123


Mark TownsendDirector, Product Managementfor
Bryn LlewellynPL/SQL Product Manager
Oracle Corporation

Less Pain, More GainUse the new PL/SQL featuresin Oracle9i Database
to get better programsby writing fewer code lines
paper #30720, OracleWorld, Copenhagen, Tue 25-June-2002

But before I start…But before I start…

OTN homepageOTN homepage
TechnologiesTechnologies
PL/SQLPL/SQL
otn.oracle.com/tech/pl_sqlotn.oracle.com/tech/pl_sql

9.2.0 Enhancements
This presentation focuses on enhancements introduced in Oracle9i Database Release 2We’ll refer to this as Version 9.2.0 for brevityMajor enhancements were also introduced in Oracle9i Database Release 1We’ll refer to that as Version 9.0.1This succeded the last release of Oracle8iWe’ll refer to that as Version 8.1.7

Recap of 9.0.1 Enhancements
Some of you will be upgrading directlyfrom Version 8.1.7 to Version 9.2.0You’ll get PL/SQL benefits that go way beyond what’s discussed todayThe new Version 9.0.1 featurestogether with the new Version 9.2.0 featuresallow you to writesignificantly faster PL/SQL applicationswith dramatically fewer lines of code

Recap of 9.0.1 Enhancements
Native compilationCursor expressions;Table functions;Multilevel collections;Exception handling in bulk binding DML operations;Bulk binding in native dynamic SQLCASE statements and CASE expressions

Recap of 9.0.1 Enhancements
VARCHAR2 <-> NVARCHAR2 (etc) assignment;VARCHAR2 <-> CLOB assignment;SUBSTR and INSTR w/ CLOB;Seamless access to new SQL features (eg MERGE, multitable insert, new time datatypes)OO:Schema evolution, inheritance supportUtl_Http, Utl_Raw, Utl_File enhancedNineteen new packages

Recap of 9.0.1 EnhancementsManipulating records faster by up to 5x;Inter-package calls faster by up to 1.5x;Utl_Tcp native implementation(underlies Utl_Http, Utl_Smtp)
Common SQL parser

Summary of 9.2.0 Enhancements
Index-by-varchar2 tables,aka associative arrays
RECORD binds in DML andin BULK SELECTs
Utl_File enhancements
GUI debugging via JDeveloper Version 9.0.3

Associative arrays
declaretype word_list is table of varchar2(20)index by varchar2(20);
the_list word_list;beginthe_list ( 'book' ) := livre;the_list ( 'tree' ) := 'arbre';
end;

Associative arrays
idx varchar2(20);.../* loop in lexical sort order */idx := the_list.First();while idx is not nullloopShow ( idx || ' : ' || the_list(idx) );idx := the_list.Next(idx);
end loop;

Associative arraysThese three flavors of index-by tables are now supported …
– index by binary_integer– index by pls_integer– index by varchar2
the term associative array is now usedfor all these variants in line withcommon usage in other 3GLs

Lookup caching scenario
Req't to look up a value via a uniquenon-numeric key is generic computational problemOracle9i Database provides a solution with SQL and a B*-tree index (!)But performance improvement by using an explicit PL/SQL implementationTrue even before the new index-by-varchar2 table

Lookup caching scenario
Scenarios characterized by very frequent lookup in a relatively small set of values, usually in connection with flattening a relational representation for reportingor for UI presentationWe'll use a simple neutral scenario
(not to complicate the following examples with distracting detail)

Lookup caching scenarioselect * from translations;ENGLISH FRENCH-------------------- ----------computer ordinateurtree arbre...furniture meubles
Allow lookup from French to EnglishAllow efficient addition of newvocabulary pairs

The Vocab packageWe’ll abstract the solution as a package...
package Vocab isfunction Lookup (p_english in varchar2)return varchar2;
procedure New_Pair (p_english in varchar2,p_french in varchar2);
end Vocab;

The Vocab packageMust support...
beginShow ( Vocab.Lookup ( 'tree' ) );...Vocab.New_Pair ( 'garden', 'jardin' );Show ( Vocab.Lookup ( 'garden' ) );
end;

package body Vocab is
/* Naïve pure SQL approach */
function Lookup ( p_english in varchar2 ) return varchar2isv_french translations.french%type;
beginselect french into v_french from translations
where english = p_english;return v_french;
end;...
end Vocab;

package body Vocab is
/* Naïve pure SQL approach */
...procedure New_Pair ( p_english in varchar2, p_french in varchar2 ) isbegininsert into translations ( english, french )values ( p_english, p_french );
end New_Pair;end Vocab;

Naïve pure SQLConcerned only about correctness of behavior and ease of algorithm designAccept the performance we getEach time Lookup is invoked, we make a round trip between PL/SQL and SQLThis frequently repeated context switch can become significantly expensive
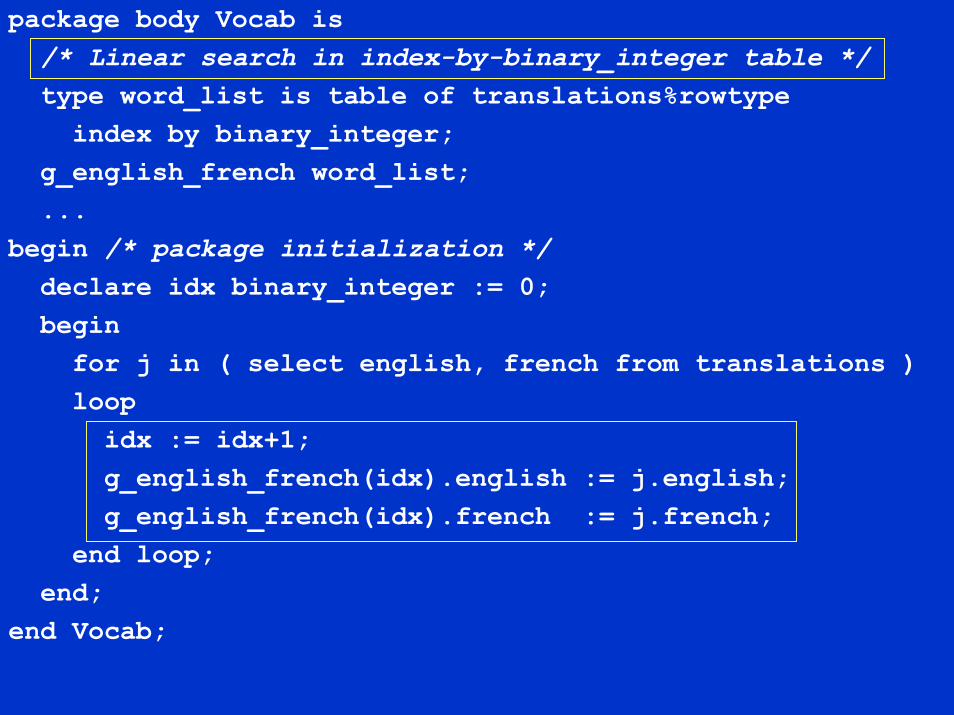
package body Vocab is/* Linear search in index-by-binary_integer table */type word_list is table of translations%rowtype
index by binary_integer;g_english_french word_list;...
begin /* package initialization */declare idx binary_integer := 0;begin
for j in ( select english, french from translations )loop
idx := idx+1;g_english_french(idx).english := j.english;g_english_french(idx).french := j.french;
end loop;end;
end Vocab;
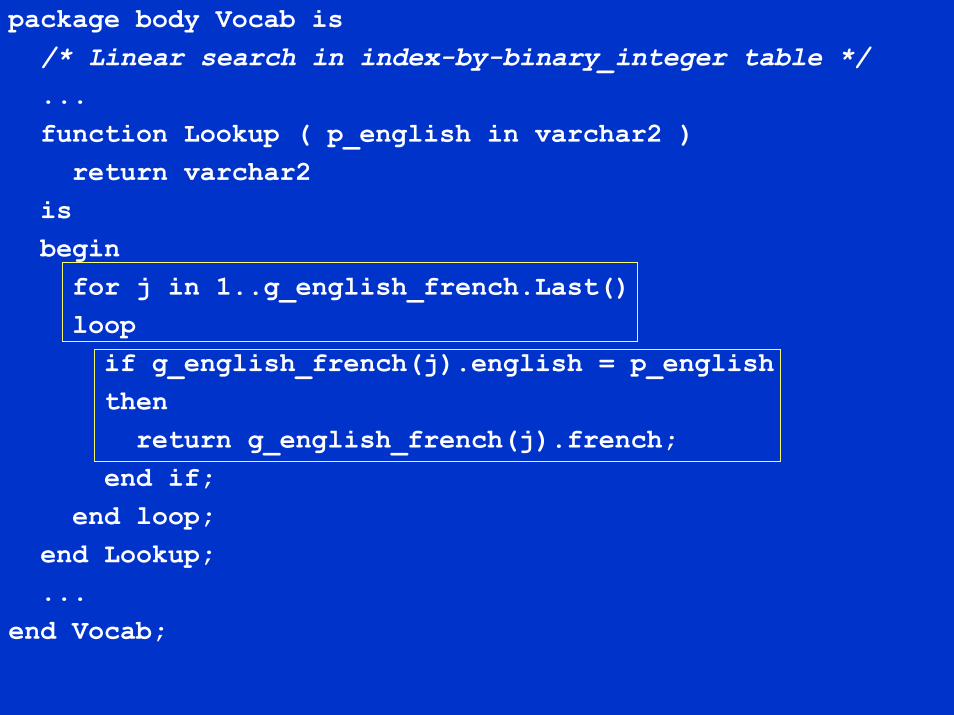
package body Vocab is/* Linear search in index-by-binary_integer table */...function Lookup ( p_english in varchar2 )
return varchar2isbegin
for j in 1..g_english_french.Last()loop
if g_english_french(j).english = p_englishthen
return g_english_french(j).french;end if;
end loop;end Lookup;...
end Vocab;

package body Vocab is/* Linear search in index-by-binary_integer table */...procedure New_Pair (
p_english in varchar2, p_french in varchar2 )is
idx binary_integer;begin
idx := g_english_french.Last() + 1;g_english_french(idx).english := p_english;g_english_french(idx).french := p_french;insert into translations ( english, french )
values ( p_english, p_french );end New_Pair;...
end Vocab;

Linear search in index-by-binary_integer table
Algorithm is still trivial, but does require some explicit codingThe entire table contents are loaded into an index-by-binary_integer tableWell-known disadvantage that on average half the elements are examined before we find a match

Binary chop search in index-by-binary_integer table
Possible improvement: maintain the elements in lexical sort orderCompare the search target to the half-way element to determine which half it's inRepeat this test recursively on the relevant half

Binary chop search in index-by-binary_integer table
Requires more elaborate coding - and testingPoses a design problem for the New_PairprocedureEither the array must be opened at the insertion point copying all later elements to the next slotOr it must be created sparse

