Map-Reduce Applications: Counting, Graph Shortest Paths Adapted from UMD Jimmy Lin’s slides, which is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States. See http://creativecommons.org/licenses/by-nc-sa/3.0/us/ for details
Transcript
Map-Reduce Applications:
Counting, Graph Shortest Paths
Adapted from UMD Jimmy Lin’s slides, which is licensed under a Creative
Commons Attribution-Noncommercial-Share Alike 3.0 United States. See
http://creativecommons.org/licenses/by-nc-sa/3.0/us/ for details
CS 4407 University College Cork,
Gregory M. Provan
Overview
MapReduce Introduction
Simple counting, averaging
Graph problems and representations
Parallel breadth-first search
CS 4407 University College Cork,
Gregory M. Provan
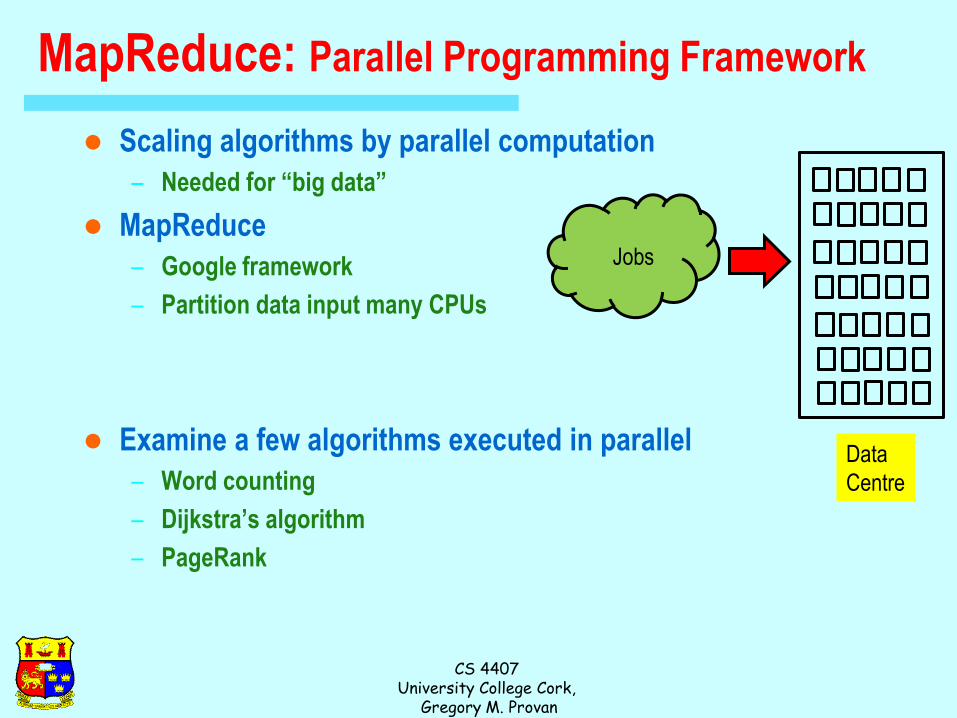
MapReduce: Parallel Programming Framework
Scaling algorithms by parallel computation
– Needed for “big data”
MapReduce
– Google framework
– Partition data input many CPUs
Examine a few algorithms executed in parallel
– Word counting
– Dijkstra’s algorithm
– PageRank
Jobs
Data
Centre
CS 4407 University College Cork,
Gregory M. Provan
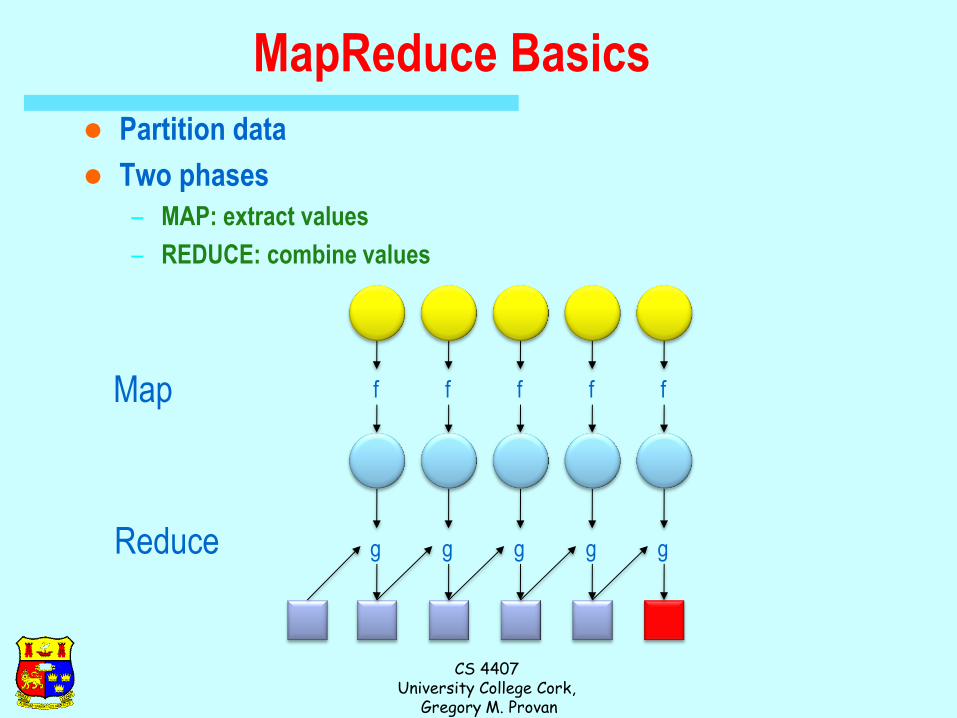
MapReduce Basics
Partition data
Two phases
– MAP: extract values
– REDUCE: combine values
g g g g g
f f f f f Map
Reduce
CS 4407 University College Cork,
Gregory M. Provan
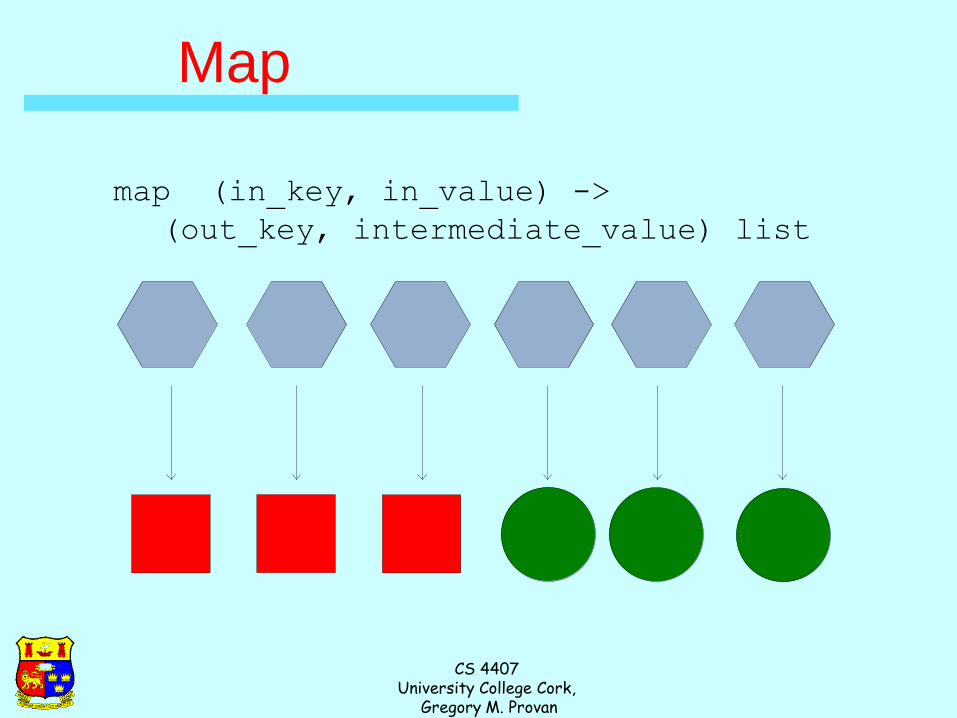
Map
Records from the data source (lines out of files, rows of a
