26
Learning Structural SVMs with Latent Variables Xionghao Liu
| Date post: | 17-Dec-2015 |
| Category: |
Documents |
| Upload: | augusta-lawrence |
| View: | 219 times |
| Download: | 3 times |

Learning Structural SVMs with Latent Variables
Xionghao Liu

Annotation Mismatch
Input x
Annotation y
Latent h
x
y = “jumping”
h
Action Classification
Mismatch between desired and available annotations
Exact value of latent variable is not “important”
Desired output during test time is y

• Latent SVM
• Optimization
• Practice
• Extensions
Outline – Annotation Mismatch
Andrews et al., NIPS 2001; Smola et al., AISTATS 2005;Felzenszwalb et al., CVPR 2008; Yu and Joachims, ICML 2009

Weakly Supervised Data
Input x
Output y {-1,+1}
Hidden h
x
y = +1
h

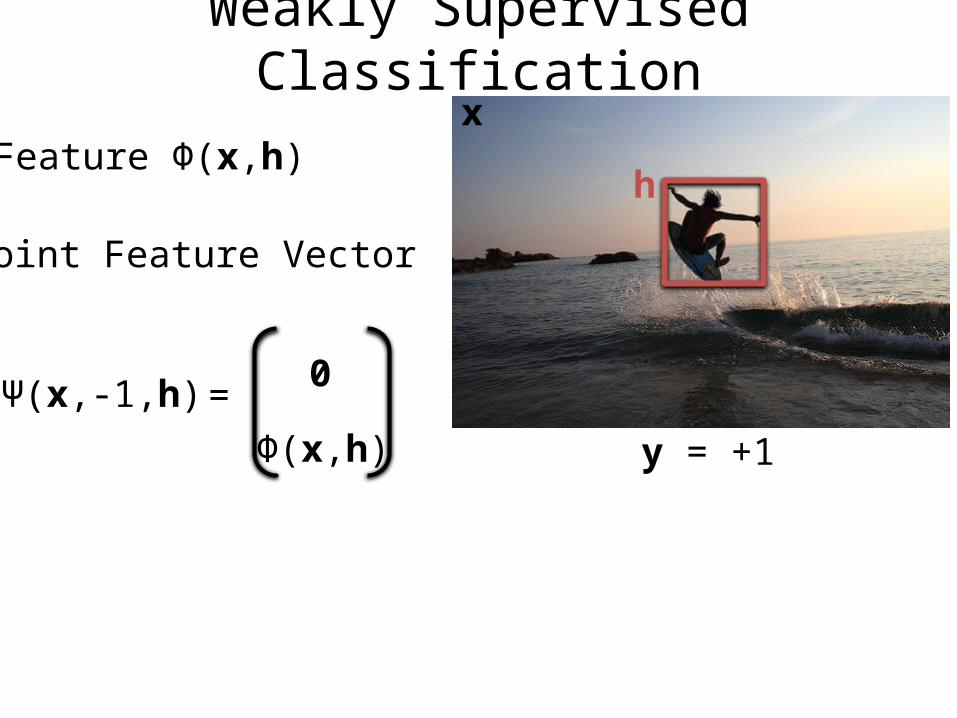
Weakly Supervised Classification
Feature Φ(x,h)
Joint Feature Vector
Ψ(x,y,h)
x
y = +1
h

Weakly Supervised Classification
Feature Φ(x,h)
Joint Feature Vector
Ψ(x,+1,h) Φ(x,h)
0
=
x
y = +1
h
Weakly Supervised Classification
Feature Φ(x,h)
Joint Feature Vector
Ψ(x,-1,h) 0
Φ(x,h)
=
x
y = +1
h

Weakly Supervised Classification
Feature Φ(x,h)
Joint Feature Vector
Ψ(x,y,h)
Score f : Ψ(x,y,h) (-∞, +∞)
Optimize score over all possible y and h
x
y = +1
h

Scoring function
wTΨ(x,y,h)
Prediction
y(w),h(w) = argmaxy,h wTΨ(x,y,h)
Latent SVM
Parameters

