35
MACHINE LEARNING IN RUST WITH LEAF AND COLLENCHYMA RUST TALK BERLIN | Feb.2016 > @autumn_eng
| Date post: | 20-Mar-2017 |
| Category: |
Technology |
| Upload: | michael-j-hirn |
| View: | 1,215 times |
| Download: | 1 times |

MACHINE LEARNING IN RUSTWITH LEAF AND COLLENCHYMARUST TALK BERLIN | Feb.2016
> @autumn_eng

“In machine learning, we seek methods by which the computer will
come up with its own program based on examples that we provide.”
MACHINE LEARNING ~ PROGRAMMING BY EXAMPLE
[1]: http://www.cs.princeton.edu/courses/archive/spr08/cos511/scribe_notes/0204.pdf

AREAS OF ML
[1]: http://cs.jhu.edu/~jason/tutorials/ml-simplex
DOMAIN KNOWLEDGE LOTS OF DATA PROOF. TECHNIQUES
BAYESIAN DEEP CLASSICAL
INSIGHTFUL MODEL FITTING MODEL ANALYZABLE MODEL

> DEEP LEARNING. TON OF DATA + SMART ALGOS + PARALLEL COMP.
[1]: http://www.andreykurenkov.com/writing/a-brief-history-of-neural-nets-and-deep-learning/

LARGE, SPARSE, HIGH-DIMENSIONAL DATASETS, LIKEIMAGES, AUDIO, TEXT, SENSORY & TIMESERIES DATA
KEY CONCEPTS | DATA

> DEEP NEURAL NETWORK UNIVERSAL FUNCTION APPROXIMATOR, REPRESENTING HIRARCHICAL STRUCTURES IN LEARNED DATA
KEY CONCEPTS | ALGORITHMS
[1]: http://cs231n.github.io/neural-networks-1/

> DEEP NEURAL NETWORK
KEY CONCEPTS | ALGORITHMS
[image]: http://www.kdnuggets.com/wp-content/uploads/deep-learning.png

> BACKPROPAGATION COMPUTING GRADIENTS OF THE NETWORK THROUGH THE CHAIN RULE
KEY CONCEPTS | ALGORITHMS
[1]: http://cs231n.github.io/optimization-2/

KEY CONCEPTS | PARALLEL COMPUTATION
> MULTI CORE DEVICES (GPUs) HIGH-DIMENSIONAL MATHEMATICAL OPERATIONS CAN BE EXECUTED MORE EFFICIENTLY ON SPECIAL-PURPOSE CHIPS LIKE GPUS OR FPGAS.

> COLLENCHYMA PORTABLE, PARALLEL, HPC IN RUST
[1]: https://github.com/autumnai/collenchyma
SIMILAR PROJECTS: ARRAYFIRE (C++)
COLLENCHYMA | OVERVIEW
[1]: https://github.com/autumnai/collenchyma

COLLENCHYMA FUNDAMENTAL CONCEPTS
1. PORTABLE COMPUTATION | FRAMEWORKS/BACKEND2. PLUGINS | OPERATIONS3. MEMORY MANAGEMENT | SHAREDTENSOR

A COLLENCHYMA-FRAMEWORK DESCRIBES A COMPUTATIONAL LANGUAGE LIKE RUST, OPENCL, CUDA.
A COLLENCHYMA-BACKEND DESCRIBES A SINGLE COMPUTATIONAL-CAPABLE HARDWARE (CPU, GPU, FPGA) WHICH IS ADDRESSABLE BY A FRAMEWORK.
COLLENCHYMA | PORTABLE COMPUTATION

/// Defines a Framework.pub trait IFramework { /// Initializes a new Framework. /// /// Loads all the available hardwares fn new() -> Self where Self: Sized;
/// Initializes a new Device from the provided hardwares. fn new_device(&self, &[Self::H]) -> Result<DeviceType, Error>;}
/// Defines the main and highest struct of Collenchyma.pub struct Backend<F: IFramework> { framework: Box<F>, device: DeviceType,}
COLLENCHYMA | PORTABLE COMPUTATION

