64
Managing Ambiguity, Gaps, and Errors in Spoken Language Processing Gina-Anne Levow May 14, 2009
| Date post: | 03-Jan-2016 |
| Category: |
Documents |
| Upload: | erik-sutton |
| View: | 220 times |
| Download: | 0 times |

Managing Ambiguity, Gaps, and Errors in Spoken Language Processing
Gina-Anne LevowMay 14, 2009

Research Background & Interests
Dialogue Spoken and Multimodal Dialogue Systems
Recognizing spoken corrections (Levow 98,99,01,04) Predicting turn-taking behavior (Levow 05)
Recognizing prominence and tone (Levow 05,06,08,WL07,DL08)
Topic and story segmentation (Levow 04+, Matveeva&Levow 07)
Prosodic and lexical evidence Search and retrieval (Meng et al 01, Levow 03,07,Levow et al 05)
Focus on speech, cross-language News, conversation/interview data

Roadmap Motivation Tone and Pitch Accent
Challenges: Contextual variation & Training demands Data collections and processing Modeling Context for Tone and Pitch Accent
Aside: Novel features Reducing Training Demands: Semi- and Un-supervised
Learning Cross-language Spoken Document Retrieval
Challenges: Ambiguity, Gaps, and Errors Retrieval setting Multi-scale processing:
Phrases to subwords: translation, indexing, and expansion Conclusion

Challenges Growing opportunities for speech applications
Explosive growth in audio data Ubiquitous mobile devices
Systems rely on supporting resources and technologies
May be limited Labeled training data for task, linguistic resources
Or noisy Speech recognition, machine translation
Successful systems must remain effective Employ techniques to mitigate the impact of
ambiguity, gaps, and errors

Challenges: Context Tone and Pitch Accent Recognition
Key component of language understanding Lexical tone carries word meaning Pitch accent carries semantic, pragmatic, discourse
meaning Non-canonical form (Shen 90, Shih 00, Xu 01)
Tonal coarticulation modifies surface realization In extreme cases, fall becomes rise
Tone is relative To speaker range
High for male may be low for female To phrase range, other tones
E.g. downstep

Challenges: Training Demands
Tone and pitch accent recognition Exploit data intensive machine learning
SVMs (Thubthong 01,Levow 05, SLX05) Boosted and Bagged Decision trees (X. Sun, 02) HMMs: (Wang & Seneff 00, Zhou et al 04, Hasegawa-
Johnson et al, 04,… Can achieve good results with huge sample sets
SLX05: ~10K lab syllabic samples -> > 90% accuracy Training data expensive to acquire
Time – pitch accent 10s of times real-time Money – requires skilled labelers Limits investigation across domains, styles, etc
Human language acquisition doesn’t use labels

Strategy: Overall Common model across languages
Common machine learning classifiers
Acoustic-prosodic model No word label, POS, lexical stress info No explicit tone label sequence model
English, Mandarin Chinese (also isiZulu, Cantonese)

Strategy: Context Exploit contextual information
Features from adjacent syllables Height, shape: direct, relative
Compensate for phrase contour
Analyze impact of Context position, context encoding Up to 24% reduction in error over no context

English Data Collection Boston University Radio News Corpus
(Ostendorf et al, 95)
Manually ToBI annotated, aligned, syllabified
Pitch accent aligned to syllables Unaccented, High, Downstepped High, Low
(Sun 02, Ross & Ostendorf 95) Unaccented vs Accented

Mandarin Data Collections Lab speech data: (Xu, 1999)
5 syllable utterances: vary tone, focus position In-focus, pre-focus, post-focus
TDT2 Voice of America Mandarin Broadcast News
Automatically force aligned to anchor scripts Automatically segmented, pinyin pronunciation lexicon Manually constructed pinyin-ARPABET mapping CU Sonic – language porting
High, Mid-rising, Low, High falling (,Neutral)

Local Feature Extraction Uniform representation for tone, pitch accent
Motivated by Pitch Target Approximation Model Tone/pitch accent target exponentially approached
Linear target: height, slope (Xu et al, 99) Base features:
Pitch, Intensity max, mean, min, range (Praat, speaker normalized)
Pitch at 5 points across voiced region Duration Initial, final in phrase
Slope: Linear fit to last half of pitch contour

