44
Learning Privately from Multiparty Data Jihun Hamm 1 , Paul Cao 2 and Mikhail Belkin 1 1 Dept. CSE, The Ohio State University 2 Dept. CSE, UC-San Diego

Learning Privately from
Multiparty Data
Jihun Hamm1, Paul Cao2 and Mikhail Belkin1
1Dept. CSE, The Ohio State University
2Dept. CSE, UC-San Diego

Example 1: medical research
• Each medical institute has private data
• Goal: collaboratively train a disease classifier
without revealing patient data

Example 2: smartphones
Trusted mediator • Smartphone collecting private data, e.g., emails
• Goal: collaboratively train a spam classifier without
revealing email contents
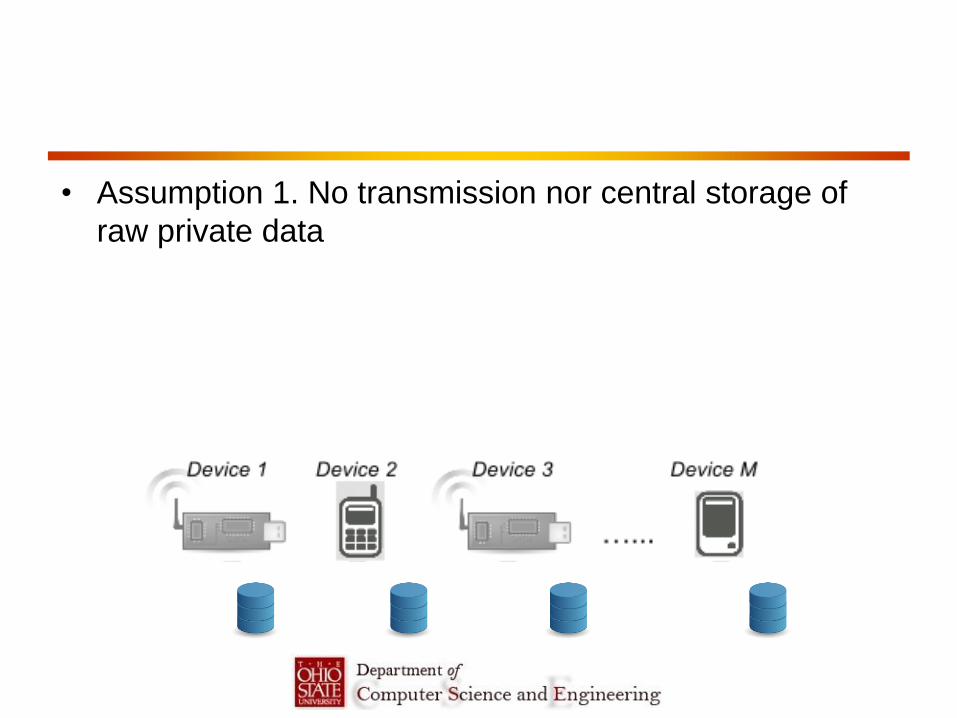
Trusted mediator • Assumption 1. No transmission nor central storage of
raw private data

