79
LUIS HENRIQUE ALVES LOURENC ¸O PROCESSAMENTO PARALELO DE ´ AUDIO EM GPU CURITIBA 2009

LUIS HENRIQUE ALVES LOURENCO
PROCESSAMENTO PARALELO DE AUDIO EM GPU
CURITIBA
2009

LUIS HENRIQUE ALVES LOURENCO
PROCESSAMENTO PARALELO DE AUDIO EM GPU
Trabalho de Conclusao de Curso apresentadocomo requisito parcial a obtencao do grau deBacharel em Ciencia da Computacao. Pro-grama de Graduacao, Setor de Ciencias Exatas,Universidade Federal do Parana.
Orientador: Prof. Dr. Luis Carlos Erpen deBona
CURITIBA
2009

Sumario
Lista de Figuras . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . v
Resumo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . vi
1 Introducao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
2 Programacao Paralela . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1 Paralelismo em Nıvel de Instrucao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.2 Multiprocessadores e Paralelismo em Nıvel de Thread . . . . . . . . . . . . . . . . . . . . . . . 5
2.3 Paralelismo em Nıvel de Dados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.4 Compute Unified Device Architecture (CUDA) . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.4.1 Escondendo Processadores . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.4.2 Gerenciamento de Threads . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.4.3 Hierarquia de Memoria . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
3 Audio Digital . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.1 Processamento de Audio Digital . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.2 Compressao de Audio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.3 O padrao MPEG-1 Layer III . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.3.1 Banco de Filtros Polifasicos de Analise . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
ii

iii
3.3.2 Transformacao Discreta de Cosseno Modificada . . . . . . . . . . . . . . . . . . . . . 17
3.3.3 Modelagem Psicoacustica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.3.4 Quantificacao nao-Uniforme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.3.5 Codificacao de Huffman . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.3.6 Formatacao da Sequencia de Bits . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.4 LAME Ain’t an Mp3 Encoder . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
4 Processamento de Audio em GPU . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
4.1 Modelo de Servidor de Audio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4.2 Um Servidor de Audio com codificacao em GPU . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
4.2.1 Detalhes da Implementacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4.2.2 Codificacao em GPU . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4.3 Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
5 Conclusao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
Referencias Bibliograficas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
Anexo A -- CUDA Application Programming Interface . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
A.1 Extensoes da Linguagem C . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
A.1.1 Qualificadores de Funcao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
A.1.2 Qualificadores de Variaveis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
A.1.3 Parametros de Configuracao da Execucao . . . . . . . . . . . . . . . . . . . . . . . . . . 38
A.1.4 Variaveis Pre-definidas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
A.1.5 O Compilador NVCC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39

iv
A.2 Componente de Execucao Comum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
A.2.1 Tipos Pre-definidos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
A.2.2 Funcoes Matematicas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
A.2.3 Funcoes de Tempo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
A.2.4 Tipo Textura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
A.3 Componente de Execucao em GPU . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
A.3.1 Funcoes Matematicas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
A.3.2 Funcao de Sincronizacao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
A.3.3 Funcoes de Textura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
A.3.4 Funcoes Atomicas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
A.4 Componente de Execucao em CPU . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
A.4.1 API de Execucao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
A.4.2 API do Driver . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
Anexo B -- Speaker (servidor) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
Anexo C -- Listener (cliente) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
Anexo D -- lhal04.h . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
Anexo E -- psyKernel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67

v
Lista de Figuras
Figura 2.1 Exemplo de Soma Paralela de um Vetor . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
Figura 2.2 Modelo da Arquitetura NVidia (GeForce 8) [HALFHILL, 2008] . . . . . . . . . . 8
Figura 2.3 Hierarquia de Memoria em CUDA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
Figura 3.1 Processo de Codificacao MP3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
Figura 3.2 Limiar Absoluto de Audicao . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
Figura 3.3 Mascaramento de Frequencia . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
Figura 3.4 Quantificacao nao-Uniforme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
Figura 4.1 Modelo de Servidor de Audio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25

Resumo
Este trabalho se propoe a demonstrar que o processamento paralelo em Unidades de
Processamento Grafico (GPU, do ingles, Graphics Processing Unit) pode ser amplamente utili-
zado para o processamento de audio a fim de melhorar o desempenho dos algoritmos existentes
e permitir que mais dados sejam processados com menor latencia. Com isso, pode permite-se
uma melhora sensıvel na qualidade do conteudo. Esse tipo de abordagem torna-se util de-
vido as novas tecnologias multimıdia, como a TV digital de alta definicao, os conteudos online
(Streamming de audio e vıdeo) e a comunicacao atraves de meios digitais, como o VoIP ou
videoconferencia.
Palavras-chave: Processamento Paralelo, GPU, CUDA, MPEG-1 Layer III, MP3, Servidor de
Audio.
vi

1
1 Introducao
A producao e o processamento de multimıdia no formato digital estao se popularizando
cada vez mais. Isso pode ser percebido na evolucao da industria do cinema e dos jogos, no
desenvolvimento da tv digital, nos estudios de gravacao de musica, na utilizacao dos meios
digitais para comunicacao, na popularizacao dos aparelhos celulares, reprodutores de vıdeo e
de musica, entre outros [PEDDIE, 2001].
Um dos aspectos fundamentais para os sistemas multimıdia e a baixa latencia [LAGO,
2004], especialmente no caso de mıdias contınuas como o audio e o vıdeo. Esses sistemas
exigem baixa latencia para um grande volume de dados. Uma abordagem que tem se mostrado
eficiente para aplicacoes que necessitam de alta capacidade de processamento ou que processam
um grande volume de dados e o processamento paralelo [HENNESSY; PATTERSON, 1990].
A exigencia do mercado de processadores graficos resultou na evolucao das Unida-
des de Processamento Grafico (GPU1) em um dispositivo altamente paralelo, com suporte a
multithreading2, com muitos processadores de alto desempenho e com largo barramento do
memoria. O grande desafio e desenvolver aplicacoes que permitam usar a capacidade de esca-
lar em grau de paralelismo e, assim, aproveitar o aumento constante do numero de nucleos de
processamento.
Devido a sua estrutura altamente paralela as GPUs estao deixando de ser dispositivos
exclusivos para o processamento de aplicacos graficas, e comecam a ser utilizadas para reali-
zar o processamento de aplicacoes de proposito geral. A Programacao de proposito geral em
1em ingles, Graphics Processing Unit2Capacidade de executar varios processos simultaneamente

2
GPU (GPGPU3) tem como objetivo aproveitar todo o poder de processamento das GPUs que
atualmente possuem centenas de processadores independentes e diferentes tipos de memorias.
Os primeiros programas de proposito geral que aproveitavam o potencial das GPUs fo-
ram escritos atraves de APIs4 desenvolvidas exclusivamente para a computacao grafica, como e
o caso das bibliotecas graficas OpenGL5 e Direct3D6 que por muito tempo foram a unica forma
de criar programas capazes de utilizar as GPUs. Porem o modelo de programacao voltado para
aplicacoes graficas era muito confuso e nao se mostrou ideal a programacao de proposito geral.
Assim foram desenvolvidos modelos de programacao de proposito geral para permitir que o
hardware das GPUs fosse utilizado. O modelo desenvolvido pela NVidia e o Compute Uni-
fied Device Architecture (CUDA7). O objetivo desse modelo e simplificar a programacao em
GPU para que o programador possa se concentrar no paralelismo. Isso e possıvel porque a API
desenvolvida abstrai o hardware da GPU enquanto bibliotecas na linguagem C simplificam o
acesso aos recursos do dispositivo. A ATI desenvolveu um modelo semelhante ao da NVidia,
o Close to Metal (CTM) [PEERCY; SEGAL; GERSTMANN, 2006]. O CTM permite que o
desenvolvedor acesse o conjunto nativo de instrucoes diretamente e, com isso, tenha mais fle-
xibilidade no desenvolvimento e obtenha o melhor desempenho de seu hardware. Alem dessas,
outras APIs, como a RapidMind8 que implementa abstracoes das GPUs Intel e AMD, foram
criadas para possibilitar a programacao de proposito geral em GPUs.
Este trabalho apresenta o estudo do modelo programacao paralela CUDA e do padrao
MPEG-1 Layer III9 de compressao de audio para demonstrar que o paralelismo das GPUs pode
ser aplicado na criacao e na melhoria de tecnicas que permitam melhorar o desempenho de
sistemas multimıdia. O objetivo do trabalho e propor um modelo de Servidor de Audio que
permita a implementacao de um Servidor de Audio que utilize o processamento em GPU. E,
3em inges, General Purpose computing on Graphic Processing Units4API, Application Programming Inteface, e o conjunto de rotinas e padroes definidos por um software para
utilizacao de suas funcionalidades5http://www.opengl.org/6http://en.wikipedia.org/wiki/Direct3D7em ingles, Compute Unified Device Architecture8www.rapidmind.net9O padrao MPEG-1 Layer III tambem e conhecido como MP3

3
com isso, possa demonstrar que a implementacao de tecnicas de processamento de audio em
GPU, especialmente utilizando o modelo CUDA, e viavel. O capıtulo 2 introduz conceitos da
programacao paralela necessarios para em seguida entender o modelo de programacao CUDA.
O capıtulo 3 introduz os conceitos do Audio Digital relevantes a este trabalho, apresenta um
estudo do padrao MPEG-1 Layer III e faz uma breve apresentacao do codificador LAME. O
capıtulo 4 apresenta um modelo de Servidor de Audio e uma implementacao baseada no mo-
delo, que utiliza um codificador de audio implementado em partes em CUDA. Alem disso sao
analisados os resultados dos testes realizados com o codificador e com o Servidor de Audio
implementado. Por fim, o capıtulo 5 conclui o trabalho.

4
2 Programacao Paralela
A programacao paralela em geral e relacionada com o aumento de desempenho, uma
vez que permite mais de uma execucao simultaneamente. Porem esse aumento de desempenho
esta associado ao grau de paralelismo de cada programa, ou seja, a capacidade de cada programa
executar suas instrucoes ou seu codigo ao mesmo tempo.
Neste capıtulo serao abordados os tipos de paralelismo para introduzir os conceitos ne-
cessarios a programacao paralela e, em seguida, um estudo do modelo de programacao CUDA.
Uma revisao da API do modelo CUDA encontra-se no anexo A.
2.1 Paralelismo em Nıvel de Instrucao
Desde 1985, os processadores utilizam a sobreposicao da execucao de instrucoes atraves
da tecnica de pipelining para melhorar seu desempenho [HENNESSY; PATTERSON, 1990]. A
esta sobreposicao de execucoes se da o nome de Paralelismo em Nıvel de Instrucao. Com isso e
possıvel permitir que duas instrucoes seriais sejam executadas de forma paralela, uma vez que
nem toda instrucao depende de sua antecessora.
A maior limitacao do Paralelismo em Nıvel de Instrucao e a dependencia entre as
instrucoes, isso significa que muitas vezes uma instrucao deve esperar um ou mais estagios ate
que outra instrucao disponibilize o dado necessario por ela. Aumentar o paralelismo em nıvel
de instrucao significa diminuir o nıvel de dependencia entre as intrucoes.

5
2.2 Multiprocessadores e Paralelismo em Nıvel de Thread
A afirmacao de que os processadores convencionais estao chegando a seus limites
fısicos pode ser constatada pela desaceleracao da melhora de desempenho destes processadores
e pela reducao da melhora de desempenho trazida pelo paralelismo em nıvel de instrucao. Ou
seja, a melhora de desempenho dos processadores e cada vez menor e o paralelismo em nıvel
de instrucao melhora cada vez menos o desempenho desses dispositivos. Com isso, os mul-
tiprocessadores passam a desempenhar o papel principal na arquitetura de computadores para
continuar a melhorar o desempenho dos computadores.
Alem disso a tendencia por tras dos multiprocessadores e reforcada por outros fatores:
• Aumento no interesse em servidores e no desempenho dos servidores;
• Crescimento no numero de aplicacoes de processamento intenso de dados;
• Melhora no entendimento de como usar os multiprocessadores de uma forma eficiente;
Porem, existem dois problemas: a arquitetura de multiprocessadores e um campo ex-
tenso e diverso que em sua maior parte e novo e com muitas ideias [HENNESSY; PATTERSON,
1990]. E uma grande abrangencia implica necessariamente em discutir abordagens que podem
nao permanecer com o tempo.
Uma Thread, ou processo leve, e uma linha de execucao de um programa que possui
suas proprias variaveis de controle como o contador1 e outras estruturas, porem ela compartilha
o mesmo codigo e pode compartilhar a mesma regiao de dados com outras threads. O advento
dos multiprocessadores permite um paralelismo real no qual as threads executam em processa-
dores diferentes simultaneamente ao inves de alternarem sua execucao no mesmo processador.
Nao ha dependencia entre threads, portanto elas podem executar de forma livre umas das outras.
1Program Counter (PC)

6
Figura 2.1: Exemplo de Soma Paralela de um Vetor
2.3 Paralelismo em Nıvel de Dados
No Paralelismo em Nıvel de Dados os dados sao divididos em partes que sao execu-
tadas paralelamente em unidades de processamento diferentes. O exemplo mais simples do
paralelismo em nıvel de dados e o incremento paralelo dos valores de um vetor. Como exempli-
ficado na Figura 2.1, que mostra a aplicacao paralela de uma funcao que soma 4 (representada
pelos cırculos) ao valor de cada posicao de um vetor. Dessa forma, o tempo de execucao de
todas as somas equivale a execucao de uma unica soma, pois todas sao executadas ao mesmo
tempo em unidades de processamento diferentes. As GPUs foram desenvolvidas para utilizar
esse tipo de paralelismo e permitir o processamento de grandes quantidades de dados simulta-
neamente.
2.4 Compute Unified Device Architecture (CUDA)
Com a compra da ATI pela AMD, a NVidia permaneceu como a maior empresa de-
senvolvedora exclusivamente de GPUs. Com isso a concorrencia pelo mercado de GPUs se
concentrou nos tres principais desenvolvedores: A Intel, a AMD e a NVidia. Porem, a Intel
e a AMD, como produtoras de CPUs2, pretendem integrar nucleos graficos aos seus proces-
sadores em um futuro breve [HALFHILL, 2008]. Essa integracao pode fazer o mercado de
placas graficas reduzir, pois a venda desse tipo de dispositivo se restringiria a aplicacoes que2Central Processing Unit em ingles, ou Unidade Central de Processamento