Binary chop search in index-by-binary_integer table
Neither of these approaches is very comfortableThe sparse alternative is not complete until we cater for the corner case where a gapfills up
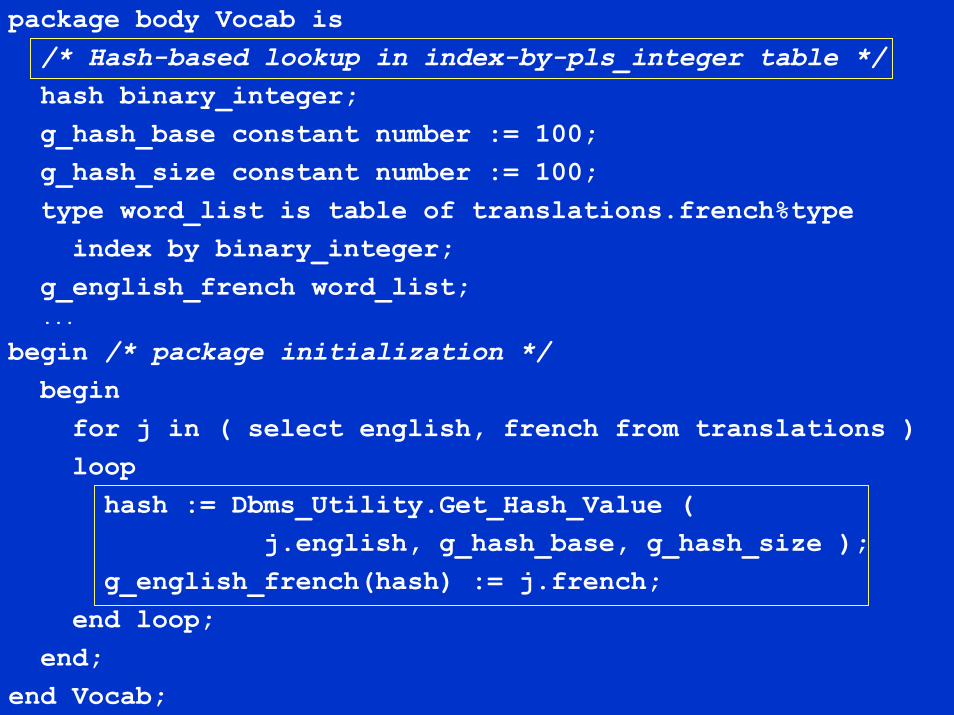
package body Vocab is/* Hash-based lookup in index-by-pls_integer table */hash binary_integer;g_hash_base constant number := 100;g_hash_size constant number := 100;type word_list is table of translations.french%type
index by binary_integer;g_english_french word_list;...
begin /* package initialization */begin
for j in ( select english, french from translations )loop
hash := Dbms_Utility.Get_Hash_Value (j.english, g_hash_base, g_hash_size );
g_english_french(hash) := j.french;end loop;
end;end Vocab;

package body Vocab is/* Hash-based lookup in index-by-pls_integer table */...function Lookup ( p_english in varchar2 )
return varchar2 isbegin
hash := Dbms_Utility.Get_Hash_Value (p_english, g_hash_base, g_hash_size );
return g_english_french(hash);end Lookup;...
end Vocab;
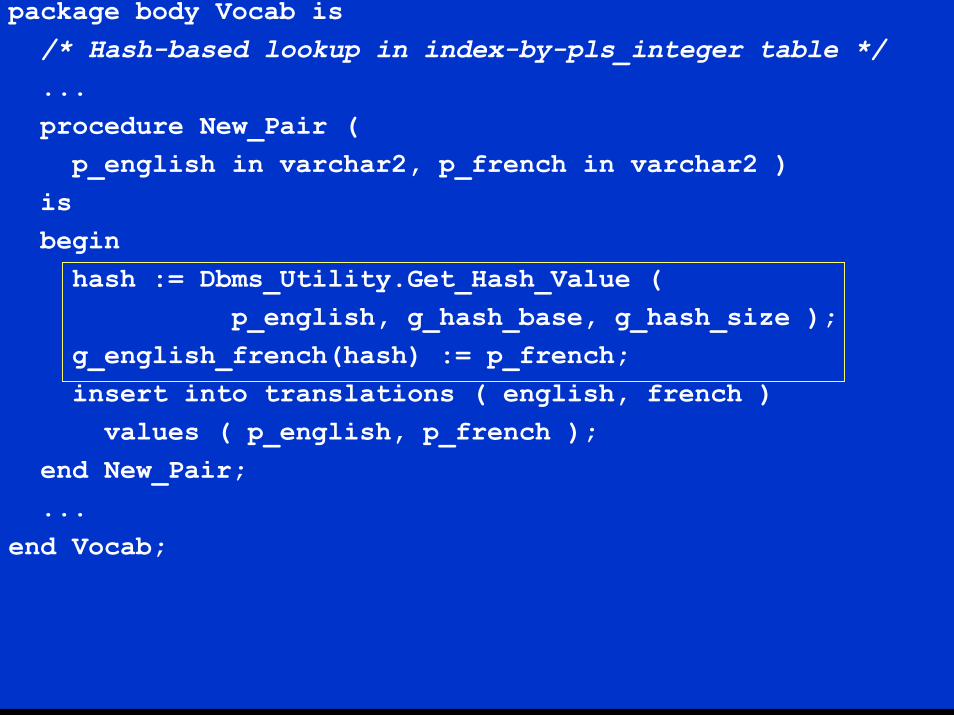
package body Vocab is/* Hash-based lookup in index-by-pls_integer table */...procedure New_Pair (
p_english in varchar2, p_french in varchar2 )isbegin
hash := Dbms_Utility.Get_Hash_Value (p_english, g_hash_base, g_hash_size );
g_english_french(hash) := p_french;insert into translations ( english, french )
values ( p_english, p_french );end New_Pair;...
end Vocab;

Hash-based lookup in index-by-binary_integer table
The algorithm as shown is too naïve for real-world useNo guarantee that two distinct values for the nameIN parameter to Get_Hash_Value will always produce distinct hash valuesTo be robust, a collision avoidance scheme must be implemented

Hash-based lookup in index-by-binary_integer table
Oracle provides no specific support for collision avoidance in Get_Hash_ValueSolving this is a non-trivial design, implementation and testing taskProbable that the resulting index-by-binary_integertable will be quite sparseWill discuss this later

Purpose-built B*-tree structurein PL/SQL
Study the relevant computer science textbooksImplement a B*-tree structure in PL/SQL, horror of wheel re-invention notwithstanding!Very far from trivial - certainly too long and complex for inclusion hereBut at 9.20, we don’t need to entertain that uncomfortable thought: Oracle does this for us behind the scenes !
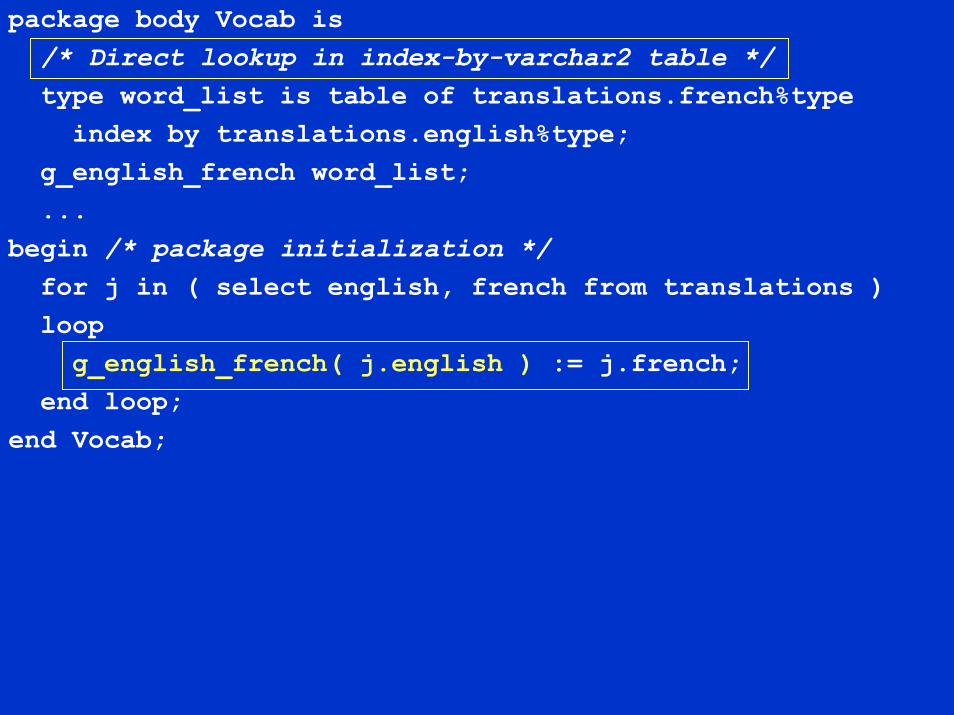
package body Vocab is/* Direct lookup in index-by-varchar2 table */type word_list is table of translations.french%type
index by translations.english%type;g_english_french word_list;...
begin /* package initialization */for j in ( select english, french from translations )loop
g_english_french( j.english ) := j.french;end loop;
end Vocab;
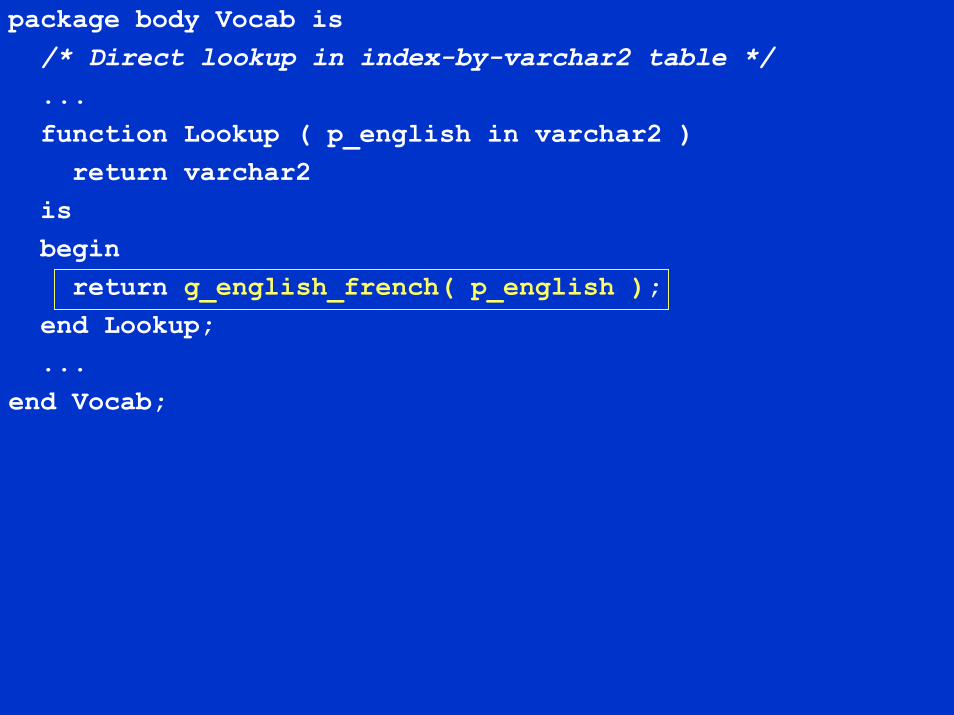
package body Vocab is/* Direct lookup in index-by-varchar2 table */...function Lookup ( p_english in varchar2 )
return varchar2isbegin
return g_english_french( p_english );end Lookup;...
end Vocab;
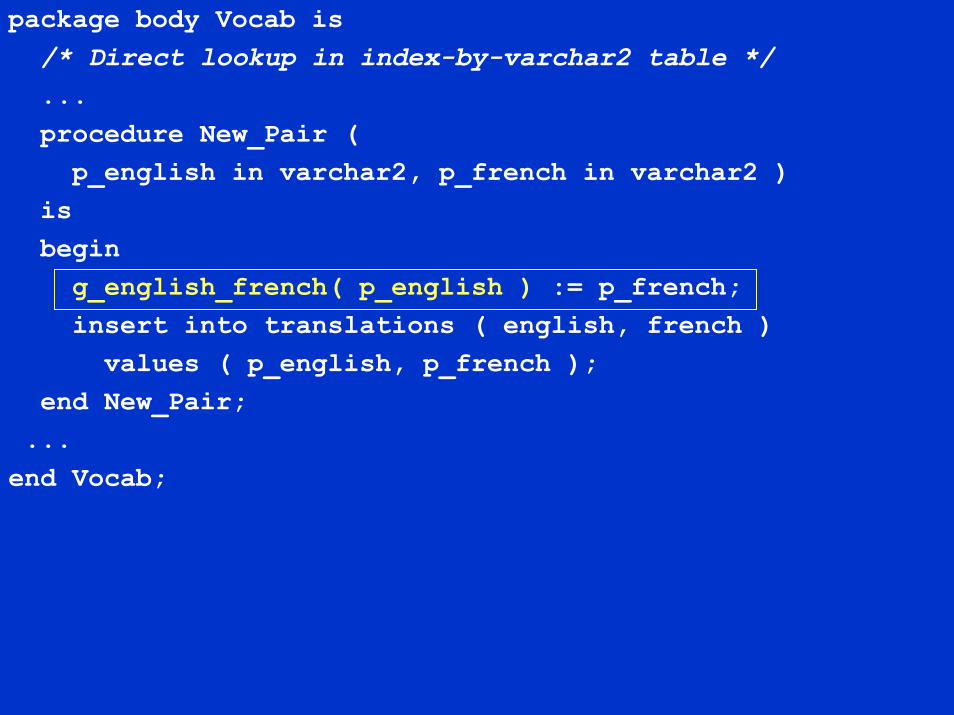
package body Vocab is/* Direct lookup in index-by-varchar2 table */...procedure New_Pair (
p_english in varchar2, p_french in varchar2 )isbegin
g_english_french( p_english ) := p_french;insert into translations ( english, french )
values ( p_english, p_french );end New_Pair;
...end Vocab;

