62
Martin Zapletal @zapletal_martin Cake Solutions @cakesolutions
| Date post: | 28-Jul-2015 |
| Category: |
Software |
| Upload: | martin-zapletal |
| View: | 999 times |
| Download: | 5 times |

Martin Zapletal @zapletal_martinCake Solutions @cakesolutions

● Increasing importance of data analytics● Current state
○ Destructive updates○ Analytics tools with poor scalability and integration○ Manual processes○ Slow iterations○ Not suitable for large amounts of data

● Shared memory, disk, shared nothing, threads, mutexes, transactional memory, message passing, CSP, actors, futures, coroutines, evented, dataflow, ...
We can think of two reasons for using distributed machine learning: because you have to (so much data), or because you want to (hoping it will be faster). Only the first reason is good.
Zygmunt Z
Elapsed times for 20 PageRank iterations
[1, 2]

● Microsoft's data centers average failure rate is 5.2 devices per day and 40.8 links per day,
with a median time to repair of approximately five minutes (and a maximum of one week).
● Google new cluster over one year. Five times rack issues 40-80 machines seeing 50 percent
packet loss. Eight network maintenance events (four of which might cause ~30-minute
random connectivity losses). Three router failures (resulting in the need to pull traffic
immediately for an hour).
● CENIC 500 isolating network partitions with median 2.7 and 32 minutes; 95th percentile of
19.9 minutes and 3.7 days, respectively for software and hardware problems [3]

● MongoDB separated primary from its 2 secondaries. 2 hours later the old primary rejoined and rolled back everything on the new primary
● A network partition isolated the Redis primary from all secondaries. Every API call caused the billing system to recharge customer credit cards automatically, resulting in 1.1 percent of customers being overbilled over a period of 40 minutes.
● The partition caused inconsistency in the MySQL database. Because foreign key relationships were not consistent, Github showed private repositories to the wrong users' dashboards and incorrectly routed some newly created repositories.
● For several seconds, Elasticsearch is happy to believe two nodes in the same cluster are both primaries, will
accept writes on both of those nodes, and later discard the writes to one side.● RabbitMQ lost ~35% of acknowledged writes under those conditions.● Redis threw away 56% of the writes it told us succeeded.● In Riak, last-write-wins resulted in dropping 30-70% of writes, even with the strongest consistency
settings● MongoDB “strictly consistent” reads see stale versions of documents, but they can also return garbage
data from writes that never should have occurred. [4]
● Complementary● Distributed data processing framework Apache Spark won Daytona
Gray Sort 100TB Benchmark● Distributed databases

● Whole lifecycle of data
● Data processing - Futures, Akka, Akka Cluster, Reactive Streams, Spark, …
● Data stores● Integration● Distributed computing primitives● Cluster managers and task schedulers● Deployment, configuration management and DevOps● Data analytics and machine learning

ACID Mutable State

CQRS
Kappa architecture
Batch-Pipeline
Kafka
All
you
r d
ata
NoSQL
SQL
Spark
Client
Client
Client Views
Stream processor
Client
QueryCommand
DBDB
Denormalise/Precompute
Flume
ScoopHive
Impala
Serving DB
Oozie
HDFS
Lambda Architecture
Batch Layer Serving Layer
Stream layer (fast)
Query
QueryAll
you
r d
ata
[5]

[6]


● Basic building block of neural networks
a = f(Σ(y * w) + b)

● Multi Layer Perceptron (Feed Forward Neural Network)
● Network training○ Many “optimal” solutions○ Optimization and training techniques - LBFGS, Backpropagation,
batch and online gradient descent, Downpour SGD, Sandblaster LBFGS
○ New methods for large networks - deep learning
● We will only need forward propagation

-10.895
1.195
1
0
0.999595
-24.584
-1.159
7.360
-40.119
1.991
35.369
-24.687-53.197
-8.627
-57.122
2.616
61.488
-52.985
-22.904
-67.173
22.172-53.706
27.098-0.375
Output 2.613296075440797E-4 for input Vector(0, 0)Output 0.9989222606269823 for input Vector(0, 1)Output 0.9995952194411893 for input Vector(1, 0)Output 4.0074182099155245E-7 for input Vector(1, 1)

trait HasInput { var input: Node = _ def addInput(i: Node): Unit = input = i}
trait HasOutput { var output: Node = _ def addOutput(o: Node): Unit = output = o}
class Edge extends HasInput with HasOutput { var weight: Double = 0.3 def run(in: Input) = output.run(WeightedInput(in.feature, weight))}

