39
Leveraging Probabilistic Data Structures for Real Time Analytics with Redis Modules Itamar Haber, Redis Labs
| Date post: | 16-Jan-2017 |
| Category: |
Data & Analytics |
| Upload: | itamar-haber |
| View: | 546 times |
| Download: | 0 times |

Leveraging Probabilistic Data Structures for Real Time Analytics with Redis Modules
Itamar Haber, Redis Labs

2
Who We Are
The open source home and commercial provider of Redis
Open source. The leading in-memory database platform, supporting any high performance OLTP or OLAP use case.
Chief Developer Advocate at Redis [email protected]@itamarhaber

3
There are three kindsof people in the world;those who can countand those who can’t.

About 10 Things About Redis

5
1.Redis: REmote DIctionary Server2./ rɛdɪs/: “red-iss”3.OSS: http://github.com/antirez/redis4.3-clause BSD-license: http://redis.io5. In-memory: (always) read from RAM6.A database for: 5 data structures7.And: 4 more specialized ones

6
8.Developed & maintained: (mostly) Salvatore Sanfilippo (a.k.a. @antirez) and his OSS team at @RedisLabs
9.Short history:v1.0 August 9th, 2009 … v3.2 May 6th, 2016
10.“The Leatherman™ of Databases”:mostly used as a DB, cache & broker

7
11.A couple or so of extra features:(a) atomicity; (b) transactions;(c) configurable persistence;(d) expiration; (e) eviction; (f) PubSub; (g) Lua scripts;(h) high availability; (i) clustering
12.Next version (v4.0): MODULES!

8
2..4 Reasons Why Redis Is A Must For AnyData-Driven Real-Time Analytical Process
Simplicity VersatilityPerformance
“it is very fast”Next 3 slides
+ ‘demo’while(!eof)

9
Redis 1011. Redis is “NoSQL”0. No (explicit) schema, access by key1. Key -> structure -> data
SIMPL-ICI-TY: simple, I see it, thank you
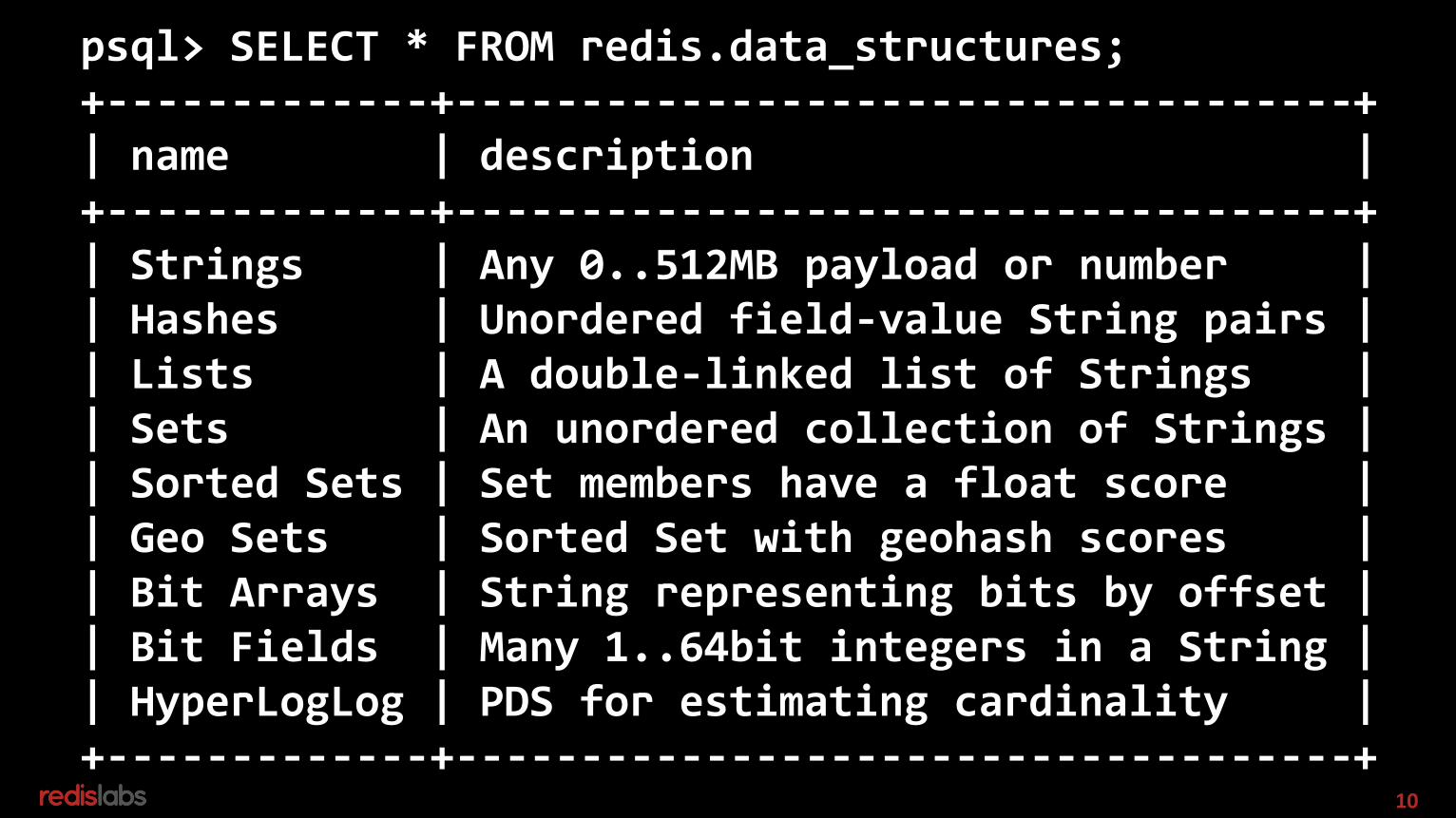
10
psql> SELECT * FROM redis.data_structures;+-------------+------------------------------------+| name | description |+-------------+------------------------------------+| Strings | Any 0..512MB payload or number | | Hashes | Unordered field-value String pairs || Lists | A double-linked list of Strings || Sets | An unordered collection of Strings || Sorted Sets | Set members have a float score || Geo Sets | Sorted Set with geohash scores || Bit Arrays | String representing bits by offset || Bit Fields | Many 1..64bit integers in a String || HyperLogLog | PDS for estimating cardinality |+-------------+------------------------------------+

