59
VOL. 10 Issue 1 Localisation Focus THE INTERNATIONAL JOURNAL OF LOCALISATION The peer-reviewed and indexed localisation journal ISSN 1649-2358

VOL. 10 Issue 1
Localisation FocusTHE INTERNATIONAL JOURNAL OF LOCALISATION
The peer-reviewed and indexed localisation journal
ISSN 1649-2358

Localisation FocusThe International Journal of Localisation
VOL. 10 Issue 1 (2011)
CONTENTS
EditorialReinhard Schäler .........................................................................................................3
Research articles:
An Argument for Business Process Management in LocalisationDavid Filip, Eoin Ó Conchúir………………………………......................................4
Enabling Complex Asian Scripts on Mobile Devices Waqar Ahmad, Sarmad Hussain……………………………….................................18
LocConnect: Orchestrating Interoperability in a Service-oriented LocalisationArchitecture Asanka Wasala, Ian O'Keeffe, Reinhard Schäler………………………...................29
Localisation in International Large-scale Assessments of Competencies:Challenges and Solutions Britta Upsing, Gabriele Gissler, Frank Goldhammer, Heiko Rölke, Andrea Ferrari ………………………........................................................................44

EDITORIAL BOARDAFRICAKim Wallmach, Lecturer in Translation and Interpreting, University of South Africa, Pretoria, South Africa; Translator and Project ManagerASIAPatrick Hall, Emeritus Professor of Computer Science, Open University, UK; Project Director, Bhasha Sanchar, Madan Puraskar Pustakalaya, NepalSarmad Hussain, Professor and Head of the Center for Research in Urdu Language Processing, NUCES, Lahore, PakistanMs Swaran Lata, Director and Head of the Technology Development of Indian Languages (TDIL) Programme, New Dehli, IndiaAUSTRALIA and NEW ZEALANDJames M. Hogan, Senior Lecturer in Software Engineering, Queensland University of Technology, Brisbane, AustraliaEUROPEBert Esselink, Solutions Manager, Lionbridge Technologies, Netherlands; authorSharon O'Brien, Lecturer in Translation Studies, Dublin City University, Dublin, IrelandMaeve Olohan, Programme Director of MA in Translation Studies, University of Manchester, Manchester, UKPat O'Sullivan, Test Architect, IBM Dublin Software Laboratory, Dublin, IrelandAnthony Pym, Director of Translation- and Localisation-related Postgraduate Programmes at the Universitat Rovira I Virgili, Tarragona, SpainHarold Somers, Professor of Language Engineering, University of Manchester, Manchester, UKMarcel Thelen, Lecturer in Translation and Terminology, Zuyd University, Maastricht, NetherlandsGregor Thurmair, Head of Development, linguatec language technology GmbH, Munich, GermanyAngelika Zerfass, Freelance Consultant and Trainer for Translation Tools and Related Processes; part-time Lecturer, University of Bonn,GermanyNORTH AMERICATim Altanero, Associate Professor of Foreign Languages, Austin Community College, Texas, USADonald Barabé, Vice President, Professional Services, Canadian Government Translation Bureau, CanadaLynne Bowker, Associate Professor, School of Translation and Interpretation, University of Ottawa, CanadaCarla DiFranco, Programme Manager, Windows Division, Microsoft, USADebbie Folaron, Assistant Professor of Translation and Localisation, Concordia University, Montreal, Quebec, CanadaLisa Moore, Chair of the Unicode Technical Committee, and IM Products Globalisation Manager, IBM, California, USASue Ellen Wright, Lecturer in Translation, Kent State University, Ohio, USASOUTH AMERICATeddy Bengtsson, CEO of Idea Factory Languages Inc., Buenos Aires, ArgentinaJosé Eduardo De Lucca, Co-ordinator of Centro GeNESS and Lecturer at Universidade Federal de Santa Catarina, Brazil
PUBLISHER INFORMATIONEditor: Reinhard Schäler, Director, Localisation Research Centre, University of Limerick, Limerick, IrelandProduction Editor: Karl Kelly, Manager Localisation Research Centre, University of Limerick, Limerick, IrelandPublished by: Localisation Research Centre, CSIS Department, University of Limerick, Limerick, Ireland
AIMS AND SCOPELocalisation Focus – The International Journal of Localisation provides a forum for localisation professionals and researchers to discuss andpresent their localisation-related work, covering all aspects of this multi-disciplinary field, including software engineering, tools and technologydevelopment, cultural aspects, translation studies, project management, workflow and process automation, education and training, and details ofnew developments in the localisation industry. Proposed contributions are peer-reviewed thereby ensuring a high standard of published material.Localisation Focus is distributed worldwide to libraries and localisation professionals, including engineers, managers, trainers, linguists, researchersand students. Indexed on a number of databases, this journal affords contributors increased recognition for their work. Localisation-related papers,articles, reviews, perspectives, insights and correspondence are all welcome.
Subscibers to the print edition of Localisation Focus - The international journal of Localisation can access an archive of past issues online.
Subscription: To subscribe to Localisation Focus - The International Journal of Localisation www.localisation.ie/lf
Copyright: © 2011 Localisation Research CentrePermission is granted to quote from this journal with the customary acknowledgement of the source.Opinions expressed by individual authors do not necessarily reflect those of the LRC or the editor.
Localisation Focus – The International Journal of Localisation (ISSN 1649-2358) is published and distributed annually and has been publishedsince 1996 by the Localisation Research Centre, University of Limerick, Limerick, Ireland. Articles are peer reviewed and indexed by majorscientific research services.

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
Localisation is now firmly established as anacademic discipline and part of the academic canon.It is time to take stock, to look back over the 16 yearsof work of the Localisation Research Centre at theUniversity of Limerick, the large body of academicpublications now available in our discipline, and toventure a view into the future. Social Localisation,driven by users rather than enterprises, will certainlybecome a defining part of this future. Mobile devicesand languages not known in mainstream localisationtoday will require a radical change in the way weperceive localisation. Mapping out andunderstanding the processes underlying thesechanges will become paramount.
In their contribution, David Filip and Eoin ÓConchúir present a strong argument for the use ofBusiness Project Management in Localisation. Theypresent three case studies to illustrate how BPM canhelp us to understand and meaningfully react to theconstantly evolving state of localisation and theemerging and powerful evolution of user-drivenlocalisation. The use cases cover the contentauthoring business logic of WordPress, the traditionallocalisation process used by large, medium and smallenterprises, and the localisation process deployed bynonprofit businesses.
The explosive growth of wireless networks andmobile devices in emerging markets and developingregions of the world have opened up new avenues forlocalisation. More than ever before, localisers need tounderstand the specific challenges and problemsassociated with mobile device localisation – and,specifically, those requiring the enabling of complexAsian scripts. Waqar Ahmad and Sarmad Hussainhighlight the need for making mobile devicesaccessible in the local languages (and scripts) of thegrowing user population in Asia and in domains asdiverse as education, health, entertainment, business,sports, and social networks. Their contribution,Enabling Complex Asian Scripts on Mobile Devices,reports on the successful deployment of an opensource rendering engine, Pango, on the Symbianplatform for Urdu, Hindi, and Khmer.
Interoperability is one of the areas in localisation
3
FROM THE EDITOR
research that probably attracted most attention in2011, especially in the context of the increasedtraction of the XML-based Localisation InterchangeFile Format, XLIFF, among both academic andindustrial researchers, as indicated by the highlysuccessful and now well-established series of XLIFFSymposia. Asanka Wasala, Ian O’Keeffe, andReinhard Schäler report on OrchestratingInteroperability in a Service-oriented LocalisationArchitecture using LocConnect within a service-oriented architecture (SOA) framework.
A team from the German Institute for InternationalEducational Research and cApStAn LinguisticQuality Control cover an area of research that hasbeen largely unreported in the literature and atlocalisation events, namely the challengesencountered, and the solutions provided byresearchers and practitioners working on thelocalisation of International Large-scale Assessmentsof Competencies. Britta Upsing, Gabriele Gissler,Frank Goldhammer, Heiko Rölke, and Andrea Ferraritake the Programme for International StudentAssessment (PISA) and the Programme for theAssessment of Adult Competencies (PIACC) as anexample and describe how their groups dealt with thespecific challenges in this brand-new area ofinternationalisation and localisation.
In 2012, this journal will expand its reach in Africareporting on the significant localisation activitiestaking place on this exciting continent. In addition,we will work on a thorough survey of research inlocalisation, providing easy access to the body ofwork now available.
Finally, on behalf of the editorial team, I would liketo thank the Centre for Next Generation Localisation(CNGL) for its generous support, and the more than20 international members of our editorial board fortheir continued and enthusiastic assistance to developand grow Localisation Focus – The InternationalJournal of Localisation, the world’s first peer-reviewed and indexed academic journal inlocalisation.
Reinhard Schäler

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
An Argument for Business Process Management in LocalisationDr. David Filip, Dr. Eoin Ó Conchúir
Centre for Next Generation Localisation,Localisation Research Centre,
CSIS Department,University of Limerick,
Irelandwww.cngl.ie
[email protected], [email protected]
AbstractEnterprise-level translation management systems cater well for their well-defined use cases. With the rise of user-generated content, the world of localisation is extending to include what we term as 'self-service' localisation. Thelocalisation needs of this emerging environment may differ from more traditional enterprise-level scenarios. In thispaper, we present an argument for using business process management (BPM) to help us better understand anddefine this emerging aspect of localisation, and we explore the implications of this for the localisation industry.Modelling a business process allows for that process to be managed and re-engineered, and the changes inefficiency quantified. It also helps to ensure that automated process aids and electronic systems are put in place tosupport the underlying business process, matching the real needs of its stakeholders. In this paper, we specificallylook at emerging self-service localisation scenarios in the context both of the evolution of the traditional industryprocess as well as in the context of not-for-profit localisation.
Keywords: : business process management, BPM, modelling, user-generated content, self-service localisation
4
1. Acronyms Used and Basic Definitions1
BI - Business Intelligence. The process andtechnology of organising and presenting businessprocess data and meta data to human analysts anddecision makers to facilitate critical businessinformation retrieval.
Bitext - a structured (usually mark up languagebased) artefact that contains aligned source (naturallanguage) and target (natural language) sentences.We consider Bitext to be ordered by default (such asin an XLIFF file - defined below, an "unclean" richtext format (RTF) file, or a proprietary databaserepresentation). Nevertheless, unordered Bitextartefacts like translation memories (TMs) orterminology bases (TBs) can be considered specialcases of Bitext or Bitext aggregates, since the onlypurpose of a TM as an unordered Bitext is to enrichordered Bitext, either directly or through training aMachine Translation engine.
Bitext Management - a group of processes thatconsist of high level manipulation of ordered and/orunordered Bitext artefacts. Usually the end purposeof Bitext Management is to create target (naturallanguage) content from source (natural language)content, typically via other enriching BitextTransforms, so that Bitext Management Processesare usually enclosed within a bracket of sourcecontent extraction and target content re-importation.
Bitext Transformation - Similar to BitextManagement, but the Bitext is enriched with newlycreated or manually modified target content. Theagents in Bitext Transformation may be both man andmachine, or any combination of the two.
BOM* - Bill of Materials
BPM - Business Process Management
CAT* - Computer Aided Translation
1For standard localisation industry acronyms see MultiLingual 2011 Resource Directory (MultilLingual 2011). Such standard industry terms aremarked with an asterisk (*). We also give short definitions for terms that may be considered commonplace to prevent misunderstanding.

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
ESB - Enterprise Service Bus, an open standards,message-based, distributed integration infrastructurethat provides routing, invocation and mediationservices to facilitate the interactions of disparatedistributed applications and services in a secure andreliable manner (Menge 2007).
HB - Hand Back. This is being used systematically intwo related meanings, either as the message/materialconformant to a related HO BOM, leaving anorganisation/swimlane as response to the HO, or thelast process/subprocess that happens before thecorresponding pool-crossing flow.
HO - Hand Off. This is being used systematically intwo related meanings, either as the message/materialleaving an organisation/swimlane to solicit aresponse conformant with its BOM, or the lastprocess/sub-process that happens before thecorresponding pool-crossing flow.
IS - Information System
LSP* - Language Service Provider
Man - used as synonymous with human, not male,such as for 'man-hours'.
Message - the token in an ESB facilitated workflowor generally any SOA driven workflow. Messages arebeing enriched as they travel through workflows.
MLV* - Multilanguage Vendor, a type of LSP.
NFP - Not-for-profit
Process - procedure consisting of logically connectedsteps with predefined inputs and outputs.
SLV* - Single Language Vendor, a type of LSP.
SMB* - small and medium-sized businesses
SOA - Service Oriented Architecture, an architectureconcept which defines that applications provide theirbusiness functionality in the form of reusableservices (Menge 2007).
Swimlane - Pool and Lane as used in BPMN not insports.
TM* - Translation Memory
TMS* - Translation Management System
Token - whatever travels through a defined processor workflow. Each token instantiates the process orworkflow. In this sense, multiple instances of aworkflow are created not only as different tokensentering the predefined processing but also at anypre-defined point in the workflow or process wheretokens are split according to business rules.
Workflow - an automated process. This is not acommonplace distinction, but we coin it for practicalconvenience.
XLIFF* - OASIS XLIFF, i.e. XML LocalizationInterchange File Format. We mention XLIFF in itscapacity as a token in localisation processes and as amessage being enriched in an ESB or SOA basedworkflow.
XOR - exclusive OR, logical connective. Used hereto characterise the exclusive gate in modelling, asused in BPMN (2011).
2. Introduction
In its essence, localisation is driven by users'preferences to access information in their nativelanguage, and this is no different for informationbeing presented online (Yunker 2003). In thecorporate context, this has lead to companiesproviding localised versions of their websites, forexample (Jiménez-Crespo 2010).
Meanwhile, with the widespread availability of 'Web2.0' platforms, it is not only corporations themselvesthat are producing localisable and localised content(O'Hagan 2009). For example, fans of certainpublications (in this case, comics) have producedunsolicited user-generated translations in acollaborative manner (O'Hagan 2009). Indeed, user-generated content (be it opinions or otherwise) isnothing new, although the possibility to workcollaboratively online is relatively new. Theinvolvement of online communities in translation hasevolved to become solicited user-generatedtranslations. This general concept of leveraging thelatent talent of the crowd, particularly online, wascoined as crowdsourcing (Howe 2006).
The shift in how content is being transformed in thelocalisation and translation world has been termedthe "technological turn" (Cronin 2010). With respectto content distribution, Cronin argues that the mostnotable change has come in the form of electronicwork station PCs being gradually replaced by the use
5

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
of distributed mobile computing. This transition isleading to Internet-capable devices becomingubiquitous. Rather than localisation being driven bythe need to produce static centrally-created content,the emergence of user-generated content is leading tothe localisation of user-generated content intopersonalised, user-driven content. Internet-connectedplatforms present the potential of collaborative,community translations. This is in contrast to thecommercial option of translation through employedtranslators, freelance translators, or the use of alocalisation vendor to act as an intermediary.
While enterprise-based localisation of content andsoftware, being produced in-house, is a matureprocess with quality assurance certificationsavailable (Cronin 2010), the involvement of onlinecommunities (or the "crowd") in localisation is arelatively newer field. Similar to the concept of "opensourcing", the crowdsourcing of localisation isoutsourcing the tasks involved to an "unknownworkforce" (Ågerfalk and Fitzgerald 2008). Weassume that in such a context, contractual agreementsmay not be in place with members of the community.Rather than being able to agree binding deadlineswith paid translators, community members may offerto work on translation tasks on a whim (depending onthe process put in place).
In this paper we argue that the evolved state oflocalisation is yet to be fully understood. Indeed,there is a constant evolution of how the concept ofuser-driven translation can be applied in real-worldsituations.
In the following sections, we argue that the activity ofbusiness process management (BPM) is a valuabletool for allowing us to understand the newrequirements of information systems involving user-generated content and user-provided translations. Inlater sections, we present three case studies toillustrate how BPM may be applied, and what mayhappen if the underlying business processes are notcorrectly incorporated into a new informationsystem. Finally, we conclude that given theadvancement of self-service localisation, even in thecorporate context, such emergent business processescan be better addressed through BPM.
3. New Business Processes, and Business ProcessManagement
On the subject of newly-emerging business processesin localisation, we must define how a certain block of
content to be localised will be ultimately used. Toillustrate this point, let us compare the difference inexpectations between the localised version of acorporate brochure when contrasted with that samecorporation's desire to localise its ongoing socialmedia stream for different locales. With the formerexample, we may expect very formal and accuratelanguage, whereas the latter may allow for a moreinformal approach. A further distinction may be madebetween relatively informal content being producedby a corporation and useful customer-generatedcontent that may benefit other customers of differentnative languages. An example of this would be adescriptive forum message, posted online by acustomer, providing a solution to an issue with acompany's product. Indeed, translation quality is amultidimensional concept that can be approached indifferent ways including process-orientedinternational standards, or more community-basedlocalisation (Jiménez-Crespo 2010).
To illustrate that point, we present Table 1. The tableshows how content coming from different sourcesmay be localised using different approaches. Theupper-left quadrant may be seen as the traditionalroute taken in localisation. Such business processesare the main focus of translation managementsystems. The upper-right quadrant may be too costlycompared to the value it produces, since a constantstream of user-generated content may overwhelmtraditional localisation processes. Indeed, companiesare presented with the emerging choice of facilitatingtheir online community in localising content that hasbeen produced by their peers. The lower twoquadrants are of particular interest, as it is here that acommunity of translators (the "unknown workforce")may be asked to help with the localisation of content.It should be noted that volunteer translators are notnecessarily individuals donating their free time, butalso representatives of external organisations whowould benefit from having the content made
6
Traditionally-generated content
User-generatedcontent
Traditional contentlocalisation
Localisation ofcorporate-controlledcontent by a paidcontracted entity(such as alocalisation serviceprovider).
Localisation of user-generated content bya paid contractedentity (such as alocalisation serviceprovider).
User-driven contentlocalisation
Localisation ofcorporate-controlledcontent by volunteercommunitymembers.
Localisation of user-generated content byvolunteercommunitymembers.
Table 1: Both in-house and community-generated content may be localised byeither commercial localisation vendors or by the community itself.

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
available in their primary language.
Focusing on any of these four quadrants in Table 1presents us with different business processes beingrepresented. For example, a system allowing for ad-hoc volunteer translations of short social mediamessages may have quite different requirements to asystem involving tightly-controlled contractedfreelance translators. In the following sub-section,we argue that it is critical that the underlying businessprocesses be closely matched by the functionality ofelectronic systems designed to support them. Weexplain how a mismatch in information technology(IT) strategy with information systems (IS) strategyalong with business strategy may lead to practicalfailure of the system being produced.
3.1 Information Systems PerspectiveIn the localisation context, a "system" may be thesocio-technical entity that supports traditionalenterprise-based localisation, or a user-drivenlocalisation scenario. To discuss how systems may bedesigned to cater for any particular permutation ofthe localisation process, we must first address thenature of a system itself. In information systemstheory, the "system" does not merely refer to acomputing machine such as a personal computer(PC). Neither does it refer simply to a softwareapplication (large or small, TMS, ESB etc.) designedto facilitate certain operations. Rather, we view aninformation system as a socio-technical entity,similar to Galliers (2004).
An information system is comprised of theinformation being processed and produced, alongwith the organisational context of its users and otherstakeholders. An information system designed toencompass a socio-technical environment wouldcombine information and knowledge sharing servicesthat would facilitate both the exploration andexploitation of knowledge (Galliers 2006).
A long-standing view of information systems is thatthe activities falling under informationcommunications technology (ICT) developmentmust be closely aligned to the information system asa whole, which in turn must be aligned to theorganisation's business strategy (Galliers 2006). Amisalignment between these concepts or activitiesmay lead to a failed system. A failure does notnecessarily imply that the system itself does notfunction (Laudon and Laudon 1996). For example, asystem may be perceived as failed if it has not beensuccessfully adopted by its intended user base, even
if the system itself runs "as designed". In this paper,technology underlying localisation including CATtools and Translation Management Systems (TMS) isdiscussed from this broader IS perspective. As such,they need to be aligned with business objectives.
3.2 Business Process Management (BPM)A business process is a ''set of partially orderedactivities intended to reach a goal'' (Hammer andChampy 1993). Relating this to localisation, a high-level business process may be taking a mono-lingualtechnical manual and all the steps required toadapting it to various target locales. Similarly, abusiness process may describe the activities requiredto produce a community-based localisation project.In localisation specifically, Lenker et al (2010) arguethat by abstracting a localisation business process asa workflow, the process can be potentially automatedand its efficiency improved. Business processes maybe quite low-level, with a large organisation beingcomprised of thousands of such processes (Turban etal 1993).
Formally, a process is seeded with inputs, and itproduces outputs. Thus, the output of a process canbe measured. This is an advantageous approach,since measurements of process efficiency allow us totweak the process and measure the consequences.BPM thus provides a structured framework forunderstanding the business process itself, and thenoptimising that process.
3.3 Modelling Business ProcessesAn information system may be developed to improvethe current workings of an organisational unit, or itmay be conceived to support an entirely new set ofbusiness activities. In either case, we may analyse theunderlying business activities, producing conceptualmodels of the activities.
Modelling a business process is the act of formallydescribing the business processes at hand. Manybusinesses have process models of their systems(Cox et al 2005). Once contextual information hasbeen elicited about the socio-technical system, andexplicitly described through business processmodelling, an understanding of what problems needto be solved should emerge (Cox et al 2005).
Business processes can be captured in a standardlanguage, that being Business Process Model andNotation (BPMN, formerly also known as BusinessProcess Modeling Notation). It is maintained by theObject Management Group (OMG). It offers an
7

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
extensive standard modelling framework, readilyunderstandable by business people, includinganalysts and technical developers (BPMN 2011).Models recorded in this manner allow for thebusiness processes to be modelled while abstractingfrom actual implementation details. This provides astandardised way of communicating processinformation to other business users, processimplementers, customers, and suppliers.Requirements engineering approaches can be appliedto BPM, such as employing role activity diagrams(Bleistein et al 2005).
By taking a set of models produced in a standardmodelling language, BPM can let us carry outbusiness process improvement through businessprocess re-engineering. Software tools allow theanalyst to work on the business process models inorder to produce an optimised set of processes,ultimately improving the workings of theorganisation.
4. Case studies
In this section, we present a number of case studies todemonstrate the concepts behind BPM, and how theymay be applied to localisation. These case studies arethen compared and contrasted in the followinganalysis and discussion section.
BPM, in essence, deals with understanding thebusiness processes of an organisation. The concept ofan organisation here is a socio-technical grouping ofpeople and systems. In order to manage any businessprocess, it is necessary to understand the participantsin the system, the activities taking place in thesystem, and the message flow of informationthroughout the system (BPMN 2011). For example,Lewis et al (2009) analyse the set of activities andcommunication mechanisms involved in a traditionallocalisation workflow, and use this to understandnewer community-based approaches to localisation.First, though, we present a simple example of a
system that supports the business logic of contentcreation.
4.1 Case Study 1: Content authoring businesslogic encapsulated by WordPressWith the advent of the World Wide Web in the early1990s, content publishers (both individuals andorganisations) were presented with a new opportunityto publish their content. At its most basic, text contentcan be published online as a hypertext mark-uplanguage (HTML) document by uploading it to a webserver. The document can contain static content, andso is limited in how it can encapsulate the businesslogic of a more complex content system. Aninformation system may be represented somewhat byinterlinking static HTML documents. More likely,however, is the need to support the business logicthrough dynamic server-side scripting which wouldoutput HTML documents generated on the fly.
By the late 1990s, a trend in personal web pages wasto publish a 'log' of web sites found by the web pageowner, in chronological order. Yet, by that stage,most web loggers (who became known as 'bloggers')hand-coded their web sites. No tools were publiclyavailable that would support the requirement ofdynamically publishing a series of links to a webpage (Blood 2004).
In 1999, a free web logging system called Blogger(http://www.blogger.com) was launched with the tag"Push-button publishing for the people". Thesimplicity of the system made it very popular, withnon-technical users beginning to use the web loggingplatform simply as a way to publish their thoughtsand opinions online, without necessarily any links inthe published post (Blood 2004). This was the birthof the blog post format.
At the time of writing this paper, WordPress(http://www.wordpress.org) is one of several popularopen-source blogging systems, having first beenreleased in 2003. Perhaps due to the platform's ease
8
Figure 1: Single-user content authoring and publishing as supported by WordPress.

