k
CRCRCRs
CR
ks
sV
sVsH
in
o
(3.5)
Comparing equation.5.5 with second order BPF transfer function, we get the
following relations for K, ὠ0, and Q.
11
,CR
kKGain (3.6)
21321
21,CCRRR
RRncyPoleFreque p
(3.7)
12231311
21321
21
1111,
CR
k
CRCRCR
CCRRR
RR
QivityPoleselect p
(3.8)
Therefore for the SKBPF of the filter with nominal values of the components yields k
= 75,987, Q = 8.34 and fo = 25HZ.
The parameters gain, pole frequency and pole selectivity gives poor results. So
the pole parameters with real part and imaginary part are used as the input parameter
in the fault dictionary creation for fault diagnosis in SKBPF.
3.5 CMOS OPERATIONAL AMPLIFIER
Operational amplifiers are key elements in analog processing systems. In
analog and mixed signal systems, an operational amplifier is commonly used to
amplify small signals, to add or subtract voltages and in active filtering. The CMOS
opamp is the most important building block of linear CMOS and switched capacitor
circuits. The two stage CMOS opamp is a simple and robust technology providing
good values for most of its electrical parameters. Two stage opamp adopt miller
compensation to achieve stability in closed loop conditions. The simplest
Page 40
27
compensation technique for two stage opamp is to connect a capacitor across the high
gain stage.
3.5.1 DESIGN PROCEDURE
The design procedure begins by choosing device length to be used throughout
the circuit. Because transistor modelling varies strongly with channel length, the
selection of device length to be use in the design allows for more accurate simulation
models. The following design procedure assumes the specifications for the following
parameters are given in the table 3.1
SPECIFICATIONS PROPOSED VALUE
Gain >=70db
Gain bandwidth >=10MHZ
Z Phase margin >=45o
Slew rate >=10 V/us
Input Common Mode Range (ICMR) =0.4 V ~ 1.5 V
Common Mode Rejection Ratio (CCMR) >= 60db
Output swing >=±1.8V
The steps to find the aspect ratio of transistors are given below
Step 1: From the desired phase margin, choose the minimum value for Cc, i.e. for a
60o phase margin we use the following relationship.
> 0.22 (3.9)
Step 2: Determine the minimum value for the trial current (I5)
5 = SR. Cc (3.10)
Step 3: Design for S3 from the maximum input voltage specification.
Table 3.1 Specifications for CMOS Operational Amplifier
Page 41
28
3 =I5
K 3[V − V(max ) − [V(max ) + V(min )]] (3.11)
Step 4: Design for S1 (S2) to achieve the desired GB.
1 = . (3.12)
Step 5: Design for S5 from minimum input voltage. First calculate VDS5 (Sat) to find
S5.
VS5(Sat) = () − − 5
5
− () (3.13)
5 =25
5[5()] (3.14)
Step 6: Find S6 and I6
gm 6 = 10 ∗ gm 1 (3.15)
gm 4 = √2KP S4I5 (3.16)
6 = 4 ∗6
4 (3.17)
6 =6
2 66 (3.18)
Step 7: Design S7 to achieve the desired current ratios between I5 and I6.
7 = 5 ∗6
5 (3.19)
3.5.1 SCHEMATIC OF OPERATIONAL AMPLIFIER
CMOS two stage operational amplifier includes biasing circuit, differential
amplifier and output gain stage as shown in figure 3.6. The width and length of each
transistor circuit is calculated using design procedure. The circuit is simulated using
the calculated size.
Page 42
29
DEVICE CALCULATED SIZE SIMULATED SIZE
CL 10pf 10pf
CC 2.5pf 2.5pf
Iref 50uA 50uA
M1 0.684um/0.18um 4.5um/0.45um
M2 0.684um/0.18um 4.5um/0.45um
M3 2.4um/0.18um 8um/0.45um
M4 2.4um/0.18um 8um/0.45um
M5 0.42um/0.18um 0.42um/0.18um
M6 0.684um/0.18um 49.5um/0.45um
M7 19.84um/0.18um 5um/0.45um
M8 3.48um/0.18um 5um/0.45um
Figure 3.6 Two Stage CMOS Opamp
Table 3.2 Device sizes for Two Stage CMOS Opamp
Page 43
30
The values of the transistors are adjusted to obtain a response closer to ideal
one and the values of the devices are tabulated in table 3.2. The table shows the
devices and their corresponding calculated and simulated sizes.
3.6 FAULT CLASSIFICATION
Fault classification is performed on the bench mark circuits in two steps
namely fault dictionary creation and fault diagnosis using the proposed algorithms.
3.6.1 FAULT DICTIONARY
Fault dictionary technique consists of fault free and faulty cases of a bench
mark circuit. Fault dictionary is constructed for all the three bench mark circuits.
3.6.2 FAULT DICTIONARY – SVF and SKBPF
The fault dictionary for SVF and SKBPF is constructed by simulating transfer
function and the steps are followed as shown in figure 3.7. The transfer function for
the benchmark circuit is simulated by injecting faults to the components. The fault is
injected with ±50% deviation from nominal value with a step size of 10%. Two types
of fault dictionaries are constructed for each bench mark circuit and they include fault
dictionary with single fault and fault dictionary with double fault. Single fault
dictionary is constructed by injecting fault to a single component and the other
component values are varied within their tolerance limit. Double fault is constructed
by injecting faults to two components at a time and other components are varied
within their tolerance limit.
Page 44
31
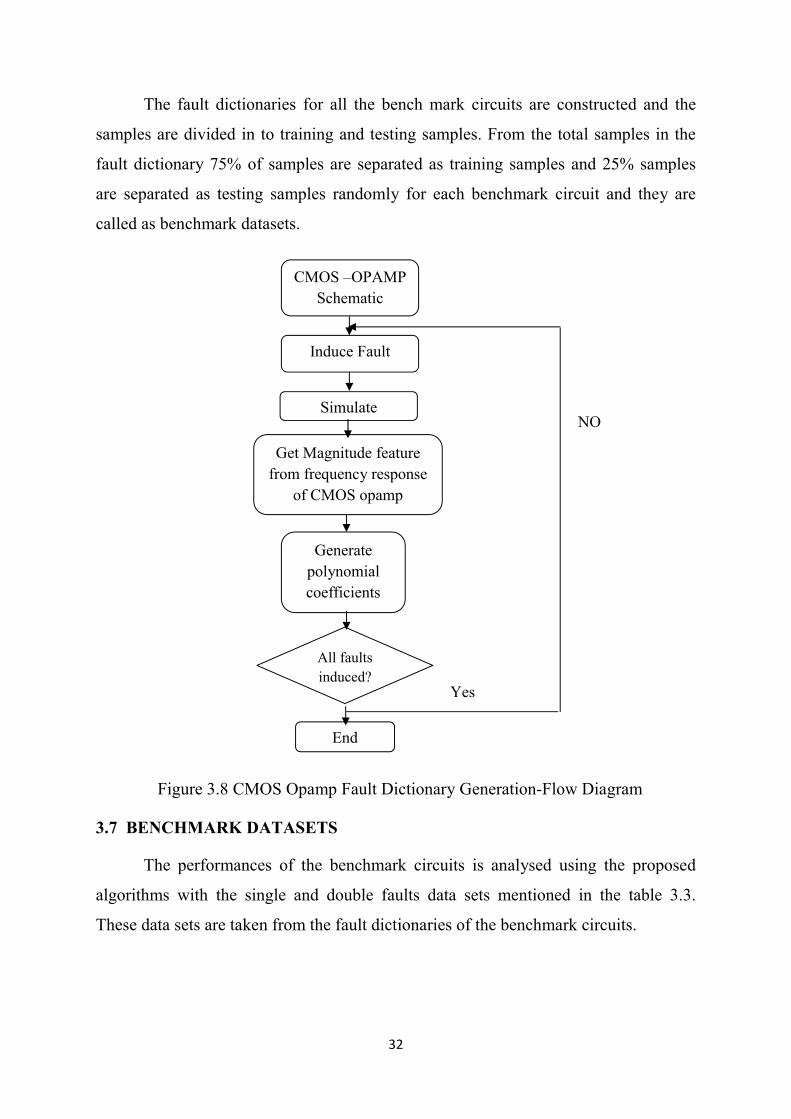
3.6.3 FAULT DICTIONARY –CMOS OPAMP
The fault dictionary for CMOS-operational amplifier is constructed by
following sequence of steps as shown in figure 3.8. The CMOS opamp schematic as
per the design procedure is simulated for fault free response. The magnitude of output
voltage is extracted from the frequency response of operational amplifier and the
obtained data is given as input to the curve fitting toolbox to generate polynomial
coefficients. The fault is injected to a single device by either opening the terminals of
the component or shorting the terminals of the component and the other device
dimensions are varied with in ±20% from the nominal designed dimensions with the
step size of 4%. The magnitude response curve and the corresponding data’s are
obtained for each fault. The magnitude response curve data’s are given as input for
curve fitting tool to generate coefficients and the fault dictionary is constructed from
the polynomial coefficients.
Figure 3.7 Fault Dictionary Generation steps for SVF and SKBPF-Flow Diagram
Yes
NO
Induce Fault
Simulate
Get Features
Bench mark
Circuit
Transfer function
All faults
induced?
End
Page 45
32
The fault dictionaries for all the bench mark circuits are constructed and the
samples are divided in to training and testing samples. From the total samples in the
fault dictionary 75% of samples are separated as training samples and 25% samples
are separated as testing samples randomly for each benchmark circuit and they are
called as benchmark datasets.
3.7 BENCHMARK DATASETS
The performances of the benchmark circuits is analysed using the proposed
algorithms with the single and double faults data sets mentioned in the table 3.3.
These data sets are taken from the fault dictionaries of the benchmark circuits.
Figure 3.8 CMOS Opamp Fault Dictionary Generation-Flow Diagram
Generate
polynomial
coefficients
Yes
NO
Induce Fault
Simulate
Get Magnitude feature
from frequency response
of CMOS opamp
CMOS –OPAMP
Schematic
All faults
induced?
