37
Latent Dirichlet Allocation a generative model for text David M. Blei, Andrew Y. Ng, Michael I. Jordan (2002) Presenter: Ido Abramovich
| Date post: | 20-Dec-2015 |
| Category: |
Documents |
| View: | 244 times |
| Download: | 0 times |

Latent Dirichlet Allocationa generative model for text
David M. Blei, Andrew Y. Ng, Michael I. Jordan (2002)
Presenter: Ido Abramovich

Overview
Motivation Other models Notation and terminology Latent Dirichlet allocation method LDA in relation to other models A geometric interpretation The problems of estimating Example

Motivation
What do we want to do with text corpora? classification, novelty detection,
summarization and similarity/relevance judgments.
Given a text corpora or other collection of discrete data we wish to:Find a short description of the data.Preserve the essential statistical relationships

Term Frequency – Inverse Document Frequency
tf-idf (Salton and McGill, 1983) The term frequency count is compared to an
inverse document frequency count. Results in a txd matrix – thus reducing the
corpus to a fixed-length list Basic identification of sets of words that are
discriminative for documents in the collection Used for search engines

LSI (Deerwester et al., 1990)
Latent Semantic Indexing Classic attempt at solving this problem in
information retrievalUses SVD to reduce document
representationsModels synonymy and polysemyComputing SVD is slowNon-probabilistic model

pLSIHoffman (1999)
A generative model Models each word in a document as a sample
from a mixture model. Each word is generated from a single topic,
different words in the document may be generated from different topics.
Each document is represented as a list of mixing proportions for the mixture components.

Exchangeability
A finite set of random variables is said to be exchangeable if the joint distribution is invariant to permutation. If π is a permutation of the integers from 1 to N:
An infinite sequence of random is infinitely exchangeable if every finite subsequence is exchangeable
},,{ 1 Nxx
),,(),( )()1(1 NN xxpxxp

bag-of-words Assumption
Word order is ignored “bag-of-words” – exchangeability, not i.i.d Theorem (De Finetti, 1935) – if
are infinitely exchangeable, then the joint probability
has a representation as a mixture:
For some random variable θ
Nxxx ,,, 21
),,,( 21 Nxxxp
N
iiN xppdxxxp
121 )()(),,,(

Notation and terminology
A word is an item from a vocabulary indexed by {1,…,V}. We represent words using unit-basis vectors. The vth word is represented by a V-vector w such that and for
A document is a sequence of N words denoted by , where is the nth word in the sequence.
A corpus is a collection of M documents denoted by
1vw 0uw vu
nw

Latent Dirichlet allocation
LDA is a generative probabilistic model of a corpus. The basic idea is that the documents are represented as random mixtures over latent topics, where a topic is characterized by a distribution over words.

LDA – generative process
1. Choose
2. Choose
3. For each of the N words : (a) Choose a topic
(b) Choose a word from , a multinomial probability conditioned on the topic
nw
nw ),( nn zwp
nz
)11(][ ij
ijVk zwp

Dirichlet distribution
A k-dimensional Dirichlet random variable θ can take values in the (k-1)-simplex, and has the following probability density on this simplex:
111
1
1 1
)(
)()()1(
kkk
i i
ki ip

The graphical model

The LDA equations
M
dd
kN
n zdndnddnd
kN
n znnn
nn
N
nn
dzwpzppDp
dzwpzppp
zwpzppp
d
dn
n
1 1
1
1
),()()(),(
),()()(),()3(
),()()(),,,()2(
w
wz

LDA and exchangeability
We assume that words are generated by topics and that those topics are infinitely exchangeable within a document.
By de Finetti’s theorem:
By marginalizing out the topic variables, we get eq. 3 in the previous slide.
dzwpzpppN
nnnn
1
)()()(),( zw

z
zpzwpwp )(),(),(

Unigram model
N
nnwpp
1
)()(w

Mixture of unigrams
z
N
nn zwpzpp
1
)|()()(w

Probabilistic LSI
z
nn dzpzwpdpwdp )|()|()(),(

A geometric interpretation
word simplex

A geometric interpretation
word simplex
topic 2
topic 1
topic 3
topic simplex

A geometric interpretation
word simplex
topic 2
topic 1
topic 3
topic simplex
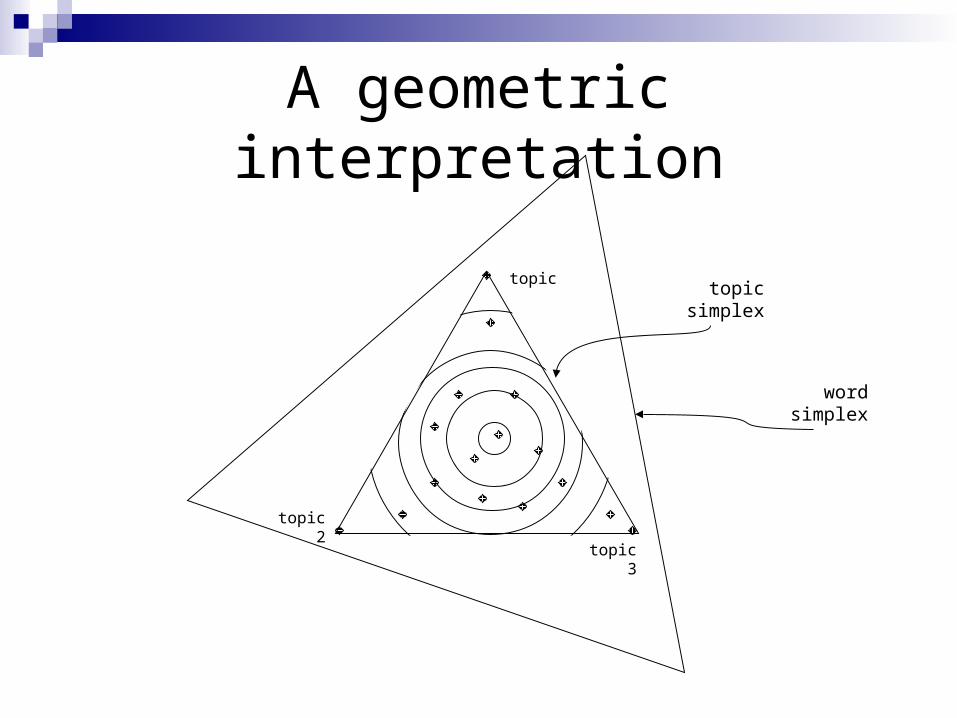
A geometric interpretation
word simplex
topic 2
topic 1
topic 3
topic simplex