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
of use, but moreover its direct addressing of thebusiness logic required by bloggers, the platform hasgained a wide user base. WordPress has been adoptedby individual bloggers and large organisations alike,such as the popular technology blog TechCrunch(http://www.techcrunch.com) and Forbes' blognetwork (http://blogs.forbes.com/) (WordPress2011a).
Figure 1 illustrates the simplest content publishingworkflow offered by WordPress. Note that we makeuse of Business Process Modelling and Notation(BPMN) for the illustrations in this paper. Thisallows for an abstracted understanding of theunderlying business process.
WordPress is a dynamic server-side platform thatencapsulates the business process of publishing andmanaging content online as an individual or as a teamof content authors. It does so by supporting theactivities of content creation, reviewing, editing, andpublishing. WordPress supports the user roles ofSuper Admin, Administrator, Editor, Author,Contributor and Subscriber (WordPress.org 2011b).A team of content authors may assign these differentroles to different people to manage the publishingprocess. For example, the Contributor role allowsthat person to author and edit their own content, butnot publish it to the blog. An Author user has thesame abilities, in addition to being able to publishtheir own content. Notably, the Editor role can createcontent, manage their content and others' content,and choose to publish others' content (it is beyond thescope of this article to further describe in detail theroles and capabilities offered by WordPress).
Figure 2: The business process of a Contributor submitting a post,and an Editor publishing that post, as supported by WordPress.
In summary, the system encapsulates the roles andactivities required for publishing content online. Thebusiness process (the set of activities involved inauthoring, editing and publishing online content) isclosely matched by the action-centric functionality ofthe WordPress system. In this case, business processmanagement may be used to understand theunderlying business process, to model it, and totweak it. By illustrating this specific case study of acontent management system, we argue moregenerally that BPM is a worthy approach forunderstanding the underlying business process, andthus making it more likely that the system beingdeveloped will align more closely with actualrequirements.
4.2 Case Study 2: The traditional industrylocalisation process in the industry, enterprise andSMB contextFigure 3 illustrates a high level model of theenterprise localisation process. Each of the high levelprocesses represented by blocks in the figure wouldneed to be defined in further levels of granularity inorder to be relevant for real implementations. Themodel is nevertheless useful as a high-levelrepresentation. It is helpful for showing the mostimportant process differences at the relevant level ofcomplexity. In this paper we only include models thatcan be quickly understood at first glance, for severalreasons:
1) To illustrate points made about processdifferences occurring in different localisationsettings.
2) To illustrate how the BPMN standard can be usedto create pictorial representations facilitatingprocess discussion in a highly intuitive way.
9

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
The model in Figure 3 anchors the localisationprocess in the broader context of multilingual contentmanagement and publishing. Content is being createdspecifically in one language, in the sense that a singlepiece of information can only be conveyedpractically in one language at a time. The publisher,however, needs to publish its information in manylanguages. As the transitions from the creation in onelanguage to multiple languages in publishing alwaysinclude transformations specific to the language pair,we have labelled the intermediate steps as "BitextManagement". Bitext Management is the centralpiece of any localisation process. In fact, BitextManagement forms the fundamental distinctionbetween localisation processes in different contextsin terms of whom, where, and how it is executed.
In contrast, Small and Medium Businesses usuallylack the resources needed to take control of theirtranslation memory leveraging. They are usuallyunable to manage their Bitext on their own.Therefore, although localisation customers legallyretain rights to their bilingual corpora, in practicetheir Bitext Management is a black box for themwhich is managed by a long term LSP partner.
In summary, BPMN has allowed us to visuallyrepresent the high-level business processes of BitextManagement for enterprises (Figure 3) and SMBs(Figure 4). It helps to demonstrate that the primarydistinction between both cases is whether the"Manage Bitext" activity happens in-house, or is theresponsibility of an LSP.
10
Figure 3: The localisation process in the enterprise context covering content management and publishing.
Figure 4: The management of Bitext is usually performed by an LSP partner for an SMB.
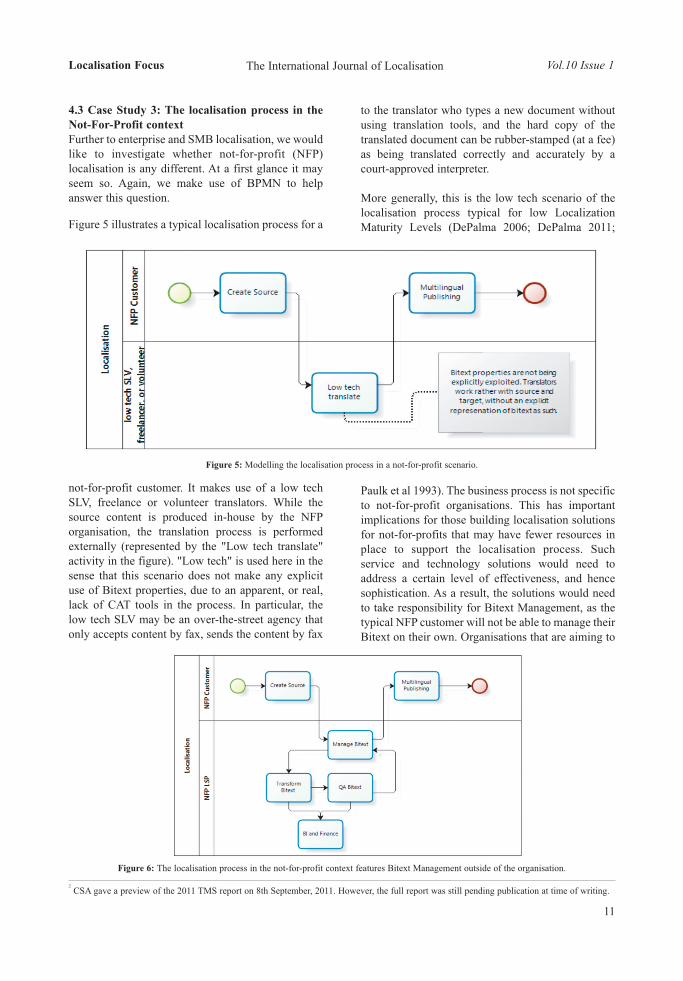
4.3 Case Study 3: The localisation process in theNot-For-Profit contextFurther to enterprise and SMB localisation, we wouldlike to investigate whether not-for-profit (NFP)localisation is any different. At a first glance it mayseem so. Again, we make use of BPMN to helpanswer this question.
Figure 5 illustrates a typical localisation process for a
not-for-profit customer. It makes use of a low techSLV, freelance or volunteer translators. While thesource content is produced in-house by the NFPorganisation, the translation process is performedexternally (represented by the "Low tech translate"activity in the figure). "Low tech" is used here in thesense that this scenario does not make any explicituse of Bitext properties, due to an apparent, or real,lack of CAT tools in the process. In particular, thelow tech SLV may be an over-the-street agency thatonly accepts content by fax, sends the content by fax
to the translator who types a new document withoutusing translation tools, and the hard copy of thetranslated document can be rubber-stamped (at a fee)as being translated correctly and accurately by acourt-approved interpreter.
More generally, this is the low tech scenario of thelocalisation process typical for low LocalizationMaturity Levels (DePalma 2006; DePalma 2011;
Paulk et al 1993). The business process is not specificto not-for-profit organisations. This has importantimplications for those building localisation solutionsfor not-for-profits that may have fewer resources inplace to support the localisation process. Suchservice and technology solutions would need toaddress a certain level of effectiveness, and hencesophistication. As a result, the solutions would needto take responsibility for Bitext Management, as thetypical NFP customer will not be able to manage theirBitext on their own. Organisations that are aiming to
Localisation Focus Vol.10 Issue 1The International Journal of Localisation
11
2CSA gave a preview of the 2011 TMS report on 8th September, 2011. However, the full report was still pending publication at time of writing.
Figure 5: Modelling the localisation process in a not-for-profit scenario.
Figure 6: The localisation process in the not-for-profit context features Bitext Management outside of the organisation.

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
support not-for-profit localisation may - in effect -emulate the SMB localisation model, at least at thishigh structural level. Figure 6 illustrates this finding.
One may therefore come to the conclusion that thereis no difference between the traditional localisationprocess (Figure 4) and the not-for-profit model(Figure 6). However, in section 5.3 we describe whythis is actually not the case.
5. Case Study Analyses
In the previous sections, we presented three casestudies by modelling the relevant business processes.Some comparisons were made between the casestudies. In this section, we discuss how the existinglocalisation solutions address the above describedscenarios and present further conclusions arisingfrom the analysis of these case studies.
Localisation platforms, such as CAT tools andTranslation Management Systems (TMS), docurrently exist and primarily address the traditionalenterprise localisation process. We wish tounderstand the level and nature of impact of nextgeneration localisation factors that we see arisingwith the inclusion of crowd sourcing concepts. To doso, we need to discuss the role of CAT tools andTMSs in the localisation-enabling InformationSystems (IS).
5.1 The role of current platforms in addressinglocalisation business needsSince 2006, Common Sense Advisory (CSA) hasbeen publishing an authoritative comparison oftranslation management systems (TMSs) (Sargentand DePalma 2007 and 2008). As there has not beena comprehensive report since 2008 (only individualTMS scorecard additions have been published)2, the2008 report still serves to define classifications andgroupings. Our classification in this paper drawsloosely from the CSA classification.
The most prestigious category according to CSA isthe Enterprise TMS (ETMS) or "cradle to grave"systems. These systems are expected to be enterprise-class information and automation systems. Manyplayers have been trying their luck in this category.The initiator and long time leader of this category hadbeen Idiom WorldServer (now SDL WorldServer),which, even today, remains unparalleled in theexpressivity of its workflow engine within the classof ETMSs. However, this class of TMSs is beingrendered largely obsolete due to the present-day
development of general enterprise architecture, interms of business need and development.
It has been noted (Sargent and DePalma 2008;Morera et al 2011) that localisation automationsystems have been successful in narrowingpermissible workflow complexity in building aparticular production workflow. Complexity hererefers, roughly, to the number of the classicalworkflow patterns (van der Aalst et al 2003; Moreraet al 2011).
TMSs can be considered as highly specificautomation systems, and different categories ofTMSs may be distinguished by their level ofspecificity for localisation workflow support. Part oftheir success is in simplification relative to traditionalindustry patterns.
For instance, most of the existing systems are hardwired for a single source language per project. Thismeans that they will be challenged by multiple sourcelanguages scenarios that play an increasinglyimportant role. The reason that current solutions havebeen built to cater exclusively for a single sourcelanguage scenario is that most of the currententerprise-class localisation processes actuallynormalise to a single source language, very oftenEnglish, especially in multinationals. Even Asian andGerman-based multinationals, that would often try touse their local languages as the source languages, areforced to use English due to outside forces. Suchforces would include the present state of the marketand procurement necessities such as economies ofscale. If English is not used as a source language, itstill tends to be used as a pivot language, throughwhich all content is translated. In the following,however, we leave aside the complexities ofmanaging multiple source languages.
The least capable, in terms of building complexautomation workflows, would be the category of TMServers. The capabilities of TM Servers in the area ofautomation can range from a simple automatedsegment pair lifecycle through to a predefined set ofstates that each pair can retain throughout its life, allthe way from 'new', through to 'revised' and to'deprecated'. Every product in this category managesto automatically search and retrieve relevantterminology, both for full and fuzzy matches.
However, this capability has been commonplace inour industry for so long that it is not even considered"automation". It is, indeed, a level of automation that
12

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
can be taken for granted thanks to the nativefunctionality of computer aided translation (CAT)technology and is usually not enhanced to a greatdegree by server-level products (apart from theapparent advantages of committing to a regularlybacked up well-resourced database, compared to alocally installed database or a local proprietarydatabase file).
In fact, many tools that had been working withoutissue locally or through local area networks (LAN)had maturity challenges when introducing orperfecting their server-based product. The leader inthis capability has, so far, been the LionbridgeTranslation Workspace that is offered through theGeoWorkz.com portal (originally known asLogoport).
We see a tension between the interests of large LSPsin attempting to control the technology space, whilecustomers seek to avoid technology lock-in. Thereare repercussions of this tension for the LSP world.An LSP may have a significant number ofstakeholders. Various types of LSPs exist rangingfrom mutually-coordinated freelancers, to bricks-andmortar SLVs, through to large multimillion so-calledMLVs competing for a place on the CSA beautycontest ladder (Kelly and Stewart 2011).
The standardisation driven by enterprises will beexploited downwards and we expect that this willlead to the language industry becoming even morestrategic, yet even more commoditised. We predictthat there will be no differentiator for SLVs except
for resource management. MLV competition willbecome even fiercer as the standardised SOA andESB based architecture will drive the cost of entryeven lower. Cyclically, the MLVs will need to dealwith large enterprises taking Bitext Management andother value added high margin services in house,forming specialised service units such as Oracle'sIreland based WPTG (Worldwide ProductTranslation Group).
5.2 Adoption of Crowdsourcing in LocalisationThe democratisation of the Web has emerged throughthe power of the "crowd". This trend has also beenincreasingly applied to the localisation process wherethe concept of crowdsourcing has seen members ofthe crowd performing localisation tasks, such astranslation and reviewing. There are two settings inwhich the stakeholders are ahead in embracing thisrelatively new trend:
1) Enterprises
2) Not-for-profit (NFP)
The crowd is important for both of these because ofsimilar, yet distinct, reasons. In the not-for-profit(and potentially charitable) setting, accessing acrowd of volunteers would be attractive. Crowd-sourced translation may also be attractive forenterprise, but there are significant levels ofinvestment required for supporting that throughtechnology, oversight and management. In otherwords, the return on investment (ROI) must still beproperly calculated even if engaging with an unpaidcrowd.
13
Figure 7: The chunking and reassembling activities in a typical localisation process.

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
We speculate that the motivation of the unpaid crowdmay be a distinguishing factor in next generationlocalisation. This may not be such an issue in a moretraditional paid translation context.
More specifically, volunteers may have little time tocontribute to a localisation project. The implicationof this is profound: the chunks of content presented tothem as tasks need to be much smaller than thoserequired in the traditional localisation workflow. Wediscuss this topic further in the next sub-section.
5.3 New Requirements for Bitext ChunkingFigure 7 shows the lower level models of chunkingand reassembling that we have been using in previousmodels when referring to Bitext Management.
The chunking process multiplies the tokens that aretravelling through the process in two steps. First, itcreates a token per target language. Second, it createsa token per one-man-chunk.
A process that uses chunking must also containreassembling further down the road to ensure thattokens are properly merged back (i.e. well handled).One may notice that the re-merging of target versionsinto one deliverable token is optional and more likelyto occur in an industry setting than in a not-for-profitsetting.
Using XLIFF as the message container providesbenefits as XLIFF is capable of carrying a token inthe size of thousands of files, or as small as a singletranslation unit (OASIS XLIFF 2008).
Figure 8 applies equally to the industry setting andthe not-for-profit setting. There is, however, a veryimportant parameter that governs the behaviour ofthe XOR gateway diagram. From a technicalperspective, the decision is simply based on a singleparameter.
Figure 8 represents the process of abstracting thesteps that are needed to be taken to get a certain
output, given an input. The figure does not itselfspecify whether or not the workflow process needs tobe automated in real life. The parameter is the size ofa one-man-chunk. In the paid industry setting theone-man-chunk may easily comprise effort of up tofive man-days (in case of relaxed schedules even tenman-days may count as one-man-chunks, and in theliterary translations world one person routinely dealswith effort in terms of man-months).
However not-for-profit organisations may have todeal with real life emergencies as they arise (such astsunamis, earthquakes, famines, and many other lessdramatic, yet time sensitive, issues). Therefore, theymay have very tight schedules as in the translationindustry, but seldom have the budgets to buy full-time resources.
Therefore, the one-man-chunk in the volunteeringsetting is better defined in terms of man-hours. Thefive-man-day chunk is not extraordinary forenterprise settings, but could take months for avolunteer to complete. As such, the content requires amuch higher level granularity of chunking for fastturnaround of each chunk.
Assuming that a not-for-profit project needs topublish multilingual information within a week of thecreation of the source text, and assuming that thecrowd of highly-motivated volunteers have onaverage 20% of normal full-time employment todedicate to the project, we conclude that a projectshould be chunked accordingly to blocks of fourman-hours.
In the case of more stringent deadlines, or where thecrowd is less disciplined, chunking may need to beset at two man-hours, or smaller.
Chunks smaller than one man-hour may not beeffective in practice, unless the tasks are specialised,such as for user interface translation projects.Following this discussion, we can see the typicalmodel for NFP localisation should be as illustrated in
14
3See classic discussion of workflow expressivity by Aalst et al. 2003.
Figure 8: Industry chunking is not for volunteers

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
The process illustrated in Figure 10 is structurallysimilar to traditional models. Yet, there are differentbusiness needs for the supporting technologybetween the two different scenarios. There are radicaldifferences, for example, in the availability ofresources. In the self-service scenarios that leveragecrowd-sourced translation, whether in an enterprisesupport or a charitable NFP scenario, automatedchunking, pull-driven automated assignments, andautomated reassembling are a must due to thedemand for much finer granularity of chunking. Incontrast, in the traditional bulk localisation scenariothese are only tentative activities that are oftensimply performed manually.
6. Conclusion
What is the token and/or the message in thelocalisation process? We have hinted that ideally thelocalisation ESB message should have the form of aflexibly chunkable and reassemblable Bitext. WithOASIS XLIFF, the industry has such a standard, yetevolving, format to capture industry wisdom andaddress new business needs. It is capable of carryingpayload and metadata with a wide range ofgranularities and process requirements. Through thebusiness process management practices applied inthis paper, we have found that the commondenominator of all localisation processes may be asfollows:
15
Figure 9: Automated chunking in terms of man-hours is essential for volunteering settings
Figure 10: a model of not-for-profit localisation, with further detail provided for content chunking.