database, etc) are fed into the map function as key*value
pairs: e.g., (filename, line).
map() produces one or more intermediate values along with
an output key from the input.
CS 4407 University College Cork,
Gregory M. Provan
map (in_key, in_value) ->
(out_key, intermediate_value) list
Map
CS 4407 University College Cork,
Gregory M. Provan
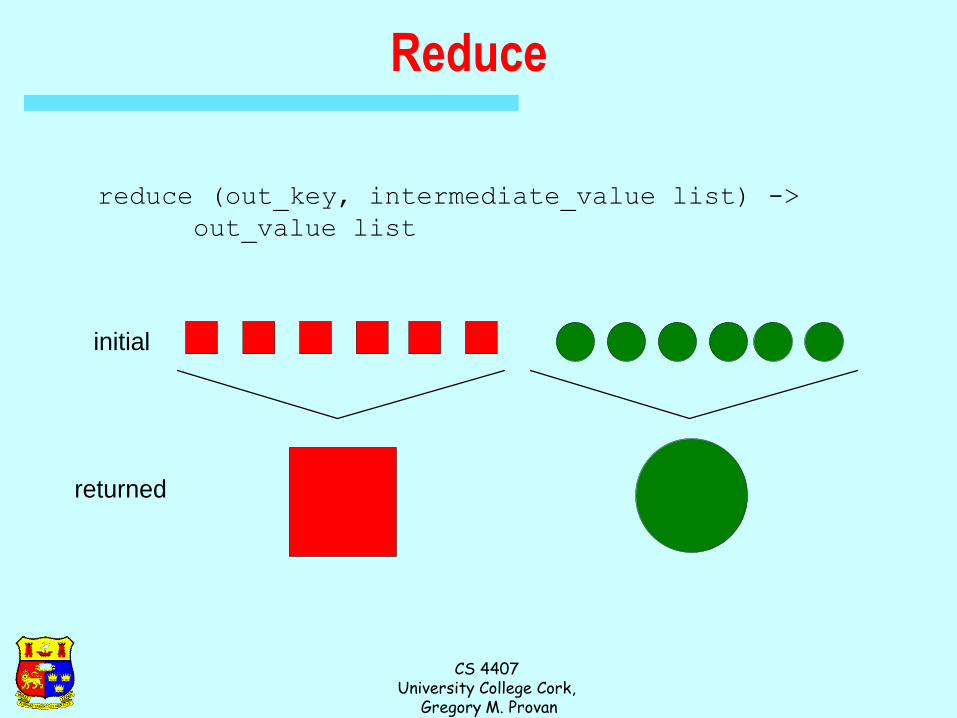
Reduce
After the map phase is over, all the intermediate values for a
given output key are combined together into a list
reduce() combines those intermediate values into one or
more final values for that same output key
(in practice, usually only one final value per key)
CS 4407 University College Cork,
Gregory M. Provan
Reduce
reduce (out_key, intermediate_value list) ->
out_value list
returned
initial
CS 4407 University College Cork,
Gregory M. Provan
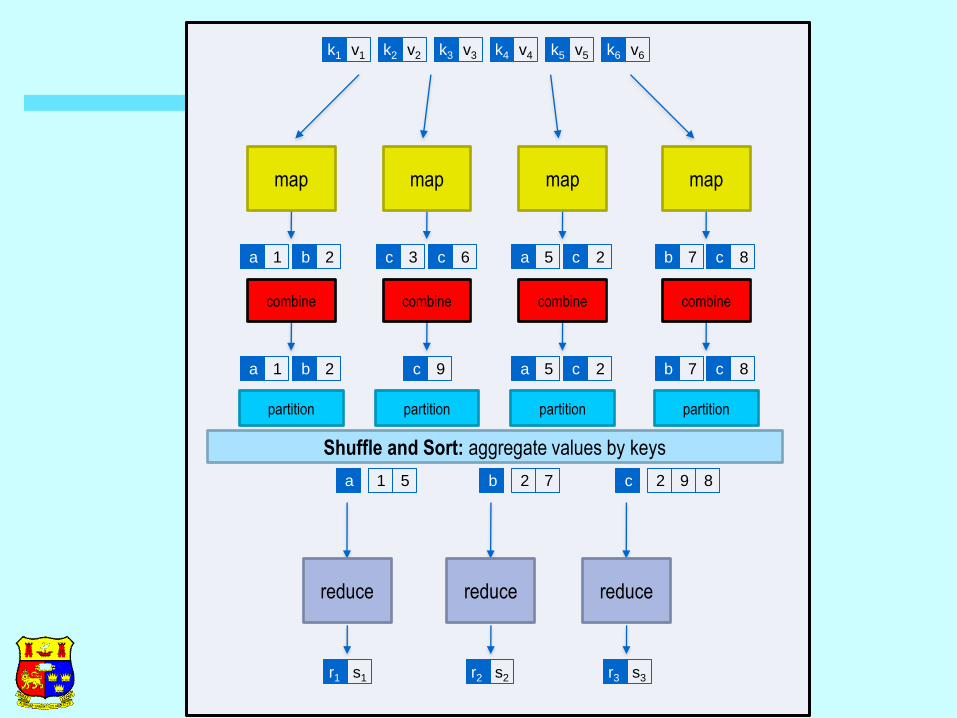
combine combine combine combine
b a 1 2 c 9 a c 5 2 b c 7 8
partition partition partition partition
map map map map
k1 k2 k3 k4 k5 k6 v1 v2 v3 v4 v5 v6
b a 1 2 c c 3 6 a c 5 2 b c 7 8
Shuffle and Sort: aggregate values by keys
reduce reduce reduce
a 1 5 b 2 7 c 2 9 8
r1 s1 r2 s2 r3 s3
CS 4407 University College Cork,
Gregory M. Provan
MapReduce: Overview
Programmers must specify: map (k, v) → <k’, v’>* reduce (k’, v’) → <k’, v’>* – All values with the same key are reduced together