Direct lookup in index-by-varchar2 table
Use precisely the B*-tree organization of the values but to do so implicitly via the new language featureCan think of the index-by-varchar2 table as the in-memory PL/SQL version of the schema-level index organized table

index-by-varchar2 table Optimized for efficiency of lookup on a non-numeric keyNotion of sparseness is not really applicableindex-by-*_integer table (now *_integer can be either pls_integer or binary_integer) is optimized for compactness of storage on the assumption that the data is densesometimes better to represent numeric key as a index-by-varchar2 table via a To_Char conversion

Associative arrays: summaryindex-by-varchar2 table is a major enhancementAllows a class of very common programming tasks to be implemented …
– much more performantly than was possible pre Version 9.2.0
– with very much less design and testing– in dramatically fewer lines of code

Associative arrays: summaryindex-by-pls_integer table is a minor enhancement that allows a clear coding guideline for all new projects
– never use BINARY_INTEGER except where it's required to match the type in an existing API

Summary of 9.2.0 EnhancementsIndex-by-varchar2 tables,aka associative arrays
RECORD binds in DML andin BULK SELECTs
Utl_File enhancements
GUI debugging via JDeveloper Version 9.0.3

RECORD bindsPL/SQL RECORD datatype corresponds to a row in a schema-level tableNatural construct when manipulating table rows programmatically, especially when a row from one table is manipulated programmatically, and then stored (via INSERT or UPDATE) in an another table with the same shape

RECORD bindsDeclaration is compact, using mytable%rowtypeGuaranteed to match the corresponding schema-level templateImmune to schema-level changes in definition of the shape of the tableRECORD can be used as subprogram parameter giving compact and guaranteed correct notation and allowing optimizations in the implementation of parameter passing

RECORD bindsSQL-PL/SQL interface allows a syntax which does not list the columns of the source/target table explicitlyAgain allowing for robust code which has a greater degree of schema-independence

RECORD bindsReduce effort of writing the codeIncrease the chances of its correctness
But... use of RECORDs in the SQL-PL/SQL interface was greatly restricted pre Version 9.2.0Supported only for single row SELECT
Thus... the listed advantages were not yet capable of being realized

RECORD bindsVersion 9.2.0 adds support for BULK SELECT in both Static and Native Dynamic SQLie full support for all flavors of SELECTAdds support (with some minor restrictions) for all Static SQL flavors of INSERT, DELETE and UPDATE
– INSERT– DELETE ... RETURNING– UPDATE ... RETURNING– UPDATE ... SET ROW
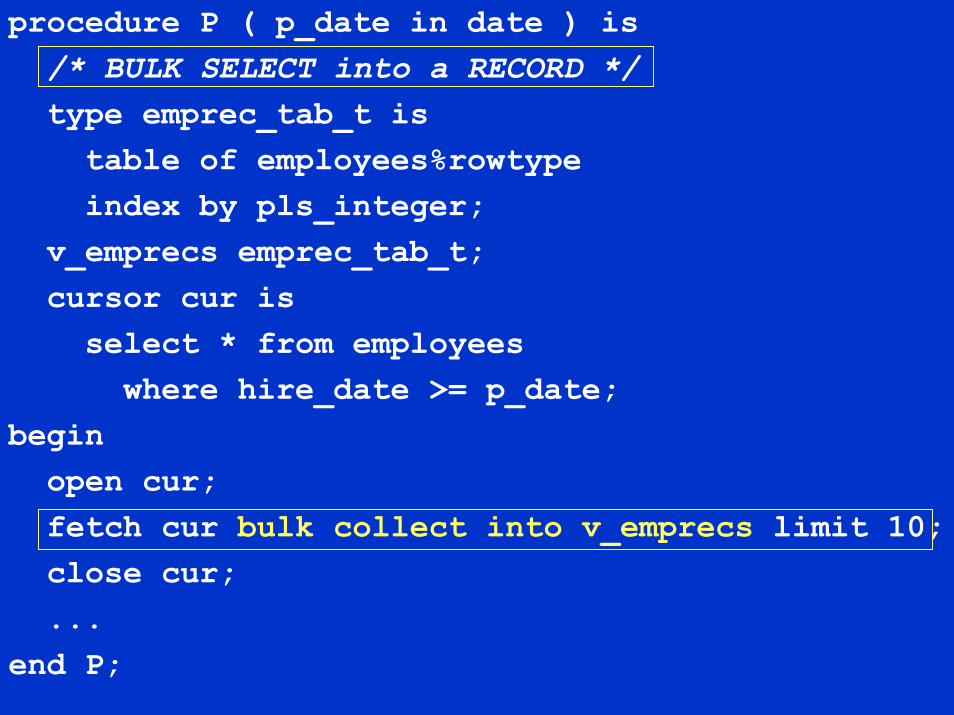
procedure P ( p_date in date ) is/* BULK SELECT into a RECORD */type emprec_tab_t istable of employees%rowtypeindex by pls_integer;
v_emprecs emprec_tab_t;cursor cur isselect * from employeeswhere hire_date >= p_date;
beginopen cur;fetch cur bulk collect into v_emprecs limit 10;close cur;...
end P;
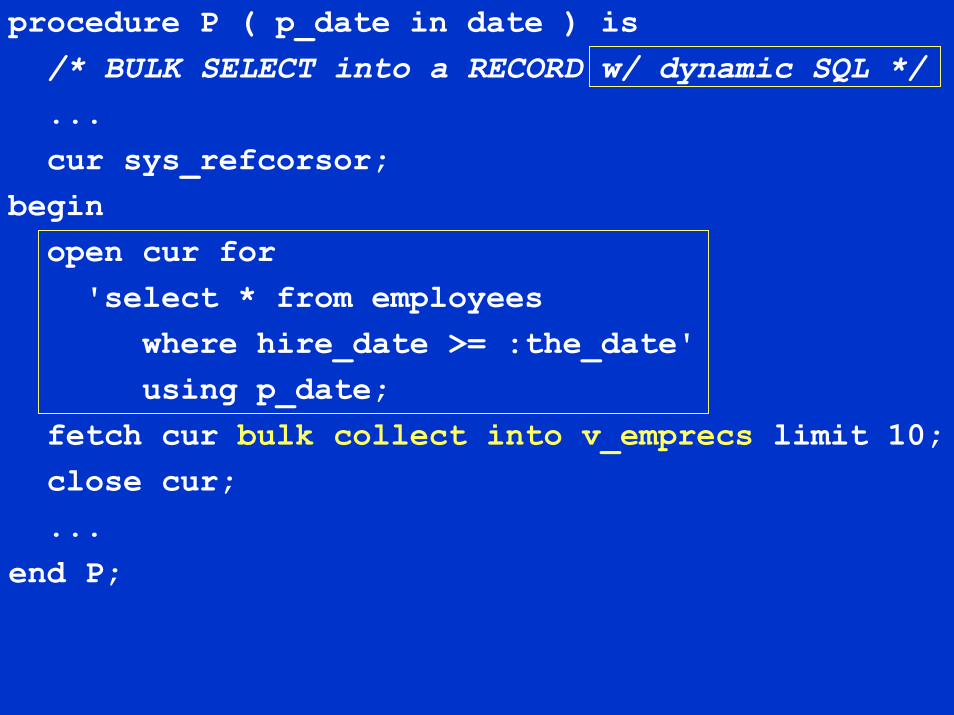
procedure P ( p_date in date ) is/* BULK SELECT into a RECORD w/ dynamic SQL */...cur sys_refcorsor;
beginopen cur for'select * from employees
where hire_date >= :the_date'using p_date;
fetch cur bulk collect into v_emprecs limit 10;close cur;...
end P;

BULK SELECT with RECORD bindWhat did this look like pre Version 9.2.0 ?