End
Page 46
33
Datasets Train Data Test Data No of Features No of Classes
SVF-Single 1403 450 4 9
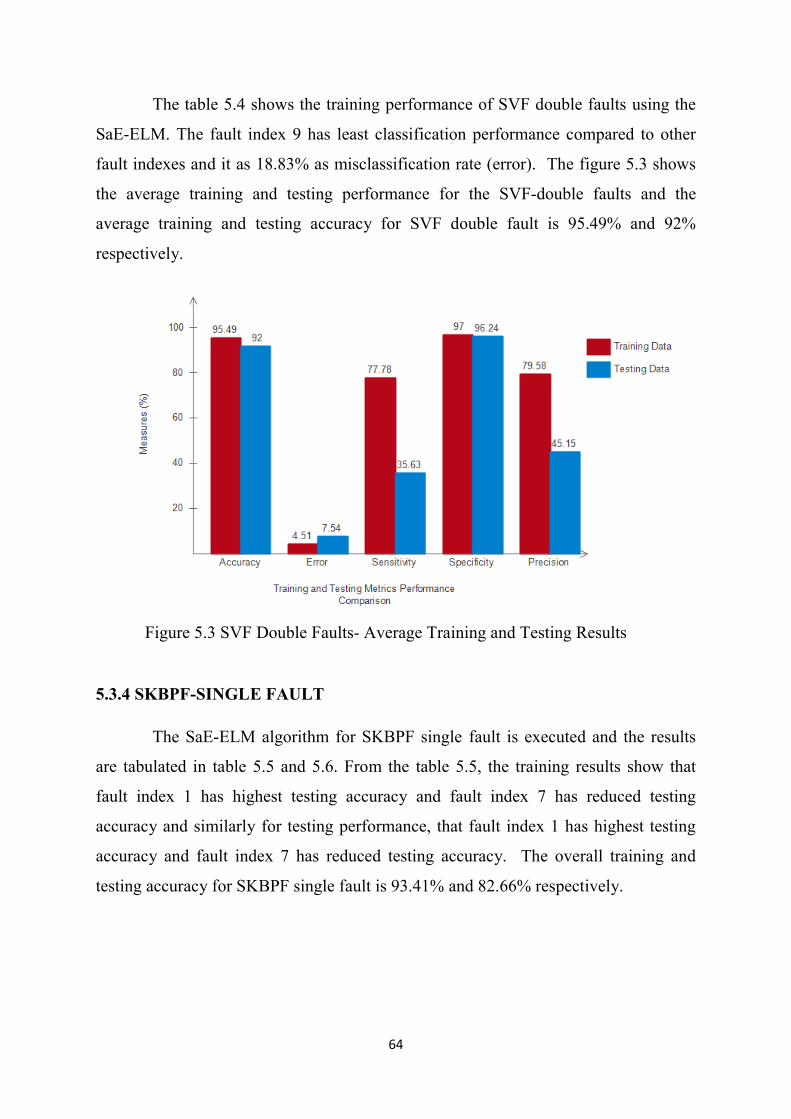
SVF-Double 5000 2000 5 10
SKBPF-Single 1093 350 4 7
SKBPF-Double 4997 1598 5 10
CMOS Opamp 181 90 5 9
3.7.1 SVF SINGLE FAULT DATA SET
SVF single fault data set corresponds to the fault dictionary of single fault. The
fault is injected in to a single component with ±50% deviation from nominal value
with a step size of 10% and the other components are kept within their tolerance limit.
There are totally 9 components in the circuit so the total fault injected is 9 for single
fault. The features correspond to component values, gain, pole selectivity and
frequency. The fault injected to the components for single fault in SVF circuit is listed
in the table 3.4. The fault dictionary sample for R1+20% includes features of gain,
pole selectivity and pole frequency and their corresponding sample values include
0.872328, 1.159479 and 794.6936 respectively. The similar procedure is followed for
all the benchmark circuits for assigning fault index to the components for creating
fault dictionary.
Table 3.3 Datasets of Benchmark circuits
Page 47
34
FAULT INJECTED TO
THE COMPONENT
FAULT INDEX
R1±50% 1
R2±50% 2
R3±50% 3
R4±50% 4
R5±50% 5
R6±50% 6
R7±50% 7
C1±50% 8
C2±50% 9
3.7.2 SVF DOUBLE FAULT DATA SET
SVF double fault data set corresponds to the fault dictionary of double fault.
The fault is injected in to two components and the other components are kept within
their tolerance limit. There are totally 9 components and so there are 36 combinations
of double fault possible for SVF circuit. The faults are injected to all the 36
combinations with ±50% deviation from nominal value with a step size of 10% and
the other components are kept within their tolerance limit and the fault dictionary is
constructed and the performance is analysed for all the combinations. Among 36
combinations only certain combinations results better performance than the other
combinations so the fault dictionary is reduced to 10 combinations and new fault
dictionary is constructed with the 10 combinations and the features are component
values of the two components, gain, pole selectivity and frequency. The 10
combinations are R1R2, R1R3, R1R5, R2R3, R2R4, R2R5, R2C1, R3R4, R3R5 and C1C2 and
the corresponding fault indexes assigned are 1, 2, 3,4,5,6,7,8,9 and 10 to construct
fault dictionary.
Table 3.4 SVF single fault index
Page 48
35
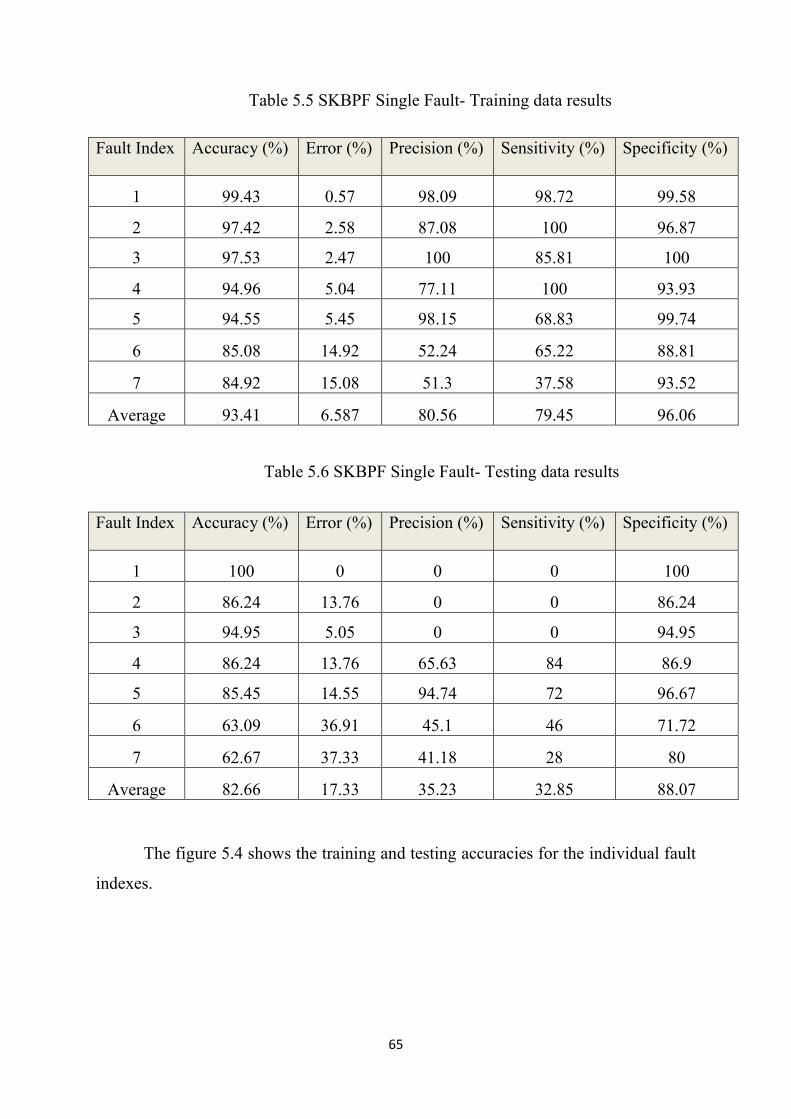
3.7.3 SKBPF SINGLE FAULT DATA SET
SKBPF single fault data set corresponds to the fault dictionary of SKBPF with
single fault. The fault is injected in to the single component with ±50% deviation from
nominal value with a step size of 10% and the other components are kept within their
tolerance limit. There are totally 7 components in the circuit so the total fault injected
is 7 which correspond to the number of classes. The components are R1, R2, R3, R4, R5,
C1 and C2 and their fault indexes used are 1, 2, 3,4,5,6 and 7 respectively in the
creation of fault dictionary. The features in the fault dictionary correspond to
component values, gain, pole selectivity and frequency, a sample of fault dictionary
with R1+10% has samples with feature values 69136.2, 10.43722 and 24629.85
respectively.
3.7.4 SKBPF DOUBLE DATA SET
SKBPF double data set corresponds to the fault dictionary of double fault. The
fault is injected in to two components and the other components are kept within their
tolerance limit. There are totally 7 components and so there are 21 combinations of
double fault possible for SVF circuit. The faults are injected to all the 21 combinations
and the fault dictionary is constructed and the performance is analysed for all the
combinations. Among 21 combinations only certain combinations results better
performance than the other combinations so the fault dictionary is reduced to 10
combinations and new fault dictionary is constructed with the 10 combinations and the
features are component values of the two components, gain, pole selectivity and
frequency. The chosen 10 combinations are R1R2, R1R3, R1R4, R1C1, R1C2, R2R4,
R3R4, R3C1, R5C2 and C1C2 and the corresponding fault indexes assigned are 1, 2,
3,4,5,6,7,8,9 and 10 to construct fault dictionary.
3.7.5 CMOS OPAMP DATA SET
The CMOS opamp data set contains samples generated by simulating the
schematic of CMOS two stage operational amplifier. There are totally 8 MOSFET
devices and the Miller capacitance so totally 18 faults which corresponds to number of
fault classes. The fault is injected to a single device and all the other device
Page 49
36
dimensions are varied within their tolerance limit. The voltage magnitude response are
obtained by opening and shorting the components which corresponds to two faults for
each device and so the fault index. The magnitude response of a fault free circuit is
shown in figure 3.9.
The magnitude response of a faulty circuit with stuck open fault injected to the
M1 device is shown in figure 3.10.
Figure 3.9 Two stage opamp fault free response
Page 50
37
The magnitude response of a faulty circuit with stuck short fault injected to the
M3 device is shown in figure 3.11.
The feature responses are obtained from these magnitude response curves given
to curve fitting tool box to generate polynomial coefficients. The fault indexes are
Figure 3.10 Two stage opamp – M1 Stuck open fault response
Figure 3.11 Two stage opamp – M3 Stuck short fault response
Page 51
38
named according to the fault model for the components and they are listed in the table
3.5.
COMPONENT FAULT
MODEL
FAULT
INDEX
FAULT
MODEL
FAULT
INDEX
M1 Stuck-Open 1 Stuck-Short 2
M2 Stuck-Open 3 Stuck-Short 4
M3 Stuck-Open 5 Stuck-Short 6
M4 Stuck-Open 7 Stuck-Short 8
M5 Stuck-Open 9 Stuck-Short 10
M6 Stuck-Open 11 Stuck-Short 12
M7 Stuck-Open 13 Stuck-Short 14
M8 Stuck-Open 15 Stuck-Short 16
C1 Stuck-Open 17 Stuck-Short 18
The sample fault dictionary constructed from the generated polynomial
coefficients for the device M4 with stuck open fault model are listed in table 3.6
COMPONENT a1 a2 a3 a4 a5
M4 Stuck Open -1.05E-19 1.93E-14 -7.81E-10 -3.12E-05 2.5036
M4 Stuck Open -1.05E-19 1.93E-14 -7.81E-10 -3.12E-05 2.5036
M4 Stuck Open -1.04E-19 1.90E-14 -7.44E-10 -3.29E-05 2.51
M4 Stuck Open -1.04E-19 1.90E-14 -7.44E-10 -3.29E-05 2.51
M4 Stuck Open 3.59E-26 2.68E-23 -2.44E-13 -3.16E-15 2.4697
M4 Stuck Open 5.18E-27 6.45E-21 -2.44E-13 9.92E-12 2.4697
M4 Stuck Open -1.06E-19 2.00E-14 -8.82E-10 -2.62E-05 2.4806
M4 Stuck Open -1.05E-19 2.01E-14 -9.13E-10 -2.45E-05 2.4714
Table 3.5 CMOS – Fault model and the fault index
Table 3.6 CMOS – Sample Fault dictionary for Stuck Open fault model
Page 52
39
The sample fault dictionary constructed from the generated polynomial
coefficients for the device M8 with stuck short fault model are listed in table 3.7.
