1 January 6, 2007 IJCAI-2007 Tutorial 1 Language Independent Methods of Clustering Similar Contexts (with applications) Ted Pedersen University of Minnesota, Duluth [email protected]http://www.d.umn.edu/~tpederse/SCTutorial.html January 6, 2007 IJCAI-2007 Tutorial 2 Language Independent Methods • Do not utilize syntactic information – No parsers, part of speech taggers, etc. required • Do not utilize dictionaries or other manually created lexical resources • Based on lexical features selected from corpora – Assumption: word segmentation can be done by looking for white spaces between strings • No manually annotated data, methods are completely unsupervised in the strictest sense
Transcript
1
January 6, 2007 IJCAI-2007 Tutorial 1
Language Independent Methods of Clustering Similar Contexts
– Now PhD student at the Language Technologies Institute at Carnegie-Mellon University
– http://www.cs.cmu.edu/~anaghak/
• Ted, Amruta, and Anagha were supported by the National Science Foundation (USA) via CAREER award #0092784
5
January 6, 2007 IJCAI-2007 Tutorial 9
Background and Motivations
January 6, 2007 IJCAI-2007 Tutorial 10
Headed and Headless Contexts• A headed context includes a target word
– Our goal is to cluster the target word based on the surrounding contexts
– The focus is on the target word and making distinctions among word meanings
• A headless context has no target word– Our goal is to cluster the contexts based on
their similarity to each other– The focus is on the context as a whole and
making topic level distinctions
6
January 6, 2007 IJCAI-2007 Tutorial 11
Headed Contexts (input)
• I can hear the ocean in that shell.• My operating system shell is bash.• The shells on the shore are lovely.• The shell command line is flexible.• An oyster shell is very hard and black.
January 6, 2007 IJCAI-2007 Tutorial 12
Headed Contexts (output)
• Cluster 1: – My operating system shell is bash.– The shell command line is flexible.
• Cluster 2:– The shells on the shore are lovely.– An oyster shell is very hard and black.– I can hear the ocean in that shell.
7
January 6, 2007 IJCAI-2007 Tutorial 13
Headless Contexts (input)• The new version of Linux is more stable and
better support for cameras.• My Chevy Malibu has had some front end
troubles.• Osborne made one of the first personal
computers.• The brakes went out, and the car flew into the
house. • With the price of gasoline, I think I’ll be taking
the bus more often!
January 6, 2007 IJCAI-2007 Tutorial 14
Headless Contexts (output)
• Cluster 1:– The new version of Linux is more stable and better
support for cameras.– Osborne made one of the first personal computers.
• Cluster 2: – My Chevy Malibu has had some front-end troubles.– The brakes went out, and the car flew into the house. – With the price of gasoline, I think I’ll be taking the bus
more often!
8
January 6, 2007 IJCAI-2007 Tutorial 15
Web Search as Application
• Snippets returned via Web search are headed contexts since they include the search term– Name Ambiguity is a problem with Web search.
Results mix different entities– Group results into clusters where each cluster is
associated with a unique underlying entity • Pages found by following search results can also
be treated as headless contexts
January 6, 2007 IJCAI-2007 Tutorial 16
Name Discrimination
9
January 6, 2007 IJCAI-2007 Tutorial 17
George Millers!
January 6, 2007 IJCAI-2007 Tutorial 18
10
January 6, 2007 IJCAI-2007 Tutorial 19
January 6, 2007 IJCAI-2007 Tutorial 20
11
January 6, 2007 IJCAI-2007 Tutorial 21
January 6, 2007 IJCAI-2007 Tutorial 22
Email Foldering as Application
• Email (public or private) is made up of headless contexts– Short, usually focused…
• Cluster similar email messages together – Automatic email foldering– Take all messages from sent-mail file or inbox
and organize into categories
12
January 6, 2007 IJCAI-2007 Tutorial 23
Clustering News as Application
• News articles are headless contexts– Entire article or first paragraph– Short, usually focused
• Cluster similar articles together, can also be applied to blog entries and other shorter units of text
January 6, 2007 IJCAI-2007 Tutorial 24
What is it to be “similar”?• You shall know a word by the company it keeps
– Firth, 1957 (Studies in Linguistic Analysis)• Meanings of words are (largely) determined by their
distributional patterns (Distributional Hypothesis)– Harris, 1968 (Mathematical Structures of Language)
• Words that occur in similar contexts will have similar meanings (Strong Contextual Hypothesis)– Miller and Charles, 1991 (Language and Cognitive Processes)
• Various extensions…– Similar contexts will have similar meanings, etc.– Names that occur in similar contexts will refer to the same
underlying person, etc.
13
January 6, 2007 IJCAI-2007 Tutorial 25
General Methodology• Represent contexts to be clustered using first or
second order feature vectors– Lexical features
• Reduce dimensionality to make vectors more tractable and/or understandable (optional)– Singular value decomposition
• Cluster the context vectors– Find the number of clusters– Label the clusters
• Evaluate and/or use the contexts!
January 6, 2007 IJCAI-2007 Tutorial 26
Identifying Lexical Features
Measures of Association and Tests of Significance
14
January 6, 2007 IJCAI-2007 Tutorial 27
What are features?
• Features are the salient characteristics of the contexts to be clustered
• Each context is represented as a vector, where the dimensions are associated with features
• Contexts that include many of the same features will be similar to each other
January 6, 2007 IJCAI-2007 Tutorial 28
Feature Selection Data
• The contexts to cluster (evaluation/test data)– We may need to cluster all available data, and not
hold out any for a separate feature identification step• A separate larger corpus (training data), esp. if
we cluster a very small number of contexts– local training – corpus made up of headed contexts– global training – corpus made up of headless contexts
• Feature selection data may be either the evaluation/test data, or a separate held-out set of training data
15
January 6, 2007 IJCAI-2007 Tutorial 29
Feature Selection Data
• Test / Evaluation data : contexts to be clustered– Assume that the feature selection data is the test
data, unless otherwise indicated• Training data – a separate corpus of held out
feature selection data (that will not be clustered)– may need to use if you have a small number of
contexts to cluster (e.g., web search results)– This sense of “training” due to Schütze (1998)
• does not mean labeled• simply an extra quantity of text
January 6, 2007 IJCAI-2007 Tutorial 30
Lexical Features• Unigram
– a single word that occurs more than X times in feature selection data and is not in stop list
• Stop list– words that will not be used in features– usually non-content words like the, and, or, it …– may be compiled manually– may be derived automatically from a corpus of text
• any word that occurs in a relatively large percentage (>10-20%) of contexts may be considered a stop word
16
January 6, 2007 IJCAI-2007 Tutorial 31
Lexical Features• Bigram
– an ordered pair of words that may be consecutive, or have intervening words that are ignored
– the pair occurs together more than X times and/or more often than expected by chance in feature selection data
– neither word in the pair may be in stop list• Co-occurrence
– an unordered bigram• Target Co-occurrence
– a co-occurrence where one of the words is the target
January 6, 2007 IJCAI-2007 Tutorial 32
Bigrams• Window Size of 2
– baseball bat, fine wine, apple orchard, bill clinton• Window Size of 3
– house of representatives, bottle of wine, • Window Size of 4
– president of the republic, whispering in the wind• Selected using a small window size (2-4 words)• Objective is to capture a regular or localized
pattern between two words (collocation?)