// Initialize a CUDA Backend.let backend = Backend::<Cuda>::default().unwrap();
// Initialize a CUDA Backend - the explicit waylet framework = Cuda::new();let hardwares = framework.hardwares();let backend_config = BackendConfig::new(framework, hardwares[0]);let backend = Backend::new(backend_config).unwrap();
COLLENCHYMA | PORTABLE COMPUTATION

COLLENCHYMA-PLUGINS ARE CRATES, WHICH EXTEND THE COLLENCHYMA BACKEND WITH FRAMEWORK AGNOSTIC, MATHEMATICAL OPERATIONS E.G. BLAS OPERATIONS
COLLENCHYMA | OPERATIONS
[1]: https://github.com/autumnai/collenchyma-blas [2]: https://github.com/autumnai/collenchyma-nn

/// Provides the functionality for a backend to support Neural Network related operations.pub trait NN<F: Float> { /// Initializes the Plugin. fn init_nn();
/// Returns the device on which the Plugin operations will run. fn device(&self) -> &DeviceType;}
/// Provides the functionality for a Backend to support Sigmoid operations.pub trait Sigmoid<F: Float> : NN<F> { fn sigmoid(&self, x: &mut SharedTensor<F>, result: &mut SharedTensor<F>) -> Result<(), ::co::error::Error>; fn sigmoid_plain(&self, x: &SharedTensor<F>, result: &mut SharedTensor<F>) -> Result<(), ::co::error::Error>; fn sigmoid_grad(&self, x: &mut SharedTensor<F>, x_diff: &mut SharedTensor<F>) -> Result<(), ::co::error::Error>; fn sigmoid_grad_plain(&self, x: &SharedTensor<F>, x_diff: &SharedTensor<F>) -> Result<(), ::co::error::Error>;}
COLLENCHYMA | OPERATIONS
[1]: https://github.com/autumnai/collenchyma-nn/blob/master/src/plugin.rs

impl NN<f32> for Backend<Cuda> { fn init_nn() { let _ = CUDNN.id_c(); } fn device(&self) -> &DeviceType { self.device() }}
impl_desc_for_sharedtensor!(f32, ::cudnn::utils::DataType::Float);impl_ops_convolution_for!(f32, Backend<Cuda>);impl_ops_sigmoid_for!(f32, Backend<Cuda>);impl_ops_relu_for!(f32, Backend<Cuda>);impl_ops_softmax_for!(f32, Backend<Cuda>);impl_ops_lrn_for!(f32, Backend<Cuda>);impl_ops_pooling_for!(f32, Backend<Cuda>);
COLLENCHYMA | OPERATIONS
[1]: https://github.com/autumnai/collenchyma-nn/blob/master/src/frameworks/cuda/mod.rs

COLLENCHYMA’S SHARED TENSOR IS A DEVICE- AND FRAMEWORK-AGNOSTIC MEMORY-AWARE, N-DIMENSIONAL STORAGE.
COLLENCHYMA | MEMORY MANAGEMENT

OPTIMIZED FOR NON-SYNC USE CASE
pub struct SharedTensor<T> { desc: TensorDesc, latest_location: DeviceType, latest_copy: MemoryType, copies: LinearMap<DeviceType, MemoryType>, phantom: PhantomData<T>,}
COLLENCHYMA | MEMORY MANAGEMENT
[1]: https://github.com/autumnai/collenchyma/blob/master/src/tensor.rs

fn sigmoid(&self,x: &mut SharedTensor<f32>,result: &mut SharedTensor<f32> ) -> Result<(), ::co::error::Error>
{ match x.add_device(self.device()) { _ => try!(x.sync(self.device())) } match result.add_device(self.device()) { _ => () }
self.sigmoid_plain(x, result)}
COLLENCHYMA | MEMORY MANAGEMENT
[1]: https://github.com/autumnai/collenchyma-nn/blob/master/src/frameworks/cuda/helper.rs

