38
Language and Document Models in Information Retrieval ZhuoRan Chen 2006-2-8

Language and Document Models in Information Retrieval
ZhuoRan Chen
2006-2-8

Table of Content
Definitions Applications Evaluations SLM for IR Burstiness

What is a SLM?
A Statistical Language Model (SLM) is a probability distribution function over sequences of words. An example: P(“Rose is red”) > P(“Red is
Rose”) > 0 Another: P( color around | It might be
nice to have a little more ) = ?

Two Stories of SLM
The Story of Document Model Giving a document (def: a sequence of words), how good
is that document (the odds that it is composed by a person)?
Judgment may be drawn from words and other sources, e.g. syntax, burstiness, hyperlinks, etc.
The Story of generating (used in SR and IR) Giving a training set (def: a collection of sequences), how
can we generate a sequence that is in accordance with the training set?
In speech recognition: generating the next word; In IR: generating a query from a document

What SLM can do?
Speech recognition Machine Translation Information Retrieval Handwriting recognition Spelling check OCR …

How can SLM do that?
Compare the probabilities of candidates of word sequences and pick one that “looks” most likely.
The actual question depends on specific field MT: Giving a bag of words, what is the best
permutation to get a sentence? Speech recognition: Giving the preceding words,
what is the next word? IR: Giving a document, what is the query?

Challenges in SLM
Long sequences Partial independence assumption
Sparseness Smoothing methods
Distributions Is there really one?

Evaluation of SLMs
Indirect evaluation Compare the outcomes of the application, be it
MT, SR, IR, or others. Issues: slow, depends on dataset, other
components, etc
Direct evaluation Perplexity Cross entropy

Evaluation of SLM: Perplexity
Definition: Perplexity is geometric average of inverse probability
Formula
(from Joshua Goodman)
Usually the lower the better, but … Limits:
LM must be normalized (sum to 1) The probability of any term must > 0.

Evaluation of SLM: Cross entropy
Entropy = log2 perplexity Example

The Poisson Model – Bookstein and Swanson
Intuition: content-bearing words clustered in relevant documents; non-content words occur randomly.
Methods: linear combination of Poisson distributions The two-poisson model, surprisingly, could account for
the occupancy distribution of most words.
2211
!)1(
!)( e
ke
kkf
kk

Poisson Mixtures – Church & Gale Enhancements for 2-Poisson: Poisson mixtures,
negative binomial... Problems: Parameter estimation and Overfit
From
Church&
Gale1995

Formulas (from Church&Gale)

SLM for IR – Ponte & Croft
Tell a story different from 2-Poisson Doesn’t rely on Bayer’s theorem Conceptually simple and parameter free, leave
room for further improvement
))|(ˆ0.1()|(ˆ)|(ˆ
Qt Qt
ddd MtpMtpMQp
cs
cf
RtpRdtpMtp t
dtavg
dtml
d
,),( ˆ)(
ˆ0.1),()|(ˆ

SLM for IR – Lafferty and Zhai
A framework that incorporates Bayesian theory, Markov chain, and language modeling by using the “loss function”
Feathers query expansion
}1,0{ ),|(),|(),|(
),,();(
RQ D QDDQiDQ
DQi
ddRpSdpuqp
RLqdR
m
i
qdi cqpm
qdR1
)ˆ|(log1
);(

SLM for IR – Liu and Croft
The Query likelihood model: To generate query from documentarg max P(D|Q) = arg max P(Q|D)P(D)
D D
P(D) assumed to be uniform. Many ways to model P(D|Q): multi-variant Bernoulli, multinomial, tf-idf, HMM, noisy channel, risk minimization function (K-L divergence) and all the smoothing methods.

SLM + Syntactic
Chelba and Jelinek Construct ngrams from syntactic analysis
e.g. The contract ended with a loss of 7 cents after trading as low as 89 cents.
(ended (with (…))) after ended_after headword: long distance information
when predicting using ngram Left-to-right increasmentally parsing
strategy: usable for speech recognition

Smoothing Strategies
No smoothing (Maximal Likelihood)
Interpolation
Jelinek-Mercer
Good-Turing
Absolute discounting

Smoothing Strategies – maximum likelihood
Formula: P(z|xy) = C(xyz)/C(xy) The name comes from that it does not
waste any probability mass on unseen events, maximizes the probability of observed events.
Cons: zero probabilities for unseen n-grams, which will propagate into P(D).

