34
Lecture 9: Hidden Markov Model Kai-Wei Chang CS @ University of Virginia [email protected] Couse webpage: http://kwchang.net/teaching/NLP16 1 CS6501 Natural Language Processing

Lecture 9: Hidden Markov Model
Kai-Wei ChangCS @ University of Virginia
Couse webpage: http://kwchang.net/teaching/NLP16
1CS6501 Natural Language Processing

This lecture
vHidden Markov ModelvDifferent views of HMMvHMM in supervised learning setting
2CS6501 Natural Language Processing

CS6501 Natural Language Processing 3
Recap: Parts of Speech
vTraditional parts of speechv~ 8 of them

CS6501 Natural Language Processing 4
Recap: Tagset
vPenn TreeBank tagset”, 45 tags: vPRP$, WRB, WP$, VBGvPenn POS annotations:
The/DT grand/JJ jury/NN commmented/VBD on/IN a/DT number/NN of/IN other/JJ topics/NNS ./.
vUniversal Tag set, 12 tagsv NOUN, VERB, ADJ, ADV, PRON, DET, ADP, NUM,
CONJ, PRT, “.”, X

CS6501 Natural Language Processing 5
Recap: POS Tagging v.s. Word clustering
vWords often have more than one POS: backvThe back door = JJvOn my back = NNvWin the voters back = RBvPromised to back the bill = VB
vSyntax v.s. Semantics (details later)
These examples from Dekang Lin

Recap: POS tag sequences
vSome tag sequences more likely occur than others
vPOS Ngram viewhttps://books.google.com/ngrams/graph?content=_ADJ_+_NOUN_%2C_ADV_+_NOUN_%2C+_ADV_+_VERB_
CS6501 Natural Language Processing 6
ExistingmethodsoftenmodelPOStaggingasasequencetagging problem