17
January 6, 2007 IJCAI-2007 Tutorial 33
Co-occurrences
• president law– the president signed a bill into law today– that law is unjust, said the president– the president feels that the law was properly applied
• Usually selected using a larger window (7-10 words) of context, hoping to capture pairs of related words rather than collocations
January 6, 2007 IJCAI-2007 Tutorial 34
Bigrams and Co-occurrences• Pairs of words tend to be much less
ambiguous than unigrams– “bank” versus “river bank” and “bank card”– “dot” versus “dot com” and “dot product”
• Three grams and beyond occur much less frequently (Ngrams very Zipfian)
• Unigrams occur more frequently, but are noisy
18
January 6, 2007 IJCAI-2007 Tutorial 35
“occur together more often than expected by chance…”
• Observed frequencies for two words occurring together and alone are stored in a 2x2 matrix
• Expected values are calculated, based on the model of independence and observed values– How often would you expect these words to occur
together, if they only occurred together by chance?– If two words occur “significantly” more often than the
expected value, then the words do not occur together by chance.
January 6, 2007 IJCAI-2007 Tutorial 36
2x2 Contingency Table
100,000300
notArtificial
400100Artificial
notIntelligence
Intelligence
19
January 6, 2007 IJCAI-2007 Tutorial 37
2x2 Contingency Table
100,00099,700300
99,60099,400200notArtificial
400300100Artificial
notIntelligence
Intelligence
January 6, 2007 IJCAI-2007 Tutorial 38
2x2 Contingency Table
100,00099,700300
99,60099,400.099,301.2
200.0298.8
notArtificial
400300.0398.8
100.0000.12
Artificial
notIntelligence
Intelligence
20
January 6, 2007 IJCAI-2007 Tutorial 39
Measures of Association
∑
∑
=
=
−=
=
2
1,
22
2
1,
2
),()],(),([
)),(),(
log*),((
ji ji
jiji
ji
ji
jiji
wwexpectedwwexpectedwwobserved
X
wwexpectedwwobserved
wwobservedG
January 6, 2007 IJCAI-2007 Tutorial 40
Measures of Association
78.819188.750
2
2
=
=
XG
21
January 6, 2007 IJCAI-2007 Tutorial 41
Interpreting the Scores…
• G^2 and X^2 are asymptotically approximated by the chi-squared distribution…
• This means…if you fix the marginal totals of a table, randomly generate internal cell values in the table, calculate the G^2 or X^2 scores for each resulting table, and plot the distribution of the scores, you *should* get …
January 6, 2007 IJCAI-2007 Tutorial 42
22
January 6, 2007 IJCAI-2007 Tutorial 43
Interpreting the Scores…
• Values above a certain level of significance can be considered grounds for rejecting the null hypothesis – H0: the words in the bigram are independent– 3.84 is associated with 95% confidence that
the null hypothesis should be rejected
January 6, 2007 IJCAI-2007 Tutorial 44
Measures of Association
• There are numerous measures of association that can be used to identify bigram and co-occurrence features
• Many of these are supported in the Ngram Statistics Package (NSP)– http://www.d.umn.edu/~tpederse/nsp.html
• NSP is integrated into SenseClusters
23
January 6, 2007 IJCAI-2007 Tutorial 45
Measures Supported in NSP• Log-likelihood Ratio (ll)• True Mutual Information (tmi)• Pointwise Mutual Information (pmi)• Pearson’s Chi-squared Test (x2)• Phi coefficient (phi)• Fisher’s Exact Test (leftFisher)• T-test (tscore)• Dice Coefficient (dice)• Odds Ratio (odds)
January 6, 2007 IJCAI-2007 Tutorial 46
Summary• Identify lexical features based on frequency counts or
measures of association – either in the data to be clustered or in a separate set of feature selection data– Language independent
• Unigrams usually only selected by frequency– Remember, no labeled data from which to learn, so somewhat
less effective as features than in supervised case• Bigrams and co-occurrences can also be selected by
frequency, or better yet measures of association– Bigrams and co-occurrences need not be consecutive– Stop words should be eliminated– Frequency thresholds are helpful (e.g., unigram/bigram that
occurs once may be too rare to be useful)
24
January 6, 2007 IJCAI-2007 Tutorial 47
References• Moore, 2004 (EMNLP) follow-up to Dunning and Pedersen on log-
likelihood and exact testshttp://acl.ldc.upenn.edu/acl2004/emnlp/pdf/Moore.pdf
• Pedersen, Kayaalp, and Bruce. 1996 (AAAI) explanation of the exact conditional test, a stochastic simulation of exact tests. http://www.d.umn.edu/~tpederse/Pubs/aaai96-cmpl.pdf
• Pedersen, 1996 (SCSUG) explanation of exact tests for collocation identification, and comparison to log-likelihoodhttp://arxiv.org/abs/cmp-lg/9608010
• Dunning, 1993 (Computational Linguistics) introduces log-likelihood ratio for collocation identificationhttp://acl.ldc.upenn.edu/J/J93/J93-1003.pdf
January 6, 2007 IJCAI-2007 Tutorial 48
Context Representations
First and Second Order Methods
25
January 6, 2007 IJCAI-2007 Tutorial 49
Once features selected…
• We will have a set of unigrams, bigrams, co-occurrences or target co-occurrences that we believe are somehow interesting and useful– We also have any frequency and measure of
association score that have been used in their selection