class Perceptron extends Neuron { override var activationFunction: Double => Double = Neuron.sigmoid override var bias: Double = 0.2
var inputs: Seq[Edge] = Seq() var outputs: Seq[Edge] = Seq()
var weightsT: Seq[Double] = Vector() var featuresT: Seq[Double] = Vector()
private def allInputsAvailable(w: Seq[Double], f: Seq[Double], in: Seq[Edge]) = w.length == in.length && f.length == in.length
override def run(in: WeightedInput): Unit = { featuresT = featuresT :+ in.feature weightsT = weightsT :+ in.weight
if(allInputsAvailable(weightsT, featuresT, inputs)) { val activation = activationFunction(weightsT.zip(featuresT).map(x => x._1 * x._2).sum + bias)
featuresT = Vector() weightsT = Vector()
outputs.foreach(_.run(Input(activation))) } }}

val hiddenLayer1 = new Perceptron()val edgei1h1 = new Edge()edgei1h1.addInput(inputLayer1)edgei1h1.addOutput(hiddenLayer1)hiddenLayer1.addInputs(Seq(edgei1h1, edgei2h1, edgei3h1))hiddenLayer1.addOutputs(Seq(edgeh1o1))
Source.fromFile("src/main/resources/data2.csv") .getLines() .foreach{ l => val splits = l.split(",")
inputLayer1.run( WeightedInput(splits(0).toDouble, 1))
inputLayer2.run( WeightedInput(splits(1).toDouble, 1)) inputLayer3.run( WeightedInput(splits(2).toDouble, 1)) }
00.00010.0002
0.00010.0002 0
0.00010.0002 0
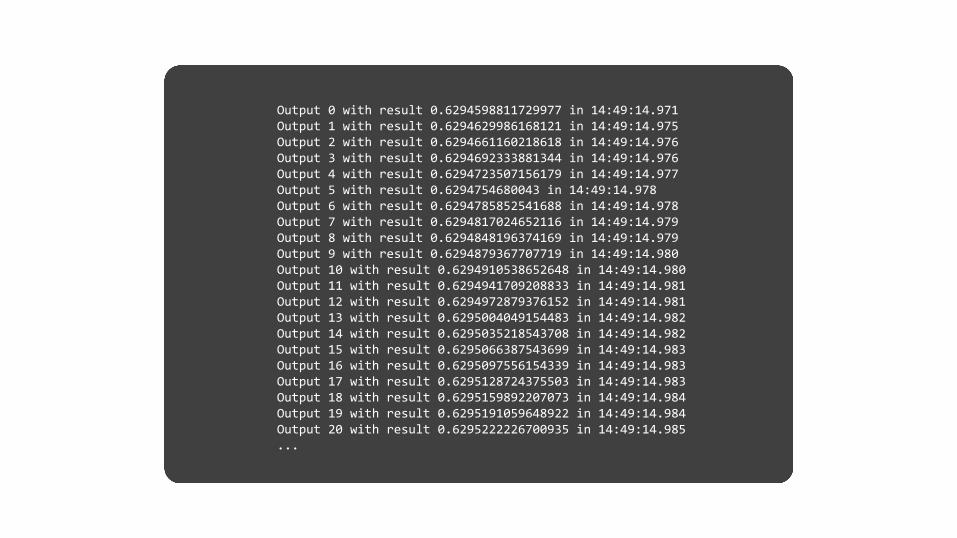
Output 0 with result 0.6294598811729977 in 14:49:14.971Output 1 with result 0.6294629986168121 in 14:49:14.975Output 2 with result 0.6294661160218618 in 14:49:14.976Output 3 with result 0.6294692333881344 in 14:49:14.976Output 4 with result 0.6294723507156179 in 14:49:14.977Output 5 with result 0.6294754680043 in 14:49:14.978Output 6 with result 0.6294785852541688 in 14:49:14.978Output 7 with result 0.6294817024652116 in 14:49:14.979Output 8 with result 0.6294848196374169 in 14:49:14.979Output 9 with result 0.6294879367707719 in 14:49:14.980Output 10 with result 0.6294910538652648 in 14:49:14.980Output 11 with result 0.6294941709208833 in 14:49:14.981Output 12 with result 0.6294972879376152 in 14:49:14.981Output 13 with result 0.6295004049154483 in 14:49:14.982Output 14 with result 0.6295035218543708 in 14:49:14.982Output 15 with result 0.6295066387543699 in 14:49:14.983Output 16 with result 0.6295097556154339 in 14:49:14.983Output 17 with result 0.6295128724375503 in 14:49:14.983Output 18 with result 0.6295159892207073 in 14:49:14.984Output 19 with result 0.6295191059648922 in 14:49:14.984Output 20 with result 0.6295222226700935 in 14:49:14.985...