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
Parsing of source text -> routing Bitext -> enrichingBitext -> quality assuring Bitext -> exporting targettext.
For performing the localisation processes in anyorganisational setting it is critical to be able to extractglobal business intelligence from most of theworkflows and processes involved.
For an enterprise, managing Bitext has alsotraditionally meant enforcing process andtechnology. We argue that this is not a priori aconsequence of including Bitext Management in theenterprise process. Rather, in the past, the enterprisemay have had to take stringent control due to the lackof standardisation in the areas of both Bitext andBitext Transformation processes.
Today many enterprise-level practitioners have seenthat enforcing process and methodology is notsustainable and/or indeed very expensive. We can seetwo complementary trends:
1) Standardisation of Bitext message, both payloadand metadata.
2) Reuse of available SOA architectures and extra-Localisation workflow solutions, namely theunderlying ESBs.
What can be used as the ESB in this case? Whilemost readily-available ESB specialised middlewarecomes to mind, it can, theoretically, be anysufficiently expressive3 workflow engine.'Theoretically' must be emphasised here, as clearlyany Turing-complete engine can do what is needed,which is, however, far from claiming that the level ofeffort needed would be practically achievable orotherwise relevant. In real life situations, manyfactors play important roles in making this decision,including but not limited to:
1) Legacy investment into and the present state ofthe overall IS in the organisation
2) Level of fitness of the current IS for the businessneeds of the organisation
3) Legacy investment into and the present state ofspecialised localisation technology
4) Importance of unified BI on localisation withinthe organisation
5) Licensing models of legacy solutions6) Long term vendor relationships
Enterprise users want to prevent lock-in and managequality on an 'as needed' basis, which very oftenapplies to string level. In fact, we see, from our casestudy analysis, the community workflow and theenterprise workflow converging.
The 21st century has seen an onslaught of service-oriented architectures, not only in the IT mainstreambut also in the localisation and translation industry.Many an industry player has realised that they nolonger wish to be locked in to a particular languagetechnology stack, and some have found theirEnterprise Service Buses relevant as potentialbackbones for what they need to achieve in the areaof localisation and translation.
It seems clear that the challenge in the localisationand translation industry is not just of processmodelling. It is rather a complex ChangeManagement issue that cannot be properly addressedwithout applying mature Business ProcessManagement techniques.
Acknowledgements
This research is supported by the Science FoundationIreland (Grant 07/CE/I1142) as part of the Centre forNext Generation Localisation (www.cngl.ie) in theLocalisation Research Centre at the University ofLimerick.
All BPMN models used in this paper were createdusing the free Bizagi Modeler Software, v2.0.0.2,which is BPMN 2 compliant.
References
Aalst, Van der, W.M.P., Hofstede, ter, A.H.M.,Kiepuszewski, B., Barros, A.P. (2003) 'Workflow Patterns',Distributed and Parallel Databases, 14, 5-51.
Aalst, Van der, W.M.P. (2004) 'Pi calculus versus Petri nets:Let us eat "humble pie" rather than further inflate the "Pihype"', unpublished.
Ågerfalk, P. J. and Fitzgerald, B. (2008) 'Outsourcing to anUnknown Workforce: Exploring Opensourcing as a GlobalSourcing Strategy', MIS Quarterly, 32(2), 385-409.
Bleistein, S., Cox, K., Verner, J. and Phalp, K. (2006)'Requirements engineering for e-business advantage',Requirements Engineering, 11(1), 4-16.
16

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
Blood, R. (2004) 'How Blogging Software Reshapes theOnline Community', Communications of the ACM, 47(12),53-55.
Brabham, D. C. (2008) 'Moving the crowd at iStockphoto:The composition of the crowd and motivations forparticipation in a crowdsourcing application', First Monday,13(6).
Business Process Model and Notation v2.0 (BPMN) (2011)Needham, Massachusetts: Object Management Group, Inc(OMG).
Cronin, M. (2010) 'The Translation Crowd', Tradumatica:traduccio i tecnologies de la informacio i la comunicacio, 8,December 2010.
Cox, K., Phalpc, K. T., Bleisteina, S. J. and Vernerb, J. M.(2005) 'Deriving requirements from process models via theproblem frames approach', Information and SoftwareTechnology, 47(5), 319-337.
DePalma, D.A. (2006) Localization Maturity Model,Lowell: Common Sense Advisory, 16 August.
DePalma, D.A. (2011) Localization Maturity Model 2.0,Lowell: Common Sense Advisory, 28 March.
Galliers, R. D. (2004) 'Reflections on Information SystemsStrategizing', in Avgerou, C., Ciborra, C. and Land, F., eds.,The Social Study of Information and CommunicationTechnology: Innovation, Actors, and Contexts, Oxford:Oxford University Press, 231-262.
Galliers, R. D. (2006) 'On confronting some of the commonmyths of Information Systems strategy discourse', inMansell, R., Quah, D. and Silverstone, R., eds., The(Oxford) Handbook of Information and CommunicationTechnology, Oxford: Oxford University Press.
Hammer, M. and Champy, J. (1993) Reengineering thecorporation: a manifesto for business revolution, New York:HarperBusiness.
Howe, J. (2006) 'The rise of crowdsourcing', Wired, 14(6),available: http://www.wired.com/wired/archive/14.06/crowds.html [accessed 4 July 2011].
Jiménez-Crespo, M. A. (2010) 'Web Internationlisationstrategies and translation quality: researching the case of"international" Spanish', Localisation Focus, 9(1), 13-25.
Kelly, N., Stewart, R.G. (2011) The Top 50 LanguageService Providers, Lowell: Common Sense Advisory, 31May.
Laudon, K.C. and Laudon, J.P. (1996) ManagementInformation Systems: Organization and Technology,Englewood Cliffs: Prentice-Hall.
Lenker, M., Anastasiou, D. and Buckley, J. (2010)'Workflow Specification for Enterprise Localisation',Localisation Focus, 9(1), 26-35.
Lewis, D., Curran, S., Doherty, G., Feeney, K., Karamanis,N., Luz, S. and McAuley, J. (2009) 'Supporting Flexibilityand Awareness in Localisation Workflow', LocalisationFocus, 8(1), 29-38.
Menge, F. (2007) 'Enterprise Service Bus', Free and OpenSource Software Conference 2007 (FOSS4G), Victoria,Canada, 24-27 September.
Morera, A., Aouad, L, Collins, J.J. (2011) 'AssessingSupport for Community Workflows in Localisation',accepted for 4th Workshop on Business ProcessManagement and Social Software (BPMS2'11), August.
MultiLingual (2011) MultiLingual 2011 ResourceDirectory, Sandpoint: MultiLingual, available:https://www.multilingual.com/downloads/2011RDPrint.pdf[accessed 1 August 2011].
OASIS XLIFF 1.2 (2008) Oasis, available:http://docs.oasis-open.org/xliff/v1.2/os/xliff-core.html[accessed 2 August 2011].
O'Hagan, M. (2009) 'Evolution of User-generatedTranslation: Fansubs, Translation Hacking andCrowdsourcing', The Journal of Internationalisation andLocalisation, 1, 94-121.
Paulk, M.C., Curtis, W., Chrissis, M.B., Weber, C.V. (1993)Capability Maturity Model for Software, Version 1.1,Technical Report CMU/SEI-93-TR-024 ESC-TR-93-177,Pittsburgh, Pennsylvania: Software Engineering Institute,available: http://www.sei.cmu.edu/reports/93tr024.pdf[accessed 2 August 2011].
Sargent, B.B., DePalma, D.A. (2008) TranslationManagement Systems, Lowell: Common Sense Advisory,16 September.
Sargent, B.B., DePalma, D.A. (2007) TranslationManagement System Scorecards, Lowell: Common SenseAdvisory, 26 February.
Turban, E., Leidner, D., McLean, E. and Wetherbe, J. (2007)Information Technology for Management: TransformingOrganizations in the Digital Economy, ed. 6, Wiley.
WordPress.org (2011a) Showcase [online], available:https://wordpress.org/showcase/ [accessed 13 July 2011].
WordPress.org (2011b) Roles and Capabilities [online],available: https://codex.wordpress.org/Roles_and_Cap-abilities [accessed 5 July 2011].
Yunker, J. (2003) Beyond Borders: Web GlobalizationStrategies. Indianapolis: New Riders.
17

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
1. Introduction
The number of mobile phone subscriptionsworldwide is expected to reach 5 billion in 2010 (ITU2010). Mobile device penetration in developingcountries of Asia is also increasing at a rapid pace(MobiThinking 2010). While current and past usageof mobile devices has mostly been for voice, there isa significant increase in text and other data servicesusing smart-phones (adMob 2010). It is expected thatmore than 85% of mobile handsets will be equippedfor mobile web access by the end of 2011(MobiThinking 2010), as many smart-phones todayhave processing power and other capabilitiescomparable to desktop computers of the early 1990s.
As the hardware capabilities of mobile devicesimprove, they are increasingly being used in areaslike education, health, entertainment, news, sports,and social networks. This usage of smart-phonesrequires that text and other data services are madeavailable in local languages. However, most of themobile devices that are currently in use only supportLatin script. There is limited or no support availablefor many other language scripts, specifically those ofdeveloping Asia. The devices generally support basic
Latin, bitmap and True Type Fonts (TTF). MostAsian languages scripts, on the other hand, are verycursive, context sensitive and complex (Hussain2003; Wali and Hussain 2006), and can only berealized using more elaborate font frameworks, e.g.Open Type Fonts (OTF) (Microsoft 2009). Suchframeworks are not supported on most mobiledevices and smart-phones at this time. Many peoplein developing Asia are only literate in their ownlanguages and are, therefore, unable to utilize theirmobile devices for anything other than voice calls.Developing font support is an essential pre-cursor tomaking content available in local language scripts.Once support is in place, content can be created,allowing people to utilize the additional capabilitiesof mobile phones for their socio-economic gains.
Whether focusing on iPhone (Apple Inc. 2010),Symbian based Nokia Phones (Forum.Nokia Users2009), Google Android (Google 2009), WindowsMobile (Microsoft 2010), or Blackberry, theworldwide web is full of queries and postsshowcasing the needs and concerns of developers andend-users, who are looking for particular languagesupport on their devices. While there is extensivelocalisation support for desktop computers, mobile
18
Enabling Complex Asian Scripts on Mobile Devices
AbstractThe increasing penetration of mobile devices has resulted in their use in diverse domains such as education, health,entertainment, business, sports, and social networks. However, a lack of appropriate support for many locallanguages on mobile devices, which use complex scripts rather than Latin scripts, is constraining many peopleacross developing Asia and elsewhere from using their mobile devices in the same way. There are some ad hocsolutions for certain scripts, but what is needed is a comprehensive and scalable framework which would supportall scripts. The Open Type Font (OTF) framework is now being widely used for supporting complex writingsystems on computing platforms. If support for OTF is also enabled on mobile devices, it would allow them toalso support complex scripts. This paper reports on work in this area, taking Pango, an open source renderingengine, and porting and testing its language modules on a mobile platform to provide support for Open Type Fonts.The paper describes the process for successful deployment of this engine on Nokia devices running the Symbianoperating system for Urdu, Hindi and Khmer languages. The testing results show that this is a viable solution forenabling complex scripts on mobile devices, which can have significant socio-economic impact, especially fordeveloping countries.
Keywords: : Mobile Devices, Smart-Phones, Pango, Localisation, Open Type Fonts, Complex Writing Systems
Waqar AhmadComputer Science Department,
National University of Computer and EmergingSciences, Lahore, [email protected]
Sarmad Hussain Center for Language Engineering,
Al-Khawarzimi Institute of Computer Science,University of Engineering and Technology,
Lahore, [email protected]

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
devices are lagging behind. Smart-phone softwaredevelopers try to find workarounds for resolvinglocalisation issues and sometimes achieve limitedsuccess. However, total success can only be achievedif the underlying device platform providescomprehensive support. If the underlying platformhas limitations, then they are also reflected in theworkarounds produced by software developers. Amajor problem is that mobile platforms providelimited software internationalisation support andtherefore, localisation for certain languages maybecome very difficult.
In this paper we have suggested a solution foralleviating some of the problems associated with thesupport of complex Asian scripts on mobile devicesusing Pango - an open source library for text layoutand rendering with an emphasis oninternationalisation (Taylor 2004). Research anddevelopment has been carried out with a focus onevaluating the viability of Pango as a text layout andrendering engine on mobile platforms. For thisproject, Symbian has been chosen as the mobileplatform. The project has two components: onecomponent deals with porting script specific modulesof Pango to the Symbian platform; the othercomponent is the development of an application(referred to as the SMSLocalized Applicationhereinafter) that can send/receive SMS in locallanguages using Pango with mobiles, as a proof ofconcept.
Although all of the language specific modules ofPango have been successfully ported to the Symbianplatform, extensive testing is performed for Urdu andan initial level of testing is performed for Khmer andHindi. The results of the tests are quite promising andconfirm the viability of Pango as a font engine formobile devices. The SMSLocalized applicationcontains features customised for local languagescripts. This application has been tested for Urdu;however, the architecture of the application is veryflexible and as such allows quick applicationcustomization for other languages. This paperpresents the relevant background and details of thiswork.
2. Current Localisation Support on MobilePlatforms
Limitations in script support on mobile devices areoften due to constraints specific to mobile handsetssuch as a small amount of memory, limitedprocessing power and other factors. During our
research, we have learnt that most of the issuesrelated to localisation on mobile phones fall into oneor more of following patterns:
l The localisation features supported on a mobiledevice may not be adequately documented. As aresult of this, information about localisationfeatures may only become known after acquiringand evaluating the device by installing localisedsoftware.
l Only a limited set of features for a language maybe supported on the device. For instance, TrueType Fonts (TTF) may be supported but not OpenType Fonts (OTF), which will results in lack ofsupport of a various languages and their scripts.
l In mobile device system software, languagesupport may exist at the level of menu items butmay be missing at application level. Forinstance, a device may have an operating systemwith a properly localised user interface but an on-device messenger application may not allow theuser to input text in a local language.
l A particular device platform may support manylanguages as a whole. However, when a device isreleased into the market, it may only be equippedwith a subset of the platform's supportedlanguages. For instance, a language-pack may bemissing or the font rendering engine may beconstrained by its multilingual language support.
As previously mentioned, software developerscontinue trying to find workarounds for thelocalisation issues which are, in many ways, limitedby the support provided by the underlying deviceplatform. The following sections give an overview ofthe extent of localisation support on some of themajor smart-phone platforms.
A. SymbianSymbian OS, currently owned by Nokia, is the mostwidely deployed operating system on mobile phones.It supports application development using JavaMicro Edition (Java ME) and C/C++. Symbianoperating system supports a very basic level of userinterface which does not make it usable by laymanusers. Therefore, on top of the Symbian operatingsystem, some mobile device vendors have developedrich user interfaces. Two such user interfaces are S60,developed by Nokia, and UIQ, developed by UIQtechnology. (Morris 2007).
19

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
Symbian supports a number of languages. However,it does not support Open Type Fonts (Forum.Nokia2009). Its default engine is based on the FreeTypefont library (Forum.Nokia 2009). The Symbianoperating system, however, can be extended byplugging in an external font engine to add support forlanguages or scripts not already supported (Morris2007). For instance, an engine can be developed, oradapted from open source, that adds support for opentype fonts with complex scripts i.e. if a third partydeveloper wants open type font support, s/he candevelop and plug the font engine into the operatingsystem which can then be used by any softwareapplication on the device.
B. Windows MobileWindows Mobile is a Windows CE based operatingsystem developed by Microsoft. Windows CE isprimarily designed for constrained devices like PDAsand can be customized to match the hardwarecomponents of the underlying device (Microsoft2010). Windows Mobile supports the Microsoft .NetCompact Framework for application development,which in turn supports a subset of Microsoft .NetFramework features.
According to the Microsoft website (Microsoft2010), WordPad, Inbox, Windows Messenger, andFile Viewer applications are not enabled for complexscripts like Arabic, Thai, and Hindi.
There are some commercial solutions for localisationon the Windows Mobile platform. One such solutionis Language Extender. It supports Arabic, Czech,English, Estonian, Farsi, Greek, Hebrew, Hungarian,Latvian, Lithuanian, Polish, Romanian, Russian,Slovak, and Turkish (ParaGon Software Group2010). However, Open Type Fonts for other complexwriting systems, e.g. Urdu Nataleeq (Wali andHussain 2006) are not available.
C. AndroidAndroid is a relatively new mobile software stackbased on Linux. It allows application developmentusing the Java programming language. However, anative SDK is also available from the Androiddeveloper website that can be used to develop nativeapplications in C/C++ (Google 2010).
Localisation on the Android platform is still limitedto a few languages. Independent developers havetried workarounds with limited success (Kblog2009). There is lot of debate on language supportissues on Android forums (Google Android
Community 2010). However, it has still not beenmade clear, officially, from Google as to whensupport for OTF will be included.
Google (2009) talks about localisation for German,French, and English but does comment aboutlanguages using non-Latin scripts.
D. Apple iPhoneAccording to Apple (Apple 2010), the Apple iPhone3G supports a number of languages includingEnglish (U.S), English (UK), French (France),German, Traditional Chinese, Simplified Chinese,Dutch, Turkish, Ukrainian, Arabic, Thai, Czech,Greek, Hebrew, Indonesian, Malay, Romanian,Slovak, and Croatian. Again, only TTF based fonts,e.g. for Arabic script, are supported, and OTF fontsare not supported.
E. Monotype Imaging Rasterization and LayoutEngines for Mobile PhonesMonotype imaging (2010) provides engines for fontrasterization (iType Font Engine) and layout(WorldType Layout Engine) for smart-phones. Thesolution is ANSI C based and is available forintegration with Android, Symbian and Windows CE.However, full Open Type Font support is notavailable in their solutions.
F. Other Smart-phone PlatformsOther smart-phone platforms like RIM Blackberry,Palm WebOS etc. are not investigated in detail froma localisation perspective in the current work. Theysupport localisation features, however, theirlimitations are similar to those mentioned above, asare discussed on online developer and end-userforums (ParaGon Software Group 2010).
3. Current Work
An investigation is conducted to evaluate thepossibility of using Pango as a text rendering andlayout engine for smart-phones. The project coversthe following:
1. Porting language specific modules of Pango tothe Symbian operating System.
2. Development of an SMS application(SMSLocalized), designed so that it can becustomized for scripts supported by Pango.
As Symbian is a dominant and mature mobileplatform, it has been chosen for this project. Pango
20

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
has a basic module and multiple scripts for specificmodules, e.g. for Arabic/Urdu, Indic, Khmer,Tibetan, etc. There has already been a compilation ofPango for the Symbian platform (Cairo Graphics2009), however, this compilation only covers thebasic module, and script-specific modules have notbeen ported. We use Cairo and compile individualscript modules on Symbian. Among the modulesported, Arabic (for Urdu), Indic and Khmer are testedafter deployment. The rest of the paper is focused onthis process of porting and testing the script specificmodules of Pango on the Symbian platform.
A. Symbian OverviewAs said earlier, Symbian OS is currently the mostwidely deployed operating system on mobile phones.It supports application development using Java andC/C++. Java application development on Symbian isenabled using Java Micro Edition (Java ME) andC/C++ application development is enabled using thenative OS application framework. (Morris 2007). Tofully exploit native device features, development inC/C++ is required. Therefore, for this project, whichrequires extensive native device features, thedevelopment is also carried out in C/C++. A typicalSymbian C/C++ application is designed according toModel-View-Controller (MVC) architecture(Harrison and Shackman 2007). The SMSLocalizedApplication has also been developed according to thesame MVC architecture.
As Pango is a C based library (Martensen 2009),Symbian support for C/C++ makes it easier to portthe library. Depending upon the type of featuresaccessed by an application from the device operatingsystem, a Symbian application may require officialsigning from Symbian Signed. For development andtesting of our application, we used the 'developercertificates.'
B. Pango OverviewPango is a popular text layout and rendering libraryused extensively on various desktop platforms.Pango is the core library used in GTK+-2.x for textand font handling (Martensen 2009; also Taylor2004). Pango has a number of script specificmodules, including modules for Arabic, Hebrew,Hangul, Thai, Khmer, Syriac, Tibetan, and Indicscripts. Pango can work with multiple font back-ends and rendering libraries as mentioned in thefollowing list (Martensen 2009).
l Client side fonts using the FreeType andFontconfig libraries. Rendering can be done with
Cairo or Xft libraries, or directly to an in-memorybuffer with no additional libraries.
l Native fonts on Microsoft Windows usingUniscribe for complex-text handling. Renderingcan be done via Cairo or directly using the nativeWin32 API.
l Native fonts on MacOS X using ATSUI forcomplex-text handling. Rendering using Cairo.ATSUI is the library for rendering Unicode texton Apple Mac OS X.
C. R&D ChallengesMobile application development poses a lot ofchallenges primarily due to the constrained nature ofthe devices. Limited memory size, low processingpower, dependency on batteries, constrained inputand output modalities and limited system API access,are just some of the many constraints faced by mobileapplication developers and researchers.
While the support for high level applicationdevelopment for mobile devices is extensivelyavailable, low-level application development remainschallenging. Even more challenging is exploringareas which are relatively lesser traversed byapplication developers and researchers e.g.localisation and font rendering. Lack ofdocumentation, few forum discussion threads,scarcity of expert developers, the unpredictablenature of development and the limited debugging andtesting platforms, are among some of the majorchallenges that we faced during project R&D onlocalisation for smart-phones. Even installation of afont file on a mobile device may at times become achallenge. For example, it is not always easy to findout where to copy font files, how to get the device todetect a new font etc. Details such as these may onlybe known after extensive exploration of the deviceplatform under consideration, as it may bedocumented well for application developers.
D. Libraries The integration of Pango with Cairo provides acomplete solution for text handling and graphicsrendering. The combination of Pango and Cairo,along with their dependencies, is compiled for theSymbian platform as part of this project. Thefollowing libraries are required for complete solutionto work properly:
1) PangoPango is a font rendering and text layout engine
21

