36
Localized Asynchronous Packet Scheduling for Buffered Crossbar Switches Deng Pan and Yuanyuan Yang State University of New York Stony Brook
| Date post: | 24-Dec-2015 |
| Category: |
Documents |
| Upload: | owen-simpson |
| View: | 223 times |
| Download: | 3 times |

Localized Asynchronous Packet Scheduling for
Buffered Crossbar Switches
Deng Pan and Yuanyuan Yang
State University of New York Stony Brook

Outline
Introduction Related work Localized asynchronous packet scheduling Simulation results Conclusions

Introduction
Crossbar switches have long been the preferred structures for high speed switches and routers: Provide non-blocking capability. Overcome the bandwidth limitation of bus-based
switches. Packet forwarding is simple.
Introduction
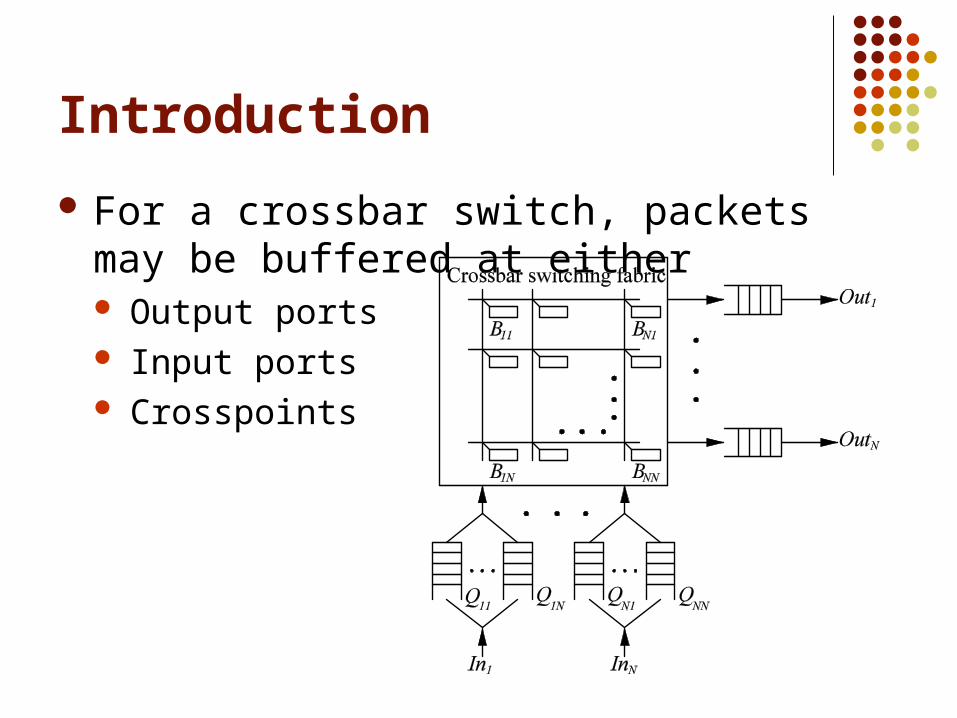
For a crossbar switch, packets may be buffered at either Output ports Input ports Crosspoints

Introduction
Output queued (OQ) switches only have buffer space at the output side. Achieve 100% throughput. Require speedup of N for an NxN switch.
Input queued (IQ) switches only have buffer space at the input side. Require no speedup. Have to work with high time complexity algorithms
in order to achieve 100% throughput.

Introduction
Combined input-output queued (CIOQ) switches make a trade-off between the crossbar speedup and the complexity of the scheduling algorithms. Have small fixed speedup of two. Achieve 100% throughput with any iterative
maximal matching algorithms. Emulate OQ switches.

Introduction
Buffered crossbar switches are a special type of CIOQ switches. Each crosspoint of the crossbar has a small
buffer. Crosspoint buffers eliminate the input and output
contention. Buffered crossbar switches can directly schedule
and switch variable length packets.

Introduction
Previous scheduling algorithms for crossbar switches mainly focused on fixed length packet scheduling or cell scheduling. At input ports, new packets are segmented into
fixed length cells. The cells are used as the scheduling units and
transmitted across the switching fabric. At output ports, the cells are reassembled into
original packets.

