38
Lecture 8: Lecture 8: OpenMP OpenMP

Lecture 8:Lecture 8:
OpenMP OpenMP

Parallel Programming Models
Parallel Programming Models:
Data parallelism / Task parallelism Explicit parallelism / Implicit parallelism Shared memory / Distributed memory Other programming paradigms
• Object-oriented
• Functional and logic

Parallel Programming Models
Shared MemoryThe programmer’s task is to specify the activities of a set of processes that communicate by reading and writing shared memory. • Advantage: the programmer need not be concerned with data-distribution
issues. • Disadvantage: performance implementations may be difficult on computers
that lack hardware support for shared memory, and race conditions tend to arise more easily
Distributed MemoryProcesses have only local memory and must use some other mechanism (e.g., message passing or remote procedure call) to exchange information.• Advantage: programmers have explicit control over data distribution and
communication.
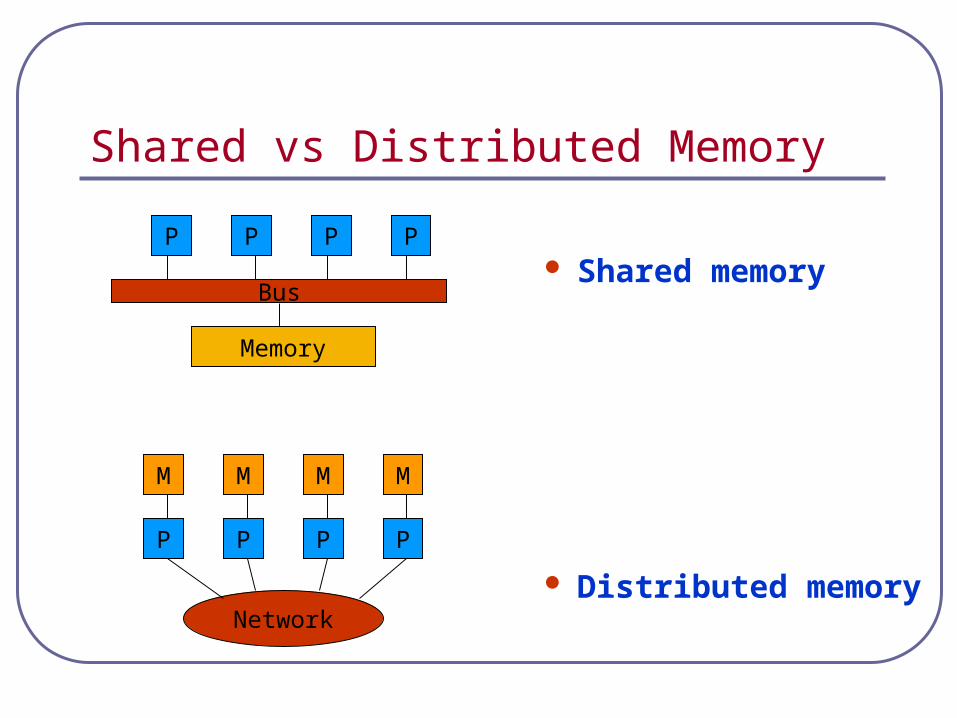
Shared vs Distributed Memory
Shared memory
Distributed memory
Memory
Bus
P P P P
P P P P
M M M M
Network

Parallel Programming Models
Parallel Programming Tools:
Parallel Virtual Machine (PVM)• Distributed memory, explicit parallelism
Message-Passing Interface (MPI)• Distributed memory, explicit parallelism
PThreads• Shared memory, explicit parallelism
OpenMP• Shared memory, explicit parallelism
High-Performance Fortran (HPF)• Implicit parallelism
Parallelizing Compilers• Implicit parallelism