• Convert contexts to be clustered into a vector representation based on these features
January 6, 2007 IJCAI-2007 Tutorial 50
Possible Representations
• First Order Features– Native SenseClusters
• each context represented by a vectors of features
• Second Order Co-Occurrence Features– Native SenseClusters
• each word in a context replaced by vector of co-occurring words and averaged together
– Latent Semantic Analysis• each feature in a context replaced by vector of
contexts in which it occurs and averaged together
26
January 6, 2007 IJCAI-2007 Tutorial 51
First Order RepresentationNative SenseClusters
• Context by Feature• Each context is represented by a vector
with M dimensions, each of which indicates if a particular feature occurred in that context– value may be binary or a frequency count– bag of words representation of documents is
first order, where each doc is represented by a vector showing words that occur therein
January 6, 2007 IJCAI-2007 Tutorial 52
Contexts• x1: there was an island curse of black
magic cast by that voodoo child • x2: harold a known voodoo child was
gifted in the arts of black magic• x3: despite their military might it was a
serious error to attack• x4: military might is no defense against a
voodoo child or an island curse
27
January 6, 2007 IJCAI-2007 Tutorial 53
Unigram Features
• island 1000• black 700• curse 500• magic 400• child 200
• (assume these are frequency counts obtained from feature selection data…)
January 6, 2007 IJCAI-2007 Tutorial 54
First Order Vectors of Unigrams
10101x400000x311010x211111x1
childmagiccurseblackisland
28
January 6, 2007 IJCAI-2007 Tutorial 55
Bigram Feature Set• island curse 189.2• black magic 123.5• voodoo child 120.0• military might 100.3• serious error 89.2• island child 73.2• voodoo might 69.4• military error 54.9• black child 43.2• serious curse 21.2
• (assume these are log-likelihood scores from feature selection data)
January 6, 2007 IJCAI-2007 Tutorial 56
First Order Vectors of Bigrams
10110x4
01100x3
10001x2
10011x1
voodoo child
serious error
military might
island curse
blackmagic
29
January 6, 2007 IJCAI-2007 Tutorial 57
First Order Vectors
• Values may be binary or frequency counts• Forms a context by feature matrix• May optionally be smoothed/reduced with
Singular Value Decomposition – More on that later…
• The contexts are ready for clustering…– More on that later…
January 6, 2007 IJCAI-2007 Tutorial 58
Second Order Features
• First order features directly encode the occurrence of a feature in a context– Native SenseClusters : each feature represented by a
binary value or frequency count in a vector• Second order features encode something ‘extra’
about a feature that occurs in a context, something not available in the context itself– Native SenseClusters : each feature is represented by a
vector of the words with which it occurs – Latent Semantic Analysis : each feature is represented
by a vector of the contexts in which it occurs
30
January 6, 2007 IJCAI-2007 Tutorial 59
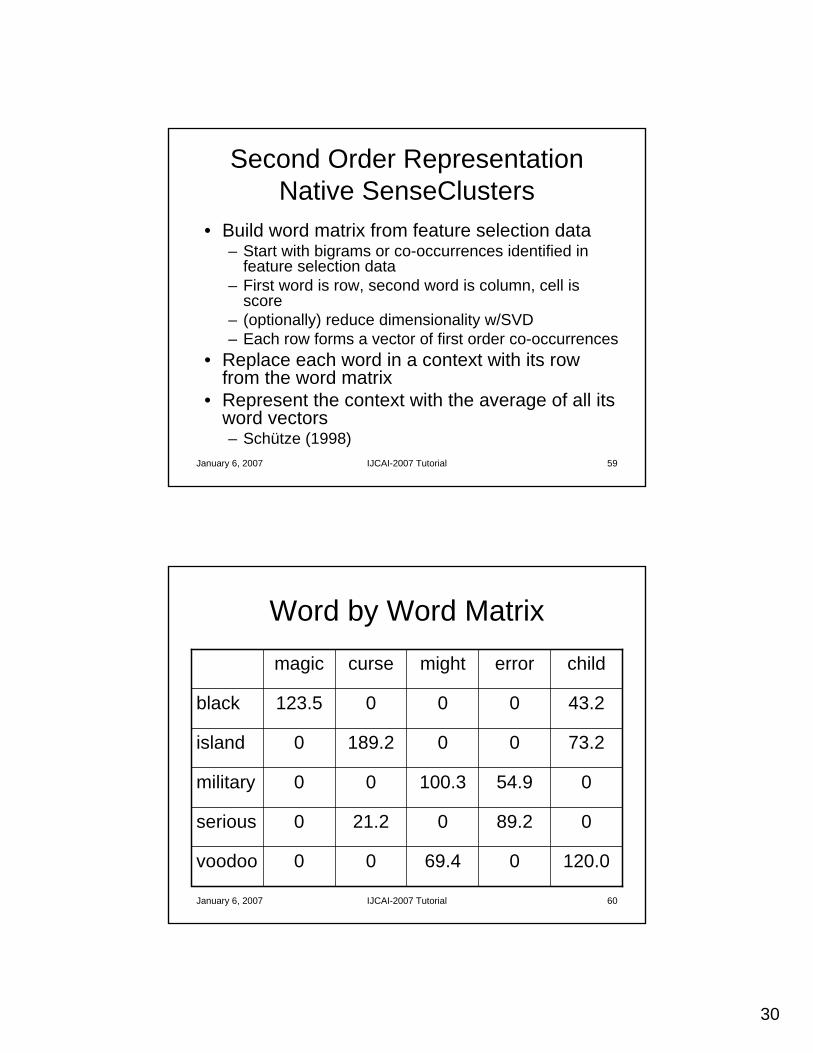
Second Order RepresentationNative SenseClusters
• Build word matrix from feature selection data– Start with bigrams or co-occurrences identified in
feature selection data– First word is row, second word is column, cell is
score– (optionally) reduce dimensionality w/SVD– Each row forms a vector of first order co-occurrences
• Replace each word in a context with its row from the word matrix
• Represent the context with the average of all its word vectors– Schütze (1998)
January 6, 2007 IJCAI-2007 Tutorial 60
Word by Word Matrix
120.0069.400voodoo
089.2021.20serious
054.9100.300military
73.200189.20island
43.2000123.5black
childerrormightcursemagic
31
January 6, 2007 IJCAI-2007 Tutorial 61
Word by Word Matrix• …can also be used to identify sets of related words• In the case of bigrams, rows represent the first word in a
bigram and columns represent the second word– Matrix is asymmetric
• In the case of co-occurrences, rows and columns are equivalent– Matrix is symmetric
• The vector (row) for each word represent a set of first order features for that word
• Each word in a context to be clustered for which a vector exists (in the word by word matrix) is replaced by that vector in that context
January 6, 2007 IJCAI-2007 Tutorial 62
There was an island curse of blackmagic cast by that voodoo child.
120.0069.400voodoo
73.200189.20island
43.2000123.5black
childerrormightcursemagic
32
January 6, 2007 IJCAI-2007 Tutorial 63
Second Order Co-Occurrences
• Word vectors for “black” and “island” show similarity as both occur with “child”
• “black” and “island” are second order co-occurrence with each other, since both occur with “child” but not with each other (i.e., “black island” is not observed)
January 6, 2007 IJCAI-2007 Tutorial 64
Second Order Representation
• x1: there was an island curse of black magic cast by that voodoo child
• x1: there was an [curse,child] curse of [magic, child] magic cast by that [might,child] child
There was an island curse of blackmagic cast by that voodoo child.
