45
Lecture 17: Supervised Learning Recap Machine Learning April 6, 2010
| Date post: | 19-Dec-2015 |
| Category: |
Documents |
| View: | 218 times |
| Download: | 0 times |

Lecture 17: Supervised Learning Recap
Machine LearningApril 6, 2010

Last Time
• Support Vector Machines• Kernel Methods

Today
• Short recap of Kernel Methods• Review of Supervised Learning• Unsupervised Learning– (Soft) K-means clustering– Expectation Maximization– Spectral Clustering– Principle Components Analysis– Latent Semantic Analysis

Kernel Methods
• Feature extraction to higher dimensional spaces.
• Kernels describe the relationship between vectors (points) rather than the new feature space directly.

When can we use kernels?
• Any time training and evaluation are both based on the dot product between two points.
• SVMs• Perceptron• k-nearest neighbors• k-means• etc.

Kernels in SVMs
• Optimize αi’s and bias w.r.t. kernel• Decision function:

Kernels in Perceptrons
• Training
• Decision function

Good and Valid Kernels
• Good: Computing K(xi,xj) is cheaper than ϕ(xi)• Valid: – Symmetric: K(xi,xj) =K(xj,xi)
– Decomposable into ϕ(xi)Tϕ(xj)• Positive Semi Definite Gram Matrix
• Popular Kernels– Linear, Polynomial– Radial Basis Function– String (technically infinite dimensions)– Graph

Supervised Learning
• Linear Regression• Logistic Regression• Graphical Models– Hidden Markov Models
• Neural Networks• Support Vector Machines– Kernel Methods

Major concepts
• Gaussian, Multinomial, Bernoulli Distributions• Joint vs. Conditional Distributions• Marginalization• Maximum Likelihood• Risk Minimization• Gradient Descent• Feature Extraction, Kernel Methods

Some favorite distributions
• Bernoulli
• Multinomial
• Gaussian

Maximum Likelihood
• Identify the parameter values that yield the maximum likelihood of generating the observed data.
• Take the partial derivative of the likelihood function• Set to zero• Solve
• NB: maximum likelihood parameters are the same as maximum log likelihood parameters

Maximum Log Likelihood
• Why do we like the log function?• It turns products (difficult to differentiate) and
turns them into sums (easy to differentiate)
• log(xy) = log(x) + log(y)• log(xc) = c log(x)•

Risk Minimization
• Pick a loss function– Squared loss– Linear loss– Perceptron (classification) loss
• Identify the parameters that minimize the loss function.– Take the partial derivative of the loss function– Set to zero– Solve

Frequentists v. Bayesians
• Point estimates vs. Posteriors• Risk Minimization vs. Maximum Likelihood• L2-Regularization– Frequentists: Add a constraint on the size of the
weight vector– Bayesians: Introduce a zero-mean prior on the
weight vector– Result is the same!

L2-Regularization
• Frequentists:– Introduce a cost on the size of the weights
• Bayesians:– Introduce a prior on the weights

Types of Classifiers
• Generative Models– Highest resource requirements. – Need to approximate the joint probability
• Discriminative Models– Moderate resource requirements. – Typically fewer parameters to approximate than generative models
• Discriminant Functions– Can be trained probabilistically, but the output does not include
confidence information
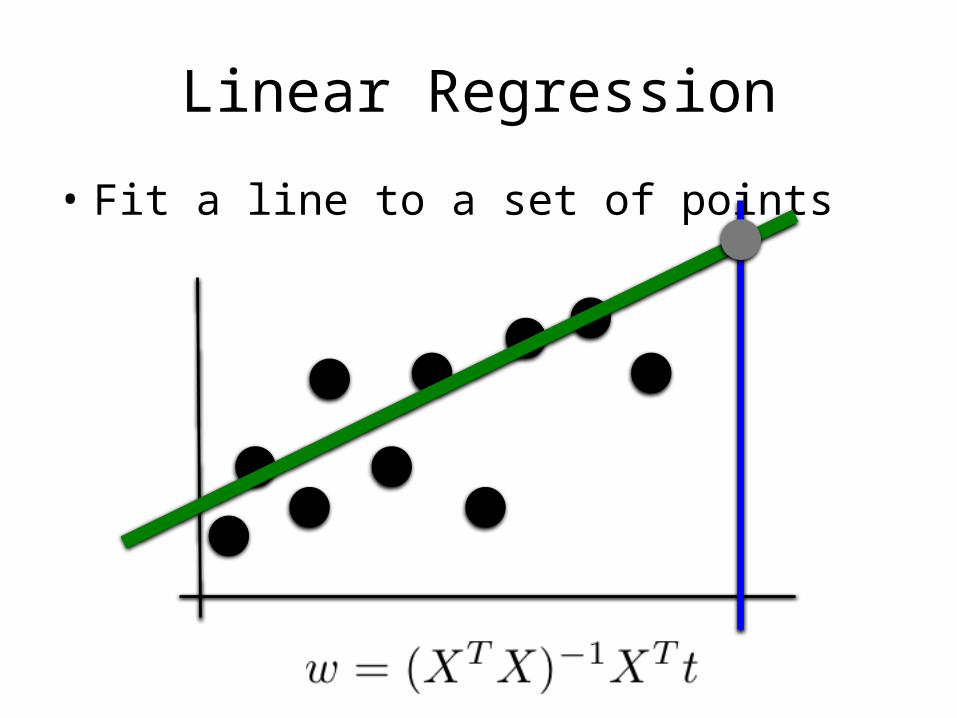
Linear Regression
• Fit a line to a set of points

Linear Regression
• Extension to higher dimensions– Polynomial fitting
– Arbitrary function fitting• Wavelets• Radial basis functions• Classifier output

Logistic Regression
• Fit gaussians to data for each class• The decision boundary is where the PDFs cross
• No “closed form” solution to the gradient.• Gradient Descent

Graphical Models
• General way to describe the dependence relationships between variables.
• Junction Tree Algorithm allows us to efficiently calculate marginals over any variable.