Source.fromFile("src/main/resources/data2.csv") .getLines() .toList .par .foreach { l => ... }
Output 0 with result 0.6615020337700888 in 12:15:53.564Output 0 with result 0.6622847063345205 in 12:15:53.564

object Perceptron { def activation(w: Vector[Double], f: Vector[Double], bias: Double, activationFunction: Double => Double) = activationFunction(w.zip(f).map(x => x._1 * x._2).sum + bias)}
object Network { def feedForward(features: Vector[Double], network: Seq[Vector[Vector[Double] => Double]]): Vector[Double] = network.foldLeft(features)((b, a) => a.map(_(b)))}
val network = Seq[Vector[Vector[Double] => Double]]( Vector( Perceptron.activation(Vector(0.3, 0.3, 0.3), _, 0.2, Neuron.sigmoid), Perceptron.activation(Vector(0.3, 0.3, 0.3), _, 0.2, Neuron.sigmoid)), Vector(Perceptron.activation(Vector(0.3, 0.3, 0.3), _, 0.2, Neuron.sigmoid)))
Network.feedForward(Vector(splits(0).toDouble, splits(1).toDouble, splits(2).toDouble), network)

● Actor framework for truly concurrent and distributed systems● Thread safe mutable state● Send messages, create new actors, change behaviour● Multiple options how to express Neural network

def props() = Props(behaviour)def behaviour = addInput(addOutput(feedForward(_, _, 0.2, sigmoid, Vector(), Vector()), _))
private def allInputsAvailable(w: Vector[Double], f: Vector[Double], in: Seq[ActorRef[Nothing]]) = w.length == in.length && f.length == in.length
def feedForward( inputs: Seq[ActorRef[Nothing]], outputs: Seq[ActorRef[Input]], bias: Double, activationFunction: Double => Double, weightsT: Vector[Double], featuresT: Vector[Double]): Behavior[NodeMessage] = Partial[NodeMessage] {
case WeightedInput(f, w) => val featuresTplusOne = featuresT :+ f val weightsTplusOne = weightsT :+ w
if (allInputsAvailable(featuresTplusOne, weightsTplusOne, inputs)) { val activation = activationFunction(weightsTplusOne.zip(featuresTplusOne).map(x => x._1 * x._2).sum + bias) outputs.foreach(_ ! Input(activation))
feedForward(inputs, outputs, bias, activationFunction, Vector(), Vector()) } else { feedForward(inputs, outputs, bias, activationFunction, weightsTplusOne, featuresTplusOne) }}

Activation 0.5498414227985574 using features Vector(0.0, 0.0, 1.0E-4)Activation 0.549856273704096 using features Vector(0.0, 1.0E-4, 2.0E-4)Activation 0.5498711245207856 using features Vector(1.0E-4, 2.0E-4, 2.0E-4)Activation 0.6294619594716266 using features Vector(0.5498414227985574, 0.549856273704096)Activation 0.5498859752486001 using features Vector(3.0E-4, 4.0E-4, 0.0)Activation 0.5499082511736245 using features Vector(3.0E-4, 4.0E-4, 3.0E-4)Activation 0.6294661160203068 using features Vector(0.5498711245207856, 0.5498859752486001)Activation 0.5499453772705898 using features Vector(4.0E-4, 5.0E-4, 6.0E-4)Activation 0.549893400579171 using features Vector(1.0E-4, 5.0E-4, 2.0E-4)Activation 0.5499453772705898 using features Vector(7.0E-4, 0.0, 8.0E-4)Activation 0.6294692333865788 using features Vector(0.5499082511736245, 0.549893400579171)Activation 0.5499231016791383 using features Vector(1.0E-4, 9.0E-4, 2.0E-4)Activation 0.5499231016791383 using features Vector(3.0E-4, 4.0E-4, 5.0E-4)Activation 0.549967652661781 using features Vector(6.0E-4, 5.0E-4, 7.0E-4)Activation 0.5500047778685057 using features Vector(6.0E-4, 8.0E-4, 9.0E-4)Activation 0.5500196277952787 using features Vector(7.0E-4, 8.0E-4, 0.001)Activation 0.5500716018368813 using features Vector(9.0E-4, 0.0011, 0.0012)Activation 0.5501458485714356 using features Vector(0.0013, 0.0014, 0.0015)Activation 0.5501532731220817 using features Vector(0.0016, 0.001, 0.0017)

● Sequential program always one total order of operations● No order guarantees in distributed system● Akka messages sent directly from the first to the second will not be
received out-of-order for a pair of actors (non transitive)

● At-most-once. Messages may be lost.● At-least-once. Messages may be duplicated but not lost.● Exactly-once.
Ack [8]

1.
4.
7.
2.
3.
5.
6.
8.
9.
10.
11.