Optionally, also: partition (k’, number of partitions) → partition for k’ – Often a simple hash of the key, e.g., hash(k’) mod n – Divides up key space for parallel reduce operations combine (k’, v’) → <k’, v’>* – Mini-reducers that run in memory after the map phase – Used as an optimization to reduce network traffic
The execution framework handles everything else…
CS 4407 University College Cork,
Gregory M. Provan
“Everything Else”
The execution framework handles everything else… – Scheduling: assigns workers to map and reduce tasks – “Data distribution”: moves processes to data – Synchronization: gathers, sorts, and shuffles intermediate
data – Errors and faults: detects worker failures and restarts
Limited control over data and execution flow – All algorithms must expressed in m, r, c, p
You don’t know: – Where mappers and reducers run – When a mapper or reducer begins or finishes – Which input a particular mapper is processing – Which intermediate key a particular reducer is processing
CS 4407 University College Cork,
Gregory M. Provan
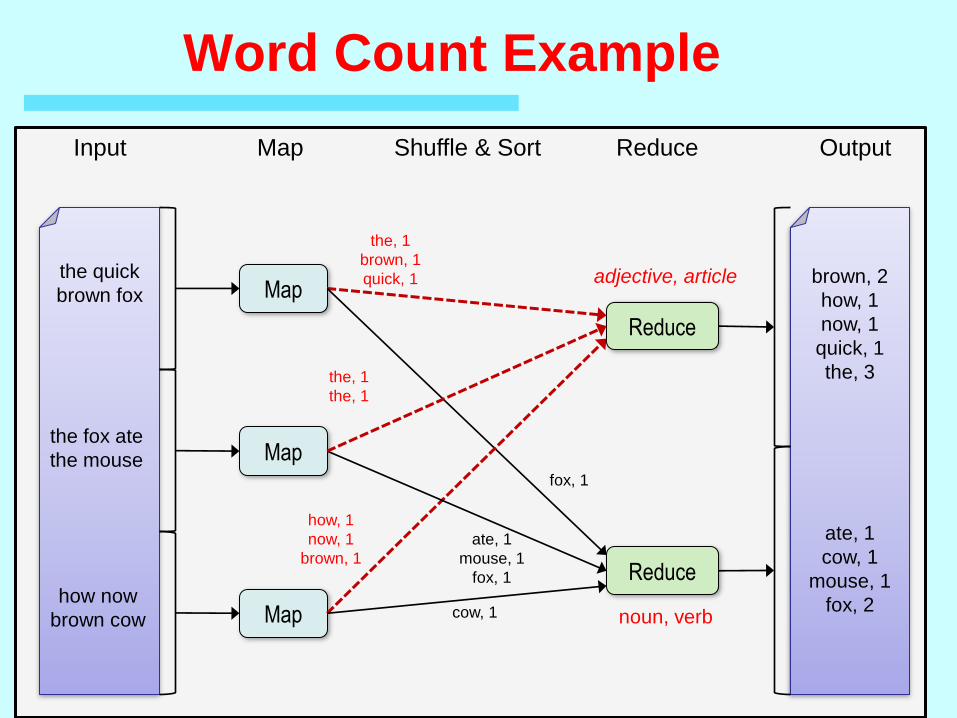
Word Count Example
the quick
brown fox
the fox ate
the mouse
how now
brown cow
Map
Map
Map
Reduce
Reduce
brown, 2
how, 1
now, 1
quick, 1
the, 3
ate, 1
cow, 1
mouse, 1
fox, 2
the, 1
brown, 1
quick, 1
fox, 1
the, 1
the, 1
how, 1
now, 1
brown, 1
ate, 1
mouse, 1
fox, 1
cow, 1
Input Map Shuffle & Sort Reduce Output
noun, verb
adjective, article
CS 4407 University College Cork,
Gregory M. Provan
Word Count: Baseline
What’s the impact of combiners?
