37
Managing Large Data, BI Tools and the Future of Big Data Steve Geddes Applications Manager Georgia Department of Audits
| Date post: | 24-Dec-2015 |
| Category: |
Documents |
| Upload: | gwenda-isabella-richardson |
| View: | 214 times |
| Download: | 0 times |

Managing Large Data, BI Tools and the Future of Big Data
Steve GeddesApplications ManagerGeorgia Department of Audits

Ask not for Forgiveness but for all the Data Too much red tape Stall tactics We might miss something

Entity Scare tactics Data is too Big Confidential Data Loss of Knowledge about the system Incur additional costs Data may be housed with third party Database does not support extracts Specialized program to extract data Etc….

Can I Manage this Data ? Size… What is too big ? Get true estimations from a DBA Zip or Compress Data Securing Data (especially Confidential
Fields) Difficulty in Transmitting Large Data SQL Knowledge

Data dictionary and/or Entity Relation Diagram (ER) Table description or create sql for each table. Field definitions – date, text, number
What is the underlying Database Data dump if same DB engine
What export formats do you support (CSV, fix length) We prefer CSV with double delimited ||
Row counts for each table for quality assurance Ask the Entity to Identify confidential fields within the
data
Prepare yourself for data

Sample ER Diagram

Additional Concerns Issues with character conversion from memo
fields, and other bad data Typically seen in mainframe environments Encoding issues , line feeds or returns Conversion on time stamps / dates
Loading the data in a timely process Space Requirements Securing the Data Retention of Data

Now that I have all this data… How do I work with it ? Excel ? Notepad? (not going to cut it) MS Access has a limit of 2 gig Power pivot (plug in for Excel)…Maybe

Get a Free Database Engine
PostgreSQL MySQL Cassandra Oracle Express Etc..

The Quick Steps Download Database Engine Create new user , do not use default owner Create new database for this project Create new schema (name for a project)
Think of retention , project tracking info like number or id
Create table from definition Import data tables into new table Check control numbers for match (row counts
and/or totals)

Check Data Quality
A great tool for quality checking is: Talend Open Studio for Data
Quality Create a database connection Or load a text file (txt, csv, etc) Browse to the table or file you want to
analyze Select the indicators by column type


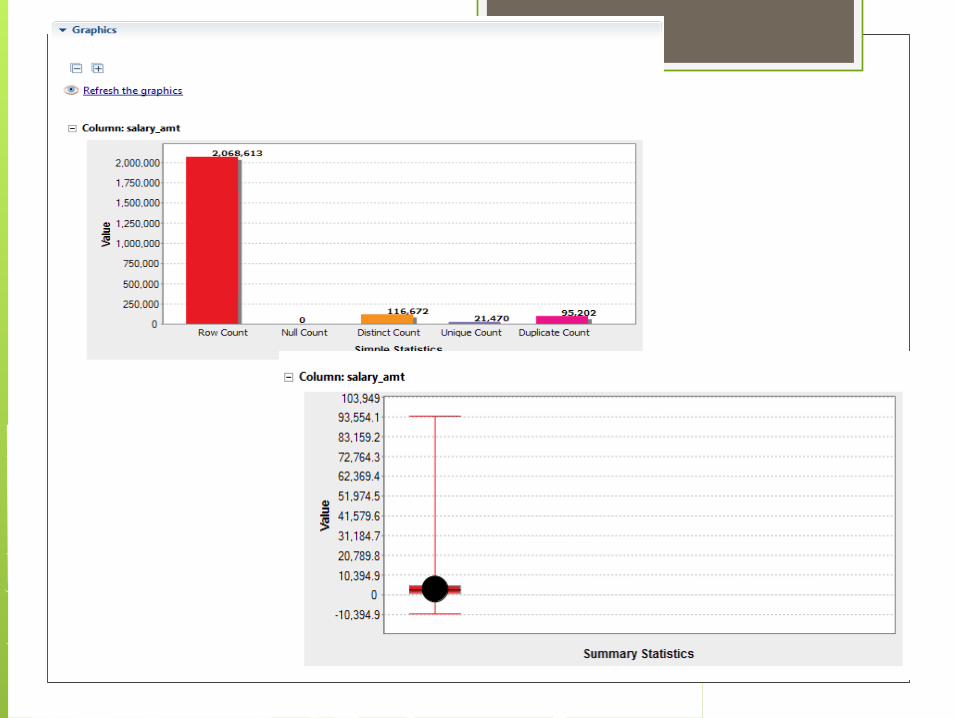

Ready to Query using Structure Query Language (SQL)
Most free tools support a graphical Query Builder functionality
Basic Select Select (What fields) From (Which tables) Where (conditions)
Joins Inner join Outer join
Functions Avg Sum Max Min Etc…