?
?
?
? + 1
? + 1
? + 1
? + 1
? + 1
? + 1
? + 2
? + 2

Output 76 with result 0.6298492571946717 in 2015-05-21 17:26:56.504Output 77 with result 0.6298357692712147 in 2015-05-21 17:26:56.504Output 78 with result 0.6298679316729997 in 2015-05-21 17:26:56.504Output 79 with result 0.6298674125610421 in 2015-05-21 17:26:56.504Output 80 with result 0.6298866035455875 in 2015-05-21 17:26:56.504Output 81 with result 0.6298959406028078 in 2015-05-21 17:26:56.504Output 82 with result 0.6299052760580531 in 2015-05-21 17:26:56.504Output 83 with result 0.6299057948796922 in 2015-05-21 17:26:56.505Output 84 with result 0.6299094252583786 in 2015-05-21 17:26:56.505Output 85 with result 0.6299332807659122 in 2015-05-21 17:26:56.505Output 86 with result 0.6299426148804811 in 2015-05-21 17:26:56.505Output 87 with result 0.6299462447313531 in 2015-05-21 17:26:56.505Output 88 with result 0.6299612820238325 in 2015-05-21 17:26:56.505[INFO] [05/21/2015 17:26:56.504] [akka-akka.actor.default-dispatcher-13] [akka://akka/user/hiddenLayer1] Message [Node$WeightedInput] from Actor[akka://akka/deadLetters] to Actor[akka://akka/user/hiddenLayer1#162015581] was not delivered. [1] dead letters encountered. This logging can be turned off or adjusted with configuration settings 'akka.log-dead-letters' and 'akka.log-dead-letters-during-shutdown'.Output 89 with result 0.6299706150403437 in 2015-05-21 17:26:56.505Output 90 with result 0.6299799476901787 in 2015-05-21 17:26:56.506[INFO] [05/21/2015 17:26:56.504] [akka-akka.actor.default-dispatcher-13] [akka://akka/user/hiddenLayer1] Message [Node$WeightedInput] from Actor[akka://akka/deadLetters] to Actor[akka://akka/user/hiddenLayer1#162015581] was not delivered. [2] dead letters encountered. This logging can be turned off or adjusted with configuration settings 'akka.log-dead-letters' and 'akka.log-dead-letters-during-shutdown'.Output 91 with result 0.6299809846419518 in 2015-05-21 17:26:56.506Output 92 with result 0.6299986118617977 in 2015-05-21 17:26:56.506

● Model parallelism● Actor creation manual or Cluster Sharding
val idExtractor: ShardRegion.IdExtractor = {
case i: AddInputs =>
}
val shardResolver: ShardRegion.ShardResolver = {
case i: AddInputs =>
}
Mac
hin
e 1
Mach
ine 2
Mac
hin
e 3
Mach
ine 4
Mac
hin
e 1 M
achin
e 2
Mac
hin
e 3 M
achin
e 4 [9]

class Perceptron() extends Actor with Neuron { ...
override def receive = run orElse addInput orElse addOutput
val shardRegion = ClusterSharding(context.system).shardRegion(Edge.shardName)
def run: Receive = { case WeightedInput(_, f, w) => featuresT = featuresT :+ f weightsT = weightsT :+ w
if(allInputsAvailable(weightsT, featuresT, inputs)) { val activation = activationFunction(weightsT.zip(featuresT).map(x => x._1 * x._2).sum + bias)
featuresT = Vector() weightsT = Vector()
outputs.foreach(shardRegion ! Input(_, activation)) } }}

Output 18853 with result 0.6445355972059068 in 17:33:12.248Output 18854 with result 0.6392081778097862 in 17:33:12.248Output 18855 with result 0.6476549338361918 in 17:33:12.248Output 18856 with result 0.6413832367161323 in 17:33:12.248[17:33:12.353] [ClusterSystem-akka.actor.default-dispatcher-21] [Cluster(akka://ClusterSystem)] Cluster Node [akka.tcp://[email protected]:2551] - Leader is removing unreachable node [akka.tcp://[email protected]:54495][17:33:12.388] [ClusterSystem-akka.actor.default-dispatcher-22] [akka.tcp://[email protected]:2551/user/sharding/PerceptronCoordinator] Member removed [akka.tcp://[email protected]:54495][17:33:12.388] [ClusterSystem-akka.actor.default-dispatcher-35] [akka.tcp://[email protected]:2551/user/sharding/EdgeCoordinator] Member removed [akka.tcp://[email protected]:54495]
[17:33:12.415] [ClusterSystem-akka.actor.default-dispatcher-18] [akka://ClusterSystem/user/sharding/Edge/e-2-1-3-1] null java.lang.NullPointerException
[17:33:12.436] [ClusterSystem-akka.actor.default-dispatcher-2] [akka://ClusterSystem/user/sharding/Edge/e-2-1-3-1] null java.lang.NullPointerException
[17:33:12.436] [ClusterSystem-akka.actor.default-dispatcher-2] [akka://ClusterSystem/user/sharding/Edge/e-2-1-3-1] null java.lang.NullPointerException