Evaluation
vHow many words in the unseen test data can be tagged correctly?
vUsually evaluated on Penn TreebankvState of the art ~97% vTrivial baseline (most likely tag) ~94%vHuman performance ~97%
CS6501 Natural Language Processing 7
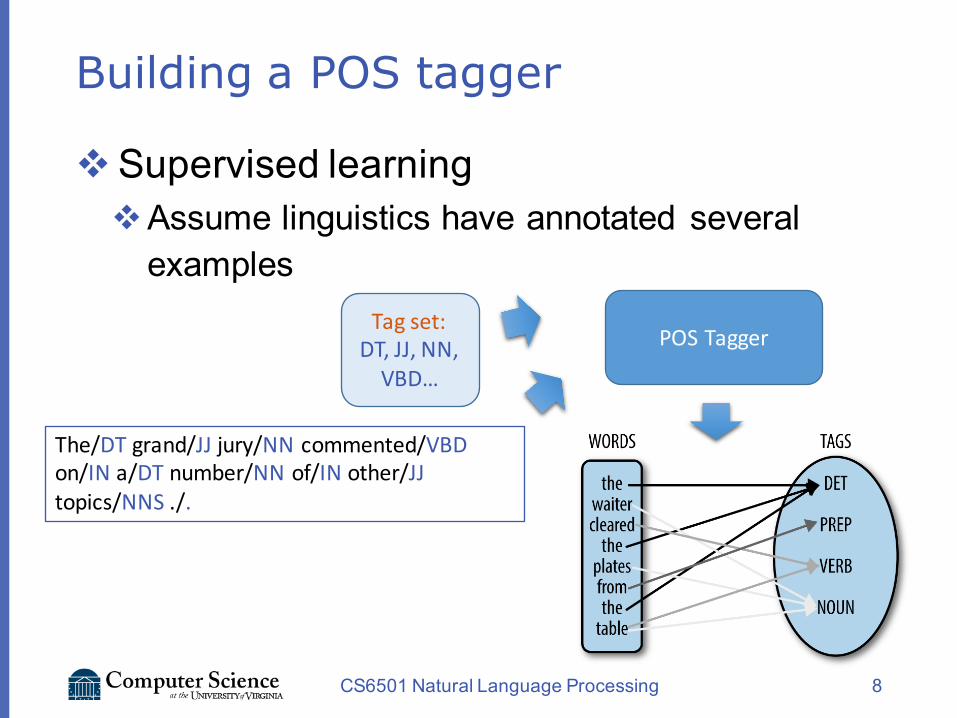
Building a POS tagger
vSupervised learningvAssume linguistics have annotated several
examples
CS6501 Natural Language Processing 8
The/DT grand/JJjury/NN commented/VBDon/INa/DT number/NN of/IN other/JJtopics/NNS ./.
Tag set:DT,JJ,NN,VBD…
POSTagger
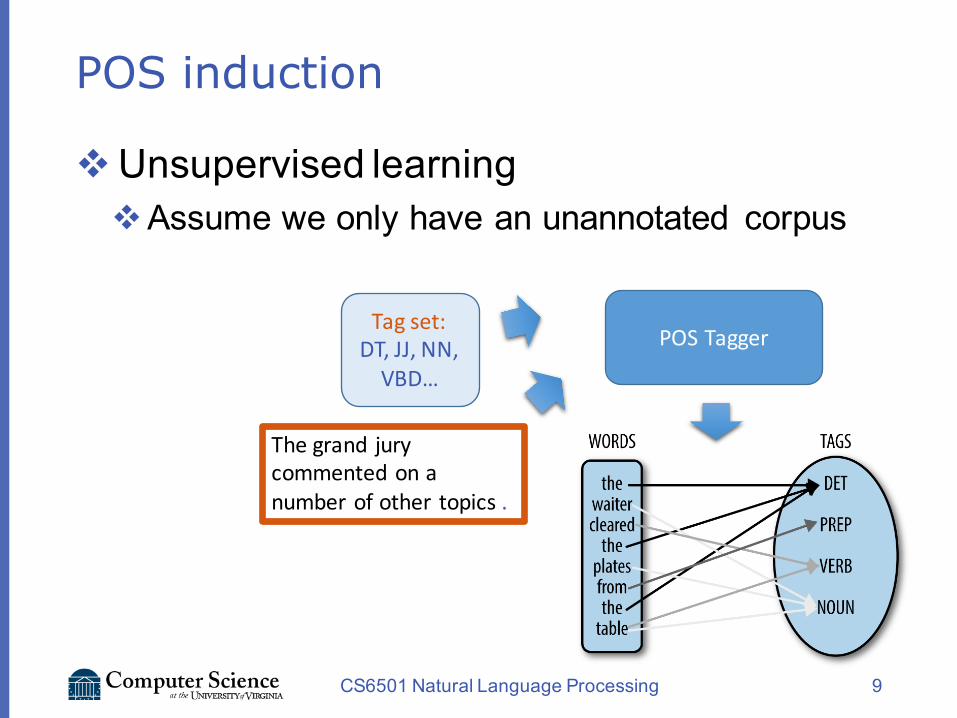
POS induction
vUnsupervised learningvAssume we only have an unannotated corpus
CS6501 Natural Language Processing 9
Thegrand jurycommentedon anumberofother topics.
Tag set:DT,JJ,NN,VBD…
POSTagger

TODAY: Hidden Markov Model
vWe focus on supervised learning setting vWhat is the most likely sequence of tags
for the given sequence of words w
vWe will talk about other ML models for this type of prediction tasks later.
CS6501 Natural Language Processing 10

Let’s try
a/DT d6g/NN 0s/VBZ chas05g/VBG a/DTcat/NN ./.
a/DT f6x/NN0s/VBZ9u5505g/VBG./.
a/DT b6y/NN0s/VBZ s05g05g/VBG ./.a/DT ha77y/JJ b09d/NN
What is the POS tag sequence of the following sentence?
a ha77y cat was s05g05g .
CS6501 Natural Language Processing 11
Don’tworry!Thereisnoproblemwithyoureyesorcomputer.