declaretype employee_ids_t is table of employees.employee_id%type
index by binary_integer;type first_names_t is table of employees.first_name%type
index by binary_integer;type last_names_t is table of employees.last_name%type
index by binary_integer;type emails_t is table of employees.email%type
index by binary_integer;type phone_numbers_t is table of employees.phone_number%type
index by binary_integer;type hire_dates_t is table of employees.hire_date%type
index by binary_integer;type job_ids_t is table of employees.job_id%type
index by binary_integer;type salarys_t is table of employees.salary%type
index by binary_integer;type commission_pcts_t is table of employees.commission_pct%type
index by binary_integer;type manager_ids_t is table of employees.manager_id%type
index by binary_integer;type department_ids_t is table of employees.department_id%type
index by binary_integer;
v_employee_ids employee_ids_t;v_first_names first_names_t;v_last_names last_names_t;v_emails emails_t;v_phone_numbers phone_numbers_t;v_hire_dates hire_dates_t;v_job_ids job_ids_t;v_salarys salarys_t;v_commission_pcts commission_pcts_t;v_manager_ids manager_ids_t;v_department_ids department_ids_t;
type emprec_tab_t is table of employees%rowtypeindex by pls_integer;
v_emprecs emprec_tab_t;...
begin...
end;
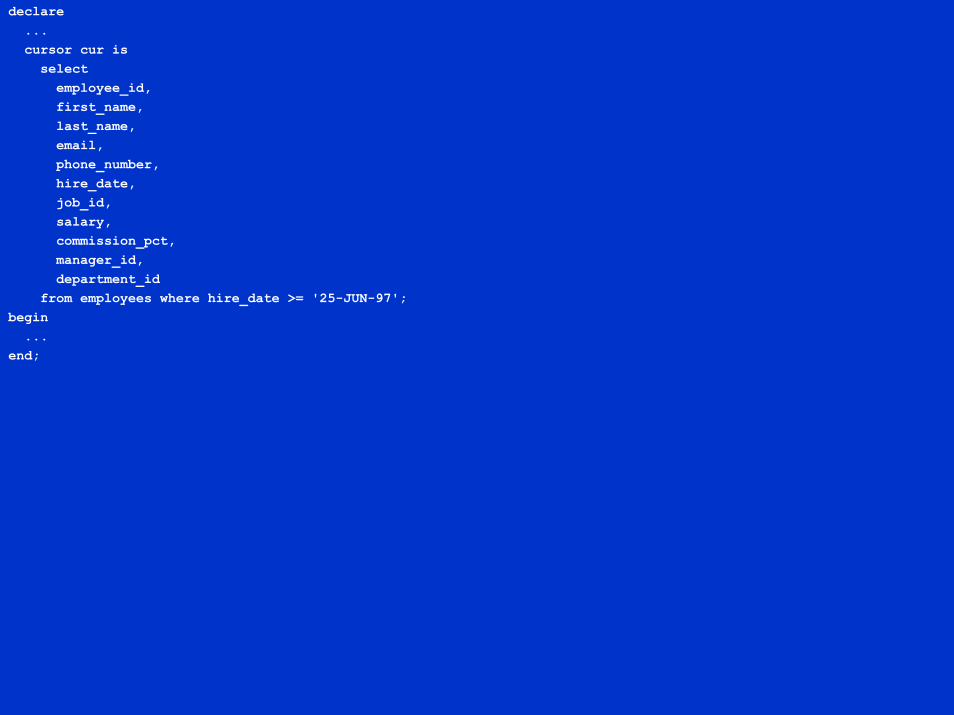
declare...cursor cur isselectemployee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,commission_pct,manager_id,department_id
from employees where hire_date >= '25-JUN-97';begin...
end;
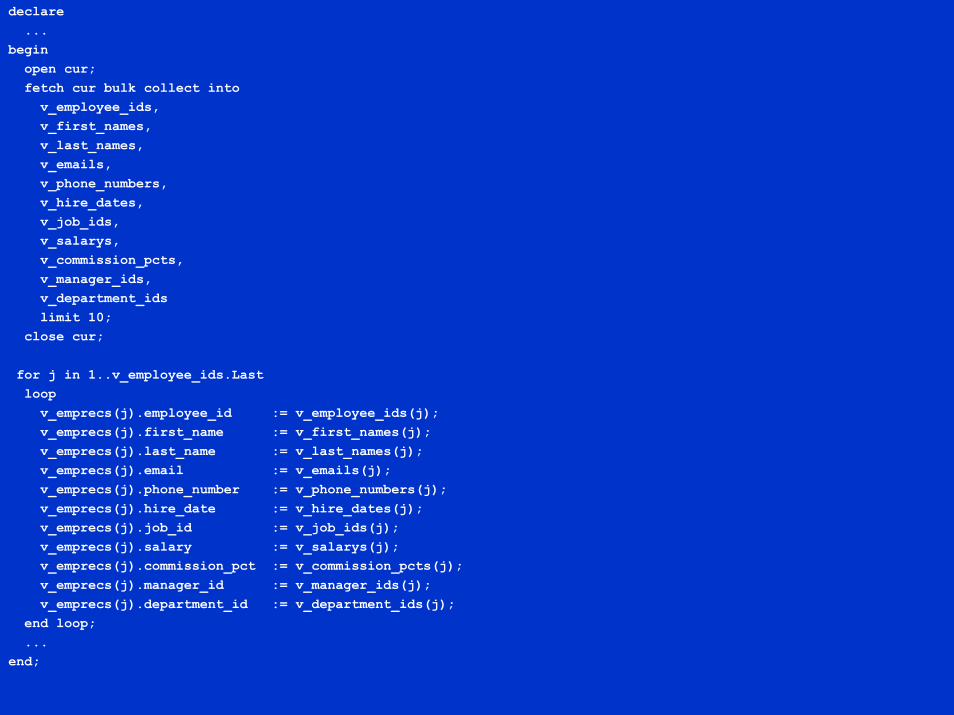
declare...
beginopen cur;fetch cur bulk collect intov_employee_ids,v_first_names,v_last_names,v_emails,v_phone_numbers,v_hire_dates,v_job_ids,v_salarys,v_commission_pcts,v_manager_ids,v_department_idslimit 10;
close cur;
for j in 1..v_employee_ids.Lastloopv_emprecs(j).employee_id := v_employee_ids(j);v_emprecs(j).first_name := v_first_names(j);v_emprecs(j).last_name := v_last_names(j);v_emprecs(j).email := v_emails(j);v_emprecs(j).phone_number := v_phone_numbers(j);v_emprecs(j).hire_date := v_hire_dates(j);v_emprecs(j).job_id := v_job_ids(j);v_emprecs(j).salary := v_salarys(j);v_emprecs(j).commission_pct := v_commission_pcts(j);v_emprecs(j).manager_id := v_manager_ids(j);v_emprecs(j).department_id := v_department_ids(j);
end loop;...
end;

BULK SELECT with RECORD bindPre Version 9.2.0 you needed a scalar index-bytable for each select list item and had to list all columns explicitly to be robustNeeded explicit loop to assign RECORD values following the SELECTApproaches what is feasible to maintainFeels especially uncomfortable because of the artificial requirement to compromise the natural modeling approach by slicing the desired table of records vertically into N tables of scalars
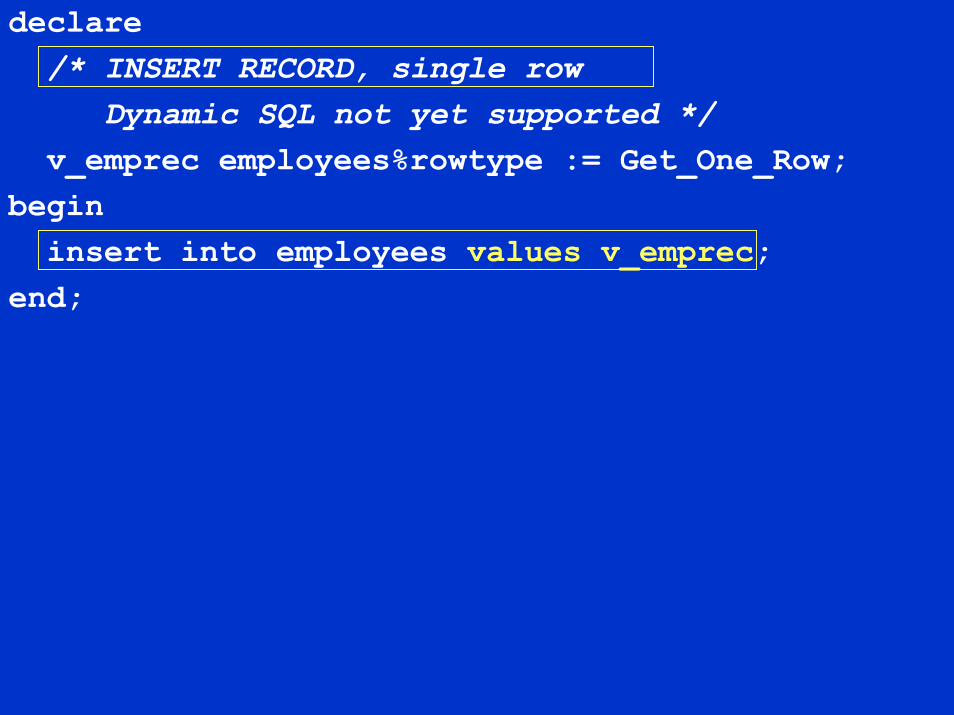
declare/* INSERT RECORD, single row
Dynamic SQL not yet supported */v_emprec employees%rowtype := Get_One_Row;
begininsert into employees values v_emprec;
end;

declare/* BULK INSERT RECORD
Dynamic SQL not yet supported */v_emprecs Emp_Util.emprec_tab_t :=Emp_Util.Get_Many_Rows;
beginforall j in v_emprecs.first..v_emprecs.lastinsert into employees values v_emprecs(j);
end;
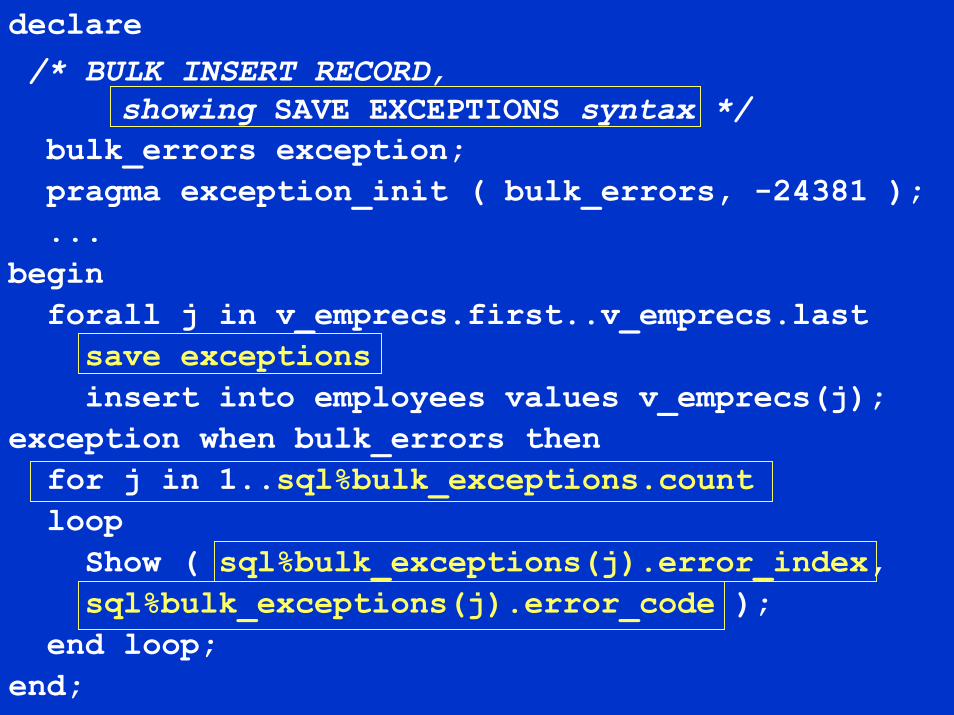
declare/* BULK INSERT RECORD,
showing SAVE EXCEPTIONS syntax */bulk_errors exception;pragma exception_init ( bulk_errors, -24381 );...
beginforall j in v_emprecs.first..v_emprecs.lastsave exceptionsinsert into employees values v_emprecs(j);
exception when bulk_errors thenfor j in 1..sql%bulk_exceptions.countloopShow ( sql%bulk_exceptions(j).error_index,sql%bulk_exceptions(j).error_code );
end loop;end;