f1(·) f2(·) f3(·) fM(·)
Trusted mediator • Assumption 1. Private data should not be transmitted
nor stored outside each party
• Assumption 2. Each party has computational power, and
locally trains a classifier using its private data
f1(·) f2(·) f3(·) fM(·)
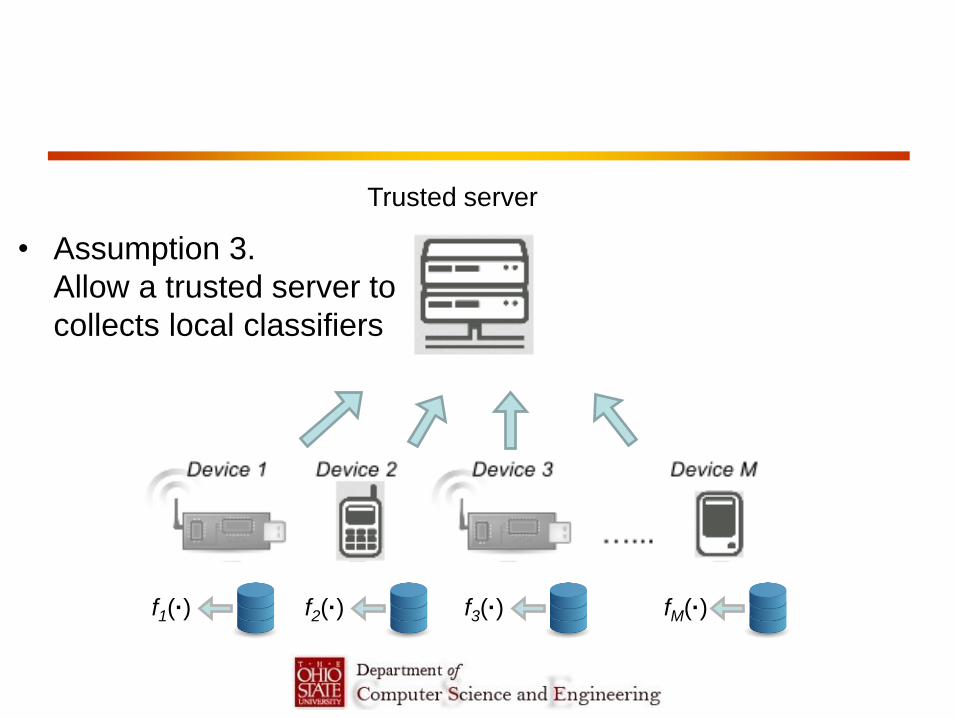
Trusted server
• Assumption 3.
Allow a trusted server to
collects local classifiers

Problem
• Q. How to combine local classifiers {fj(·)} to build an
accurate global classifier in a private manner?

Problem
• Q. How to combine local classifiers {fj(·)} to build an
accurate global classifier in a private manner?
• Previous approach
– Parameter averaging [Pathak et al.’10]
– Local classifiers {w1, … , wM } → 1/M ∑ wi
– Communication-efficient learning
– Simple but has restrictions

Problem
• Q. How to combine local classifiers {fj(·)} to build an
accurate global classifier in a private manner?
• Previous approach
– Parameter averaging [Pathak et al.’10]
– Local classifiers {w1, … , wM } → 1/M ∑ wi
– Communication-efficient learning
– Simple but has restrictions
• Proposal: ensemble approach
– Make ensemble decisions (e.g., voting) from local classifiers
– Flexible: Don’t care what {fj(·)} are

Idea 1/2
f1(·) f2(·) f3(·) fM(·)
Auxiliary
unlabeled
data
Trusted server
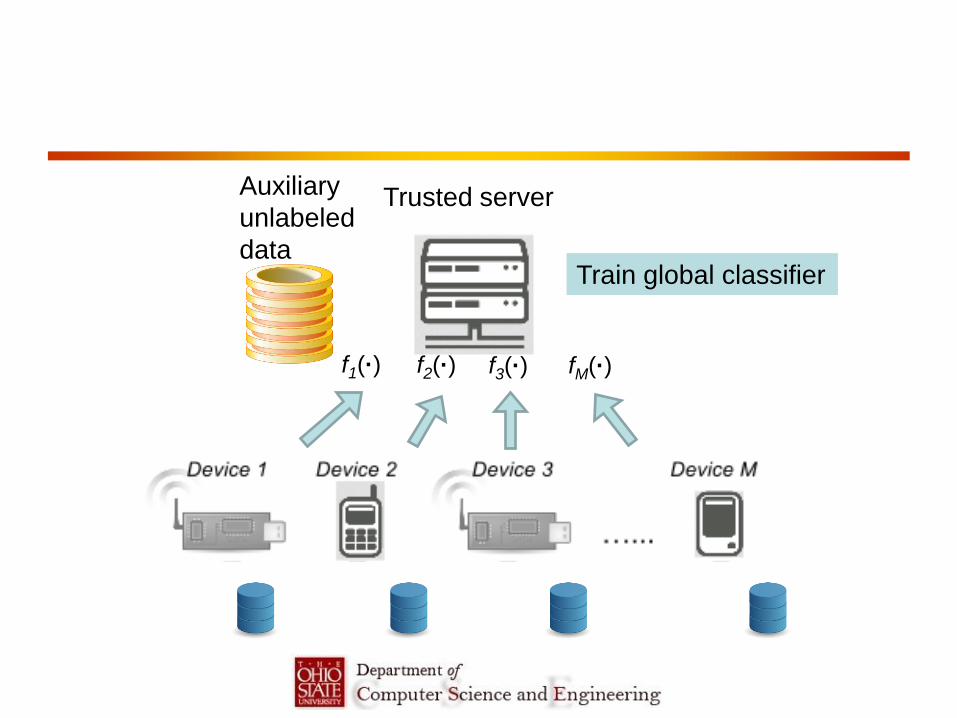
f1(·) f2(·) f3(·) fM(·)
Trusted server Auxiliary
unlabeled
data Train global classifier