Let’s try
v a/DT d6g/NN 0s/VBZ chas05g/VBG a/DTcat/NN ./.a/DT dog/NN is/VBZ chasing/VBG a/DT cat/NN ./.
v a/DT f6x/NN 0s/VBZ 9u5505g/VBG ./.a/DT fox/NN is/VBZ running/VBG ./.
v a/DT b6y/NN 0s/VBZ s05g05g/VBG ./.a/DT boy/NN is/VBZ singing/VBG ./.
v a/DT ha77y/JJ b09d/NNa/DT happy/JJ bird/NN
v a ha77y cat was s05g05g .
a happy cat was singing .
CS6501 Natural Language Processing 12

How you predict the tags?
vTwo types of information are usefulvRelations between words and tagsvRelations between tags and tags
v DT NN, DT JJ NN…
CS6501 Natural Language Processing 13

Statistical POS tagging
vWhat is the most likely sequence of tags for the given sequence of words w
CS6501 Natural Language Processing 14
P(DTJJNN|asmartdog)= P(DDJJNNasmartdog)/P(asmartdog)∝ P(DDJJNNasmartdog)= P(DDJJNN)P(asmartdog|DDJJNN)

Transition Probability
v Joint probability 𝑃(𝒕,𝒘) = 𝑃 𝒕 𝑃(𝒘|𝒕)v𝑃 𝒕 = 𝑃 𝑡+, 𝑡,, … 𝑡.
= 𝑃 𝑡+ 𝑃 𝑡, ∣ 𝑡+ 𝑃 𝑡1 ∣ 𝑡,, 𝑡+ …𝑃 𝑡. 𝑡+ … 𝑡.2+∼ P t+ P t, 𝑡+ 𝑃 𝑡1 𝑡, …𝑃(𝑡. ∣ 𝑡.2+)= Π78+. 𝑃 𝑡7 ∣ 𝑡72+
v Bigram model over POS tags!(similarly, we can define a n-gram model over POS tags, usually we called high-order HMM)
CS6501 Natural Language Processing 15
Markovassumption

Emission Probability
v Joint probability 𝑃(𝒕,𝒘) = 𝑃 𝒕 𝑃(𝒘|𝒕)vAssumewordsonlydependontheirPOS-tagv𝑃 𝒘 𝒕 ∼ 𝑃 𝑤+ 𝑡+ 𝑃 𝑤, 𝑡, …𝑃(𝑤. ∣ 𝑡.)= Π78+. 𝑃 𝑤7 𝑡7
i.e., P(a smart dog | DD JJ NN )= P(a | DD) P(smart | JJ ) P( dog | NN )
CS6501 Natural Language Processing 16
Independentassumption