CS 4407 University College Cork,
Gregory M. Provan
Word Count: Version 1
CS 4407 University College Cork,
Gregory M. Provan
Word Count: Version 2
CS 4407 University College Cork,
Gregory M. Provan
Design Pattern for Local Aggregation
“In-mapper combining”
– Fold the functionality of the combiner into the mapper by
preserving state across multiple map calls
Advantages
– Speed
– Faster than actual combiners
Disadvantages
– Explicit memory management required
– Potential for order-dependent bugs
CS 4407 University College Cork,
Gregory M. Provan
Combiner Design
Combiners and reducers share same method signature
– Sometimes, reducers can serve as combiners
– Often, not…
Remember: combiner are optional optimizations
– Should not affect algorithm correctness
– May be run 0, 1, or multiple times
Example: find average of all integers associated with the same key
CS 4407 University College Cork,
Gregory M. Provan
Computing the Mean: Version 1
CS 4407 University College Cork,
Gregory M. Provan
Single Source Shortest Path
Problem: find shortest path from a source node to one or
more target nodes
– Shortest might also mean lowest weight or cost
First, a refresher: Dijkstra’s Algorithm
CS 4407 University College Cork,
Gregory M. Provan
Pseudocode for Dijkstra
Initialize the cost of each vertex to
cost[s] = 0;
heap.insert(s);
While (! heap.empty()) n = heap.deleteMin()
For (each vertex a which is adjacent to n along edge e)
if (cost[n] + edge_cost[e] < cost[a]) then