class Edge extends PersistentActor with HasInput with HasOutput { override def persistenceId: String = self.path.name var weight: Double = 0.3
override def receiveCommand: Receive = run orElse addInput orElse addOutput override def receiveRecover: Receive = recover orElse addInputRecover orElse addOutputRecover
val shardRegion = ClusterSharding(context.system).shardRegion(Perceptron.shardName)
def run: Receive = { case Input(r, f) => shardRegion ! WeightedInput(output, f, weight)
case UpdateWeightCommand(r, w) => persist(UpdatedWeightEvent(r, w)) { event => weight = event.weight } }
def recover: Receive = { case UpdatedWeightEvent(_, w) => weight = w }}
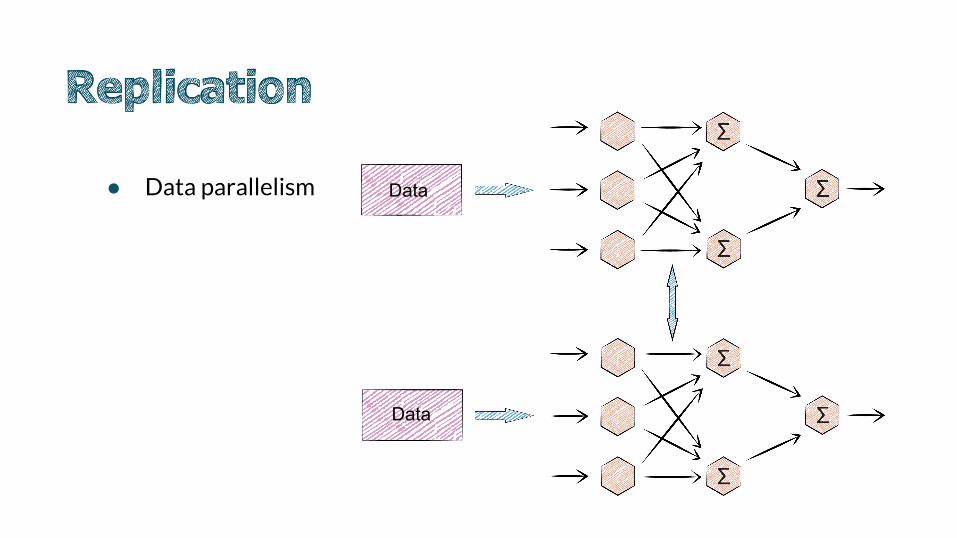
● Data parallelism
Data
Data

ElasticSearch gives up on partition tolerance, it means, if enough nodes fail, cluster state turns red and ES does not proceed to operate on that index.
ES is not giving up on availability. Every request will be responded, either true (with result) or false (error).
● Synchronous and asynchronout replication● Avaiability and consistency during partition
[4]

Clock: (r0 -> 1), Value: x
r0 r1 r2

r0 r1 r2
(r0 -> 1), x (r0 -> 1), x (r0 -> 1), x
(r2 -> 1), y
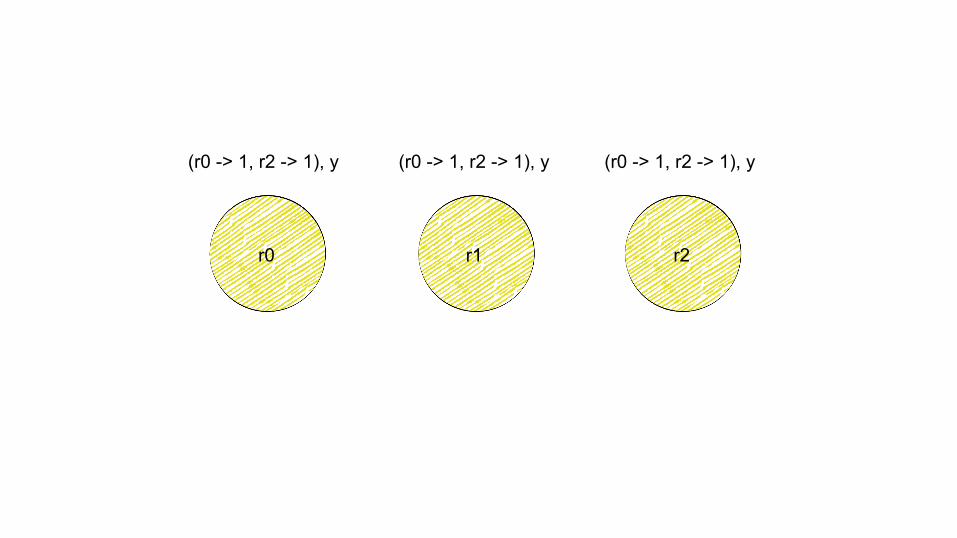
r0 r1 r2
(r0 -> 1, r2 -> 1), y(r0 -> 1, r2 -> 1), y(r0 -> 1, r2 -> 1), y

(r0 -> 1), x (r2 -> 1), y
Conflict
r0 r1 r2

class Edge( override val aggregateId: Option[String], override val replicaId: String, override val eventLog: ActorRef) extends EventsourcedActor with HasInput with HasOutput {
var weight: Double = 0.3
override def onCommand: Receive = run orElse addInput orElse addOutput private var versionedState: ConcurrentVersions[Double, Double] = ConcurrentVersions(0.3, (s, a) => a)
...
override def onEvent: Receive = { case UpdatedWeightEvent(w) => versionedState = versionedState.update(w, lastVectorTimestamp, lastEmitterReplicaId) if (versionedState.conflict) { val conflictingVersions = versionedState.all val avg = conflictingVersions.map(_.value).sum / conflictingVersions.size
val newTimestamp = conflictingVersions.map(_.updateTimestamp).foldLeft(VectorTime())(_.merge(_)) versionedState.update(avg, newTimestamp, replicaId) versionedState = versionedState.resolve(newTimestamp)
weight = versionedState.all.head.value } else { weight = versionedState.all.head.value } }}