Learning Latent SVM
(yi, yi(w))Σi
Empirical risk minimization
minw
No restriction on the loss function
Annotation mismatch
Training data {(xi,yi), i = 1,2,…,n}

Learning Latent SVM
(yi, yi(w))Σi
Empirical risk minimization
minw
Non-convex
Parameters cannot be regularized
Find a regularization-sensitive upper bound

Learning Latent SVM
- wT(xi,yi(w),hi(w))
(yi, yi(w))wT(xi,yi(w),hi(w)) +

Learning Latent SVM
(yi, yi(w))wT(xi,yi(w),hi(w)) +
- maxhi wT(xi,yi,hi)
y(w),h(w) = argmaxy,h wTΨ(x,y,h)

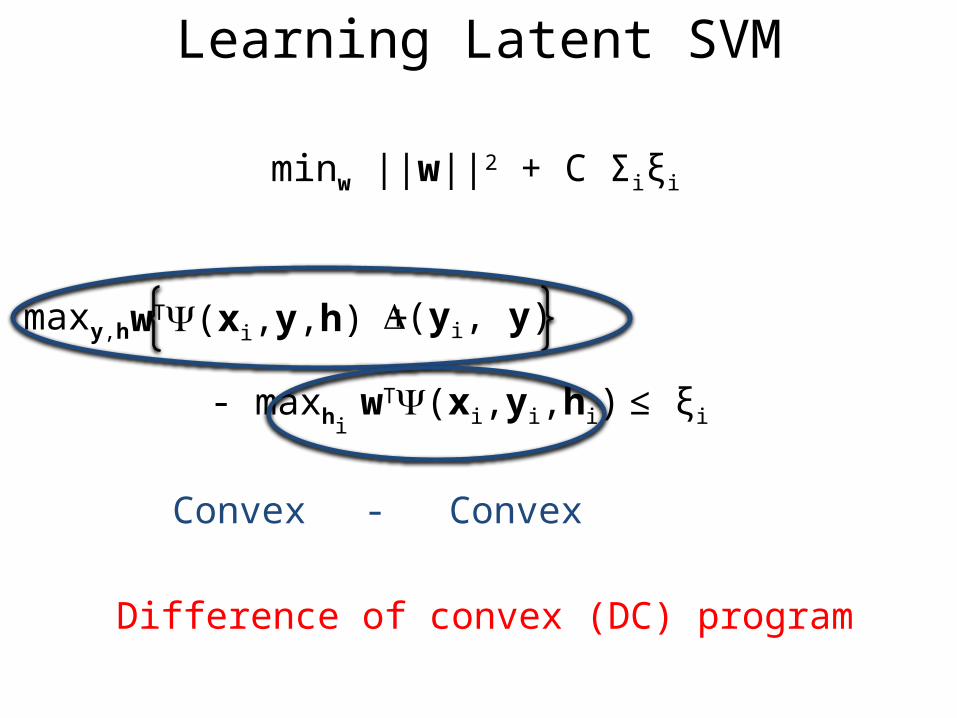
Learning Latent SVM
(yi, y)wT(xi,y,h) +maxy,h
- maxhi wT(xi,yi,hi) ≤ ξi
minw ||w||2 + C Σiξi
Parameters can be regularized
Is this also convex?
Learning Latent SVM
(yi, y)wT(xi,y,h) +maxy,h
- maxhi wT(xi,yi,hi) ≤ ξi
minw ||w||2 + C Σiξi
Convex Convex-
Difference of convex (DC) program

minw ||w||2 + C Σiξi
wTΨ(xi,y,h) + Δ(yi,y) - maxhi wTΨ(xi,yi,hi) ≤ ξi
Scoring function
wTΨ(x,y,h)
Prediction
y(w),h(w) = argmaxy,h wTΨ(x,y,h)
Learning
Recap

• Latent SVM
• Optimization
• Practice
• Extensions
Outline – Annotation Mismatch

Learning Latent SVM
(yi, y)wT(xi,y,h) +maxy,h
- maxhi wT(xi,yi,hi) ≤ ξi
minw ||w||2 + C Σiξi
Difference of convex (DC) program