78.8024.463.141.2x1
childerrormightcursemagic
January 6, 2007 IJCAI-2007 Tutorial 66
Second Order RepresentationNative SenseClusters
• Context by Feature/Word• Cell values do not indicate if feature
occurred in context. Rather, they show the strength of association of that feature with other words that occur with a word in the context.
34
January 6, 2007 IJCAI-2007 Tutorial 67
Second Order RepresentationLatent Semantic Analysis
• Build first order representation of context– Use any type of features selected from feature
selection data– result is a context by feature matrix
• Transpose the resulting first order matrix– result is a feature by context matrix– (optionally) reduce dimensionality w/SVD– Replace each feature in a context with its row from
the transposed matrix• Represent the context with the average of all its
context vectors– Landauer and Dumais (1997)
January 6, 2007 IJCAI-2007 Tutorial 68
First Order Vectors of Unigrams
10101x400000x311010x211111x1
childmagiccurseblackisland
35
January 6, 2007 IJCAI-2007 Tutorial 69
Transposed
1011child
0011magic
1001curse
0011black
1001island
x4x3x2x1
January 6, 2007 IJCAI-2007 Tutorial 70
harold a known voodoo child was gifted in the arts of black magic
1011child
0011magic
00 11black
x4x3x2x1
36
January 6, 2007 IJCAI-2007 Tutorial 71
Second Order Representation
• x2: harold a known voodoo child was gifted in the arts of black magic
• x2: harold a known voodoo [x1,x2,x4] was gifted in the arts of [x1,x2] [x1,x2]
• x2: [x1,x2,x4] + [x1,x2] + [x1,x2]
January 6, 2007 IJCAI-2007 Tutorial 72
x2: harold a known voodoo child was gifted in the arts of black magic
.3011x2
x4x3x2x1
37
January 6, 2007 IJCAI-2007 Tutorial 73
Second Order RepresentationLatent Semantic Analysis
• Context by Context• The features in the context are
represented by the contexts in which those features occur
• Cell values indicate the similarity between the contexts
January 6, 2007 IJCAI-2007 Tutorial 74
Summary• First order representations are intuitive, but…
– Can suffer from sparsity– Contexts represented based on the features that
occur in those contexts• Second order representations are harder to
visualize, but…– Allow a word to be represented by the words it co-
occurs with (i.e., the company it keeps)– Allows a context to be represented by the words that
occur with the words in the context – Allow a feature to be represented by the contexts in
which it occurs– Allows a context to be represented by the contexts
where the words in the context occur– Helps combat sparsity…
38
January 6, 2007 IJCAI-2007 Tutorial 75
References• Pedersen and Bruce 1997 (EMNLP) first order method of discrimination
http://acl.ldc.upenn.edu/W/W97/W97-0322.pdf
• Landauer and Dumais 1997 (Psychological Review) overview of LSA.http://lsa.colorado.edu/papers/plato/plato.annote.html
• Schütze 1998 (Computational Linguistics) introduced second order method http://acl.ldc.upenn.edu/J/J98/J98-1004.pdf
• Purandare and Pedersen 2004 (CoNLL) compared first and second order methodshttp://acl.ldc.upenn.edu/hlt-naacl2004/conll04/pdf/purandare.pdf
– First order better if you have lots of data– Second order better with smaller amounts of data
January 6, 2007 IJCAI-2007 Tutorial 76
Dimensionality Reduction
Singular Value Decomposition
39
January 6, 2007 IJCAI-2007 Tutorial 77
Motivation
• First order matrices are very sparse– Context by feature– Word by word
• NLP data is noisy– No stemming performed– synonyms
January 6, 2007 IJCAI-2007 Tutorial 78
Many Methods
• Singular Value Decomposition (SVD)– SVDPACKC http://www.netlib.org/svdpack/
• Multi-Dimensional Scaling (MDS)• Principal Components Analysis (PCA)• Independent Components Analysis (ICA)• Linear Discriminant Analysis (LDA)• etc…
40
January 6, 2007 IJCAI-2007 Tutorial 79
Effect of SVD
• SVD reduces a matrix to a given number of dimensions This may convert a word level space into a semantic or conceptual space– If “dog” and “collie” and “wolf” are
dimensions/columns in a word co-occurrence matrix, after SVD they may be a single dimension that represents “canines”
January 6, 2007 IJCAI-2007 Tutorial 80
Effect of SVD
• The dimensions of the matrix after SVD are principal components that represent the meaning of concepts– Similar columns are grouped together
• SVD is a way of smoothing a very sparse matrix, so that there are very few zero valued cells after SVD
41
January 6, 2007 IJCAI-2007 Tutorial 81
How can SVD be used?
• SVD on first order contexts will reduce a context by feature representation down to a smaller number of features– Latent Semantic Analysis performs SVD on a
feature by context representation, where the contexts are reduced
• SVD used in creating second order context representations for native SenseClusters– Reduce word by word matrix
• These two contexts share no words in common, yet they are similar! disk and linux both occur with “Apple”, “IBM”, “data”, “graphics”, and “memory”
• The two contexts are similar because they share many second order co-occurrences
1.0.72
memory
.00
.00
organ
.131.1.032.71.7.16.00.96linux
.00.91.002.11.3.01.00.76disk
Plasmagraphicstissuedataibmcellsbloodapple
• I got a new disk today!• What do you think of linux?