● Replica r0 - update weight to 0, 1, 2● Replica r1 - 3, 4, 5● Replica r2 - 6, 7, 8
Conflicting versions on replica 0 value 4.0 vector clock VectorTime(r1 -> 1) value 7.0 vector clock VectorTime(r2 -> 1)
Conflicting versions on replica 0 resolved value 5.5 vector clock VectorTime(r1 -> 1,r2 -> 1)
Conflicting versions on replica 0 value 5.5 vector clock VectorTime(r1 -> 1,r2 -> 1)value 0.0 vector clock VectorTime(r0 -> 1)
Conflicting versions on replica 0 resolved value 2.75 vector clock VectorTime(r1 -> 1,r2 -> 1,r0 -> 1)
Conflicting versions on replica 0value 2.75 vector clock VectorTime(r1 -> 1,r2 -> 1,r0 -> 1)value 3.0 vector clock VectorTime(r1 -> 2)
Conflicting versions on replica 0 resolved Vector(value 2.875 vector clock VectorTime(r1 -> 2,r2 -> 1,r0 -> 1)
Conflicting versions on replica 0 value 5.0 vector clock VectorTime(1-e1 -> 5,r2 -> 1,r0 -> 1)value 6.0 vector clock VectorTime(r2 -> 3,1-e1 -> 1)
Conflicting versions on replica 0 resolved Vector(value 5.5 vector clock VectorTime(1-e1 -> 5,r2 -> 3,r0 -> 1)

class Edge extends Actor with HasInput with HasOutput { var weight: Double = 0.3
val replicator = DataReplication(context.system).replicator implicit val cluster = Cluster(context.system)
replicator ! Subscribe(self.path.name, self)
override def receive: Receive = run orElse addInput orElse addOutput
def run: Receive = { ... case UpdateWeight(w) => replicator ! Update(self.path.name, GCounter(), WriteLocal)(_ + w)
case Changed(key, GCounter(mergedWeight)) if key == self.path.name => weight = mergedWeight }}

● Replica r0 - update weight to 0, 1, 2● Replica r1 - 3, 4, 5● Replica r2 - 6, 7, 8
Weight on replica r2 changed to 21Weight on replica r0 changed to 3Weight on replica r1 changed to 12Weight on replica r2 changed to 24Weight on replica r0 changed to 36Weight on replica r1 changed to 15Weight on replica r2 changed to 36Weight on replica r1 changed to 36

● Publisher and subscriber● Source[Circle].map(_.toSquare).filter(_.color == blue)● Lazy topology definition
Publisher Subscriber
toSquare
color == blue
backpressure

input ~> network(topology, weights) ~> zipWithIndex ~> formatPrintSink
def buildLayer( layer: Int, input: Outlet[DenseMatrix[Double]], topology: Array[Int], weights: DenseMatrix[Double]): Outlet[DenseMatrix[Double]] = { val currentLayer = builder.add(hiddenLayer(layer))
input ~> currentLayer.in0 hiddenLayerWeights(topology, layer, weights) ~> currentLayer.in1
if (layer < topology.length - 1) buildLayer(layer + 1, currentLayer.out, topology, weights) else currentLayer.out }

def hiddenLayer(layer: Int) = { def feedForward(features: DenseMatrix[Double], weightMatrices: DenseMatrix[Double]) = { val bias = 0.2 val activation: DenseMatrix[Double] = weightMatrices * features activation(::, *) :+= bias sigmoid.inPlace(activation) activation }
FlowGraph.partial() { implicit builder: FlowGraph.Builder[Unit] => import akka.stream.scaladsl.FlowGraph.Implicits._
val zipInputAndWeights = builder.add(Zip[DenseMatrix[Double], DenseMatrix[Double]]()) val feedForwardFlow = builder.add(Flow[(DenseMatrix[Double], DenseMatrix[Double])] .map(x => feedForward(x._1, x._2)))
zipInputAndWeights.out ~> feedForwardFlow
new FanInShape2(zipInputAndWeights.in0, zipInputAndWeights.in1, feedForwardFlow.outlet) }}

Networkweights vector n
zipfeedForward
activation
*
zipWithIndex
indexLayer
ZipWithIndex
feature vector n+1
feature vector n

[10]

● In memory dataflow distributed data processing framework, streaming and batch
● Distributes computation using a higher level API● Moves computation to data● Fault tolerant● Caching
● Transformations○ Lazy, form the DAG○ map, filter, flatMap, mapPartitions, mapPartitionsWithIndex, sample,
union, intersection, distinct, groupByKey, reduceByKey, sortByKey, join, cogroup, repatition, cartesian, glom, ...
● Actions○ Execute DAG, retrieve result○ reduce, collect, count, first, take, foreach, saveAs…, min, max, ...