Parallel Programming Models
Shared Memory Model
Used on Shared memory MIMD architectures
Program consists of many independent threads
Concurrently executing threads all share a single, common address space.
Threads can exchange information by reading and writing to memory using normal variable assignment operations
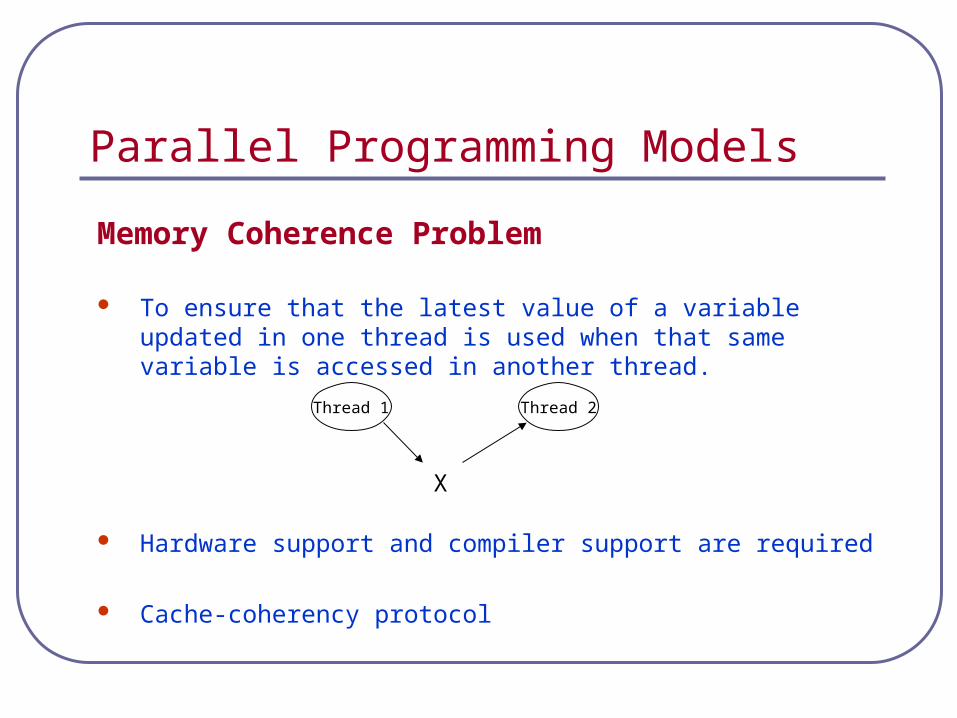
Parallel Programming Models
Memory Coherence Problem
To ensure that the latest value of a variable updated in one thread is used when that same variable is accessed in another thread.
Hardware support and compiler support are required
Cache-coherency protocol
Thread 1 Thread 2
X

Parallel Programming Models
Distributed Shared Memory (DSM) Systems
Implement Shared memory model on Distributed memory MIMD architectures
Concurrently executing threads all share a single, common address space.
Threads can exchange information by reading and writing to memory using normal variable assignment operations
Use a message-passing layer as the means for communicating updated values throughout the system.

Parallel Programming Models
Synchronization operations in Shared Memory Model
Monitors Locks Critical sections Condition variables Semaphores Barriers

OpenMP
OpenMP
www.openmp.org/

OpenMP
Shared-memory programming model Thread-based parallelism Fork/Join model Compiler directive based No support for parallel I/O
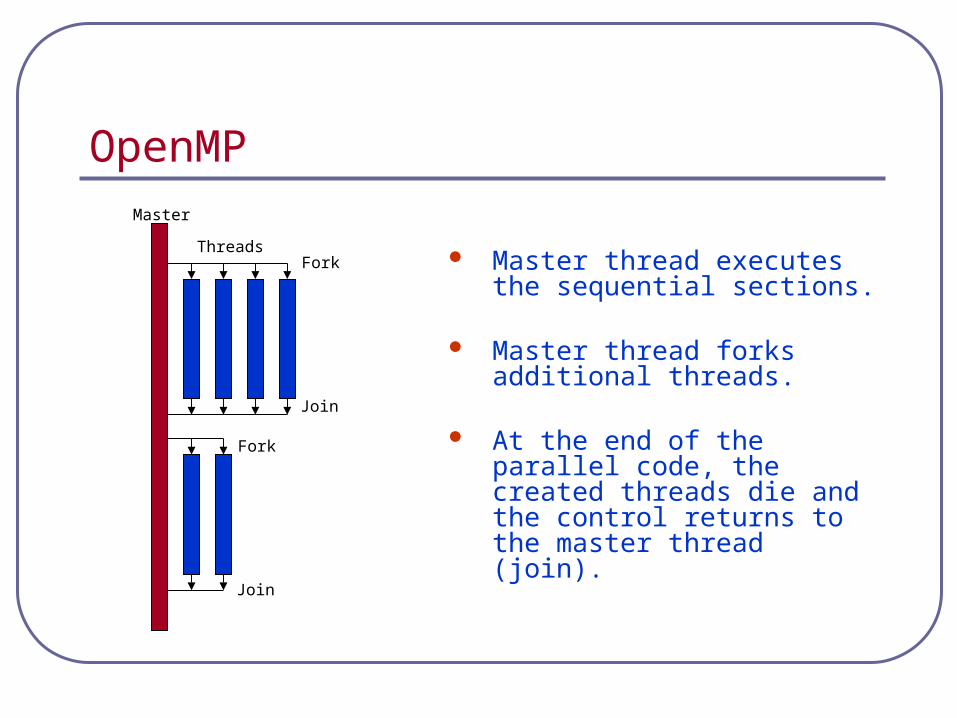
OpenMP
Master thread executes the sequential sections.
Master thread forks additional threads.
At the end of the parallel code, the created threads die and the control returns to the master thread (join).
Master
ThreadsFork
Join
Fork
Join