7
necessitam de um desempenho grafico realmente alto. Por outro lado, ja existem placas graficas
vendidas integradas ao computador, portanto as consequencias da integracao de nucleos graficos
as CPUs nao deve ser tao graves.
Com isso a NVidia encontrou na GPGPU3 uma forma de se diferenciar no mercado
e aproveitar ainda mais a capacidade de processamento de suas GPUs. Porem os modelos de
programacao GPGPU existentes eram muito complexos. Esses modelos haviam sido criados
para o processamento grafico (OpenGL e Direct3D). E mapear um problema de proposito geral
para o domınio grafico nem sempre e uma tarefa simples. Alem disso, o resultado final de-
pende do mapeamento escolhido. Portanto, os modelos existentes se mostraram inviaveis para
a programacao GPGPU. Assim, a NVidia aproveitou a oportunidade de criar um novo modelo
de programacao GPGPU. E entao surgiu o CUDA.
CUDA, em ingles, Compute Unified Device Architecture, e a API que implementa o
novo modelo de programacao GPGPU desenvolvido pela NVidia. Seu objetivo e proporcionar
um ambiente de programacao simples, por isso CUDA implementa um mecanismo de abstracao
do hardware da GPU atraves de bibliotecas de funcoes nas linguagens C/C++. CUDA permite
que o programador mantenha o foco na programacao paralela, pois nao requer o gerenciamento
convencional de threads, esse gerenciamento e abstraıdo pela API. Alem disso, a API per-
mite que programas desenvolvidos em CUDA nao deixem de funcionar devido a atualizacao do
harware [NVIDIA, 2008]. CUDA e uma solucao para o paralelismo real em nıvel de thread
com alto numero de processadores que possui uma arquitetura amplamente difundida. Alem
disso a GPU e especialmente adequada para resolver problemas que podem ser expressados por
computacao de dados paralela (ou seja, o mesmo programa e executado em varios elementos de
dado paralelamente - paralelismo em nıvel de dados) com alta intensidade aritmetica (taxa de
operacoes aritmeticas em relacao a taxa de operacoes de memoria). Como o mesmo programa e
executado para cada elemento de dado, a necessidade de fluxos de controle sofisticados e baixa.
Portanto, o modelo de programacao CUDA se mostra adequado para utilizar de forma eficiente
3Programacao de Proposito Geral em Unidades de Processamento Grafico (GPU), em ingles, General Proposecomputing on Graphics Processing Units

8
Figura 2.2: Modelo da Arquitetura NVidia (GeForce 8) [HALFHILL, 2008]
o paralelismo das GPUs.
2.4.1 Escondendo Processadores
NVidia sempre escondeu a arquitetura de suas GPUs atraves de uma API. Como resul-
tado disso, os programas nao acessam o hardware diretamente. Ao inves disso, as funcoes que
manipulam diretamente o hardware estao implementadas na API.
A figura 2.2 mostra um modelo da arquitetura GPU que serviu como base para o mo-
delo da API de programacao em CUDA. As threads sao executadas nos processadores de thre-
ads4 e gerenciadas pela propria arquitetura de forma transparente ao usuario. Funcoes CUDA,
chamadas de kernel5, sao executadas em paralelo6 por um conjunto de processadores de thre-
ads e possuem acesso a alguns tipos de memoria, incluindo a memoria principal da GPU e uma
memoria compartilhada entre conjuntos de processadores. Alem disso, CUDA permite uma
programacao heterogenea, ou seja, a programacao pode ser dividida entre a CPU e a GPU de
forma que o codigo C serial seja executado em CPU, enquanto kernels paralelos em CUDA
executam em GPU.4do ingles, Thread Processors. Tambem sao conhecidos por Stream Processors. Na arquitetura de GPU eram
conhecidos como Shaders5Um Kernel consiste em uma funcao CUDA que contem o codigo que sera executado em GPU6Paralelismo em nıvel de Thread [HENNESSY; PATTERSON, 1990]

9
2.4.2 Gerenciamento de Threads
As threads em CUDA sao identificadas por blocos, ou seja, cada bloco possui um con-
junto de threads que executam o mesmo trecho de codigo de forma independente entre si. Os
blocos de threads podem ser unidimensionais, bidimensionais ou tridimensionais. As threads
de um mesmo bloco podem cooperar, pois tem acesso a mesma memoria compartilhada. Alem
disso, existem funcoes definidas na biblioteca CUDA que implementam barreiras [SILBERS-
CHATZ; GALVIN, 2000] para sincronizar a execucao das threads. O numero de threads por
bloco e limitado pelos recursos de memoria.
Os blocos de um kernel em CUDA sao identificados por grids, que podem ser uni-
dimensionais ou bidimensionais. As threads de cada bloco em um grid executam de forma
independente das threads dos outros blocos.
A arquitetura Tesla [NVIDIA, 2008] implementada nas placas NVidia mais recentes
e baseada em um vetor de multiprocessadores7. Quando um programa CUDA executando em
CPU chama o grid de um kernel, os blocos do grid sao ordenados e distribuıdos aos multiproces-
sadores da GPU. As threads de um bloco executam concorrentemente em um multiprocessador.
Ao terminar a execucao de um bloco, novos blocos sao lancados para ocupar os multiprocessa-
dores vagos.
Na arquitetura Tesla, um multiprocessador consiste em 8 nucleos de processamento
escalar8. O multiprocessador cria, gerencia e executa threads concorrentes em hardware sem
overhead de escalonamento. Ele tambem implementa barreiras de sincronizacao com uma unica
instrucao.
Para gerenciar centenas de threads executando diferentes programas, o multiproces-
sador implementa um novo tipo de arquitetura chamada de SIMT (Single Intruction, Multiple
Thread). O multiprocessador mapeia cada thread para um nucleo de processamento. E cada
thread executa de forma independente com seu proprio endereco de instrucao e registradores.
7em ingles, Streaming Multiprocessors8em ingles, Scalar Processor

10
O SIMT cria, gerencia e executa threads em grupos de ate 32 threads paralelas, chamadas
warps. As threads que compoe um warp iniciam juntas no mesmo endereco, mas sao livres
para executar independentemente.
Quando um multiprocessador recebe conjunto de um ou mais blocos para executar, ele
o divide em warps que serao escalonados pelo SIMT. A cada instrucao, o SIMT seleciona um
warp que esta pronto para executar e passa para a proxima instrucao nas threads ativas. Um
warp executa uma instrucao comum por vez, assim, quando todas as threads estao executando
juntas, isto e, de forma semelhante, o warp e executado com maior eficiencia.
2.4.3 Hierarquia de Memoria
De forma semelhante a arquitetura do SIMT, que gerencia as threads, o multiproces-
sador implementa o SIMD (Single Instruction, Multiple Data), que com uma instrucao simples
controla o processamento de varios elementos.
Como ilustrado na figura 2.3, cada thread pode acessar 4 tipos de memoria. Cada
thread possui uma memoria local privada e um conjunto de registradores de 32 bits. Cada bloco
de threads possui uma memoria compartilhada9 visıvel a todas as threads do bloco. Todas as
threads do dispositivo possuem acesso a mesma memoria global10, que e a memoria principal
da GPU. E existem tambem as memorias de Constante11 e de Textura12 que sao acessıveis a
todas as threads. Sao memorias somente-leitura otimizadas utilizadas para a entrada de dados
externos ao dispositivo o que permite o acesso indireto a memoria RAM da maquina13.
Um programa pode manipular as memorias global, de contante e de textura atraves da
biblioteca CUDA. Isso inclui alocacao de memoria, liberacao de memoria alocada, assim como
a transferencia entre a memoria do computador e do dispositivo.
O numero de blocos que um multiprocessador comporta depende de quantos regis-
9Shared memory10em ingles, Device Memory11Constant memory12Texture memory13Host Memory

11
Figura 2.3: Hierarquia de Memoria em CUDA
tradores por thread e quanta memoria compartilhada por bloco sao necessarios para um dado
kernel. Se nao houver registradores ou memoria compartilhada suficiente por multiprocessador
para processar pelo menos um bloco, o kernel ira falhar.
Se uma instrucao executada por um warp escreve na mesma posicao de memoria para
mais de uma thread do warp, a ordem que as escritas ocorrem e indefinida.

12
3 Audio Digital
Um sinal analogico de audio e um sinal eletrico que representa as vibracoes mecanicas
do ar. Tais sinais possuem duas dimensoes que representam a pressao do ar variando de acordo
com o tempo. Os sistemas analogicos, utilizam a voltagem do sinal eletrica para representar a
variacao da pressao do ar. Porem os sistemas analogicos sao bastante vulneraveis a distorcoes
de sinal [WATKINSON, 2001].
O audio digital e simplesmente um meio alternativo de transportatr um sinal de audio.
Embora existam varias maneiras de implementar isso, ha um sistema conhecido por Pulse Code
Modulation (PCM [POHLMANN, 2000]), que e amplamente utilizado. No sistema PCM, o
tempo e representado de forma discreta. Dessa forma, o sinal de audio nao e composto por uma
representacao contınua, mas por medidas em intervalos regulares. Este processo e chamado
de amostragem e a frequencia cujas amostras sao medidas e chamado de taxa de amostragem.
Cada amostra ainda varia infinitamente como o sinal original, porem, assim como o tempo,
sua representacao e um valor discreto. E para completar a conversao para o formato PCM,
cada amostra e representada por um valor discreto em um processo chamado quantizacao. Esse
processo consiste em representar a pressao do audio no instante da captura em um valor de
amostra.
Alem de nao ser tao vulneravel a distorcoes, a representacao de audio em formato digi-
tal ofecere varias vantagens [PAN, 1993], como a reprodutibilidade, e ainda permite a aplicacao
de implementacoes eficientes para varias funcoes de processamento de audio.

13
3.1 Processamento de Audio Digital
O processamento de audio digital1 e empregado na gravacao e armazenamento de
audio, para mixagem de sons e producao de programas de tv, assim como em produtos co-
merciais como CDs. O audio digital e, de uma forma digital, todo o caminho do microfone ate
os alto-falantes, onde procesadores de sinais digitais eficientes permitem o processamento em
tempo-real. Atraves do processamento de audio e possıvel modelar o conjunto de amostras de
audio de forma a se obter os efeitos desejados. Com o processamento de audio e possıvel obter
[ROADS et al., 1996]:
• Manipulacao a dinamica da amplitude do som;
• Mixagem para combinar varias faixas de audio;
• Filtros e equalizadores para modificar o espectro de frequencia de um som;
• Efeitos de atraso (time-delay);
• Convolucao, transformacoes simultaneas nos domınios do tempo e da frequencia;
• Projecao espacial, incluindo reverberacao;
• Reducao de ruıdo.
3.2 Compressao de Audio
A Compressao de Audio Digital utiliza de tecnicas de processamento de audio para
permitir o armazenamento e a transmissao de informacao de audio de forma eficiente [PAN,
1993]. Otimizar o processo de compressao de audio permite aumentar a variedade de aplicacoes
para o audio digital. Isso inclui os dispositivos de musica portateis; o audio para cinema; radio
e televisao digital de alta qualidade; aparelhos de DVD e muito mais [CAVAGNOLO; BIER, ].
1Processamento de Sinais de Audio Digital

14
As tecnicas de compressao de audio diferem pela complexidade de seus algoritmos,
pela qualidade da compressao do audio e pela quantidade de dados comprimidos. Tecnicas
simples como a transformacao µ-law2 [PAN, 1993] e a modulacao diferencial adaptaviva por
codigos de pulsos (ADPCM3) [PAN, 1993] podem ser facilmente implementados para processar
audio em tempo-real. O desafio e desenvolver uma implementacao em tempo-real para o padrao
de audio MPEG-1 layer III [PAN, 1995]. As proximas secoes explicam alguns dos conceitos
mais importantes do padrao MPEG-1 Layer III.
3.3 O padrao MPEG-1 Layer III
O MPEG, Motion Pictures Experts Group, e o grupo formado pela ISO4 para definir
padroes de compressao e transmissao de audio e vıdeo. Os padroes MPEG cobrem diferentes
aspectos. Dentre eles, o padrao MPEG-1, foi o primeiro a definir a codificacao do audio.
O padrao MPEG-1 de audio efetua a compressao do audio baseado nas limitacoes
fısicas da audicao humana. O ouvido humano e capaz de detectar sons em uma faixa de
frequencia que varia de 20Hz a 20KHz. De forma que, nao faz sentido armazenar todos os
dados referentes a frequencias fora dessa faixa. Alem disso, dentro da faixa de frequencias
audıveis, a percepcao da audicao humana obedece a uma curva (Figura 3.2) onde a percepcao
da intensidade de um som varia com a frequencia. E, por fim, o ouvido humano nao consegue
captar todos os sons simultaneamente, o que e conhecido como efeito de mascaramento de sons,
onde alguns sons sao escondidos por outros mais fortes. Ou seja, o padrao MPEG-1 de audio
se utiliza das limitacoes da percepcao da audicao humana para eliminar informacoes de audio
sem causar alteracoes perceptıveis, sendo por isso conhecido tambem como um algoritmo de
codificacao perceptiva.
No padrao MPEG-1 Layer III, o audio capturado no formato PCM passa por um banco
de filtros que decompoe 1152 amostras5 PCM do audio em 32 sub-bandas de frequencias de
2http://en.wikipedia.org/wiki/M-law algorithm3Adaptative Differential Pulse-Code Modulation4International Organization for Standardization5Um quadro MP3 e composto de 1152 amostras PCM