Put them together
v Joint probability 𝑃(𝒕,𝒘) = 𝑃 𝒕 𝑃(𝒘|𝒕)v 𝑃 𝒕,𝒘
= P t+ P t, 𝑡+ 𝑃 𝑡1 𝑡, …𝑃 𝑡. 𝑡.2+𝑃 𝑤+ 𝑡+ 𝑃 𝑤, 𝑡, …𝑃(𝑤. ∣ 𝑡.)
= Π78+. 𝑃 𝑤7 𝑡7 𝑃 𝑡7 ∣ 𝑡72+e.g., P(a smart dog , DD JJ NN )
= P(a | DD) P(smart | JJ ) P( dog | NN )
P(DD | start) P(JJ | DD) P(NN | JJ )
CS6501 Natural Language Processing 17
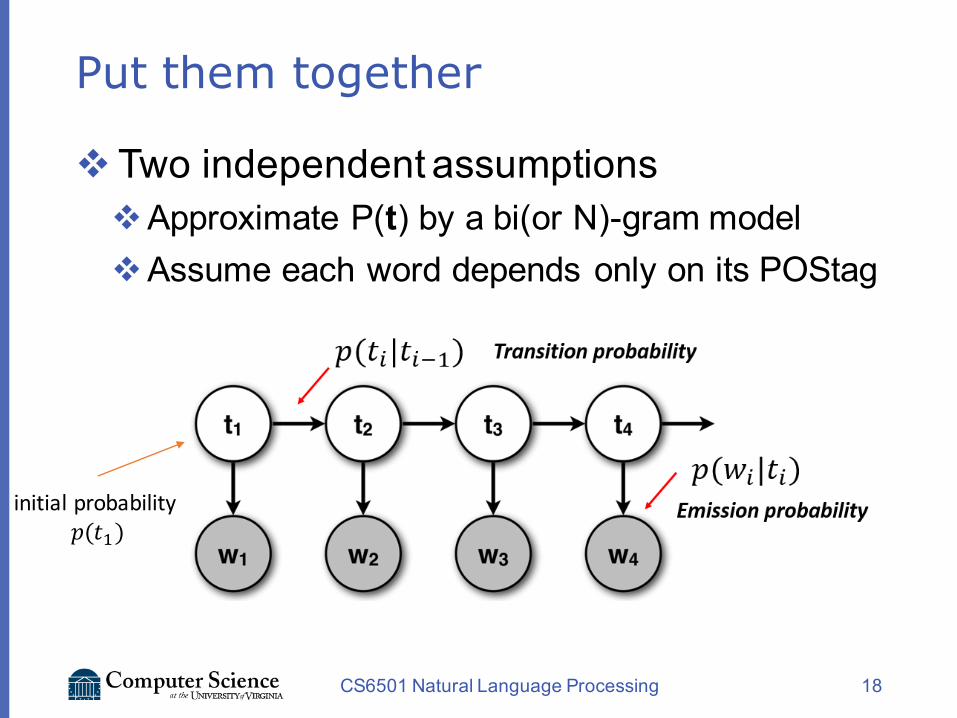
Put them together
