UCSD ECE154C Handout #21 Prof. Young-Han Kim Thursday, June 8, 2017 Solutions to Practice Final Examination (Spring 2016) There are 4 problems, each problem with multiple parts, each part worth 10 points. Your answer should be as clear and readable as possible. Please justify any claim that you make. 1. Lossless source coding (30 points). Consider a source S that produces independent and identically distributed symbols from the alphabet {A,B,C } with p A =0.5, p B =0.3, and p C =0.2. (a) Find a binary Tunstall code that encodes the source sequence into 3 binary code symbols at a time. (b) What is the rate of this code, i.e., the average number of encoded source symbols per code symbol? (c) Suppose now that the Tunstall code is followed by a binary Huffman code, forming a variable-to-variable-length code. What is the rate of this code, i.e., the ratio of the average number of source symbols to the average number of code symbols? Solution : (a) We need 2 3 = 8 source sequences for the Tunstall coding. However, since we have three symbols, each branching in the Tunstall coding procedure yields 2 new source sequences, keeping the total number odd. Hence, we can only use 7 source strings for the encoding. The Tunstall coding procedure is shown below. A 0.5 B 0.3 C 0.2 0.25 0.15 0.10 0.15 0.09 0.06 AA AB AC BA BB BC One possible encoding is as follows: AA → 000 AB → 001 AC → 010 BA → 011 BB → 100 BC → 101 C → 110. 1
Transcript
UCSD ECE154C Handout #21Prof. Young-Han Kim Thursday, June 8, 2017
Solutions to Practice Final Examination (Spring 2016)
There are 4 problems, each problem with multiple parts, each part worth 10 points. Youranswer should be as clear and readable as possible. Please justify any claim that you make.
1. Lossless source coding (30 points). Consider a source S that produces independent andidentically distributed symbols from the alphabet {A,B,C} with pA = 0.5, pB = 0.3,and pC = 0.2.
(a) Find a binary Tunstall code that encodes the source sequence into 3 binary codesymbols at a time.
(b) What is the rate of this code, i.e., the average number of encoded source symbolsper code symbol?
(c) Suppose now that the Tunstall code is followed by a binary Huffman code, forminga variable-to-variable-length code. What is the rate of this code, i.e., the ratio ofthe average number of source symbols to the average number of code symbols?
Solution :
(a) We need 23 = 8 source sequences for the Tunstall coding. However, since wehave three symbols, each branching in the Tunstall coding procedure yields 2 newsource sequences, keeping the total number odd. Hence, we can only use 7 sourcestrings for the encoding. The Tunstall coding procedure is shown below.
A
0.5
B
0.3
C
0.2
0.25 0.15 0.10 0.150.09
0.06
AA AB AC BA BB BC
One possible encoding is as follows:
AA→ 000
AB → 001
AC → 010
BA→ 011
BB → 100
BC → 101
C → 110.
1
(b) The average number of encoded source symbols is given by
Alternatively, the average number of code symbols can be computed by addingthe probabilities at the internal nodes, so we have
L̄c = 1.0 + 0.55 + 0.45 + 0.30 + 0.25 + 0.15
= 2.7.
Thus the rate of this code is given by L̄s/L̄c = 0.667.
2. A binary code (40 points). Consider a binary code with the following four codewords:0000000, 0111000, 1000110, and 1111111.
(a) What is the rate of this code? Justify your answer.
(b) Is this code linear? Justify your answer.
(c) How many errors is this code guaranteed to correct?
(d) Suppose that this code is used over a binary symmetric channel with crossoverprobability p ∈ [0, 1/2]. What is the conditional probability of an undetectederror, given that the codeword 0111000 was sent?
Solution :
(a) The block length n is 7, and there are four codewords, so 2k = 4, giving k = 2.Thus, the rate of the code is k
n= 2
7.
(b) The sum of the second and third codewords is 1111110, which is not a codeword.Thus the code is not linear.
(c) By looking at all possible Hamming distances between distinct codewords, we seethat the minimum distance of this code is dmin = 3. Thus, this code is guaranteedto correct one bit error.(Note : This code is not linear; therefore, in order to find dmin, it is not enough tomerely look at the distances of one particular codeword from other codewords, orat the Hamming weights of all codewords. We actually have to check all
(42
)= 6
distances.)
(d) An undetected error will occur if the received vector is the same as one of theother three codewords. This can happen in the following ways.
i. The second, third and fourth bits are flipped. In this case, we get the all-zerocodeword as output.
ii. The first, fifth, sixth and seventh bits are flipped. In this case, we get theall-one codeword as output.