Context Features Local context:
Extended features Adjacent points of preceding, following syllables
Difference features Difference between
Pitch max, mean, mid, slope Intensity max, mean
Of preceding, following and current syllable Phrasal context:
Compute collection average phrase slope Compute scalar pitch values, adjusted for slope

Supervised Classification Classifier: Support Vector Machine
Linear kernel Multiclass formulation
SVMlight (Joachims), LibSVM (Cheng & Lin 01) 4:1 training / test splits
Experiments: Effects of Context position: preceding, following,
none, both Context encoding: Extended/Difference
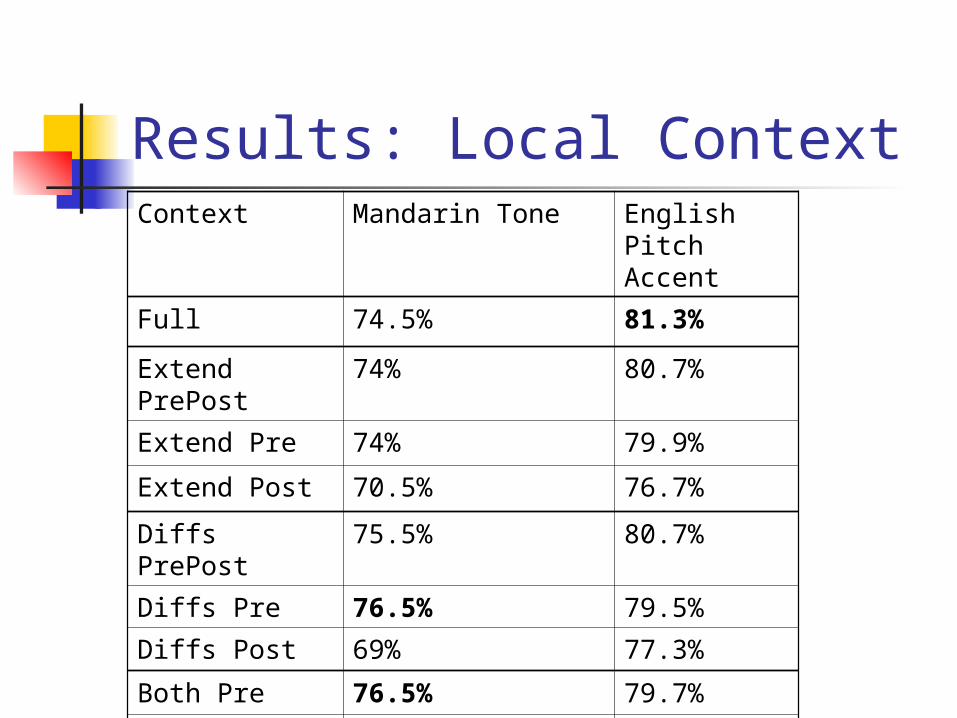
Results: Local ContextContext Mandarin Tone English
Pitch Accent
Full 74.5% 81.3%
Extend PrePost
74% 80.7%
Extend Pre 74% 79.9%
Extend Post 70.5% 76.7%
Diffs PrePost 75.5% 80.7%
Diffs Pre 76.5% 79.5%
Diffs Post 69% 77.3%
Both Pre 76.5% 79.7%
Both Post 71.5% 77.6%
No context 68.5% 75.9%

Results: Local ContextContext Mandarin Tone English
Pitch Accent
Full 74.5% 81.3%
Extend PrePost
74% 80.7%
Extend Pre 74% 79.9%
Extend Post 70.5% 76.7%
Diffs PrePost 75.5% 80.7%
Diffs Pre 76.5% 79.5%
Diffs Post 69% 77.3%
Both Pre 76.5% 79.7%
Both Post 71.5% 77.6%
No context 68.5% 75.9%

Results: Local ContextContext Mandarin Tone English
Pitch Accent
Full 74.5% 81.3%
Extend PrePost
74% 80.7%
Extend Pre 74% 79.9%
Extend Post 70.5% 76.7%
Diffs PrePost 75.5% 80.7%
Diffs Pre 76.5% 79.5%
Diffs Post 69% 77.3%
Both Pre 76.5% 79.7%
Both Post 71.5% 77.6%
No context 68.5% 75.9%

