Learning to Hash with its Application to Big Data Retrieval and Mining Wu-Jun Li Department of Computer Science and Engineering Shanghai Jiao Tong University Shanghai, China Joint work with Weihao Kong and Minyi Guo Jan 18, 2013 Li (http://www.cs.sjtu.edu.cn/ ~ liwujun) Learning to Hash CSE, SJTU 1 / 45
Transcript
Learning to Hashwith its Application to Big Data Retrieval and Mining
Wu-Jun Li
Department of Computer Science and EngineeringShanghai Jiao Tong University
Shanghai, China
Joint work with Weihao Kong and Minyi Guo
Jan 18, 2013
Li (http://www.cs.sjtu.edu.cn/~liwujun) Learning to Hash CSE, SJTU 1 / 45
Projected with real-valued projection functionGiven a point x, each projected dimension i will be associated with areal-valued projection function fi(x) (e.g. fi(x) = wT
i x)
Quantization Stage
Turn real into binary
Li (http://www.cs.sjtu.edu.cn/~liwujun) Learning to Hash CSE, SJTU 11 / 45
The hashing function family is defined independently of the trainingdataset:
Locality-sensitive hashing (LSH): (Gionis et al., 1999; Andoni andIndyk, 2008) and its extensions (Datar et al., 2004; Kulis andGrauman, 2009; Kulis et al., 2009).
SIKH: Shift invariant kernel hashing (SIKH) (Raginsky and Lazebnik,2009).
Hashing function: random projections.
Li (http://www.cs.sjtu.edu.cn/~liwujun) Learning to Hash CSE, SJTU 12 / 45
To generate a code of m bits, PCAH performs PCA on X, and then usethe top m eigenvectors of the matrix XXT as columns of the projectionmatrix W ∈ Rd×m. Here, top m eigenvectors are those corresponding tothe m largest eigenvalues {λk}mk=1, generally arranged with thenon-increasing order λ1 ≥ λ2 ≥ · · · ≥ λm. Let λ = [λ1, λ2, · · · , λm]T .Then
Λ = W TXXTW = diag(λ)
Define hash functionh(x) = sgn(W Tx)
Li (http://www.cs.sjtu.edu.cn/~liwujun) Learning to Hash CSE, SJTU 19 / 45
[Schur-Horn Lemma (Horn, 1954)] Let c = {ci} ∈ Rm and b = {bi} ∈ Rm
be real vectors in non-increasing order respectively, i.e.,c1 ≥ c2 ≥ · · · ≥ cm, b1 ≥ b2 ≥ · · · ≥ bm. There exists a Hermitian matrixH with eigenvalues c and diagonal values b if and only if
k∑i=1
bi ≤k∑
i=1
ci, for any k = 1, 2, ...,m,
m∑i=1
bi =
m∑i=1
ci.
So we can prove :There exists a solution to the IsoHash problem. And this solution is in theintersection of T (a) and M(Λ).
Li (http://www.cs.sjtu.edu.cn/~liwujun) Learning to Hash CSE, SJTU 24 / 45
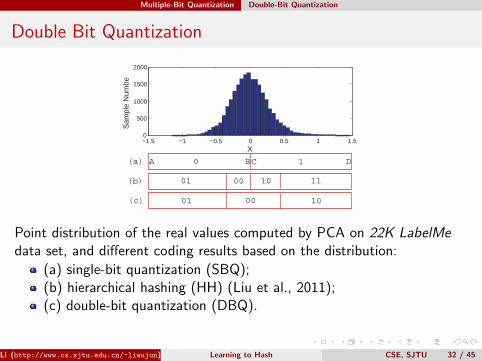
The popular coding strategy SBQ which adopts zero as the thresholdis shown in Figure (a). Due to the thresholding, the intrinsicneighboring structure in the original space is destroyed.The HH strategy (Liu et al., 2011) is shown in Figure (b). If we used(A,B) to denote the Hamming distance between A and B, we canfind that d(A,D) < d(A,C) for HH, which is obviously notreasonable.With our DBQ code, d(A,D) = 2, d(A,B) = d(C,D) = 1, andd(B,C) = 0, which is obviously reasonable to preserve the similarityrelationships in the original space.