3
iii. The first six bits are flipped. In this case, we get the third codeword asoutput.
By adding the probablities for these individual cases, we see that the conditionalprobability of an undetected error, given 0111000 was sent, is
Pe = p3(1− p)4 + p4(1− p)3 + p6(1− p).
3. Linear parity check codes (50 points). Consider a binary linear code defined by thegenerator matrix
G =
1 0 1 1 1 0 01 1 1 1 0 0 10 1 1 0 0 1 1
.
(a) Find the parity check matrix of the form H =[A I
].
(b) What is the minimum distance of this code? Justify your answer.
(c) Find all the patterns of 4 erasures that this code can fill in correctly.
Suppose now that a new code is formed by puncturing the last bit of all codewords.
(d) Find the parity check matrix for the new code of the form H =[B I
].
(e) What is the minimum distance of the new code?
Solution :
(a) Replacing the first row of G by the (modulo 2) sum of the second and third rows,the second row by the sum of the first and second rows, and the third row by thesum of all three rows, we get a new generator matrix
G =
1 0 0 1 0 1 00 1 0 0 1 0 10 0 1 0 1 1 0
.
Note : This transformation is equivalent to pre-multiplying G by the full-rank
(b) Notice that H does not have two identical columns; thus, dmin ≥ 3. Also, thefirst, fourth and sixth columns of H sum to zero, and are thus linearly dependent.So, dmin = 3 for this code.
(c) Recall that an erasure pattern can be filled in uniquely, if and only if the corre-sponding columns of H are linearly independent. Based on this, the following 21patterns of 4 erasures can be uniquely filled in by this code:(1, 2, 3, 4), (1, 2, 3, 5), (1, 2, 3, 6), (1, 2, 3, 7), (1, 2, 4, 5), (1, 2, 4, 7), (1, 2, 5, 6), (1, 2, 6, 7),(1, 3, 4, 7), (1, 3, 5, 7), (1, 3, 6, 7), (1, 4, 5, 7), (1, 5, 6, 7), (2, 3, 4, 5), (2, 3, 4, 6), (2, 3, 4, 7),(2, 4, 5, 6), (2, 4, 6, 7), (3, 4, 5, 7), (3, 4, 6, 7), (4, 5, 6, 7).Alternatively, recall that an erasure pattern cannot be filled in uniquely, if andonly if the location of the erasures is a superset of the location of 1’s in somenonzero codeword. Using the generator matrix G, the codewords can be enumer-ated as follows:
0000000
0010110
0100101
0110011
1001010
1011100
1101111
1111001.
Based on the codewords, we see that the following patterns of four erasures cannotbe filled in:(1, 3, 5, 6), (2, 3, 5, 6), (3, 4, 5, 6), (3, 5, 6, 7), (1, 2, 5, 7), (2, 3, 5, 7), (2, 4, 5, 7), (2, 5, 6, 7),(1, 2, 4, 6), (1, 3, 4, 6), (1, 4, 5, 6), (1, 4, 6, 7), (1, 3, 4, 5), (2, 3, 6, 7).
(d) Observe that the last bit of the codewords occur only in the last parity relation.So, if we remove the last row and last column of H, we will get a parity checkmatrix for the punctured code. Thus, a parity check matrix for the puncturedcode is given by
Hp =
1 0 0 1 0 00 1 1 0 1 01 0 1 0 0 1
.
This parity check matrix is of the required form Hp =[B I
].
(e) Observe that the second and fifth columns of Hp are identical, i.e., linearly de-pendent. This shows that the punctured code has dmin = 2.
4. Convolutional codes (130 points). Consider a binary convolutional code with the fol-
5
lowing encoder structure and initial state 00:
// ⊕ // y
x . // z−1 //
��
z−1
��
OO
// ⊕ // ⊕ // z
(a) What is the rate of this code? Justify your answer.
(b) Draw a trellis diagram for this code corresponding to the first 5 input symbols.
(c) Find the free Hamming distance dfree of this code.
We now increase the rate of the code by puncturing under the pattern(11,X1, 11,X1, 11,X1, . . .). For example, a codeword 11010100 . . . in the original codebecomes 111010 . . . in the punctured code. The next 7 questions are on this puncturedcode.
(d) What is the rate of this code? Justify your answer.