Context: Summary Employ common acoustic representation
Tone (Mandarin), pitch accent (English) SVM classifiers - linear kernel: 76%, 81% Local context effects:
Up to > 20% relative reduction in error Preceding context greatest contribution
Carryover vs anticipatory Consistent with phonetic analysis (Xu) that carryover
coarticulation is greater than anticipatory

Aside: Voice Quality & Energy
w/ Dinoj Surendran
Assess local voice quality and energy features for tone Not typically associated with tones: Mandarin
Considered: VQ: NAQ, AQ, etc; Spectral balance; Spectral
Tilt; Band energy Useful: Band energy significantly improves
Mandarin: neutral tone Supports identification of unstressed syllables
Spectral balance predicts stress in Dutch

Roadmap Motivation Tone and Pitch Accent
Challenges: Contextual variation & Training demands Data collections and processing Modeling Context for Tone and Pitch Accent
Aside: Novel features Reducing Training Demands: Semi- and Un-
supervised Learning Cross-language Spoken Document Retrieval
Challenges: Ambiguity, Gaps, and Errors Retrieval setting Multi-scale processing:
Phrases to subwords: translation, indexing, and expansion Conclusion

Strategy: Training Challenge:
Can we use the underlying acoustic structure of the language – through unlabeled examples – to reduce the need for expensive labeled training data?
Exploit semi-supervised and unsupervised learning Semi-supervised Laplacian SVM K-means and spectral clustering Substantially outperform baselines
Can approach supervised levels

Semi-supervised Learning Approach:
Employ small amount of labeled data Exploit information from additional –
presumably more available –unlabeled data Few prior exampes: self-training: Ostendorf TR
Classifier: Laplacian SVM (Sindhwani,Belkin&Niyogi ’05) Semi-supervised variant of SVM
Exploits unlabeled examples RBF kernel, typically 6 nearest neighbors, transductive

Experiments Pitch accent recognition:
Binary classification: Unaccented/Accented 1000 instances, proportionally sampled
Labeled training: 200 unacc, 100 acc 80% accuracy (cf. 84% w/15x labeled SVM)
Mandarin tone recognition: 4-way classification: n(n-1)/2 binary classifiers 400 instances: balanced; 160 labeled
Clean lab speech- in-focus-94% cf. 99% w/SVM, 1000s train; 85% w/SVM 160 training
samples Broadcast news: 70%
Cf. < 50% w/SVM 160 training samples

Pitch Accent Learning Curves

Unsupervised Learning Question:
Can we identify the tone structure of a language from the acoustic space without training?
Analogous to language acquisition Significant recent research in unsupervised
clustering Established approaches: k-means Spectral clustering (Shi & Malik ‘97, Fischer & Poland
2004): asymmetric k-lines Little research for tone
Self-organizing maps (Gauthier et al,2005) Tones identified in lab speech using f0 velocities
Cluster-based bootstrapping (Narayanan et al, 2006)

Pitch Accent Clustering Clustering alternatives:
3 Spectral approaches: Perform spectral decomposition of affinity matrix
Asymmetric k-lines (Fischer & Poland 2004) Symmetric k-lines (Fischer & Poland 2004) Laplacian Eigenmaps (Belkin, Niyogi, & Sindhwani 2004) Binary weights, k-lines clustering
K-means: Standard Euclidean distance # of clusters: 2-16
Assign most frequent class label to each cluster 4 way distinction: 1000 samples, proportional
Best results: > 78% 2 clusters: asymmetric k-lines; > 2 clusters: kmeans
Larger # clusters: all similar

Contrasting Learners

Tone Clustering: I Mandarin four tones:
400 samples: balanced 2-phase clustering: 2-5 clusters each Asymmetric k-lines, k-means clustering
Clean read speech: In-focus syllables: 87% (cf. 99% supervised) In-focus and pre-focus: 77% (cf. 93% supervised)
Broadcast news: 57% (cf. 74% supervised) K-means requires more clusters to reach k-lines level

Tone Structure
First phase of clustering splits high/rising from low/falling by slopeSecond phase by pitch height

