57
Word embeddings and neural language modeling AACIMP 2015 Sergii Gavrylov
| Date post: | 22-Jan-2017 |
| Category: |
Science |
| Upload: | sergii-gavrylov |
| View: | 706 times |
| Download: | 0 times |

Word embeddings and neural language modeling
AACIMP 2015Sergii Gavrylov

Overview● Natural language processing
● Word representations
● Statistical language modeling
● Neural models
● Recurrent neural network models
● Long short-term memory rnn models

Natural language processing
● NLP mostly works with text data (but its methods could be applied
to music, bioinformatic, speech etc.)
● From the perspective of machine learning NL is a sequence of
variable-length sequences of high-dimensional vectors.

Word representation

One-hot encodingV = {zebra, horse, school, summer}

One-hot encodingV = {zebra, horse, school, summer}
v(zebra) = [1, 0, 0, 0] v(horse) = [0, 1, 0, 0]v(school) = [0, 0, 1, 0]v(summer) = [0, 0, 0, 1]

One-hot encodingV = {zebra, horse, school, summer}
v(zebra) = [1, 0, 0, 0] v(horse) = [0, 1, 0, 0]v(school) = [0, 0, 1, 0]v(summer) = [0, 0, 0, 1]
(+) Pros:Simplicity
(-) Cons:One-hot encoding can be memory inefficientNotion of word similarity is undefined with one-hot encoding

Distributional representation
Is there a representation that preserves the similarities of word meanings?
d(v(zebra), v(horse)) < d(v(zebra), v(summer))

Distributional representation
Is there a representation that preserves the similarities of word meanings?
d(v(zebra), v(horse)) < d(v(zebra), v(summer))
“You shall know a word by the company it keeps” - John Rupert Firth

Distributional representation
clic.cimec.unitn.it/marco/publications/acl2014/lazaridou-etal-wampimuk-acl2014.pdf
“A cute, hairy wampimuk is sitting on the hands.”

Distributional representation
www.cs.ox.ac.uk/files/6605/aclVectorTutorial.pdf

Distributional representation
www.cs.ox.ac.uk/files/6605/aclVectorTutorial.pdf

Distributional representation
(+) Pros:SimplicityHas notion of word similarity
(-) Cons:Distributional representation can be memory inefficient

Distributed representation
V is a vocabulary
wi ∈ V
v(wi) ∈ Rn
v(wi) is a low-dimensional, learnable,
dense word vector

Distributed representation
colah.github.io/posts/2014-07-NLP-RNNs-Representations

Distributed representation
(+) Pros:Has notion of word similarityis memory efficient (low dimensional)
(-) Cons:is computationally intensive

Distributed representation as a lookup table
W is a matrix whose rows are v(wi) ∈ Rn
v(wi) returns ith row of W

Statistical language modeling
A sentence s = (x1, x
2, … , x
T)
How likely is s?p(x
1, x
2, … , x
T)
according to the chain rule (probability)

n-gram modelsn-th order Markov assumption

n-gram modelsn-th order Markov assumption
bigram model of s = (a, cute, wampimuk, is, on, the, tree, .)1. How likely does ‘a’ follow ‘<S>’?2. How likely does ‘cute’ follow ‘a’?3. How likely does ‘wampimuk’ follow ‘cute’?4. How likely does ‘is’ follow ‘wampimuk’?5. How likely does ‘on’ follow ‘is’?6. How likely does ‘the’ follow ‘on’?7. How likely does ‘tree’ follow ‘the’?8. How likely does ‘.’ follow ‘tree’?9. How likely does ‘<\S>’ follow ‘.’?

n-gram modelsn-th order Markov assumption
bigram model of s = (a, cute, wampimuk, is, on, the, tree, .)
the counts are obtained from a training corpus

n-gram modelsIssues:
Data sparsityLack of generalization:
[ride a horse], [ride a llama] [ride a zebra]