15
Sinal Digitalde Áudio(PCM)
Banco de Filtros
MDCT
FFTModelagem
Psicoacústica
Controle deDistorção
Quantificaçãonão-Uniforme
Controlede Taxa
Codifica-ção de
HuffmanFormatação
daSeqüência
deBits
Sinal de ÁudioCodificado
Figura 3.1: Processo de Codificacao MP3
mesma largura. Apos esse processo, a Transformada Discreta de Cosseno Modificada [PRIN-
CEN; BRADLEY, 1986] (MDCT6) e aplicada a cada amostra de cada sub-banda. Com isso, as
sub-bandas, que pertencem ao domınio do tempo, serao mapeadas para o domınio da frequencia.
Enquanto isso, aplica-se a Transformada Rapida de Fourier [DUHAMEL; VETTERLI, 1990]
(FFT7) nas amostras originais para revelar seu espectro sonoro. O espectro, por sua vez, passa
pela modelagem psicoacustica que determina a taxa de energia8 do sinal para o limiar de mas-
caramento de cada sub-banda, que sera utilizada na fase de quantificacao. O bloco de controle
de distorcao utiliza as taxas da relacao sinal / mascaramento (SMR9) do modelo psicoacustico
para decidir quantos bits disponibilizar para a quantificacao dos sinais das sub-bandas para re-
duzir o ruıdo de quantificacao. Em seguida as amostras quantificadas passam pela codificacao
de Huffman [HUFFMAN, 1952] para reduzir a entropia das amostras. Por fim, as amostras
codificadas e suas informacoes sao empacotadas. As subsecoes a seguir descrevem os detalhes
das principais operacoes realizadas. O processo descrito acima esta ilustrado na Figura 3.1.
3.3.1 Banco de Filtros Polifasicos de Analise
O primeiro passo do processo de codificacao e a passagem do sinal de audio PCM por
um banco de filtros. O Banco de Filtros Polifasicos de Analise tem como objetivo decompor o
sinal em 32 sub-bandas. Essa decomposicao agrupa as amostras de sub-banda da mesma forma
6Modified Discret Cosine Transform7Fast Fourier Transform8Nıvel de pressao do ar determinada pelo sinal, em decibeis (dB)9Signal-to-Mask Ratio

16
que no sinal original, porem pode causar algumas distorcoes10.
A sequencia de 1152 amostras PCM de audio de um quadro MP3 sao filtradas de
maneira que cada sub-banda possua 36 amostras. O resultado do banco de filtros e definida pela
seguinte equacao:
S[i] =63
∑k=0
7
∑j=0
M[i][k]∗ (C[k +64 j]∗X [k +64 j])
Onde i e o ındice de cada uma das 32 sub-bandas; S[i] e a amostra resultante para a sub-banda i e
tempo11 t; C[n] e um dos 512 coeficientes da janela de analise definida pelo padrao [PRINCEN;
BRADLEY, 1986]; X [n] e uma amostra de audio de um buffer de amostras de 512 posicoes;
M[i][k] e a matriz de coeficientes da analise que e definido pela equacao:
M[i][k] = cos[(2∗ i+1)∗ (k−16)∗π
64]
Esse conjunto de equacoes esta otimizado para reduzir o numero de calculos. Para
melhorar o entendimento desse calculo, essas equacoes podem ser simplificadas na seguinte
equacao de convolucao:
St[i] =511
∑n=0
X [t−n]∗Hi[n]
Onde X [t] representa uma amostra de audio no tempo t. H[i] que e definido pela
equacao H[i] = h[i]∗cos[ (2∗i+1)∗(n−16)∗π
64 ], representa o filtro responsavel por decompor o audio
em sub-bandas de frequencia adequadas, por isso e chamado de filtro polifasico. E, por fim,
h[n] e definido por −C[n] se o resultado de n/64 for ımpar, caso contrario h[n] = C[n].
10Aliasing [VAIDYANATHAN, 1987]11O tempo t e representado por um inteiro multiplo de 32 intervalos de amostra

17
3.3.2 Transformacao Discreta de Cosseno Modificada
Nesse processo, as amostras das 32 sub-bandas recebidas do banco de filtros sao ma-
peadas em uma transformacao discreta de cosseno modificada (MDCT). Como resultado, as
amotras, que pertencem ao domınio do tempo, serao mapeadas no domınio da frequencia.
Antes de computar a MDCT, quatro funcoes janela12 sao aplicadas as amostras. Funcoes
janela, sao funcoes utilizadas em processamento de sinais para melhorar a eficiencia da analise
do espectro de onda (espectro sonoro no caso do processamento de audio). O padrao MPEG-1
Layer III especifica dois tamanhos de blocos MDCT: o bloco longo de 18 amostras e o bloco
curto de 6 amostras. Ha 50% de sobreposicao entre sucessivas janelas de transformadas uma
vez que o tamanho da janela e 36 ou 12 respectivamente. Da mesma forma, dependendo da
dinamica de cada sub-banda sao usadas janelas longas ou curtas. Se as amostras de uma dada
sub-banda se comportam de forma estacionaria, a janela regular, longa, e usada. Se as amostras
sao transitorias, a janela curta e aplicada para subdividir o resultado da sub-banda em frequencia
e intensificar a resolucao de tempo. Este mecanismo ajuda a evitar o aparecimento do fenomeno
de pre-eco13, o que pode acontecer quando aplicamos a FFT sobre um conjunto de amostras.
O efeito de pre-eco ocorre quando ha uma demanda muito alta de bits em um curto espaco de
tempo (por exemplo, um momento de silencio seguido de um ataque abrupto), e com isso o
ruıdo de quantizacao exagerado de um determinado trecho de audio e espalhado para instantes
anteriores a sua ocorrencia causando um ruıdo audıvel no sinal codificado, nos instantes anteri-
ores a ocorrencia do ataque. As outras duas janelas utilizadas para manipular as transicoes de
longo para curto ou de curto para longo sao chamadas de janela de inıcio e janela de parada,
respectivamente. O bloco curto e um terco do bloco longo, de forma que tres blocos curtos
substituem um bloco longo. O numero de amostras de um quadro de amostras nao e alterado
pela tamanho do bloco. Para um dado quadro de amostras, a MDCT possui 3 modos de blo-
cos, 2 modos com o mesmo tamanho de blocos (longos ou curtos) e um modo misto, onde as
duas sub-bandas de mais baixa frequencia usam blocos de longos e as 30 sub-bandas de mais
12http://en.wikipedia.org/wiki/Window function13http://wiki.hydrogenaudio.org/index.php?title=Pre echo

18
alta frequencia utilizam blocos curtos. Assim e possıvel fornecer melhor resolucao para as
frequencias mais baixas, sem sacrificar as resolucao de tempo para as frequencias mais altas.
3.3.3 Modelagem Psicoacustica
A modelagem psicoacustica e o componente chave para o desempenho do codificador.
Com ela e possıvel simular a percepcao do som pelo sistema auditivo humano. Na codificacao,
a modelagem psicoacustica decide quais partes sao acusticamente irrelevantes e quais nao sao,
e remove as partes inaudıveis. Para isso, ela se aproveita da falta habilidade do sistema au-
ditivo humano em ouvir sons quantificados sobre um mascaramento. O mascaramento e uma
propriedade do sistema auditivo humano que ocorre quando um sinal de audio forte se encontra
proximo de um sinal de audio mais fraco no espectro ou no tempo, tornando o sinal de audio
mais fraco imperceptıvel.
O limiar absoluto de audicao14 consiste na quantidade mınima de energia necessaria
para um tom puro ser detectado em um ambiente silencioso. Se a energia de um numero de tons
de frequencia for medida, obtem-se o grafico da figura 3.2. Isso significa que todos os valores
abaixo da linha do grafico nao podem ser detectados.
O mascaramento de frequencia e um fenomeno que torna um sinal de baixa frequencia
inaudıvel pela ocorrencia simultanea de um sinal mais forte em uma frequencia suficientemente
proxima. O limiar do mascaramento de frequencia pode ser medido e qualquer sinal abaixo
dele nao sera audıvel, como demonstra o grafico da Figura 3.3. O limiar depende da intensidade
sonora e da frequencia da mascara. Com isso e possıvel intensificar o ruıdo de quantificacao de
uma sub-banda o que significa que menos bits serao necesarios para representar o sinal nessa
sub-banda.
Alem do mascaramento no domınio da frequencia, tambem existe o mascaramento
temporal. Isso acontece quando dois sons aparecem em um intervalo muito pequeno de tempo.
O som mais forte pode mascarar o mais fraco. Os efeitos do mascaramento temporal aconte-
14Absotute Threshold of Hearing(ATH)

19
Figura 3.2: Limiar Absoluto de Audicao
cem antes e depois de um som forte. Um som pode sofrer de pos-mascaramento, quando isso
acontece apos um som mais forte, ou pre-mascaramento, quando o som mais forte ocorre logo
em seguida. O pre-mascaramento pode prevenir a ocorrencia de pre-eco.
3.3.4 Quantificacao nao-Uniforme
O bloco de Quantificacao nao-Uniforme recebe o resultado da MDCT, uma janela de
mudanca e informacoes de mascaramento da modelagem psicoacustica para efetuar a quantificacao.
O resultado e um dado codificado de acordo com as limitacoes da audicao humana. A Quantificacao
nao-Uniforme e a parte que mais consome tempo no algoritmo de codificacao. Ela e dividida em
tres nıveis: A execucao do bloco de Quantificacao nao-Uniforme que executa o loop externo,
responsavel pela analise da distorcao, que, por sua vez, executa o loop interno que e responsavel
pela quantificacao e codificacao.
Como demonstrado na Figura 3.4, as amostras das sub-bandas sao quantificadas em um
processo iterativo. O loop interno quantifica a entrada e incrementa o passo do quantificador ate
que os dados possam ser codificados com um certo numero de bits. Apos a execucao do loop

20
Sinal nãoMascarado Sinais
Mascarados
Limiar de Audição
Máscara Limiar de audiçãomodificado
Freqüência
Nív
el
de
Pre
ss
ão
do
Ar
Figura 3.3: Mascaramento de Frequencia
interno, o loop externo faz a verificacao de cada fator de escala da sub-banda, se a distorcao
permitida for excedida, o fator de escala e incrementado e o loop interno e executado novamente.
O loop externo, tambem conhecido como loop de controle de distorcao, controla o
ruıdo produzido pela quantificacao no loop interno. O ruıdo e eliminado pela multiplicacao das
amostras por um fator de escala. O loop externo e executado ate que o ruıdo permaneca abaixo
do limiar de mascaramento para cada fator de escala da sub-banda.
O loop interno, ou loop de controle de taxa, realiza a quantificacao do audio no domınio
da frequencia e o prepara a operacao de formatacao. A tabela do codigo de Huffman atri-
bui palavras menores aos menores valores quantificados. O numero total de bits resultados da
codificacao pode exceder o numero de bits disponıveis em um quadro, isso pode ser corrigido
ajustando o ganho global para resultar em um passo de quantificacao maior e, consequente-
mente, um valor quantificado menor. Essa operacao e repetida com diferentes tamanhos de
passos de quantificacao ate que o numero de bits necessarios pela codificacao de Huffman seja
suficientemente pequeno.

21
Amostrasde
Sub-banda ÁudioCodificado
Loop Externo
Codifica-ção de
Huffman
Quanti-ficação
AjusteGlobal de
Ganho
Ajuste do Fator
de escala
Ajusta o fator de escala e volta ao loop interno,Repete enquanto o ruído da quantificação não for aceitável
Loop InternoAjusta o ganho até que o valorquantificado seja menor que o bitrate
bitrateS S
Compara o ruído de quantificação de cada
sub-banda com o limiar de mascaramento
Figura 3.4: Quantificacao nao-Uniforme
3.3.5 Codificacao de Huffman
Dependendo da implementacao, a codificacao de Huffman baseada em 32 tabelas
estaticas de Huffman e efetuada durante ou apos a quantificacao. A codificacao de Huffman
fornece uma compressao sem perda de dados, portanto e capaz de reduzir o tamanho sem perda
de qualidade. Na Codificacao de Huffman a entropia e baseada na distribuicao estatıstica de um
grupo de valores. Uma tabela de substituicao cobrindo todos os valores e estabelecida a partir
dos dados estatısticos. Nessa tabela, os valores com maiores possibilidades de aparecerem nos
dados sao associados a uma palavra menor e dados que raramente aparecem sao associados a
palavras maiores. Entretanto, a codificacao de Huffman e um codigo de tamanho variavel e
portanto a construcao da tabela de codigos nao e uma tarefa trivial. As amostras sao ordenadas
pela frequencia e entao divididas em tres faixas distintas. Isso permite que cada faixa seja co-
dificada com um conjunto diferente de tabelas especıficamente ajustadas para as estatısticas de
cada faixa.
3.3.6 Formatacao da Sequencia de Bits
A ultima parte da codificacao consiste na producao da sequencia de bits compatıvel
com o padrao MPEG-1 Layer III. A sequencia de bits e particionada em quadros que represen-

22
tam 1152 amostras PCM. O cabecalho descreve a taxa de bits e a frequencia de amostragem
usadas para o audio codificado. Informacoes como tipo de bloco, tabelas de huffman, ganho
de sub-banda e fatores de sub-banda sao selecionados. Uma tecnica utilizada para ajustar a
variacao do tempo de codificacao e a utilizacao de um reservatorio de bits. O codificador pode
doar alguns bits quando ele precisa de menos do que a media de bits necessaria para codificar
um quadro. Em seguida, quando o codificador precisar de mais bits, ele pode emprestar do
reservatorio. O codificador pode emprestar apenas bits doados de quadros passados, nao pode
emprestar de quadros futuros.
3.4 LAME Ain’t an Mp3 Encoder
Considerado um dos melhores, se nao o melhor, codificador MP3, o LAME 15 (acronimo
recursivo de LAME Ain’t an Mp3 Encoder) iniciou em 1998 como um projeto open source que
visava melhorar o modelo psicoacustico, a eliminacao de ruıdo e o desempenho do codificador
dist1016 da ISO, que e a implementacao do padrao MPEG-1 Layer III. Portanto, a princıpio,
o LAME nao era tecnicamente um codificador (por isso o seu nome), apenas uma tentativa de
melhorar o codificador da ISO. Para evitar problemas legais, o LAME foi desenvolvido sob
uma licensa aberta (a LGPL) ao contrario do codigo da ISO e da patente da organizacao de
pesquisa alema Fraunhofer-Gesellschaft17, que desenvolveu o algoritmo de compressao MP3.
Em 1999, o projeto apresentou seu proprio modelo psicoacustico, chamado de GPSYCHO, que
tem como objetivo melhorar o modelo da ISO. Finalmente, em Maio de 2000, todo o codigo
da ISO havia sido reescrito e o LAME surgiu com seu proprio codificador desenvolvido pela
equipe de programadores open source por tras do projeto LAME.
15lame.sourceforge.net16padrao ISO 11172-317http://www.fraunhofer.de

23
4 Processamento de Audio em GPU
E possıvel melhorar a eficiencia das tecnicas de processamento de audio, como a com-
pressao de audio digital, atraves do desenvolvimento do hardware, do desenvolvimento de novas
tecnicas de processamento de sinais ou de melhorias nas tecnicas existentes. Nesse sentido a
programacao de proposito geral em GPU pode ser vista como um meio para tornar algoritmos
de processamento de audio digital mais eficientes atraves do paralelismo desses dispositivos.
Dessa forma o hardware das GPUs pode ser usado para incrementar o desempenho dos algo-
ritmos apenas com algumas modificacoes nas tecnicas de processamento de audio existentes e
sem a necessidade de desenvolver novas tecnicas de processamento de sinais.
Neste trabalho propomos a implementacao de Servidor de Audio que utiliza a programacao
paralela em GPUs do modelo CUDA para melhorar o desempenho do processamento do audio.
Para demonstrar que essa abordagem e possıvel, as proximas secoes deste capıtulo descrevem
um modelo de servidor de audio que captura o audio de um microfone, processa o audio e
transmite o audio processado a um cliente que, apos conectado ao servidor, recebe o audio,
realiza um novo processamento, se necessario, e reproduz o audio. Tambem e descrita a
implementacao de um servidor de audio baseado nesse modelo. O processamento de audio
realizado por essa imlpementacao e a codificacao do audio capturado. Para melhorar o de-
sempenho da codificacao, o codificador foi modificado a fim de ter sua execucao paralelizada
atraves da implementacao de funcoes em CUDA.