cost [a] = cost[n] + edge_cost[e]
previous_on_path_to[a] = n;
if (a is in the heap) then heap.decreaseKey(a)
else heap.insert(a)
CS 4407 University College Cork,
Gregory M. Provan
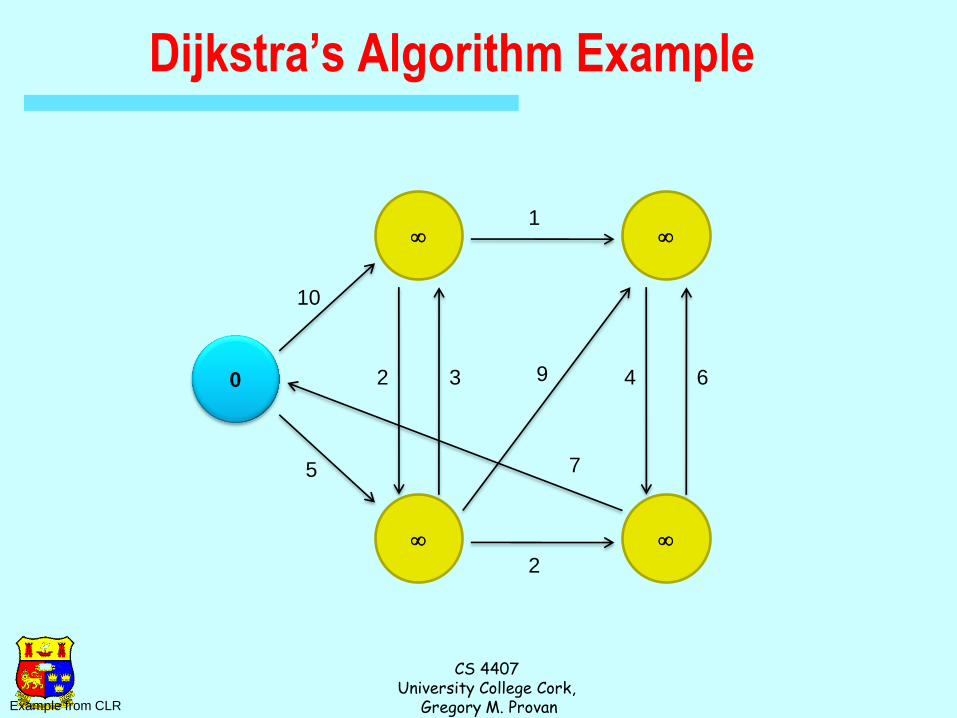
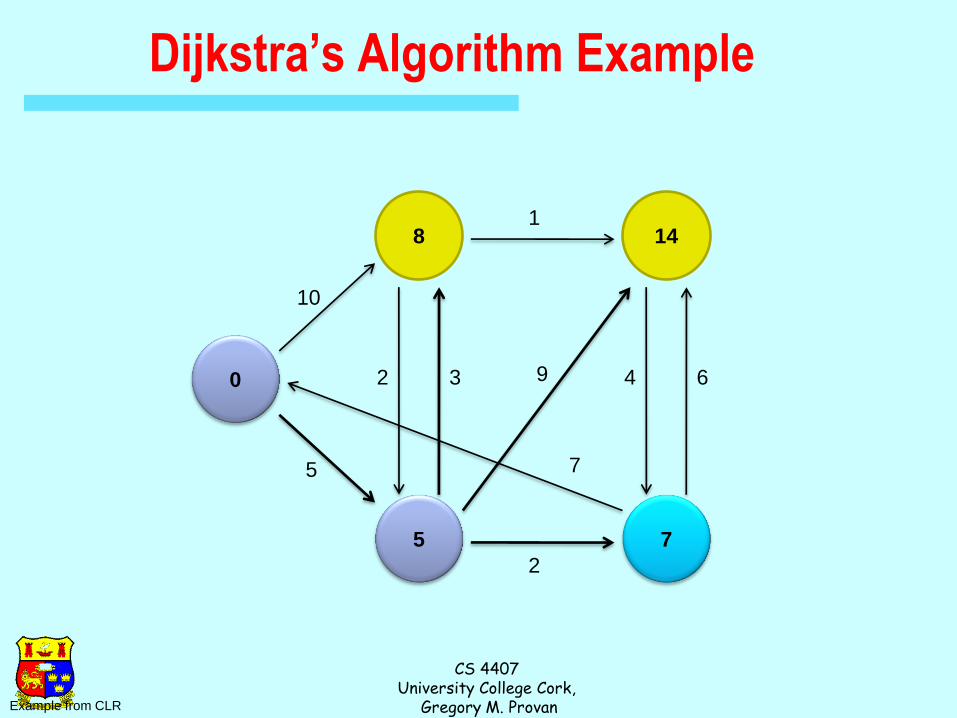
Dijkstra’s Algorithm Example
0
10
5
2 3
2
1
9
7
4 6
Example from CLR
CS 4407 University College Cork,
Gregory M. Provan
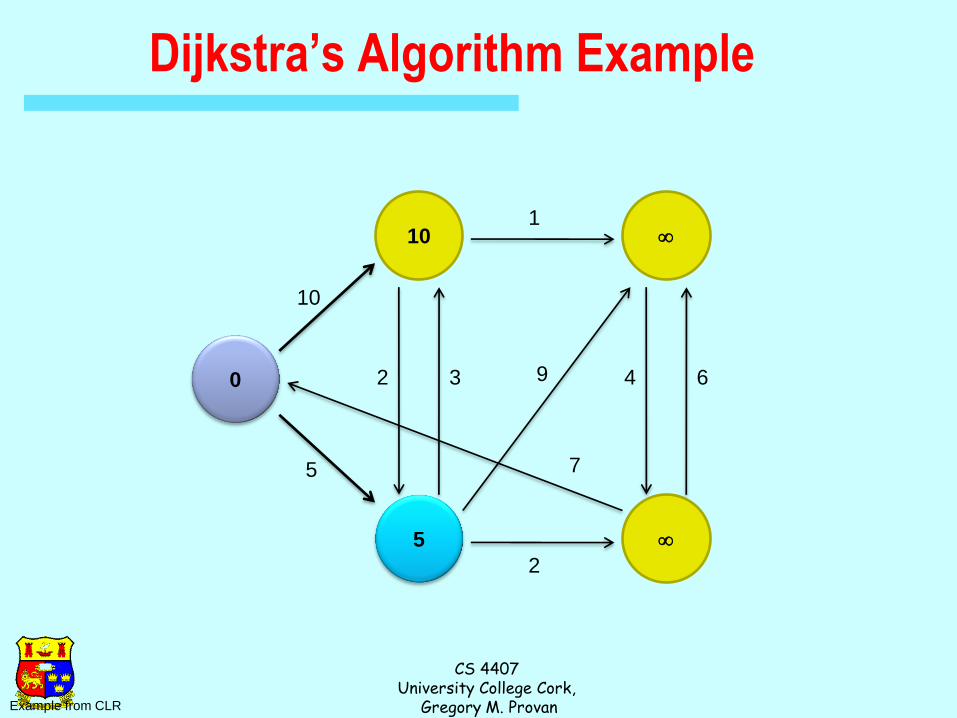
Dijkstra’s Algorithm Example
0
10
5
Example from CLR
10
5
2 3
2
1
9
7
4 6
CS 4407 University College Cork,
Gregory M. Provan
Dijkstra’s Algorithm Example
0
8
5
14
7
Example from CLR
10
5
2 3
2
1
9
7
4 6
CS 4407 University College Cork,
Gregory M. Provan
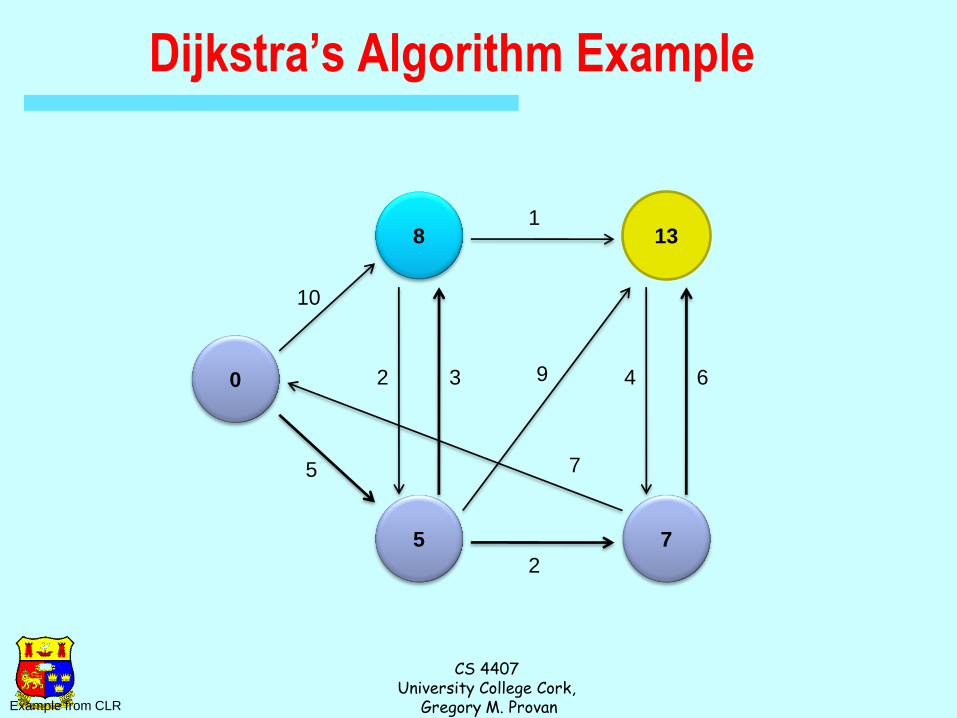
Dijkstra’s Algorithm Example
0
8
5
13