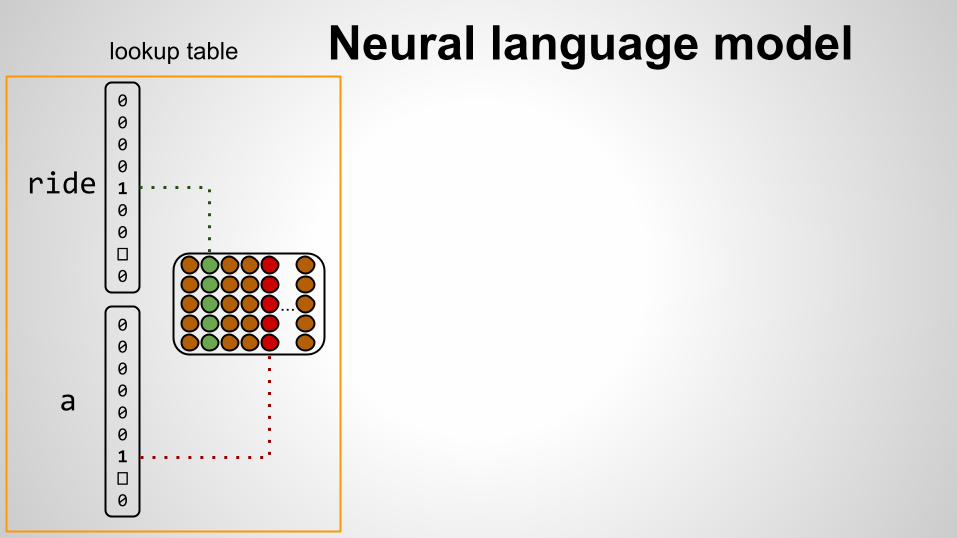
Neural language model
ride
a
lookup table

Neural language model0000100�0
0000001�0
ride
a
lookup table

Neural language model0000100�0
0000001�0
...
ride
a
lookup table
0000100�0
0000001�0
...
ride
a
lookup table Neural language model

Neural language model0000100�0
0000001�0
...
ride
a
lookup table
neural network

Neural language model0000100�0
0100000�0
0000001�0
...
ride
a
lookup table
neural network

Neural language model0000100�0
0100000�0
0000001�0
...
ride
a
lookup table
neural network
zebra should have representation similar to horse and llama
Now we can generalize to the unseen n-grams
[ride a zebra]

Recurrent neural network models
There is no Markov assumption

Recurrent neural network models
There is no Markov assumption
arxiv.org/pdf/1503.04069v1.pdf

Recurrent neural network models
yesterday

Recurrent neural network models
yesterday

Recurrent neural network models
yesterday

Recurrent neural network models
yesterday

Recurrent neural network models
yesterday we

Recurrent neural network models
yesterday we

Recurrent neural network models
yesterday we

Recurrent neural network models
yesterday we

Recurrent neural network models
yesterday we were
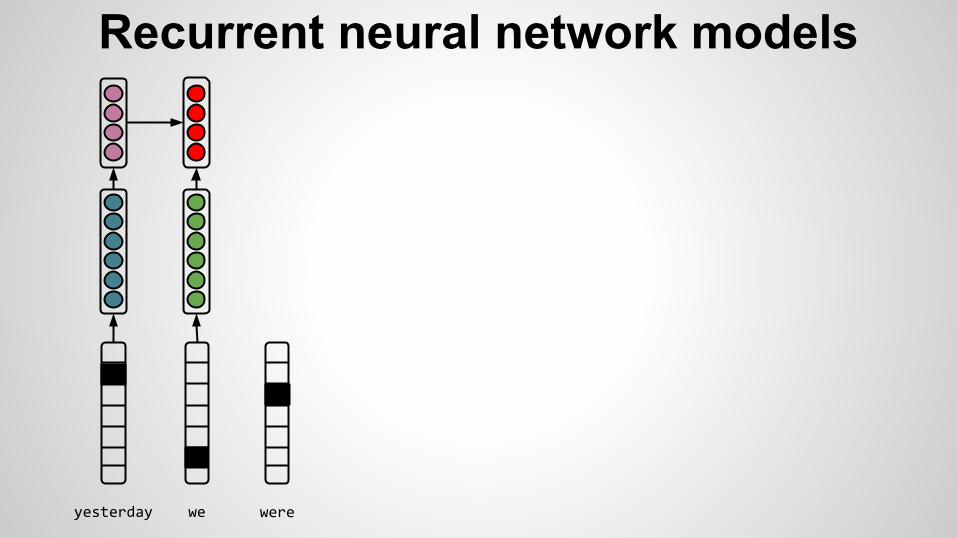
Recurrent neural network models
yesterday we were