vTwo independent assumptionsvApproximate P(t) by a bi(or N)-gram model vAssume each word depends only on its POStag
CS6501 Natural Language Processing 18
initialprobability𝑝(𝑡+)
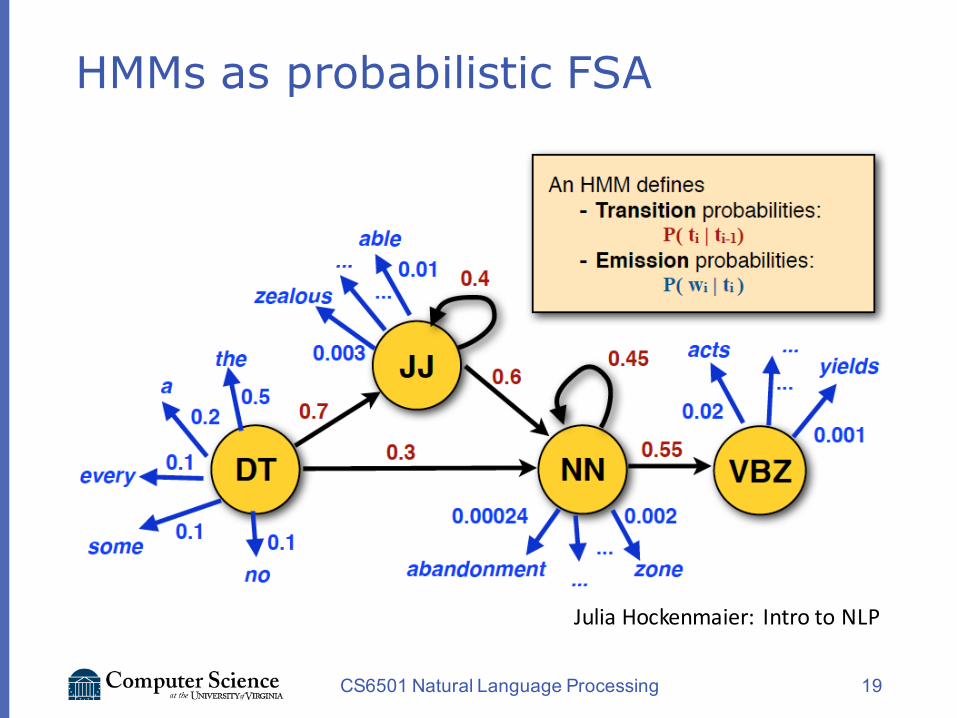
HMMs as probabilistic FSA
CS6501 Natural Language Processing 19
JuliaHockenmaier: IntrotoNLP
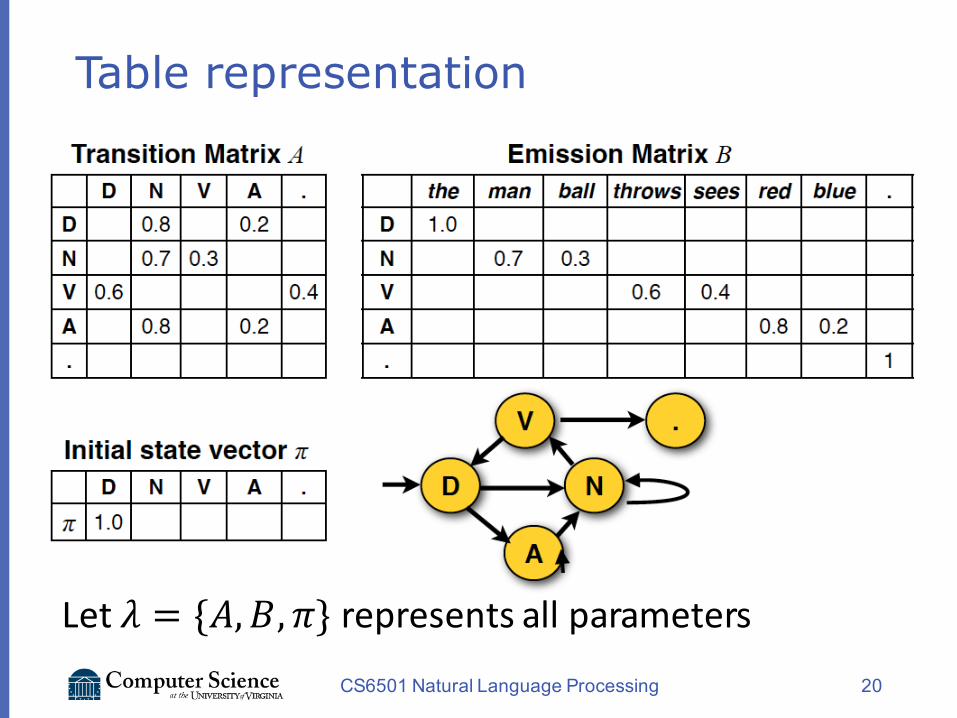
Table representation
CS6501 Natural Language Processing 20
Let𝜆 = {𝐴, 𝐵, 𝜋} representsallparameters