(e) Draw a trellis diagram for this code corresponding to the first 5 input symbols.
(f) Find the free Hamming distance dfree of this code.
(g) Find the codeword corresponding to the input sequence 01010. How about 11011?
(h) Let y(1)y(2)y(3) · · · be the codeword corresponding to the input x(1)x(2)x(3) · · · .Find y(3) and y(6) in terms of x(1), x(2), . . . . More generally, what is y(3k), k =1, 2, . . . , in terms of the input symbols?
(i) Suppose that the sequence 010111 is received when this code is used for a binarysymmetric channel. Find the codeword nearest to this sequence in Hammingdistance. What is the corresponding input sequence?
(j) Suppose that the sequence 1?10??110000 is received when this code is used for abinary erasure channel. Find the codeword by filling in the erasures. Repeat thisproblem for the received sequence 00?1?01?1000.
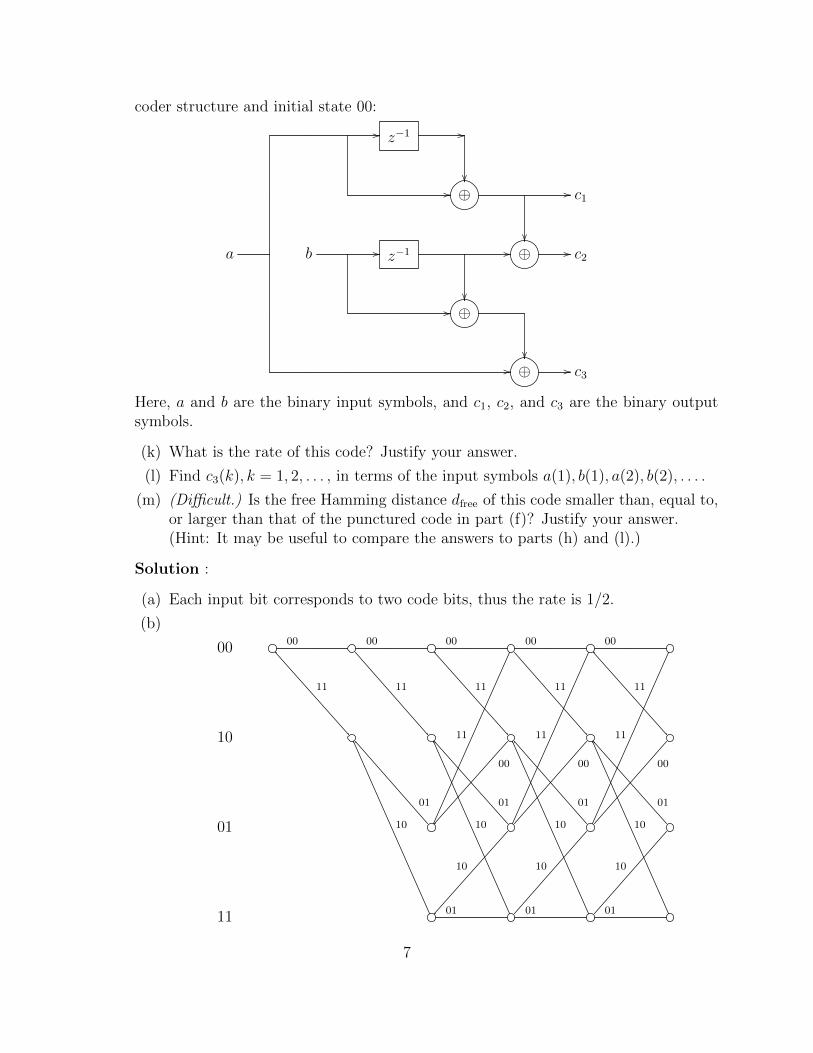
Now, consider the binary 4-state convolutional code represented by the following en-
6
coder structure and initial state 00:
// z−1 //
��// ⊕
��
// c1
a b // z−1 //
��
⊕ // c2
// ⊕
��// ⊕ // c3
Here, a and b are the binary input symbols, and c1, c2, and c3 are the binary outputsymbols.
(k) What is the rate of this code? Justify your answer.
(l) Find c3(k), k = 1, 2, . . . , in terms of the input symbols a(1), b(1), a(2), b(2), . . . .
(m) (Difficult.) Is the free Hamming distance dfree of this code smaller than, equal to,or larger than that of the punctured code in part (f)? Justify your answer.(Hint: It may be useful to compare the answers to parts (h) and (l).)