Apply privacy mechanism
Trusted server Auxiliary
unlabeled
data

h(· ; wp) h(· ; wp) h(· ; wp) h(· ; wp)
Trusted server Auxiliary
unlabeled
data

First attempt – majority voting
• Trusted mediator has local classifiers
Trusted server
f1(x) f2(x) f3(x)
Auxiliary
unlabeled
data
x1
x2
x3
x4
...
xN

• Perform majority voting
Trusted server
f1(x) f2(x) f3(x) vote
x1
x2
x3
x4
...
xN
1 -1 1
1 1 1
1 -1 -1
-1 1 -1
...
1 1 1
1
1
-1
-1
...
1

Trusted server
f1(x) f2(x) f3(x) vote
x1
x2
x3
x4
...
xN
1 -1 1
1 1 1
1 -1 -1
-1 1 -1
...
1 1 1
1
1
-1
-1
...
1
• New ‘labeled’ data is created from auxiliary data

Trusted server
y
x1
x2
x3
x4
...
xN
1
1
-1
-1
...
1
Train h(x) with
some learning
algorithm

Trusted mediator
y
x1
x2
x3
x4
...
xN
1
1
-1
-1
...
1
Train h(x) by ERM

Trusted mediator
y
x1
x2
x3
x4
...
xN
1
1
-1
-1
...
1
Train h(x) by ERM
Sanitize w* by
wp ← w* + η
[Chaudhuri’11]

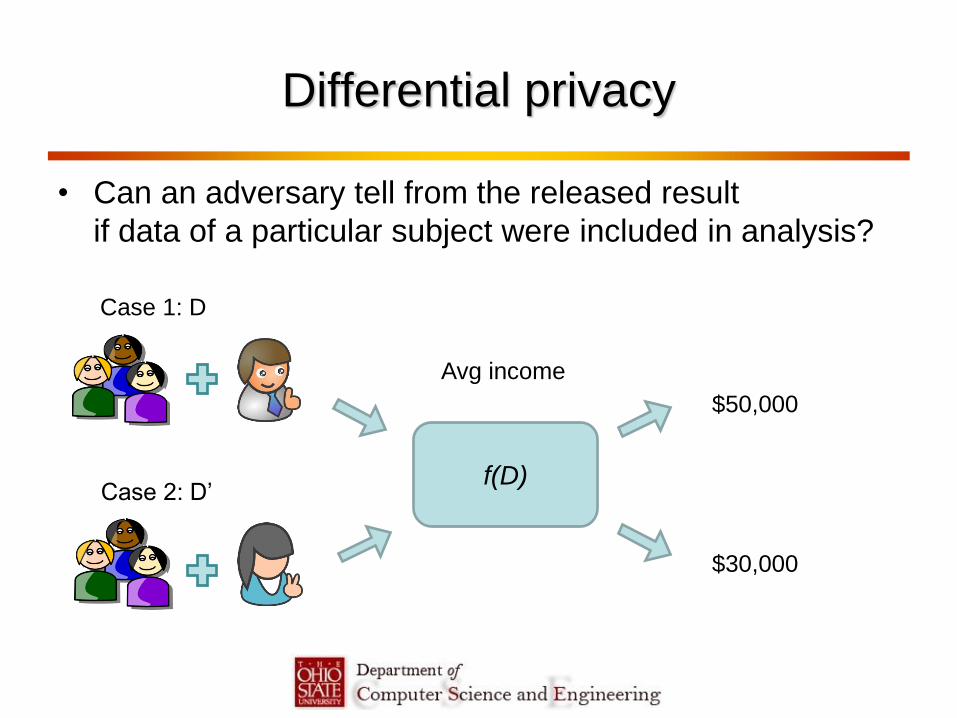
Differential privacy
• Can an adversary tell from the released result
if data of a particular subject were included in analysis?
Differential privacy
• Can an adversary tell from the released result
if data of a particular subject were included in analysis?
Case 1: D
Case 2: D’ f(D)
Avg income
$50,000
$30,000