OpenMPGeneral Code Structure #include <omp.h> main () {
int var1, var2, var3;
Serial code . . .
Fork a team of threads. Specify variable scoping #pragma omp parallel private(var1, var2) shared(var3) {
Parallel section executed by all threads . . .
All threads join master thread and disband } Resume serial code . . . }

OpenMPGeneral Code Structure #include <omp.h> main () { int nthreads, tid;
#pragma omp parallel private(tid) /* Fork a team of threads */ {
tid = omp_get_thread_num(); printf("Hello World from thread = %d\n", tid);
if (tid == 0) { /* master thread */ nthreads = omp_get_num_threads(); printf("Number of threads = %d\n", nthreads);
} } /* All threads join master thread and terminate */ }

OpenMPparallel Directive
The execution of the code block after the parallel pragma is replicated among the threads.
#include <omp.h> main () { struct job_struct job_ptr;struct task_struct task_ptr;
#pragma omp parallel private(task_ptr) {
task_ptr = get_next_task(&job_ptr);while(task_ptr != NULL){
complete_task(task_ptr)task_ptr =
get_next_task(&job_ptr);}
}
}
job_ptr
task_ptr
task_ptrMaster tread Thread 1
Shared variables

OpenMP
parallel for Directive #include <omp.h>
main () { int i; float b[5];
#pragma omp parallel for{
for (i=0; i < 5; i++) b[i] = i;
}
}
b
i iMaster
Thread (0)Thread 1
In parallel for, variables are by default shared with the exception that the loop index variable is private.

OpenMP
Execution context: is an address space containing all of the variables the thread may access.
Shared variable: has the same address in the execution context of every thread
Private variable: has a different address in the execution context of every thread

OpenMP
private Clause declares variables in its list to be private to each thread
private (list)
#include <omp.h> main () { int i,n; float a[10][10];
n=10;#pragma omp parallel for \ private(j) {
for (i=0; i < n; i++) for (j=0; j < n; j++)
a[i][j] = a[i][j] + i; }
}

OpenMPcritical Directive Directs the compiler to enforce mutual exclusion among the threads
executing the block of code.
#include <omp.h>
main() {
int x;
x = 0;
#pragma omp parallel shared(x)
{
#pragma omp critical
x = x + 1;
} /* end of parallel section */
}

OpenMPreduction Directive
reduction (operator : variable)
#include <omp.h> main () { int i, n; float a, x, p; n=100;a=0.0; #pragma omp parallel for \ private(x) \ reduction(+:a) for (i=0; i < n; i++) {
x = i/10.0; a += x*x;
}
p = a/n;
}

OpenMP
reduction Operators
+ addition
- subtraction
* multiplication
& bitwise and
| bitwise or
^ bitwise exclusive or
&& conditional and
|| conditional or

OpenMP
Loop Scheduling: allows the iterations of a loop to be allocated to threads.
Static schedule: all iterations are allocated to threads before they execute any loop iterations.• Low overhead
• High load imbalance
Dynamic schedule: only some of the iterations are allocated to threads at the beginning of loop’s execution. Threads that complete their iterations are then eligible to get additional work. • Higher overhead
• Reduce load imbalance

OpenMP
schedule Clause schedule (type [, chunk])
type: static, dynamic, etc.chunk: number of contiguous iterations assigned to each
thread
Increasing chunk size can reduce overhead and increase cache hit rate.