Li (http://www.cs.sjtu.edu.cn/~liwujun) Learning to Hash CSE, SJTU 32 / 45
A. Andoni and P. Indyk. Near-optimal hashing algorithms for approximatenearest neighbor in high dimensions. Commun. ACM, 51(1):117–122,2008.
M. Chu. Constructing a Hermitian matrix from its diagonal entries andeigenvalues. SIAM Journal on Matrix Analysis and Applications, 16(1):207–217, 1995.
M. Datar, N. Immorlica, P. Indyk, and V. S. Mirrokni. Locality-sensitivehashing scheme based on p-stable distributions. In Proceedings of theACM Symposium on Computational Geometry, 2004.
A. Gionis, P. Indyk, and R. Motwani. Similarity search in high dimensionsvia hashing. In Proceedings of International Conference on Very LargeData Bases, 1999.
Y. Gong and S. Lazebnik. Iterative quantization: A procrustean approachto learning binary codes. In Proceedings of Computer Vision andPattern Recognition, 2011.
A. Horn. Doubly stochastic matrices and the diagonal of a rotation matrix.American Journal of Mathematics, 76(3):620–630, 1954.
Li (http://www.cs.sjtu.edu.cn/~liwujun) Learning to Hash CSE, SJTU 45 / 45
W. Kong and W.-J. Li. Double-bit quantization for hashing. InProceedings of the Twenty-Sixth AAAI Conference on ArtificialIntelligence (AAAI), 2012a.
W. Kong and W.-J. Li. Isotropic hashing. In Proceedings of the 26thAnnual Conference on Neural Information Processing Systems (NIPS),2012b.
W. Kong, W.-J. Li, and M. Guo. Manhattan hashing for large-scale imageretrieval. In The 35th International ACM SIGIR conference on researchand development in Information Retrieval (SIGIR), 2012.
B. Kulis and K. Grauman. Kernelized locality-sensitive hashing for scalableimage search. In Proceedings of International Conference on ComputerVision, 2009.
B. Kulis, P. Jain, and K. Grauman. Fast similarity search for learnedmetrics. IEEE Trans. Pattern Anal. Mach. Intell., 31(12):2143–2157,2009.
W. Liu, J. Wang, S. Kumar, and S. Chang. Hashing with graphs. InProceedings of International Conference on Machine Learning, 2011.
Li (http://www.cs.sjtu.edu.cn/~liwujun) Learning to Hash CSE, SJTU 45 / 45
M. Norouzi and D. J. Fleet. Minimal loss hashing for compact binarycodes. In Proceedings of International Conference on Machine Learning,2011.
M. Raginsky and S. Lazebnik. Locality-sensitive binary codes fromshift-invariant kernels. In Proceedings of Neural Information ProcessingSystems, 2009.
J. Wang, S. Kumar, and S.-F. Chang. Sequential projection learning forhashing with compact codes. In Proceedings of International Conferenceon Machine Learning, 2010a.
J. Wang, S. Kumar, and S.-F. Chang. Semi-supervised hashing forlarge-scale image retrieval. In Proceedings of Computer Vision andPattern Recognition, 2010b.
Y. Weiss, A. Torralba, and R. Fergus. Spectral hashing. In Proceedings ofNeural Information Processing Systems, 2008.
Li (http://www.cs.sjtu.edu.cn/~liwujun) Learning to Hash CSE, SJTU 45 / 45



















































![AnEnergyEfficientClusteringScheme …cs.nju.edu.cn/gchen/newpaper/UploadFiles/AHSWN07.pdf026(Ye) Ad Hoc & Sensor Wireless Networks April 21, 2006 17:33 102Ye,etal. HEED [8] is a protocol](https://static.documents.pub/doc/80x56/5b1a11787f8b9a28258d1e60/anenergyefcientclusteringscheme-csnjueducngchennewpaperuploadfiles-ye.jpg)