COMPONENT a1 a2 a3 a4 a5
M4 Stuck Open -2.58E-31 5.09E-26 -2.22E-18 5.59E-17 -2.58E-31
M4 Stuck Open -2.42E-31 4.37E-26 -2.40E-18 4.18E-17 -2.42E-31
M4 Stuck Open -1.99E-31 3.93E-26 -2.58E-18 4.57E-17 -1.99E-31
M4 Stuck Open 1.96E-31 -3.31E-26 -2.76E-18 -2.36E-17 1.96E-31
M4 Stuck Open -3.06E-31 6.07E-26 -2.96E-18 6.51E-17 -3.06E-31
M4 Stuck Open -2.58E-31 5.09E-26 -2.22E-18 5.59E-17 -2.58E-31
M4 Stuck Open -1.47E-32 -9.78E-28 -1.45E-18 -2.29E-17 -1.47E-32
M4 Stuck Open 1.15E-31 -1.79E-26 -1.31E-18 -1.76E-17 1.15E-31
Table 3.7 CMOS – sample fault dictionary for stuck short fault model
Page 53
40
CHAPTER 4
EXTREME LEARNING MACHINE
Extreme learning machine (ELM) is a single hidden-layer feed forward neural
network learning algorithm. ELM for multi-layer perceptron is a new algorithm that
randomly chooses hidden nodes and analytically determines the output weights of the
network. Theoretically, the ELM algorithm tends to provide good generalization
performance at an extremely fast learning speed. The experimental results based on
artificial and real benchmarking problems show that ELM can result in a better
generalization performance in many cases and can learn thousands of times faster than
traditional learning algorithms for feed-forward neural networks.
4.1 MATHEMATICAL MODEL
Huang et al., 2004, is the reference for the description of ELM. The ELM
architecture is shown in figure 4.1.The regression problem can be formulated as an
attempt to find solutions for Wi = ( wi1, wi2,...win ) and βi using the following system
of equations
= , = 1,2 … . . (4.1)
Where
= ∑ (⟨, ⟩ + ) , = 1,2 … . . (4.2)
Page 54
41
The equations can also be expressesd as Hβ=T, where H is the hidden layer’s
output matrix of the neural network.
(, , . . , , , . . , , , … , ) =
⎝
⎜⎛
(⟨, ⟩ + ) … . (⟨, ⟩ + )..
(⟨, ⟩ + ) … . (⟨, ⟩ +
⎠
⎟⎞
=
.
.
, =
.
.
(4.3)
Figure 4.1 ELM Architecture
Page 55
42
Each column on matrix H is made of the values of the corresponding hidden
layer node, evaluated for each one of the patterns Xi in the training set.
The ELM algorithm randomly selects the values for weights Wi and bi and
then obtains corresponding values for β, from the generalised linear model. This is
done by calculating the minimum quadratic solution of the linear system, given by
β = HT (4.4)
Where
H = (HH) H (4.5)
is the generalised Moore-Penrose inverse matrix. The solution obtained has
the following properties
It minimizes the training error
β = arg min‖Hβ − T‖ (4.6)
It is the minimum Euclidean norm among all the possible solutions of the linear
system
= ‖HT‖ ≤ ‖‖ (4.7)
4.2 ELM ALGORITHM
Given a training set D= (Xi , ti ) : Xi ∈ Rn , ti ∈ R , i=1,2........N, the
activation function g(t) and m neurons in the hidden layer.
Step1: Assign arbitrary input weights for W and bias b.
Step2: Calculate hidden layer output matrix H.
Step 3: Calculate the output weights β:
= HT (4.8)
The H† is generalised Moore-Penrose inverse matrix. The solution obtained
corresponds to the orthogonal projection of vector T, which determines the class
Page 56
43
corresponding to each pattern in the m-dimensional vector subspace (given by the
number of nodes in the hidden layer) made by the column vectors of matrix H.
If N=m (i.e. there are as many nodes in the hidden layers as patterns in the
training set), matrix H is square and the corresponding system of equations has a
unique solution, which is equivalent to saying that the training error is equal to zero.
This happens because vector T is in the subspace made by the m column vectors of
matrix H. The hidden layer output matrix H is obtained from the input weight,
features and the activation function. There are 5 different activation functions
available for ELM and they are sigmoid, sine, hard-limit, triangular basis and radial
basis.
4.2.1 SIGMOID ACTIVATION FUNCTION
A sigmoid function is a mathematical function having an "S" shape (sigmoid
curve). A sigmoid function is a bounded differentiable real function that is defined for
all real input values and has a positive derivative at each point. It is real-valued and
differentiable, having either a non-negative or non-positive first derivative which is
bell shaped. Sigmoid functions are often used in artificial neural networks to introduce
nonlinearity in the model. The sigmoid function consists of 2 functions, logistic and
tangential. The values of logistic function range from 0 and 1 and -1 to +1 for
tangential function. The expression for sigmoid activation is given by equation 4.9 and
it shown in figure 4.2
() = 1
1 + (4.9)
Figure 4.2 Sigmoid Activation Function
Page 57
44
4.2.2 SINE ACTIVATION FUNCTION
The sine activation function takes the trigonometric sine of input. The output
lies in the range (-1, +1) and learning procedure seems to perform mode
decomposition when it is used instead of sigmoid. The sine activation function
discovers the most important frequency components of the function with discrete set
of input and output samples. The expression for sine activation is given in equation
4.10 and it is shown in figure 4.3
() = sin() (4.10)
4.2.3 HARD-LIMIT ACTIVATION FUNCTION
The hard limit activation function is also called as step function and the output
is set to one of the two levels, depending on whether the total input is greater than or
less than the threshold value. The hard limit activation function expression can be
written as
() = 0, < 0
() = 1 , ≥ 0 (4.10)
Figure 4.3 Sine Activation Function
Figure 4.4 Hard limit Activation Function
Page 58
45
4.2.4 TRIANGULAR BASIS ACTIVATION FUNCTION
Triangular basis (tribas) is a neural network transfer function. It computes the
layers output from the net input. The expression for tribas function is
() = () (4.11)
4.2.5 RADIAL BASIS ACTIVATION FUNCTION
Radial basis function is a real valued function and its value depends on the
distance from the origin. It takes parameter that determines the centre (mean) value of
the function used as a desired value. Gaussian is commonly used RBF function and
the expression for the Gaussian function is given by equation 4.11 and the function is
shown in figure 4.6
() =1
√2п
()
(4.11)
Figure 4.5Triangular Basis Activation Function
Figure 4.6 Radial Basis Activation Function
Page 59
46
The activation function can be chosen based on the application. The
performance of the algorithm is analysed by varying the activation function for the
data sets mentioned in the section 3.7 and table 3.3.
4.3 SIMULATION RESULTS
The single fault and double fault data set of SVF benchmark circuit is taken as
the first dataset and the performance of the bench mark circuits are analysed using the
ELM algorithm by following the steps mentioned in the flowchart in figure 4.7.
4.3.1 SVF-SINGLE FAULT
The ELM algorithm for single fault is executed by varying the activation
functions and the hidden nodes. The results for single fault for the varied activation
function are shown in figure 4.8. The results of the varied activation function shows
that the sigmoid activation function gives the higher training and testing accuracy
compared to the other activation functions. The hidden node numbers for sigmoid
activation is varied and the 20 hidden nodes gives the higher accuracy compared to the
Figure 4.7 ELM algorithm Steps
Page 60
47
other hidden nodes. The sigmoid function with 20 hidden nodes gives better results
for SVF with single fault.
4.3.2 SVF- DOUBLE FAULT
The performance of the SVF circuit with double faults is analysed through
ELM algorithm by changing the different activation functions available in the
algorithm and by changing the hidden node numbers. The results for ELM with varied
activation function for double fault is tabulated in table 4.1.
Activation
Functions
Training Time
(Seconds)
Testing Time
(Seconds)
Training
Accuracy (%)
Testing
Accuracy (%)
Sigmoid 0.1563 0.0313 83.51 83.6
Sine 0.2031 0.0469 84.64 84.15
Hard Limit 0.1875 0.0313 65.14 64.67
Triangular Basis 0.2344 0.0328 77.45 77.93
Radial Basis 0.2358 0.0469 84.88 85.4
Figure 4.8 SVF Single -Fault Performance for different activation
function
Table 4.1 SVF Double Fault- Performance compsrisons
for different activation function
Page 61
48
The tabled results indicate that Radial basis function shows higher training
and testing accuracy compared to the other activation functions. The performance for
all the activation function is analysed with 60 hidden nodes because it gives
reasonable training and testing accuracy in minimum time.
The performance of the circuit using ELM with double fault can be improved
by varying the hidden nodes with Radial basis activation function. The training and
testing performance for the varied hidden node numbers for Radial basis is shown in
below figure 4.9 and 4.10
Figure 4.9 Training accuracies for different hidden nodes
Figure 4.10 Testing accuracies for different hidden nodes
Page 62
49
4.3.3 SKBPF-SINGLE FAULT
The ELM algorithm for SKBPF single fault is executed by varying the
activation functions and the hidden nodes. The results for single fault for the varied
activation function are listed in table 4.2. The results of the varied activation function
shows that the triangular basis activation function gives the higher training and testing
accuracy compared to the other activation functions for 80 hidden nodes.
Activation
Functions
Training
Time
(Seconds)
Testing
Time
(Seconds)
Training
Accuracy (%)
Testing
Accuracy (%)
Sigmoid 0.0313 0.0313 86.55 61.71
Sine 0.1705 0.0158 86.46 61.14
Hard Limit 0.1875 0..469 84.81 75.71
Triangular Basis 0.0469 0.0147 86.18 83.17
Radial Basis 0.0358 0.0469 86.73 55.14
4.3.4 SVF- DOUBLE FAULT
The ELM algorithm is analysed for its performance for the SKBPF Double
fault dataset. The performance is analysed by changing the different activation
functions available in the algorithm and by changing the hidden node numbers. The
results for ELM with varied activation function for double fault is shown in figure
4.11. The results from the chart indicate that triangular basis function shows higher
training and testing accuracy compared to the other activation functions. The
performance is analysed with 60 hidden nodes.