Introduction
Variable length packet scheduling, or packet scheduling, improves the switch efficiency by avoiding the segmentation-and-reassemble (SAR) process. Higher throughput. Shorter packet latency. Lower hardware cost.

Introduction
[Turner Infocom’06] proposed two packet scheduling algorithms for buffered crossbar switches. They can provide work-conserving guarantees, or
emulate scheduling algorithms for OQ switches. They schedule packets by imposing an order on
buffered packets. Each crosspoint needs 2L or more buffer space,
where L is the maximum packet length.

Introduction
We consider the other side of the problem, low time complexity and easy to implement packet scheduling algorithms.
We present the Localized Asynchronous Packet Scheduling (LAPS) algorithm and analyze its performance. Local info based No comparison Crosspoint buffer size of L

Outline
Introduction Related work Localized asynchronous packet scheduling Simulation results Conclusions

Related work
Scheduling algorithms in the literature for buffered crossbar switches are generally designed with two possible objectives: To achieve high throughput. To emulate scheduling algorithms for OQ switches.
The latter is a stronger requirement, but the implementation of the former can be simpler.

Related work
Cell scheduling algorithms for high throughput CIXB-1, CIXOB-k, MCBF, SCBF…
Cell scheduling algorithms to emulate scheduling algorithms for OQ switches GBVOQ_OCF, GBFG_SP, MCAF-LTF…
Packet scheduling schemes Packet VOQ, Packet LOOFA, DPFQ…

Outline
Introduction Related work Localized asynchronous packet scheduling Simulation results Conclusions

Localized asynchronous packet scheduling
Structure of a buffered crossbar switch Ini: input port
Outj: output port
Bij: crosspoint buffer
Qij: virtual queue
The crossbar has
speedup of two.

Localized asynchronous packet scheduling
Based on the locations of the packets to be scheduled, there are three types of scheduling involved in a buffered crossbar switch. Input scheduling Crossbar scheduling Output scheduling

Localized asynchronous packet scheduling
Output scheduling has been well studied, and various scheduling algorithms are proposed.
Output scheduling usually does not affect the throughput performance as long as they are work-conserving.
We use a simple FIFO algorithm for output scheduling, which is work-conserving.

Localized asynchronous packet scheduling
For input scheduling, Select a backlogged virtual queue whose crosspoint
buffer is empty, and send its head packet to the crosspoint buffer.
When there are multiple eligible virtual queues, different arbitration rules can be used.
Since the crossbar has speedup of two, the packet is sent to the crosspoint buffer with bandwidth 2R.
Crossbar scheduling is similar.

Localized asynchronous packet scheduling
In order to reduce the packet latency, cut-through switching can be used on the crossbar.
Similarly, cut-through switching can be used at output ports.

Localized asynchronous packet scheduling

Localized asynchronous packet scheduling
In input scheduling, the scheduling candidates of an input port are only the virtual queues whose crosspoint buffers are empty.
This restriction simplify the implementation by enabling one bit to represent the status of the crosspoint buffer.

Localized asynchronous packet scheduling
With speedup of two, LAPS achieves 100% throughput for any admissible traffic.
Define Zij(t)=Qij(t)+Bij(t)
If Bij is not empty at time t, ∑kZkj(t) has a negative derivative.
If Qij is not empty at time t, ∑kQik(t) +∑kZkj(t) has a negative or zero derivative.

Localized asynchronous packet scheduling
Assume that the traffic arrives according to a Poisson process and the packet length follows an exponential distribution with mean M.
Ini can be approximately modeled as an M/M/1 system, and accordingly

Localized asynchronous packet scheduling
Hardware implementation Only local info is necessary, and it is suitable for
distributed implementation and highly scalable. Since no comparison is necessary, the arbiters
can implemented by priority encoders, which can make fast decisions in hardware.
Since each crosspoint buffer needs only L buffer space, it minimize the cost for the switch.