11
Redis for Data Scientists steps:1. 147 OSS clients (49 languages), e.g.:
Python, Java, Spark, R, Julia, Matlab2. Make a request with the client, i.e.:
PING3. Server sends back the reply, i.e.g:
PONG

12
~$ redis-cli127.0.0.1:6379> SET counter 1OK127.0.0.1:6379> GET counter"1"127.0.0.1:6379> INCR counter(integer) 2127.0.0.1:6379> APPEND counter b||!2b(integer) 7127.0.0.1:6379> GETSET counter "\x00Hello\xffWorld""2b||!2b"127.0.0.1:6379>

The Evolution of Versatility

14
Flexibility (v0.0.1): model (almost) anything with basic “building blocks” and simple rulesComposability: transactions (v1.2) and server-embedded scripted logic (v2.6)Extendibility: modules (v4) for adding custom data structures and commands

Redis Modules

16
Redis Modules are:1. Dynamically loaded libraries2. Future-compatible binaries3. (will be mostly) written in C4. Use an API that the server provides5. (nearly) as fast as core commands6. Planned for public release Q3 2016

17
3 layers of the Modules API:1.Operational layer: admin, memory,
disk, call arguments, replies…2.High-level layer: client-like access to
core and modules’ commands3.Low-level: (almost) native access to
core data structures memory

18
Benchmark: Sum Of 1M Scores In A Sorted Set
Methodology Time (sec)
Local client (Python) 1.2
Embedded script (Lua) 1.25
High-level API 1.05
Low-level Iterators API 0.1

19
On averageabout 63.79%of all statisticsare made up

Probabilistic Data Structures (PDSs)

21
There are three kindsof data structures…
…and those who bothcan count and can’t.

22
Data Structures of the 3rd kind• Why: accuracy is (in theory) possible
but scale makes it (nearly) impossible• Example: number of unique visitors• Alternative: estimate the answer• Data structure: the HyperLogLog• Ergo: modules as models for PDSs

23
The “good” PDSs are1. Efficient: sublinear space-time 2. Accurate: within their parameters3. Scalable: by merging et al.4. Suspiciously not unlike: the Infinite
Improbability Drive (The Hitch Hiker Guide to the Galaxy, Adams D.)