BULK INSERT with RECORD bindWhat did this look like pre Version 9.2.0 ?
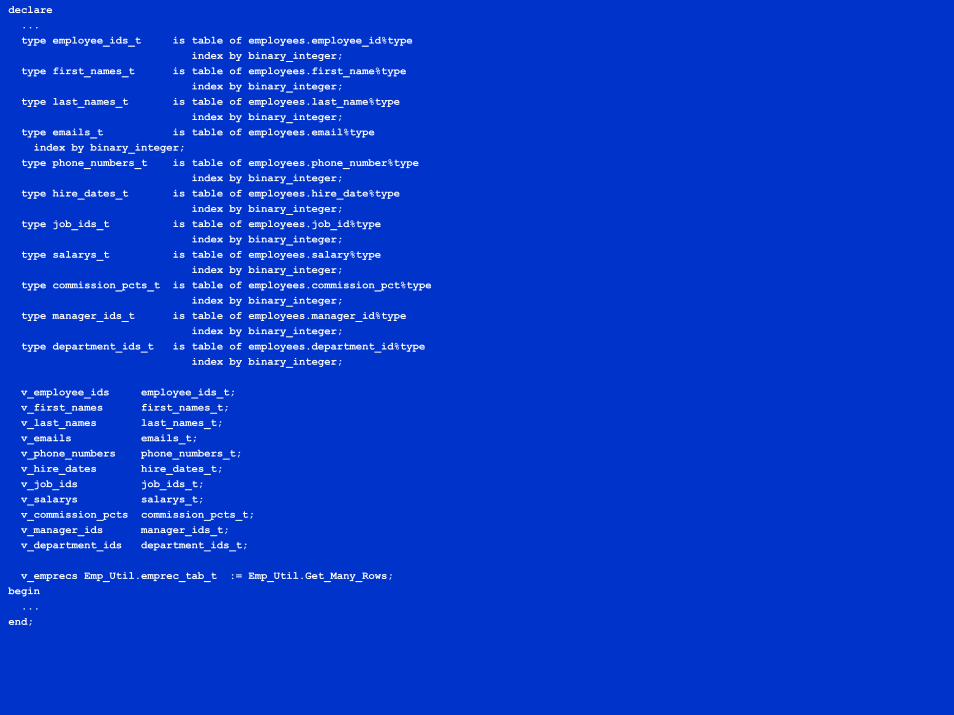
declare...type employee_ids_t is table of employees.employee_id%type
index by binary_integer;type first_names_t is table of employees.first_name%type
index by binary_integer;type last_names_t is table of employees.last_name%type
index by binary_integer;type emails_t is table of employees.email%typeindex by binary_integer;
type phone_numbers_t is table of employees.phone_number%typeindex by binary_integer;
type hire_dates_t is table of employees.hire_date%typeindex by binary_integer;
type job_ids_t is table of employees.job_id%typeindex by binary_integer;
type salarys_t is table of employees.salary%typeindex by binary_integer;
type commission_pcts_t is table of employees.commission_pct%typeindex by binary_integer;
type manager_ids_t is table of employees.manager_id%typeindex by binary_integer;
type department_ids_t is table of employees.department_id%typeindex by binary_integer;
v_employee_ids employee_ids_t;v_first_names first_names_t;v_last_names last_names_t;v_emails emails_t;v_phone_numbers phone_numbers_t;v_hire_dates hire_dates_t;v_job_ids job_ids_t;v_salarys salarys_t;v_commission_pcts commission_pcts_t;v_manager_ids manager_ids_t;v_department_ids department_ids_t;
v_emprecs Emp_Util.emprec_tab_t := Emp_Util.Get_Many_Rows;begin...
end;
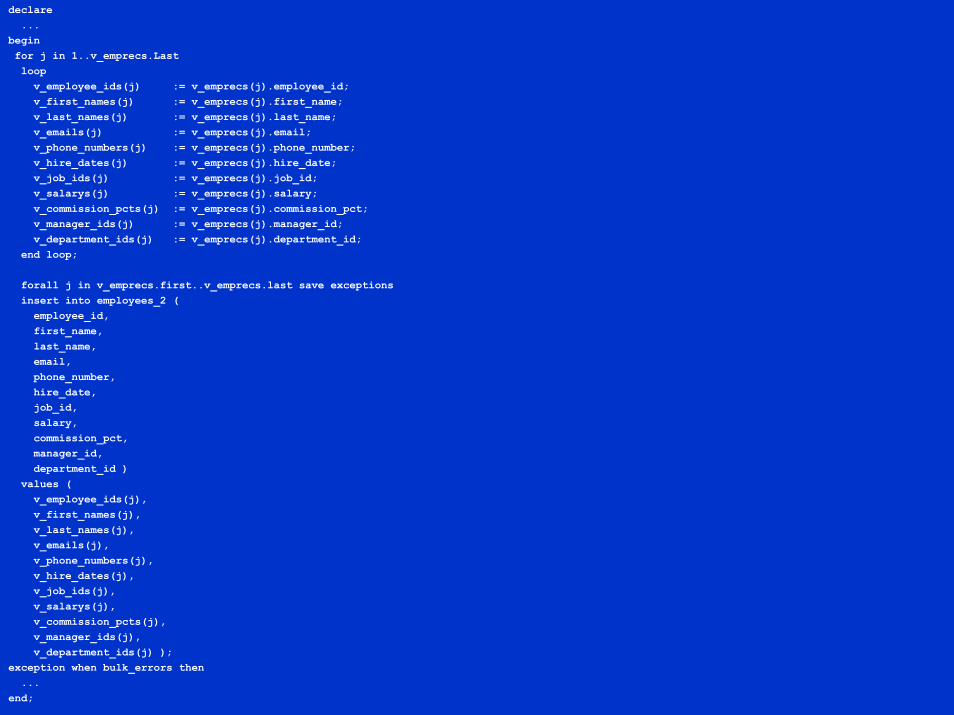
declare...
beginfor j in 1..v_emprecs.Lastloopv_employee_ids(j) := v_emprecs(j).employee_id;v_first_names(j) := v_emprecs(j).first_name;v_last_names(j) := v_emprecs(j).last_name;v_emails(j) := v_emprecs(j).email;v_phone_numbers(j) := v_emprecs(j).phone_number;v_hire_dates(j) := v_emprecs(j).hire_date;v_job_ids(j) := v_emprecs(j).job_id;v_salarys(j) := v_emprecs(j).salary;v_commission_pcts(j) := v_emprecs(j).commission_pct;v_manager_ids(j) := v_emprecs(j).manager_id;v_department_ids(j) := v_emprecs(j).department_id;
end loop;
forall j in v_emprecs.first..v_emprecs.last save exceptionsinsert into employees_2 (employee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,commission_pct,manager_id,department_id )
values (v_employee_ids(j),v_first_names(j),v_last_names(j),v_emails(j),v_phone_numbers(j),v_hire_dates(j),v_job_ids(j),v_salarys(j),v_commission_pcts(j),v_manager_ids(j),v_department_ids(j) );
exception when bulk_errors then...
end;

BULK INSERT with RECORD bindPre Version 9.2.0 you needed a scalar index-bytable for each target column and had to list all columns explicitly to be robustNeeded explicit loop to assign the scalr tables before the INSERTAgain, approaches what is feasible to maintainAgain, feels especially uncomfortable because of the artificial requirement to compromise the natural modeling approach by slicing the desired table of records vertically into N tables of scalars
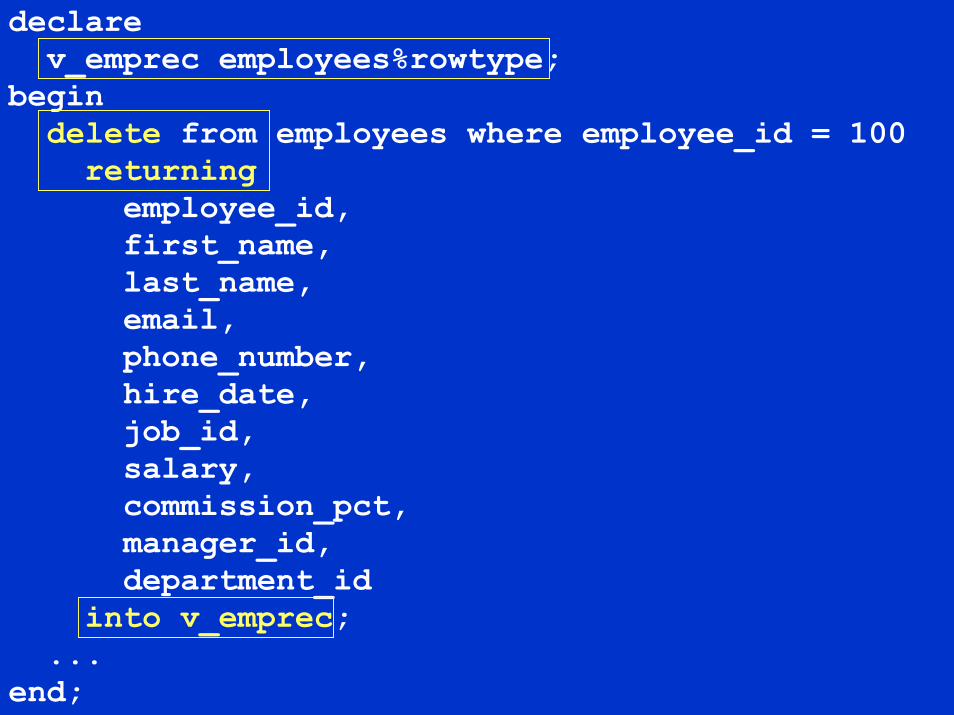
declarev_emprec employees%rowtype;
begindelete from employees where employee_id = 100returningemployee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,commission_pct,manager_id,department_id
into v_emprec;...
end;
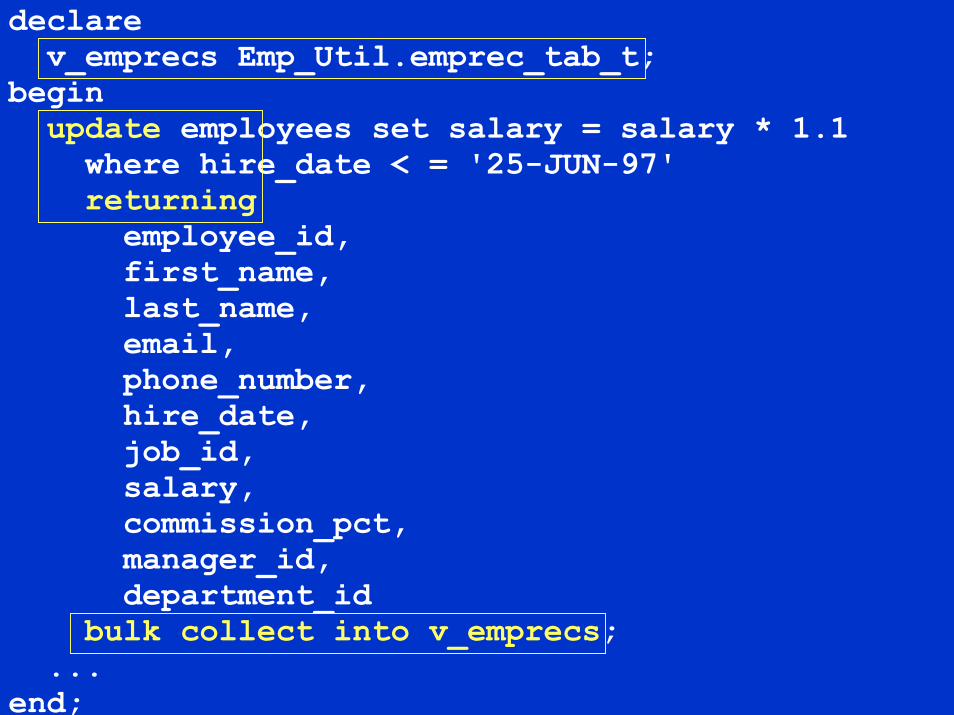
declarev_emprecs Emp_Util.emprec_tab_t;
beginupdate employees set salary = salary * 1.1where hire_date < = '25-JUN-97'returningemployee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,commission_pct,manager_id,department_id
bulk collect into v_emprecs;...
end;