Discussion Common prosodic framework for tone
and pitch accent recognition
Contextual modeling enhances recognition Local context and broad phrase contour
Carryover coarticulation has larger effect for Mandarin Exploiting unlabeled examples for recognition
Semi- and Un-supervised approaches Best cases approach supervised levels with less training Exploits acoustic structure of tone and accent space

Roadmap Motivation Tone and Pitch Accent
Challenges: Contextual variation & Training demands Data collections and processing Modeling Context for Tone and Pitch Accent
Aside: Novel features Reducing Training Demands: Semi- and Un-supervised
Learning Cross-language Spoken Document Retrieval
Challenges: Ambiguity, Gaps, and Errors Retrieval setting Multi-scale processing:
Phrases to subwords: translation, indexing, and expansion Conclusion

Cross-language Spoken Document Retrieval
Explosive growth in online audio Increasing proportion non-English, esp. Chinese
Challenges: Ambiguity: many translations, acoustic confusion Gaps: OOV in recognition, translation (esp. NE) Errors: Misrecognition, mistranslation, misseg.
Solution I: subword units may help Transliteration, subword recognition, matching
Solution II: expansion may help Clean side collections provide terms

The Answer: A Preview Perform word-based speech recognition
Lexicon constraints greatly improve accuracy Perform phrase-based query translation
Minimizes translation ambiguity Convert both to character bigrams and match
Elegantly handles ambiguous term granularity Add evidence from proper name matching
Using syllable bigrams Perform document expansion to enhance
match

CL-SDR Architecture
DocumentExpansion
MandarinRetrievalSystem
MandarinTranscription
ComparableMandarin
Documents
BalancedGloss
Translation With
Stemming Backoff,χ2 Feature Selection
Inquery 3.1p1
Ranked list
VOAMandarinBroadcast
Audio:2265 stories
NYTEnglish
NewswireExemplars
Speech Recognition
Exhaustive RelevanceJudgments
Evaluation
17Topics
mAP
(Beginning from and building on the MEI project, Meng et al 01)

CL-SDR Architecture
DocumentExpansion
MandarinRetrievalSystem
MandarinTranscription
ComparableMandarin
Documents
BalancedGloss
Translation With
Stemming Backoff,χ2 Feature Selection
Inquery 3.1p1
Ranked list
VOAMandarinBroadcast
Audio:2265 stories
NYTEnglish
NewswireExemplars
Speech Recognition
Exhaustive RelevanceJudgments
Evaluation
17Topics
mAPMulti-scale points

Document Expansion
ComparableDocuments
RetrievalSystem
RankedDocument
ListTerm
Selection
ExpandedDocuments
Original Documents
DocumentsRetrievalSystem
(Singhal ’99)

Translation Granularity Ambiguity:
[[Human]7 [Rights] 30] 1
Phrases beat words
Three sources Translation lexicon Named entities Numeric expressions
Mean A
vera
ge P
reci
sion

Multi-scale Indexing and Expansion
Goal: Allow partial match,
minimize ambiguity Word segmentation:
Noisy, errorful in Mandarin text, speech
Single characters: ambiguous Overlapping char. bigrams:
Partial match, semantic units
Retrieval best w/character bigrams
Also outperform syllables Words improve expansion term
choice
Mean A
vera
ge P
reci
sion

Transliteration: Subword Translation
Untranslatable names Create cross-language
phonetic map Train transformation-based
error-driven learning on name translations
Produce 1-best syllables
Combine with standard term translation
Small, consistent improvement
Mean A
vera
ge P
reci
sion

Pre- and Post-translation Document Expansion
DocumentExpansion
EnglishRetrievalSystem
MandarinTranscription
ComparableMandarin
Documents
BalancedGloss
Translation
Inquery 3.1p1
Ranked list
VOAMandarinBroadcast
Audio:2265 stories
NYTEnglish
NewswireExemplars
Speech Recognition
Exhaustive RelevanceJudgments
Evaluation
17Topics
mAP
DocumentExpansion
ComparableEnglish
Documents