Outline
Introduction Related work Localized asynchronous packet scheduling Simulation results Conclusions

Simulation results
We have conducted simulations to verify the 100% throughput of LAPS and to measure its delay and buffer requirement.
We consider five different LAPS implementations: Fixed priority (FP) Random (RD) Round-robin (RR) Oldest packet first (OPF) Longest queue first (LQF)

Simulation results
In order to reflect the burst nature of real network traffic, we emulate the incoming traffic by a Markov modulated Poisson process.

Simulation results
We considered both uniform traffic and non-uniform traffic.
The packet length in the simulation is uniformly distributed between [50, 1500] bytes.
We consider a 16×16 switch, and each input port or output port has bandwidth of 1G bps.

Simulation results
Throughput
Simulation results
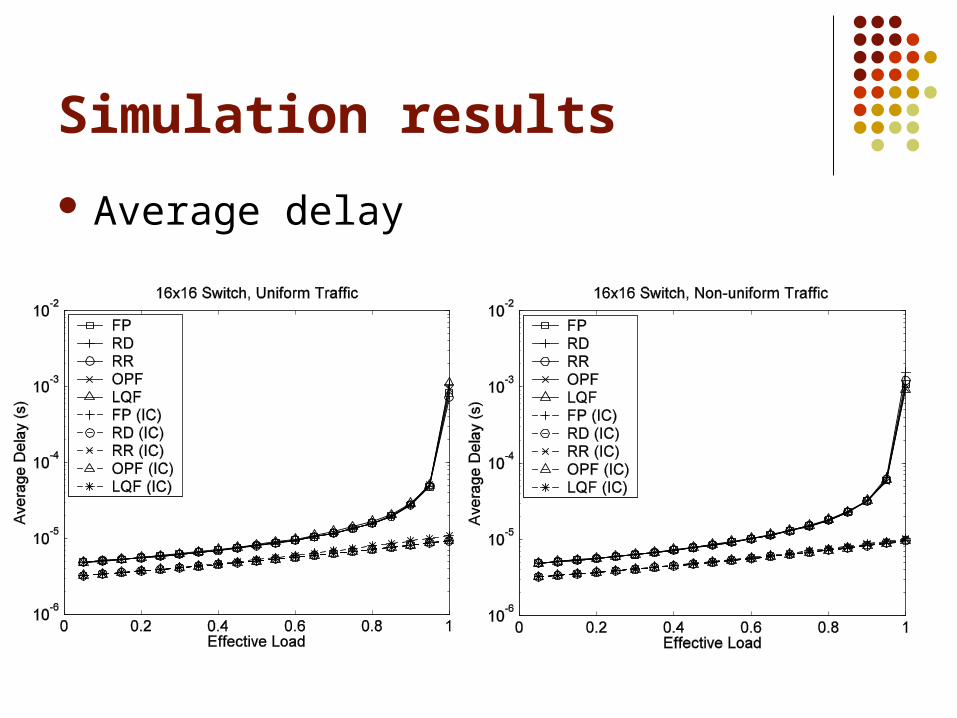
Average delay

Simulation results
Maximum queue length

Outline
Introduction Related work Localized asynchronous packet scheduling Simulation results Conclusions

Conclusions
Due to the introduction of crosspoint buffers, buffered crossbar switches can directly schedule and transmit variable length packets.
Packet scheduling algorithms avoid SAR and are more efficient than cell scheduling algorithms. Higher throughput Shorter latency Lower hardware cost

Conclusions
We presented the Localized Asynchronous Packet Scheduling (LAPS) scheme. Local info based No comparison Crosspoint buffer of size L
We theoretically proved that LAPS achieves 100% throughput with speedup of two, and conducted simulations to verify the results.

Thank you!
Questions?












![Transient Behavior of a Buffered Crossbar Converging to Weighted Max … · 2014-02-20 · (WRR) scheduling –often in the form of weighted fair queueing (WFQ) [4]– which takes](https://static.documents.pub/doc/80x56/5ea02e1dd1b37f056f1d6d50/transient-behavior-of-a-buffered-crossbar-converging-to-weighted-max-2014-02-20.jpg)