OpenMP
schedule Clause #include <omp.h> main () { int i,n; float a[10];
n=10;#pragma omp parallel for \ private(i) \schedule(static,5){
for (i=0; i < n; i++) a[i] = a[i] + i;
}
}

OpenMP
schedule Directive #include <omp.h> #define CHUNKSIZE 100 #define N 1000 main () { int i, chunk; float a[N], b[N], c[N]; for (i=0; i < N; i++)
a[i] = b[i] = i * 1.0; chunk = CHUNKSIZE;
#pragma omp parallel shared(a,b,c,chunk) private(i) { /* iterations will be distributed dynamically in chunk sized pieces*/
#pragma omp for schedule(dynamic,chunk) nowait { for (i=0; i < N; i++)
c[i] = a[i] + b[i]; }
} /* end of parallel section */ }

OpenMPnowait Clause
tells the compiler to omit the barrier synchronization at the end of the parallel for loop
#include <omp.h> #define CHUNKSIZE 100 #define N 1000 main () { int i, chunk; float a[N], b[N], c[N]; for (i=0; i < N; i++)
a[i] = b[i] = i * 1.0; chunk = CHUNKSIZE;
#pragma omp parallel shared(a,b,c,chunk) private(i) {
#pragma omp for schedule(dynamic,chunk) nowait { for (i=0; i < N; i++)
c[i] = a[i] + b[i]; }
}}

OpenMPfor Directive
specifies that the iterations of the loop immediately following it must be executed in parallel by the team.
for (i=0; i < n; i++){
low=a[i];high=b[i];if (low > high) {
break;}for (j=low; j < high; j++)
c[j]=(c[j]-a[i])/b[i]; }
#pragma omp parallel private(i,j)for (i=0; i < n; i++){
low=a[i];high=b[i];if (low > high) {
break;}#pragma omp for for (j=low; j < high; j++)
c[j]=(c[j]-a[i])/b[i]; }