Table 4.2 SKBPF Single Fault- Performance comparisons
for different activation function
Page 63
50
4.3.5 CMOS-Operational Amplifier
The ELM algorithm performance for the CMOS data set is analysed and the
results are tabulated in the table 4.3 for varied activation functions.
Activation Functions Training Time
(Seconds)
Testing Time
(Seconds)
Training
Accuracy (%)
Testing
Accuracy (%)
Sigmoid 0.0625 0.0133 53.04 34.44
Sine 0.0469 0.0148 50.83 40.00
Hard Limit 0.1875 0.0469 44.20 35.56
Triangular Basis 0.0469 0.0147 49.72 43.33
Radial Basis 0.0156 0.0046 51.93 41.11
The table results shows that the triangular basis function gives better results
for both training and testing accuracies compared to the other activation function.
Figure 4.11 SKBPF Double -Fault Performance comparison for
different activation functions
Table 4.3 CMOS Opamp- Performance comparisons for
different activation function.
Page 64
51
CHAPTER 5
SELF ADAPTIVE EVOLUTIONARY EXTREME LEARNING
MACHINE (SaE-ELM)
Self-adaptive evolutionary extreme learning machine (SaE-ELM) is a single
hidden-layer feed forward neural network (SLFN). Self-adaptive differential evolution
is used along with extreme learning machine to optimize the hidden node parameters
to get better solution. The hidden nodes are optimized by self-adapting the trial vector
and control parameters in a strategy pool by learning from the previous experiences to
generate best solution, then the output weight of the network is calculated using
Moore’s Penrose inverse as in ELM. The classification performance of SAE-ELM is
higher compared to other evolutionary algorithms like evolutionary –extreme learning
machine (E-ELM), different evolutionary Levenberg –Marquadrt. The reason for
higher performance is mainly due to the self-adaptive strategy involved in determining
the suitable control parameters and vector strategies.
5.1 DIFFERENTIAL EVOLUTION
Evolutionary algorithms (EA) are widely used as global search method for
optimizing the neural network parameters. Differential Evolution is a simple and
widely used method for optimizing the parameters. It is population based stochastic
direct search technique for selecting the network parameters. DE is used to train the
network parameters of feed forward neural network. In DE all the network parameters
are encoded in to a single population vector and the error function is computed
between the network predicted output and the expected output, the resulting error
function is used as fitness function for evaluating all the population.
DE starts with a number of D-dimensional search variable vectors. The total
number of all the variable vectors in the beginning of the algorithm is called as
population (NP). The population size is kept constant throughout the execution of the
algorithm. DE optimizes the D-dimensional vector to produce optimum solution. The
initial D-dimensional vector for ELM network can be written as
Page 65
52
ɵ, = ,(,) , … , ,(,)
, ,(,) , … , ,(,)
, (5.1)
Where ai and bi are randomly generated, G is the generation and k=1, 2... , NP.
These vectors are referred to as chromosomes and the individual vectors are referred
to as genes. The target vectors are obtained from the population by undergoing
sequence of operations like initialization, mutation, crossover and selection.
STEP 1: INITIALIZATION
In initialization a set of NP individual parameter vectors ɵ, are initialized to
cover the parameter space by using the equation
ɵ, = ɵ + (0,1).(ɵ − ɵ ) (5.2)
Where ɵ = [ɵ , ɵ
… … , ɵ ] and ɵ = [ɵ
, ɵ … … , ɵ
] are the
minimum and maximum parameter bounds respectively.
STEP 2: MUTATION
Mutation is the genetic operator used to maintain genetic diversity from one
generation population to next generation. It alters one or more values in a
chromosome from its initial state. In DE the mutant vector is generated using self-
organizing map which takes the difference between the randomly chosen population
vectors to perturb an existing vector. There are different mutation strategies to
generate mutant vector , from the each individual parameter vector ɵ, at
current generation. The mutation strategies frequently used are DE/rand/1, DE/rand-
to-best/2, DE/rand/2 and DE/current-to-rand/1.
Mutation Strategy 1: DE/rand/1
, = ɵ + .(ɵ
− ɵ) (5.3)
Mutation Strategy 2: DE/rand-to-best/2
, = ɵ + .ɵ, − ɵ
+ .ɵ − ɵ
+ .(ɵ − ɵ
) (5.4)
Page 66
53
Mutation Strategy 3: DE/rand/2
, = ɵ + .ɵ
− ɵ + .(ɵ
− ɵ) (5.5)
Mutation Strategy 4: DE/current-to-rand/1
, = ɵ + .ɵ
− ɵ, + .ɵ − ɵ
(5.6)
In all these equations, the indices r , r
, r, r
, r are mutually exclusive
integers randomly generated within the range [1, 2 ...., NP], which are also different
from the index k. The positive amplification factor F is used to control the scaling of
the difference vectors and is usually selected within the range 0 ≤ F ≤ 2. The control
parameter K is randomly generated within the region 0 ≤ K ≤ 1. The different vector
generation strategies usually perform differently when solving different optimization
problems.
The “DE/rand/1” strategy is suitable for solving multimodal problems due to its
stronger exploration capability but convergence speed is very slow. The “DE/rand-to-
best/2” converges rapidly and performs well when dealing with unimodal problems
but for multimodal problems, this strategy stuck at a local optimum and lead to a
premature convergence. Two-difference-vectors-based strategies, “DE/rand-to-best/2”
and “DE/rand/2” could lead to a better perturbation than one-difference-vector-based
strategies, but they also require a high computational cost. “DE/current-to-rand/1” is a
rotation-invariant strategy and it is efficient in solving multiobjective optimization
problems.
STEP 3: CROSSOVER
Crossover is the genetic operator to produce new population from the parent
population. In DE the crossover is used to increase the diversities of the perturbed
parameter vectors. The trail vector , = [, , ,
… … , , ] is created from the
mutant vector , = [, , ,
… … , , ] using crossover equation
Page 67
54
,
= ,
( ≤ ) ( = )
ɵ,
, ℎ (5.7)
Where CR is the crossover rate to control the fraction of parameter values copied from
the mutant vector and is a positive value chosen in the region 0 ≤ < 1. is
the jth evaluation of a uniform random number generator with outcome in [0,1].
is randomly chosen integer from [1,D] and it is used to ensure that there exists at least
one parameter in ,
differing from the target vector ɵ,.
STEP 4: SELECTION
Selection is the process of selecting the best vector from the population using
the fitness function. The fitness function is evaluated by using all the trail and target
vectors and the population with lowest fitness function is kept as the population for
the next generation.
The steps 2 to 4 are repeated until the best trail vector is obtained or maximum
iteration is met.
The main drawbacks of DE algorithm are very slow convergence rate and the
trail vector strategy and control parameters are chosen manually. The generalization
performance of the algorithm mainly depends on the chosen trail vector and control
parameter. To overcome the drawback of differential evolution, self-adaptive
evolutionary algorithm (SaE) is used in this work.
5.2 SaE-ELM
Self-adaptive evolutionary extreme learning machine (SaE-ELM) is used to
optimize the input weights and hidden node biases in SLFN to improve the
performance. The hidden node parameters in the network are optimized using SADE.
ELM described in the section 4.1 is used to determine the output weight of the
network.
Page 68
55
The SAE-ELM algorithm involves Initialization, Calculations of output weight
and RMSE, mutation and crossover, evaluation for a given set of training data and L
hidden nodes with an activation function.
STEP 1: INITIALIZATION
In initialization a set of NP vectors where each one includes all network hidden
parameters are initialized as the population for first generation.
ɵ, = ,(,) , … , ,(,)
, ,(,) , … , ,(,)
, (5.8)
Where aj and bj (j=1, 2....., L) are randomly generated , G represents the generation
and k=1,2 ..., NP.
The number of population is user-specified parameter because it highly
depends on the real world application.
STEP 2: CALCULATION OF OUTPUT WEIGHT AND RMSE
The network output weight and root mean square error is calculated for each
population vector with the output and error equations
β, = H, (5.9)
Where H, is the Moore’s Penrose of generalized inverse of Hk,G .
, = ∑ || ∑ β
,(,), ,(,), − (5.10)
The population vector with best RMSE is stored as ɵ, and ɵ, for the first
generation.
STEP 3: MUTATION AND CROSSOVER
The trial vector strategy is chosen from the candidate pool constructed from the
four strategies as in DE based on the probability pl,G where pl,G is the probability to
chose strategy l (l=1,2,3,4 ) in Gth generation. A fixed number of iterations LP called
as learning period and the probability pl,G is updated based on the below assumptions
Figure 3.1 ELM Architecture
Page 69
56
1. When ≤ , each strategy has the equal probability to be chosen (, =
)
2. When > , , =,
∑ ,
Where , =∑ ,
∑ , ∑ ,
+ є where , denotes the number of
trial vectors generated by the lth strategy at gth generation that can successfully
enter the next generation. , is the number of trial vectors generated by the
lth strategy at gth generation that are discarded in the next generation. є is the
small positive constant added to avoid null success rate.
The control parameter F and the Crossover ration CR are randomly
generated for each target vector based on the normal distributions N(0.5, 0.3)
and N(0.5,1) respectively. The mean value of CR is gradually adjusted
according to the previous CR values that have generated the trial vectors
successfully entering the next generation.
STEP 4: EVALUATION
All the trail vectors , generated at the (G+1) generation are evaluated
using the below equation
ɵ, =
⎩⎪⎨
⎪⎧
, ɵ,− ,
> є.ɵ,
, ɵ,− ,
< є.ɵ,
, < ɵ,
,
ɵ,
(5.11)
The norm of the output weight is also added as the criteria for trial vector
selection ‖‖ because the neural network with smaller weights produce better
generalization performance.
Steps 3 and 4 are repeated until the best trial vector is chosen or maximum
iteration is reached.
Page 70
57
5.3 SIMULATION RESULTS
The SaE-ELM algorithm performance is evaluated by using the data sets
mentioned in section 3.7 in table 3.3 by following the steps mentioned below. The
performance analysis of the algorithm is measured by using metrics evaluated from
the confusion matrix.
Step 1: Initial population is created by using the number of hidden neurons, number of
input neurons and with the specified population.
Step 2: The fitness function is computed for the initial population by computing the
output weight and misclassification rate for that population.
Step 3: The fitness function is evaluated as many times as specified by us.
Step 4: The output weight based on the fitness function evaluated which gives
minimum misclassification is chosen as the best weight for that iteration.
Step 5: Cross over operation is performed based on the cross over ratio and strategy
mentioned.
Step 6: The steps 2 to 5 are repeated unless the maximum generation is reached.
Step 7: The output weight which competes the other weights by using the strategies is
chosen as the best weight for the training phase and the expected fault index for
training is obtained from the training best weight.
Step 8: The best weight obtained during the training phase is used for the computation
of output weight for testing.
Step 9: The computed testing best weight is used for computing the expected fault
index for testing.