BULK UPDATE and DELETEwith RECORD bind
What did this look like pre Version 9.2.0 ?
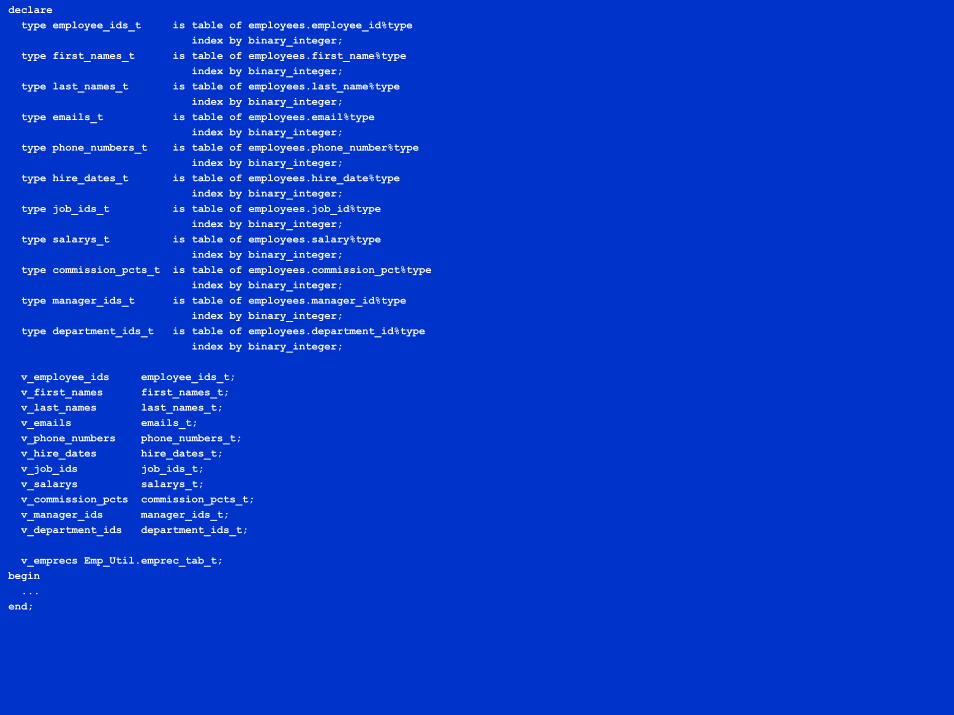
declaretype employee_ids_t is table of employees.employee_id%type
index by binary_integer;type first_names_t is table of employees.first_name%type
index by binary_integer;type last_names_t is table of employees.last_name%type
index by binary_integer;type emails_t is table of employees.email%type
index by binary_integer;type phone_numbers_t is table of employees.phone_number%type
index by binary_integer;type hire_dates_t is table of employees.hire_date%type
index by binary_integer;type job_ids_t is table of employees.job_id%type
index by binary_integer;type salarys_t is table of employees.salary%type
index by binary_integer;type commission_pcts_t is table of employees.commission_pct%type
index by binary_integer;type manager_ids_t is table of employees.manager_id%type
index by binary_integer;type department_ids_t is table of employees.department_id%type
index by binary_integer;
v_employee_ids employee_ids_t;v_first_names first_names_t;v_last_names last_names_t;v_emails emails_t;v_phone_numbers phone_numbers_t;v_hire_dates hire_dates_t;v_job_ids job_ids_t;v_salarys salarys_t;v_commission_pcts commission_pcts_t;v_manager_ids manager_ids_t;v_department_ids department_ids_t;
v_emprecs Emp_Util.emprec_tab_t;begin...
end;
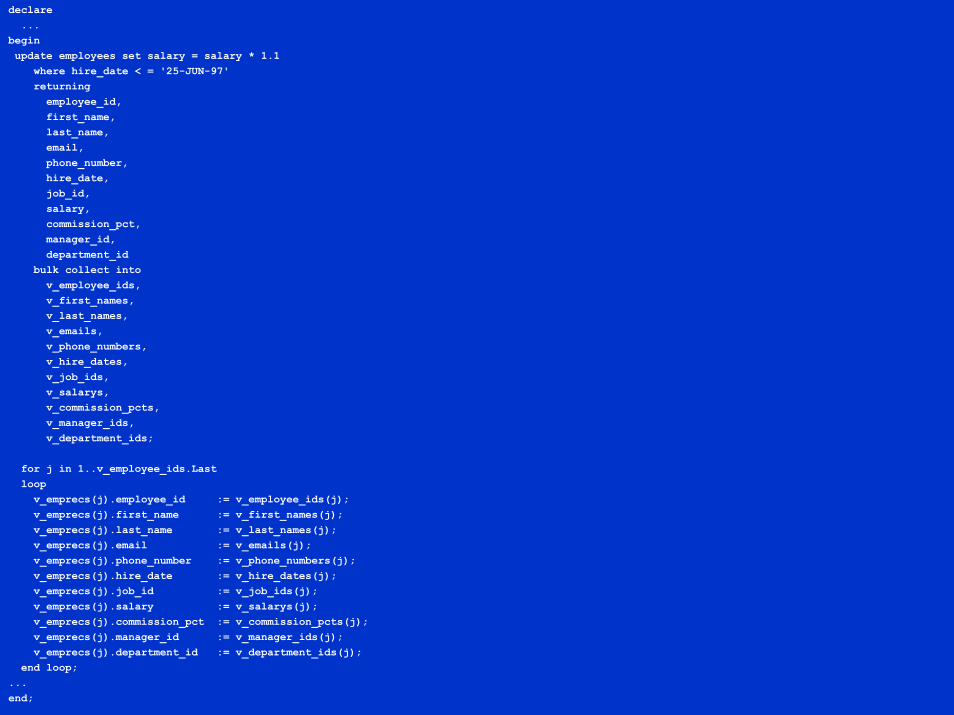
declare...
beginupdate employees set salary = salary * 1.1
where hire_date < = '25-JUN-97'returningemployee_id,first_name,last_name,email,phone_number,hire_date,job_id,salary,commission_pct,manager_id,department_id
bulk collect intov_employee_ids,v_first_names,v_last_names,v_emails,v_phone_numbers,v_hire_dates,v_job_ids,v_salarys,v_commission_pcts,v_manager_ids,v_department_ids;
for j in 1..v_employee_ids.Lastloopv_emprecs(j).employee_id := v_employee_ids(j);v_emprecs(j).first_name := v_first_names(j);v_emprecs(j).last_name := v_last_names(j);v_emprecs(j).email := v_emails(j);v_emprecs(j).phone_number := v_phone_numbers(j);v_emprecs(j).hire_date := v_hire_dates(j);v_emprecs(j).job_id := v_job_ids(j);v_emprecs(j).salary := v_salarys(j);v_emprecs(j).commission_pct := v_commission_pcts(j);v_emprecs(j).manager_id := v_manager_ids(j);v_emprecs(j).department_id := v_department_ids(j);
end loop;...end;

BULK UPDATE and DELETEwith RECORD bind
Even at Version 9.2.0, we don’t yet have a RETURNING * syntaxBut pre Version 9.2.0 you needed a scalar index-bytable for each target columnAgain, approaches what is feasible to maintainAgain, feels especially uncomfortable because of the artificial requirement to compromise the natural modeling approach by slicing the desired table of records vertically into N tables of scalars

UPDATE ... SET ROW =with RECORD bind
This syntax is useful when a row from one table is manipulated programmatically, and then stored in for example an auditing table with the same shape where an earlier version of the row already existsFirst, the single row syntax…

declarev_emprec employees%rowtype :=Emp_Util.Get_One_Row;
beginv_emprec.salary := v_emprec.salary * 1.2;update employees_2set row = v_emprecwhere employee_id = v_emprec.employee_id;
end;

UPDATE ... SET ROW =with RECORD bind
What did this look like pre Version 9.2.0 ?

declarev_emprec employees%rowtype := Emp_Util.Get_One_Row;
beginv_emprec.salary := v_emprec.salary * 1.2;update employeessetfirst_name = v_emprec.first_name,last_name = v_emprec.last_name,email = v_emprec.email,phone_number = v_emprec.phone_number,hire_date = v_emprec.hire_date,job_id = v_emprec.job_id,salary = v_emprec.salary,commission_pct = v_emprec.commission_pct,manager_id = v_emprec.manager_id,department_id = v_emprec.department_id
where employee_id = v_emprec.employee_id;end;