24
4.1 Modelo de Servidor de Audio
Este trabalho comecou como um estudo do modelo CUDA de programacao paralela em
GPU e uma analise das possıveis aplicacoes para tal tecnologia. Entre as possıveis aplicacoes
para o processamento paralelo em GPU citadas estao: algoritmos geneticos, criptografia [MA-
NAVSKI., 2007], compactacao, processamento de imagens, processamento de audio, reconhe-
cimento de fala [CHONG et al., 2008] e VoIP. Por fim, foi decidido que este trabalho deveria
desenvolver um modelo de Servidor de Audio e aplicar o processamento em GPU. Dessa forma,
foi possıvel unir as propostas de trabalhar com redes de computadores, processamento paralelo
em GPU e processamento de audio.
O modelo proposto consiste em um servidor que captura o sinal analogico do audio
de um microfone e converte-o para o formato digital atraves de uma biblioteca de audio, repre-
sentada na Figura 4.1 pela Captura de Audio. Apos a captura, o audio, ja no formato digital, e
processado utilizando uma tecnica de processamento de audio implementado em CUDA. Essa
etapa corresponde ao Processamento de Audio na Figura 4.1. Em seguida, o audio processado
e enviado para um cliente atraves de um protocolo de rede. Essa comunicacao entre o servidor
e o cliente esta representada na Figura 4.1 pela Transferencia do Audio Processado. O cliente,
entao, recebe os dados do servidor e realiza um novo processamento, caso seja necessario. E,
por fim, o audio digital e convertido em um sinal analogico para ser executado pelas caixas de
som do cliente. Essa acao e representada na Figura 4.1 pela Reproducao do Audio.
Esse modelo de Servidor de Audio serve como base para demonstrar a utilizacao do
modelo CUDA de programacao paralela em GPU para realizar o processamento de audio. E
dessa forma mostrar que a programacao paralela em GPU pode ser utilizada como um meio de
melhorar o desempenho de tecnicas de processamento de audio existentes, como por exemplo,
a codificacao de audio.

25
Proces-samento
do Áudio
Proces-samento
do Áudio
Processado
Envio
Figura 4.1: Modelo de Servidor de Audio
4.2 Um Servidor de Audio com codificacao em GPU
A primeira implementacao do modelo desenvolveu um Servidor de Audio que utiliza
a biblioteca ALSA1 para capturar o sinal analogico de audio do microfone e converte-lo no
formato PCM de 16 bits little-endian sinalizado; ou seja, cada amostra de audio possui valores
entre -32768 e 32767; em apenas um canal (mono); com taxa de amostragem de 44100Hz, isso
significa que sao capturadas 44100 amostras de audio por segundo. E, alem disso, o Servidor
de audio possui um socket2 configurado com o protocolo UDP [POSTEL, 1980] para enviar
os dados do audio para um cliente. Foi implementado tambem um cliente que se conecta ao
servidor atraves do mesmo protocolo de rede, recebe o audio do servidor e reproduz o audio
digital utilizando o ALSA. O algoritmo do servidor consiste em capturar e enviar o audio para o
cliente, esses procedimentos sao executados repetidamente nessa ordem de ate que a execucao
do servidor seja interrompida pelo usuario. Da mesma forma o cliente recebe e reproduz o audio
do servidor, esses procedimentos tambem sao executados nessa ordem ate que o servidor pare
1Advanced Linux Sound Architecture2http://en.wikipedia.org/wiki/Internet socket

26
de enviar mais dados, pois a funcao de recebimento de dados do cliente e bloqueante. Com essa
implementacao e possıvel capturar o audio em formato digital e reproduzı-lo em outra maquina.
Porem essa implementacao nao representava o modelo proposto, pois nao realizava ne-
nhum processamento de audio entre a captura e a reproducao do audio. Para que a implementacao
correspondesse ao modelo era necessario a implementacao alguma tecnica para processar o
audio do Servidor de Audio implementado. Depois de analisar algumas alternativas, como a
criptografia do audio, foi decidido que o processamento seria uma codificacao do audio cap-
turado. Dessa forma, foi possıvel reduzir a quantidade de dados enviados para o cliente e,
portanto, melhorar a qualidade do audio capturado sem aumentar o tempo de envio do audio
para o cliente.
Entao, foram pesquisados alguns codificadores de audio, entre eles o Speex3, que e um
codificador de audio especializado em fala4. Porem o codificador escolhido foi o LAME. Pois,
dessa forma, foi possıvel aproveitar a documentacao do concurso da NVidia de implementacao
do codificador LAME em CUDA5. Na pagina do concurso, a NVidia disponibiliza uma versao
pre-modificada da versao 3.97 do LAME que foi utilizada como base para o codificador deste
trabalho. O codificador LAME recebe o audio em formato digital, realiza a eliminacao das
partes inaudıveis pelo ouvido humano e comprime o audio restante gerando dados no formato
MP3.
Com isso, a API da biblioteca do codificador LAME foi utilizada para implementar
a codificacao do Servidor de Audio que codifica os dados capturados pelo microfone com a
finalidade de diminuir o tempo de envio. Enquando a implementacao do LAME em CUDA tem
o objetivo de reduzir o tempo da compressao dos dados.
3http://speex.org/4em ingles, speech codec5http://cudacontest.nvidia.com/index.cfm?action=contest.contest&contestid=2

27
4.2.1 Detalhes da Implementacao
O cliente e o servidor foram implementados na linguagem C e para as modificacoes
do codigo da biblioteca LAME foram utilizados C e CUDA. A primeira coisa a ser feita em um
ciclo e a configuracao do LAME. A cada codificacao o LAME deve ser configurado pois algu-
mas variaveis de configuracao nao podem ser reutilizadas. A geracao do audio e feita atraves
de um microfone configurado pela biblioteca de audio ALSA que captura o audio no formato
PCM de 16 bits little-endian sinalizado, em apenas um canal, com uma taxa de amostragem
de 44100Hz. Para conter o audio capturado, utiliza-se um buffer implementado em um vetor
de elementos do tipo short int (16 bits) com 1152 posicoes6. Logo, cada leitura do microfone
captura 1152 amostras PCM.
Apos a captura, o audio e copiado para a memoria da GPU e codificado utilizando
uma funcao de codificacao da biblioteca LAME mantendo as mesmas configuracoes supracita-
das. Os dados do audio codificado retornados pela funcao sao armazenados em um buffer de
unsigned char de tamanho definido atraves de uma funcao da biblioteca LAME que calcula o
tamanho do buffer de acordo com as configuracoes definidas.
Por fim, o buffer MP3 e enviado a um cliente em outra maquina atraves de um soc-
ket que utiliza o protocolo UDP. Do outro lado, o cliente recebe o buffer MP3 e realiza sua
descodificacao utilizando uma funcao de descodificacao da biblioteca LAME que retorna o
audio em amostras PCM e na sequencia esse audio e reproduzido atraves da biblioteca de audio
ALSA.
4.2.2 Codificacao em GPU
Para codificar o audio foram utilizadas funcoes da biblioteca LAME, foi utilizada a
versao 3.97 do LAME disponibilizada pelo concurso da NVidia de implementacao do codifi-
cador LAME em CUDA. Essa versao do LAME possui uma implementacao em CUDA para
o filtro passa-alta do modelo psicoacustico e do ajuste de escala de amostra da funcao de
6Tamanho do quadro MP3

28
codificacao.
O filtro passa-alta do modelo psicoacustico e usado para a deteccao de ataques e,
com isso, evitar o pre-eco. A implementacao paralela do filtro passa-alta permite que todas
as 576 sub-bandas executem o filtro simultaneamente. O ajuste de escala das amostras ocorre
na preparacao do processo de codificacao e consiste em multiplicar o valor de cada amos-
tra PCM por um valor de escala. Este ajuste tem como objetivo alterar o volume sonoro das
amostras. A implementacao dessa funcao em CUDA permite a execucao das multiplicacoes
em paralelo. Essas funcoes foram implementadas pela NVidia no codigo disponibilizado para
o concurso de implementacao do codificador LAME em CUDA. E importante para que estas
implementacao possam ter ganhos de desempenho que o buffer de amostras seja copiado para a
memoria da GPU na preparacao para a codificacao, pois com isso o tempo de acesso a memoria
e otimizado. Portanto foi necessario incluir no Servidor de Audio funcoes da API CUDA para
implementar a copia dos dados para a GPU.
4.3 Resultados
As maquinas utilizadas para os testes dessa implementacao possuem processador Intel R©
CoreTM2 Quad 2.4GHz de 64 bits, 2GB de memoria RAM, equipada com uma GPU Ge-
Force 8600 GT com 256MB de memoria global. O sistema operacional utilizado e o Debian
GNU/Linux versao 5.0 (lenny/sid) com o kernel 2.6.24-1-amd64.
Para medir o desempenho do codificador LAME com modificacoes implementadas
em CUDA, foi realizado um teste comparando o tempo de codificacao do LAME modificado
com a versao 3.97 original do LAME7. No teste realizado, cada implementacao codificou um
conjunto de 6 arquivos no formato WAV [BORN, 1995] com diferentes tamanhos, onde 3 desses
arquivos possuiam amostras em Mono (um canal) e os outros 3 arquivos possuiam amostras em
Stereo (dois canais). Os arquivos foram codificados utilizando a configuracao padrao do LAME
com taxa de bits constante8, mantendo a escala (volume sonoro) e o numero de canais. Cada7http://sourceforge.net/project/showfiles.php?group id=290&package id=3098Constant Bit Rate (CBR)
29
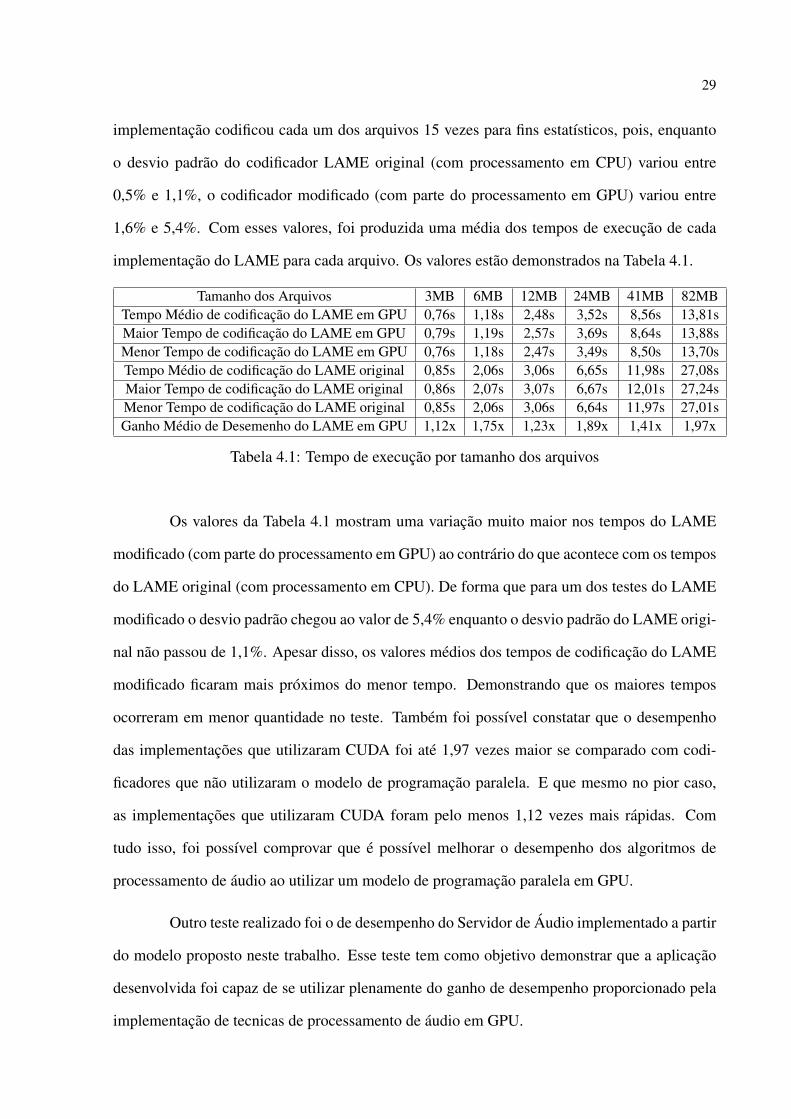
implementacao codificou cada um dos arquivos 15 vezes para fins estatısticos, pois, enquanto
o desvio padrao do codificador LAME original (com processamento em CPU) variou entre
0,5% e 1,1%, o codificador modificado (com parte do processamento em GPU) variou entre
1,6% e 5,4%. Com esses valores, foi produzida uma media dos tempos de execucao de cada
implementacao do LAME para cada arquivo. Os valores estao demonstrados na Tabela 4.1.
Tamanho dos Arquivos 3MB 6MB 12MB 24MB 41MB 82MBTempo Medio de codificacao do LAME em GPU 0,76s 1,18s 2,48s 3,52s 8,56s 13,81sMaior Tempo de codificacao do LAME em GPU 0,79s 1,19s 2,57s 3,69s 8,64s 13,88sMenor Tempo de codificacao do LAME em GPU 0,76s 1,18s 2,47s 3,49s 8,50s 13,70sTempo Medio de codificacao do LAME original 0,85s 2,06s 3,06s 6,65s 11,98s 27,08sMaior Tempo de codificacao do LAME original 0,86s 2,07s 3,07s 6,67s 12,01s 27,24sMenor Tempo de codificacao do LAME original 0,85s 2,06s 3,06s 6,64s 11,97s 27,01sGanho Medio de Desemenho do LAME em GPU 1,12x 1,75x 1,23x 1,89x 1,41x 1,97x
Tabela 4.1: Tempo de execucao por tamanho dos arquivos
Os valores da Tabela 4.1 mostram uma variacao muito maior nos tempos do LAME
modificado (com parte do processamento em GPU) ao contrario do que acontece com os tempos
do LAME original (com processamento em CPU). De forma que para um dos testes do LAME
modificado o desvio padrao chegou ao valor de 5,4% enquanto o desvio padrao do LAME origi-
nal nao passou de 1,1%. Apesar disso, os valores medios dos tempos de codificacao do LAME
modificado ficaram mais proximos do menor tempo. Demonstrando que os maiores tempos
ocorreram em menor quantidade no teste. Tambem foi possıvel constatar que o desempenho
das implementacoes que utilizaram CUDA foi ate 1,97 vezes maior se comparado com codi-
ficadores que nao utilizaram o modelo de programacao paralela. E que mesmo no pior caso,
as implementacoes que utilizaram CUDA foram pelo menos 1,12 vezes mais rapidas. Com
tudo isso, foi possıvel comprovar que e possıvel melhorar o desempenho dos algoritmos de
processamento de audio ao utilizar um modelo de programacao paralela em GPU.
Outro teste realizado foi o de desempenho do Servidor de Audio implementado a partir
do modelo proposto neste trabalho. Esse teste tem como objetivo demonstrar que a aplicacao
desenvolvida foi capaz de se utilizar plenamente do ganho de desempenho proporcionado pela
implementacao de tecnicas de processamento de audio em GPU.