Step 10: The misclassification rate for training and testing is computed from the
expected fault index of training and testing
Page 71
58
5.3.1CONFUSION MATRIX
A confusion matrix is used in the field of machine learning and specifically
for the statistical classification. Confusion matrix is also called as error matrix and it is
a specific table layout which allows visualization of the performance of the algorithm
and it is mainly used for supervised learning. Each column of the matrix represents the
predicted class instances and each row represents the instances of actual class. The
figure 5.1 shows the general confusion matrix for 3 class classification.
The element (i, j) in the confusion matrix is the number of samples whose
predicted class is i and whose known label is class j. The diagonal elements represent
the correctly classified samples.
5.3.1.1 THE TABLE OF CONFUSION
In confusion matrix each cell in the matrix has fields as True Positive, True
Negative, False Positive and False Negative. For a particular class all the parameters
can be given generally as
i. TRUE POSITIVE (TP)
True positive denotes the correctly predicted labels. In the confusion matrix it
corresponds to the diagonal element of the corresponding class.
For class 1 TP = Confusion matrix (1, 1).
Figure 5.1 General Confusion Matrix
Page 72
59
ii. TRUE NEGATIVE (TN)
True positive denotes the correctly predicted other labels. In the confusion matrix
it corresponds to the sum of the columns and rows by excluding that particular class.
For class 1 TN= Confusion matrix (2, 2),(2,3), (3,2) and (3,3).
iii. FALSE POSITIVE (FP)
False positive is the falsely predicting a label. In the confusion matrix it
corresponds to the sum of the values in the corresponding column.
For class 1 FP= Confusion matrix (2, 1) and (3, 1).
iv. FALSE NEGATIVE(FN)
False negative represents the missing or incoming label. In the confusion matrix it
corresponds to the sum of the values in the corresponding row.
For class 1 FP= Confusion matrix (1, 2) and (1, 3).
These fields obtained from the confusion matrix are used to compute performance
metrics for the classifiers. The performance metrics are accuracy, error, precision,
sensitivity and specificity.
v. ACCURACY
Accuracy is the proportion of correct classification to the total number of samples.
= +
+ + + (5.12)
vi. ERROR
Error is the proportion of incorrect classification to the total number of
samples.
= +
+ + + (5.13)
Page 73
60
vii. SPECIFICITY
Specificity is the proportions of actual negative cases are correctly identified.
=
+ (5.14)
viii. SENSITIVITY
Sensitivity is the proportions of actual positive cases are correctly identified.
=
+ (5.15)
ix. PRECISION
Precision is the reproducibility of measurement.
=
+ (5.16)
These measures are used for analysing the algorithms for all the bench mark
circuits.
5.3.2 SVF-SINGLE FAULT
The SaE-ELM algorithm for single fault is executed by varying the
MAX_FES parameter. The results obtained by varying the MAX_FES parameter for
SVF single fault is shown in figure 5.2. The results from the table indicate if
MAX_FES is set to 300 it gives higher accuracy for both training and testing in
minimal time compared to other values. Max_FES is the maximum number of
function evaluation performed to generate the fitness function.
Page 74
61
The training and testing performance for SVF single fault using SaE-ELM
analysed using confusion matrix metrics are tabulated in table 5.1 and 5.2.
Fault Index Accuracy (%) Error (%) Precision (%) Sensitivity (%) Specificity (%)
1 98.15 1.85 98.5 84.52 99.84
2 97.86 2.14 100 80.52 100
3 94.94 5.06 68.72 100 94.31
4 98.15 1.85 93.46 89.94 99.2
5 98.5 1.5 100 86.54 100
6 94.23 5.77 68.29 89.74 94.79
7 93.66 6.34 79.31 58.6 98.07
8 99.22 0.78 100 92.9 100
9 99.22 0.78 93.37 100 99.12
Average 97.1 2.89 89.07 86.97 98.37
Figure 5.2 SVF Single Fault- Training and Testing Performances for
different MAX-FES
Table 5.1 SVF single Fault -Training data results
Page 75
62
Fault Index Accuracy (%) Error (%) Precision (%) Sensitivity (%) Specificity (%)
1 99.56 0.44 0 0 99.56
2 97.33 2.67 0 0 97.33
3 98.22 1.78 0 0 98.22
4 100 0 0 0 100
5 97.33 2.67 100 76 100
6 91.11 8.89 78.85 82 93.71
7 91.56 8.44 81.63 80 94.86
8 92.89 7.11 75.76 100 90.86
9 90.22 9.78 100 56 100
Average 95.35 4.64 48.47 43.78 97.17
The tabled results show the training and testing performance of the classifier
(SaE-ELM). The results show that the classifier has higher training accuracy for fault
index 8 and 9. Similarly the classifier has higher testing accuracy for fault index 4.
The classifier classified all the faults correctly and accurately for fault index 4. The
overall training and testing accuracy for SVF single fault is 97.1% and 95.35%
respectively.
5.3.3 SVF- DOUBLE FAULT
The SaE-ELM algorithm is analysed for its performance for the SVF Double
fault dataset. The testing and training results for SVF-Double fault using SaE-ELM
algorithm is tabulated in table 5.3 and 5.4. The table results from table 5.3 shows the
classification performance of SaE-ELM for individual fault indexes. The algorithm
shows higher training and testing performance for fault index 7. The same fault index
has higher specificity, sensitivity and precision which indicate that the classifier has
able to predict all the positive cases and the performance measure for that fault index
is reproducible.
Table 5.2 SVF single Fault - Testing data results
Page 76
63
Fault Index Accuracy (%) Error (%) Precision (%) Sensitivity (%) Specificity (%)
1 95.82 4.18 77.15 82.57 97.29
2 93.8 6.20 74.87 57.2 97.87
3 91.3 8.70 55.39 66.8 94.02
4 91.96 8.04 56.52 85 92.73
5 97.12 2.88 91.4 78.6 99.18
6 95.36 4.64 84.54 65.6 98.67
7 100 0 100 100 100
8 96.16 3.84 78.95 84 97.51
9 93.42 6.58 76.98 58.2 97.82
10 100 0 100 100 100
Average 95.49 4.506 79.58 77.97 97.509
Fault Index Accuracy (%) Error (%) Precision (%) Sensitivity (%) Specificity (%)
1 95.3 4.7 0 0 95.3
2 93.39 6.61 0 0 93.39
3 95.6 4.4 0 0 95.6
4 89.19 10.81 0 0 89.19
5 95.3 4.70 0 0 95.3
6 86.59 13.41 81.55 42.21 97.63
7 100 0 100 100 100
8 88.39 11.61 88.89 48 98.5
9 81.17 18.83 81.01 32 97.51
10 99.7 0.3 100 98.5 100
Average 92.46 7.537 45.145 32.071 96.246
Table 5.3 SVF Double Fault- Training data results
Table 5.4 SVF Double Fault- Testing data results
Page 77
64
The table 5.4 shows the training performance of SVF double faults using the
SaE-ELM. The fault index 9 has least classification performance compared to other
fault indexes and it as 18.83% as misclassification rate (error). The figure 5.3 shows
the average training and testing performance for the SVF-double faults and the
average training and testing accuracy for SVF double fault is 95.49% and 92%
respectively.
5.3.4 SKBPF-SINGLE FAULT
The SaE-ELM algorithm for SKBPF single fault is executed and the results
are tabulated in table 5.5 and 5.6. From the table 5.5, the training results show that
fault index 1 has highest testing accuracy and fault index 7 has reduced testing
accuracy and similarly for testing performance, that fault index 1 has highest testing
accuracy and fault index 7 has reduced testing accuracy. The overall training and
testing accuracy for SKBPF single fault is 93.41% and 82.66% respectively.
Figure 5.3 SVF Double Faults- Average Training and Testing Results
Page 78
65
Fault Index Accuracy (%) Error (%) Precision (%) Sensitivity (%) Specificity (%)
1 99.43 0.57 98.09 98.72 99.58
2 97.42 2.58 87.08 100 96.87
3 97.53 2.47 100 85.81 100
4 94.96 5.04 77.11 100 93.93
5 94.55 5.45 98.15 68.83 99.74
6 85.08 14.92 52.24 65.22 88.81
7 84.92 15.08 51.3 37.58 93.52
Average 93.41 6.587 80.56 79.45 96.06
Fault Index Accuracy (%) Error (%) Precision (%) Sensitivity (%) Specificity (%)
1 100 0 0 0 100
2 86.24 13.76 0 0 86.24
3 94.95 5.05 0 0 94.95
4 86.24 13.76 65.63 84 86.9
5 85.45 14.55 94.74 72 96.67
6 63.09 36.91 45.1 46 71.72
7 62.67 37.33 41.18 28 80
Average 82.66 17.33 35.23 32.85 88.07
The figure 5.4 shows the training and testing accuracies for the individual fault
indexes.
Table 5.5 SKBPF Single Fault- Training data results
Table 5.6 SKBPF Single Fault- Testing data results
Page 79
66
5.3.5 SKBPF- DOUBLE FAULT
The SaE-ELM algorithm for SKBPF double fault dataset is simulated and the
training and testing results are generated and the performance analysis is performed
with these results. The results are tabulated in table 5.7 and 5.8. The table 5.7 shows
the training results for SKBPF double fault. The algorithm produces higher training
accuracy almost for all the fault indexes. The table 5.8 shows the testing performance
using the SaE-ELM algorithm. The algorithm shows higher testing accuracy for two
fault indexes namely fault index 4 and 5 and least testing accuracy for fault index 10.
The overall training and testing accuracy for SKBPF double faults using SaE-ELM is
97.5% and 82% respectively. The precision for training is high which is 90.55% and
for testing it is 10.53 % which means that the training results are highly reproducible
and testing results are less reproducible.
Figure 5.4 SKBPF Single Fault- Training and Testing
performance for each fault index
Page 80
67
Fault Index Accuracy (%) Error (%) Precision (%) Sensitivity (%) Specificity (%)
1 99.04 0.96 91.84 99.2 99.02
2 97.94 2.06 100 79.4 100
3 97.96 2.04 83.17 99.8 97.75
4 96.22 3.78 76.86 89 97.02
5 97.42 2.58 96.49 77 99.69
6 98.48 1.52 86.81 100 98.31
7 98.5 1.5 100 85 100
8 97.42 2.58 87.03 87.2 98.55
9 96.04 3.96 85.12 77.96 98.3
10 99.5 0.5 95.23 100 99.44
Average 97.85 2.148 90.255 89.456 98.80
Fault Index Accuracy (%) Error (%) Precision (%) Sensitivity (%) Specificity (%)
1 83.1 16.9 0 0 83.1
2 100 0 0 0 100
3 98.37 1.63 0 0 98.37
4 100 0 0 0 100
5 100 0 0 0 100
6 89.11 10.89 0 0 89.11
7 61.7 38.3 10.53 29.17 66.15
8 52.85 47.15 0 0 65.49
9 84.89 15.11 0 0 97.88
10 50.06 49.94 0 0 100
Average 82 17.99 10.53 29.17 90.01
Table 5.7 SKBPF Double Fault- Training data results
Table 5.8 SKBPF Double Fault - Testing data results
Page 81
68
The figure 5.5 shows the average training and testing performance measures
for the SKBPF-double faults.