Recurrent neural network models
yesterday we were

Recurrent neural network models
yesterday we were
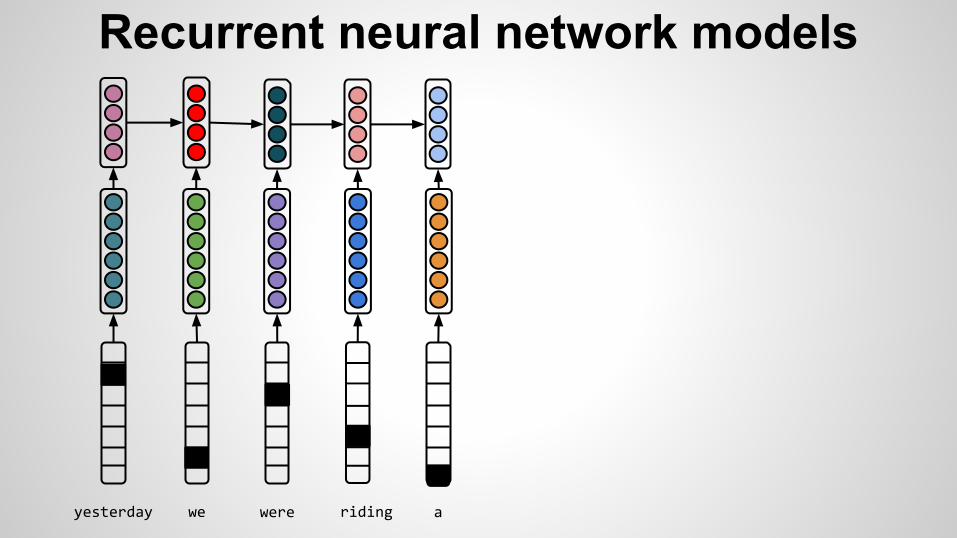
Recurrent neural network models
yesterday we were riding a

Recurrent neural network models
yesterday we were riding a
horse

Recurrent neural network models
Vanishing/exploding gradient problemwww.jmlr.org/proceedings/papers/v28/pascanu13.pdf
Naïve transition has difficulty in handling long-term dependencies