30
TCL TCA TM TCo TE TTServidor de Audio sem codificacao - 54035µs - - 4µs 54045µs
Servidor de Audio com codificacao em CPU 3263µs 50734µs - 12µs 3µs 54043µsServidor de Audio com codificacao em GPU 3196µs 47123µs 13µs 7µ 3µs 51200µs
Tabela 4.2: Desempenho do Servidor de Audio
Esse teste mediu os tempos de execucao de algumas funcoes de diferentes versoes do
Servidor de Audio. As versoes do Servidor de Audio utilizadas foram: um Servidor de Audio
sem codificacao que apenas captura o audio e envia ao cliente que reproduz o audio recebido;
um Servidor de Audio com codificacao em CPU que captura o audio, codifica-o utilizando
o codificador LAME original do teste anterior e envia o resultado da codificacao ao cliente
que o descodifica e reproduz o audio resultante; e o Servidor de Audio com codificacao em
GPU, descrito na secao anterior, que utiliza o codificador LAME modificado (com parte do
processamento em GPU).
Os tempos medidos para esse teste foram o tempo de configuracao do codificador
LAME (TCL), o tempo de captura do audio (TCA), o tempo de copia das amostras para a
memoria da GPU (TM), o tempo de codificacao (TCo), o tempo de envio dos dados (TE) e o
tempo total de cada ciclo do servidor (TT). Os valores foram medidos em micro segundos (µs).
Com isso obteve-se a Tabela 4.2.
Vale destacar que a captura do audio esta sujeita a variacoes de acordo com o audio
introduzido. Logo, o desvio padrao nesse caso chegou a 35% no Servidor de Audio sem
codificacao, a 37,2% no Servidor de Audio com codificacao em CPU e a 62% Servidor de
Audio com codificacao em GPU. Alem disso pode-se considerar que o tempo de captura, em
teoria, deve ser semelhante para os diferentes servidores de audio e, portanto, seus valores
nao alteram o resultado desejado, que era medir a eficiencia da implementacao do codificador
LAME em GPU.
Como demontra a Tabela 4.2, foi possıvel conseguir uma reducao no tempo de envio
dos dados, pois com a codificacao a quantidade de dados enviados ao cliente por ciclo9 reduziu
9Cada ciclo corresponde ao processo de captura, codificacao e envio do audio.

31
de 2304 bytes10 para aproximadamente 208 bytes. Deve-se lembrar que o tempo de envio
dos dados medido neste teste consiste no tempo de execucao da funcao responsavel por essa
acao. Porem, para isso, foi necessario introduzir a configuracao do LAME, que precisa ser
reconfigurado para cada codificacao.
Da mesma forma, foi possıvel reduzir o tempo de codificacao utilizando a versao mo-
dificada do LAME que possui parte de seu processamento em GPU. Nessa comparacao, o Servi-
dor de Audio com codificacao em GPU conseguiu codificar o audio 1,71 vezes mais rapido que
o Servidor de Audio com codificacao em CPU. Porem, mais uma vez, foi necessario acrecentar
o tempo da copia dos dados do audio para a memoria da GPU. Dessa forma, apesar do desem-
penho geral do Servidor de Audio nao ter sido melhorado, pois, em proporcao ao tempo total
de execucao de um ciclo, o tempo de codificacao e muito pequeno e somado ao tempo gasto
transferindo os dados para a memoria da GPU, ou seja, o ganho de desempenho de codificacao
nao foi suficiente para compensar o tempo gasto transferindo os dados para a memoria da GPU.
Porem, o aumento da quantidade de dados a serem processados podem permitir que o ganho de
desempenho do processamento compense o tempo de copia dos dados para a memoria da GPU.
Mas para comprovar esta afirmacao e necessario analisar a variacao dos tempos de copia dos
dados para a memoria da GPU e de codificacao em relacao ao aumento da quantidade de dados.
Ainda existem partes do codificador LAME que podem ser implementadas em CUDA
a fim de melhorar ainda mais seu desempenho. Por exemplo, reescrever as funcoes que uti-
lizam a FFT11 em CUDA; paralelizar os filtros Replay Gain12 e passa-baixa13, assim como
outras otimizacoes na funcao de analise psicoacustica e nas funcoes de codificacao, entre outras
possıveis implementacoes que nao foram citadas aqui. Alem disso um novo teste medindo o
tempo de execucao das funcoes do LAME que foram implementadas em CUDA seria util para
analisar o ganho de desempenho obtido pelo codificador.
101152 amostras de 2 bytes cada11E possıvel utilizar a biblioteca cuFFT que possui um amplo suporte as funcoes de FFT.12Responsaveis por normalizar o ruıdo perceptıvel nas amostras de audio13Responsavel por atenuar a amplitude das frequencias

32
5 Conclusao
Neste trabalho foram introduzidos os principais conceitos a respeito da programacao
paralela e alguns conceitos que envolvem o audio digital e o processamento de sinais, com o
objetivo de desenvolver um modelo de Servidor de Audio que permita o desenvolvimento de
uma aplicacao que utilize o processamento em GPU para melhorar o desempenho de tecnicas
de processamento de audio. Demostrando, com isso, que o modelo de programacao paralela em
GPU e adequado para ser utilizado em aplicacoes multimıdia.
Foi implementado um Servidor de Audio, baseado no modelo proposto, que utiliza a
programacao em GPU para implementar a codificacao do audio. A ideia foi utilizar a codificacao
do audio para reduzir a quantidade de dados enviada e reduzir o tempo de codificacao utilizando
uma implementacao do codificador LAME em CUDA. Para avaliar o Servidor de Audio imple-
mentado, foram realizados experimentos. O primeiro experimento comparou o desempenho
do codificador de audio em GPU com o desempenho de sua versao em CPU. Enquanto o se-
gundo experimento comparou os tempos de execucao das funcoes de tres versoes do Servidor de
Audio: uma versao sem codificacao, uma com codificacao em CPU e a ultima com codificacao
em GPU.
Os experimentos demostraram que a aplicacao implementada nao possuia volume de
dados intenso ou grau de paralelismo suficientes para tornar o resultado do uso da tecnica de
processamento paralelo em GPU expressivo. Porem, os resultados mostraram que o modelo de
programacao paralela em GPU foi capaz de otimizar o desempenho da codificacao do audio,
como foi proposto.
Assim, foi possıvel demonstrar que a utilizacao da GPU para a programacao de proposito

33
geral esta evoluindo rapidamente de maneira a se tornar um meio eficiente e viavel para a
implementacao de diversos tipos de aplicacoes. E que os sistemas multimıdia podem se aprovei-
tar do aumento da capacidade de processamento, proporcionado pelos modelos de programacao
em GPU, para melhorar do desempenho das tecnicas existentes e para a criacao de novas
tecnicas.

34
Referencias Bibliograficas
BORN, G. Formats Handbook. London: Thomson Computer Press, 1995.
CAVAGNOLO, B.; BIER, J. Introduction to digital audio compression.
CHONG, J. et al. Data-parallel large vocabulary continuous speech recognition on graphicsprocessors. In: Proceedings of the 1st Annual Workshop on Emerging Applications and ManyCore Architecture (EAMA). [S.l.: s.n.], 2008. p. 23–35.
DUHAMEL, P.; VETTERLI, M. Fast fourier transforms: A tutorial review and a state ofthe art. Signal Process., Elsevier North-Holland, Inc., Amsterdam, The Netherlands, TheNetherlands, v. 19, n. 4, p. 259–299, 1990. ISSN 0165-1684.
HALFHILL, T. R. Parallel Processing with CUDA. January 28 2008. InStat MicroprocessorReport.
HENNESSY, J. L.; PATTERSON, D. A. Computer Architecture; A Quantitative Approach.San Francisco, CA, USA: Morgan Kauffman Publishers Inc., 1990. ISBN 1558600698.
HUFFMAN, D. A. A method for the construction of minimum-redundancy co-des. Proceedings of the IRE, v. 40, n. 9, p. 1098–1101, 1952. Disponıvel em:<http://ieeexplore.ieee.org/xpls/abs all.jsp?arnumber=4051119>.
LAGO, N. P. Processamento Distribuıdo de Audio em Tempo Real. Abril 2004.
MANAVSKI., S. A. Cuda compatible gpu as an efficient hardware accelerator for aescryptography. In: . [S.l.: s.n.], 2007. p. 65–68.
NVIDIA. NVIDIA CUDA Compute Unified Device Architecture Programming Guide. Version2.0. June 7 2008.
PAN, D. Y. Digital audio compression. Digital Tech. J., Digital Equipment Corp., Acton, MA,USA, v. 5, n. 2, p. 28–40, 1993. ISSN 0898-901X.
PAN, D. Y. A tutorial on mpeg/audio compression. IEEE MultiMedia, IEEE Computer SocietyPress, Los Alamitos, CA, USA, v. 2, n. 2, p. 60–74, 1995. ISSN 1070-986X.
PEDDIE, J. Digital Media Technology: Industry Trends and Developments. 2001. IEEEComputer Graphics and Applications.
PEERCY, M.; SEGAL, M.; GERSTMANN, D. A performance-oriented data parallel virtualmachine for gpus. In: SIGGRAPH ’06: ACM SIGGRAPH 2006 Sketches. New York, NY, USA:ACM, 2006. p. 184. ISBN 1-59593-364-6.
POHLMANN, K. C. Principles of Digital Audio. [S.l.]: McGraw-Hill Professional, 2000.ISBN 0071348190.

35
POSTEL, J. User Datagram Protocol. [S.l.], August 1980. 3 p. Disponıvel em:<http://www.rfc-editor.org/rfc/rfc768.txt>.
PRINCEN, J. P.; BRADLEY, A. B. Analysis/synthesis filter bank design based on time domainaliasing cancellation. IEEE Transaction on Acoustics, Speech and Signal Processing, n. 5, p.1153–1161, out. 1986.
ROADS, C. et al. The Computer Music Tutorial. Cambridge, MA, USA: MIT Press, 1996.ISBN 0-252-18158-3.
SILBERSCHATZ, A.; GALVIN, P. B. Operating System Concepts. New York, NY, USA: JohnWiley & Sons, Inc., 2000. ISBN 0471418846.
VAIDYANATHAN, P. P. Quadrature mirror filter banks, M-band extensions and perfectreconstruction techniques. v. 4, n. 3, p. 4–20, jul. 1987.
WATKINSON, J. Introduction to Digital Audio. Newton, MA, USA: Butterworth-Heinemann,2001. ISBN 0240516435.