24
Top-K - k most frequent samplesThe entire algorithm:1. Maintain set S of k counters2. For each sample s:2.1 If s exists in S, increment S(x)2.1 Otherwise, if there’s space add x
to S , else decrement all counters

25
Modelling Top-K with Redis1. Sorted Set -> unique members2. Member -> element and score3. ZSCORE: O(1) membership4. ZADD: O(Log(N)) write5. ZRANGEBYSCORE: O(Log(N)) seek

26
redis> TOPK.ADD tk 2 a(integer) 1redis> TOPK.ADD tk 2 b(integer) 1redis> TOPK.ADD tk 2 b(integer) 0redis> ZRANGE tk 1 -1 WITHSCORES1) "a"2) "1"3) "b"4) "2"redis> TOPK.ADD tk 2 c(integer) -1
ksample
score
1 means added0 is freq. incr.
indicates eviction

27
redis> ZRANGE tk 1 -1 WITHSCORES1) "b"2) "2"3) "c"4) "2"redis> TOPK.ADD tk 2 c(integer) 0redis> ZRANGE tk 1 -1 WITHSCORES1) "b"2) "2"3) "c"4) "3"
a evicted, c addedb’s and c’s score = 2
(global offset = -1)

28
topk Redis Module1.Optimization: a global score offset2.Eviction: reservoir sampling3.TOPK.PRANK: percentile rank4.TOPK.PRANGE: percentile range5.Where: Redis Module Hub/topk

29
Bloom filter – set membership1.Answers: “have I seen this?”2.Good for: avoiding hard work3.Promises: no false negatives4.Sometimes: false positives (error)5.Gist: hash values of the samples are
indexes in an array of counters

30
redis> CBF.ADD bloom a(integer) 1redis> CBF.ADD bloom b(integer) 2redis> CBF.CHECK bloom a(integer) 1redis> CBF.CHECK bloom b(integer) 1redis> CBF.CHECK bloom c(integer) 0
0 1 0 21 0
h1(a), h2(a)
h1(b), h2(b)h1(c), h2(c)

31
redablooms Redis Module1.Error rate: defaults to %52.Counting: 4-bit registers, allows
removing samples, default capacity is 100,00 samples
3.Scalable: multiple filters combined4. Redis Module Hub/redablooms