textFile mapmapreduceByKey
collect
sc.textFile("counts") .map(line => line.split("\t")) .map(word => (word(0), word(1).toInt)) .reduceByKey(_ + _) .collect()
[11]

● Accumulators○ Processes can only add○ Associative, commutative operation○ Only driver program can read the value○ Exactly once semantics only guaranteed for actions
object DoubleAccumulatorParam extends AccumulatorParam[Double] {
def zero(initialValue: Double): Double = 0
def addInPlace(d1: Double, d2: Double): Double = d1 + d2
}

def forwardRun( topology: Array[Int], data: DenseMatrix[Double], weightMatrices: Array[DenseMatrix[Double]]): DenseMatrix[Double] = {
val bias = 0.2 val outArray = new Array[DenseMatrix[Double]](topology.size) val blas = BLAS.getInstance()
outArray(0) = data
for(i <- 1 until topology.size) { val weights = hiddenLayerWeights(topology, i, weightMatrices)
val outputCurrent = new DenseMatrix[Double](weights.rows, data.cols) val outputPrevious = outArray(i - 1)
blas.dgemm("N", "N", outputCurrent.rows, outputCurrent.cols, weights.cols, 1.0, weights.data, weights.offset, weights.majorStride, outputPrevious.data, outputPrevious.offset, outputPrevious.majorStride, 1.0, outputCurrent.data, outputCurrent.offset, outputCurrent.rows)
outArray(i) = outputCurrent outArray(i)(::, *) :+= bias sigmoid.inPlace(outArray(i)) }
outArray(topology.size - 1)}

val sc = new SparkContext("local", "Neural Network")
val result = sc.textFile("src/main/resources/data.csv", 3)
.map { l =>
val splits = l.split(",")
val features = splits.map(_.toDouble)
new DenseMatrix(3, 1, Array(features(0), features(1), features(2)))
}
.map(in => forwardRun(topology, in, weights))
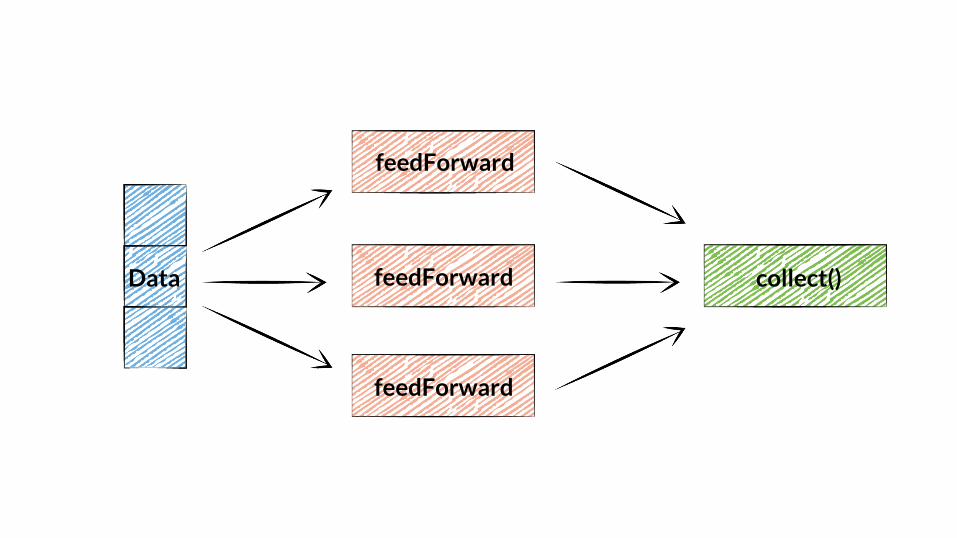
Data
feedForward
feedForward
feedForward
collect()