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
available with an open source license. Pango has anumber of language specific modules, includingmodules for Hebrew, Arabic, Hangul, Thai, Khmer,Syriac, Tibetan, and Indic scripts (Martensen 2009),as discussed.
2) CairoCairo is a 2-D graphics library which supportsmultiple output devices i.e. X-Window, Win32, PDF,SVG etc. The library has been written in the Cprogramming language; however, its bindings areavailable in other languages such as Java, C++, PHPetc. (Cairo Graphics 2010).
3) FreeTypeFreeType is an ANSI C compliant font rasterizationlibrary. It provides access to font files of variousformats and performs actual font rasterization. Fontrasterization features include the conversion of glyphoutline of characters to bitmaps. It does not provideAPIs to perform features like text layout or graphicsprocessing (Free Type 2009).
4) FontConfig FontConfig allows the selection of an appropriatefont given certain font characteristics. It supports fontconfiguration and font matching features anddepends on the Expat XML parser. FontConfig hastwo key modules: The Configuration Module buildsan internal configuration from XML files and theMatching Module accepts font patterns and returnsthe nearest matching font (FontConfig 2009).
5) GLib GLib provides the core application building blocksfor libraries and applications written in C. It providesthe core object system used in GNOME, the mainloop implementation, and a number of utilityfunctions for strings and common data structures(Pango 2009).
6) Pixman Pixman is a low level pixel manipulation library forX and Cairo. Supported pixel manipulation featuresinclude image compositing and trapezoid (Pixman2009).
7) ExpatExpat is an XML parsing library written in C. It is astream-oriented parser in which an applicationregisters handlers for components that the Expatparser might find in the XML document e.g. XMLstart tags (Expat 2009).
8) libpng Libpng is a library written in C for the manipulationof images in PNG (Portable Network Graphics)format (Roelof 2009).
E. Tools and TechnologiesThe following tools and technologies are used for thedevelopment of this work.
1) Code BaselineCode from http://code.google.com/p/cairo-for-symbian/ (Cairo Graphics 2009) is taken as baselinefor the current work. This is an earlier compilation ofthe basic Pango module for the Symbian platform.
2) Development ToolsThe Following tools were used during development:
l Carbide C++ v2.3.0: an IDE provided by Nokiafor application development on the Symbianplatform (Forum.Nokia 2009).
l Symbian S60 3rd Edition Feature Pack 2 SDKv1.1.2: a development kit for Nokia S60 andSymbian platforms. It includes a simulator fortesting applications on a Windows desktop beforethey are installed and tested on actual devices(Forum.Nokia 2009).
F. Application ArchitectureThe project has two major parts. The first is an SMSapplication for testing font support and porting of thelanguage modules of Pango and development.
1) SMSLocalized ApplicationThe SMSLocalized application is a Symbianapplication designed for the languages supportedthrough Pango. The application has the followingfeatures.
l Allows typing of text using an SMS Text editor.
l Displays an on-screen keypad, which isconfigurable based on a text-file for a language.
l Sends and receives text as SMS.
l Automatically wakes up whenever a new messageis received.
The SMSLocalized application is implemented forthe Urdu language, chosen for its complexity incontextual shaping and positioning of glyphs(Hussain 2003).
22

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
Figure 1 depicts the SMSLocalized application classdiagram developed in Symbian C/C++.SMSLocalized Application, SMSLocalizedDoc-ument, SMSLocalizedAppUi, and NewMessageCon-tainerView are required by the MVC architecture ofSymbian applications.
To enable Urdu text input on mobile phones, acustom key map has to be defined so that theappropriate Urdu characters are rendered againsteach key press. Many mobile phones support multi-tapped text input, where each key on the keypadrepresents more than one characters. Thisarrangement of character sequences against eachnumeric key on the mobile phone is called thekeymap i.e. each numeric key on the device has anassociated keymap.
On a typical Symbian device, a keymap is definedagainst each key on the device keypad so a charactercan be entered using the multi-tapping nature ofNumeric keypads. NumerciLocalizedPtiEngineprovides customized low level input mechanisms.One key feature supported in this class is that itdefines a new keymap for the local language.NumericKeypad is used to draw a custom localisedkeypad on the mobile screen. This involvesmeasuring screen size and dividing it appropriately toallow sufficient space for a numeric keypadconsisting of four rows and three columns while stillgiving enough space to enter text. The CSMSWatcherclass inherits from CActive and registers an activeobject with the scheduler. It implements methods tohandle messages received by the application.
Figure 1: Class Diagram of the SMSLocalized Application
To prevent the Symbian operating system fromloading the default keymap and using the customizedkeymap for another local language, a new keymaphas to be defined and a mechanism developed to loadthis sequence of characters when the applicationstarts up. This involves defining a custom Unicodesequence against each key on the numeric keypad ina text file and using the CPtiEngine API of theSymbian platform to load customized keymapsequences from the relevant resource file.
2) Script Specific Modules of PangoThe second major component of the solution is thePangocairo library core and script-specific modules.The Pangocairo library, along with script-specificmodules, are compiled and ported to Symbianplatform.
Pango supports multiple scripts including Latin,Cyrillic, Arabic, Hangul, Hebrew, Indic and Thai.Figure 2 provides an overview of the high levelarchitecture of Pango (Taylor 2001). The followingare key features of the Pango Architecture (Taylor2001):
l Unicode has been used as common characterencoding mechanism throughout the Pangosystem.
l There is a core functionality module, Pango Core,which includes functions such as itemization(subdivision of text strings) and line breaking.
l There are script specific modules for handlingfeatures unique to each script. Each script module
23

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
has been further split into two modules: thelanguage module and the shaper module. Thelanguage module is independent of the renderingsystem and the shaper module (e.g. Arabic XShaper, PS X Shaper) is dependent on therendering system.
l Pango rendering components support multiplerendering back ends. There are separatecomponents for each rendering backend e.g. Xrendering backend is responsible for rendering Xfonts using XLib and XServer.
Figure 2: Pango Architecture (Taylor 2001)
Pangocairo itself includes packages of standardC/C++ libraries. Therefore, it can be ported to theSymbian platform, which also supports C/C++.However, this task is challenging because theavailability of the technical information required islimited. The following are some importantmodifications carried out in Pango and its dependentlibraries in order to port it onto the Symbianoperating system.
l Declarations of language specific modules areincluded in the code, which lead to the generationof interface functions. These interface functionsenable access to the language specific modules inthe code.
l The source code that needs to be compiled for theSymbian operating system must be referred to inappropriate 'project make files' i.e. .mmp files.References to interface components of scriptspecific modules (e.g. Arabic) are included inappropriate .mmp files.
l On start-up, the Symbian operating system loadsfont files from specific folders. Since the
FontConfig library accesses font files, it isupdated so that it can access Nafees Nastaliquefont files loaded by the Symbian operatingsystem.
l Some of required Pango API functions are notexposed for external access in the Symbian code.Such functions are declared and listed inappropriate interface files.
In addition to the above, a component that interfaceswith the Pango library has been created. Thiscomponent enables access to the text renderingfeatures of Pango i.e., it can take any Unicode text asinput and return the rendered text in a formatcompatible with the requirements of the Symbianoperating system.
3) Deployment and Testing PlatformsBoth components of the solution were deployed andtested on the following platforms.
l WINSCW
This is a simulator for theS60 Symbian platformincluded in Symbian S60 3rd Edition Feature Pack 2SDK v1.1.2 for Windows Platform.
l Nokia E51 (A Symbian Phone)
The following are the specifications of the Nokia E51handset-a Symbian based phone:
i. Symbian: v9.2 S60 v3.1 UIii. CPU: ARM 11 369 MHz Processoriii. RAM: 96 MBG. Testing Results
The SMSLocalized application and language specificmodules of Pangocairo framework were deployedand tested on both a Windows emulator (SymbianS60 3rd Edition) and a real device (Nokia E51). Theapplication works successfully on both platforms.Figure 3 shows the SMSLocalized applicationrunning on the Nokia S60 3rd Edition Emulator. Theon-Screen Urdu Keypad in Nafees Nastalique OpenType Font can also be seen. Figure 4 shows Urdu textwritten in Nafees Nastalique font (an Open TypeFont) as rendered on the Nokia E51.
An Open Type Font file contains glyphs and rules.The glyph tables are in a similar format to those usedto store vectorized outlines for TTF files. In addition,rules for glyph positioning and their contextualsubstitution are represented in different tables.
24
Localisation Focus Vol.10 Issue 1The International Journal of Localisation
Finally, marks which are associated with glyphs canalso be adjusted through rules for finer tuning offonts. All of these aspects are thoroughly tested forNafees Nastalique, and the open Urdu font freelyavailable online. More than 500 Urdu ligatures1consisting of two to eight characters are chosen fromthe list of valid ligatures available online (CRULP2009). The arbitrary selection includes complexligatures, which exhibit cursiveness, contextsensitive shaping and positioning of glyphs. Table 1shows the ligature counts for two to eight charactercombinations selected for this testing.
The ligature set included all available Urducharacters.
Figure 3: the SMSLocalized Application on Nokia S60 3rd EditionEmulator.
Table 1: Summary of Ligature Set Selected for Testing
Table 2 shows the frequency of each letter in the testset and the contexts (initial, medial, final andisolated) in which it has been tested. In addition, themark association and placement is tested. Though thecurrent tests do not test every possible shape of eachUrdu letter, as there is glyph variation based on othercharacters in the context and not just the fourcontexts listed, the testing is still representative andthese results can be extrapolated to un-testedsubstitution and positioning rules with confidence.The shaded cells in the table are for non-joiningcharacters, which do not occur in initial or medialpositions. The ligatures were displayed andmanually tested on the Symbian S60 Emulator(WINSCW) and the Nokia E51device.
Figure 4: Pango Urdu (Open Type Font Nafees Nastalique) textrendering on a Nokia E51
Figures 4 and 5 show the rendering results of some ofthe selected ligatures on the phone and emulatorrespectively, showing the cursiveness, glyphsubstitution, glyph positioning and mark placementcomplexities.
25
1Ligature is the portion of the written representation of a word that is formed by characters combining together. A word may have one or moreligatures and a ligature may be formed by one or more characters. A non-joining character or a word-ending will end a ligature.
Character Count perLigature
Number of LigaturesTested
2 903 1074 955 816 987 658 20
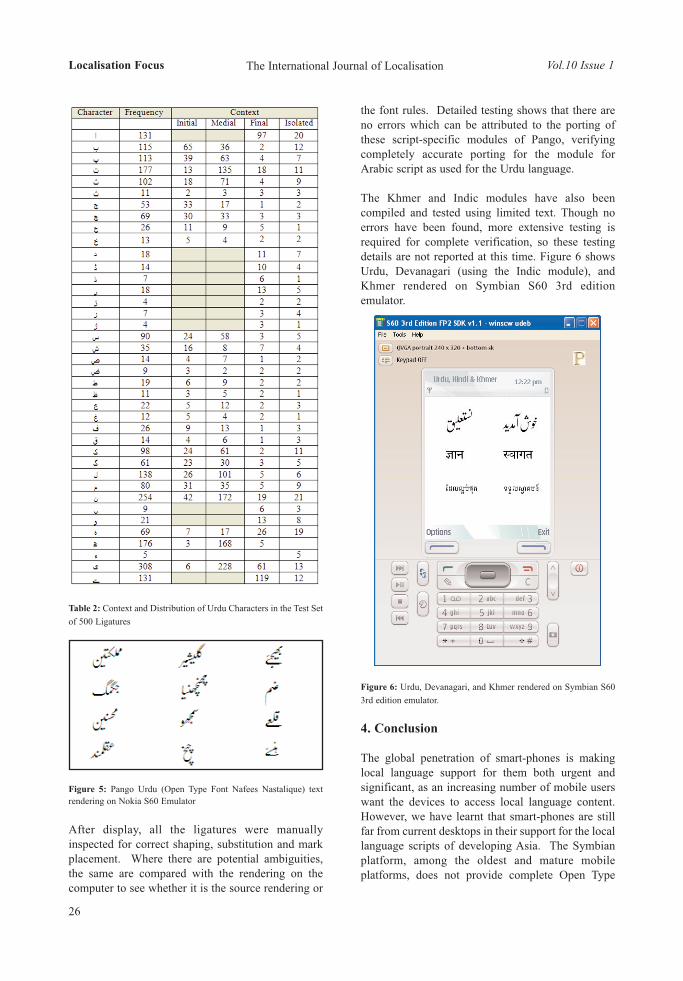
Localisation Focus Vol.10 Issue 1The International Journal of Localisation
Table 2: Context and Distribution of Urdu Characters in the Test Setof 500 Ligatures
Figure 5: Pango Urdu (Open Type Font Nafees Nastalique) textrendering on Nokia S60 Emulator
After display, all the ligatures were manuallyinspected for correct shaping, substitution and markplacement. Where there are potential ambiguities,the same are compared with the rendering on thecomputer to see whether it is the source rendering or
the font rules. Detailed testing shows that there areno errors which can be attributed to the porting ofthese script-specific modules of Pango, verifyingcompletely accurate porting for the module forArabic script as used for the Urdu language.
The Khmer and Indic modules have also beencompiled and tested using limited text. Though noerrors have been found, more extensive testing isrequired for complete verification, so these testingdetails are not reported at this time. Figure 6 showsUrdu, Devanagari (using the Indic module), andKhmer rendered on Symbian S60 3rd editionemulator.
Figure 6: Urdu, Devanagari, and Khmer rendered on Symbian S603rd edition emulator.
4. Conclusion
The global penetration of smart-phones is makinglocal language support for them both urgent andsignificant, as an increasing number of mobile userswant the devices to access local language content.However, we have learnt that smart-phones are stillfar from current desktops in their support for the locallanguage scripts of developing Asia. The Symbianplatform, among the oldest and mature mobileplatforms, does not provide complete Open Type
26

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
Font (OTF) support. However, the porting of Pangoscript-specific modules can add OTF support toSymbian. This has been successfully achievedthrough our project. All of the Pango language scriptmodules have been ported to the Symbian OS, withextensive testing carried out for Urdu and initialtesting performed for Khmer. Through the process,we have learnt that the Urdu, Indic and Khmerlanguage modules of Pango work well on theSymbian platform. We believe that given theextensive support for international languages byPango, it is a good choice for serving as a text layoutand rendering engine for smart-phone devices.
Currently, the project is continuing to port and testadditional script modules. The SMSLocalizedapplication is being integrated to communicate withPango for rendering and additional work is underwayto develop similar support for the Android opensource platform.
Acknowledgements
This work has been supported by the PANLocalization project (www.PANL10n.net) grant byIDRC Canada (www.idrc.ca), administered throughCenter for Language Engineering (www.CLE.org.pk),Al-Khawarizmi Institute of Computer Science,University of Engineering and Technology, Lahore,Pakistan.
References
adMob (2010) AdMob Mobile Metrics [online], available:http://metrics.admob.com/ [accessed 15 Aug 2010]
Android Developers on Google Groups (2010) Localization[online], available: http://groups.google.com/group/adroid-platform/browse_thread/thread/8887a2fe29c38e7 [accessed17 Aug 2010].
Apple (2010) iPhone 4 Technical Specifications [online],available:http://www.apple.com/iphone/specs.html[accessed 20 Aug 2010].
Cairo Graphics (2010) Cairo Tutorial [online], available:http://cairographics.org/tutorial/ [accessed 12 May 2009].
Cairo Graphics (2009) Cairo for Symbian OS [online],available: http://code.google.com/p/cairo-for-symbian/[accessed 18 May 2009].
CRULP (2009) Valid Ligatures for Urdu [online], available:http://www.crulp.org/software/ling_resources/UrduLigatures.htmhttp://www.forum.nokia.com/ [accessed 11 Mar2010].
Edwards, L. and Barker, R. (2004) Developing S60Applications: A Guide for Symbian OS C++ Developers,U.S.: Addison Wesley.
Expat (2009) The Expat XML Parser [online], available:http://expat.sourceforge.net/ [accessed 13 May 2009].
Free Type (2009) The FreeType Project [online], available:http://www.freetype.org/index2.html [accessed 12 May2009].
FontConfig (2009) User's Manual [online], available:http://fontconfig.org/fontconfig-user.html [accessed 13 May2009].
Forum.Nokia (2009) Support for Open Type Fonts [online],available: http://discussion.forum.nokia.com/forum/show-thread.php?163031-Support-for-Open-Type-Fonts[accessed 16 Aug 2010].
Forum.Nokia Users (2009), Discussion Board [online],available:http://discussion.forum.nokia.com/forum/[accessed 7 Oct 2009].
Google (2009) Localizing Android Apps [DRAFT] [online],available:http://groups.google.com/group/android-developers/web/localizing-android-apps-draft [accessed 14May 2010].
Google (2010) Android 2.2 Platform [online], available:http://developer.android.com/sdk/android-2.2.html[accessed 10 Oct 2010].
Google Android Community (2010) Arabic LanguageSupport [online], available: http://code.google.com/p/an-droid/issues/detail?id=5597&colspec=id%20type%20status%20owner%20summary%20stars [accessed 19 Aug 2010].
Harrison, R. and Shackman, M. (2007) Symbian OS C++for Mobile Phones: Application Development for SymbianOS v9, England: John Wiley & Sons, Ltd.
Hussain, S.(2003). 'www.LICT4D.asia/Fonts/Nafees_Nas-talique.' Proceedings of 12th AMIC Annual Conference onE-Worlds: Governments, Business and Civil Society, AsianMedia Information Center, Singapore.
International Telecommunication Union (2010) ITU sees 5billion mobile subscriptions globally in 2010 [online],available: http://www.itu.int/newsroom/press_releases/2010/06.html [accessed 18 Aug 2010].Kblog (2009) Arabic Language in Android [online]available: http://blog.amr-gawish.com/39/arabic-language-in-android/ [accessed 19 Aug 2010]
Microsoft (2009) OpenType Specification [online],available: http://www.microsoft.com/typography/otspec/[accessed 10 Oct 2010].
27

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
Microsoft (2010) Creating a Complex Scripts-enabled Run-Time Image [online], available: http://msdn.microsoft.com/en-us/library/ee491707.aspx [accessed 16 Aug 2010].
MobiThinking (2010) Global mobile stats: all latest qualityresearch on mobile Web and marketing [online], available:http://mobithinking.com/mobile-marketing-tools/latest-mobile-stats [accessed 16 Aug 2010].
Monotype Imaging (2010) Products and Services [online],available: http://www.monotypeimaging.com/products-services/ [accessed 5 Aug 2010].
Morris, B. (2007) The Symbian OS ArchitectureSourcebook: Design and Evolution of a Mobile Phone OS,England: John Wiley & Sons, Ltd.
Pango (2009) Pango Reference Library [online] available:http://library.gnome.org/devel/pango/stable/ [accessed 15May 2009].
ParaGon Software Group (2010) Language Extender forWindows Mobile Pocket PC [online], available:http://pocket-pc.penreader.com/ [accessed 16 Aug 2010].
ParaGon Software Group (2010) PILOC for Palm [online]available: http://palm.penreader.com/ [accessed 24 Aug2010].
Pixman (2009) Pixmann [online], available:http://cgit.freedesktop.org/pixman [accessed 13 May 2009].
Roelof, G. (2009) LibPng for Windows [online], available:http://gnuwin32.sourceforge.net/packages/libpng.htm[accessed 15 May 2009].
Roelof, G. (2009) LibPng [online], available:http://www.libpng.org/pub/png/libpng.html [accessed 15May 2009].
Sales, J. (2005) Symbian OS Internals: Real-time KernelProgramming, England: John Wiley & Sons, Ltd.
Taylor, O. (2004) 'Pango, an open-source Unicode textlayout engine,' 25th Internationalization and UnicodeConfernece, Unicode Consortium, Washington DC.
Taylor, O. (2001) Pango: Internationalized Text Handling[online],available:http://fishsoup.net/bib/PangoOls2001.pdf [accessed 10 Jun 2009].
Wali, A., Hussain, S. (2006) 'Context Sensitive Shape-Substitution in Nastaliq Writing system: Analysis andFormulation,' Proceedings of International JointConferences on Computer, Information, and SystemsSciences, and Engineering (CISSE2006).
28

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
1. Introduction
The term localisation has been defined as the"linguistic and cultural adaptation of digital contentto the requirements and locale of a foreign market,and the provision of services and technologies for themanagement of multilingualism across the digitalglobal information flow" (Schäler 2009). As thedefinition suggests, localisation is a complex process.Localisation involves many steps: projectmanagement, translation, review, quality assuranceetc. It also requires a considerable effort as it involvesmany languages, dealing with characteristics andchallenges unique to each of these languages such asthe handling of right-to-left scripts, collation, andlocale specific issues. Time-frame is anotherparameter that affects the complexity of thelocalisation process. Localisation processes requiredealing with frequent software updates, shortsoftware development life cycles and thesimultaneous shipment of source and target languageversions (simship). A broad spectrum of software isrequired to handle the process, ranging from projectmanagement software to translation software. A largenumber of file formats are encountered during thelocalisation process. These file formats may consistof both open standard and proprietary file formats.Localisation processes involve different types oforganisations (e.g. translation and localisation
service providers) and different professions (e.g.translators, reviewers, and linguists). Localisationconstantly has to deal with new challenges such asthose arising in the context of mobile device contentor integration with content management systems. Inthis extremely complex process, the ultimate goal isto maximise quality (translations, user interfaces etc.)and quantity (number of locales, simships etc.) whileminimising time and overall cost.
Interoperability is the key to the seamless integrationof different technologies and components across thelocalisation process. The term interoperability hasbeen defined in a number of different ways in theliterature. For example, Lewis et al. (2008) defineinteroperability as: "The ability of a collection ofcommunicating entities to (a) share specifiedinformation and (b) operate on that informationaccording to an agreed operational semantics".
The most frequently used definition for the term"interoperability" is by the IEEE: "Interoperability isthe ability of two or more systems or components toexchange information and to use the information thathas been exchanged." (IEEE, 1991).
However, interoperability, while presenting one ofthe most challenging problems in localisation, hasnot had much attention paid to it in the literature. We
29
LocConnect: Orchestrating Interoperability in a Service-orientedLocalisation Architecture
Asanka Wasala, Ian O'Keeffe and Reinhard Schäler
Centre for Next Generation Localisation Localisation Research Centre
CSIS Dept., University of Limerick,Limerick, Ireland.
{Asanka.Wasala, Ian.OKeeffe, Reinhard.Schaler}@ul.ie
AbstractInteroperability is the key to the seamless integration of different entities. However, while it is one of the mostchallenging problems in localisation, interoperability has not been discussed widely in the relevant literature. Thispaper describes the design and implementation of a novel environment for the inter-connectivity of distributedlocalisation components, both open source and proprietary. The proposed solution promotes interoperabilitythrough the adoption of a Service Oriented Architecture (SOA) framework based on established localisationstandards. We describe a generic use scenario and the architecture of the environment that allows us to studyinteroperability issues in localisation processes. This environment was successfully demonstrated at the CNGLPublic Showcase in Microsoft, Ireland, November 2010.
Keywords: : Interoperability, Localisation, SOA, XLIFF, Open Standards