5.3.6 CMOS-Operational Amplifier
The SaE-ELM algorithm is executed for the CMOS data set the results for
each fault index are tabulated in the table 5.9 and 5.10. From the table 5.9, the results
show that the fault indexes 6, 10, 12 and 15 have highest training accuracy among the
other fault indexes. The fault index 1 has least training accuracy with higher
percentage error with 19% compared to other fault indexes. The average training
accuracy for CMOS opamp using SaE-ELM is 91.68% and the average error is
8.32%.The other measures of the CMOS opamp circuits are precision, sensitivity and
specificity and their average measures are 64.7, 59.23 and 95.22 respectively.
Figure 5.5 SKBPF Double Faults- Average Training and Testing
Results
Page 82
69
Fault
Model
Fault
Index
Accuracy
(%)
Error
(%)
Precision
(%)
Sensitivity
(%)
Specificity
(%)
M1-Open 1 81 19 36.36 61.54 83.91
M1-Short 2 93 7 0 0 100
M2-Open 3 90 10 66.67 57.14 95.35
M2-Short 4 98 2 80 100 97.83
M3-Open 5 87 13 54.55 42.86 94.19
M3-Short 6 100 0 100 100 100
M4-Open 7 86 14 50 57.14 90.7
M4-Short 8 91 9 25 14.29 96.77
M5-Open 9 82 18 33.33 38.46 88.51
M5-Short 10 100 0 100 100 100
M6-Open 11 94.44 5.56 72.22 100 93.51
M6-Short 12 100 0 100 100 100
M7-Open 13 86.67 13.33 52.38 84.62 87.01
M7-Short 14 88.89 11.11 50 20 97.5
M8-Open 15 100 0 100 100 100
M8-Short 16 94.44 5.56 0 0 100
C1-Open 17 88.89 11.11 0 0 100
C1-Short 18 88.89 11.11 50 90 88.75
Average 91.68 8.32 64.7 59.23 95.22
The table 5.10 shows the testing results of CMOS-OPAMP. The results shows
that the fault indexes 2, 3, 4, 10 and 15 have higher testing accuracy of 100 %
compared to other fault indexes. The fault index 7 has least testing accuracy of 61.54
% with error of 38.46% compared to rest of the fault indexes.
Table 5.9 CMOS Opamp- Training Results
Page 83
70
Fault
Model
Fault
Index
Accuracy
(%)
Error
(%)
Precision
(%)
Sensitivity
(%)
Specificity
(%)
M1-Open 1 92.31 7.69 0 0 92.31
M1-Short 2 100 0 0 0 100
M2-Open 3 100 0 0 0 100
M2-Short 4 100 0 0 0 100
M3-Open 5 84.62 15.38 50 50 90.91
M3-Short 6 100 0 100 100 100
M4-Open 7 61.54 38.46 25 33.33 70
M4-Short 8 73.08 26.92 0 0 90.48
M5-Open 9 65.38 34.62 20 16.67 80
M5-Short 10 100 0 0 0 100
M6-Open 11 77.27 22.73 0 0 77.27
M6-Short 12 100 0 0 0 100
M7-Open 13 81.82 18.18 0 0 81.82
M7-Short 14 81.82 18.18 0 0 100
M8-Open 15 100 0 100 100 100
M8-Short 16 77.27 22.73 0 0 100
C1-Open 17 81.82 18.18 0 0 100
C1-Short 18 81.82 18.18 50 100 77.78
Average 86.59 13.40 34.5 40 92.25
The average training and testing accuracy for CMOS opamp using SaE-ELM is
91.68% and 86.59% respectively.
Table 5.10 CMOS Opamp- Testing Results
Page 84
71
CHAPTER 6
KERNEL EXTREME LEARNING MACHINE
Kernel based Extreme learning machine (KELM) is a single hidden-layer feed
forward neural network learning algorithm. In KELM the number of hidden nodes is
not chosen, it is arbitrarily determined by the algorithm based on the application. The
ELM algorithm determines the initial parameters of input weights and hidden biases
randomly with simple kernel function. The stability and generalization performance of
the ELM algorithm is determined by these input parameters. KELM improves the
stability and performance by eliminating feature mapping of hidden neurons and with
the group of activation functions. KELM has kernel parameters which are optimised
and it improves the generalization performance compared to ELM.
6.1 EXTREME LEARNING MACHINE
There are two steps in ELM learning process. They are feature mapping and
linear projection. The feature mapping is the process of mapping the input space RD to
high dimensional feature space RL with preserving the properties of the training data.
Optimization scheme is used for the linear projection of high dimensional data to low
dimensional feature space RC and linear classifier is used for classification. In ELM
tuneable activation function is used for solving the data dependent on hidden neurons.
To avoid the application of time consuming algorithm for the determination of the
ELM space dimensionality and performance, KELM is used for the applications.
6.2 KERNEL EXTREME LEARNING MACHINE
The Kernel methods are new class of algorithms which reduces the cost
function. The ELM algorithm is widely used in many fields but it consumes time in
determining the ELM space, to overcome this drawback kernel version of ELM can be
used. The kernel version of ELM is similar to ELM in generating input weights
randomly , the only difference between ELM and KELM is that the hidden layer
output is not calculated they are inherently encoded called as ELM kernel matrix and
they are defined as = where represents the training data representations in
Page 85
72
ELM space . In KELM the kernel matrix defined on the input data determines the
ELM space. The kernel version of ELM is obtained from the output function of ELM
by replacing the hidden layer output matrix by kernel matrix. The N arbitrary distinct
samples (xi ,ti) | xi Ԑ Rn , ti Ԑ Rm , i=1,2,......,N the output function in ELM with L
hidden neurons is
() = ℎ() = ℎ() (6.1)
β= [β1,β2,......, βL] is the vector of output weights between the hidden layer of L
neurons and the output neuron and h(x)=[ h1(x),h2(x),......, hL(x)] is the output vector
of the hidden layer with respect to the input x and it maps the data from input space to
the ELM feature space.
To improve the generalization performance and to decrease the training error
the output weight and training error should be minimized at the same time.
Minimize |Hβ − T|, |β| (6.2)
Where ||Hβ-T|| is the training error and ||β|| is the output weight.
The least square solution based on Karush-Kuhn-Tuker theorems (KKT) conditions
the output weight β can be written as
β = 1
+
(6.3)
Where H is the hidden layer output matrix,
C is the regularization coefficient and T is the expected output matrix of the input
samples.
The output function of the ELM learning algorithm is
() = ℎ() 1
+
(6.4)
Page 86
73
If the feature mapping of h(x) is unknown then the kernel matrix is used to determine
the ELM feature space which is defined based on the Mercer’s conditions is defined as
= : = ℎ()ℎ = , (6.5)
The output function of KELM can be defined as
() = [(, ), … … , (, )] 1
+
(6.6)
Where M=HHT and k (i,j) is the kernel function of hidden neurons of single hidden
layer feed-forward neural networks. There are 4 different kernel functions available in
KELM for the computation of kernel matrix. The kernel functions are RBF kernel,
linear kernel, polynomial kernel and wavelet kernel. Among the four kernels RBF
kernel is chosen as standard kernel for the applications because of the nature of inputs
given to the kernel and it has higher performance in terms of accuracies in lesser time
compared to the other kernels.
6.3 SIMULATION RESULTS
The KELM algorithm performance is evaluated by using the data sets
mentioned in section 3.7 in table 3.3. The steps for analysing the performance of the
circuits using KELM is mentioned in the flowchart in figure 6.1. The figure shows the
difference in the computation between the ELM and KELM algorithms. The
performance analysis of the algorithm is measured by using metrics evaluated from
the confusion matrix.
Page 87
74
6.3.1 SVF-SINGLE FAULT
The KELM algorithm for single fault is executed by varying the kernel
parameter for RBF kernel. The results obtained by varying the kernel parameter for
SVF single fault is shown in table 6.1. The results from the table indicate that if the
kernel parameter is reduced the training and testing accuracies are increased
drastically. These kernel parameters are varied randomly by trial and error basis. The
kernel parameter 1 and below 1 values gives the improved accuracies compared to the
other kernel parameter. For SVF circuit with single fault kernel parameter 0.01 is
chosen as the standard value for the RBF kernel. The figure 6.2 shows the chart for
training and testing accuracies for the varied kernel parameters. From the figure 0.01
Figure 6.1 KELM and ELM Algorithm steps
Page 88
75
and below its range gives the maximum training and testing accuracy. For these values
the faults are classified correctly for both in the training and testing phase.
Kernel Parameter Training Time(s) Testing Time(s) Training Accuracy Testing Accuracy
1000 0.1447 0.0223 0.2174 0.2111
500 0.1512 0.0225 0.2689 0.2370
100 0.1474 0.0245 0.3581 0.2963
10 0.1426 0.0241 0.8295 0.8111
1 0.1327 0.0279 0.9542 0.9593
0.5 0.1936 0.0320 0.9886 0.9889
0.01 0.1453 0.0318 1 1
0.001 0.2378 0.0276 1 1
The training and testing performance for SVF single fault using KELM
analysed with additional metrics obtained from confusion matrix are tabulated in table
6.2 and 6.3.
Table 6.1 SVF Single Fault – Performance measures for varied
Kernel Parameter
Figure 6.2 SVF Single Fault – Training and Testing accuracies for
varied Kernel Parameter
Page 89
76
Fault Index Accuracy (%) Error (%) Precision (%) Sensitivity (%) Specificity (%)
1 100 0 100 100 100
2 100 0 100 100 100
3 100 0 100 100 100
4 100 0 100 100 100
5 100 0 100 100 100
6 100 0 100 100 100
7 100 0 100 100 100
8 100 0 100 100 100
9 100 0 100 100 100
Average 100 0 100 100 100
Fault Index Accuracy (%) Error (%) Precision (%) Sensitivity (%) Specificity (%)
1 98.22 1.78 93.75 90 99.25
2 98.67 1.33 95.83 92 99.5
3 97.33 2.67 82.76 96 97.5
4 98.67 1.33 92.31 96 99
5 98.67 1.33 100 88 100
6 99.56 0.44 96.15 100 99.5
7 99.56 0.44 100 96 100
8 99.11 0.89 94.23 98 99.25
9 99.11 0.89 97.92 94 99.75
Average 98.77 1.23 94.77 94.44 99.31
The tabled results show the training and testing performance of the KELM
algorithm. The results from table 6.2 show that the classifier has higher training
Table 6.2 SVF Single Fault -Training data results
Table 6.3 SVF Single Fault -Testing data results
Page 90
77
accuracies for all the fault indexes i.e. all the faults are classified correctly during the
training phase. Similarly the table results for testing shows that all the fault indexes
are classified with minimum error. The average training and testing accuracies for
SVF single fault using KELM are 100% and 98.77% respectively.
6.3.2 SVF- DOUBLE FAULT
The KELM algorithm is used for classifying double faults in SVF benchmark
circuit. The training results for SVF-Double fault using KELM algorithm is tabulated
in table 6.4. The results show the classification performance of KELM for individual
fault classes. The algorithm shows higher training accuracy for all the fault indexes.