45
January 6, 2007 IJCAI-2007 Tutorial 89
References• Deerwester, S. and Dumais, S.T. and Furnas, G.W. and
Landauer, T.K. and Harshman, R., Indexing by Latent Semantic Analysis, Journal of the American Society for Information Science, vol. 41, 1990
• Landauer, T. and Dumais, S., A Solution to Plato's Problem: The Latent Semantic Analysis Theory of Acquisition, Induction and Representation of Knowledge, Psychological Review, vol. 104, 1997
• Schütze, H, Automatic Word Sense Discrimination, Computational Linguistics, vol. 24, 1998
• Berry, M.W. and Drmac, Z. and Jessup, E.R.,Matrices, Vector Spaces, and Information Retrieval, SIAM Review, vol 41, 1999
Many many methods…• Cluto supports a wide range of different
clustering methods– Agglomerative
• Average, single, complete link…– Partitional
• K-means (Direct)– Hybrid
• Repeated bisections
• SenseClusters integrates with Cluto– http://www-users.cs.umn.edu/~karypis/cluto/
January 6, 2007 IJCAI-2007 Tutorial 92
General Methodology
• Represent contexts to be clustered in first or second order vectors
• Cluster the context vectors directly– vcluster
• … or convert to similarity matrix and then cluster– scluster
47
January 6, 2007 IJCAI-2007 Tutorial 93
Agglomerative Clustering
• Create a similarity matrix of contexts to be clustered– Results in a symmetric “instance by instance”
matrix, where each cell contains the similarity score between a pair of instances
– Typically a first order representation, where similarity is based on the features observed in the pair of instances
)()(
YXYX
∪∩
January 6, 2007 IJCAI-2007 Tutorial 94
Measuring Similarity• Integer Values
– Matching Coefficient
– Jaccard Coefficient
– Dice Coefficient
• Real Values
– Cosine
YX ∩
YXYX
∪∩
YXYX
+∩×2
YX
YXrr
⋅
48
January 6, 2007 IJCAI-2007 Tutorial 95
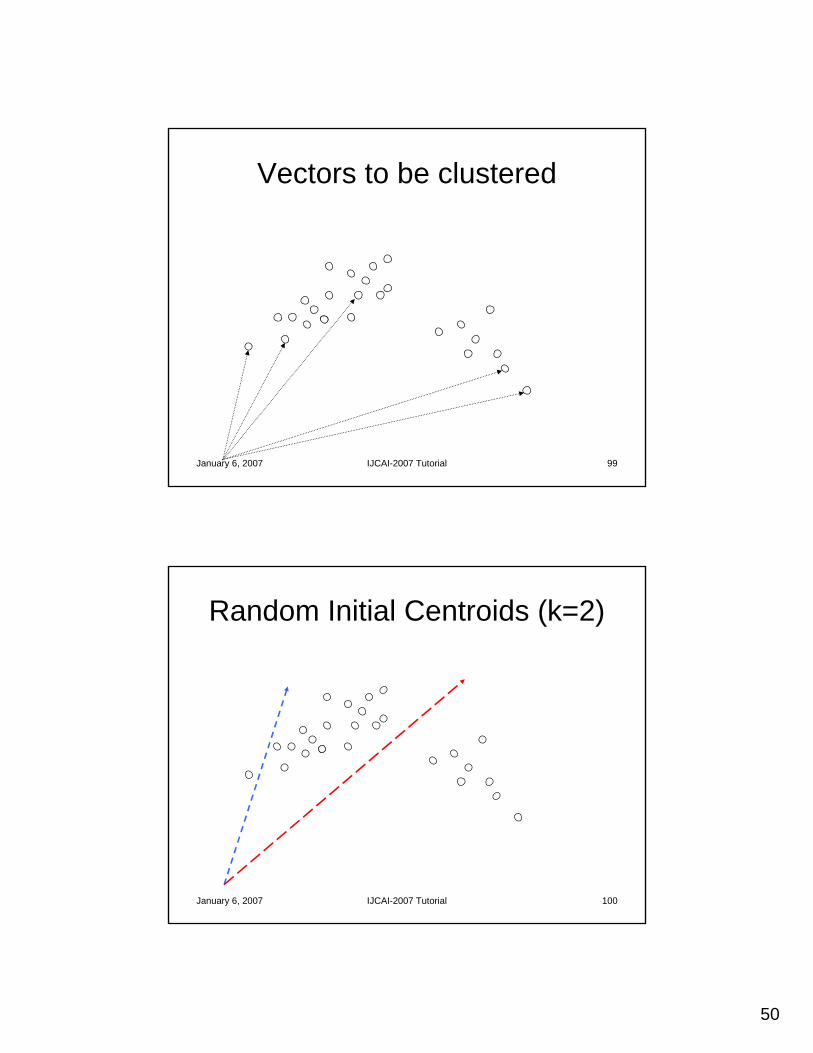
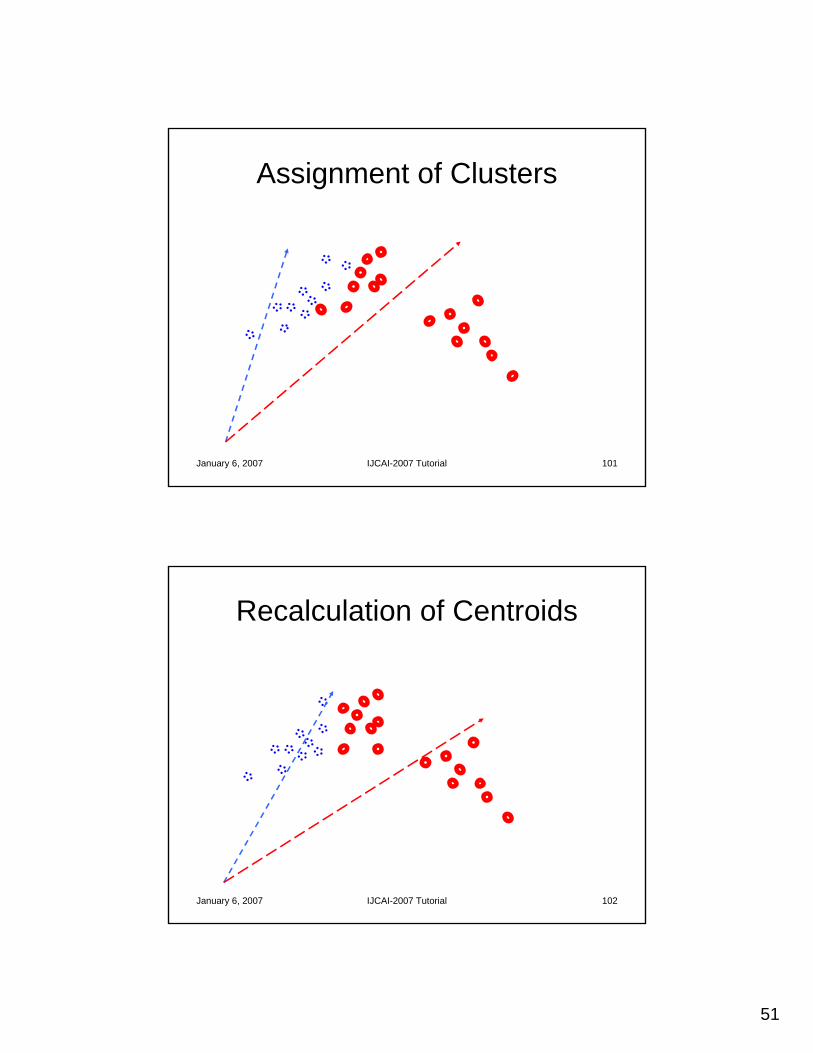
Agglomerative Clustering
• Apply Agglomerative Clustering algorithm to similarity matrix– To start, each context is its own cluster– Form a cluster from the most similar pair of contexts– Repeat until the desired number of clusters is
• Want internal similarity to increase, while external similarity decreases
• Want internal distances to decrease, while external distances increase
January 6, 2007 IJCAI-2007 Tutorial 114
Cluster Stopping
58
January 6, 2007 IJCAI-2007 Tutorial 115
Cluster Stopping
• Many Clustering Algorithms require that the user specify the number of clusters prior to clustering
• But, the user often doesn’t know the number of clusters, and in fact finding that out might be the goal of clustering