Junction Tree Algorithm
• Moralization– “Marry the parents”– Make undirected
• Triangulation– Remove cycles >4
• Junction Tree Construction– Identify separators such that the running intersection
property holds• Introduction of Evidence– Pass slices around the junction tree to generate marginals

Hidden Markov Models
• Sequential Modeling– Generative Model
• Relationship between observations and state (class) sequences

Perceptron
• Step function used for squashing.• Classifier as Neuron metaphor.

Perceptron Loss
• Classification Error vs. Sigmoid Error– Loss is only calculated on Mistakes
Perceptrons usestrictly classificationerror

Neural Networks
• Interconnected Layers of Perceptrons or Logistic Regression “neurons”

Neural Networks
• There are many possible configurations of neural networks– Vary the number of layers– Size of layers
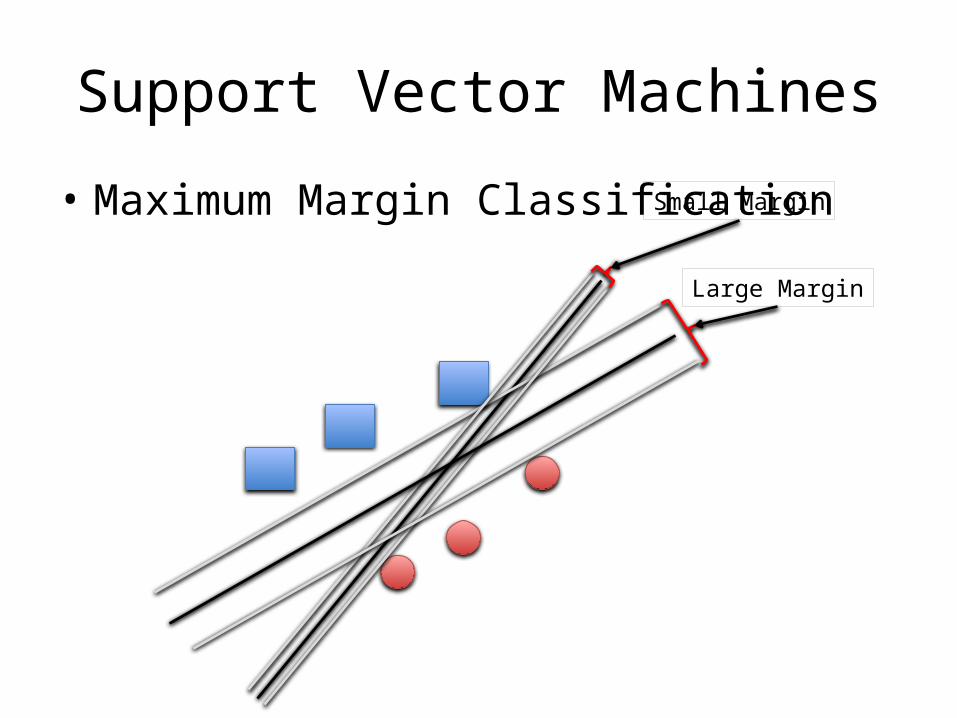
Support Vector Machines
• Maximum Margin Classification Small Margin
Large Margin

Support Vector Machines
• Optimization Function
• Decision Function

30
Visualization of Support Vectors

Questions?
• Now would be a good time to ask questions about Supervised Techniques.

Clustering
• Identify discrete groups of similar data points• Data points are unlabeled

Recall K-Means
• Algorithm– Select K – the desired number of clusters– Initialize K cluster centroids– For each point in the data set, assign it to the cluster
with the closest centroid
– Update the centroid based on the points assigned to each cluster
– If any data point has changed clusters, repeat

k-means output

Soft K-means
• In k-means, we force every data point to exist in exactly one cluster.
• This constraint can be relaxed.
Minimizes the entropy of cluster assignment

Soft k-means example

Soft k-means
• We still define a cluster by a centroid, but we calculate the centroid as the weighted mean of all the data points
• Convergence is based on a stopping threshold rather than changed assignments

Gaussian Mixture Models
• Rather than identifying clusters by “nearest” centroids
• Fit a Set of k Gaussians to the data.

GMM example

Gaussian Mixture Models
• Formally a Mixture Model is the weighted sum of a number of pdfs where the weights are determined by a distribution,

Graphical Modelswith unobserved variables
• What if you have variables in a Graphical model that are never observed?– Latent Variables
• Training latent variable models is an unsupervised learning application
laughing
amused
sweating
uncomfortable

Latent Variable HMMs
• We can cluster sequences using an HMM with unobserved state variables
• We will train the latent variable models using Expectation Maximization

Expectation Maximization
• Both the training of GMMs and Gaussian Models with latent variables are accomplished using Expectation Maximization– Step 1: Expectation (E-step)• Evaluate the “responsibilities” of each cluster with the
current parameters
– Step 2: Maximization (M-step)• Re-estimate parameters using the existing
“responsibilities”
• Related to k-means

Questions
• One more time for questions on supervised learning…

Next Time
• Gaussian Mixture Models (GMMs)• Expectation Maximization

















![Semi-supervised Learning with Ladder Networkspapers.nips.cc/...semi-supervised-learning-with-ladder-networks.pdf · Semi-Supervised Learning with Ladder Networks ... 3] or classification](https://static.documents.pub/doc/80x56/5af9e4237f8b9ae92b8cfd03/semi-supervised-learning-with-ladder-learning-with-ladder-networks-3-or-classication.jpg)