7
Example from CLR
10
5
2 3
2
1
9
7
4 6
CS 4407 University College Cork,
Gregory M. Provan
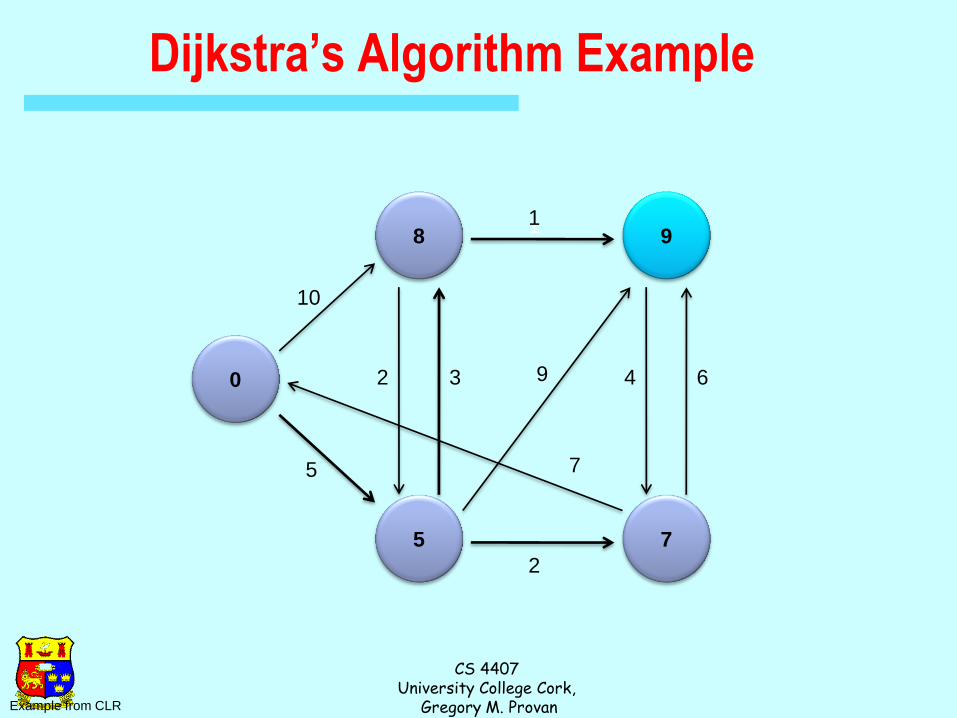
Dijkstra’s Algorithm Example
0
8
5
9
7
1
Example from CLR
10
5
2 3
2
1
9
7
4 6
CS 4407 University College Cork,
Gregory M. Provan
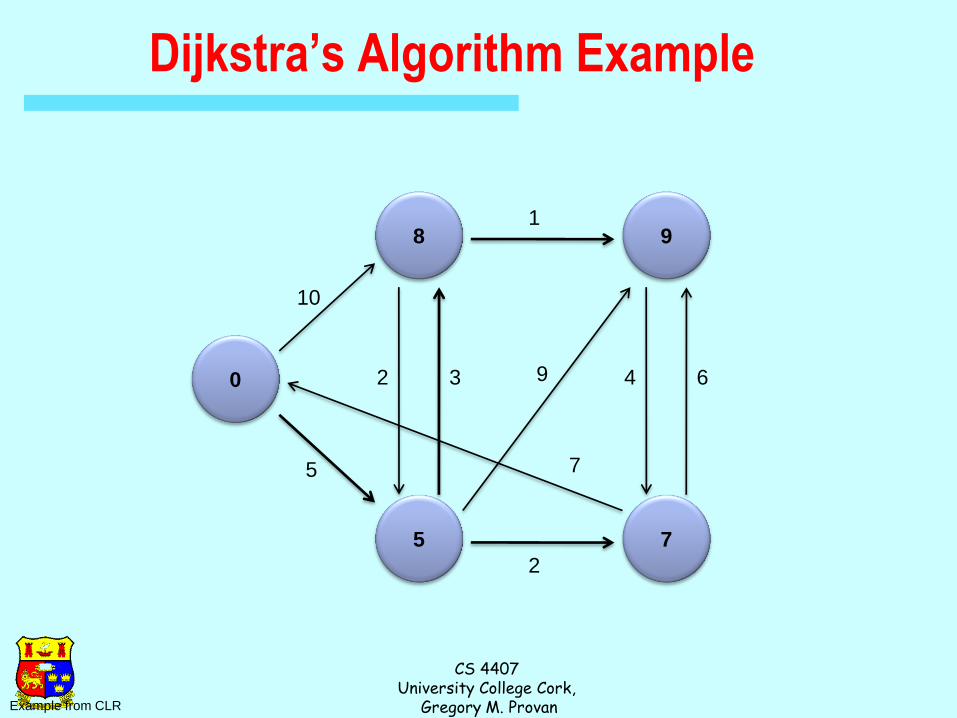
Dijkstra’s Algorithm Example
0
8
5
9
7
Example from CLR
10
5
2 3
2
1
9
7
4 6
CS 4407 University College Cork,
Gregory M. Provan
Single Source Shortest Path
Problem: find shortest path from a source node to one or
more target nodes
– Shortest might also mean lowest weight or cost
Single processor machine: Dijkstra’s Algorithm
MapReduce: parallel Breadth-First Search (BFS)
CS 4407 University College Cork,
Gregory M. Provan