Traditional BI Solutions Web enabled Subscribe/schedule reports Run off a Datamart or warehouse to
reduce over head on active OLTP systems
Integrate with existing portals / share point interfaces
Supports many styles and types of reporting

BI – What is ETL ?
Used for reoccurring processes , cron jobs , scripts ETL – Extract, transform, load tools Tools
CloverETL Community Edition - http://www.cloveretl.com/products/community-edition
Jaspersoft ETL - talend

BI - Welcome to the Third Dimension
OLAP – (On-Line Analytical Processing) ROLAP - Relational On-line Analytical
Processing (driven from a database) MOLAP - Multidimensional On-line
Analytical Processing. (preprocessed data in memory)

Cube The collection of dimensions, hierarchies and
measures. Fact table
consists of the measurements, metrics or facts of a business process. It is located at the center of a star schema or a snowflake schema surrounded by dimension tables.
Dimensions a data element that categorizes each item in a data
set into non-overlapping regions. A data warehouse dimension provides the means to "slice and dice" data. Dimensions provide structured labeling information to otherwise unordered numeric measures.
Cubes – Think of a Rubik’s Cube

The MultiDimensional eXpressions (MDX) language provides a specialized syntax for querying and manipulating the multidimensional data
Once you have your cube defined you then can create an MDX query to get started. This query then is uploaded to a BI tool so users
can start looking at the data
Working with Cubes

JasperSoft BI Reporting Tool

Drill down capabilities (web based)


Swap Axes

User driven settings

Export options for Reports Excel PDF Charts + data Save to file

The Future is Big Data, really… BIG
90% of the data in the world today has been created in the last two years alone
According to analysts, about 80% of the data in the world is unstructured
Its large , complex, and unstructured

Terabyte: A Terabyte (TB) is approximately one trillion bytes, or 1,000 Gigabytes. A Terabyte could hold 1,000 copies of the Encyclopedia Britannica. Ten Terabytes could hold the printed collection of the Library of Congress.
Petabyte: A Petabyte (PB) is approximately 1,000 Terabytes or one million Gigabytes. 1 Petabyte could hold approximately 20 million 4-door filing cabinets full of text. It could hold 500 billion pages of standard printed text. It would take about 500 million floppy disks to store the same amount of data.
Exabyte: An Exabyte (EB) is approximately 1,000 Petabytes. Another way to look at it is that an Exabyte is approximately one quintillion bytes or one billion Gigabytes. There is not much to compare an Exabyte to. It has been said that 5 Exabytes would be equal to all of the words ever spoken by mankind.
Zettabyte - A Zettabyte (ZB), is approximately 1,000 Exabytes. There is nothing to compare a Zettabyte to but to say that it would take a whole lot of ones and zeroes to fill it up.
Bits, Bytes and Ouch my head hurts

235 Terabytes of data was collected by the U.S. Library of Congress in April 2011.
IDC Estimates that by 2020,business transactions on the internet- will reach 450 billion per day.
Facebook stores, accesses, and analyzes 30+ Petabytes of user generated data.
Walmart handles more than 1 million customer transactions every hour.
More than 5 billion people are calling, texting, tweeting and browsing on mobile phones worldwide
Big Data in Business

The Rapid Growth of Unstructured Data
YouTube users upload 48 hours of new video every minute of the day.
571 new websites are created every minute of the day. Brands and organizations on Facebook receive 34,722 Likes
every minute of the day. 100 terabytes of data are uploaded daily to Facebook. According to Twitter’s own research in early 2012, it sees
roughly 175 million tweets every day, and has more than 465 million accounts.
30 Billion pieces of content are shared on Facebook every month.
Data production will be 44 times greater in 2020 than it was in 2009.

What does all this Mean? The amount of data in the world today is
equal to: Every person in the US tweeting three
tweets per minute for 26,976 years. Every person in the world having more
than 215m high-resolution MRI scans a day.
More than 200 HD movies – which would take a person 47m years to watch.

Big Data & Real Business Issues
According to estimates, the volume of business data worldwide, across all companies, doubles every 1.2 years.
Poor data can cost businesses 20%–35% of their operating revenue.
Bad data or poor data quality costs US businesses $600 billion annually.
According to execs, the influx of data is putting a strain on IT infrastructure.

The future is here ……..
The ability to query and analyze really big unstructured data
No SQL Map Reduce Distributed cluster data processing
using the cloud private or public


The Apache Hadoop software library is a framework that allows for the distributed processing of large datasets across clusters of computers using simple programming models.
It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-avaiability.
Hadoop

Companion Tools on the Rise
Hive is a data warehouse system for Hadoop that facilitates easy data summarization, ad-hoc queries, and the analysis of large datasets stored in Hadoop.
Hive provides a mechanism to project structure onto this data and query the data using a SQL-like language called HiveQL.

Thanks

