fn main() { // Initialize a CUDA Backend. let backend = Backend::<Cuda>::default().unwrap(); // Initialize two SharedTensors. let mut x = SharedTensor::<f32>::new(backend.device(), &(1, 1, 3)).unwrap(); let mut result = SharedTensor::<f32>::new(backend.device(), &(1, 1, 3)).unwrap(); // Fill `x` with some data. let payload: &[f32] = &::std::iter::repeat(1f32).take(x.capacity()).collect::<Vec<f32>>(); let native = Backend::<Native>::default().unwrap(); x.add_device(native.device()).unwrap(); write_to_memory(x.get_mut(native.device()).unwrap(), payload); // Write to native host memory. x.sync(backend.device()).unwrap(); // Sync the data to the CUDA device. // Run the sigmoid operation, provided by the NN Plugin, on your CUDA enabled GPU. backend.sigmoid(&mut x, &mut result).unwrap(); // See the result. result.add_device(native.device()).unwrap(); // Add native host memory result.sync(native.device()).unwrap(); // Sync the result to host memory. println!("{:?}", result.get(native.device()).unwrap().as_native().unwrap().as_slice::<f32>());}
COLLENCHYMA | BRINGING IT TOGETHER
[1]: https://github.com/autumnai/collenchyma#examples

> LEAF MACHINE INTELLIGENCE FRAMEWORK
[1]: https://github.com/autumnai/leaf
SIMILAR PROJECTS: Torch (Lua), Theano (Python), Tensorflow (C++/Python), Caffe (C++)
LEAF | OVERVIEW

Fundamental Parts
Layers (based on Collenchyma plugins)Solvers

CONNECTED LAYERS FORM A NEURAL NETWORK
BACKPROPAGATION VIA TRAITS=> GRADIENT CALCULATION EASILY SWAPABLE
LEAF | Layers

T = DATATYPE OF SHAREDTENSOR (e.g. f32).B = BACKEND
/// A Layer that can compute the gradient with respect to its input.pub trait ComputeInputGradient<T, B: IBackend> { /// Compute gradients with respect to the inputs and write them into `input_gradients`. fn compute_input_gradient(&self, backend: &B, weights_data: &[&SharedTensor<T>], output_data: &[&SharedTensor<T>], output_gradients: &[&SharedTensor<T>], input_data: &[&SharedTensor<T>], input_gradients: &mut [&mut SharedTensor<T>]);}
LEAF | Layers

POOLING LAYER
EXECUTE ONE OPERATIONOVER A REGION OF THE INPUT
LEAF | Layers
[image]: http://cs231n.github.io/convolutional-networks/