The fault indexes have higher precision, sensitivity and specificity. The testing results
for the above mentioned faults are tabulated in table 6.5. The results show that most of
the fault indexes have high testing accuracies the fault index 6 has less accuracy
compared to the other fault indexes with testing accuracy of 85% and the
corresponding fault index have lesser precision 32% which indicates that the
performance reproducibility is less of for that corresponding fault index.
Fault Index Accuracy (%) Error (%) Precision (%) Sensitivity (%) Specificity (%)
1 100 0 100 100 100
2 100 0 100 100 100
3 99.98 0.02 99.8 100
99.98
4 100 0 100 100 100
5 100
0 100 100 100
6 100
0 100 100 100
7 100
0 100 100 100
8 100
0 100 100 100
9 99.98 0.02 100
99.8 100
10 100 0 100
100 100
Average 99.96 0.004 99.98 99.98 99.98
Table 6.4 SVF Double Fault- Training data results
Page 91
78
Fault Index Accuracy (%) Error (%) Precision (%) Sensitivity (%) Specificity (%)
1 93.5 6.5 65.33 73.87 95.67
2 89.64 10.4 48.15 45.5 94.55
3 94.15 5.85 94.62 44 99.72
4 87.29 12.71 39.02 48 91.66
5 91.7 8.30 61.04 47 96.66
6 84.74 15.26 32.2 47.5 88.88
7 99.75 0.25 100 97.5 100
8 90.85 9.15 54.59 50.5 95.33
9 88.66 11.34 49.06 52 93.25
10 99.75 0.25 97.56 100 99.72
Average 92 8 64.157 60.59 95.54
The figure 6.3 shows the average training and testing performance measures
for the SVF double fault. The average results from the figure indicates the training
error is comparitively very less comapred to the testing error which is of 8%. The
average training and testing accuracies for SVF double faults using KELM are
99.96% and 92 % respectively.
Table 6.5 SVF Double Fault- Testing Performance
Page 92
79
6.3.3 SKBPF-SINGLE FAULT
The KELM algorithm for SKBPF single fault is executed and the training and
results are tabulated in table 6.6 for each fault class. The training result table 6.6
shows that among 7 fault indexes, the fault index 5 have maximum accuracy of 100%
which indicates that all the faults are correctly classified with 0 error and the other
measures for these fault indexes also 100 % which indicates the classifier gives
maximum performance for all the possible cases.
Fault Index Accuracy (%) Error (%) Precision (%) Sensitivity (%) Specificity (%)
1 100 0 100 100 100
2 100 0 100 100 100
3 100 0 100 100 100
4 100 0 100 100 100
5 100 0 100 100 100
6 93.23 6.77 78.06 75.16 06.35
7 93.23 6.77 75.46 78.34 95.73
Average 98.06 1.93 93.36 93.35 86.01
Table 6.6 SKBPF Single Fault- Training data results
Figure 6.3 SVF Double Faults- Average Training and Testing
Performance measures
Page 93
80
The testing results of SKBPF with single fault using KELM for each fault
indexes is tabulated in table 6.7 From the table 6.7, the results shows that the testing
accuracy is high for all the fault index except for fault index 6 and class 7 whose
training accuracy is 87.32% and the precision of these two fault indexes are almost
half of the other fault indexes which indicates the performance reproducibility of these
two fault indexes are very less.
Fault Index Accuracy (%) Error (%) Precision (%) Sensitivity (%) Specificity (%)
1 100 0 100 100 100
2 100 0 100 100 100
3 100 0 100 100 100
4 99.02 0.98 100 94 100
5 99.02 0.98 94.34 100 98.83
6 87.32 12.68 54.84 68 90.57
7 87.32 12.68 57.89 44 94.61
Average 96.09 3.90 86.72 86.57 97.71
The training and testing performance measures for each fault indexes can be
analysed from the chart shown in figure 6.4. The average training and testing
accuracies are 99.06% and 96.09% respectively for SKBPF circuit with single fault.
Table 6.7 SKBPF Single Fault- Testing data results
Page 94
81
6.3.4 SKBPF- DOUBLE FAULT
The KELM algorithm for SKBPF circuit with double faults is simulated. The
training and testing results are generated from the simulated results and the
performance analysis is performed with these results. The results are tabulated in table
6.8 and 6.9. The table 6.8 shows the training results for SKBPF double fault. The
algorithm produces 100% training accuracy for all the fault indexes. The algorithm
also produces 100 % precision, sensitivity and specificity for all the fault indexes
during training phase, which indicates that the classifier produces 100% results for all
the possible cases during training phase.
Figure 6.4 SKBPF Single Fault- Training and Testing accuracy performances for
each fault indexes
Page 95
82
Fault Index Accuracy (%) Error (%) Precision (%) Sensitivity (%) Specificity (%)
1 100 0 100 100 100
2 100 0 100 100 100
3 100 0 100 100 100
4 100 0 100 100 100
5 100 0 100 100 100
6 100 0 100 100 100
7 100 0 100 100 100
8 100 0 100 100 100
9 100 0 100 100 100
10 100 0 100 100 100
Average 100 0 100 100 100
The table 6.9 shows the testing performance of SKBPF double fault using
KELM algorithm. The algorithm shows higher testing accuracy all the classes except
for fault index 7 and 8 which have less testing accuracy compared to other fault
indexes and the precision is 0 for these two fault indexes which shows that the
performance or classification reproducibility cannot be obtained for these fault
indexes.
Table 6.8 SKBPF Double Faults –Training data results
Page 96
83
Fault Index Accuracy (%) Error (%) Precision (%) Sensitivity (%) Specificity (%)
1 94.81 5.19 89.29 50.34 99.38
2 96.31 3.69 100 60.67 100
3 97.56 2.44 92.56 78.87 99.38
4 94.99 5.01 78.79 56.93 98.56
5 95.74 4.26 21.74 51.72 96.56
6 98.37 1.63 85.64 100 98.2
7 76.22 23.78 0 0 83.14
8 75.45 24.55 0 0 85.86
9 87.73 12.27 29.73 40.74 91.75
10 88.74 11.26 80.67 72.18 94.25
Average 90.59 9.408 57.48 51.45 94.71
The figure 6.5 shows the average training and testing performance measures
for the SKBPF-double faults. The average training and testing accuracies for SKBPF
for double faults using KELM is 100% and 90.59% respectively.
Table 6.9 SKBPF-Double Fault Testing Data Performance
Figure 6.5 SKBPF Double Faults- Average Training and Testing Performance
Page 97
84
6.3.5 CMOS-OPERATIONAL AMPLIFIER
The KELM algorithm is executed for the CMOS data set the training results
for each fault class are tabulated in the table 6.10. From the table 6.10, the results
show that the fault index 6 and 10 has the maximum training accuracy of 100% which
means that the all the faults belonging to this fault index are correctly classified with
0% error compared to the other fault indexes.
Fault
Model
Fault
Index
Accuracy
(%)
Error
(%)
Precision
(%)
Sensitivity
(%)
Specificity
(%)
M1-Open 1 88 12 53.85 53.85 93.1
M1-Short 2 93 7 50 14.29 98.92
M2-Open 3 85 15 48 85.71 84.88
M2-Short 4 99 1 100 87.5 100
M3-Open 5 82 18 40 57.14 86.05
M3-Short 6 100 0 100 100 100
M4-Open 7 83 17 38.46 35.71 90.7
M4-Short 8 93 7 0 0 100
M5-Open 9 87 13 50 38.46 94.25
M5-Short 10 100 0 100 100 100
M6-Open 11 94.44 5.56 72.22 100 93.51
M6-Short 12 97.78 2.22 100 71.43 100
M7-Open 13 88.89 11.11 57.89 84.62 89.61
M7-Short 14 88.89 11.11 50 20 97.5
M8-Open 15 97.78 2.22 88.24 100 97.33
M8-Short 16 94.44 5.56 0 0 100
C1-Open 17 88.89 11.11 50 50 93.75
C1-Short 18 88.89 11.11 0.5 50 93.75
Average 91.67 8.33 65.54 58.26 95.18
Table 6.10 CMOS Opamp- Training Results
Page 98
85
The table 6.11 shows the testing results of CMOS-OPAMP. The results shows
that the fault index 5 has less testing accuracy which is 76.92% compared to other
fault indexes. The overall training and testing accuracy for CMOS-opamp using
KELM is 91.67% and 88.93 % respectively.
Fault
Model
Fault
Index
Accuracy
(%)
Error
(%)
Precision
(%)
Sensitivity
(%)
Specificity
(%)
M1-Open 1 80.77 19.23 25 33.33 86.96
M1-Short 2 88.46 11.54 0 0 97.87
M2-Open 3 78.85 21.15 33.33 83.33 78.26
M2-Short 4 98.08 1.92 100 8 100
M3-Open 5 76.92 23.08 25 25 86.36
M3-Short 6 100 0 100 100 100
M4-Open 7 84.62 15.38 37.5 0.5 89.13
M4-Short 8 90.38 9.62 0 0 100
M5-Open 9 82.69 17.31 0 0 93.48
M5-Short 10 100 0 100 100 100
M6-Open 11 88.89 11.11 54.55 100 87.18
M6-Short 12 95.56 4.44 100 60 100
M7-Open 13 84.44 15.56 44.44 66.67 87.18
M7-Short 14 84.44 15.56 0 0 95
M8-Open 15 95.56 4.44 71.43 100 95
M8-Short 16 88.89 11.11 0 0 100
C1-Open 17 91.11 8.89 50 50 95.12
C1-Short 18 91.11 8.89 50 50 95.12
Average 88.93 11.06 49.45 49.90 93.70
Table 6.11 CMOS Opamp- Testing Results
Page 99
86
6.4 PERFORMANCE COMPARISON OF PROPOSED METHODOLGIES
The three algorithms ELM, SaE-ELM and KELM are proposed in this project.
All these algorithms are used to train Single layer feedforward neural networks
(SLFN). ELM is the basic algorithm used to train the network with the random
generated input weights, this algorithm gives better performance compared to the
other algorithms but still the performance of the algorithm can be improved by
optimizing the hidden node parameters. SaE-ELM is used for optimizing the hidden
node parameters and uses ELM algorithm for classification. This algorithm shows
improved performance compared to ELM because of the hidden node optimization.
The next proposed algorithm is the kernel version of ELM, this algorithm shows
higher performance compared to the other two proposed algorithms because it reduces
the cost function and it uses only the kernel matrix and the training sample for the
computation of output weight and classification unlike ELM uses, input weight, bias,
hidden neurons for the output weight computation and classification. The 5 data sets
namely SVF with single and double faults, SKBPF with single and double faults and
CMOS opamp data sets described in section 3.7 in table 3.3 are given as input for
evaluating the performance of all the proposed algorithms. The training and testing
results of all the algorithms are compared separately for each datasets.