Differential privacy
• Can an adversary tell from the released result
if data of a particular subject were included in analysis?
Case 1: D
Case 2: D’ f(D) ←f(D) + η
Avg income + noise
P(f(D) = S)
P(f(D’) = S)
$30,000
$50,000

Differential privacy
• Let
– D, D’: neighboring datasets
– : randomized output from of an algorithm on D
• Def: is ε-DP if
for all D ~ D’ and measurable S
• Means: even if an adversary knew all entries of data D
except one, she cannot guess accurately whether it is
from Bob or Alice from the output
P(f(D)) P(f(D’))

Privacy mechanisms
• Q. How to make f(D) differentially private?

Privacy mechanisms
• Q. How to make f(D) differentially private?
• A. Laplace mechanism [Dwork’06]
– Def. Sensitivity :
– Theorem : is ε-DP.
• A. Exponential mechanism [McSherry’07]

Multiparty differential privacy
• Multiparty ε-DP
– M parties, arbitrary # of samples per party,
where can be arbitrarily different, then
• Laplace mechanism [Dwork’06]
– Def (sensitivity) :
– Theorem : is ε-DP.

Sensitivity of majority voting
• Sensitivity in the worst case
– Adversary observes all votes {fi(x)} except fM(x)
– If f1(x) , … , fM-1(x) are evenly divided, then fM(x) becomes the
casting vote
– Worst case: if DM changes, majority-voted labels for ALL
auxiliary samples can change
– If w* = argmin Rs(w), sensitivity S(w*) = 1/λ
– Cf. single-party: 1/(Nλ)

Sensitivity of majority voting
• Sensitivity in the worst case
– Adversary observes all votes {fi(x)} except fM(x)
– If f1(x) , … , fM-1(x) are evenly divided, then fM(x) becomes the
casting vote
– Worst case: if DM changes, majority-voted labels for ALL
auxiliary samples can change
– If w* = argmin Rs(w), sensitivity S(w*) = 1/λ
– Cf. single-party: 1/(Nλ)
• Naïve voting approach impractical !

Idea 2/2 – use “soft” voting
• Goal: make w* insensitive to the decision of any single
party
• Def: weight α(x) is the fraction of positive votes on x
– Is more informative than majority-voted label
– Changes only by a factor of 1/M at most when DM changes

Standard ERM
• Standard ERM (with regularization)

α-Weighted ERM
• Standard ERM (with regularization)
• Weighted ERM (with regularization)
– Each sample considered as both positive and negative samples
– Multiclass extension is straightforward

Properties
• Why minimize weighted risk ?

Properties
• Why minimize weighted risk ?
• Lemma 1. Sensitivity of is 1/(Mλ).

Properties
• Why minimize weighted risk ?
• Lemma 1. Sensitivity of is 1/(Mλ).
• How is related to ?