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
aim to address this deficit by presenting a novelapproach to interoperability across localisation toolsthrough the adoption of a Service OrientedArchitecture (SOA) framework based on establishedlocalisation standards. We describe a generic usescenario and the architecture of the approach offeringan environment for the study of interoperabilityissues in localisation process management. To ourknowledge, this is the first demonstrator prototypebased on SOA and open localisation standardsdeveloped as a test bed in order to exploreinteroperability issues in localisation.
The remainder of the paper is organized as follows:Section 2 provides an overview of interoperability ingeneral, and in localisation in particular, in thecontext of open localisation standards; Section 3explains the experimental setup, introduces theLocConnect framework, and presents the localisationcomponent interoperability environment developedas part of this research; Section 4 presents thearchitecture of LocConnect in detail; and section 5discusses future work. The paper concludes with asummary of the present work and the contributionsmade by this study.
2. Background
Currently, software applications are increasinglymoving towards a distributed model. Standards arevital for the interoperability of these distributedsoftware applications. However, one of the majorproblems preventing successful interoperabilitybetween and integration of distributed applicationsand processes is the lack of (standardised) interfacesbetween them.
In order to address these issues, workflowinteroperability standards have been proposed(Hayes et al 2000) to promote greater efficiency andto reduce cost. The Wf-XML message set defined bythe Workflow Management Coalition (WfMC) andThe Simple Workflow Access Protocol (SWAP) areexamples of such internet-scale workflow standards(Hayes et al 2000). Most of these standards onlydefine the data and metadata structure whilestandards such as Hyper-Text Transfer Protocol(HTTP), Common Object Request BrokerArchitecture (CORBA), and the Internet Inter-ORBProtocol (IIOP) focus on the transportation of datastructures (Hayes et al 2000).
From a purely functional standpoint, we also have theWeb Service Description Language (WSDL), the
most recent version being WSDL 2.0 (W3C 2007).WSDL is an XML-based language that definesservices as a collection of network endpoints or ports.It is regarded as being a simple interface definitionlanguage (Bichler and Lin 2006) which does notspecify message sequence or its constraints onparameters (Halle et al 2010). However, while it doesdescribe the public interface to a web service, itpossesses limited descriptive ability and covers onlythe functional requirements in a machine-readableformat. Where this becomes an issue is in defining anon-static workflow, as the interface does not provideenough information to allow a broker to make a valuejudgement in terms of other qualities that are ofconsiderable interest in the localisation process, suchas the quality, quantity, time and cost aspectsdiscussed earlier. These service attributes are muchmore difficult to define, as they cover the non-functional aspects of a service, e.g. how well it isperformed. This contrasts with the more Booleanfunctional requirements (either it complies with theservice support requirements, or it does not).Therefore, WSDL does not provide sufficientcoverage to support our requirements forinteroperability.
There are some notable examples of localisation andtranslation-centric web services, such as thosecurrently offered by Google, Bing and Yahoo!.However, even here we run into interoperabilityissues as the interfaces provided do not follow anyspecific standard, and connecting to these services isstill very much a manual process requiring theintervention of a skilled computer programmer to setup the call to the service, to validate the data sent interms of string length, language pair, and so on, andthen to handle the data that is returned. Somelocalisation Translation Management Systems (TMS)purport to provide such flexibility, but they tend to bemonolithic in their approach, using pre-definedworkflows, and requiring dedicated developers toincorporate services from other vendors into theseworkflows through the development of bespokeAPIs. What is needed is a unified approach forintegrating components, so that any service can becalled in any order in an automated manner.
2.1 The XLIFF StandardThe XML-based Localization Interchange FileFormat (XLIFF) is an open standard for exchanginglocalisation data and metadata. It has been developedto address various issues related to the exchange oflocalisation data.
30

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
The XLIFF standard was first developed in 2001 bya technical committee formed by representatives of agroup of companies, including Oracle, Novell,IBM/Lotus, Sun, Alchemy Software, Berlitz,Moravia-IT, and ENLASO Corporation (formerly theRWS Group). In 2002, the XLIFF specification wasformally published by the Organization for theAdvancement of Structured Information Standards(OASIS) (XLIFF-TC 2008).
The purpose of XLIFF as described by OASIS is to"store localizable data and carry it from one step ofthe localization process to the other, while allowinginteroperability between tools" (XLIFF-TC 2008).By using this standard, localisation data can beexchanged between different companies,organizations, individuals or tools. Various fileformats such as plain text, MS Word, DocBook,HTML, XML etc. can be transformed into XLIFF,enabling translators to isolate the text to be translatedfrom the layout and formatting of the original fileformat.
The XLIFF standard aims to (Corrigan & Foster2003):
l Separate translatable text from layout andformatting data;
l Enable multiple tools to work on source strings;
l Store metadata that is helpful in thetranslation/localisation process.
The XLIFF standard is becoming the de factostandard for exchanging localisation data. It isaccepted by almost all localisation service providersand is supported by the majority of localisation toolsand CAT tools. The XLIFF standard is beingcontinuously developed further by the OASIS XLIFFTechnical Committee (2010).
2.2 Localisation Standards and InteroperabilityIssuesAlthough the adoption of localisation standardswould very likely provide benefits relating toreusability, accessibility, interoperability, andreduced cost, software publishers often refrain fromthe full implementation of a standard or do not carryout rigorous standard conformance testing. There isstill a perceived lack of evidence for improvedoutcomes and an associated fear of the high costs ofstandard implementation and maintenance. One ofthe biggest problems with regards to tools and
technologies today is the pair-wise product drift(Kindrick et al 1996), i.e. the need for the output ofone tool to be transformed in order to compensate foranother tool's non-conforming behaviour. This trait ispresent within the localisation software industry.Although the successful integration of differentsoftware brings enormous benefits, it is still a veryarduous task.
Most current CAT tools, while accepting anddelivering a range of file formats, maintain their ownproprietary data formats within the boundary of theapplication. This makes sharing of data between toolsfrom different software developers very difficult, asconversion between formats often leads to data loss.
XLIFF, as mentioned above, intends to provide asolution to these problems, but true interoperabilitycan only be achieved once the XLIFF standard isimplemented in full by the majority of localisationtools providers. Currently, XLIFF compliance seemsto be regarded as an addition to the function list ofmany localisation applications, rather than beingused to the full extent of its abilities, and indeedmany CAT tools seem to pay mere lip service to theXLIFF specification (Anastasiou and Morado-Vazquez 2010; Bly 2010), outputting just a minorsubset of the data contained in their proprietaryformats as XLIFF to ensure conformance.
3. Experimental Setup
With advancements in technology, the localisationprocess of the future can be driven by a successfulintegration of distributed heterogeneous softwarecomponents. In this scenario, the components aredynamically integrated and orchestrated dependingon the available resources to provide the best possiblesolution for a given localisation project. However,such an ideal component-based interoperabilityscenario in localisation is still far from reality.Therefore, in this research, we aim to model this idealscenario by implementing a series of prototypes. Asthe initial step, an experimental setup has beendesigned containing the essential components.
The experimental setup includes multiple interactingcomponents. Firstly, a user creates a localisationproject by submitting a source file and supplyingsome parameters through a user interface component.Next, the data captured by this component is sent toa Workflow Recommender component. TheWorkflow Recommender implements the appropriatebusiness process. By analysing source file content,
31

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
resource files as well as parameters provided by theuser, the Workflow Recommender offers an optimumworkflow for this particular localisation project.Then, a Mapper component analyses this workflowand picks the most suitable components to carry outthe tasks specified in the workflow. Thesecomponents can be web services such as MachineTranslation systems, Translation Memory Systems,Post Editing systems etc. The Mapper will establishlinks with the selected components. Then a datacontainer will be circulated among the differentcomponents according to the workflow establishedearlier. As this data container moves throughdifferent components, the components modify thedata. At the end of the project's life cycle, a Convertercomponent transforms this data container to atranslated or localised file which is returned to theuser.
Service Oriented Architecture is a key technologythat has been widely adopted for integrating suchhighly dynamic distributed components. Ourresearch revealed that the incorporation of anorchestration engine is essential to realise asuccessful SOA-based solution for coordinatinglocalisation components. Furthermore, the necessityof a common data layer that will enable thecommunication between components becameevident. Thus, in order to manage the processes aswell as data, we incorporated an orchestration engineinto the aforementioned experimental setup. Thisexperimental setup along with the orchestrationengine provide an ideal framework for theinvestigation of interoperability issues amonglocalisation components.
3.1 LocConnectAt the core of the experimental setup are theorchestration engine and the common data layer,which jointly provide the basis for the exploration ofinteroperability issues among components. Thisprototype environment is called LocConnect. Thefollowing sections introduce the features ofLocConnect and describe its architecture.
3.1.1 Features of LocConnectLocConnect interconnects localisation componentsby providing access to an XLIFF-based data layerthrough an Application Programming Interface(API). By using this common data layer we allow forthe traversal of XLIFF-based data between differentlocalisation components. Key features of theLocConnect testing environment are summarizedbelow.
l Common Data Layer and ApplicationProgramming Interface
LocConnect implements a common XLIFF-baseddatastore (see section 4.5) corresponding toindividual localisation projects. The components canaccess this datastore through a simple API.Furthermore, the common datastore can also holdvarious supplementary resource files related to alocalisation project (see section 4.4). Componentscan manipulate these resource files through the API.
l Workflow Engine
The orchestration of components is achieved via anintegrated workflow engine that executes alocalisation workflow generated by anothercomponent.
l Live User Interface (UI)
One of the important aspects of a distributedprocessing scenario is the ability to track progressalong the different components. An AJAX-poweredUI has been developed to display the status of thecomponents in real-time. LocConnect's UI has beendeveloped in a manner that allows it to be easilylocalised into other languages.
l Built-in post-editing component (XLIFF editor)
In the present architecture, localisation projectcreation and completion happens within LocConnect.Therefore, an online XLIFF editor was developedand incorporated into LocConnect in order tofacilitate post-editing of content.
l Component Simulator
In the current experimental setup, only a smallnumber of components, most of them developed aspart of the CNGL research at the University ofLimerick and other participating research groups,have been connected up. The WorkflowRecommender, Mapper, Leveraging Component anda Translating Rating component are among thesecomponents. A component simulator was, therefore,developed to allow for further testing ofinteroperability issues in an automated localisationworkflow using the LocConnect framework.
A single-click installer and administratorconfiguration panel for LocConnect were developedas a part of this work to allow for easy installation
32

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
and user-friendly administration.
3.1.2 Business CaseCloud-based storage and applications are becomingincreasingly popular. While the LocConnectenvironment supports the adhoc connection oflocalisation components, it can also serve as cloud-based storage for localisation projects. These andother key advantages of LocConnect from a businesspoint of view are highlighted below.
l Cloud-based XLIFF and resource file storage
LocConnect can simply be used as a cloud-basedXLIFF storage. Moreover, due to its ability to storeresource files (e.g. TMX, SRX etc.), it can be used asa repository for localisation project files. As such,LocConnect offers a central localisation datarepository which is easy to backup and maintain.
l Concurrent Versioning System (CVS)
During a project's life cycle, the associated XLIFFdata container continuously changes as it travelsthrough different localisation components.LocConnect keeps track of these changes and storesdifferent versions of the XLIFF data container.Therefore, LocConnect acts as a CVS system forlocalisation projects. LocConnect provides thefacility to view both data and metadata associatedwith the data container at different stages of aworkflow.
l In-built Online XLIFF editor
Using the inbuilt online XLIFF editor, users can editXLIFF content easily. The AJAX-based UI allowseasy inline editing of content. Furthermore, theonline editor shows alternative translations as well asuseful metadata associated with each translation unit.
l Access via internet or intranet
With its single click installer, it can easily bedeployed via the internet or an intranet. LocConnectcan also act as a gateway application whereLocConnect is connected to the internet while thecomponents can safely reside within an intranet.
l Enhanced revenues
The LocConnect-centric architecture increases dataexchange efficiency as well as automation. Due toincreased automation, we would expect lower
localisation costs and increased productivity.
3.2 Description of Operation (Use Case)The following scenario provides a typical use casefor LocConnect in the above experimental setup.
A project manager logs into the LocConnect serverand creates a LocConnect project (a.k.a. a job) byentering some parameters. Then the project manageruploads a source file. The LocConnect server willgenerate an XLIFF file and assign a unique ID to thisjob. Next, it will store the parameters capturedthrough its interface in the XLIFF file and embed theuploaded file in the same XLIFF file as an internalfile reference. The Workflow Recommender will thenpick up the job from LocConnect (see the proceduredescribed in section 4.2.1), retrieve thecorresponding XLIFF file and analyse it. TheWorkflow Recommender will generate an optimumworkflow to process the XLIFF file. The workflowdescribes the other components that this XLIFF filehas to go through and the sequence of thesecomponents. The Workflow Recommender embedsthis workflow information in the XLIFF file. Oncethe workflow information is attached, the file will bereturned to the LocConnect server. WhenLocConnect receives the file from the WorkflowRecommender, it decodes the workflow informationfound in the XLIFF file and initiates the rest of theactivities in the workflow. Usually, the next activitywill be to send the XLIFF file to a MapperComponent which is responsible for selecting thebest web services, components etc. for processing theXLIFF file. LocConnect will establishcommunication with the other specified componentsaccording to the workflow and componentdescriptions. As such, the workflow will be enactedby the LocConnect workflow engine. Once theXLIFF file is fully processed, XLIFF content can beedited online using LocConnect's built-in editingcomponent. During the project's lifecycle, the projectmanager can check the status of the componentsusing LocConnect's live project tracking interface.Finally, the project manager can download theprocessed XLIFF and the localised files.
4. Architecture
This section describes the LocConnect architecture indetail.
LocConnect is a web-based, client-server system.The design is based on a three-tier architecture asdepicted in figure 1. The implementation of the
33

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
system is based on PHP and AJAX technologies.
Figure 1. Three-tier architecture of LocConnect
User interface tier - a client-based graphical userinterface that runs on a standard web browser. Theuser interface provides facilities for projectmanagement, administration and tracking.
Middle tier - contains most of the logic andfacilitates communication between the tiers. Themiddle tier mainly consists of a workflow engine andprovides an open API with a common set of rules thatdefine the connectivity of components and their inputoutput (IO) operations. The components simply dealwith this interface in the middle tier.
Data Storage tier - uses a relational database for thestorage and searching of XLIFF and other resourcedata. The same database is used to store informationabout individual projects.
The tiers are described below.
4.1 User InterfaceWeb-based graphical user interfaces were developedfor:
1. Capturing project parameters during projectcreation;
2. Tracking projects (i.e. to display the currentstatus of projects);
3. Post-editing translations;
4. Configuring the server and localising theinterface of LocConnect.
During project creation, a web-based form ispresented to a user. This form contains fields that are
required by the Workflow Recommender to generatea workflow. Parameters entered through this interfacewill be stored in the XLIFF file along with theuploaded source file (or source text) and resourcefiles. The project is assigned a unique ID through thisinterface and this ID is used throughout the project'slifecycle.
The project-tracking interface reflects the project'sworkflow. It shows the current status of a project, i.e.pending, processing, or complete in relation to eachcomponent. It displays any feedback messages (suchas errors, warnings etc.) from components. Thecurrent workflow is shown in a graphicalrepresentation. Another important feature is a log ofactivities for the project. Changes to the XLIFF file(i.e. changes of metadata) during different stages ofthe workflow can be tracked. The project-trackinginterface uses AJAX technologies to dynamicallyupdate its content frequently (see figure 2).
Figure 2. Project Tracking UI
At the end of a project's lifecycle, the user is giventhe option to post-edit its content using the built-inXLIFF post-editor interface. It displays sourcestrings, translations, alternative translations andassociated metadata. Translations can be editedthrough this interface. The Post-editing componentalso uses AJAX to update XLIFF files in the maindatastore (see section 4.4). See figure 3 for a screen-shot of the post-editing interface. A preliminarytarget file preview mechanism has been developedand integrated into the same UI.
34

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
Figure 3. Post-Editing Interface
A password-protected interface has been provided forthe configuration of the LocConnect server. Throughthis interface various configuration options such asLocConnect database path, component descriptionsetc. can be edited. The same interface can be used tolocalise the LocConnect server itself (see figure 4 fora screenshot of the administrator's interface).
Figure 4. Administrator's Interface
The user interfaces were implemented in PHP,Javascript, XHTML and use the JQuery library forgraphical effects and dynamic content updates.
4.2 Middle tier: Application ProgrammingInterface (API)The LocConnect server implements aRepresentational State Transfer (REST) - based
interface (Fielding 2000) to send and retrieveresources, localisation data and metadata betweencomponents through HTTP-GET and HTTP-POSToperations using proper Uniform ResourceIdentifiers (URI). These resources include:
l Localisation projects;
l XLIFF files;
l Resource files (i.e. files such as TBX, TMX, SRXetc.);
l Resource Metadata (metadata to describe resourcefile content).
The LocConnect API provides functions for thefollowing tasks:
1. Retrieving a list of jobs pending for a particularcomponent (list_jobs method);
2. Retrieving an XLIFF file corresponding to aparticular job (get_job method);
3. Setting the status of a job. The status can be oneof the following: Pending, Processing, Complete(set_status method);
4. Sending a feedback message to the server(send_feedback method);
5. Sending processed XLIFF files to the sever(send_output method);
6. Sending a resource file (i.e. a non-XLIFF assetfile) to the server (send_resource method);
7. Retrieving a resource file from the server(get_resource method);
8. Retrieving metadata associated with a resourcefile (get_metadata method).
A complete description of each REST-based functionis provided below.
Obtaining available jobs: list_jobs methodThis method takes a single argument: component ID.It will return an XML containing the IDs of jobspending for any given component. The IDs arealphanumeric and consist of 10 characters. Thecomponent ID is a string (usually, a short form of acomponent's name, such as WFR for Workflow
35

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
Recommender).
This method uses the HTTP GET method tocommunicate with the LocConnect server.
<jobs><job>16674f2698</job><job>633612fb37</job>
</jobs>
Retrieving the XLIFF file corresponding to aparticular job: get_job methodThis method takes two arguments: component ID andjob ID. It will return a file corresponding to the givenjob ID and component ID. Usually, the file is anXLIFF file, however it can be any text-based file.Therefore, the returned content is always enclosedwithin special XML mark-up: <content>..</content>.The XML declaration of the returned file will beomitted in the output (i.e. <?xml version="1.0" ..?>will be stripped off from the output).
This method uses the HTTP GET method tocommunicate with the LocConnect server.
<content><xliffversion='1.2'xmlns='urn:oasis:names:tc:xliff:document:1.2'><file original='hello.txt' source-language='en' target-language='fr' datatype='plaintext'><body><trans-unit id='hi'>
<source>Hello world</source><target>Bonjour le monde</target>
</trans-unit></body>
</file></xliff></content>
Setting current status: set_status methodThis method takes three arguments: component ID,job ID, status. The status can be 'pending','processing' or 'complete'. Initially, the status of a jobis set to 'pending' by the LocConnect server to markthat a job is available for pick up by a certaincomponent. Once the job is picked by the component,it will change the status of the job to 'processing'.This ensures that the same job will not be re-allocatedto the component. Once the status of a job is set to'complete', LocConnect will perform the next actionspecified in the workflow.
This method uses the HTTP GET method tocommunicate with the LocConnect server.
Sending feedback message: send_feedbackmethodThis method takes three arguments: component ID,job ID, feedback message. Components can sendvarious messages (e.g. error messages, notificationsetc.) to the server through this method. Thesemessages will be instantly displayed in the relevantjob tracking page of the LocConnect interface. Thelast feedback message sent to the LocConnect serverbefore sending the output file will be stored withinthe LocConnect server and it will appear in theactivity log of the job. The messages are restricted to256 words in length.
This method uses the HTTP GET method tocommunicate with the LocConnect server.
Sending a processed XLIFF file: send_outputmethodThis method takes three arguments: component ID,job ID and content. The content is usually aprocessed XLIFF file. Once the content is receivedby LocConnect, it will be stored within theLocConnect datastore. LocConnect will wait for thecomponent to set the status of the job to 'complete'and move on to the next step of the workflow.
This method uses the HTTP POST method tocommunicate with the LocConnect server.
Storing a resource file: send_resource methodThis method takes one optional argument: resourceID and two mandatory arguments: resource file andmetadata description. The resource file should be intext format. Metadata has to be specified using thefollowing notation:
Metadata notation: 'key1:value1-key2:value2-key3:value3'e.g. 'language:en-domain:health'
If the optional argument resource ID is not given,LocConnect will generate an ID and assign that ID tothe resource file. If the resource ID is given, it willoverwrite the current resource file and metadata withthe new resource file and metadata.
This method usew the HTTP POST method tocommunicate with the LocConnect server.
Retrieving a stored resource file: get_resourcemethodThis method takes one argument: resource ID. Giventhe resource ID, the LocConnect server will return
36