val sqlContext = new org.apache.spark.sql.SQLContext(sc)import sqlContext.implicits._
val resultDF = result.toDF("result")resultDF .filter(resultDF("result") > "String") .select(resultDF("result") + "String")
// StructType(StructField(result,DoubleType,true))
resultDF.registerTempTable("results")val filtered3 = sqlContext.sql( "SELECT result + \"String\" " + "FROM (" + "SELECT result " + "FROM results) r " + "WHERE r.result >= \"String\"")
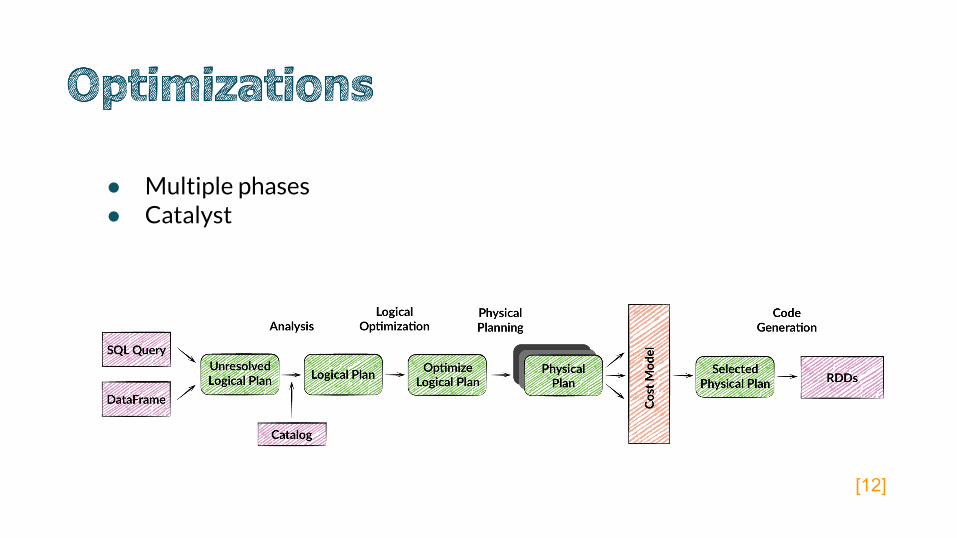
● Multiple phases● Catalyst
[12]

object PushPredicateThroughProject extends Rule[LogicalPlan] { def apply(plan: LogicalPlan): LogicalPlan = plan transform { case filter @ Filter(condition, project @ Project(fields, grandChild)) => val sourceAliases = fields.collect { case a @ Alias(c, _) => (a.toAttribute: Attribute) -> c }.toMap project.copy(child = filter.copy( replaceAlias(condition, sourceAliases), grandChild)) }}
case Divide(e1, e2) => val eval1 = expressionEvaluator(e1) val eval2 = expressionEvaluator(e2)
eval1.code ++ eval2.code ++ q""" var $nullTerm = false var $primitiveTerm: ${termForType(e1.dataType)} = 0
if (${eval1.nullTerm} || ${eval2.nullTerm} ) { $nullTerm = true } else if (${eval2.primitiveTerm} == 0) $nullTerm = true else { $primitiveTerm = ${eval1.primitiveTerm} / ${eval2.primitiveTerm} } """.children

=== Result of Batch Resolution ====== Result of Batch Remove SubQueries ====== Result of Batch ConstantFolding ====== Result of Batch Filter Pushdown ===
== Parsed Logical Plan =='Project [('result + String) AS c0#2] 'Filter ('r.result >= String) 'Subquery r 'Project ['result] 'UnresolvedRelation [results], None
== Analyzed Logical Plan ==Project [(CAST(result#1, DoubleType) + CAST(String, DoubleType)) AS c0#2] Filter (CAST(result#1, DoubleType) >= CAST(String, DoubleType)) Subquery r Project [result#1] Subquery results Project [_1#0 AS result#1] LogicalRDD [_1#0], MapPartitionsRDD[5] at map at SQLContext.scala:394
== Optimized Logical Plan ==LocalRelation [c0#2], []
== Physical Plan ==LocalTableScan [c0#2], []

case class Person(age: Int, height: Double)val people = sc.parallelize((0 to 100).map(x => Person(x, x)))
people .map(p => Person(p.age, p.height * 2.54)) .filter(_.age < 35)
people .filter(_.age < 35) .map(p => Person(p.age, p.height * 2.54))
people .map(p => Person(p.age, p.height * 2.54)) .filter(_.height < 170)
people .filter(_.height < 170) .map(p => Person(p.age, p.height * 2.54))

Choose the best combination of tools for given use case.
Understand the internals of selected tools.
The environment often fully asynchronous and distributed.
1)
2)
3)


● Jobs at www.cakesolutions.net/careers● Code at https://github.com/zapletal-martin/reactive-deep-learning● Twitter @zapletal_martin

[1] http://www.csie.ntu.edu.tw/~cjlin/talks/twdatasci_cjlin.pdf
[2] http://blog.acolyer.org/2015/06/05/scalability-but-at-what-cost/
[3] https://queue.acm.org/detail.cfm?id=2655736
[4] https://aphyr.com/
[5] http://www.benstopford.com/2015/04/28/elements-of-scale-composing-and-scaling-data-platforms/
[6] http://malteschwarzkopf.de/research/assets/google-stack.pdf
[7] http://malteschwarzkopf.de/research/assets/facebook-stack.pdf
[8] http://en.wikipedia.org/wiki/Two_Generals%27_Problem
[9] http://static.googleusercontent.com/media/research.google.com/en/us/archive/large_deep_networks_nips2012.pdf
[10] http://www.smartjava.org/content/visualizing-back-pressure-and-reactive-streams-akka-streams-statsd-grafana-and-influxdb
[11] http://www.slideshare.net/LisaHua/spark-overview-37479609
[12] https://ogirardot.wordpress.com/2015/05/29/rdds-are-the-new-bytecode-of-apache-spark/

