36
ANEXO A -- CUDA Application Programming Interface
A interface de programacao (API) do modelo CUDA fornece um meio de programa-
dores familiarizados com a linguagem C escreverem facilmente programas para executar em
GPU. Para isso um conjunto mınimo de extensoes da linguagem C permitem indicar partes do
codigo para ser executado em GPU. A API consiste tambem em uma biblioteca de execucao1
que permite o controle de mais de uma GPU a partir da CPU; funcoes especıficas para execu-
tarem em GPU; e uma componente comum que define tipos e um subconjunto da biblioteca
padrao C permitem a execucao tanto em CPU quanto em GPU. As unicas funcoes da biblioteca
padrao C suportadas para executar em GPU sao as disponibilizadas pela componente comum
da biblioteca de execucao.
A.1 Extensoes da Linguagem C
A API CUDA define 4 extensoes para a linguagem C: qualificadores de funcao, que
definem se a funcao deve ser chamada em CPU ou GPU e onde ela deve ser executada; qualifica-
dores de variaveis que especificam em qual memoria a variavel sera alocada; uma nova diretiva
que especifica como um kernel deve ser executado; e variaveis pre-definidas que especificam as
dimensoes do grid e dos blocos e os ındices dos blocos e threads.
A.1.1 Qualificadores de Funcao
Os qualificadores de funcao device , global e host sao responsaveis por de-
finir se a funcao definida sera executada em CPU ou GPU e a partir de onde ela pode ser
1CUDA runtime library

37
invocada.
O qualificador device declara uma funcao que e executada em GPU e pode ser
chamada apenas a partir da GPU. O qualificador global declara uma funcao como sendo
um kernel. Tal funcao e executada em GPU e pode ser chamada apenas a partir da CPU. O
qualificador host declara uma funcao que e executada em CPU e pode ser chamada apenas a
partir da CPU. E equivalente declarar uma funcao com o qualificador host ou sem nenhum
dos qualificadores de funcao. O qualificador host pode ser utilizado em conjunto com o
qualificador device . Nesse caso o codigo sera compilado para GPU e CPU.
Os qualificadores de funcao possuem restricoes. Funcoes definidas para executar em
GPU nao suportam recursao; nao podem possuir declaracoes de variaveis estaticas; e nao po-
dem ter numero variavel de argumentos. Ponteiros para funcoes device nao sao suportados.
Os qualificadores global e host nao podem ser usados juntos. Funcoes global de-
vem retornar void, pois essas funcoes sao assıncronas, ou seja, a chamada retorna antes do fim
de sua execucao. Parametros de funcoes global sao passados para a GPU pela memoria
compartilhada e sao limitados a 256 bytes.
A.1.2 Qualificadores de Variaveis
Os qualificadores de variaveis definem em qual tipo de memoria a variavel declarada
sera alocada.
Varıaveis declaradas com o qualificador device serao alocadas na memoria global
da GPU; que permanecem em memoria durante o tempo de execucao do kernel; e acessıveis por
todas as threads do grid e a partir da CPU atraves da biblioteca de execucao. Qualquer um dos
outros qualificadores de variaveis podem ser utilizados junto com o qualificador device . O
qualificador constant define variaveis que residem na memoria constante; que permanecem
em memoria durante o tempo de execucao do kernel; e acessıveis por todas as threads do grid
e a partir da CPU atraves da biblioteca de execucao. O qualificador shared define variaveis
alocadas na memoria compartilhada de um bloco de threads; que permanecem em memoria

38
durante a execucao do bloco; e acessıveis a todas as threads do bloco. Apenas apos a execucao
do comando syncthreads() que a escrita a variaveis compartilhadas sao garantidas de serem
vistas pelas outras threads do bloco.
Os qualificadores de variaveis possuem restricoes. Nao e permitido utiliza-los em
struct ou union, em parametros formais e em variaveis locais de uma funcao que executa
em CPU. Os qualificadores shared e constant implicam em armazenamento estatico.
Variaveis device e constant sao declaradas fora de funcoes. Variaveis constant nao
podem ser definidas em GPU, apenas atraves de funcoes de execucao especıficas em CPU.
Variaveis shared nao podem possuir uma declaracao como parte de suas declaracoes. Os
enderecos obtidos de variaveis device , shared ou constant podem ser utilizadas ape-
nas em GPU. Entretanto, os enderecos de variaveis device ou constant obtidos atraves
da funcao cudaGetSymbolAddress()2 podem ser usadas em CPU.
A.1.3 Parametros de Configuracao da Execucao
Qualquer chamada de uma funcao global deve especificar uma configuracao de
execucao para a chamada.
A configuracao de execucao define a dimensao do grid e dos blocos que serao usados
para executar a funcao no dispositivo. A especificacao da configuracao e feita inserindo uma
expressao da forma <<< Dg, Db, Ns, S >>> entre o nome da funcao e a lista de argumentos.
Dg e do tipo dim3, que sera abordado na secao A.2.1, e especifica o tamanho do grid em
ate duas dimensoes, onde o numero de blocos a serem lancados e Dg.x * Dg.y (o numero de
blocos na dimensao x vezes o numero de blocos na dimensao y). Db tambem e do tipo dim3
e especifica o tamanho de cada bloco em ate tres dimensoes, tal que Db.x * Db.y * Db.z (o
numero de blocos na dimensao x vezes o numero de blocos na dimensao y vezes o numero de
blocos na dimensao z) equivale ao numero de threads por bloco. Ns e do tipo size t e especifica
o numero de bytes na memoria compartilhada que sera alocada dinamicamente em cada bloco
para uma chamada alem da memoria alocada estaticamente. Esse valor e usado para definir o2Secao 4.5.2.3 do Guia de Programacao CUDA [NVIDIA, 2008]

39
tamanho de vetores alocados dinamicamente. O argumento Ns e opcional e tem valor padrao
igual a 0. S e do tipo cudaStream t e especifica o stream associado. O argumento S e opcional
e tem valor padrao igual a 0.
Os argumentos de configuracao de execucao sao avaliados antes dos argumentos da
funcao e ambos sao passados atraves da memoria compartilhada para a GPU. Se algum dos
parametros de configuracao da execucao forem maior que o permitido a execucao ira falhar.
A.1.4 Variaveis Pre-definidas
As variaveis pre-definidas sao variaveis definidas automaticamente a partir da chamada
de uma funcao. Elas possuem as dimensoes e tamanhos do grid e dos blocos e os ındices dos
blocos e threads.
A variavel gridDim e do tipo dim3 e contem o tamanho do grid para todas as suas
dimensoes. A variavel blockIdx e do tipo uint3, que sera explicado na secao A.2.1, e contem o
ındice do bloco corrente para cada uma das dimensoes do grid. A variavel blockDim e do tipo
dim3 e contem o tamanho do bloco todas as suas dimensoes. A variavel threadIdx e do tipo
uint3 e contem o ındice da thread corrente para cada uma das dimensoes do bloco. E a variavel
warpSize e do tipo int e contem o tamanho do warp em threads.
Nao e possıvel indicar o endereco ou atribuir valor a nenhuma dessas variaveis.
A.1.5 O Compilador NVCC
O compilador nvcc busca simplificar o processo de compilacao do codigo CUDA. O
compilador prove opcoes de linha de comando simples e familiares.
A rotina basica do nvcc consiste em separar o codigo GPU do codigo CPU e compilar
o codigo GPU em uma forma binaria conhecida como cubin. O codigo CPU gerado permanece
em C e sera compilado com outra ferramenta no ultimo estagio da compilacao.
Aplicacoes podem ignorar o codigo CPU gerado e carregar e executar o codigo cubin

40
em GPU diretamente utilizando a API do driver3 ou podem linkar o codigo cubin com o codigo
CPU.
O codigo CUDA e compilado de acordo com as regras de sintaxe da linguagem C++.
C++ e totalmente suportado no codigo CPU, no entanto, apenas o subconjunto de regras de
C sao totalmente suportadas em GPU. Caracterısticas especıficas como classes, heranca, ou
declaracao de variaveis em blocos basicos nao sao suportadas. Como consequencia do uso das
regras de sintaxe de C++, ponteiros void nao podem ser associados a ponteiros nao-void sem o
uso de typecast.
O nvcc introduz duas diretivas: noinline e # pragma unroll.
Por padrao, uma funcao device e definida como inline, ou seja, a funcao e copiada
inteira para cada posicao onde ela e chamada. A diretiva noinline e utilizada para indicar
para o processador nao fazer isso se possıvel. Ainda assim, a funcao deve estar no mesmo
arquivo em que ela e chamada.
Por padrao o compilador desenrola pequenos loops para melhorar o desempenho da
aplicacao. A diretiva # pragma unroll permite controlar o desenrolamento de qualquer loop.
A diretiva deve ser inserida imediatamente antes do loop. Ela pode ser opcionalmente seguida
pelo numero de vezes que o loop sera desenrolado. # pragma unroll 1 indica ao compilador
que o loop nao deve ser desenrolado. Se o numero de vezes que o loop sera desenrolado, o
compilador desenrola o loop todo.
A.2 Componente de Execucao Comum
A componente de execucao comum4, como o nome diz, pode ser usada tanto em GPU
quanto em CPU.
3Ver secao A.4.24Common Runtime Component

41
A.2.1 Tipos Pre-definidos
char1, uchar1, char2, uchar2, char3, uchar3, char4, uchar4, short1, ushort1,
short2, ushort2, short3, ushort3, short4, ushort4, int1, uint1, int2, uint2, int3, uint3, int4,
uint4, long1, ulong1, long2, ulong2, long3, ulong3, long4, ulong4, float1, ufloat1, float2,
ufloat2, float3, ufloat3, float4, ufloat4 sao estruturas baseadas dos tipos basicos inteiro e ponto
flutuante. Suas primeira, segunda, terceira e quarta componentes sao acessıveis atraves dos
campos x, y, z e w respectivamente. Todos esses tipos possuem um construtor com a forma
make <nome do tipo>(). Por exemplo: make int2(int x, int y) cria uma variavel do tipo int2
com valor (x, y).
O tipo dim3 e baseado no tipo uint3. Esse tipo e usado para especificar dimensoes.
Quando uma variavel e definida com esse tipo, qualquer componente nao especificada possuira,
por padrao, valor 1.
A.2.2 Funcoes Matematicas
As funcoes matematicas da biblioteca padrao C/C++ suportadas em CUDA sao espe-
cificadas na componente de execucao comum, ou seja, podem ser executadas tanto em CPU
como em GPU.
A Secao B.1 do Guia de Programacao CUDA [NVIDIA, 2008] contem uma lista das
funcoes matematicas da biblioteca padrao C/C++ que sao suportadas em CUDA.
A.2.3 Funcoes de Tempo
Quando a funcao clock t clock(); e executada em GPU, ela retorna o valor de um
contador do multiprocessador que e incrementado a cada ciclo do clock. Cada multiprocessador
da GPU possui um contador individual. Coletando o valor desse contador no inıcio e no final
de um kernel, tirando a diferenca entre as duas coletas e guardando o resultado por thread e
possıvel medir o numero de clocks que cada thread precisou para completar a execucao do

42
kernel.
A.2.4 Tipo Textura
A biblioteca de execucao CUDA suporta um subconjunto de instrucoes para o acesso
a memoria de textura. E possıvel obter benefıcios de desempenho ao ler dados da memoria de
textura ao inves da memoria global.
A memoria de textura e lida atraves de um kernel usando funcoes chamadas de fet-
ches de textura. O primeiro parametro de um fetch e um objeto chamado de referencia de
textura. Uma referencia de textura define qual parte da textura sera buscada. Ela deve ser limi-
tada atraves da CPU a algumas regioes de memoria, chamadas texturas, antes de serem usadas
pelo kernel. Varias regioes distintas podem ser limitadas a uma mesma textura ou a texturas
sobrepostas na memoria.
Uma referencia de textura possui varios atributos. Um deles e a dimensao da textura,
que especifica onde a textura esta enderecada. Uma textura e enderecada como um vetor de ate
3 dimensoes. Os elementos do vetor sao chamados de elementos de textura.
Outros atributos definem os tipos de entrada e saıda do fetch de textura; como as coor-
denadas das entradas sao interpretadas e que processamento deve ser feito.
Alguns atributos de textura sao imutaveis e devem ser conhecidos em tempo de compilacao.
Eles sao especificados ao declarar a referencia de textura. Uma referencia de textura e declarada
no escopo do arquivo como uma variavel do tipo textura: texture<Type, Dim, ReadMode>
texRef;. Onde Type especifica o tipo do dado que sera retornado pela busca da textura. Type e
restrito a tipos inteiros basicos, ponto flutuantes de precisao simples e qualquer dos tipos com
1, 2 ou 4 componentes definidos na secao A.2.1. Dim especifica a quantidade de dimensoes
da referencia de textura e pode possuir valor igual a 1, 2 ou 3. Dim e um argumento opcio-
nal e, por padrao, possui valor igual a 1. ReadMode possui valor igual a cudaReadMode-
ElementType ou cudaReadModeNormalizedFloat. Caso ReadMode seja cudaReadMode-
NormalizedFloat e Type seja um inteiro de 16 ou 8 bits, o valor retornado e convertido para

43
ponto flutuante. Caso ReadMode seja cudaReadModeElementType, nenhuma conversao e
realizada. O atributo ReadMode e opcional e possui como valor padrao cudaReadModeEle-
mentType.
Os outros atributos de uma referencia de textura sao mutaveis e podem ser alteradas
em tempo de execucao atraves de instrucoes da CPU. Eles especificam onde as coordenadas da
textura estao normalizadas ou nao; o modo de enderecamento; e filtros de textura.
A.3 Componente de Execucao em GPU
As funcoes da componente de execucao em GPU podem ser utilizadas apenas em
funcoes que executam na GPU.
A.3.1 Funcoes Matematicas
Para algumas das funcoes referenciadas na secao A.2.2 existe uma versao menos pre-
cisa porem mais rapida na componente de execucao em GPU. Seus nomes possuem o mesmo
prefixo com (por exemplo: sinf(x)). Essas funcoes estao listadas na Secao B.2 do Guia de
Programacao CUDA [NVIDIA, 2008].
O compilador tambem possui uma opcao (-use fast math) para forcar cada funcao a
compilar a sua versao menos precisa, se ela existir.
A.3.2 Funcao de Sincronizacao
A funcao syncthreads() sincroniza todas as threads em um bloco. Uma vez que
todas as threads atingiram este ponto, a execucao prossegue normalmente.
E permitido utilizar a funcao syncthreads() instrucoes condicionais, apenas se as
condicoes forem avaliadas identicamente para todas as threads do bloco. Se essa condicao nao
for atendida, a execucao pode resultar efeitos nao desejados.

44
A.3.3 Funcoes de Textura
Uma textura pode ser qualquer regiao de memoria linear ou um vetor CUDA (que sao
regioes de memoria otimizadas para utilizar texturas).
Utilizando uma regiao de memoria linear, a textura pode ser acessıvel atraves da
famılia de funcoes tex1Dfetch().
Quando vetores CUDA sao usados para acessar uma textura, utiliza-se as funcoes
tex1D(), tex2D ou tex3D.
A.3.4 Funcoes Atomicas
Uma funcao atomica realiza leitura, modificacao e escrita em uma unica operacao em
uma palavra de 32 ou 64 bits em algum endereco na memoria global ou na compartilhada. Por
exemplo, a funcao atomicAdd() le uma palavra de 32 bits de algum endereco de memoria na
memoria global na compartilhada, soma um inteiro a palavra e escreve o resultado no mesmo
endereco. A operacao e atomica no sentido de garantir que sera executada sem interferencia de
outras threads.
A.4 Componente de Execucao em CPU
A componente de execucao em CPU fornece um conjunto de funcoes para manipular o
gerenciamento da GPU; o gerenciamento de contexto; o gerenciamento de memoria; o controle
de execucao; o gerenciamento das referencias de textura; e a interoperabilidade com OpenGL
e Direct3D. A componente de execucao em CPU e composta de duas partes: a API do driver
CUDA e a API de execucao CUDA. Essas partes sao mutuamente exclusivas, ou seja, so e
permitido a uma aplicacao usar uma delas.