OpenMPsingle Directive
Specifies that the enclosed code is to be executed by only one thread in the team.Threads in the team that do not execute the single directive wait at the end of the enclosed code block
for (i=0; i < n; i++){
low=a[i];high=b[i];if (low > high) {
break;}for (j=low; j < high; j++)
c[j]=(c[j]-a[i])/b[i]; }
#pragma omp parallel private(i,j)for (i=0; i < n; i++){
low=a[i];high=b[i];if (low > high) {
#pragma omp singlebreak;
}#pragma omp forfor (j=low; j < high; j++)
c[j]=(c[j]-a[i])/b[i]; }
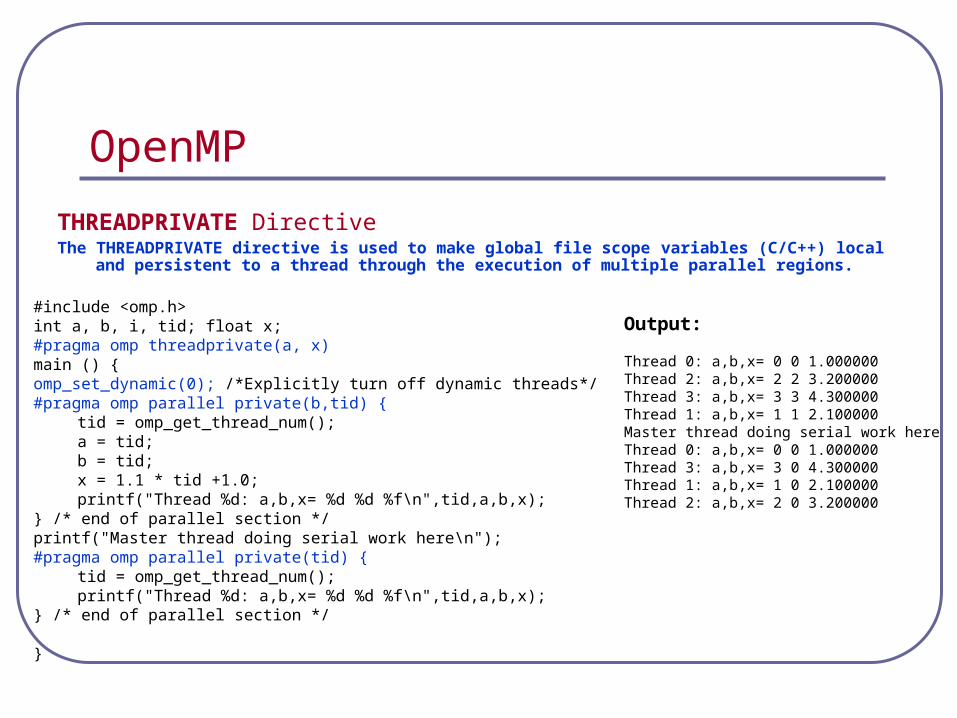
OpenMP
#include <omp.h> int a, b, i, tid; float x; #pragma omp threadprivate(a, x) main () { omp_set_dynamic(0); /*Explicitly turn off dynamic threads*/ #pragma omp parallel private(b,tid) {
tid = omp_get_thread_num(); a = tid; b = tid; x = 1.1 * tid +1.0; printf("Thread %d: a,b,x= %d %d %f\n",tid,a,b,x);
} /* end of parallel section */ printf("Master thread doing serial work here\n"); #pragma omp parallel private(tid) {
tid = omp_get_thread_num(); printf("Thread %d: a,b,x= %d %d %f\n",tid,a,b,x);
} /* end of parallel section */
}
Output:
Thread 0: a,b,x= 0 0 1.000000 Thread 2: a,b,x= 2 2 3.200000 Thread 3: a,b,x= 3 3 4.300000 Thread 1: a,b,x= 1 1 2.100000 Master thread doing serial work here Thread 0: a,b,x= 0 0 1.000000 Thread 3: a,b,x= 3 0 4.300000 Thread 1: a,b,x= 1 0 2.100000 Thread 2: a,b,x= 2 0 3.200000
THREADPRIVATE Directive The THREADPRIVATE directive is used to make global file scope variables (C/C++) local and
persistent to a thread through the execution of multiple parallel regions.

OpenMPparallel sections Directive – Functional Parallelism
Specifies that the enclosed section(s) of code are to be divided among the threads in the team to be evaluated concurrently.
#include <omp.h> main () { ...#pragma omp parallel sections {
#pragma omp section /* thread 1 */v = alpha(); #pragma omp section /* thread 2 */w = beta();#pragma omp section /* thread 3 */y = delta();
} /* end of parallel section */ x = gamma(v,w);printf(“%f\n”, epsilon(x,y));}
}

OpenMPparallel sections Directive – Functional Parallelism
Another solution:main () { ...#pragma omp parallel{
#pragma omp sections {
#pragma omp section /* thread 1 */v = alpha(); #pragma omp section /* thread 2 */w = beta();
}#pragma omp sections {
#pragma omp section /* thread 3 */x = gamma(v,w); #pragma omp section /* thread 4 */y = delta();
}} /* end of parallel section */ printf(“%f\n”, epsilon(x,y));}}

OpenMPsection Directive #include <omp.h> #define N 1000 main () { int i; float a[N], b[N], c[N], d[N]; for (i=0; i < N; i++) {
a[i] = i * 1.5; b[i] = i + 22.35;
}#pragma omp parallel shared(a,b,c,d) private(i) {
#pragma omp sections nowait {
#pragma omp section for (i=0; i < N; i++)
c[i] = a[i] + b[i]; #pragma omp section for (i=0; i < N; i++)
d[i] = a[i] * b[i]; } /* end of sections */
} /* end of parallel section */ }

OpenMP
Synchronization constructs:
master directive: specifies a region that is to be executed only by the master thread of the team
critical directive: specifies a region of code that must be executed by only one thread at a time
barrier directive: synchronizes all threads in the team
atomic directive: specifies that a specific memory location must be updates atomically (a mini critical section)

OpenMP
barrier Directive #pragma omp barrier
... ;
atomic Directive #pragma omp atomic
... ;