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
the resource associated with the given ID.
This method uses the HTTP GET method tocommunicate with the LocConnect server.
Retrieving metadata associated with a resourcefile: get_metadata methodThis method takes one argument: resource ID. TheLocConnect server will return the metadataassociated with the given resource ID as shown in theexample below:
<metadata><meta key="language" value="en"><meta key="domain" value="health">
</metadata>
This method uses the HTTP GET method tocommunicate with the LocConnect server.
4.2.1 Component-Server Communication ProcessA typical LocConnect component-servercommunication process includes the followingphases.
Step 1: list_jobs
This component calls the list_jobs method to retrievea list of available jobs for that component byspecifying its ID.
Step 2: get_job
This component uses get_job to retrieve the XLIFFfile corresponding to the given job ID and thecomponent ID.
A component may either process one job at a time ormany jobs at once. However, the get_job method isonly capable of returning a single XLIFF file at atime.
Step 3: set_status - Set status to processing
This component sets the status of the selected job to'processing'.
Step 4: Process file
This component processes the retrieved XLIFF file.It may send feedback messages to the server whileprocessing the XLIFF file. These feedback messageswill be displayed in the job tracking interface of theLocConnect.
Step 5: send_output
This component sends the processed XLIFF file backto the LocConnect server using send_output method.
Step 6: set_status
This component sets the status of the selected job to'complete'. This will trigger the LocConnect server tomove to the next stage of the workflow.
4.3 Middle tier: Workflow EngineA simple workflow engine has been developed andincorporated into the LocConnect server to allow forthe management and monitoring of individuallocalisation jobs. The current workflow engine doesnot support parallel processes or branching.However, it allows the same component to be usedseveral times in a workflow. The engine parses theworkflow information found in the XLIFF datacontainer (see section 4.5) and stores the workflowinformation in the project management datastore.The project management datastore is then used tokeep track of individual projects. In the current setup,setting the status of a component to 'complete' willtrigger the next action of the workflow.
4.4 LocConnect DatastoreThe database design can be logically stratified in 3layers:
l Main datastore holds XLIFF files;
l Project management datastore holds data aboutindividual projects and their status;
l Resource datastore holds data and metadata aboutother resource files;
The main datastore is used to store XLIFF filescorresponding to different jobs. It stores differentversions of the XLIFF file that correspond to aparticular job. Therefore, the LocConnect server alsoacts as a Concurrent Versions System (CVS) forlocalisation projects.
The project management datastore is used for storingthe information necessary to keep track of individuallocalisation jobs with respect to localisationworkflows. Furthermore, it is used to store varioustime-stamps such as job pick-up time, job completiontime etc by different components.
37

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
The resource datastore is used to store various assetfiles associated with localisation projects. The assetfiles can be of any text-based file format such asTMX, XLIFF, SRX, TBX, XML etc. Thecomponents can store any intermediate files,temporary or backup files in this datastore. The filescan then be accessed at any stage during workflowexecution. The resource files (i.e. asset files) can bedescribed further using metadata. The metadataconsists of key-value pairs associated with theresource files and can also be stored in the resourcedatastore.
SQLite was chosen as the default database forimplementing the logical data structure in thisprototype, for a number of reasons. Firstly, it can beeasily deployed. It is lightweight and virtually noadministration required. Furthermore, it does notrequire any configuration.
4.5 XLIFF Data ContainerThe core of this architecture is the XLIFF-based datacontainer defined in this research. Maximum efforthas been made to abstain from custom extensions indefining this data container. Different componentswill access and make changes to this data containeras it travels through different components anddifferent phases of the workflow. The typicalstructure of the data container is given in figure 5.
When a new project is created in LocConnect, it willappend parameters captured via the project creationpage into the metadata section (see section 2) of thedata container. The metadata is stored as key-valuepairs. During the workflow execution process,various components may use, append or change themetadata. The source file uploaded by the user willbe stored within the XLIFF data container as aninternal file reference (see section 1). Any resourcefiles uploaded during the project creation will also bestored as external-references as shown in section 4.4.The resource files attached to this data container canbe identified by their unique IDs and can be retrievedat any stage during the process. Furthermore, theidentifier will allow retrieval of the metadataassociated with those resources.
After project creation, the data container generated(i.e. the XLIFF file) is sent to the WorkflowRecommender component. It analyses the projectmetadata as well as the original file format torecommend the optimum workflow to process thegiven source file. If the original file is in a formatother than XLIFF, the Workflow Recommender will
suggest that the data container to be sent to a FileFormat Converter component. The file formatconverter will read the original file from the aboveinternal-file reference and convert the source file intoXLIFF. The converted content will be stored in thesame data container using the <body> section and theskeleton sections. The data container with theconverted file content is then reanalysed by theWorkflow Recommender component in order topropose the rest of the workflow. The workflowinformation will be stored in section 3 of the datacontainer. When the LocConnect server receives thedata container back from the WorkflowRecommender component, it will parse the workflowdescription and execute the rest of the sequence.Once the entire process is completed, the convertercan use the data container to build the target file.
In this architecture, a single XLIFF-based datacontainer is being used throughout the process.Different workflow phases and associated tools canbe identified by the standard XLIFF elements such as<phase> and <tools>. Furthermore, tools can includevarious statistics (e.g. <count-groups>) in the sameXLIFF file.
The XLIFF data container based architectureresembles the Transmission Control Protocol and theInternet Protocol (TCP/IP) architecture in that thedata packet is routed based on its content. However,in this scenario, LocConnect plays several roles,including the role of a router, web server and a fileserver.
38
Localisation Focus Vol.10 Issue 1The International Journal of Localisation
39
Figure 5. XLIFF-Based Data Container

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
5. Discussion and Future Work
Savourel (2007) highlights the importance of a"Translation Resource Access API" which facilitateslocalisation data exchange among different systemsin a heterogeneous environment. Like Savrourel(2007) we also believe that access to a common datalayer through an API would enable interoperabilitybetween different localisation components. Thedevelopment of the prototype has revealedsyntactical requirements of such an API as well as thecommon data layer. Whilst the prototype provides atest bed for the exploration of interoperability issuesamong localisation tools, it has a number oflimitations.
In the present architecture, metadata is being storedas attribute-value pairs within an internal filereference of the XLIFF data container (see section 3of figure 5). However, according to the currentXLIFF specification (XLIFF-TC 2008), XMLelements cannot be included within an internal filereference. Doing so will result in an invalid XLIFFfile. While this could be interpreted as a limitation ofthe XLIFF standard itself, the current metadatarepresentation mechanism also presents severalproblems. The metadata is exposed to all thecomponents. Yet there might be situations wheremetadata should only be exposed to certaincomponents. Therefore, some security and visibilitymechanisms have to be implemented for themetadata. Moreover, there may be situations wherecomponents need to be granted specific permissionsto access metadata, e.g. read or write. Theseproblems can be overcome by separating themetadata from the XLIFF data container. That is, themetadata has to be stored in a separate datastore (asin the case of resource files). Then, specific APIfunctions can be implemented to manipulatemetadata (e.g. add, delete, modify, retrieve) bydifferent components. This provides a securemechanism to manage metadata.
The Resource Description Framework (RDF) is aframework for describing metadata (Anastasiou2011). Therefore, it is worthwhile exploring thepossibility of representing metadata using RDF. Forexample, API functions could be implemented toreturn the metadata required by a component in RDFsyntax.
The current API lacks several important functions.Functions should be implemented for deletingprojects (and associated XLIFF files), modifying
projects, deleting resource files and modifyingmetadata associated with resource files etc. Thecurrent API calls set_output and set_status to'complete' could be merged (i.e. sending the outputby a component will automatically set its status to'complete'). Furthermore, a mechanism could beimplemented for granting proper permissions tocomponents for using the above functions. Usermanagement is a significant aspect that we did notpay much attention to when developing the initial testbed. User roles could be designed and implementedso that users with different privileges can assigndifferent permissions to components as well asdifferent activities managed through the LocConnectserver. This way, data security could be achieved to acertain extent. Furthermore, an API key should beintroduced for the validation of components asanother security measure. This way, componentswould have to specify the key whenever they useLocConnect API functions in order to access theLocConnect data.
The XLIFF data container could contain sensitivedata (i.e. source content, translations or metadata)which some components should not be able to access.A mechanism could be implemented to secure thecontent and to grant permissions to components sothat they would only be able to access relevant datafrom the XLIFF data container. There are threepotential solutions to this problem. One would be tolet the workflow recommender (or the Mapper) selectonly secure and reliable components. The secondsolution could be to encrypt content within theXLIFF data container. The third solution could be toimplement API functions to access specific parts ofthe XLIFF data container. However, the lattermechanism will obviously increase the complexity ofthe overall communication process due to frequentAPI calls to the LocConnect server.
Because the XLIFF standard was originally definedas a localisation data exchange format, it has, so far,not been thoroughly assessed with regard to itssuitability as a localisation data storage format or asa data container. A systematic evaluation has to beperformed on the use of XLIFF as a data container inthe context of a full localisation project life cycle, asfacilitated by our prototype. For example, during thetraversal, an XLIFF-based data container couldbecome cumbersome causing performancedifficulties. Different approaches to addressing likelyperformance issues could be explored, such as datacontainer compression, support for parallelprocessing, or the use of multiple XLIFF-based data
40

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
containers transmitted in a single compressedcontainer. The implications of such strategies wouldhave to be evaluated, such as the need to equip thecomponents with a module to extract and compressthe data container.
While the current workflow engine provides essentialprocess management operations, it currently lacksmore complex features such as parallel processes andbranching. Therefore, incorporation of a fully-fledged workflow engine into the LocConnect serveris desirable. Ideally, the workflow engine shouldsupport standard workflow description languagessuch as Business Process Execution Language(BPEL) or Yet Another Workflow Language(YAWL). This would allow the LocConnect server tobe easily connected to an existing business process,i.e. localisation could be included as a part of anexisting workflow. In the current system, theworkflow data is included as an internal file referencein the XLIFF data container (see section 3 of figure5) which invalidates the XLIFF file due to the use ofXML elements inside the internal file reference. Infuture versions, this problem can be easily addressedby simply storing the generated workflow as aseparate resource file (e.g. using BPEL) andproviding the link to the resource file in the XLIFFdata container as an external file reference.
LocConnect implements REST-based services forcommunication with external components.Therefore, it is essential to implement our ownsecurity measures in the REST-based API. Sincethere are no security measures implemented in thecurrent LocConnect API, well-established andpowerful security measures such as XML encryption,API keys would need to be implemented in the APIas well as in the data transmission channel (e.g. theuse of Secure Socket Layer (SSL) tunnels for RESTcalls).
Currently, the LocConnect server implements a'PULL' based architecture where components have toinitiate the data communication process. Forexample, components must keep checking for newjobs in the LocConnect server and fetch jobs from theserver. The implementation of both 'PUSH' and'PULL' based architectures would very likely yieldmore benefits. Such architecture would help tominimize communication overhead as well asresource consumption (e.g. the LocConnect servercan push a job whenever a job is available for acomponent, rather than a component continuouslychecking the LocConnect server for jobs). The
implementation of both 'PUSH' and 'PULL' basedarchitectures would also help to establish theavailability of the components prior to assigning ajob, and help the LocConnect server to detectcomponent failures. The current architecture lacksthis capability of identifying communication failuresassociated with components. If the LocConnectserver could detect communication failures, it couldthen select substitute components (instead of failedcomponents) to enact a workflow. An architecturesimilar to internet protocol could be implementedwith the help of a Mapper component. For example,whenever the LocConnect server detects acomponent failure, the data container could beautomatically re-routed to another component thatcan undertake the same task so that the failure of acomponent will not affect the rest of the workflow.
The current resource datastore is only capable ofstoring textual data. Therefore, it could be enhancedto store binary data too. This would enable the storingof various file formats including windows executablefiles, dll files, video files, images etc. Once theresource datastore is improved to store binary data,the original file can be stored in the resourcedatastore and in XLIFF, and a reference to thisresource can be included as an external file reference(see section 1 of figure 5).
In the present architecture, the information aboutcomponents has to be manually registered with theLocConnect server using its administrator interface.However, the architecture should be improved todiscover and register ad-hoc componentsautomatically.
5.1 Proposed improvements to the XLIFF baseddata container and new architectureBy addressing the issues related to the above XLIFF-based data container, a fully XLIFF compliant datacontainer could be developed to evaluate its effect onimprovements in interoperability. A sample XLIFFdata container is introduced in figure 6.
This data container differs from the current datacontainer (see figure 5) in the following aspects:
The new container:
l Does not represent additional metadata (i.e.metadata other than that defined in the XLIFFspecification) within the data container itself.Instead, this metadata will be stored in a separatemetadata store that can be accessed via
41

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
corresponding API functions.
l Does not represent workflow metadata as aninternal file reference. Instead, the workflowmetadata will be stored separately in the resourcedatastore. A link to this workflow will then beincluded in the XLIFF data container as anexternal file reference (see section 2 of figure 6).
l Does not store the original file as an internal filereference. It will also be stored separately in theresource datastore. An external file reference willbe included in the XLIFF file as shown in section1 of figure 6.
The new data container does not use any extensionsto store additional metadata or data, nor does it useXML syntax within internal-file elements. Thus, theabove architecture would provide a fully XLIFFcompliant (i.e. XLIFF strict schema compatible)interoperability architecture. Due to the separation ofthe original file content, workflow information andmetadata from the XLIFF data container, thecontainer itself becomes lightweight and easy tomanipulate. The development of a file formatconverter component based on this data containerwould also be uncomplicated.
6. Conclusions
In this paper we presented and discussed a service-oriented framework that was developed and then
applied to evaluate interoperability in localisationprocess management using the XLIFF standard. Theuse cases, architecture and issues of this approachwere discussed. A prototype of the framework wassuccessfully demonstrated at the CNGL PublicShowcase in Microsoft, Ireland, in November 2010.
The framework has revealed the additional metadataand related infrastructure services required forlinking distributed localisation tools and services. Ithas also been immensely helpful in identifyingprominent issues that need to be addressed whendeveloping a commercial application.
The prototype framework described in this paper isthe first to use XLIFF as a data container to addressinteroperability issues among localisation tools. Inour opinion, the successful implementation of thispilot prototype framework suggests the suitability ofXLIFF as a full project life-cycle data container thatcan be used to achieve interoperability in localisationprocesses. The development of the above prototypehas mostly focused on addressing the syntacticinteroperability issues in localisation processes. Thefuture work will mainly focus on addressing thesemantic interoperability issues of localisationprocesses by improving the proposed system. TheLocConnect framework will serve as a platform forfuture research on interoperability issues inlocalisation.
42
Figure 6. Improved Data Container

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
Acknowledgement
This research is supported by the Science FoundationIreland (Grant 07/CE/I1142) as part of the Centre forNext Generation Localisation (www.cngl.ie) at theLocalisation Research Centre (Department ofComputer Science and Information Systems),University of Limerick, Limerick, Ireland. We wouldalso like to acknowledge the vital contributions ofour colleagues and fellow researchers from theCNGL project.
References
Anastasiou, D. and Morado-Vazquez, L. (2010)'Localisation Standards and Metadata', ProceedingsMetadata and Semantic Research, 4th InternationalConference (MTSR 2010). Communications in Computerand Information Science, Springer, 255-276.
Anastasiou, D. (2011) 'The Impact of Localisation onSemantic Web Standards', in European Journal of ePractice,N. 12, March/April 2011, ISSN 1988-625X, 42-52.
Bichler, M. and Lin, K. J. (2006) 'Service-orientedcomputing'. IEEE Computer 39(3), 99-101.
Bly, M. (2010) 'XLIFFs in Theory and in Reality' [online],available: http://www.localisation.ie/xliff/resources/presentations/xliff_symposium_micahbly_20100922_clean.pdf [accessed 09Jun 2011].
Corrigan, J. & Foster, T. (2003) 'XLIFF: An Aid toLocalization' [online], available: http://developers.sun.com/dev/gadc/technicalpublications/articles/xliff.html[accessed 22 Jun 2009].
Fielding, R. (2000) 'Architectural Styles and the Design ofNetwork-based Software Architectures' [PhD], Universityof California, Irvine.
Halle, S., Bultan, T., Hughes, G., Alkhalaf, M. andVillemaire, R. (2010) 'Runtime Verification of Web ServiceInterface Contracts', Computer, 43(3), 59-66.
Hayes, J. G., Peyrovian, E., Sarin, S., Schmidt, M. T.,Swenson, K. D. and Weber, R. (2000) 'Workflowinteroperability standards for the Internet', InternetComputing, IEEE, 4(3), 37-45.
IEEE. (1991) 'IEEE Standard Computer Dictionary. ACompilation of IEEE Standard Computer Glossaries', IEEEStd 610, 1.
Kindrick, J. D., Sauter, J. A. and Matthews, R. S. (1996)'Improving conformance and interoperability testing',StandardView, 4(1), 61-68.
Lewis, G. A., Morris, E., Simanta, S. and Wrage, L. (2008)'Why Standards Are Not Enough to Guarantee End-to-EndInteroperability', in Proceedings of the SeventhInternational Conference on Composition-Based SoftwareSystems (ICCBSS 2008), 1343630: IEEE ComputerSociety, 164-173.
Savourel, Y. (2007) 'CAT tools and standards: a briefsummary', MultiLingual, September 2007, 37.
Schäler, R. (2009) 'Communication as a Key to GlobalBusiness'. In: Hayhoe, G. Connecting people withtechnology: issues in professional communication.Amityville N.Y. Baywood Pub. 57-67.
W3C. (2007) 'Web Service Description Language (WSDL)'Version 2.0 Part 1:Core Language, W3C Recommendation[online]. In Chinnici, R., Moreau, J, J., Ryman, A. andWeerawarana, S. eds.W3C, http://www.w3.org/TR/wsdl20.
XLIFF Technical Committee. (2008). 'XLIFF 1.2Specification' [online]. http://docs.oasis-open.org/xliff/xliff-core/xliff-core.html [accessed 25 Jun 2009].
XLIFF Technical Committee. (2010) 'XLIFF2.0 / FeatureTracking' [online], http://wiki.oasis-open.org/xliff/XLIFF2.0/FeatureTracking, [accessed 23 Jul2009].
43

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
1. Localisation in large-scale assessments
Most software or website localisation projects havethe "ultimate aim of releasing a product that lookslike it has been developed in country" (LISA 2003,p.11). This aim is reasonable for many instances oflocalisation. However, when moving to internationallarge-scale assessment studies (studies that aim tocompare skills or competence levels for givenpopulations across countries, with a view to e.g.informing education policies), localisation issubjected to the primacy of comparability ofassessment results, which may conflict with the aimof making a localised product look like it wasdeveloped in the target country itself. Unlike otherlocalisation projects, localising assessments has to beundertaken with an eye on the comparability ofmultiple target versions of assessment instruments(e.g. tests). If translated tests behave differently indifferent countries (e.g. the difficulty varies acrosslanguage versions), the significance of the research isat stake. This article will describe this potentialconflict between authenticity and comparabilitywhen localising large-scale assessments on the basisof a case study.
In the remaining part of section 1, we will definelarge-scale assessments and add the most importantdetails regarding the case study; this is followed byan overview of the particularities of localisation inlarge-scale assessment compared to web or softwarelocalisation processes. In Section 2, we will describehow these challenges can be met and show practicalexamples from our case. Section 3 will give anoverview of the lessons learned.
1.1 What is large-scale assessment?Policy makers around the globe need internationallycomparable information about the outcomes of theireducation systems, information on what pupils know,and an overview of the skills and competencies oftheir adult workforce. This need has led to theintroduction of international large-scale assessmentstudies, and since their implementation, localisingthe test content has become an important issue in thefield.
In the current context, the term large-scaleassessment (LSA) refers to national or internationalassessments that serve to describe populationcharacteristics with respect to educational conditions
44
Localisation in International Large-scale Assessments ofCompetencies: Challenges and Solutions
Britta Upsing1, Gabriele Gissler1, Frank Goldhammer1, Heiko Rölke1, Andrea Ferrari2[1]German Institute for International Educational Research,
Schloßstraße 29,60486 Frankfurt am Main
www.tba.dipf.de[2] cApStAn Linguistic Quality Control,
Chaussée de la Hulpe 268,1170 Bruxelles,www.capstan.be
[email protected], [email protected], [email protected], [email protected], [email protected]
AbstractInternational comparative studies like the Programme for International Student Assessment (PISA) pose specialchallenges to the localisation of the test content. To allow for comparison between countries, the assessments haveto be comparable with respect to measurement properties. Therefore, internationalisation and localisation arecrucial steps to guarantee test equivalence across countries. The localisation of test items is different from thelocalisation of web-based contents or software as the test content has to be authentic within a country while thetest's measurement properties have to be comparable across countries. Using the PIAAC study (Programme for the Assessment of Adult Competencies) as an example, this paperdescribes all stages of the localisation process for an international large-scale assessment. The process ranges fromthe development of source items to translation, adaptation of layout issues and meta-data adaptations. The paperconcludes with a discussion of lessons learned and open questions.