UPDATE ... SET ROW =with RECORD bind
Next, the BULK syntaxNote: you can’t reference fields of the BULK In-bind table of RECORDs in the WHERE clause…
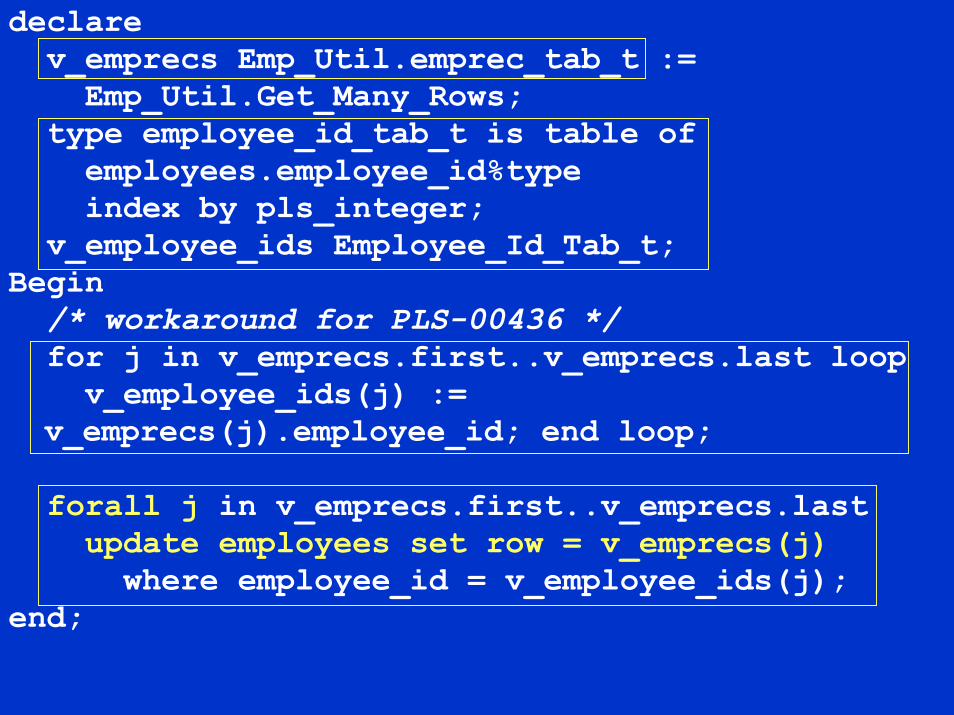
declarev_emprecs Emp_Util.emprec_tab_t :=Emp_Util.Get_Many_Rows;
type employee_id_tab_t is table ofemployees.employee_id%typeindex by pls_integer;
v_employee_ids Employee_Id_Tab_t;Begin/* workaround for PLS-00436 */for j in v_emprecs.first..v_emprecs.last loopv_employee_ids(j) :=
v_emprecs(j).employee_id; end loop;
forall j in v_emprecs.first..v_emprecs.lastupdate employees set row = v_emprecs(j)
where employee_id = v_employee_ids(j);end;

UPDATE ... SET ROW =with RECORD bind
What did the BULK synatx look like preVersion 9.2.0 ?
declarev_emprecs Emp_Util.emprec_tab_t :=Emp_Util.Get_Many_Rows;
type employee_ids_t is table of employees.employee_id%typeindex by binary_integer;
type first_names_t is table of employees.first_name%typeindex by binary_integer;
type last_names_t is table of employees.last_name%typeindex by binary_integer;
type emails_t is table of employees.email%typeindex by binary_integer;
type phone_numbers_t is table of employees.phone_number%typeindex by binary_integer;
type hire_dates_t is table of employees.hire_date%typeindex by binary_integer;
type job_ids_t is table of employees.job_id%typeindex by binary_integer;
type salarys_t is table of employees.salary%typeindex by binary_integer;
type commission_pcts_t is table of employees.commission_pct%typeindex by binary_integer;
type manager_ids_t is table of employees.manager_id%typeindex by binary_integer;
type department_ids_t is table of employees.department_id%typeindex by binary_integer;
v_employee_ids employee_ids_t;v_first_names first_names_t;v_last_names last_names_t;v_emails emails_t;v_phone_numbers phone_numbers_t;v_hire_dates hire_dates_t;v_job_ids job_ids_t;v_salarys salarys_t;v_commission_pcts commission_pcts_t;v_manager_ids manager_ids_t;v_department_ids department_ids_t;
begin...
end;
declare...
beginfor j in 1..v_emprecs.Lastloopv_employee_ids(j) := v_emprecs(j).employee_id;v_first_names(j) := v_emprecs(j).first_name;v_last_names(j) := v_emprecs(j).last_name;v_emails(j) := v_emprecs(j).email;v_phone_numbers(j) := v_emprecs(j).phone_number;v_hire_dates(j) := v_emprecs(j).hire_date;v_job_ids(j) := v_emprecs(j).job_id;v_salarys(j) := v_emprecs(j).salary * 1.2;v_commission_pcts(j) := v_emprecs(j).commission_pct;v_manager_ids(j) := v_emprecs(j).manager_id;v_department_ids(j) := v_emprecs(j).department_id;
end loop;
forall j in v_emprecs.first..v_emprecs.lastupdate employeessetfirst_name = v_first_names(j),last_name = v_last_names(j),email = v_emails(j),phone_number = v_phone_numbers(j),hire_date = v_hire_dates(j),job_id = v_job_ids(j),salary = v_salarys(j),commission_pct = v_commission_pcts(j),manager_id = v_manager_ids(j),department_id = v_department_ids(j)
where employee_id = v_employee_ids(j);end;

UPDATE ... SET ROW =with RECORD bind
Pre Version 9.2.0 you needed a scalar index-bytable for each target columnAgain, approaches what is feasible to maintainAgain, feels especially uncomfortable because of the artificial requirement to compromise the natural modeling approach by slicing the desired table of records vertically into N tables of scalars

RECORD binds: summaryYou can now take advantage of the power of the PL/SQL RECORD datatype in all SELECT constructs and in all DML constructs in Static SQLThe volume of code you had to write pre Version 9.2.0 was enormously greater – verging on unmaintainable - and forced you to compromise the natural modelling approachPre Version 9.2.0 you had to copy from one representation to another. Now that you no longer need to do this, your program runs faster

Summary of 9.2.0 EnhancementsIndex-by-varchar2 tables,aka associative arrays
RECORD binds in DML andin BULK SELECTs
Utl_File enhancements
GUI debugging via JDeveloper Version 9.0.3

Utl_File enhancementsYou can now use the DIRECTORY schema object(as for BFILEs)Line length limit for Utl_File.Get_Line and Utl_File.Put_Line has been increased to 32KNew APIs to manipulate files at the operating system levelNew APIs for handling RAW dataPerformance is improved via transparent internal reimplementation

Utl_File using DIRECTORYPre Version 9.2.0, the way to denote the director(ies) for files was via the UTL_FILE_DIRinitialization parameterDisadvantages
– instance had to be bounced to make changes to the list of directories
– all users could access files on all directoriesVersion 9.2.0 allows the same mechanism to be used with Utl_File as is used for BFILEsThe UTL_FILE_DIR initialization parameter is slated for deprecation

Utl_File o/s file managementprocedure Fgetattrprocedure Fcopyprocedure Fremoveprocedure Frename

Utl_File handling RAW dataprocedure Fseek -- go to offsetfunction Fgetpos -- report offsetprocedure Get_Rawprocedure Put_Raw

Utl_File - summaryFunctionality now provided natively for a number of common file i/o tasks
– dramatically reduces the amount of code you need to write
– delivers better performancePerformance improvement further enhanced by some transparent internal changesRobustness improved by removing some uncomfortable limitsSecurity improved by adopting the BFILE model

Summary of 9.2.0 EnhancementsIndex-by-varchar2 tables,aka associative arrays
RECORD binds in DML andin BULK SELECTs
Utl_File enhancements
GUI debuggingvia JDeveloper Version 9.0.3

GUI PL/SQL debuggingvia JDeveloper Version 9.0.3
JDeveloper Version 9.0.3 will very soon be available for download from OTNIts PL/SQL IDE subcomponent is extended to provide support for graphical debugging of PL/SQL stored subprogramsThis includes support for all the new features discussed in this presentation

Connection modelJDeveloper (when executing a PL/SQL subprogram) connects as a classical Oracle client via Oracle NetOr, any Oracle client connectsThe client (implicitly or explicitly) requests debuggingThe shadow process connects back to JDeveloper(or any equivalent 3rd party tool)via the Java Debugging Wire Protocol aka JDWP

Connection modelDbms_Debug_Jdwp.Connect_Tcp( :the_node, :the_port, ... )
Usually called transparently by the debugging tool or by some client or middle-tier infrastructure

Connection modelJava Debugging Wire Protocol aka JDWP
– industry standard invented to support Java debugging
– completely suitable for PL/SQL too– allows 3rd party tools vendors to implement
PL/SQL debuggingAt the same protocol level as say HTTP orOracle NetTypically implemented on top of TCP/IP

Connection modelJDWP also allows JDeveloper and other 3rd party tools to debug database stored JavaWhen debugging an application implemented in a mix of Java and PL/SQL
– execution point moves seamlessly from one environment to the other
– integrity of the call stack is maintained across the language boundary

Connection modelJDeveloper incorporates a JDWP listenerCan be started on any portCan spawn any number of debugging sessions running concurrently - cf tnslsnrThe Oracle shadow processes which are the debugging clients could be running on different machines, communicating with each other via say Oracle AQ
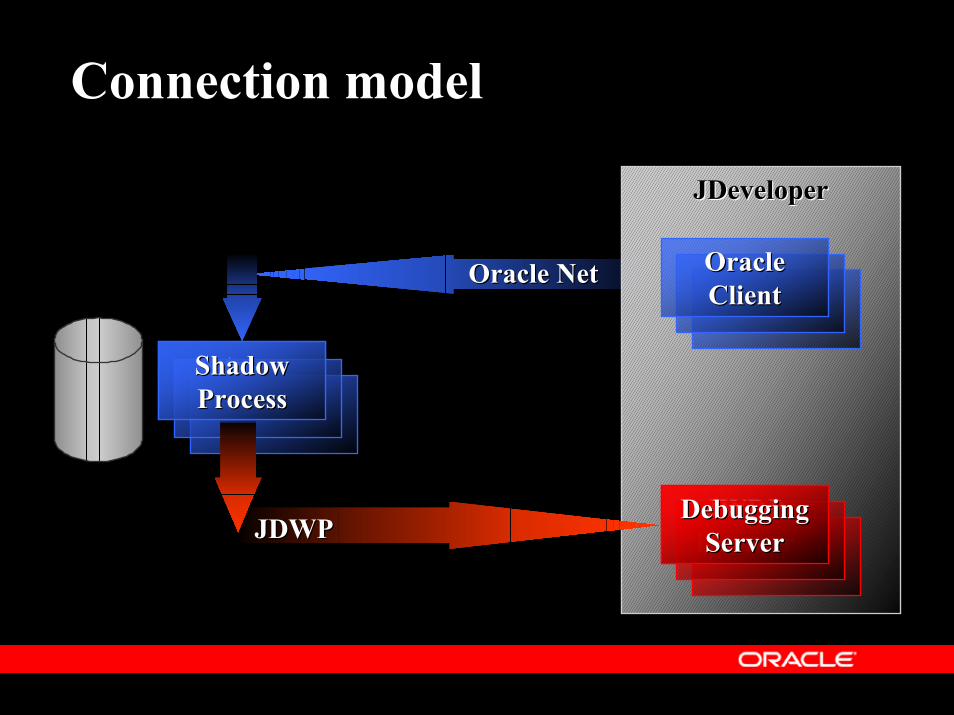
Connection model
tnstnslistenerlistener
Oracle NetOracle Net
JDeveloperJDeveloper
JWDPJWDPListenerListener
ShadowShadowProcessProcess
OracleOracleClientClient
DebuggingDebuggingServerServerJDWPJDWP