21
v States T = t1, t2…tN;
v Observations W= w1, w2…wN; v Each observation is a symbol from a vocabulary V =
{v1,v2,…vV}v Transition probabilities
v Transition probability matrix A = {aij}
v Observation likelihoodsv Output probability matrix B={bi(k)}
v Special initial probability vector π
Hidden Markov Models (formal)
𝑎7V = 𝑃 𝑡7 = 𝑗 𝑡72+ = 𝑖 1 ≤ 𝑖, 𝑗 ≤ 𝑁
𝑏7(𝑘) = 𝑃 𝑤7 = 𝑣_ 𝑡7 = 𝑖
𝜋7 = 𝑃 𝑡+ = 𝑖 1 ≤ 𝑖 ≤ 𝑁CS6501 Natural Language Processing

How to build a second-order HMM?
vSecond-order HMMvTrigram model over POS tagsv𝑃 𝒕 = Π78+. 𝑃 𝑡7 ∣ 𝑡72+, 𝑡72,v𝑃 𝒘, 𝒕 = Π78+. 𝑃 𝑡7 ∣ 𝑡72+, 𝑡72, 𝑃(𝑤7 ∣ 𝑡7)
CS6501 Natural Language Processing 22
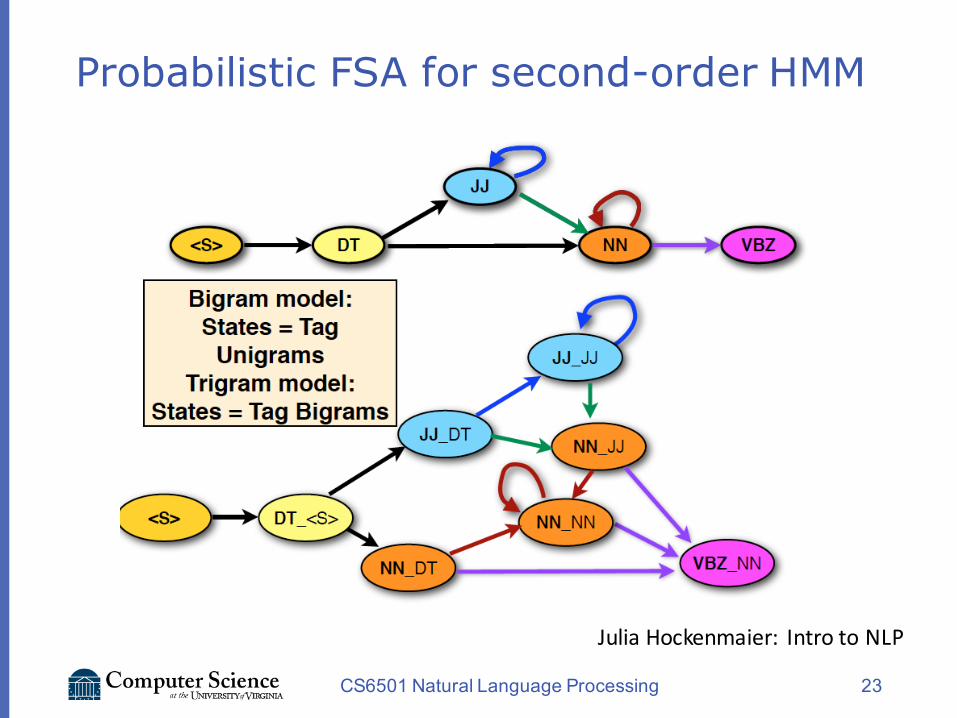
Probabilistic FSA for second-order HMM
CS6501 Natural Language Processing 23
JuliaHockenmaier: IntrotoNLP
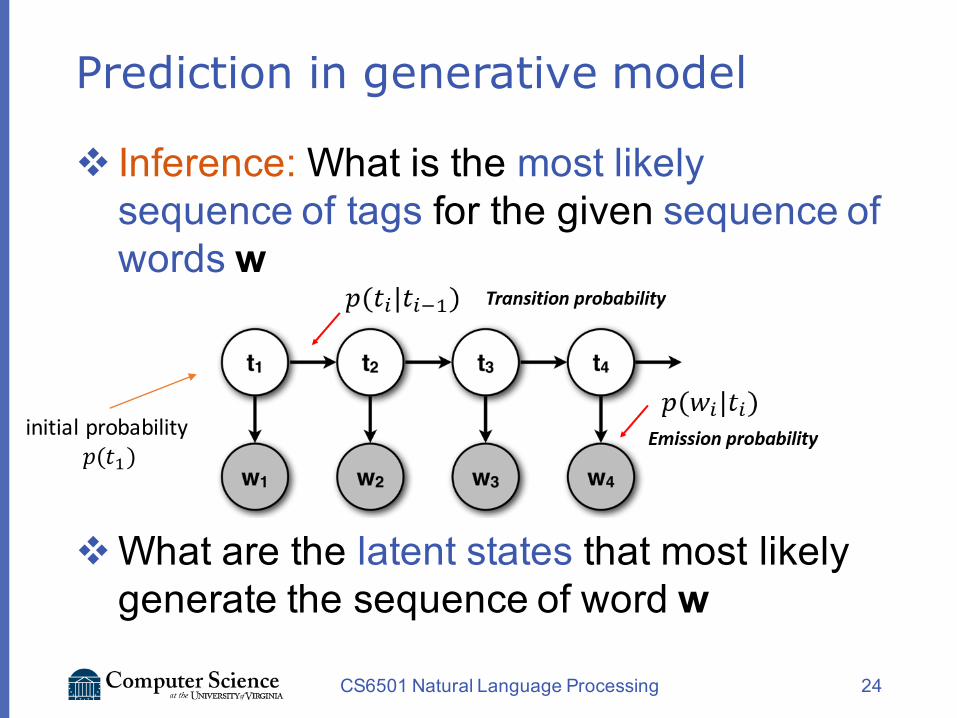
Prediction in generative model
v Inference: What is the most likely sequence of tags for the given sequence of words w
vWhat are the latent states that most likely generate the sequence of word w
CS6501 Natural Language Processing 24
initialprobability𝑝(𝑡+)