32
Count Min Sketch - item counts1.Unlike Top-K:
answers about any sample2.WRT Bloom filters -
Like: hashes as indexes to countersUnlike: array per hash function, returns the minimum of counters
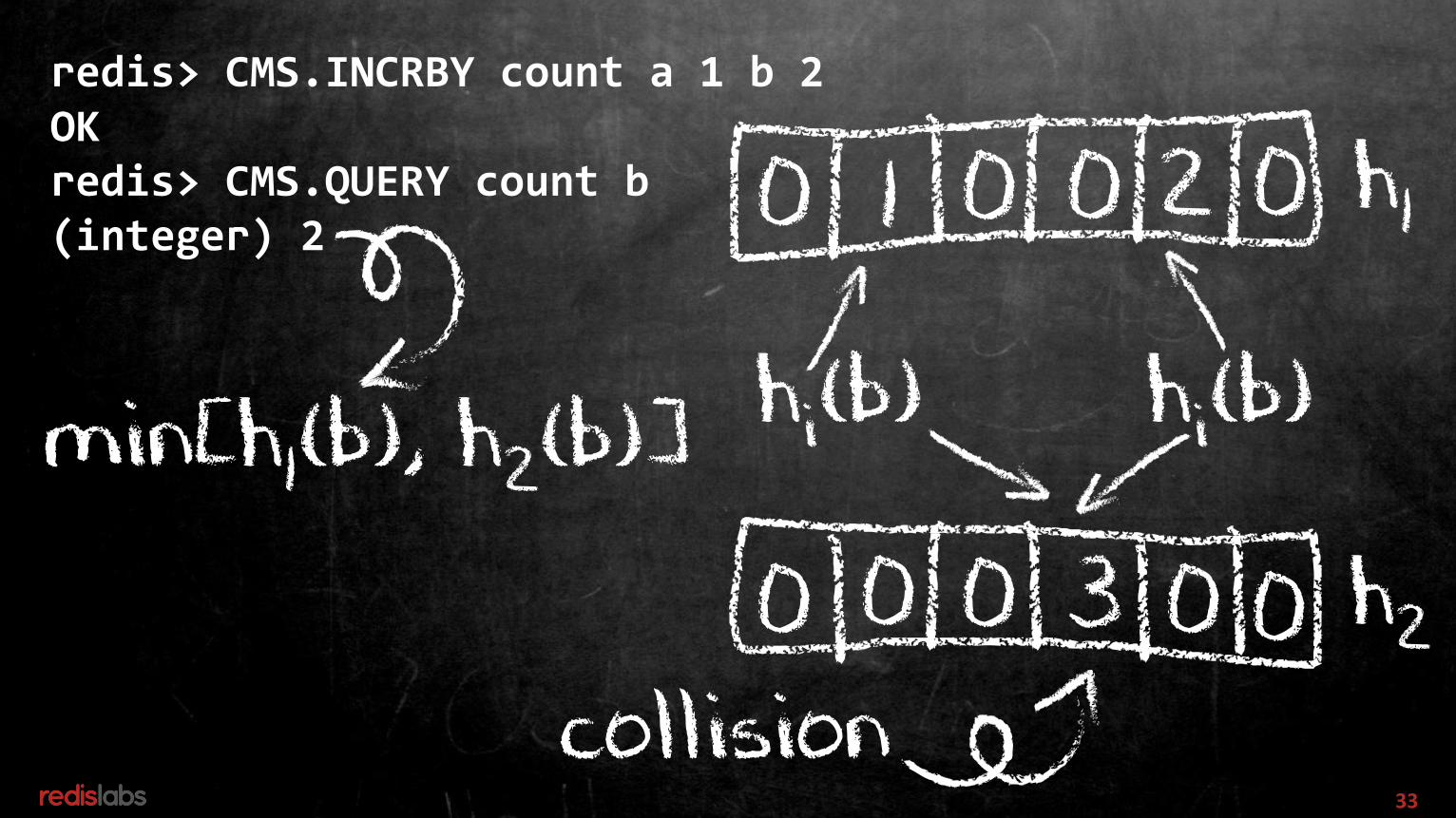
33
redis> CMS.INCRBY count a 1 b 2OKredis> CMS.QUERY count b(integer) 2
0 1 0 00 2 h1
0 0 0 03 0 h2
collision
min[h1(b), h2(b)]hi(b) hi(b)

34
countminsketch Redis Module1.Registers width: 16-bit2.Default maximum error: %0.013.Default error probability: %0.014. Redis Module Hub/countminsketch

35
redismodules.com: Redis Module Hub

36
What Is The Hub
1.Modules developed by: anyone2.Certified by: Redis Labs3.Licenses: Open Source & Commercial4.Distributed with: Redis Cloud and
Redis Labs Enterprise Cluster5.Where: redismodules.com

Thank you

Further Reading

39
1. The Redis Open Source Project Website – http://redis.io2. Redis source on GitHub – http://github.com/antirez/redis3. Redis commands documentation – http://redis.io/commands4. Infinite Improbability Drive –
https://en.wikipedia.org/wiki/Technology_in_The_Hitchhiker%27s_Guide_to_the_Galaxy#Infinite_Improbability_Drive
5. Streaming Algorithms: Frequent Items –https://people.eecs.berkeley.edu/~satishr/cs270/sp11/rough-notes/Streaming-two.pdf
6. Space/Time Trade-offs in Hash Coding with Allowable Errors –http://dmod.eu/deca/ft_gateway.cfm.pdf
7. Approximating Data with the Count-Min Data Structure –http://dimacs.rutgers.edu/~graham/pubs/papers/cmsoft.pdf

