Bridging Gaps with Document Expansion
Prior work on query expansion (European)
Pre-translation most important – need terms
Pre-translation: Compensate for ASR errors,
more translatable Post-translation:
Recover trans./ASR gaps, errors, enrichment
Post improves significantly Outperforms mono, manual Recovers (trans.) OOV
Example terms: Tariq Aziz, Boris Yeltsin, etc
Less problematic in other lang.
Mean A
vera
ge P
reci
sion

Discussion Multi-scale processing enables:
Matching at highest level of precision to reduce ambiguity
Partial matching to enable robustness to gaps and errors
In conjunction with document expansion, Can outperform retrieval on monolingual,
manually transcriptions

Future Challenges SDR:
Good effectiveness shown for clean BN speech Conversational speech: more challenging
Higher WER will emphasize partial matching Systematic, statistically valid integration of:
ASR word/subword hypotheses at multiple scales Alternate retrieval models
CL-SDR: Integrate approaches that better model uncertainty
and ambiguity in translation

Future Challenges & Opportunities
Prominence and Tone Identify prominence and emphasis to improve
spoken language understanding Integrate with speech recognition
Rerank candidates Enhance unit selection for contextually
appropriate prosody Dialogue and intonation
Predicting and managing turn-taking Utterance classification Handling miscommunication

Thanks Dinoj Surendran, Siwei Wang, Yi Xu V. Sindhwani, M. Belkin, & P. Niyogi; I. Fischer
& J. Poland; T. Joachims; C-C. Cheng & C. Lin This work supported by NSF Grant #0414919 http://people.cs.uchicago.edu/~levow/tai
MEI Team: Helen Meng, Sanjeev Khudanpur, Hsin-min Wang, Wai-Kit Lo, Doug Oard, et al.

Results & Discussion: Phrasal Context
Phrase Context
Mandarin Tone
English Pitch Accent
Phrase 75.5% 81.3%
No Phrase 72% 79.9%
•Phrase contour compensation enhances recognition•Simple strategy•Use of non-linear slope compensate may improve

Aside: More Tones Cantonese:
CUSENT corpus of read broadcast news text Same feature extraction & representation 6 tones:
High level, high rise, mid level, low fall, low rise, low level
SVM classification: Linear kernel: 64%, Gaussian kernel: 68%
3,6: 50% - mutually indistinguishable (50% pairwise) Human levels: no context: 50%; context: 68%
Augment with syllable phone sequence 86% accuracy: 90% of syllable w/tone 3 or 6: one
dominates

Results: Local ContextContext Mandarin
ToneEnglish Pitch Accent
IsiZulu Tone
Full 74.5% 81.3% 76.2%
Extend PrePost
74% 80.7% 74.7%
Extend Pre 74% 79.9% 75.3%
Extend Post
70.5% 76.7% 74.6%
Diffs PrePost
75.5% 80.7% 76.2%
Diffs Pre 76.5% 79.5% 76.5%
Diffs Post 69% 77.3% 74.6%
Both Pre 76.5% 79.7% 76.5%
Both Post 71.5% 77.6% 74.8%
No context 68.5% 75.9% 74.1%

Results: Local ContextContext Mandarin
ToneEnglish Pitch Accent
IsiZulu Tone
Full 74.5% 81.3% 76.2%
Extend PrePost
74% 80.7% 74.7%
Extend Pre 74% 79.9% 75.3%
Extend Post
70.5% 76.7% 74.6%
Diffs PrePost
75.5% 80.7% 76.2%
Diffs Pre 76.5% 79.5% 76.5%
Diffs Post 69% 77.3% 74.6%
Both Pre 76.5% 79.7% 76.5%
Both Post 71.5% 77.6% 74.8%
No context
68.5% 75.9% 74.1%

Results: Local ContextContext Mandarin
ToneEnglish Pitch Accent
IsiZulu Tone
Full 74.5% 81.3% 76.2%
Extend PrePost
74% 80.7% 74.7%
Extend Pre
74% 79.9% 75.3%
Extend Post
70.5% 76.7% 74.6%
Diffs PrePost
75.5% 80.7% 76.2%
Diffs Pre 76.5% 79.5% 76.5%
Diffs Post 69% 77.3% 74.6%
Both Pre 76.5% 79.7% 76.5%
Both Post 71.5% 77.6% 74.8%
No context 68.5% 75.9% 74.1%