impl<B: IBackend + conn::Pooling<f32>> ComputeInputGradient<f32, B> for Pooling<B> { fn compute_input_gradient(&self, backend: &B, _weights_data: &[&SharedTensor<f32>], output_data: &[&SharedTensor<f32>], output_gradients: &[&SharedTensor<f32>], input_data: &[&SharedTensor<f32>], input_gradients: &mut [&mut SharedTensor<f32>]) { let config = &self.pooling_configs[0]; match self.mode { PoolingMode::Max => backend.pooling_max_grad_plain(
output_data[0], output_gradients[0],input_data[0], input_gradients[0], config).unwrap()
}}}
LEAF | Layers
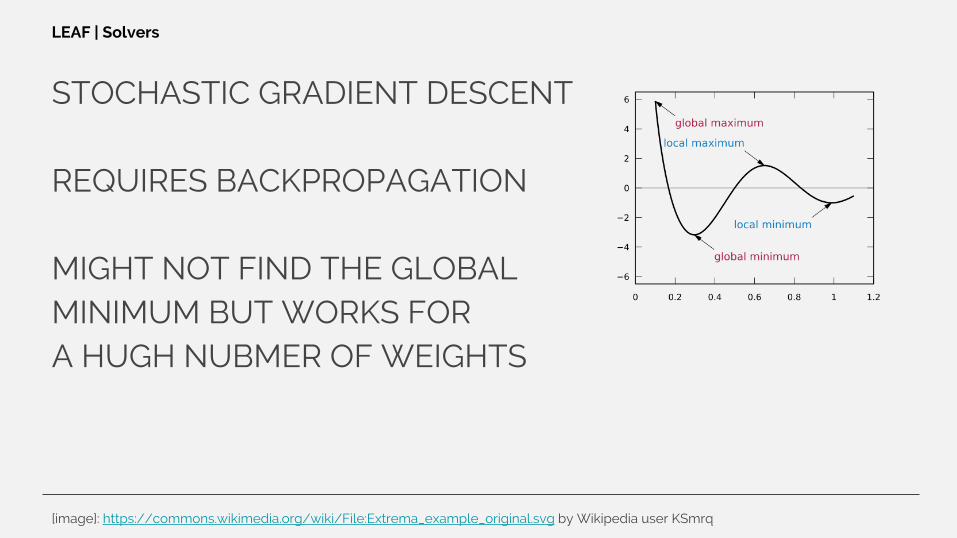
STOCHASTIC GRADIENT DESCENT
REQUIRES BACKPROPAGATION
MIGHT NOT FIND THE GLOBALMINIMUM BUT WORKS FORA HUGH NUBMER OF WEIGHTS
LEAF | Solvers
[image]: https://commons.wikimedia.org/wiki/File:Extrema_example_original.svg by Wikipedia user KSmrq

SDG WITH MOMENTUM:
LEARNING RATE
MOMENTUM OF HISTORY
LEAF | PART 2

LEAF
BRINGING ALL THE PARTS TOGETHER

> LIVE EXAMPLE - MNIST
Dataset of 50_000 (training) + 10_000 (test) handwritten digits
28 x 28 px greyscale (8bit) images
[image]: http://neuralnetworksanddeeplearning.com/chap1.html
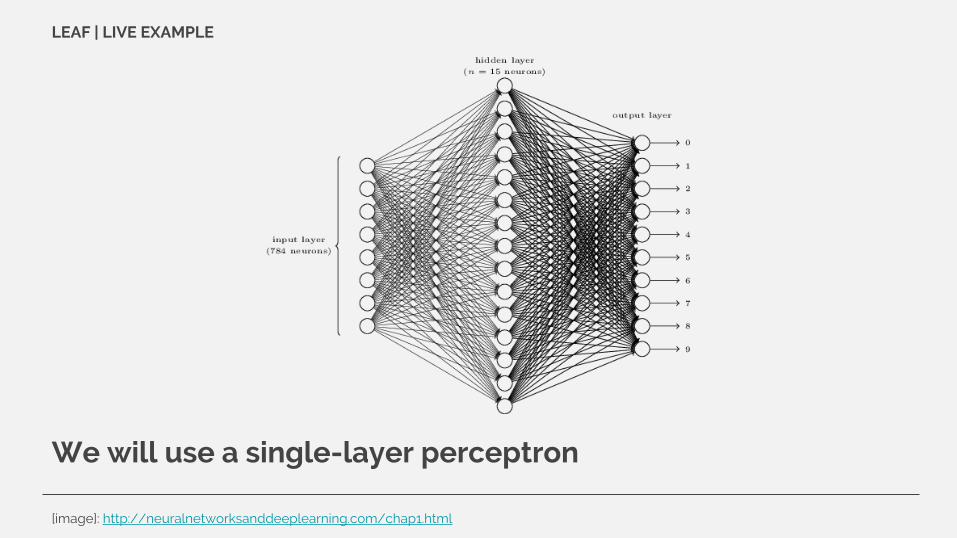
We will use a single-layer perceptron
LEAF | LIVE EXAMPLE
[image]: http://neuralnetworksanddeeplearning.com/chap1.html

RUST MACHINE LEARNING
IRC: #rust-machine-learning on irc.mozilla.org
TWITTER: @autumn_enghttp://autumnai.com

