Solution :
(a) Each input bit corresponds to two code bits, thus the rate is 1/2.
(b)
00 00
11
00
11
00
11
00
11
00
11
10
01
10
01
10
01
10
01
1001
11
00
11
00
11
00
11
10
01
10
01
10
01
7
For the branches going out of each state, the top branch corresponds to input 0,and the bottom branch corresponds to input 1.
(c) By inspecting the trellis, we can find dfree for this code, constraining the path todiverge from state 00 and end at state 00. The relevant path is shown in bold inthe following trellis diagram.
00 00
11
00
11
00
11
00
11
00
11
10
01
10
01
10
01
10
01
1001
11
00
11
00
11
00
11
10
01
10
01
10
01
We thus have dfree = 5.
(d) Every two input bits correspond to three code bits, thus the rate is 2/3.
(e)
00 00
11
0
1
00
11
0
1
00
11
10
1
0
01
10
1
0
01
1001
11
00
1
0
11
00
11
10
01
0
1
10
01
8
For the branches going out of each state, the top branch corresponds to input 0,and the bottom branch corresponds to input 1.
(f) By inspecting the trellis, we can find dfree for this code, constraining the path todiverge from state 00 and end at state 00. The relevant path is shown in red inthe following trellis diagram.
00 00
11
0
1
00
11
0
1
00
11
10
1
0
01
10
1
0
01
1001
11
00
1
0
11
00
11
10
01
0
1
10
01
We thus have dfree = 3.
(g) From the trellis diagram in part (e), we see that the codeword corresponding tothe input sequence 01010 is 00101001, and the codeword corresponding to theinput sequence 11011 is 11010010.
(h) y(3) is the same as the fourth bit of the unpunctured code, and thus we have,from the encoder structure, that y(3) = x(2)⊕ x(1) (since the initial state is 00.)Similarly, y(6) is the 8th bit of the unpunctured code, and thus, y(6) = x(4) ⊕x(3)⊕ x(2).In general, y(3k) is the same as the (4k)th bit of the unpunctured code, and isthus given by
y(3k) = x(2k)⊕ x(2k − 1)⊕ x(2k − 2).
(i) We can use Viterbi decoding to find the codeword closest in Hamming distance.
9
The relevant path is shown in red in the following trellis diagram.
00 00
11
0
1
00
11
0
1
00
11
10
1
0
01
10
1
0
01
1001
11
00
1
0
11
00
11
10
01
0
1
10
01
Therefore, the closest codeword is 000111, which is at a Hamming distance of 1from the received sequence, and the corresponding input sequence is 0010.
(j) The erasures can be filled in by analyzing the possible paths at each step in thetrellis. From inspection, the codeword corresponding to the first erasure patternis 111001110000, since none of the other 7 possible ways of filling in the erasuresproduces a valid codeword. The path corresponding to the correct codeword forthe first received sequence is shown in red in the following trellis diagram.
00 00
11
0
1
00
11
0
1
00
11
0
1
10
1
0
01
10
1
0
01
10
1
001
11
00
1
0
11
00
1
0
11
10
01
0
1
10
01
0
1
From inspection, the correct codeword corresponding to the second erasure pat-tern is 000110101000, since none of the other 7 possible ways of filling in the
10
erasures produces a valid codeword.The path corresponding to the correct codeword for the second received sequenceis shown in red in the following trellis diagram.
00 00
11
0
1
00
11
0
1
00
11
0
1
10
1
0
01
10
1
0
01
10
1
001
11
00
1
0
11
00
1
0
11
10
01
0
1
10
01
0
1
(k) Every two input bits correspond to three code bits, thus the rate is 2/3.
(l) From the encoder diagram, we have
c3(k) = a(k)⊕ b(k)⊕ b(k − 1).
(m) Similar to part (l), we have
c1(k) = a(k)⊕ a(k − 1), and
c2(k) = a(k)⊕ a(k − 1)⊕ b(k − 1).
Similar to part (h), we have
y(3k − 2) = x(2k − 1)⊕ x(2k − 3), and
y(3k − 1) = x(2k − 1)⊕ x(2k − 2)⊕ x(2k − 3).
If we map c1(k)↔ y(3k−2), c2(k)↔ y(3k−1), c3(k)↔ y(3k), a(k)↔ x(2k−1),and b(k) ↔ x(2k), we see that this code is, in fact, the same as the puncturedcode above.Thus, dfree of this code is also equal to 3.