45
A.4.1 API de Execucao
Nao ha uma inicializacao explıcita para a API de execucao. Ela e inicializada ao exe-
cutar a primeira funcao da biblioteca de execucao.
Para gerenciar as GPUs instaladas no sistema, sao utilizadas as funcoes cudaGetDe-
viceCount(), cudaGetDeviceProperties() e cudaSetDevice(). cudaGetDeviceCount() e cu-
daGetDeviceProperties() fornecem um meio de enumerar as GPUs e obter suas informacoes.
Enquanto cudaSetDevice e usada para definir a GPU que sera associada a thread da CPU.
Regioes de memoria linear sao alocadas usando a funcao cudaMalloc() ou cudaMal-
locPitch() e liberadas usando cudaFree(). Vetores CUDA sao alocados pela funcao cuda-
MallocArray() e liberadas pela funcao cudaFreeArray(). cudaMallocArray() exige que uma
descricao de formato seja criada atraves da funcao cudaCreateChannelDesc(). Um endereco
de variavel alocada ne memoria global pode ser obtido pela funcao cudaGetSymbolAddress().
E o tamanho da memoria alocada e obtido pela funcao cudaGetSymbolSize().
O Gerenciamento da referencia de textura utiliza o tipo textureReference para definir
uma referencia de textura. Antes que um kernel possa usar uma referencia de textura para ler da
memoria de textura, a referencia de textura deve ser vinculada a uma textura usando a funcao
cudaBindTexture() ou a cudaBindTextureToArray(). E para desvincular uma referencia de
textura, utiliza-se a funcao cudaUnbindTexture().
Para a interoperabilidade com o OpenGL, um buffer deve ser registrado em CUDA
antes que ele possa ser mapeado. Isso e feito com a funcao cudaGLRegisterBufferObject().
Uma vez registrado, o buffer pode sr lido ou escrito por kernels usando o endereco de memoria
da GPU retornado por cudaGLMapBufferObject(). E para eliminar o mapeamento e o registro
utiliza-se, respectivemente, as funcoes cudaGLUnmapBufferObject() e cudaGLUnregister-
BufferObject().
E para a interoperabilidade com o Direct3D e necessario determinar qual GPU sera uti-
lizada antes de qualquer execucao. Isso e feito atraves da funcao cudaD3D9SetDirect3DDevice().

46
Os recursos Direct3D sao registrados em CUDA pela funcao cudaD3D9RegisterResources().
Para remover o registro utiliza-se cudaD3DUnregisterVertexBuffer(). Assim que os recursos
foram registrados, eles podem ser mapeados em CUDA quantas vezes forem necessarias atraves
da funcao cudaD3D9MapResources(). E da mesma forma, para eliminar o mapeamento
utiliza-se cudaD3D9UnmapResources(). Um recurso mapeado pode ser lido ou escrito por
kernels utilizando o endereco de memoria retornado por cudaD3D9ResourceGetMappedPointer()
e o tamanho e o pitch sao retornados pelas funcoes: cudaD3D9ResourceGetMappedSize(),
cudaD3D9ResourceGetMappedPitch() e cudaD3D9ResourceGetMappedPitchSlice().
A.4.2 API do Driver
Antes de executar qualquer funcao da API do driver, e necessario uma inicializacao
com a funcao cuInit().
Para manipular as GPUs instaladas no sistema, sao utilizadas, entre outras, as funcoes
cuDeviceGetCount() e cuDeviceGet().
A API do driver tambem permite a manipulacao do contexto. Todos os recursos e
acoes realizados atraves da API do driver sao encapsuladas em um contexto CUDA. Uma th-
read de CPU pode possuir apenas um contexto ativo por vez. Para criar um contexto, usa-se
a funcao cuCtxCreate(). Cada thread da CPU possui uma pilha de contextos. cuCtxCreate()
poe um novo contexto no topo da pilha. Para desvincular o contexto ativo de uma thread da
CPU, a funcao cuCtxPopCurrent(). Se houver algum contexto anterior, ele sera reativado.
Uma contagem de uso e mantida para cada contexto. A funcao cuCtxCreate() cria um con-
texto com contagem igual a 1 que e incrementado pela funcao cuCtxAttach() e decrementado
pela funcao cuCtxDetach(). Um contexto e destruıdo quando a contagem chega a 0 ao chamar
a funcao cuCtxDetach() ou cuCtxDestroy(). Clientes da API podem usar as funcoes cuCtx-
PushCurrent() e cuCtxPopCurrent() para criar contextos.
O controle de execucao pode ser manipulado pelas seguintes funcoes. A funcao cu-
FuncSetBlockShape() que define o numero de threads por bloco para uma dada funcao. cu-

47
FuncSetSharedSize() define o tamanho de memoria compartilhada para a funcao. A famılia
de funcoes cuParam*() e usada para especificar os parametros do kernel que sera invocado.
cuLaunchGrid() ou cuLaunch() sao utilizadas para invocar um kernel.
O gerenciamento de memoria e feito atraves das funcoes cuMemAlloc(), cuMemAl-
locPitch() e cuMemFree() para manipular memoria linear. E atraves das funcoes cuArray-
Create() e cuArrayDestroy() para manipular vetores CUDA.
Para utilizar a memoria de textura, uma referencia de textura deve ser criada utilizando
a funcao cuTexRefSetAddress() ou cuTeXRefSetArray().
A interoperabilidade com o OpenGL requer uma inicializacao pela funcao cuGLInit().
Apos isso, um buffer deve ser registrado utilizando a funcao cuGLRegisterBufferObject()
e mapeado com a funcao cuGLMapBufferObject(). Para eliminar o mapeamento, utiliza-
se a funcao cuGLUnmapBufferObject(). E a funcao cuGLUnregisterBufferObject() para
remover o registro o buffer.
E para a interoperabilidade com o Direct3D e necessaria a criacao de um contexto. Isso
pode ser feito pela funcao cuD3D9CtxCreate(). Os recursos Direct3D podem ser registrados
em CUDA usando a funcao cuD3D9RegisterResource(). Esse registro pode ser eliminado pela
funcao cuD3D9UnregisterVertexBuffer(). Apos os recursos serem registrados em CUDA, eles
podem ser mapeados pela funcao cuD3D9MapResources(). E o mapeamento pode ser elimi-
nado pela funcao cuD3D9UnmapResources(). Um recurso mapeado pode ser lido e escrito
pelo kernel atraves do ponteiro retornado pela funcao cuD3D9ResourceGetMappedpointer(),
do tamanho retornado pela funcao cuD3D9ResourceGetMappedSize() e do pitch retornado
pelas funcoes cuD3D9ResourceGetMappedPitch() e cuD3D9ResourceGetMappedPitchSlice().

48
ANEXO B -- Speaker (servidor)
/*******************************************************************************
* Este codigo foi escrito por mim e tem a finalidade de capturar o audio
* codifica-lo de forma paralela e envia-lo a um cliente
******************************************************************************/
/* Bibliotecas Gerais */
#include <cuda.h>
#include <cuda_runtime.h>
#include <lhal04.h>
#include <lhal04_lame/include/lame.h>
void reusePort(int s){
int one=1;
if ( setsockopt(s,SOL_SOCKET,SO_REUSEADDR,(char *) &one,sizeof(one)) == -1 ){
printf("error in setsockopt,SO_REUSEPORT \n");
exit(-1);
}
}

49
int get_gpu_buffer_size( lame_global_flags *gf, int bytesPerSample, int pad )
{
int nsamp = lame_get_num_samples(gf);
return nsamp*bytesPerSample + pad; //assume 2 bytes per sample (16-bit)
}
int main(int argc, char **argv){
/* Variaveis para manipulacao do socket */
int sd;
struct sockaddr_in server;
struct hostent *hp, *gethostbyname();
struct servent *sp;
struct sockaddr_in to;
int to_len;
int length;
char localhost[MAXHOSTNAME];
char msg[MAXHOSTNAME];
/* Variaveis para manipulacao do dispositivo de audio */
int rc,i;
snd_pcm_t *handle = NULL;
snd_pcm_hw_params_t *params;
unsigned int val;

50
int direction;
snd_pcm_uframes_t frames;
buffer_t *buffer;
int size;
int num_samples_read;
lame_global_flags *gfp;
unsigned char *mp3buffer;
float *gpu_buffers[2];
int gpu_buffer_sz;
float in_buffer_l[1152];
float in_buffer_r[1152];
struct timeval tt1,tt2;
struct timeval tcl1,tcl2;
struct timeval tca1,tca2;
struct timeval ta1,ta2;
struct timeval tco1,tco2;
struct timeval te1,te2;
/* Configuracao do Socket */
if(argc > 2){
fprintf(stderr, "Uso correto: speaker <porta>\n");
exit(1);
}
sp = getservbyname("echo", "udp");

51
/* get Host information, NAME and INET ADDRESS */
gethostname(localhost, MAXHOSTNAME);
printf("----Speaker running at host NAME: %s\n", localhost);
if ( (hp = gethostbyname(localhost)) == NULL ) {
fprintf(stderr, "Can’t find host name\n");
exit(-1);
}
bcopy ( hp->h_addr, &(server.sin_addr), hp->h_length);
printf(" (Speaker INET ADDRESS is: %s )\n", inet_ntoa(server.sin_addr));
/* Construct name of socket to send to. */
server.sin_family = AF_INET;
server.sin_addr.s_addr = htonl(INADDR_ANY);
if (argc == 1)
server.sin_port = htons(0);
else
server.sin_port = htons(atoi(argv[1]));
/* Create socket on which to send and receive */
sd = socket (AF_INET,SOCK_DGRAM,0);
/* to allow another process to use the same port
howver, only ONE gets the message */
reusePort(sd);

52
if ( bind( sd, (struct sockaddr *) &server, sizeof(server) ) < 0 ) {
close(sd);
perror("binding name to datagram socket");
exit(-1);
}
/* get port information and prints it out */
length = sizeof(server);
if ( getsockname (sd, (struct sockaddr *)&server,&length) ) {
perror("getting socket name");
exit(0);
}
printf("Server Port is: %d\n", ntohs(server.sin_port));
to_len = sizeof(to);
printf("\n...server is waiting...\n");
if ((rc=recvfrom(sd, msg, sizeof(msg), 0, (struct sockaddr *) &to, &to_len)) <
0)
perror("receiving datagram message");
printf("Enviando audio para: %s:%d\n", inet_ntoa(to.sin_addr),
htons(to.sin_port));
if ((hp = gethostbyaddr((char *)&to.sin_addr.s_addr,
sizeof(to.sin_addr.s_addr), AF_INET)) == NULL)
fprintf(stderr, "Can’t find host %s\n", inet_ntoa(to.sin_addr));

53
/* Configuracao do dispositivo de audio */
/* Abre o dispositivo PCM "default" para captura (gravacao) */
rc = snd_pcm_open(&handle, "default", SND_PCM_STREAM_CAPTURE, 0);
if (rc < 0){
fprintf(stderr, "Nao consegui abrir o dispositivo pcm: %s\n",
snd_strerror(rc));
exit(1);
}
/* Aloca um objeto de parametros do harware */
snd_pcm_hw_params_malloc(¶ms);
/* Preenche os parametros com valores default */
snd_pcm_hw_params_any(handle, params);
/* Define os parametros de hardware desejados */
printf("Configuracoes de Audio...\n");
/* Define modo de acesso pcm como sendo entrelacado (interleaved) */
snd_pcm_hw_params_set_access(handle, params, SND_PCM_ACCESS_RW_INTERLEAVED);
/* Define o formato do audio como signed 16 bits little-endian */
snd_pcm_hw_params_set_format(handle, params, SND_PCM_FORMAT_S16_LE);
/* Define dois canais (stereo) */
snd_pcm_hw_params_set_channels(handle, params, CANAIS);

54
/* Define a taxa de amostragem aproximada como 44100 bits/s (qualid. de CD) */
val = SAMPLE_RATE;
direction = 0;
snd_pcm_hw_params_set_rate_near(handle, params, &val, &direction);
/* Define o tamanho do periodo em frames */
frames = 32;
direction = 0;
snd_pcm_hw_params_set_period_size_near(handle, params, &frames, &direction);
/* Escreve os parametros no Driver */
rc = snd_pcm_hw_params(handle, params);
if (rc < 0){
fprintf(stderr, "\nNao consegui definir os parametros de hw: %s\n",
snd_strerror(rc));
exit(1);
}
snd_pcm_hw_params_get_channels(params, &val);
printf("Numero de canais: %d\n",val);
snd_pcm_hw_params_get_rate(params, &val, &direction);
printf("Taxa de Amostragem: %d Hz\n",val);
printf("...OK\n\n");
gfp = lame_init();
lame_set_num_channels(gfp,CANAIS);
lame_set_mode(gfp,MONO);

55
lame_set_in_samplerate(gfp,SAMPLE_RATE);
lame_set_num_samples(gfp,1152);
lame_init_params(gfp);
lame_print_config(gfp);
lame_print_internals(gfp);
size = lame_get_size_mp3buffer(gfp);
buffer = (buffer_t *) malloc(NSAMPLES*2);
mp3buffer = (unsigned char *) malloc(size);
printf("Tamanho do buffer pcm: %d amostras\n",NSAMPLES);
printf("Tamanho do buffer mp3: %d bytes\n\n",size);
lame_close(gfp);
/* Loop principal */
while(1){
gfp = lame_init();
lame_set_num_channels(gfp,CANAIS);
lame_set_mode(gfp,MONO);
lame_set_num_samples(gfp,NSAMPLES);
lame_set_in_samplerate(gfp,SAMPLE_RATE);
lame_set_num_samples(gfp,1152);
rc = lame_init_params(gfp);
/* Captura Audio */