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
and learning outcomes, e.g. the competence level in aparticular population. Basically, LSA studies are usedfor monitoring the achievement level in a particularpopulation, for comparing assessed (sub)populations,and also for instructional programme evaluation.Such assessments may form the basis for developingand/or revising educational policies.
The International Association for the Evaluation ofEducational Achievement (IEA) was one of the firstorganisations to implement international LSA studiesto assess student achievement across countries. In1995, IEA implemented TIMSS (Trends inInternational Mathematics and Science Study) toassess student achievement in mathematics, just tomention one example (Mullis et al. 2009). The mostwidely known LSA study is the Programme forInternational Student Assessment (PISA) by theOrganisation for Economic Co-operation andDevelopment (OECD). The first PISA cycle tookplace in 2000; cycles are repeated every three years.By 2012, more than 70 countries will haveparticipated in PISA. PISA intends to measure theknowledge and skills of fifteen-year-old students andthus make inferences on the performance of theparticipating countries' education systems (OECD2010). A very first step in the shift to computer-basedassessment was made in 2006 when three countriestook part in the computer-based assessment ofscience. In 2009, participating countries had theoption to evaluate the digital reading skills of theirstudents, and a more substantial shift to thecomputer-based test mode was taken. 19 countries opted for this assessment (OECD 2011).
There have also been several attempts to measure thecompetencies of adult populations (cf. Thorn 2009):In 1994, the OECD introduced the first cycle of theInternational Adult Literacy Survey (IALS) to obtaininformation about adult literacy (prose literacy,document literacy, and quantitative literacy) inparticipating countries and two more roundsfollowed (1996 and 1998). Altogether 22 countriesparticipated in this survey. The OECD Adult Literacyand Lifeskills Survey (ALL) builds on the results ofthis study and provides an international comparisonof literacy, numeracy and problem-solving skills in
12 countries. It took place between 2002 and 2006.This study is now followed by the Programme for theInternational Assessment of Adult Competencies(PIAAC), an international large-scale survey thatassesses the skills of a representative sample of adultsin 25 countries.
This paper will use the example of PIAAC todescribe the localisation process in LSA studies. LikePISA, PIAAC is an OECD study. PIAAC is supposedto help governments to receive "high-qualitycomparative information regarding the fundamentalskills of the adult population" (Schleicher 2008, p.628). The target population consists of 16-65 year oldadults. The project is run by an internationalconsortium (that includes the authors of this paper)that is responsible for enabling the local projectteams to conduct the study in their respectivecountries. The implementation of PIAAC started in2007. The field study1 took place in 2010; the mainstudy will be carried out in 2011 and 2012. Resultswill be published in 2013. PIAAC-tests aresubdivided into three different subject domains:literacy, numeracy and problem-solving in atechnology-rich environment. In each of thedomains, the competencies of the test participants areassessed by a number of test items2 of varyingdifficulty.
Figure 1: Sample numeracy test item (question on the left, stimulusmaterial on the right)
The assessment items are preceded by a
45
1The field study serves to prepare the main study in several respects. Major goals are to evaluate the survey operations (e.g. sampling, datacollection), and to investigate empirically the assessment instruments including their psychometric characteristics (e.g. comparability acrosscountries). Based on field study results, data collection procedures and assessment instruments are revised (e.g. by dropping ill-fitting items).2 In our context, an item is the smallest assessable entity of a test. It consists of a stimulus that serves to evoke an observable response from the testtaker; this is the material that the subject uses to answer the question. Individual differences in the response are assumed to reflect individualdifferences in the assessed ability or competence. Multiple items assessing the same ability form a test that allows to measure individual abilitylevels reliably. Individual response patterns observed across the items of a test are the empirical basis for estimating the subjects' ability levels.Multiple items including one shared stimulus are usually referred to as a unit.

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
questionnaire which collects background informationabout the test participant. The sample includes 5000completed interviews per country. PIAAC is ahousehold study: the interview and the test itself takeplace in a respondent's home (Thorn 2009). PIAAC isthe first international LSA study that is completelycomputer-based3, and therefore the first study to meetthe specific challenges resulting from this test mode.Other studies are likely to follow this trend (e.g.PISA 2015).
As previously mentioned, localisation is an importantissue because all assessment instruments (i.e., testsand questionnaires) have to be made available in thenational language(s) of every participating country.PIAAC and other LSAs are challenged by localisingthe test items while maintaining the comparability ofassessment results across countries and languages.This will be further elaborated in the next section.
1.2 Particularities of internationalisation andlocalisation in assessmentsThe localisation of LSA boils down to two questions:What exactly does it mean to internationalise andlocalise a test? How is this different from otherlocalisation projects?
Adaptation of test items can occur in two scenariosand is not limited to large-scale assessments. In thefirst scenario, a test is originally developed for aspecific language and its specific national context.Using the test internationally is not an issue whendeveloping the test items. If, later on, the need arisesto adapt the test for a new culture and language, thegoal may be to obtain strict comparability, or thesource test may just serve as the blueprint of a newtest. This means that test developers have to decide"whether test adaptation is the best strategy"(Hambleton 2002, p. 65). In the second scenario,which is typical in the LSA context, the intended useof the test in an international comparison is a crucialfactor right from the outset of developing the test.This is to ensure "that a person of the same abilitywill have the same probability of answering anyassessment item successfully independent of his orher linguistic or cultural background" (Thorn 2009,p.8). Hence, in this second scenario,internationalisation plays an important role inmaking sure that the adaptation of the test will befeasible.
For computer-based tests, linguistic, cultural andtechnical aspects have to be taken into account tocreate "internationalised" source4 items. Thefollowing definition by Schäler (2007, p.40) isapplicable for the internationalisation of LSA studiesas well:
"Internationalisation is the process ofdesigning (or modifying) digital content (inits widest sense) . . . to isolate thelinguistically and culturally dependent partsof an application and of developing a systemthat allows linguistic and cultural adaptationsupporting users working in differentlanguages and cultures."
From a conceptual point of view, this means thatsource item content has to be created that ismeaningful and authentic in all target cultures, aswell as easily translatable. From a technical point ofview, software developers have to make sure thattranslators can easily edit all adaptable content.
In a second step, the adaptable content has to belocalised. Localisation is defined by Schäler (2007,p.40) as follows:
"Localisation is the linguistic and culturaladaptation of a digital product or service tothe requirements of a foreign market and themanagement of multilinguality across theglobal, digital information flow."
In the context of LSA, not all of these factors play animportant role. While Schäler emphasizes theadaptation for the target culture and making sure thatthe product works in the target culture, in the contextof LSA, it is important that test items remaincomparable across different language versions. Thecreation of test items for an international comparativetest is thus highly demanding. On the one hand, it isimportant that the items are authentic within acountry; on the other hand, they have to becomparable across countries. This is one of thecrucial aspects that differ from other localisationprocesses, resulting in a multi-step adaptationprocess.
A second aspect deals with the material that has to belocalised. In a computer-based test like PIAAC,
46
3It should be noted though that there is a paper-based component for test participants that are not familiar with using a computer.4 "Source" and "target" are used in this paper in the usual meaning in the translation context: the source text (or in our case the source item) refersto all aspects of an item, i.e., text, graphic elements, scoring information etc., which are being translated and/or adapted. The target text (or targetitem) is the translated and adapted version of the source text (source item).

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
localisation is not limited to the content of a test item.Meta-data like material related to the correct andincorrect responses of test items will have to beadapted as well. This is an aspect that plays a key rolein the localisation process of computer-based LSA.In computer-based tests this meta-data will have to bechanged in the system itself to enable automaticscoring (detailed information on this process followsin section 2.2.2).
Section 2 will explain how these two aspects aretackled in the LSA study PIAAC.
2. Case study: Localising PIAAC assessmentinstruments
Section 1.2 showed that the context of LSA placesspecial requirements on the localisation process. InPIAAC, this challenge was met by firstinternationalising and then localising the test content.Section 2.1 describes how this was done by firstcreating 'internationalised' source versions of testitems, while section 2.2 contextualises the insightsinto the localisation process itself with a focus onquality assurance.
2.1 Internationalising test itemsBefore the item development process can start, the"competence" that shall be measured by these itemshas to be defined. Basically, a competence is atheoretical construct that is used to explain andpredict individual differences in behavior. Mosteducational LSA studies target the assessment ofindividual differences in competencies like "readingliteracy" (in broad terms: how well can the testparticipant read and understand text?) or "numeracy"(again in broad terms: how well can the testparticipant deal with mathematical demands?).Defining the construct is a complicated process and"construct equivalence in the languages and culturesof interest" has to be kept in mind (Hambleton 2002,p. 65). Once the construct is specified and refined byan international expert group, the experts derive an"assessment framework" on the basis of the constructdefinition (cf. Kirsch 2001). This assessmentframework explains how the test and taskcharacteristics are related to the construct definition,and it provides systematic information about therequired combinations of task characteristics to coverthe construct. The creation of items can start once theassessment framework is set. In all LSA studiesmentioned in chapter 1.1, the source items (seeFigure 1 for an example) are created in English. Theyform the basis for the later localisation process.
Throughout the entire item development process, theinternational perspective takes an all-pervasive roleand several qualitative control mechanisms are inplace to make sure that linguistic and interculturalaspects are considered from as many linguistic andcultural perspectives as possible. A detaileddescription of how such a process can be establishedcan be found in McQueen and Mendelovits (2003).When the source items are developed, the focus isalready on authenticity and comparability. Theprocesses involved in ensuring that authentic andcomparable items are created will be explained insection 2.1.1 and 2.1.2.
2.1.1 Authenticity of item contentIn most software or web localisation projects,authenticity is the "ultimate aim" (LISA 2003, p. 11)as the localised projects are supposed to look likethey were developed in the target country itself. ForLSA studies, this means that test items should beauthentic. These items should represent demands thatare common and typical within a country.Furthermore, items should include task requirementsthat are encountered by members of the targetpopulation in their daily life. Real-life scenarios,however, are different across countries: a Japanesescenario may not be authentic in Chile. For instance,an item that asks the test participant to do a Googlesearch and to evaluate the search results may be veryauthentic in many countries, but it is unfamiliar tomost Koreans (where the Google search engine ishardly used). The second goal in LSA studies, i.e.comparability between localised versions, might becompromised if an item's context is familiar to somecountries' populations but completely unknown inothers. All localised versions of an item shouldfunction like the source version of the item, therebyyielding a high level of psychometric comparabilityacross localised versions. The major goal is that anitem has the same degree of difficulty for allcountries and measures the respective constructequally well across all countries.
Hence, when item developers create the sourceversion of a test item, they try to look for the lowestcommon denominator. This holds the risk of creatingitem material that is "bland" because the commondenominator is too low. As a compromise, thefollowing approach as used for the PISA readingassessment may be reasonable:
"The aim (…) was not to produce aninstrument whose content and contexts werecompletely familiar to all participating
47

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
students, but, as far as possible, to control theoccurrence of unfamiliarity so that no singlecultural or linguistic group would be placedat a disadvantage." (McQueen andMendelovits 2003, p. 216)
Item developers thus need to be careful when theiritems refer to national aspects, e.g. certain locations,institutions, education systems, currencies etc., asthis raises many questions: Is the aspect known in allparticipating countries? Does the level of familiarityhave an impact on the difficulty of the task? Is thisaspect a fundamental for covering the construct?
For example, items that include aspects concerning aparticular national education system raise problemseven if every country might be able to localise theprovided information. Educational terms (e.g.community college) can have different meanings indifferent countries - and be completely unknown inothers. Another issue that could make a test item lessauthentic in some countries is any reference to theclimate or weather in relation to differentseasons/months. Though a scenario involving asummer party taking place in July is realistic inEurope, this scenario is not plausible in Australia.
Decisions on how to ensure authenticity have to bemade on a case-by-case basis and alternativesolutions are possible. Item developers could decideto replace the national reference with a fictitiousname, and consequently standardise the requiredlevel of the tested persons' ability to abstract (e.g. inPISA, zed is the fictional currency unit). If the sourceversion is not standardised in this way, itemdevelopers have to indicate to translators how to dealwith this issue (e.g. if standardisation isrecommended, translators might be advised to "findan equivalent institution in your country" or ifstandardisation is not recommended, they might beasked to "use the existing name of the institutionalthough this institution is unknown in yourcountry"). In most LSA studies, item developers aresupported by international content experts and theparticipating countries themselves in making thesedecisions and in selecting or designing suitable items(cf. McQueen and Mendelovits 2003).
In PIAAC, similar measures were taken to control thedegree of unfamiliarity across countries. Domainexpert groups were set up to represent a wide rangeof languages and cultures. These expert groups wereresponsible for creating the assessment framework,which served as a basis for creating items. The item
developers created items that simulate authentic real-life scenarios. The experts checked these itemskeeping an eye on familiarity across cultures. Theselected items were presented to representatives ofthe participating countries, who were given theopportunity to check early versions of the items forcultural bias. Only those items that were accepted bycountries were translated and used for the field test.Following the field test, items that workedinconsistently across countries were dropped ormodified before being included in the main study.
2.1.2 Further measures for enabling comparabilityTo avoid item translations that could jeopardisecomparability between localised versions, severalmeasures related to linguistic and layout issues canbe implemented when preparing the source items:
1) Careful linguistic construction of the source textto ensure translatability
2) Guidelines informing translators about the degreeto which they can adapt translations to theircountries
3) Central control of the layout of the item
4) Control of adaptable parts of an item
To ensure translatability, item developers refer to anumber of general guidelines. For example, theyshould only use idiomatic speech in the sourceversion of an item with great care, as it could be verydifficult to find adequate formulations for each of thetarget languages. Also, it might be difficult to findadequate translations of things like proverbs. Itemquestions should not be directed at the "level ofnuances of language" (McQueen and Mendelovits2003, p.215). Generally, the passive voice should beavoided because it does not exist in all languages(Hambleton 2002, p. 71).
Item creation must be accompanied by detailedtranslation guidelines for preparing the subsequentlocalisation process, otherwise comparabilitybetween target versions would be questionable fromthe outset because translators for different languagesmight assume different degrees of "translatingfreedom". These guidelines should answer allquestions that a translator may have regarding theadaptation of specific item content ("Can I adapt thenumber format to the number format that is used inmy country?", "Can I adapt the name of theinstitution?"…). In addition, guidelines should
48

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
provide general instructions for the translation ofassessment items. This can include explaining whichstyle of speech needs to be used in certain settings,general information about translating assessmentitems. For example: make sure that answer choicesare kept about the same lengths in the translation sothat they do not become a clue to the correct answer,information about the target audience, etc.(Hambleton, Merenda & Spielberger 2005).
In PIAAC, translators received "translationguidelines" with general instructions on how totranslate assessment items. A second document, the"translation and adaptation guidelines", describes thestructure and content of each item as well as thecorrect and incorrect answers. It gives advice fortranslating item-specific content, e.g. on how thetranslator should deal with names (adapt or not?). Inaddition to the general translation and adaptationguidelines, a so-called verification follow up form(VFF) is used to organise and control the localisationprocess. The VFF is a spreadsheet containing all textelements of an item and related instructions,including precise translation/adaptation advicerelating to specific text elements (what should beadapted, what should not, how to understandambiguous or difficult terms, pointers on consistencyboth within and across units, etc.). The VFF serves asa means to document all comments and successivetranslated versions of each item as it goes through thedifferent phases of the localisation process: doubletranslation and reconciliation, verification, country'spost verification review, layout adaption, finalisation(for more details, see section 2.2.1).
The context of LSA studies may involve specificrequirements regarding item layout when designingthe source versions. Item developers want to be incontrol of the item layout across language versions asthe position of information that is crucial forcompleting a task may affect item difficulty (Freedle1997). This is the case when scrolling is required tosee all of the text included in an item (for example ina stimulus that imitates a webpage); or when a longtext is divided into several columns. To ensurecomparability in these cases, it may be important thatthe starting position of text elements like headlines,paragraphs or the location of the correct response isexactly the same for all language versions. This couldbe solved by designing the source version in a waythat precludes the introduction of cross-countryvariability in critical properties of the text layout.Therefore, the item editing software should allow fordefining the absolute position of each element on the
screen. In PIAAC, the CBA ItemBuilder was used asa tool for developing the source version of test items.The concept of the CBA ItemBuilder is to enableitem writers to design and edit computer-based testitems with the aid of a graphical editor that can easilybe used by non-IT-specialists. The differentcomponents of an item can be positioned in thedrawing area. The item writer has full control overthe absolute size and position of the differentcomponents because each element can be alignedpixel by pixel on the screen. Consequently, thelocation of these elements cannot be changed whenthe text is translated. In anticipation of layoutproblems that could occur after translating theEnglish source version to the different languages, thesize of each text field was not only made as large asnecessary for the English text, but was enlarged byapproximately 1/3 to have enough space forlanguages that require more space for the samecontent, e.g. German or Russian.
Finally, with regard to the subsequent localisationprocess, it needs to be decided which components ofthe source items need to be adaptable, and whichshould be static across language versions. Basically,only those elements which are meant to be translatedor adapted during the localisation process should beadaptable. Otherwise, comparability may becompromised due to uncontrolled changes.
An item usually consists of graphical and textualelements. For computer-based items, these textualelements can also include meta-data like scoringinformation. All textual elements need to beadaptable for translating the content to the targetlanguage. In addition, one could also think ofadapting the graphical elements of a test item. Forexample, this would be necessary when adapting anitem that simulates a website to a right-to-left writtenlanguage system. To achieve an authentic context forthis language version, not only does the text need tobe adapted, but also the text layout and the websitestructure.
In PIAAC, none of the participating countries used aright-to-left written language system; therefore onlytextual elements were made adaptable. Also, allcountries were supposed to use the same images asthe source item. As a consequence, textual andgraphical elements needed to be technicallyseparable. Moreover, graphics should not contain anytextual elements but if needed were superimposed bytextual elements. Even symbols were to be avoidedor at least checked in terms of their international
49

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
suitability.
The software that was used for building the sourceversions allowed the separation of the entire textualcontent from the graphical representation of an item,and to export this adaptable content as an XLIFF5file. Later on in the localisation process, this XLIFFfile was used for translation purposes. Once the texthad been translated and validated, the XLIFF file wasreimported to the test item.
The finalised internationalisation process results in aset of carefully checked and reviewed source items.These items serve as a basis for the localisationprocess, which will be described in section 2.2.
2.2 Localising test itemsThe localisation process consists of several steps toobtain items that can function comparably acrosscountries as well as being authentic within a country.The content - mostly text - included in the item has tobe adapted, but in several cases the layout or thescoring has to be adapted as well.
Section 2.2.1 will describe the adaptation and qualityassuranceprocedures involved in adapting the textualcontent, section 2.2.2 will describe the layoutadaptations, and section 2.2.3 will explain whymetadata such as the scoring of an item may have tobe adapted as well, and how this can be done.
2.2.1 Localising the contentThe International Test Commission Test AdaptationGuidelines (cf. Hambleton and de Jong 2003, p. 129)ask for a highly sophisticated translation procedure:
"D.5 Test developers/publishers shouldimplement systematic judgmental evidence,both linguistic and psychological, to improvethe accuracy of the adaptation process andcompile evidence on the equivalence of alllanguage versions."
The translations should correctly deliver the content,be authentic and fluent, and at the same time theymust not change the psychometric properties of theitem. Thus, for LSA it is recommended to set uprigorous translation procedures that involve morethan one translator for the adaptation of test items.Also, one individual can hardly meet the requiredtranslator's profile:
"There is considerable evidence suggestingthat test translators need to be (1) familiarwith both source and target languages and thecultures, (2) generally familiar with theconstruct being assessed, and (3) familiarwith the principles of good test developmentpractices." (Hambleton 2002, p. 62)
For LSA, the double-translation design isrecommended. Double-translation means that twotranslators create two independent translations of thesource text. This is followed by a "reconciliation",which consists of merging the two independenttranslations into one target version. As Grisay (2003,p. 228) puts it:
"equivalence of the source and targetlanguages is obtained by using three differentpeople (two translators and one reconciler)who all work on the (sic!) both source and thetarget versions."
In general, the idea is bringing together linguistic,domain and assessment experts that work as a team increating the best possible target version.
In PIAAC, double-translation and reconciliationwere carried out by the project teams within countriesand the translation efforts were subsequently checkedby a "verification" process provided by theinternational consortium in charge of the project.Specially recruited and trained verifiers checked bothformal correspondence of target version to the sourceversion and fluency/correctness in the target version,striving to achieve an optimal balance between thesetwo goals, which sometimes pull different ways (e.g.maintaining the order of presentation of theinformation within a sentence or passage - versusopting for a more "natural" order in the targetlanguage). They also check whether the above-mentioned layout and adaption guidelines arefollowed. Verification was followed by a discussionwith the reconciliation team. An optical layout checkwas also necessary because the translation often hadan impact on the layout. This was then followed bytesting of the scoring mechanism (cf. chapter 2.2.3)and finally by testing the integrated assessment tests.
For this multi-step localisation process, extensivedocumentation of all changes and comments isindispensable, as also highlighted by the
50
5XLIFF is the abbreviation for XML Localisation Interchange File Format. It is a standard file format which permits making adaptable data editableand manageable within a localisation process (Savourel et al. 2008).