Confusion Matrix (English)
Recognized Tone
Manually Labeled Tone
Unaccented
High Low D.S. High
Unaccented 95%
25% 100%
53.5%
High 4.6%
73% 0% 38.5%
Low 0% 0% 0% 0%
D.S. High 0.3% 2% 0% 8%

Confusion Matrix (Mandarin)
Recognized Tone
Manually Labeled Tone
High Mid-Rising
Low High-Falling | Neutral
High 84% 9%
5%
13% | 0% |
Mid-Rising 6.7%
78.6%
10%
7% | 27.3% |
Low 0% 3.6% 70% 7% | 27.3%
High-Falling
7.4% 3.6% 10%
70% | 0% |
Neutral 0% 5.3% 5% 1.5% | 45%

Related Work Tonal coarticulation:
Xu & Sun,02; Xu 97;Shih & Kochanski 00 English pitch accent
X. Sun, 02; Hasegawa-Johnson et al, 04; Ross & Ostendorf 95
Lexical tone recognition SVM recognition of Thai tone: Thubthong
01 Context-dependent tone models
Wang & Seneff 00, Zhou et al 04

Pitch Target Approximation Model
Pitch target: Linear model:
Exponentially approximated:
In practice, assume target well-approximated by mid-point (Sun, 02)
battT )(
battty )exp()(

“Bounds” on Subword-Based Systems
Character bigrams for indexing
marginally outperforms word-based systems
Syllable bigrams are quite competitive,
though somewhat behind
Mean average precision ~0.6 is a good CL-SDR target

Cross-Language SDR Challenges
Query processing (translation) Tokenization Translation lexicon coverage Selection among alternate translations
Document processing (recognition) Tokenization Recognition lexicon coverage Selection among alternate recognition
hypotheses

Laplacian SVM For SVMs, we solve
Assume if samples close in intrinsic geometry, then conditionals P(y|x1) P(y|x2) are similar.
Add new regularizer, to control complexity in intrinsic geometry, as well as ambient.
For Laplacian SVM, solve Support of Px on compact submanifold

Manifold Regularization

Spectral clustering Employs spectrum of similarity
matrix S to perform dimensionality reduction for clustering Meila-Shi clusters based on eigenvectors
correspondings to k largest eigenvalues Laplacian eigenmaps:
Create edges for k nearest neighbors Choose weights: binary or heat kernel Compute eigenv’s for Ly = lambda Dy Represent by e-vectors of m smallest e-
values Preserves distances for near neighbors

K-lines
Given vectors y (spectral) Randomly generate vectors m
(or set to eigenvectors of y) Create matrices of all vectors y
closest to each mi mj = first eigenv of MjMjT Iterate

Asymmetric clustering
Clusterable data not just Gaussian New affinity measure: conductivity Question: Kernel radius?
Often just pick best Here, select automatically, context
dependent Also, asymmetric, e.g. if dense region, other
further Symmetric – take minimum

K-means clustering
Select k= number of clusters Randomly choose k points as cluster
centers A) Assign points to nearest cluster B) Recompute cluster centers Repeat A,B until convergence + Fast, large data sets - Random initial assignments

Sequence and Factorial Models: I

Sequence and Factorial Models
Compare 0-order, 1-order
Compare linear-chain vs factorial

Query byExample
EnglishNewswireExemplars
MandarinAudioStories
President Bill Clinton and Chinese President Jiang Zemin engaged in a spirited, televised debate Saturday over human rights and theTiananmen Square crackdown, and announced a string of agreements on arms control, energy and environmental matters. There were no announced breakthroughs on American human rights concerns, including Tibet, but both leaders accentuated the positive …
美国总统克林顿的助手赞扬中国官员允许电视现场直播克林顿和江泽民在首脑会晤后举行的联合记者招待会。。特别是一九八九镇压民主运动的决定。他表示镇压天安门民主运动是错误的 , 他还批评了中国对西藏精神领袖达 国家安全事务助理伯格表示 , 这次直播让中国人第一次在种公开的论坛上听到围绕敏感的人权问题的讨论。在记者招待会上 …
