56
rc = snd_pcm_readi(handle, buffer, NSAMPLES*2);
if (rc == -EPIPE){
fprintf(stderr, "Overrun ocurred\n");
snd_pcm_prepare(handle);
rc = NSAMPLES*2;
}
else if (rc < 0){
fprintf(stderr, "Erro na leitura: %s\n", snd_strerror(rc));
}
else if (rc != NSAMPLES*2){
fprintf(stderr, "Short read. Expected %d samples, read %d samples\n",
NSAMPLES, rc/2);
/* As amostras sao de 2 bytes cada, por isso eh necessario dividir o
* tamanho do buffer e o rc por 2, uma vez que estas variaveis sao medidas
* em bytes, nao em amostras. */
}
num_samples_read = rc/2;
gpu_buffer_sz = get_gpu_buffer_size( gfp, sizeof(float), 0);
cudaMalloc((void *)&(gpu_buffers[1]), gpu_buffer_sz);
cudaMalloc((void *)&(gpu_buffers[0]), gpu_buffer_sz);
for ( i = 0; i < num_samples_read; i++){
// valores esperados: +/- 32768.0
in_buffer_l[i] = (float) buffer[i];

57
in_buffer_r[i] = (float) buffer[i];
}
cudaMemcpy( &gpu_buffers[0], in_buffer_l, sizeof(float)*num_samples_read, cudaMemcpyHostToDevice);
cudaMemcpy( &gpu_buffers[1], in_buffer_r, sizeof(float)*num_samples_read, cudaMemcpyHostToDevice);
rc = lame_encode_buffer(gfp, &gpu_buffers[0], &gpu_buffers[1], num_samples_read, mp3buffer, size);
rc = lame_encode_flush(gfp, mp3buffer, sizeof(mp3buffer));
sendto(sd, mp3buffer, size, 0, (struct sockaddr *) &to, sizeof(to));
lame_close(gfp);
}
}

58
ANEXO C -- Listener (cliente)
/*******************************************************************************
* Este codigo foi escrito por mim e tem a finalidade de receber o audio de um
* servidor, descodifica-lo e reproduzi-lo
******************************************************************************/
/* Bibliotecas Gerais */
#include <lhal04.h>
#include <orig/include/lame.h>
int main(int argc, char **argv){
/* Variaveis para manipulacao do socket */
int sd;
struct sockaddr_in server;
struct hostent *hp, *gethostbyname();
struct servent *sp;
struct sockaddr_in from;
struct sockaddr_in addr;
int fromlen;
int cc;

59
char localhost[MAXHOSTNAME];
char msg[MAXHOSTNAME];
/* Variaveis para manipulacao do audio */
int rc;
snd_pcm_t *handle;
snd_pcm_hw_params_t *params;
unsigned int val;
int direction;
snd_pcm_uframes_t frames;
buffer_t *buffer;
lame_global_flags *gfp;
unsigned char *mp3buffer;
/* Configuracao do Socket */
if(argc != 3){
fprintf(stderr, "Uso correto: listener <end_servidor> <porta>\n");
exit(1);
}
sp = getservbyname("echo", "udp");
/* get Listener Host information, NAME and INET ADDRESS */
gethostname(localhost, MAXHOSTNAME);

60
printf("----Listener running at host NAME: %s\n", localhost);
if ( (hp = gethostbyname(localhost)) == NULL ) {
fprintf(stderr, "Can’t find host %s\n", argv[1]);
exit(-1);
}
bcopy ( hp->h_addr, &(server.sin_addr), hp->h_length);
printf("(Listener INET ADDRESS is: %s )\n", inet_ntoa(server.sin_addr));
/* get Speaker Host information, NAME and INET ADDRESS */
if ( (hp = gethostbyname(argv[1])) == NULL ) {
addr.sin_addr.s_addr = inet_addr(argv[1]);
if ((hp = gethostbyaddr((char *)&addr.sin_addr.s_addr,
sizeof(addr.sin_addr.s_addr),AF_INET)) == NULL) {
fprintf(stderr, "Can’t find host %s\n", argv[1]);
exit(-1);
}
}
printf("----Speaker running at host NAME: %s\n", hp->h_name);
bcopy ( hp->h_addr, &(server.sin_addr), hp->h_length);
printf("(Speaker INET ADDRESS is: %s )\n", inet_ntoa(server.sin_addr));
/* Construct name of socket to send to. */
server.sin_family = AF_INET;
server.sin_port = htons(atoi(argv[2]));
/* Create socket on which to send and receive */

61
sd = socket (hp->h_addrtype,SOCK_DGRAM,0);
if (sd<0) {
perror("opening datagram socket");
exit(-1);
}
/* Comunica com o Servidor */
strcpy(msg, hp->h_name);
if (sendto(sd, msg, strlen(msg), 0, (struct sockaddr *)&server, sizeof(server)) < 0 )
perror("N~ao consegui comunicar com o servidor");
/* Configuracao do dispositivo de audio */
printf("Configuracoes de Audio...\n");
/*snd_pcm_open(pcm handle, handler identifier, direction, mode)*/
/*mode pode ser bloqueante (0) ou nao bloqueante (1) */
rc = snd_pcm_open(&handle, "default", SND_PCM_STREAM_PLAYBACK, 0);
if (rc < 0){
fprintf(stderr, "Nao consegui abrir o dispositivo pcm: %s\n",
snd_strerror(rc));
exit(1);
}
/* Define os parametros de hardware desejados */

62
snd_pcm_hw_params_malloc(¶ms);
snd_pcm_hw_params_any(handle, params);
snd_pcm_hw_params_set_access(handle, params, SND_PCM_ACCESS_RW_INTERLEAVED);
snd_pcm_hw_params_set_format(handle, params, SND_PCM_FORMAT_S16_LE);
snd_pcm_hw_params_set_channels(handle, params, CANAIS);
val = SAMPLE_RATE;
snd_pcm_hw_params_set_rate_near(handle, params, &val, &direction);
frames = 32;
snd_pcm_hw_params_set_period_size_min(handle, params, &frames, &direction);
rc = snd_pcm_hw_params(handle, params);
if (rc < 0){
fprintf(stderr, "Nao consegui definir os parametros de hw: %s\n", snd_strerror(rc));
exit(1);
}
snd_pcm_hw_params_get_channels(params, &val);
printf("Numero de canais: %d\n", val);
snd_pcm_hw_params_get_rate(params, &val, &direction);
printf("Taxa de Amostragem: %d Hz\n", val);
printf("...OK\n\n");
gfp = lame_init();
lame_set_num_channels(gfp,CANAIS);
lame_set_mode(gfp,MONO);

63
lame_set_out_samplerate(gfp,SAMPLE_RATE);
lame_set_num_samples(gfp,1152);
lame_set_brate(gfp, 16);
lame_init_params(gfp);
lame_decode_init();
lame_set_decode_only(gfp,1);
lame_print_config(gfp);
lame_print_internals(gfp);
buffer = (buffer_t *) malloc(NSAMPLES*2);
mp3buffer = (unsigned char *) malloc(MAXMP3);
printf("Tamanho do buffer pcm: %d amostras\n",NSAMPLES);
printf("Tamanho do buffer mp3: %d bytes\n\n",MAXMP3);
lame_close(gfp);
/* Loop principal */
while(1){
gfp = lame_init();
lame_set_num_channels(gfp,CANAIS);
lame_set_num_samples(gfp,NSAMPLES);
lame_set_mode(gfp,MONO);
lame_set_num_samples(gfp,1152);
lame_set_brate(gfp, 16);
lame_set_decode_only(gfp,1);

64
rc = lame_init_params(gfp);
lame_decode_init();
/* cc = numero de bytes recebidos */
fromlen = sizeof(from);
cc = recvfrom(sd, mp3buffer, MAXMP3, 0, (struct sockaddr *) &from,
&fromlen);
rc = lame_decode(mp3buffer, MAXMP3, buffer, NULL);
rc = snd_pcm_writei(handle, buffer, NSAMPLES*2);
if (rc < 0)
rc = snd_pcm_recover(handle, rc, 0);
if (rc < 0){
fprintf(stderr, "Reproducao de Audio falhou: %s\n", snd_strerror(rc));
break;
}
else if (rc != NSAMPLES*2)
fprintf(stderr, "Short write. Expected %d samples, written %d samples\n",
NSAMPLES, rc/2);
lame_close(gfp);
}
}

65
ANEXO D -- lhal04.h
/*******************************************************************************
* Biblioteca de Configuracao do Servidor de Audio escrita por mim que e
* incluida no codigo do servidor e do cliente
******************************************************************************/
/* Bibliotecas Gerais */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>
/* Bibliotecas de Audio */
#include <alsa/asoundlib.h>
/* Bibliotecas de Socket */
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <netdb.h>
#include <arpa/inet.h>
#include <sys/time.h>

66
#include <time.h>
#define MAXHOSTNAME 80
/* Usa a API mais recente */
#define ALSA_PCM_NEW_HW_PARAMS_API
typedef short int buffer_t;
/* Define configuracoes de Audio */
#define CANAIS 1
#define SAMPLE_RATE 44100
#define NSAMPLES 1152
#define MAXMP3 lame_get_size_mp3buffer(gfp)

67
ANEXO E -- psyKernel
/*******************************************************************************
* Este codigo e parte das modificac~oes feitas no LAME pela NVidia como ponto
* inicial para o concurso de implementac~ao do LAME em CUDA. Ele possui os
* Kernels em CUDA e as funcoes em C utilizadas pelo LAME para executar em GPU
******************************************************************************/
#include <stdio.h>
#include "cuda_runtime.h"
#include "cutil.h"
#include "cufft.h"
#include "../include/lame.h"
#include "lame_global_flags.h"
#ifdef __cplusplus
extern "C" void hpf( float *firc , float *samples, float *out, int nCoeff, int
nSamples) ;
extern "C" void scaler( float *data, int num_d, float scale) ;
extern "C" void gpu_init(void);
extern "C" void scaler2( float *d, float *d2, int num_d, float scl);
#else

68
void hpf( float *firc , float *samples, float *out, int nCoeff, int nSamples);
void scaler( float *data, int num_d, float scale);
void gpu_init(void);
void scaler2( float *d, float *d2, int num_d, float scl);
#endif
/* Filtro passa-alta do modelo psicoacustico */
// filter coefficients taken from libmp3lame/pysmodel.c
__constant__ float fircoef[] = {
-8.65163e-18*2, -0.00851586*2, -6.74764e-18*2, 0.0209036*2,
-3.36639e-17*2, -0.0438162 *2, -1.54175e-17*2, 0.0931738*2,
-5.52212e-17*2, -0.313819 *2
};
__global__ void HPFilter(float *firc,
float *firbuf,
float *ns_hpfsmpl,
int szCoeff,
int nSamps ){
int idx = blockIdx.x * gridDim.x + threadIdx.x;
int j = 0;
float sum1;
float sum2;
sum1 = firbuf[idx+10];
sum2 = 0.0f;

69
for( j=0 ; j<10; j+=2 ) {
sum1 += fircoef[j ] * ( firbuf[idx+j ] + firbuf[idx+21-j] );
sum2 += fircoef[j+1] * ( firbuf[idx+j+1 ] + firbuf[idx+21-j-1] );
}
ns_hpfsmpl[idx] = sum1+sum2;
}
static float *gpuBuf = NULL;
static float *hpfBuf = NULL;
void gpu_init(void) {
CUDA_SAFE_CALL( cudaMalloc((void**)&gpuBuf, 50000) );
CUDA_SAFE_CALL( cudaMalloc((void**)&hpfBuf, 50000) );
}
void hpf(float *coeff ,
float *samples,
float *out,
int nCoeff,
int nSamples){
int nThreads = 32;
int nBlocks = nSamples/nThreads;
dim3 gridSz( nBlocks, 1, 1);
dim3 blockSz( nThreads, 1 , 1);
if( gpuBuf == NULL ) gpu_init();

70
CUDA_SAFE_CALL( cudaMemcpy(gpuBuf, samples, sizeof(float)*(nSamples +
nCoeff), cudaMemcpyHostToDevice));
HPFilter<<< gridSz, blockSz >>>( coeff, gpuBuf, hpfBuf, nThreads, nBlocks );
CUDA_SAFE_CALL( cudaMemcpy(out, hpfBuf, sizeof(float) * nSamples,
cudaMemcpyDeviceToHost) );
}
/* Ajuste de escala de amostra */
__global__ void scaler_cuda(float *data_in,
float *data_out,
float scale){
int idx = (32 * blockIdx.x) + threadIdx.x;
data_out[idx] = data_in[idx] * scale;
}
void scaler(float *d,
int num_d,
float scl){
int nThreads = 32;

71
int nBlocks = num_d/nThreads;
if(num_d % nThreads) {
nBlocks++;
}
dim3 gridSz( nBlocks, 1, 1);
dim3 blockSz( nThreads, 1 , 1);
CUDA_SAFE_CALL( cudaMemcpy(gpuBuf, d, sizeof(float)*num_d,
cudaMemcpyHostToDevice));
scaler_cuda<<< gridSz, blockSz >>>(gpuBuf, hpfBuf, scl);
CUDA_SAFE_CALL( cudaMemcpy(d, hpfBuf, sizeof(float) * num_d,
cudaMemcpyDeviceToHost) );
}
void scaler2(float *d,
float *d2,
int num_d,
float scl){
int nThreads = 32;
int nBlocks = (num_d * 2)/nThreads;
if((num_d *2) % nThreads) {
nBlocks++;
}

72
dim3 gridSz( nBlocks, 1, 1);
dim3 blockSz( nThreads, 1 , 1);
CUDA_SAFE_CALL( cudaMemcpy(gpuBuf, d, sizeof(float)*num_d,
cudaMemcpyHostToDevice));
CUDA_SAFE_CALL( cudaMemcpy(&gpuBuf[num_d], d2, sizeof(float)*num_d,
cudaMemcpyHostToDevice));
scaler_cuda<<< gridSz, blockSz >>>(gpuBuf, hpfBuf, scl);
CUDA_SAFE_CALL( cudaMemcpy(d, hpfBuf, sizeof(float) * num_d,
cudaMemcpyDeviceToHost) );
CUDA_SAFE_CALL( cudaMemcpy(d2, &hpfBuf[num_d], sizeof(float) * num_d,
cudaMemcpyDeviceToHost) );
}






![Improvement of the Quality of Surimi Products with ...downloads.hindawi.com/journals/jfq/2017/1417856.pdf[8] M. P´erez-Mateos, H. Lourenc ¸o, P. Montero, and A. J. Border´ıas,](https://static.documents.pub/doc/80x56/5e99fe464904c05237111e27/improvement-of-the-quality-of-surimi-products-with-8-m-perez-mateos-h.jpg)