Long short-term memory rnn models
arxiv.org/pdf/1503.04069v1.pdf

Long short-term memory rnn models
arxiv.org/pdf/1503.04069v1.pdf
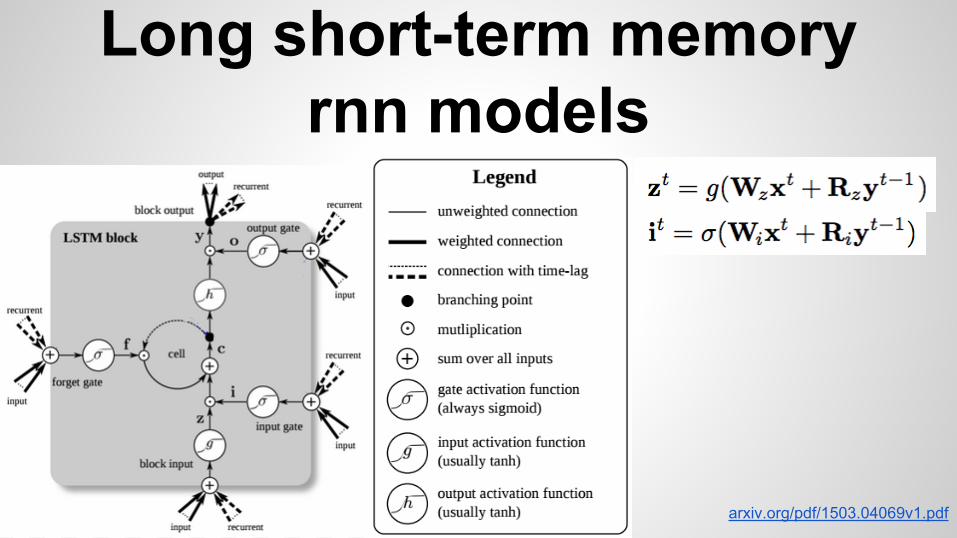
Long short-term memory rnn models
arxiv.org/pdf/1503.04069v1.pdf
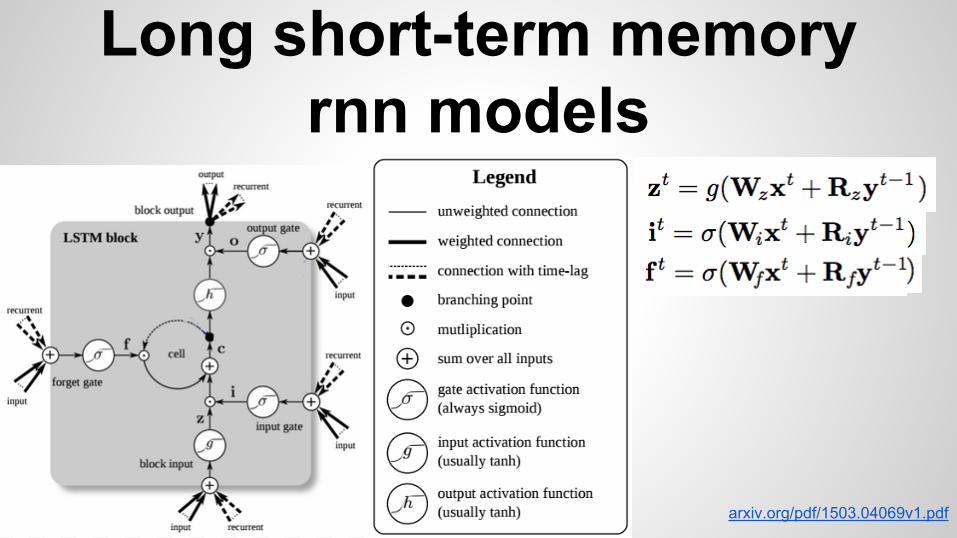
Long short-term memory rnn models
arxiv.org/pdf/1503.04069v1.pdf

Long short-term memory rnn models
arxiv.org/pdf/1503.04069v1.pdf
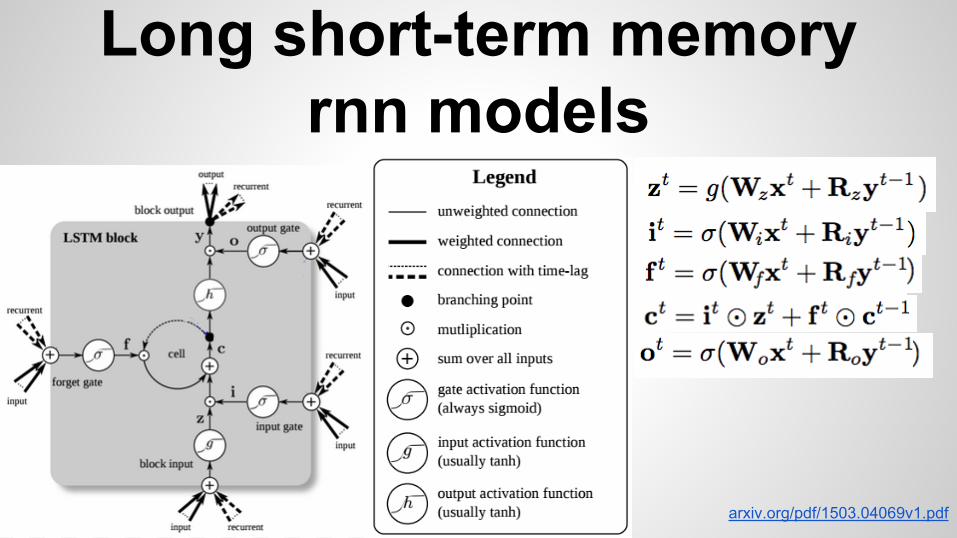
Long short-term memory rnn models
arxiv.org/pdf/1503.04069v1.pdf