CS6501 Natural Language Processing 25
Example: The Verb “race”
vSecretariat/NNP is/VBZ expected/VBN to/TO race/VB tomorrow/NR
vPeople/NNS continue/VB to/TO inquire/VBthe/DT reason/NN for/IN the/DT race/NN for/INouter/JJ space/NN
vHow do we pick the right tag?
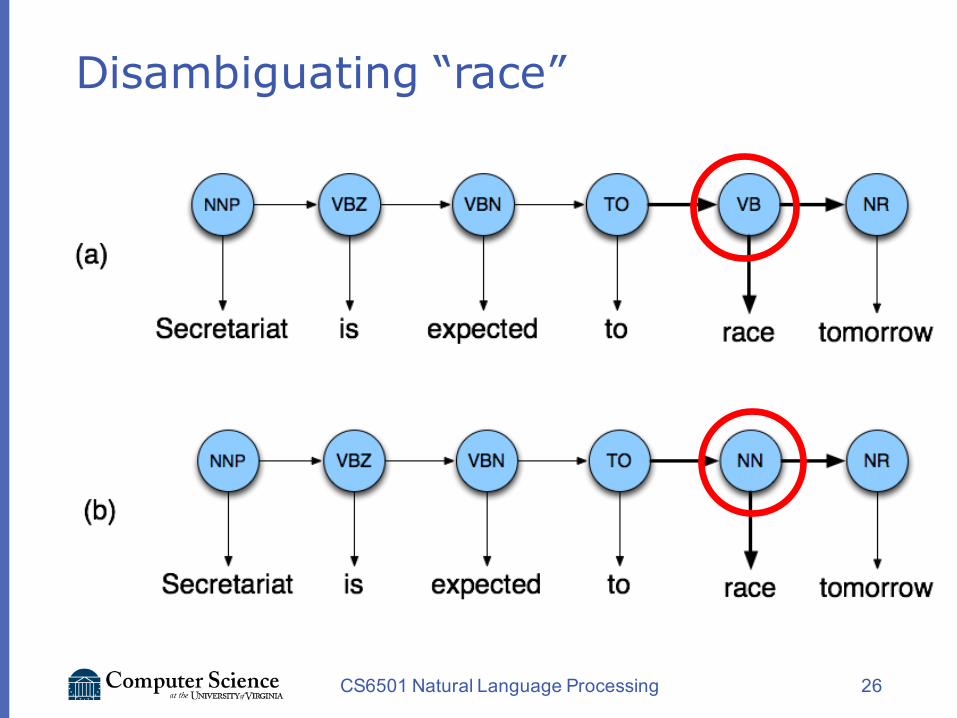
26
Disambiguating “race”
CS6501 Natural Language Processing

27
Disambiguating “race”
v P(NN|TO) = .00047v P(VB|TO) = .83v P(race|NN) = .00057v P(race|VB) = .00012v P(NR|VB) = .0027v P(NR|NN) = .0012v P(VB|TO)P(NR|VB)P(race|VB) = .00000027v P(NN|TO)P(NR|NN)P(race|NN)=.00000000032v So we (correctly) choose the verb reading,
CS6501 Natural Language Processing