Inference
We want to compute the posterior dist. Of the hidden variables given a document:
Unfortunately, this is intractable to compute in general. We write Eq. (3) as:
),|(),|,,(),,|,(
wwzwz p
pp
dpN
n
k
i
V
j
wiji
k
ii
i i
i i jni
1 1 11
1 )()(
)(),|(w

Variational inference
N
nnnzqqq
1
)|()|(),|,( z

Parameter estimation
Variational EM (E Step) For each document, find the optimizing
values of the variational parameters (γ, φ) with α, β fixed.
(M Step) Maximize variational distribution w.r.t. α, β for the γ and φ values found in the E step.
M
ddp
1
),|(log),( w

Smoothed LDA
Introduces Dirichlet smoothing on β to avoid the “zero frequency problem”
More Bayesian approach Inference and parameter learning similar to
unsmoothed LDA


Document modeling
Unlabeled data – our goal is density estimation. Compute the perplexity of a held-out test to
evaluate the models – lower perplexity score indicates better generalization.
.
M
d d
M
d dtest
N
pDperplexity
1
1)(log
exp)(w

Document Modeling – cont.data used
C. Elegans Community abstracts 5,225 abstracts 28,414 unique terms
TREC AP corpus (subset) 16,333 newswire articles 23,075 unique terms
Held-out data – 10% Removed terms – 50 stop words, words
appearing once (AP)

nematode
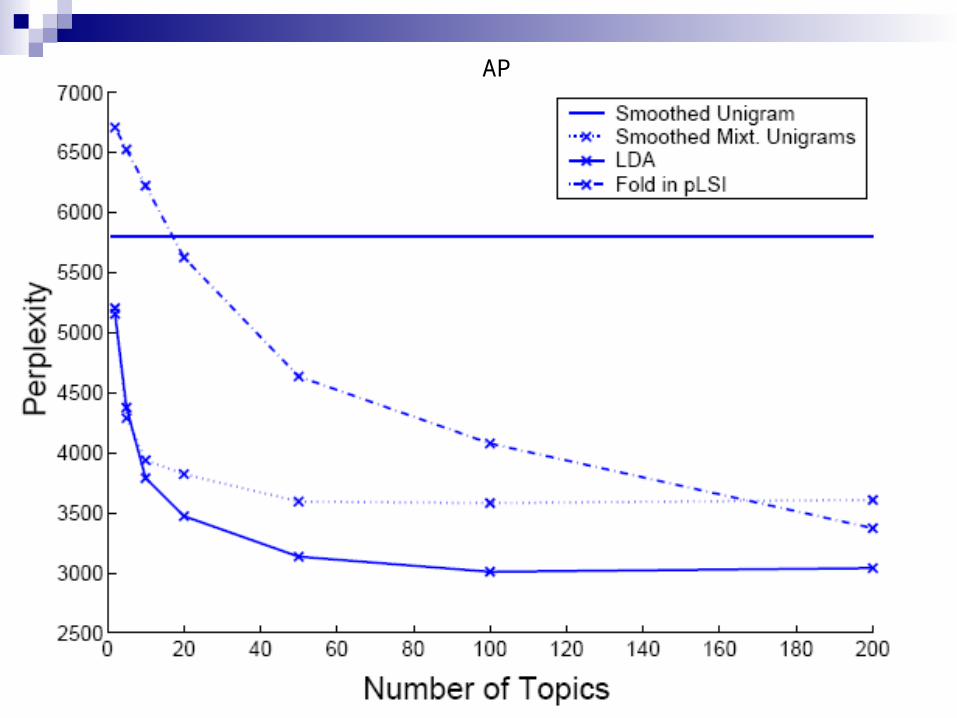
AP

Document Modeling – cont.Results
Both pLSI and mixture suffer from overfitting.
Mixture – peaked posteriors in the training set.
Can solve overfitting with variational Bayesian smoothing.
Num. topics (k)
Perplexity
Mult. Mixt.pLSI
222,2667,052
52.20 x 10817,588
101.93 x 101763.800
201.20 x 10222.52 x 105
504.19 x 101065.04 x 106
1002.39 x 101501.72 x 107
2003.51 x 102641.31 x 107

Document Modeling – cont.Results
Both pLSI and mixture suffer from overfitting.
pLSI – overfitting due to dimensionality of the p(z|d) parameter.
As k gets larger, the chance that a training document will cover all the topics in a new document decreases
Num. topics (k)
Perplexity
Mult. Mixt.pLSI
222,2667,052
52.20 x 10817,588
101.93 x 101763.800
201.20 x 10222.52 x 105
504.19 x 101065.04 x 106
1002.39 x 101501.72 x 107
2003.51 x 102641.31 x 107

Other uses

Summary
Based on the exchangeability assumption Can be viewed as a dimensionality
reduction technique Exact inference is intractable, we can
approximate instead Can be used in other collection – images
and caption for example.

.fin

