Smoothing Strategies – interpolation
Formula: P(z|xy) = w1*C(xyz)/C(xy) + w2*C(yz)/C(y) + (1-w1-w2)C(z)/C
combine unigram, bigram and trigram Search for w1, w2 – training set, pick
best Hints: allow enough training data for
each parameter Good in practice

Smoothing Strategies – Jelinek-Mercer
Formula: P(z|xy) = w1*C(xyz)/C(xy) + (1-w1) *C(yz)/C(y)
W1 usually trained using EM. Also known as “deleted-interpolation”

Example for Good-Turing smoothing (from Joshua Goodman)
Image you are fishing and you have caught 5 carp, 3 tuna, 1 trout, 1 bass.
How likely is it that your next fish is none of the four species? (2/10)
How likely is it that your next fish is tuna? (less than 3/10)

Smoothing Strategies – Good-Turing
Intuition: odds of all unseen events have a total “probability mass” of those occur once; odds for other events adjusted accordingly.
Formula:
nr: number of types that occurs r timesN: total tokens in corpus
p(w) = (r+1)/N *(nr+1/nr) note: maximum likelihood estimation for w is r/N.

Smoothing Strategies – Absolute discounting
Intuition: lower the probability mass of seen events by subtracting a constant D.
Formula: Pa(z|xy) = max{0, C(xyz)-D}/ C(xy) + w*Pa(z|y)
w = D*T/N, where N is the number of tokens and T is the number of types.
Rule of thumb: D = n1/(n1+2*n2)
Works well except for count=1 situations

The Study of Burstiness

Burstiness of Words
The definitions of word frequency Term frequency or TF: count of occurrences in a given
document Document frequency or DF: count of documents in a
corpus that a word occurs Generalized document frequency or DFj: like DF but a
word must occurs at least j times DF/N: Given a word, the chance we will see it in a
document (the p in Church2000). ∑TF/N: Given a word, the average count we will see
it in a document Given we have seen a word in one document,
what’s the chance that we will see it again?

Burstiness: the question
What are the chances of seeing one, two, and three “Noriegas” within a document?
Traditional assumptions Poisson mixture, 2-Poisson model Independence of word
The first occurrence depends on DF, but the second does not! The adaptive language model (used in SR) The degree of adaptation depends on lexical content –
independent of the frequency. “word rates vary from genre to genre, author to author, topic to topic, document to document, section to section, and paragraph to paragraph” -- Church&Gale

Count in the adaptations
Church’s formulas Cache model
Pr(w) = λPrlocal(w) + (1-λ)Prglobal(w) History-Test division; Positive and negative
adaptations Pr(+adapt) = Pr(w in test| w in history)Pr(-adapt) = Pr(w in test| w not in history)observation: Pr(+adapt) >> Pr(prior) > Pr(-adapt)
Generalized DFdfj = number of documents with j or more instances of w.
12 /)1|2Pr()2Pr( dfdfkkadapt

Experimental results – 1
High adaptation words (based on Pr(+adapt2)) a 14218 13306 and 14248 13196 ap 15694 14567 i 12178 11691 in 14533 13604 of 14648 13635 the 15183 14665 to 14099 13368----------------------------------------- agusta 18 17 akchurin 14 14 amex 20 20 apnewsalert 137 131 barghouti 11 11 berisha 18 17

Experimental results – 2
Low adaptation words asia 9560 489 brit 12632 18 ct 15694 7 eds 5631 11 english 15694 529 est 15694 72 euro 12660 261 lang 15694 24 ny 15694 370---------------------------------------------- accuses 177 3 angered 155 2 attract 109 2 carpenter 117 2 confirm 179 3 confirmation 114 2 considers 102 2
Low adaptation words much more than high adaptation ones

Experimental results – 3
Words with low frequency and high burstiess (many)
alianza, andorra, atl, awadallah, ayhan, bertelsmann, bhutto, bliss, boesak, bougainville, castel, chess, chiquita, cleopa, coolio, creatine, damas, demobilization
Words with high frequency and high burstiess (few)
a, and, as, at, by, for, from, has, he, his, in, iraq, is, it, of, on, reg, said, that, the, to, u, was, were, with

Experimental results – 4
Words with low frequency and low burstiess (lots)
accelerating, aga, aida, ales, annie, ashton, auspices, banditry, beg, beveridge, birgit, bombardments, bothered, br, breached, brisk, broadened, brunet, carrefour, catching, chant, combed, communicate, compel, concede, constituency, corpses, cushioned, defensively, deplore, desolate, dianne, dismisses
Words with high frequency and low burstiess (few)
adc, afri, ams, apw, asiangames, byline, edits, engl, filter, indi, mest, miscellaneous, ndld, nw, prompted, psov, rdld, recasts, stld, thld, ws, wstm