Pre-conditions for debuggingUser must have debug connect session and debug any procedure system privilegesmust have execute privilege on the subprograms of interestsource code must not be wrappedmust have been compiled with debug information, eg…
alter [ package | ... ] P compile debug;

GUI-initiated debugging modeA debugging exercise always involves opening the source code read from the database in the source windowThis is how the current execution point is displayed and how you set breakpoints
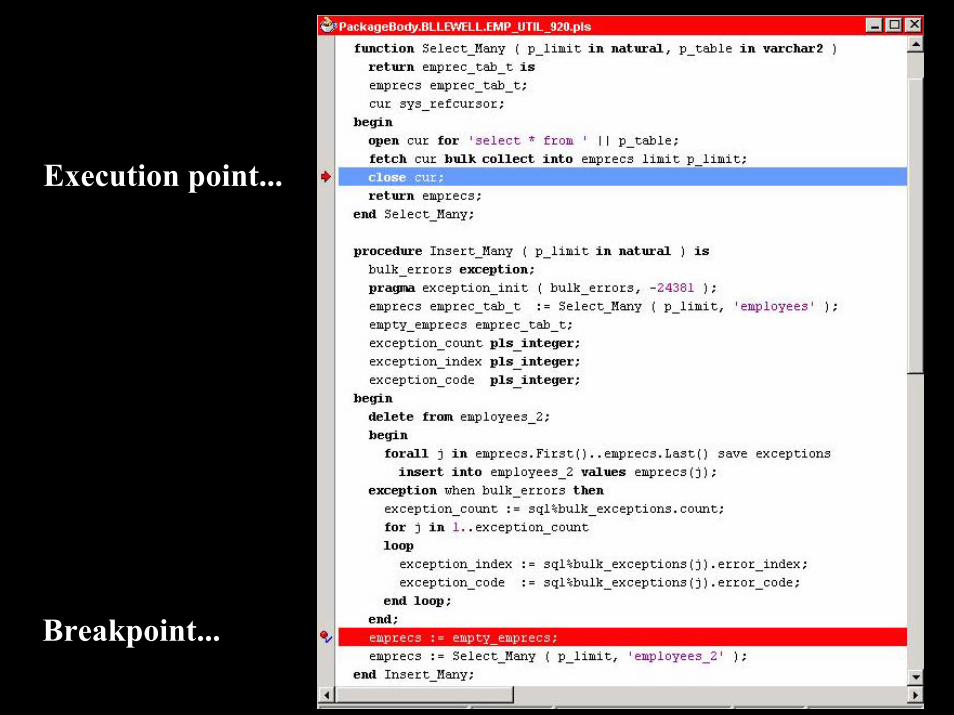
Breakpoint...Breakpoint...
Execution point...Execution point...

GUI-initiated debugging modeIn many scenarios you’re happy to kick off debugging directly from JDeveloperYou choose your top level subprogram and set its actual parameter values via the same GUI used just to execute subprograms for testingThe magic to control the JDWP listener is implicitIn the default configuration JDeveloper chooses the first available port automaticallyTo debug code which is invoked when a trigger fires, write a small procedure to invoke the SQL

Remote debugging modeWhat if the server-side PL/SQL which you want to debug is invoked from a client?
– Pro*C or Java application in a classical two-tier model
– mod_plsql component of Oracle9iAS as the middle tier in a three-tier model
The parameters that define the debugging case of interest are set by application logicCalling your subprogram with these values by hand is too tortuous

Remote debugging modeYou could change your application code to call the Dbms_Debug_Jdwp APIsBut this invasive approach is uncomfortableIn the two-tier case, use the environment variable ora_debug_jdwp, eg…
set ora_debug_jdwp=host=lap99.acme.com;port=2125
Read by the OCI layer which then calls Dbms_Debug_Jdwp.Connect_Tcpimmediately on connection

Remote debugging modeJDeveloper (or an equivalent third party tool) must be running on the indicated nodeIts JDWP listener must have been started manually to listen on the indicated portDo this by choosing remote debugging rather than the default GUI-initiated debugging mode via a UI that allows selection of the port

Remote debugging modeWhat if the client is mod_plsql ?Want to turn on debugging for the server-side PL/SQL that supports a particular browser (pseudo) sessionAnd not to turn it on for other concurrent browser sessionsThe debugging user sets a cookie via thebrowser UI – specifying JDWP host and portCauses mod_plsql to call Connect_Tcp before its normal calls and Disconnect after these

Remote debugging modeIf you use…
– a jdbc:thin Java client– Or some middle tier infrastructure other than
Oracle9iAS's mod_plsql…then you'll need to make calls to the Dbms_Debug_Jdwp API in yourself in your production code

Debugger featuresGUI-initiated and remote debugging modesCan support one or many concurrent debugging clients and thus debug interacting processesCurrent execution point displayed as highlighted line in the source extracted dynamically from the database where the code is executingBreakpoints can be set and unset before and during the debugging session. Displayed as highlighted line in source windowStart debugging session with Step Into, Step Overor Run to First Breakpoint

Debugger featuresWhen paused, can continue with Resume (aka Run to Next Breakpoint), Step Into or Step OverOr Abort the current debugging sessionCan attach condition to a breakpoint to determine if execution stops there or notWhen paused, can view the values of variables visible in the current subprogram, and the values for all variables that are currently “alive”Intuitive display for collection objects and objects of user-defined abstract datatypes

Debugger featuresCall stack displayCan click anywhere in the stack to view the values of variables that belong to the selected subprogramIntuitive display for recursive callsWhen paused, can modify the values of variables
normal caveats regarding what you can then deduce about your program's subsequent behavior!

Debugger scenarioAn index-by- pls_integer table of RECORDs of employees%rowtype is populated byBULK SELECT using Native Dynamic SQLThe index-by table is inserted into a second database table with the same shape with BULK INSERT using Static SQL with thesave exceptions constructThe table has a trigger which raises an exception on conditions of these dataAn exception handler traverses the index-by tableof exception codes

Debugger scenarioThe contents of the target table are selected using the same subprogram as at the startBut now the Native Dynamic SQL uses a different table nameThis confirms the successful insert of those rows for which an exception was not raised

Debugger scenarioThe Data Window shows the state of the variables of the function that does the BULK SELECT when paused as in the earlier screenshotThe second element of the emprecs index-by tableis expanded to show the values of each field in the RECORD…


Debugger scenarioHere’s the Call Stack window when the execution point is in the trigger…

Debugger scenarioHere’s the Code Window when the execution point is in the trigger…
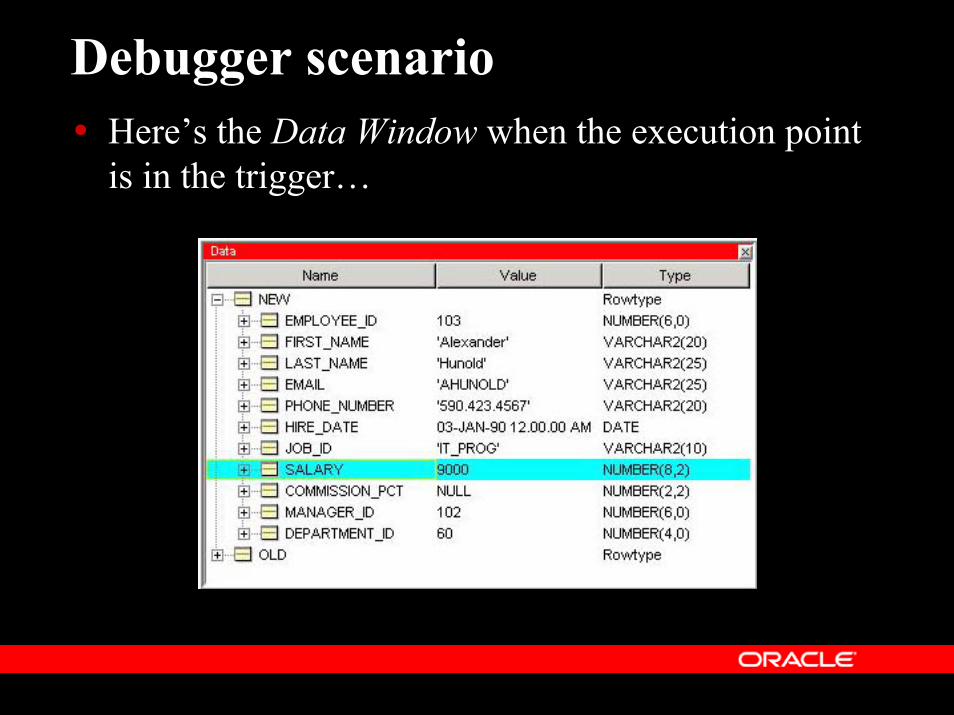
Debugger scenarioHere’s the Data Window when the execution point is in the trigger…

PL/SQL Debugging at 9.0.1and earlier
JDeveloper Version 9.0.3 also implements PL/SQL debugging via the earlier Dbms_Debug API to allow it to be used against database versions earlier than Version 9.2.0

PL/SQL debugging: summaryValue of a GUI debugger is self-evident!Consider just index-by tables of RECORDsNo PL/SQL syntax to display all fields in each row of such a structureEffort required to program a loop to do this via Dbms_Output is time-consuming and potentially error-proneJDeveloper provides ready-made intuitive mechanisms for displaying the values of arbitrarily complex structures

Oracle9i in Action170 Systems, Inc have been an Oracle Partner for eleven years and participated in the Beta Program for the Oracle9i Database with particular interest in PL/SQL Native CompilationThey have now certified their 170 MarkView Document Management and Imaging System™against Oracle9i Vesrion 9.2.0

170 MarkViewDocument Managementand Imaging System
Provides Content Management, Document Management, Imaging and Workflow solutionsTightly integrated with the Oracle9i Database, Oracle9i Application Server andthe Oracle E-Business SuiteEnables businesses to capture and manage all of their information online in a single, unified system

170 MarkView™Large-scale multi-user, multi-access systemCustomers include…
– British Telecommunications– E*TRADE Group– the Apollo Group– the University of Pennsylvania
Very large numbers of documents, images, concurrent users, and high transaction ratesPerformance and scalability especially important

170 Systems, IncPlanning to take advantage of many of the new Version 9.2.0 PL/SQL featureseg Associative Arrays to improve performance in an application that performs complex stack manipulationsValues are taken from the stack using random access based on a identifying character namePreviously, this was simulated using hashing routines written using PLSQLTherefore a performance improvement is expected

170 Systems, IncTested the JDeveloper PL/SQL debugging environment extensivelyThey like itPlan to adopt it as their PL/SQL debugging environment of choice for their developers

Summary of 9.2.0 EnhancementsIndex-by-varchar2 tables,aka associative arrays
RECORD binds in DML andin BULK SELECTs
Utl_File enhancements
GUI debugging via JDeveloper Version 9.0.3

Summary of 9.2.0 EnhancementsAll the enhancements discussed in this presentation dramatically reduce the effort of program design, implementation and testing to build applications with matching requirementsAnd Index-by-varchar2 tables, RECORD binds and the Utl_File enhancements also deliver more performant programs
you should upgrade !you should upgrade !

Q U E S T I O N SQ U E S T I O N SA N S W E R SA N S W E R S


