OpenMP
Run-time Library Routines omp_set_num_threads(void): Sets the number of threads that
will be used in the next parallel region omp_get_num_threads(void): Returns the number of threads
that are currently executing the parallel region omp_get_thread_number(void): Returns the thread number omp_get_num_procs(void): Returns the number of processors omp_in_parallel(void): used to determine if the section of code
is parallel or not
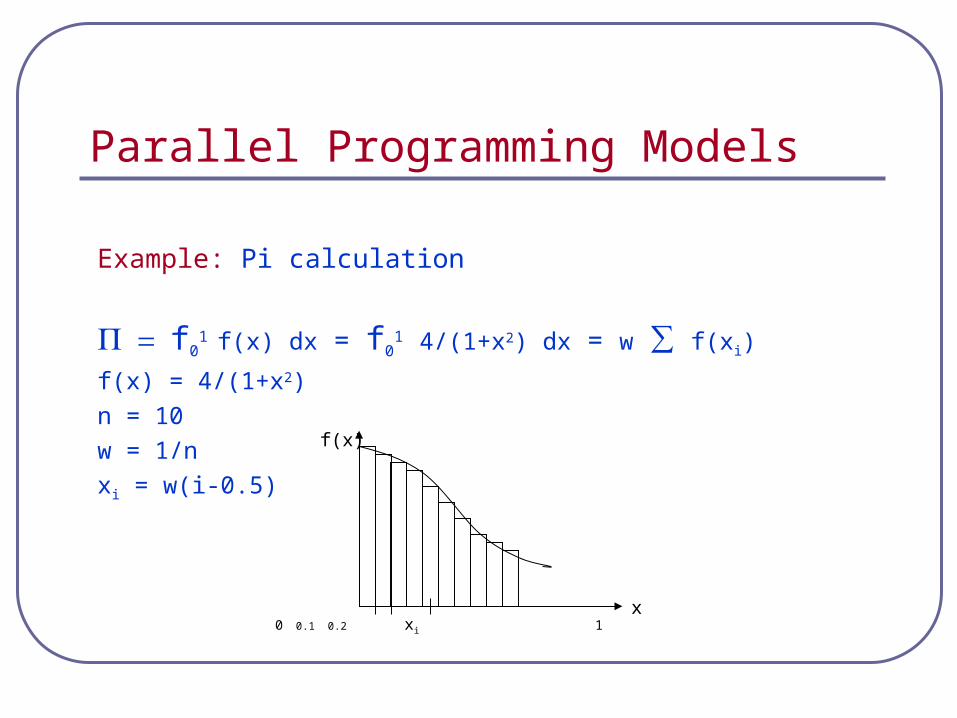
Parallel Programming Models
Example: Pi calculation
f01 f(x) dx = f0
1 4/(1+x2) dx = w ∑ f(xi)
f(x) = 4/(1+x2)
n = 10
w = 1/n
xi = w(i-0.5)
x
f(x)
0 0.1 0.2 xi 1
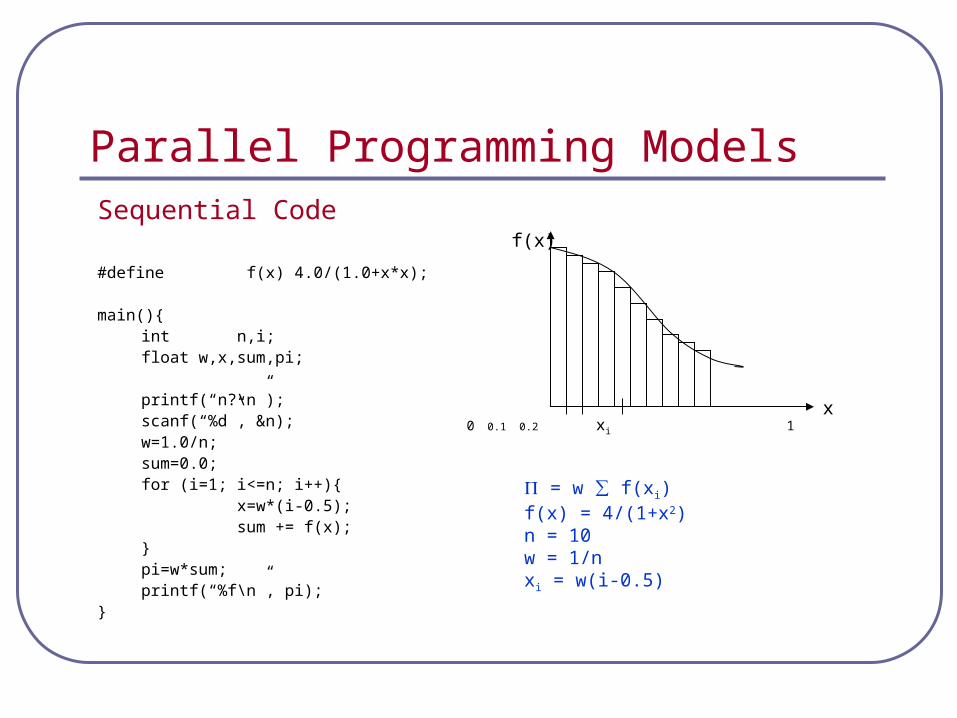