January 6, 2007 IJCAI-2007 Tutorial 116
Criterion Functions Can Help
• Run partitional algorithm for k=1 to deltaK– DeltaK is a user estimated or automatically
determined upper bound for the number of clusters• Find the value of k at which the criterion function
does not significantly increase at k+1• Clustering can stop at this value, since no further
improvement in solution is apparent with additional clusters (increases in k)
59
January 6, 2007 IJCAI-2007 Tutorial 117
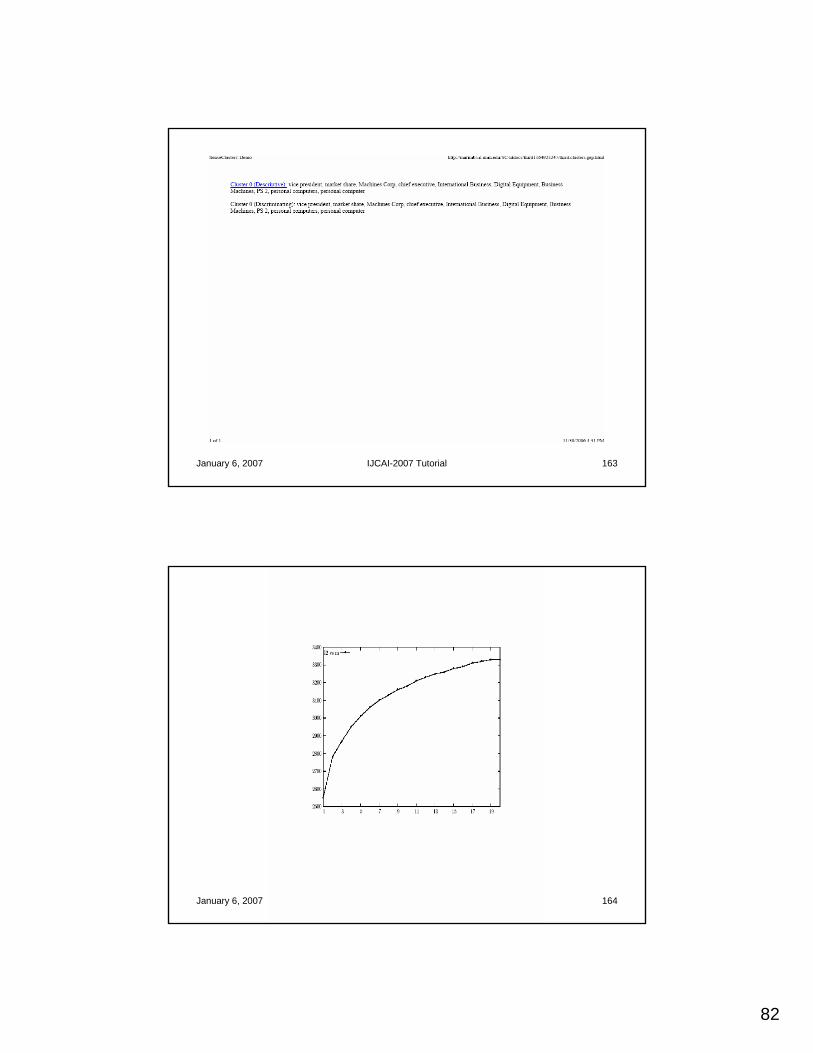
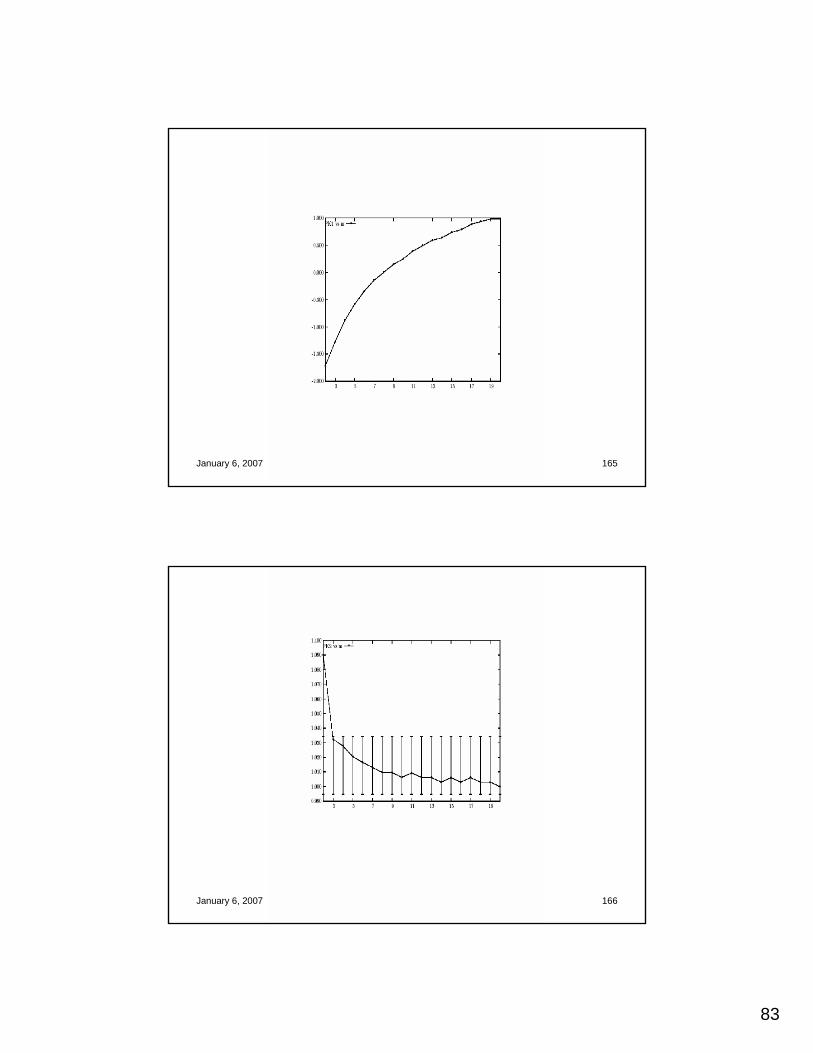
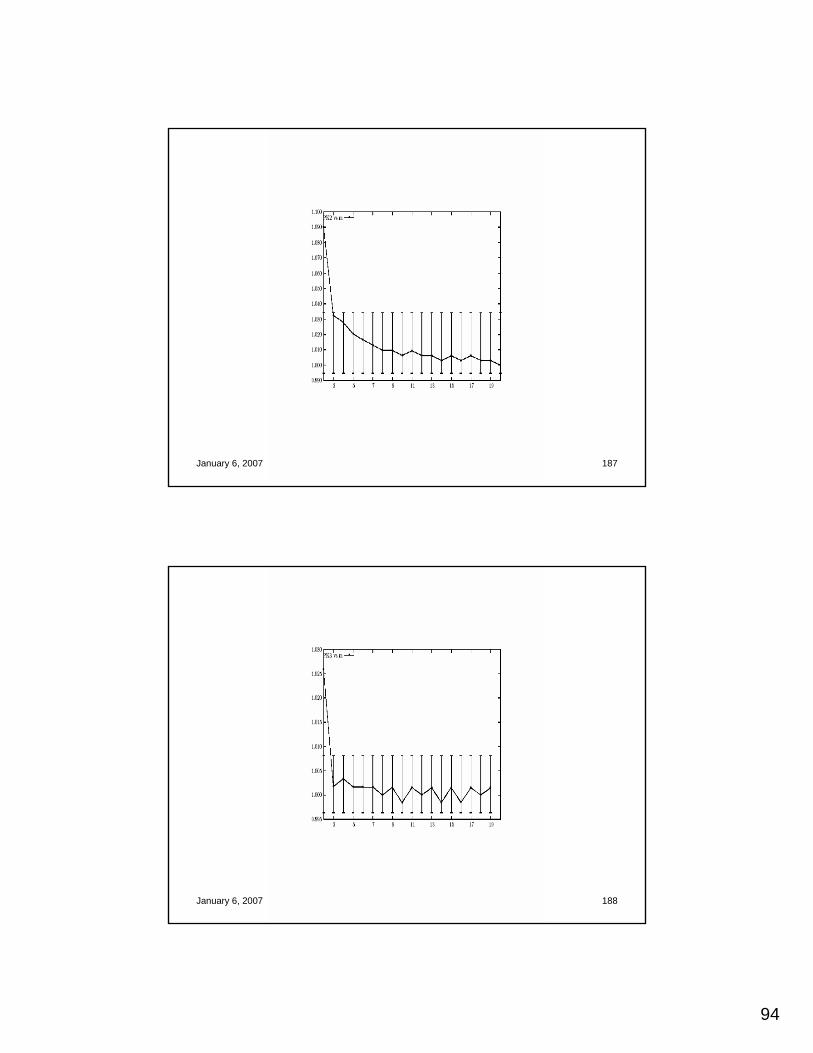
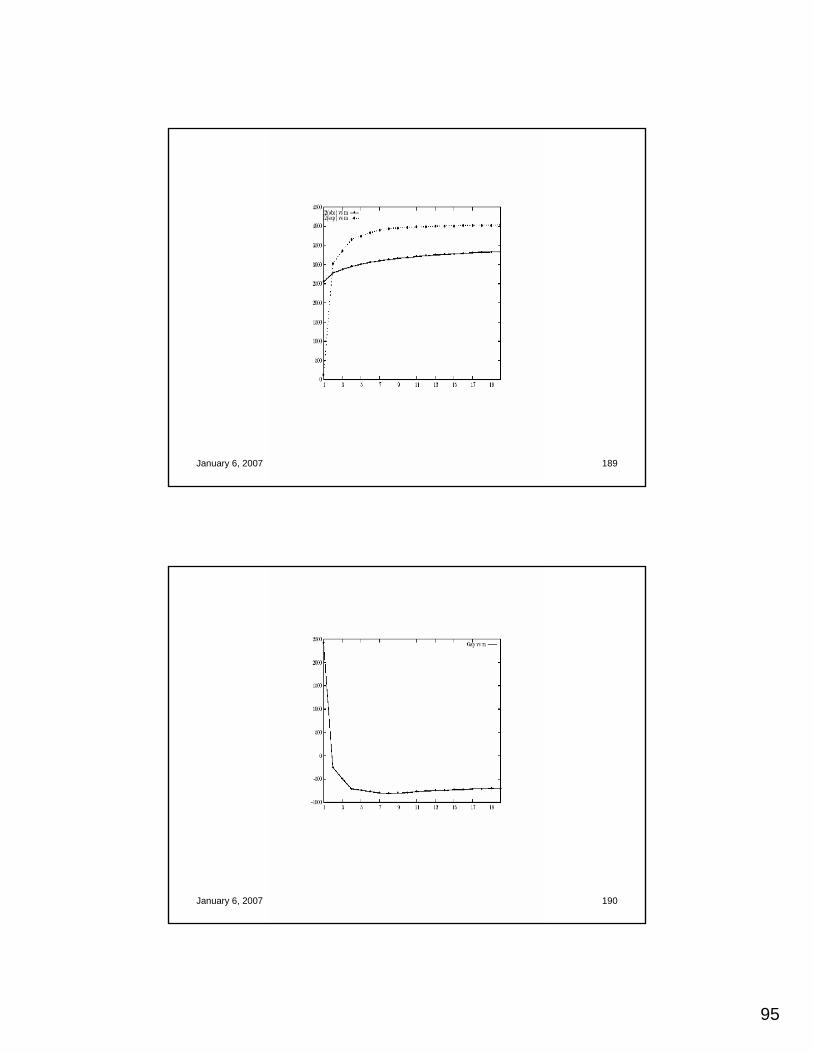
H2 versus kT. Blair – V. Putin – S. Hussein
January 6, 2007 IJCAI-2007 Tutorial 118
PK2• Based on Hartigan, 1975• When ratio approaches 1, clustering is at a plateau• Select value of k which is closest to but outside of
standard deviation interval
)1(2)(2)(2−
=kHkHkPK
60
January 6, 2007 IJCAI-2007 Tutorial 119
PK2 predicts 3 sensesT. Blair – V. Putin – S. Hussein
January 6, 2007 IJCAI-2007 Tutorial 120
PK3• Related to Salvador and Chan, 2004• Inspired by Dice Coefficient• Values close to 1 mean clustering is improving …• Select value of k which is closest to but outside of
standard deviation interval
)1(2)1(2)(2*2)(3
++−=
kHkHkHkPK
61
January 6, 2007 IJCAI-2007 Tutorial 121
PK3 predicts 3 sensesT. Blair – V. Putin – S. Hussein
January 6, 2007 IJCAI-2007 Tutorial 122
Adapted Gap Statistic• Gap Statistic by Tibshirani et al. (2001)• Cluster stopping by comparing observed data to
randomly generated data – Fix marginal totals of observed data, generate
random matrices– Random matrices should have 1 cluster, since there
is no structure to the data– Compare criterion function of observed data to
random data– The point where the difference between criterion
function is greatest is the point where the observed data is least like noise (and is where we should stop)
62
January 6, 2007 IJCAI-2007 Tutorial 123
Adapted Gap Statistic
January 6, 2007 IJCAI-2007 Tutorial 124
Gap predicts 3 sensesT. Blair – V. Putin – S. Hussein
63
January 6, 2007 IJCAI-2007 Tutorial 125
References• Hartigan, J. Clustering Algorithms, Wiley, 1975
– basis for SenseClusters stopping method PK2• Mojena, R., Hierarchical Grouping Methods and Stopping Rules: An
Evaluation, The Computer Journal, vol 20, 1977 – basis for SenseClusters stopping method PK1
• Milligan, G. and Cooper, M., An Examination of Procedures for Determining the Number of Clusters in a Data Set, Psychometrika,vol. 50, 1985– Very extensive comparison of cluster stopping methods