Long short-term memory rnn models
arxiv.org/pdf/1503.04069v1.pdf
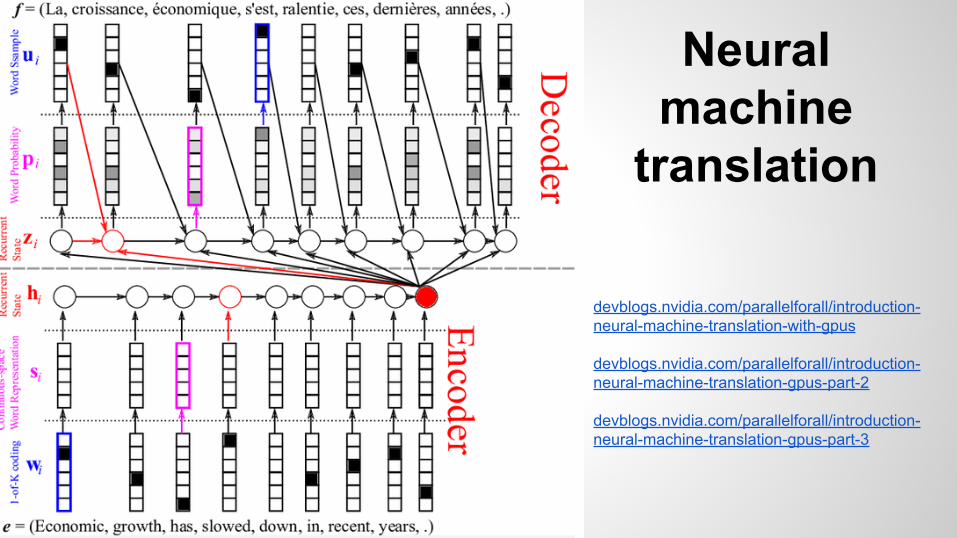
Neural machine
translation
devblogs.nvidia.com/parallelforall/introduction-neural-machine-translation-with-gpus
devblogs.nvidia.com/parallelforall/introduction-neural-machine-translation-gpus-part-2
devblogs.nvidia.com/parallelforall/introduction-neural-machine-translation-gpus-part-3

Image captioning
cs.stanford.edu/people/karpathy/cvpr2015.pdf

Image captioning
cs.stanford.edu/people/karpathy/cvpr2015.pdfarxiv.org/pdf/1411.4555v2.pdf

Conclusion
CS224d: Deep Learning for Natural Language Processingcs224d.stanford.edu
● Neural methods provide us with a powerful set of tools for embedding language.
● They provide better ways of tying language learning to extra-linguistic contexts (images, knowledge-bases, cross-lingual data).




![Neural Graph Collaborative Filtering · 2019-05-21 · item embeddings]. (1) It is worth noting that this embedding table serves as an initial state for user embeddings and item embeddings,](https://static.documents.pub/doc/80x56/5e4b2359136a851cfe576dbe/neural-graph-collaborative-filtering-2019-05-21-item-embeddings-1-it-is-worth.jpg)

![Improving word embeddings projection for Turkish hypernym ...journals.tubitak.gov.tr/elektrik/issues/elk-19-27... · neural network approaches [4–8]. These studies showed that words](https://static.documents.pub/doc/80x56/5f04d2957e708231d40fe1ce/improving-word-embeddings-projection-for-turkish-hypernym-neural-network-approaches.jpg)