Properties
• Why minimize weighted risk ?
• Lemma 1. Sensitivity of is 1/(Mλ).
• How is related to ?
• Lemma 2.
as M →∞
– Target label v is probabilistic
– v distributed according to a random classifier [Breiman, 1996]

Privacy
• Theorem 1: Output perturbation by
is -differentially private at the party level

Generalization performance
• Theorem 2: For any hypothesis , with probability of at
least ,
Roughly, Rα(wp) ≤ Rα(w0) + O(M-2 ε-2) + O(N-1)
Cf. Single-party: R(wp) ≤ R(w0) + O(N-2 ε-2) + O(N-1)
[Chaudhuri’11]
• Caution: the bound is relative to a non-private ensemble

Network intrusion detection
batch
indiv
ours
• Network intrusion detection
– Multiple gateways/routers collaboratively build an accurate network
intrusion detector, without revealing logging data
– KDDCUP-99
– 493K (training) / 311K (testing)
– M=20K devices (22 samples per device)

Network intrusion detection
batch
indiv
ours

Malicious URL prediction
batch
indiv
ours
• Malicious URL prediction
– Multiple parties (say PC users) collaboratively build malicious URL
predictors without revealing which website they visited
– 200K (training) / 200K (testing)
– M=20K devices (9 samples per device)

Malicious URL prediction
batch
indiv
ours
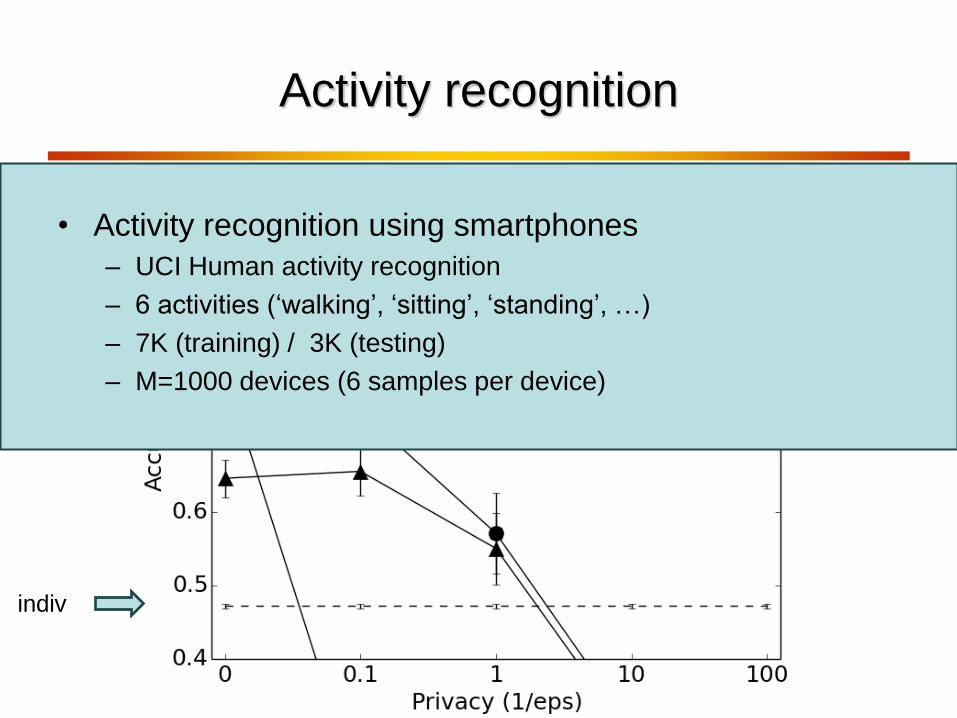
Activity recognition
batch
indiv
ours
• Activity recognition using smartphones
– UCI Human activity recognition
– 6 activities (‘walking’, ‘sitting’, ‘standing’, …)
– 7K (training) / 3K (testing)
– M=1000 devices (6 samples per device)

Activity recognition
batch
indiv
ours

Thank you !

