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
International Test Commission Test AdaptationGuidelines6 (Hambleton and de Jong 2003, p. 130):
"I.1 When a test is adapted for use in anotherpopulation, documentation of the changesshould be provided, along with evidence ofthe equivalence."
In PIAAC, so-called Verification Follow Up Forms(VFF)7 were used, which contained the afore-mentioned translation and adaptation guidelines andprovided space for discussion for the different peopleinvolved in the translation process. The verifier whochecked the reconciled version could add commentsand recommendations to one or several parts of thetranslation, and the country's reconciliation teamcould respond by accepting or refusing the verifier'srecommendations. In the VFFs, the different playerscould also explain the reasons and motives for theirdecisions. Thus, for each country detaileddocumentation was generated that contained asummary of the decisions made for every singlelocalisation issue. Errors or changes that were validfor all countries were compiled in a special "erratasheet" available for all countries.
In practice, translators (or reconcilers or verifiers)were only able to translate the text derived from thetest items and made available for them in theaforementioned XLIFF file. Everybody involved inthe translation process could preview the Englishsource version of the test item on a web-based ItemManagement Portal. More importantly, they werealso able to interact with the item in the way the testparticipant would during the test (e.g. they couldanswer the item, click on links within the stimulus,see all different pages that were included in items thatsimulated webpages etc.). After translating an XLIFFfile or after correcting a translated version, it waspossible to upload the translation to the portal andpreview the translation there. For the translation ofthe XLIFF text, the Open Language Tool (OLT)8 wasused. The OLT includes a Translation Memory,which helps to maintain consistency across test units.
2.2.2 Localising the layoutLayout adaptations became necessary aftertranslating despite all efforts made during theinternationalisation process described in section 2.1.
Country teams were required to check all their itemsfor potentially corrupt layout and report these issuesto the consortium, which then tried to adapt thelayout as required by the country. This resulted in aprotracted exchange of communication between allpartners involved until all problems were taken careof.
As mentioned in section 2.1.2, the source versionprovided extra space to accommodate languageswhose translations take up more space than Englishdoes. In several cases, the allocated space was stillinsufficient and had to be extended (or resulted in asmaller font). For languages that took up less spacethan the source version, the layout had to be adaptedin a few cases as well.
In a few isolated cases, graphics had to be exchangedin a localised item for authenticity reasons (forexample, an image that shows bottles had to beexchanged when the beverage itself was not knownin the country or carried specific connotations).
Also, justified text - which looked like, for example,an authentic newspaper article in the source item -looked unusual in some translations because thelanguages had much longer word lengths than theEnglish original. This problem was solved byhyphenating words. In such cases, hyphenated textwas not included in text that was crucial foranswering the item. All of these issues (and more)were discussed and checked by item experts to ensurethat they would not compromise cross-countrycomparability.
2.2.3 Localising the scoringIn a computer-based test, a respondent can provideanswers in several ways: response types can includemultiple choice, short text entry, numeric entry,selection of radio buttons or combo boxes, text fieldentry, highlighting text, marking graphical objects orcells, and many more. The entries given by therespondent then have to be scored. Scoring itemsmeans that a score is assigned to the test participant'sresponse. The score is defined by a scoring rule,which relates (ranges of) responses to scores.Automatic, machine-based scoring requires definingscoring rules within the system. Manual scoring, byhuman experts, relies on scoring guidelines includingscoring rules and assignments of typical responses toscores.
51
6These guidelines were set up to support test item developers when adapting test intstruments (Hambleton and de Jong 2003).7 cApStAn, a linguistic quality control company, was responsible for the generation of VFFs and for the general translation and adaptationprocedures. Their verifiers were responsible for checking the translated versions produced by the country teams. 8 The OLT is an open-source tool that is available online (The Source for Java Technology Collaboration n.d.).

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
Most response types, with the exception of free textentry, can be automatically scored by a computersystem in a straightforward manner. Automaticscoring can be more efficient than human scoring asthe time-consuming work by human scorers is notnecessary. Whenever adaptive testing9 is used,automatic scoring becomes a pre-requisite.
In a test that has to be translated, adaptation of thescoring usually does not pose any difficulties forresponse types such as multiple-choice or markinggraphical objects or cells. Here it is most importantthat the text is translated. The choice of correct orincorrect responses usually does not change theirlocation (in most languages) and no furtheradaptation is necessary. However, some scoringinformation is language or country specific and has tobe prepared in a way that allows for its localisation.
One example is the scoring of numeric responses, forinstance in the case of items involving currencies. Anitem might ask the respondent to calculate the priceof a purchase, e.g. "This radio costs 30 dollars.How much does it cost when a 10 % discount isgiven?". The correct response is "27 dollars" in ourexample. If the price of the radio and the correctresponse are not adapted in a country with a differentcurrency (for example, Japan where 1 USD = approx.80 Yen), the item context is no longer authentic. In
PIAAC (in contrast to PISA where the fictionalcurrency zeds is used, as mentioned earlier), realcurrencies were retained, with guidelines foradaptation. In such a case, the localisation of thescoring content becomes inevitable and the definedcorrect response will have to be changed in thesystem.
Localising scoring rules of numeric entry itemsrequires not only the definition of the correctnumber(s) but also decisions about acceptablespelling formats for numbers (e.g. with respect to thekind of decimal separator). Although there areinternational standards for number formats definingthe spelling of numbers country by country, it may betoo strict to accept only responses as correct if theyadhere to these standards. Given considerablevariability in the usage of number formats withincountries (and even within test participants), a morelenient scoring approach that accepts alternativenumber formats was judged to be more appropriatefor PIAAC.
In PIAAC, complexities also arose from theadaptation and localisation of the highlight responsemode. For the highlight response mode, therespondent has to mark the correct answer in thestimulus text to indicate his or her answer. Here is anexample to illustrate this and to explain how thescoring mechanism is designed in PIAAC:
52
9Adaptive testing means that the number pattern of correct and incorrect responses of a respondent has an impact on the difficulty of the next testitems that are presented. The idea is that a test taker that repeatedly shows low level skills is more likely to receive easy items, while a respondentthat shows high level skills is more likely to receive difficult items. So in Computerized Adaptive Testing the item difficulty is tailored to theindividual's performance level. Too hard and too easy items which would not contribute to a reliable measure are avoided. In an adaptive test, theupcoming item or set of iems is selected adaptively based on the performance shown in previous items. In some instances, e.g. for selecting thefirst item (set), additional contextual information (e.g. educational level) may be used as well (Wainer 2000).
Figure 2: Preview of a sample highlight item

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
Figure 3: The interface of the CBA Itembuilder. The correct textblock T1 is highlighted.
The respondent is given a text and he is asked tohighlight information in the text to give his answer.The question refers to the stimulus text and asks: "What is the latest time that children should arrive atpreschool?" (cf. Figure 2).
Figure 4: The interface of the CBA Itembuilder. The miss area textblock T2 is highlighted
The respondent gives the correct answer byhighlighting the number "9". To "teach" the computersystem which answer is correct and which isincorrect, the item developer has to indicate in thestimulus itself what the correct and what the incorrectanswer is. This is done by defining text blocks and byspecifying scoring rules referring to these text blocks.
The number "9" becomes a part of the "minimumcorrect response" text block.
In our example, the item developer makes thenumber a part of T1.
The remainder of the text becomes text block T2 (asshown in figure 4). Note that the sentence in whichthe correct answer is included is left out of any of thetext blocks.
The following scoring rules are defined in theauthoring tool:
Hit = complete (T1)Miss = partial (T2)
This means that the answer given by the respondentis considered to be correct when
1. The whole of T1 has been selected.2. No part of T2 has been selected.
Text that is not included in any of the text blocksCAN be selected. It is a part of the so-calledmaximum correct response (which is "Please haveyour child here by 9:00 am.").
After the translation of the text content, it isimportant that the text blocks are redefined as well,because they are language-dependent and thusunlikely to match the source version in terms of sizeand location. In PIAAC, this followed reconciliationand subsequent check by the verifiers. For theadaptation of the text blocks the "TranslationTextblock Editor" was used, a standalone toolderived from the CBA ItemBuilder mentioned above.
Countries could not define new text blocks or deletetext blocks, but they were able to adapt the content ofthe text blocks according to their needs. This processrequired several informed decisions about how tolocalise the scoring rule in a comparable way asillustrated with a simple example.
Question: What does the text say about how muchcomputer scientists earn?
Stimulus text:"Computer scientists under 30 typically makemore than the average salary for their agefrom day one."
In the source version of the item, the minimumcorrect response text block consists of "more", "than"and "average". Once the text is translated intoGerman, "average salary" becomes"Durchschnittsgehalt". Should test participantsreceive a correct response when they only highlight"Durchschnitts" (which represents "average" in this
53

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
compound noun)? Scoring experts within thecountries had to find answers to many scoring-specific questions, e.g. how to deal with compoundwords; how to deal with endings (e.g. shouldinflections be included in the minimum correctresponse?); is the correct response still comparable tothe source version when the target version includessignificantly more words in its minimum correctresponse?
After the field test, the text blocks could be re-adapted if the field test results showed that items inone country behaved differently from items in othercountries. The localisation of scoring was a difficulttask for the countries.
3. Lessons learned and open questions
This paper, so far, has given a brief introduction toLSA projects and discussed the role of localisation inthe area of LSA studies. As previously described,localising tests for international LSA studies posesspecific challenges that are not necessarilyencountered in other localisation processes. One ofthe main differences concerns the struggle betweenauthenticity and comparability when localising, andthe adaptation of scoring information. By describinga real scenario, we examined how these aspects aredealt with in practice. PIAAC is special in its ownright because it is the first international LSA studythat is completely computer-based (with a paper-based option for inexperienced computer users). Themulti-step procedure that was implemented tomanage these difficulties poses some open challengesfor future studies. Many of these challenges resultfrom the shift to a computer-based test mode and canbe classified into two categories: firstly, newdifficulties concerning the localised content and,secondly, and more importantly, difficultiesregarding the internationalisation and localisationprocess when trying to master both complexity andquality assurance. These challenges will be describedin the following paragraphs.
With regard to the test content, special linguisticdifficulties arise within the new field of test itemsthat simulate technology-rich environments (webpages, software tools,…). The question ofauthenticity arises when web content is translatedinto languages with a low population of speakers,like Estonian: a stimulus mimicking a web pagemight be considered as inauthentic if completelytranslated into languages for which only limitedcontent is available on the web. Also, people in some
countries typically do not use their national languageas an application interface language (for examplebecause the localised interface was only introducedvery late and people were already used to workingwith an English interface). Hence, the question aroseas to whether the interface language should betranslated or not. Similar concerns can arise forlanguages with different fonts (for which it isdifficult to translate URLs in a web browser). Nottranslating this content might make the item moredifficult for respondents who are less familiar withusing a computer (or do not speak English).Translation, however, might make the iteminauthentic, which might have an impact on thedifficulty of the item as the technical terminologymight be less familiar to the test taker. Similarproblems can arise when tests are translated intominority languages (like Valencian or Basque). Eventhough inauthenticity might be less of a problem forspeakers of these languages (as many of them arefamiliar with using their language in new contexts),there might also be an impact on the difficulty of thetasks. These issues and their influence on an item'svalidity of measurement will have to be discussedfurther in the future.
The shift from a paper-based to a computer-based testmode has a significant impact on the adaptationprocesses. One big difference compared to theadaptation process for paper-based tests is theseparation of adaptable content from static, non-adaptable content. On the one hand, this makes theprocess more complicated and requires many case-by-case decisions. On the other hand, it automaticallybrings many issues to light that would not necessarilybe (knowingly) identified during a localisationprocess for paper-based tests (Should the inlineformatting be exactly the same across languages?Can the font size be changed? What degree offreedom is allowed for changing layout?). Inaddition, the computer-based mode of test itemstechnically facilitates the direct comparisons oflocalised test items. Hence, the shift presents achallenge as well as an opportunity for makinglocalisation issues more visible than before.
This also leads to the problem of finding the rightbalance between flexibility and control. In PIAAC, aconscious decision was made not to allow thecountries or the software to make any changes to thelayout. As previously mentioned, this was helpfulbecause the consortium (and the item developers)maintained control over the location of the text. Onthe other hand, it is questionable whether it would not
54

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
have been preferable to allow for more decentralisedlayout adaptations. If the size of a text boxautomatically adapted to the length of the translatedtext, many of the manual adaptations of the items(bearing the risk of introducing new errors) couldhave been avoided. Especially for languages likeKorean and Japanese, it would also be helpful ifcountries were granted more flexibility to adapt someselected elements of the layout manually. Line space,for example, had to be doubled for Korean becausethe Korean characters become illegible with thedefault line space set in the source items. ForJapanese, line breaks were also an issue: there are noblanks between characters and text is usuallyjustified. When designing the translation process andthe software tools for the translation process, theserequirements should play a role from the verybeginning and be a part of the items'internationalisation process. Certain countries wouldthus gain access only to selected layout elements thatcould not be dealt with during internationalisation.
The adaptation process for computer-based tests alsorequires the ability to integrate two additional stepsinto the localisation process, i.e. layout and scoringadaptations. Defining the sequence of the adaptationsteps becomes a challenging task in such a complexprocess. For example, allowing any linguisticchanges to be made after the completion of scoringand layout adaptations means that these adaptationshave to be re-checked. An ideal approach would be tofirst complete all linguistic changes, and secondlyresolve all layout issues. The scoring should beadapted at the very end. Since the localisation ofautomatic scoring rules is a new area in LSA, and theconsequences of scoring adaptations are not visible inthe item itself, countries need to test scoring carefullyfollowing a test plan.
It also became clear that it is important that all peopleinvolved in the adaptation process are able to interactwith the item in the same way as the test participant.This also became apparent for the scoringmechanism, for the adaptation of which it was crucialto be able to test all changes by trying to give correctand incorrect responses. Countries received detailedtest cases from the consortium giving the correct orincorrect responses for the source version, whichcould then be adapted by the country and checked onthe Item Management Portal by giving the requiredresponse. The portal then gave feedback on whetherthe response was correct or incorrect. This allowedfor immediate feedback on whether the adaptations(of e.g. text blocks) resulted in the desirable scoring
behaviour. This procedure - testing while adapting -made the scoring adaptation process efficient forcountries because they received immediate feedbackfor any scoring adaptation decision.
Another challenge regarding the efficiency of thelocalisation process refers to the question of whoshould make adaptations, i.e. whether certainadaptation steps should be centralised and done byexperts in the consortium, or de-centralised andbecome the responsibility of the national teams. Forinstance, at the beginning of the project, theconsortium tried to give countries the freedom ofadapting their numeric scoring. This decision wasmade because the people in the national teams wouldbe able to decide if items that include currenciesshould be adapted or not (cf. previous section).However, it soon became clear that it was notefficient to teach this complicated adaptationprocedure to all countries: input was needed fromnumeracy experts to decide whether changing acurrency number would change the item'spsychometric properties, such as difficulty, as well asfrom technical experts to implement the changedscoring rule. In PIAAC, this process was thenmodified and centrally organised: the consortium andthe numeracy expert group made recommendationsand gave feedback regarding certain problematicitems, the country groups made sure that the itemswere authentic for their country, and the consortiummade the technical implementation. A conclusionfrom the PIAAC case study is that it is more efficientto implement technically difficult adaptationscentrally, after countries have provided input asregards authenticity.
One step to allow for more de-centralisation andtransparency regarding content decisions would be togive countries more, and broader, information as abasis for making decisions and finding solutionsduring the localisation process. For instance, as afuture enhancement of the PIAAC approach, onemight try to make information regarding localisationissues available and useable across countries, so thateach country team can gain a new cross-countryperspective and is able to compare differentlocalisation problems and solutions. The bundling ofinformation could result in a more consistentapproach and increased quality. Many localisationproblems do not only exist for one language butacross languages. In these cases it would be veryhelpful for a country's translation and localisationteam if they had an overview of all the localisationproblems that emerged for an item in other countries.
55

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
Furthermore, they could check whether they mighthave a similar problem that they are not yet aware of.In addition, once a problem is identified, they coulddirectly check solutions other countries had found fora similar problem and use these solutions as aguideline for their own decision. A technical solutionfor such a centrally available cross-countryinformation and documentation pool would beneeded for the localisation process.
Source version management is a difficult issue in anadaptation process that includes many differentpartners in many different countries. Even though thesource items, after "internationalisation', aresupposed to be final prior to starting the localisationprocess, several issues are only found once countrieshave started on their translations, and more are foundthrough the verification procedure. One problemregarding the file-based solution in PIAAC was thatevery time a new version became available, countrieshad to download this version and check that this wasthe latest version. A lot of these issues can probablybe avoided by advance translation: This is done inPISA, for example, where two source versions arecreated: a French source version is developed inparallel with the English source version. At leastsome of the issues that concern the translatability ofitems can thus be identified in advance. There arefewer errors when the source versions are releasedfor translation by the countries (Grisay 2003). Still, itis likely that not all problems can be found, even byusing advance translation. Source versionmanagement itself could be technically supported byusing a content management system, which wouldprevent subsequent errors caused bymiscommunication between partners or overlookingchanged material.
The question of source version management leads tothe question of translation version management. Themulti-step localisation procedure also made itdifficult for countries to translate because they had toconsult and edit a lot of material for translation. Thisshould be reduced so that cycling between manydocuments is not necessary anymore; a technicalsolution should be found. A first step in this directionhas been made with the framework of PISA 2012computer-based testing, whereby item-specifictranslation/adaptation guidelines and comments bythe different players (translators, reconciler, verifier,country post-verification reviewer) are carried withinthe XLIFF file rather than being presented in aseparate monitoring form.
4. Conclusion
As described in this article, many problems have tobe tackled in LSA studies that are not usually presentin localisation processes where comparability doesnot play a role. In particular, localisation in LSAstudies deals with balancing between authenticity ineach country and comparability across countries.To handle this challenge, a multi-stage translationand verification approach is pursued, including:
l Preparing internationalised test material l Localising content (text, images)l Localising layoutl Localising meta-data, e.g. scoring rules.
Still, several aspects can be transferred to otherlocalisation processes as well. For instance, the issueof version management is of general importance, aswell as the question of when to test a localisedversion. Other domains for which the quality oftranslations is highly critical might also benefit fromthe multi-stage translation and verification processthat is used for LSA studies. Similarly, the questionas to which adaptations should be done, and bywhom, is also relevant in all localisation processes.
On the other hand, LSA studies can take moreadvantage of the advances made by the localisationindustry. As LSA studies are shifting from paper-based assessment to computer-based assessment, thetime seems right to move towards commonly usedstandards and tools. In PIAAC, the first steps in thisdirection have been taken by introducing the XLIFFstandard as a basis for the translation and byrequiring countries to use a translation memory (TM)aware translation tool such as the OLT. Nevertheless,not all of the new possibilities have been tried yet.Another promising approach is to put more emphasison source content quality assurance.
References
Freedle, R. (1997) The relevance of multiple-choice readingtest data in studying expository passage comprehension:The saga of a 15 year effort towards anexperimental/correlational merger, Discourse Processes,23(3), 399-440.
Grisay, A. (2003) Translation procedures in OECD / PISA2000 international assessment, Language Testing, 20(2),225-240.
Hambleton, R. (2002) 'Adapting Achievement Tests into
56

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
Multiple Languages for International Assessments', inPorter, A. and Gamoran, A (eds)., Methodological advancesin crossnational surveys of educational achievement,Washington, DC: National Academy Press, 58-79.
Hambleton, R., de Jong, J. (2003) Advances in translatingand adapting educational and psychological tests, LanguageTesting, 20(2), 127-134.
Hambleton, R., Merenda, P. and Spielberger, C., eds. (2005)Adapting Educational and Psychological Tests for Cross-Cultural Assessment, Mahwah, NJ: Erlbaum.
Kirsch, I. (2001) The International Adult Literacy Survey(IALS): Understanding what was measured, ETS ResearchReport RR-01-25, Princeton, NJ: Educational TestingService.
LISA (2003). Localisation Industry Primer, 2nd ed., Fechy,Switzerland: The Localisation Industry StandardsAssociation (LISA).
McQueen, J., Mendelovits, J. (2003) PISA reading: culturalequivalence in a cross-cultural study, Language Testing,20(2), 208-224.
Mullis, I., Martin, M., Ruddock, G., O'Sullivan, C.,Preuschoff, C. (2009) TIMSS 2011 AssessmentFrameworks, Amsterdam: International Association for theEvaluation of Educational Achievement (IEA).
OECD (2010) PISA: Programme for International StudentAssessment, OECD Education Statistics (database).
OECD (2011) PISA 2009 Results: Students on Line: DigitalTechnologies and Performance, Volume VI, PISA, OECDPublishing.
Savourel, Y., Reid, J., Jewtushenko, T.; Raya, R.M. (2008)XLIFF Version 1.2 [online], available: http://docs.oasis-open.org/xliff/v1.2/os/xliff-core.html [accessed: 24 June2011].
Schäler, R. (2007) Reverse Localisation, LocalisationFocus, 6(1), 39-48 .
57

Localisation Focus Vol.10 Issue 1The International Journal of Localisation
Guidelines for AuthorsLocalisation Focus
The International Journal of LocalisationDeadline for submissions for VOL 11 Issue 1 is 30 June 2012
Localisation Focus -The International Journal of Localisation provides a forum for localisation professionals andresearchers to discuss and present their localisation-related work, covering all aspects of this multi-disciplinaryfield, including software engineering and HCI, tools and technology development, cultural aspects, translationstudies, human language technologies (including machine and machine assisted translation), project management,workflow and process automation, education and training, and details of new developments in the localisationindustry.
Proposed contributions are peer-reviewed therebyensuring a high standard of published material.
If you wish to submit an article to LocalisationFocus-The international Journal of Localisation,please adhere to these guidelines:
l Citations and references should conform to the University of Limerick guide to the Harvard Referencing Style
l Articles should have a meaningful titlel Articles should have an abstract. The abstract should be a minimum of 120 words and be autonomous and self-explanatory, not requiring reference to the paper itself
l Articles should include keywords listed after the abstract
l Articles should be written in U.K. English. If English is not your native language, it is advisableto have your text checked by a native English speaker before submitting it
l Articles should be submitted in .doc or .rtf format,.pdf format is not acceptable
l Article text requires minimal formatting as all content will be formatted later using DTP software
l Headings should be clearly indicated and numbered as follows: 1. Heading 1 text, 2. Heading 2 text etc.
l Subheadings should be numbered using the decimal system (no more than three levels) as follows:
Heading1.1 Subheading (first level)1.1.1 Subheading (second level)1.1.1.1 Subheading (third level)
l Images/graphics should be submitted in separate files (at least 300dpi) and not embedded in the textdocument
l All images/graphics (including tables) should be annotated with a fully descriptive caption
l Captions should be numbered in the sequence theyare intended to appear in the article e.g. Figure 1, Figure 2, etc. or Table 1, Table 2, etc.
More detailed guidelines are available on request byemailing [email protected] or visiting www.localisation.ie

