28
Jason and his Ice Creams
vYou are a climatologist in the year 2799vStudying global warmingvYou can’t find any records of the weather in
Baltimore, MA for summer of 2007vBut you find Jason Eisner’s diaryvWhich lists how many ice-creams Jason
ate every date that summervOur job: figure out how hot it was
http://videolectures.net/hltss2010_eisner_plm/http://www.cs.jhu.edu/~jason/papers/eisner.hmm.xls
CS6501 Natural Language Processing
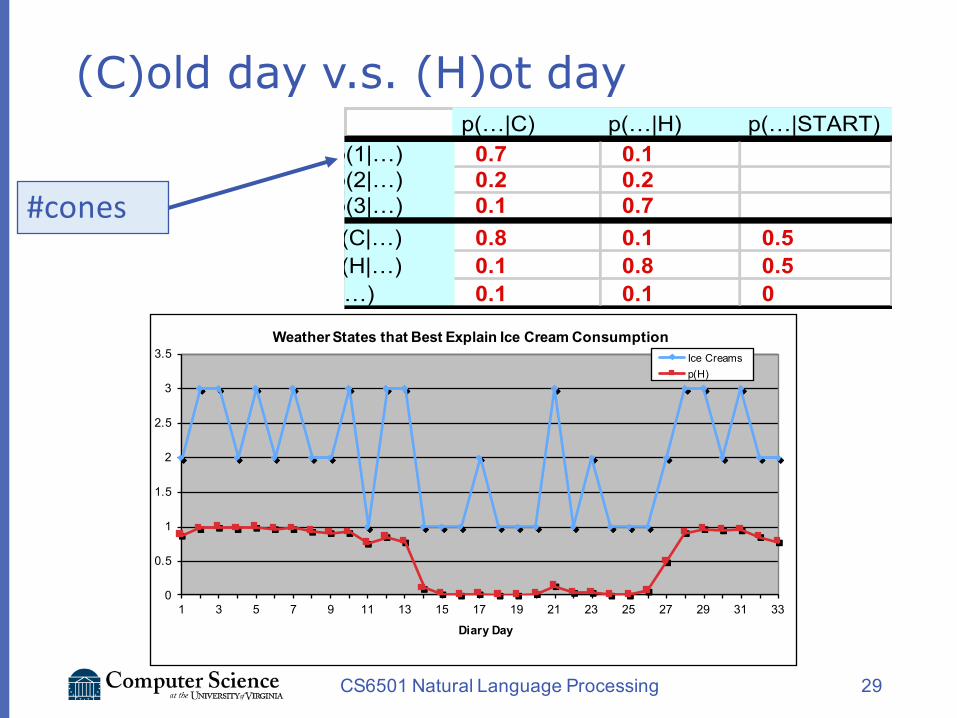
(C)old day v.s. (H)ot day
CS6501 Natural Language Processing 29
p(…|C) p(…|H) p(…|START)p(1|…) 0.7 0.1p(2|…) 0.2 0.2p(3|…) 0.1 0.7p(C|…) 0.8 0.1 0.5p(H|…) 0.1 0.8 0.5
p(STOP|…) 0.1 0.1 0
Scroll to the bottom to see a graph of what states and transitions the model thinks are likely on each day. Those likely states and transitions can be used to reestimate the red probabilities (this is the "forward-backward" or Baum-Welch algorithm), increasing the likelihood of the
#cones
0
0.5
1
1.5
2
2.5
3
3.5
1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33
Diary Day
Weather States that Best Explain Ice Cream ConsumptionIce Creamsp(H)

Three basic problems for HMMs
vLikelihood of the input:vCompute 𝑃(𝒘 ∣ 𝜆) for the input 𝒘 and HMM 𝜆
vDecoding (tagging) the input:vFind the best tag sequence
𝑎𝑟𝑔𝑚𝑎𝑥d𝑃(𝒕 ∣ 𝒘, 𝜆)
vEstimation (learning):vFind the best model parameters
v Case 1: supervised – tags are annotatedv Case 2: unsupervised -- only unannotated text
CS6501 Natural Language Processing 30
Howlikelythesentence”Ilovecat”occurs
POStagsof”Ilovecat”occurs
Howtolearnthemodel?

Three basic problems for HMMs
vLikelihood of the input:vForward algorithm
vDecoding (tagging) the input:vViterbi algorithm
vEstimation (learning):vFind the best model parameters
v Case 1: supervised – tags are annotatedvMaximum likelihood estimation (MLE)
v Case 2: unsupervised -- only unannotated textvForward-backward algorithm
CS6501 Natural Language Processing 31
Howlikelythesentence”Ilovecat”occurs
POStagsof”Ilovecat”occurs
Howtolearnthemodel?

Three basic problems for HMMs
vLikelihood of the input:vForward algorithm
vDecoding (tagging) the input:vViterbi algorithm
vEstimation (learning):vFind the best model parameters
v Case 1: supervised – tags are annotatedvMaximum likelihood estimation (MLE)
v Case 2: unsupervised -- only unannotated textvForward-backward algorithm
CS6501 Natural Language Processing 32
Howlikelythesentence”Ilovecat”occurs
POStagsof”Ilovecat”occurs
Howtolearnthemodel?

Learning from Labeled Data
v Let play a game!
vWe count how often we see 𝑡72+𝑡7 and we𝑡7then normalize.
CS6501 Natural Language Processing 33

Three basic problems for HMMs
vLikelihood of the input:vForward algorithm
vDecoding (tagging) the input:vViterbi algorithm
vEstimation (learning):vFind the best model parameters
v Case 1: supervised – tags are annotatedvMaximum likelihood estimation (MLE)
v Case 2: unsupervised -- only unannotated textvForward-backward algorithm
CS6501 Natural Language Processing 34
Howlikelythesentence”Ilovecat”occurs
POStagsof”Ilovecat”occurs
Howtolearnthemodel?
Weneeddynamicprogrammingfortheotherproblems

