• Tibshirani, R. and Walther, G. and Hastie, T., Estimating the Number of Clusters in a Dataset via the Gap Statistic,Journal of the Royal Statistics Society (Series B), 2001
• Pedersen, T. and Kulkarni, A. Selecting the "Right" Number of Senses Based on Clustering Criterion Functions, Proceedings of the Posters and Demo Program of the Eleventh Conference of the European Chapter of the Association for Computational Linguistics, 2006– Describes SenseClusters stopping methods
January 6, 2007 IJCAI-2007 Tutorial 126
Cluster Labeling
64
January 6, 2007 IJCAI-2007 Tutorial 127
Cluster Labeling
• Once a cluster is discovered, how can you generate a description of the contexts of that cluster automatically?
• In the case of contexts, you might be able to identify significant lexical features from the contents of the clusters, and use those as a preliminary label
January 6, 2007 IJCAI-2007 Tutorial 128
Results of Clustering
• Each cluster consists of some number of contexts
• Each context is a short unit of text• Apply measures of association to the
contents of each cluster to determine N most significant bigrams
• Use those bigrams as a label for the cluster
65
January 6, 2007 IJCAI-2007 Tutorial 129
Label Types
• The N most significant bigrams for each cluster will act as a descriptive label
• The M most significant bigrams that are unique to each cluster will act as a discriminating label
• Cluster 1 : george miller, happy feet, pig in, lorenzos oil, 1998 babe, byron kennedy, babe pig, mad max
• Cluster 2 : george a, october 26, a miller, essays in, mind essays, human mind
66
January 6, 2007 IJCAI-2007 Tutorial 131
Evaluation Techniques
Comparison to gold standard data
January 6, 2007 IJCAI-2007 Tutorial 132
Evaluation
• If Sense tagged text is available, can be used for evaluation– But don’t use sense tags for clustering or
feature selection!• Assume that sense tags represent “true”
clusters, and compare these to discovered clusters– Find mapping of clusters to senses that
attains maximum accuracy
67
January 6, 2007 IJCAI-2007 Tutorial 133
Evaluation• Pseudo words are especially useful, since
it is hard to find data that is discriminated– Pick two words or names from a corpus, and
conflate them into one name. Then see how well you can discriminate.
– http://www.d.umn.edu/~tpederse/tools.html• Baseline Algorithm– group all instances
into one cluster, this will reach “accuracy”equal to majority classifier