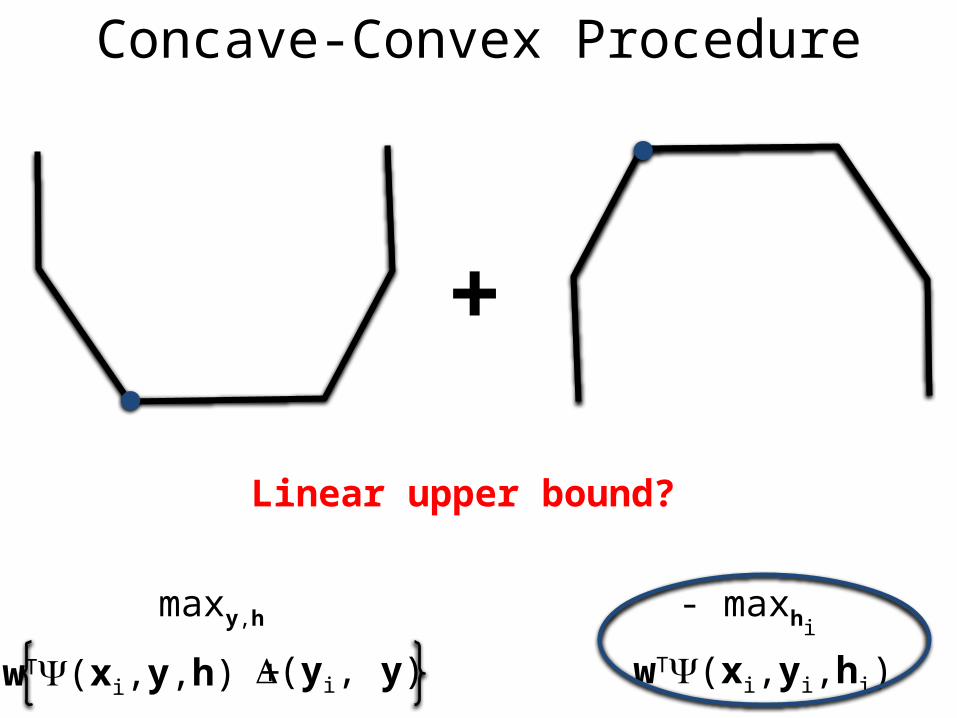
Concave-Convex Procedure
+
(yi, y)wT(xi,y,h) +
maxy,h
wT(xi,yi,hi)
- maxhi
Linear upper-bound of concave part

Concave-Convex Procedure
+
(yi, y)wT(xi,y,h) +
maxy,h
wT(xi,yi,hi)
- maxhi
Optimize the convex upper bound

Concave-Convex Procedure
+
(yi, y)wT(xi,y,h) +
maxy,h
wT(xi,yi,hi)
- maxhi
Linear upper-bound of concave part

Concave-Convex Procedure
+
(yi, y)wT(xi,y,h) +
maxy,h
wT(xi,yi,hi)
- maxhi
Until Convergence
Concave-Convex Procedure
+
(yi, y)wT(xi,y,h) +
maxy,h
wT(xi,yi,hi)
- maxhi
Linear upper bound?

Linear Upper Bound
- maxhi wT(xi,yi,hi)
-wT(xi,yi,hi*)
hi* = argmaxhi wt
T(xi,yi,hi)
Current estimate = wt
≥ - maxhi wT(xi,yi,hi)

CCCP for Latent SVMStart with an initial estimate w0
Update
Update wt+1 as the ε-optimal solution of
min ||w||2 + C∑i i
wT(xi,yi,hi*) - wT(xi,y,h)≥ (yi, y) - i
hi* = argmaxhiH wtT(xi,yi,hi)
Repeat until convergence

Thanks & QA




![IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE …sczhu/papers/PAMI_AOT_learning.pdf · 2014. 5. 6. · part-based latent SVMs model (LSVM) [5] with multiscale HoG [4] features.](https://static.documents.pub/doc/80x56/6122b776de59e56e177897f8/ieee-transactions-on-pattern-analysis-and-machine-sczhupaperspamiaot-2014.jpg)