Detection of bursty words from a stream of documents
Idea: Find features that occur with high intensity over a limited period of time
Method: infinite-state automaton. Bursts appear as state transitions
-- Kleinberg, Bursty and Hierarchical Structure in Streams. Proc. 8th ACM SIGKDD, 2002

Detecting Bursty Words
Term w occurs in a sequence of text at positions u1, u2, … events happen with positive time-gap x1, x2, … where x1=u2-u1, x2 = u3 – u2, etc.
Assume the events are emited by a probabilistic infinite-state automaton, each state associated with a exponential density function f(x)=ae-ax, where a is the “rate” parameter (expected value of gap is a-1 )

Finding the state transitions
From J. Kleinberg, Bursty and Hierachical Structure in Streams. 8th ACM SIGKDD, 2002
Optimal sequence: less state transitions while keeping the rates closely agreeing with observed gaps.

Sample Results
From database conferences: SIGMOD, VLDB 1975-2001
data, base, application 1975- 1979/1981/1982relational 1975 – 1989schema 1975 – 1980distributed 1977 – 1985statistical 1981 – 1984transaction 1987 – 1992object-oriented 1987 – 1994parallel 1989 – 1996mining 1995 –web 1998 –xml 1999 -
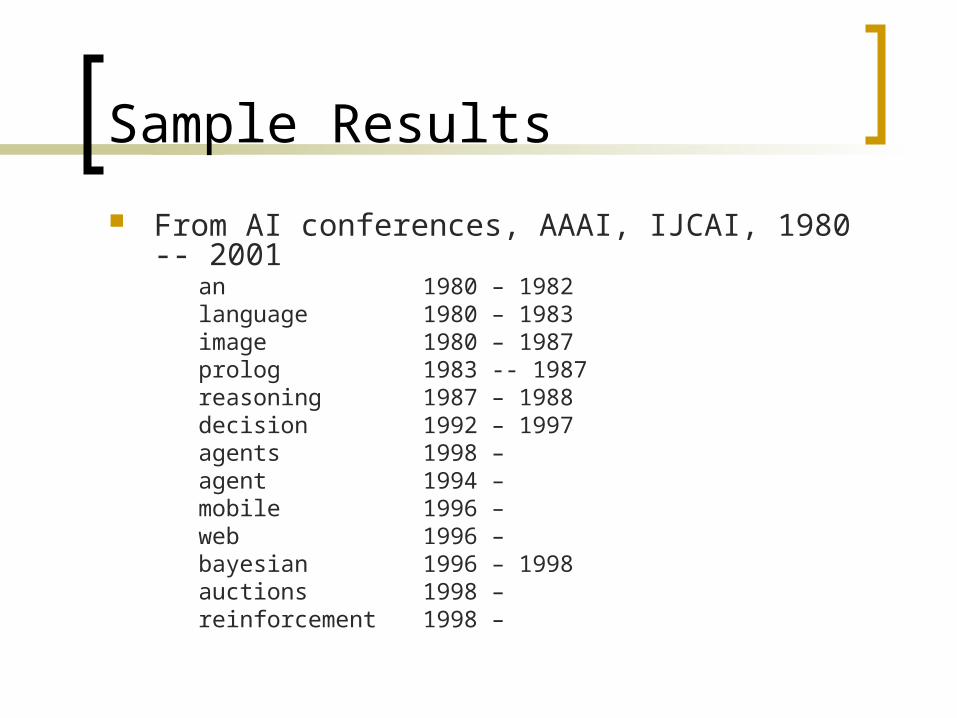
Sample Results
From AI conferences, AAAI, IJCAI, 1980 -- 2001an 1980 – 1982language 1980 – 1983image 1980 – 1987prolog 1983 -- 1987reasoning 1987 – 1988decision 1992 – 1997agents 1998 – agent 1994 – mobile 1996 – web 1996 –bayesian 1996 – 1998auctions 1998 – reinforcement 1998 –

THE END
Discussion?











![Introduction to Information Retrieval ` `%%%`# ` ~~~false [0.5cm] IIR 1: Boolean Retrieval · 2011-08-28 · 3 Probabilistic models (30) 4 Language model-based retrieval (30) 5 Latent](https://static.documents.pub/doc/80x56/5f07ee5d7e708231d41f7a26/introduction-to-information-retrieval-false-05cm-iir-1-boolean.jpg)