January 6, 2007 IJCAI-2007 Tutorial 134
Evaluation
• Pseudo words are especially useful, since it is hard to find data that is discriminated– Pick two or more words or names from a
corpus, and conflate them into one name. Then see how well you can discriminate.
– http://www.d.umn.edu/~tpederse/tools.html
68
January 6, 2007 IJCAI-2007 Tutorial 135
Baseline Algorithm
• Baseline Algorithm – group all instances into one cluster, this will reach “accuracy”equal to majority classifier
• What if the clustering said everything should be in the same cluster?
January 6, 2007 IJCAI-2007 Tutorial 136
Baseline Performance
170553580Totals
170553580C3
0000C2
0000C1
TotalsS3S2S1
170803555Totals170803555C30000C2
0000C1TotalsS1S2S3
(0+0+55)/170 = .32 if C3 is S1 (0+0+80)/170 = .47 if C3 is S3
69
January 6, 2007 IJCAI-2007 Tutorial 137
Evaluation• Suppose that C1 is labeled S1, C2 as S2, and C3 as S3• Accuracy = (10 + 0 + 10) / 170 = 12% • Diagonal shows how many members of the cluster actually
belong to the sense given on the column • Can the “columns” be rearranged to improve the overall
accuracy?– Optimally assign clusters to senses
170553580Totals6510550C3
6040020C24553010C1
TotalsS3S2S1
January 6, 2007 IJCAI-2007 Tutorial 138
Evaluation• The assignment of C1 to
S2, C2 to S3, and C3 to S1 results in 120/170 = 71%
• Find the ordering of the columns in the matrix that maximizes the sum of the diagonal.
• This is an instance of the Assignment Problem from Operations Research, or finding the Maximal Matching of a Bipartite Graph from Graph Theory.
170805535Totals6550105C3
6020400C24510530C1
TotalsS1S3S2
70
January 6, 2007 IJCAI-2007 Tutorial 139
Analysis
• Unsupervised methods may not discover clusters equivalent to the classes learned in supervised learning
• Evaluation based on assuming that sense tags represent the “true” cluster are likely a bit harsh. Alternatives?– Humans could look at the members of each cluster and
determine the nature of the relationship or meaning that they all share
– Use the contents of the cluster to generate a descriptive label that could be inspected by a human



























































































![Statistical Clustering Applied to Adaptive Matched Field ... · Statistical clustering methods [3] enable identication of re-gions of similar response on the ambiguity surface. Cluster-ing](https://static.documents.pub/doc/80x56/5f9e5cefa8eecc591c72357b/statistical-clustering-applied-to-adaptive-matched-field-statistical-clustering.jpg)