6.4.1 SINGLE FAULT RESULTS COMPARISON
The SVF, SKBPF and CMOS circuit single fault training and testing results of
all the algorithms are compared and analysed. The table 6.12 and 6.13 shows the
training results comparison of all the algorithms for single fault data set. The table
results show that KELM algorithm has 100% training classification accuracy and
100% precision compared to the other two algorithms.
Page 100
87
Algorithms Accuracy (%) Error (%)
SVF SKBPF CMOS SVF SKBPF CMOS
ELM 86.58 83.9 79.51 15.55 16.1 20.49
SaE-ELM 88.05 93.34 85.67 11.95 6.66 14.33
KELM 100 98.07 91.67 0 1.93 8.33
Algorithms Precision (%) Sensitivity (%) Specificity (%)
SVF SKBPF CMOS SVF SKBPF CMOS SVF SKBPF CMOS
ELM 88.8 84.21 60.76 86.7 84.09 55.95 98.3 97.14 94.64
SaE-ELM 89.1 80.57 64.7 86.9 79.45 59.25 98.4 86.06 95.22
KELM 100 93.36 65.54 100 93.36 58.26 100 98.87 95.18
Table 6.12 Single Fault-Training Results Comparison with Accuracy
and error
Table 6.13 Single Fault-Training Results Comparison with Precision, Sensitivity and
Specificity
Figure 6.6 SVF Single Fault-Training Results Comparison
Page 101
88
The figure 6.6, 6.7 and 6.8 shows the training performance of all the three
algorithms for SVF, SKBPF and CMOS circuits respectively.The table 6.14 and 6.15
shows the testing results comparison of all the algorithms for single fault data set. The
table results show that KELM algorithm has higher testing classification accuracy of
94.4 % compared to the other two algorithms and it has higher precision, sensitivity
and specificity measures compared to other two algorithms.
Figure 6.7 SKBPF Single Fault-Training Results Comparison
Figure 6.8 CMOS Single Fault-Training Results Comparison
Page 102
89
Algorithms Accuracy (%) Error (%)
SVF SKBPF CMOS SVF SKBPF CMOS
ELM 84.44 80.57 74.89 14.47 19.43 25.11
SaE-ELM 86.1 88.69 82.59 13.9 15.31 17.41
KELM 94.4 96.1 88.93 5.6 3.9 11.07
Algorithms Precision (%) Sensitivity (%) Specificity (%)
SVF SKBPF CMOS SVF SKBPF CMOS SVF SKBPF CMOS
ELM 86.9 79.98 49.61 84.3 80.57 48.6 98 96.48 93.46
SaE-ELM 88.6 45.7 34.5 87.6 69 40 98.1 92.03 92.25
KELM 94.7 86.72 49.45 94.4 86.57 49.90 99.3 97.7 93.7
6.4.2 DOUBLE FAULTS RESULTS COMPARISON
The SVF, SKBPF circuit double faults training and testing results of all the
algorithms are compared and analysed. The table 5.16 and 5.17 shows the training
results comparison of all the algorithms for double faults data set. The table results
show that KELM algorithm has 99.88% training classification accuracy and 99.98%
precision compared to the other two algorithms.
Algorithms Accuracy (%) Error (%)
SVF SKBPF SVF SKBPF
ELM 79.25 85.21 20.75 14.79
SaE-ELM 90 93.34 10 6.66
KELM 99.88 99.07 0.12 0.93
Table 6.14 Single Fault-Testing Results Comparison with Accuracy and
error
Table 6.15 Single Fault-Testing Results Comparison with Precision,
Sensitivity and Specificity
Table 6.16 Double Fault-Training Results Comparison with Accuracy and error
Page 103
90
Algorithms Precision (%) Sensitivity (%) Specificity (%)
SVF SKBPF SVF SKBPF SVF SKBPF
ELM 76.9 88.32 64.3 88.15 89 98.66
SaE-ELM 79.58 45.7 77.8 69 97.51 92.03
KELM 99.98 100 99.98 100 100 100
The table 6.18 and 6.19 shows the testing results comparison of all the
algorithms for double faults data set. The table results show that KELM algorithm has
93.26% testing classification accuracy and it has higher precision, sensitivity and
specificity measures compared to other two algorithms.
Algorithms Accuracy (%) Error (%)
SVF SKBPF SVF SKBPF
ELM 54.25 39.48 45.75 60.52
SaE-ELM 84.4 93.34 15.6 6.66
KELM 93.26 98.57 6.74 1.43
Algorithms Precision (%) Sensitivity (%) Specificity (%)
SVF SKBPF SVF SKBPF SVF SKBPF
ELM 81.7 33.7 89.3 32.6 94 92.86
SaE-ELM 41.15 45.7 64.14 69 96.24 92.03
KELM 64.16 57.84 65.69 51.15 95.54 94.71
Table 6.17 Double Fault-Training Results Comparison with Precision,
Sensitivity and Specificity
Table 6.18 Double Fault-Testing Results Comparison with Accuracy and error
Table 6.19 Double Fault-Training Results Comparison with Precision,
Sensitivity and Specificity
Page 104
91
The figure 6.9 and 6.10 shows the testing performance of all the three
algorithms for SVF, SKBPF circuits respectively for double faults. The figure shows
that KELM has higher classification accuracy for testing compared to ELM and SaE-
ELM.
Figure 6.9 SVF Double Faults-Testing Results Comparison
Figure 6.10 SVF Double Faults-Testing Results Comparison
Page 105
92
CHAPTER 7
CONCLUSION The parametric and catastrophic fault detection is experimented using ELM
algorithm and its variants. ELM is a single hidden layer feed forward neural network
(SLFN) and iterative tuning is not needed for the hidden layer. The algorithm
randomly chooses the input weight and the bias matrix. The hidden layer output is
calculated from the activation function and the randomly generated input matrices.
The hidden layer output is used in the computation of the output weight which is used
in the calculation of training and testing accuracy. The training and testing
classification accuracy for SVF bench mark circuit is 86.58 % and 84.44 %
respectively.
SaE-ELM is a variant of ELM, in this algorithm the hidden node parameters
are optimized and the ELM algorithm is used for fault detection. 88.05% and 86.1 %
are the training and testing accuracies obtained for SVF circuit using SaE-ELM.
KELM is an infinite SLFN which uses low rank decomposition matrix defined
on the input data improves the classification accuracy, further algorithm chooses
hidden nodes based on the application which further improves the performance. SVF
single fault detection using KELM results in 100 % training accuracy and 94.4 %
testing accuracy.
The results obtained for the other benchmark circuits are also analysed for all
the three algorithms based on the measures like accuracy, error, precision, sensitivity
and specificity. The comparison shows that KELM has higher training and testing
accuracy measures compared to other two algorithms, and has higher performance
measures compared to other two algorithms. For SVF circuit KELM gives 100%
training accuracy where as other two algorithms gives accuracy less than 90%.
KELM with infinite SLFN has higher classification accuracy and better generalization
performance with less computational time.
Page 106
93
REFERENCES
[1] Jingyu Zhou, Shulin Tian, Cheglin Yangv , and Xuelong Ren, “Test
Generation Algorithm for fault detection Analog Circuits Based on Extreme
Learning Machine,” in Hindawi Publishing Corporation, Computational
Intelligence and Neuroscience ,Volume 2014, Article ID 740836, 11 pages.
[2] Chen-Yang Pan and Kwang-Ting (Tim) Cheng, “Test Generation for Linear
Time-Invariant Analog Circuits” in IEEE TRANSACTIONS ON CIRCUITS
AND SYSTEMS—II: ANALOG AND DIGITAL SIGNAL PROCESSING,
VOL. 46, NO. 5, MAY 1999.
[3] Ting Long, Houjun Wang and Bing Long, “Test generation algorithm for
analog systems based on support vector machine” in Springer SIViP (2011)
5:527–533 DOI 10.1007/s11760-010-0168-6.
[4] Ashok Balivada, Jin Chen and Jacob A. Abraham “Analog Testing with Time
Response Parameters” in IEEE Computer Society, Issue No.02 , vol.13, pp: 18-
25, 1996.
[5] Guang-Bin Huang, Qin-Yu Zhu, and Chee-Kheong Siew, “Extreme learning
machine: Theory and applications” in Elsevier, Neurocomputing 70, pp: 489-
501, 2006.
[6] Guang-Bin Huang, Hongming Zhou, Xiaojian Ding, and Rui Zhang,
“Extreme Learning Machine for Regression and Multiclass Classification”, IEEE
TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B:
CYBERNETICS, VOL. 42, No. 2, APRIL 2012.
[7] Guang-Bin Huang, Hongming Zhou, and Xiaojian Ding, “Optimization
method based extreme learning machine for classification” in Elsevier,
Neurocomputing 74, pp: 155-163, 2010.
[8] Jiang Cui and, Youren Wang “A novel approach of analog circuit fault
diagnosis using support vector machines classifier” in Elsevier, Measurement 44,
pp: 281-289, 2011.
[9] T.REVATHI and, DR.P.SUMATHI, “A NOVEL MICROARRAY GENE
RANKING AND CLASSIFICATION USING EXTREME LEARNING
Page 107
94
MACHINE ALGORITHM”, in Journal of Theoretical and Applied Information
Technology, Vol. 68 No.3, October 2014.
[10] Qin-Yu Zhu, A.K. Qin, P.N. Suganthan and, Guang-Bin Huang,
“Evolutionary Extreme Learning Machine” in Elsevier, Pattern Recognition 38
1759 – 1763, 2005.
[11] Alexandros Iosifidisa, Anastastios Tefasa and Ioannis Pitasa, “On the
Kernel Extreme Learning Machine Classifier” in Elsevier, Pattern Recognition
Letters, 2015.
[12] Bin Li, Xuewen Rong, and Yibin Li, “An Improved Kernel Based Extreme
Learning Machine for Robot Execution Failures”, Hindawi Publishing
Corporation The Scientific World Journal, Article ID 906546, 2014.
[13] Junhua Ku, Zhihua Cai and Xiuying Yang, “Self-adaptive Differential
Evolution Extreme Learning Machine for the Classification of Hyperspectral
Images”, International Conference on Mechatronics, Control and Electronic
Engineering, 2014.
[14] Jiuwen Cao, Zhiping Lin and Guang-Bin Huang, “Self-Adaptive
Evolutionary Extreme Learning Machine”, Springer Science, 2012.
[15] P. Kalpana , K. Gunavathi,” Wavelet based fault detection in analog VLSI circuits using neural networks”in Elsevier, Applied soft computing ,2008.
Page 108
95
LIST OF PUBLICATIONS
NATIONAL CONFERENCE
1. Ms.M.Shanthi, Ms.V.Kalpana and Ms.M.C.Bhuvaneswari, “Analog circuit
fault detection using ELM and KELM”, in National Conference NCACCS
2016 on 4th April at Government College of technology, Coimbatore.
2. Ms.M.Shanthi, Ms.V.Kalpana and Ms.M.C.Bhuvaneswari, “Component level
fault detection in Analog circuits using Extreme Learning Machine”, in
National Conference CITEL 2016 on 30th March at Kumaraguru College of
technology, Coimbatore.