Parallel Programming ModelsSequential Code
#define f(x) 4.0/(1.0+x*x);
main(){int n,i;float w,x,sum,pi;
printf(“n?\n”);scanf(“%d”, &n);w=1.0/n;sum=0.0;for (i=1; i<=n; i++){
x=w*(i-0.5);sum += f(x);
}pi=w*sum;printf(“%f\n”, pi);
}
= w ∑ f(xi) f(x) = 4/(1+x2) n = 10 w = 1/nxi = w(i-0.5)
x
f(x)
0 0.1 0.2 xi 1
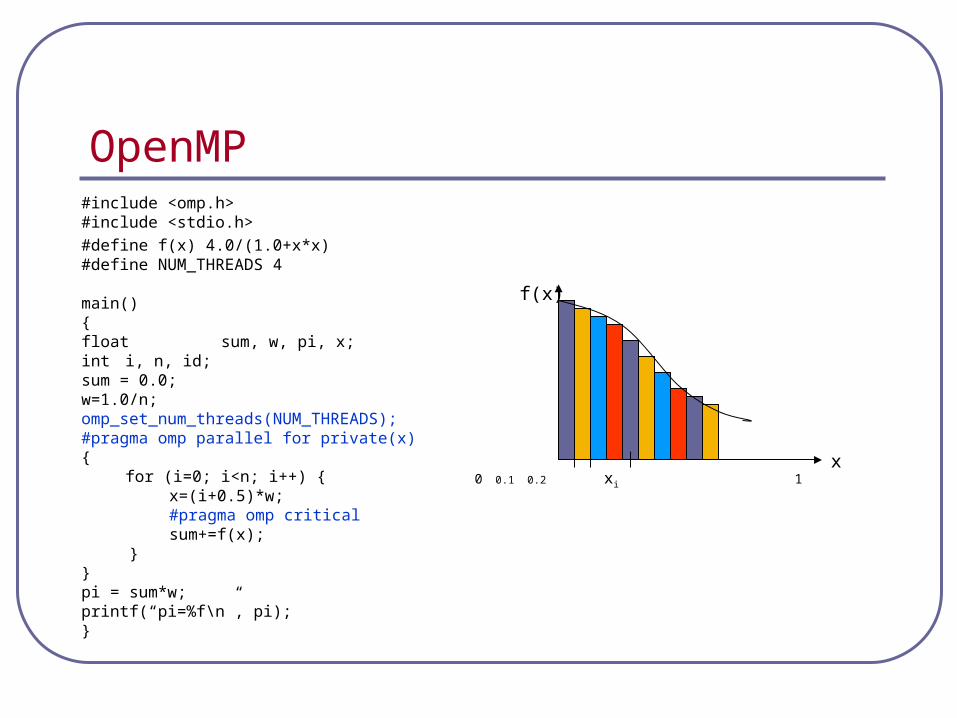
OpenMP#include <omp.h> #include <stdio.h>
#define f(x) 4.0/(1.0+x*x)#define NUM_THREADS 4
main() { float sum, w, pi, x;int i, n, id;sum = 0.0;w=1.0/n; omp_set_num_threads(NUM_THREADS);#pragma omp parallel for private(x) {
for (i=0; i<n; i++) {x=(i+0.5)*w;#pragma omp critical
sum+=f(x);}
}pi = sum*w;printf(“pi=%f\n”, pi);}
x
f(x)
0 0.1 0.2 xi 1

