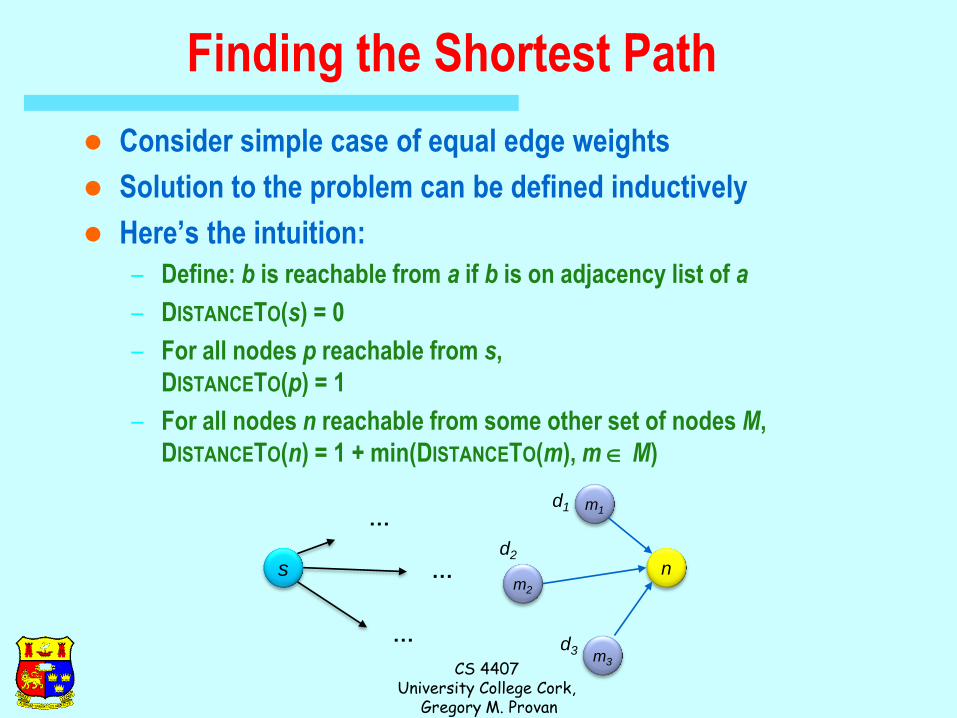
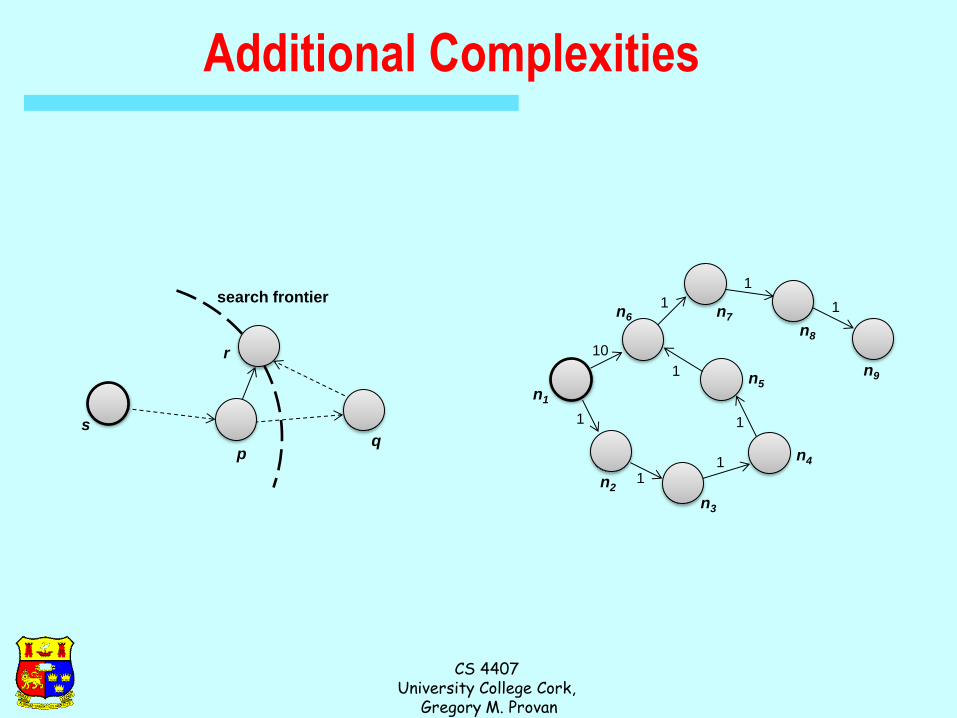
Finding the Shortest Path
Consider simple case of equal edge weights
Solution to the problem can be defined inductively
Here’s the intuition:
– Define: b is reachable from a if b is on adjacency list of a
– DISTANCETO(s) = 0
– For all nodes p reachable from s,
DISTANCETO(p) = 1
– For all nodes n reachable from some other set of nodes M,
DISTANCETO(n) = 1 + min(DISTANCETO(m), m M)
s
m3
m2
m1
n
…
…
…
d1
d2
d3
CS 4407 University College Cork,
Gregory M. Provan
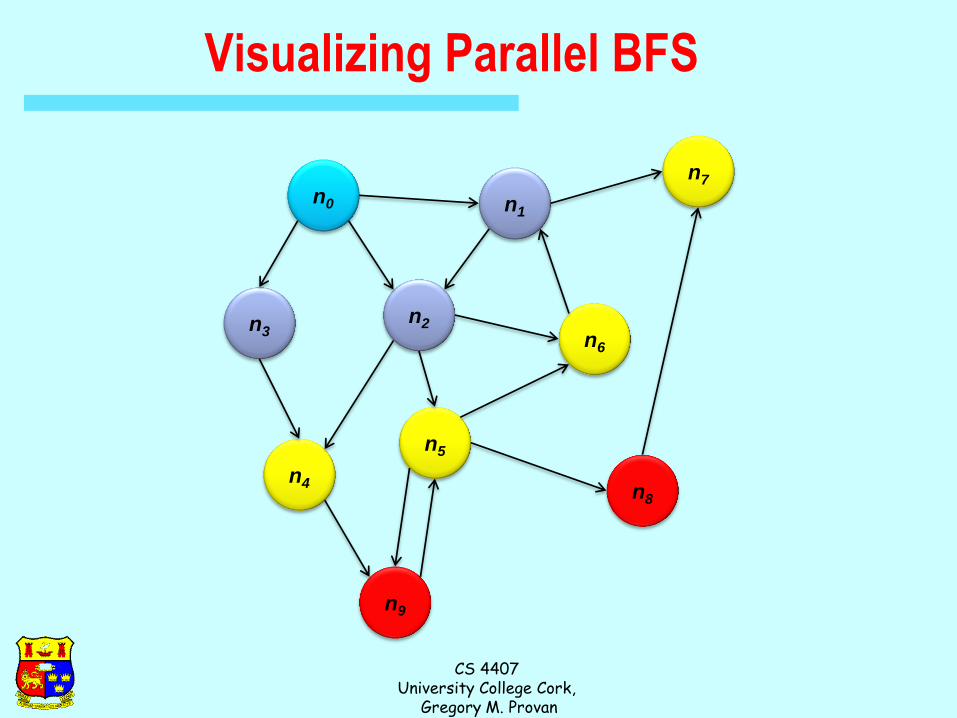
Visualizing Parallel BFS
n0
n3 n2
n1
n7
n6
n5
n4
n9
n8
CS 4407 University College Cork,
Gregory M. Provan
From Intuition to Algorithm
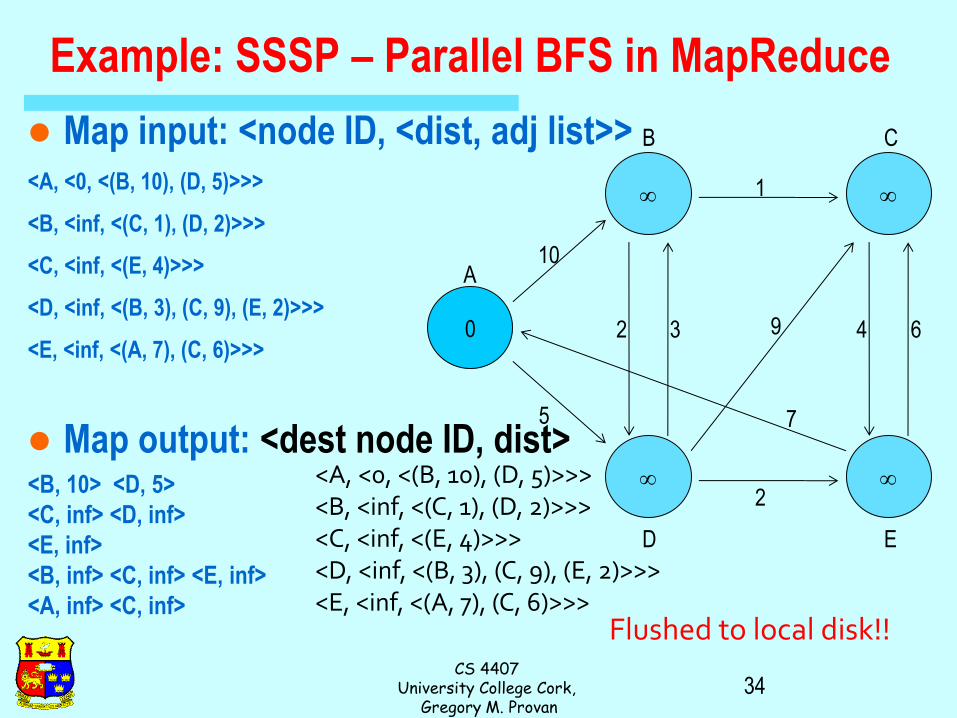
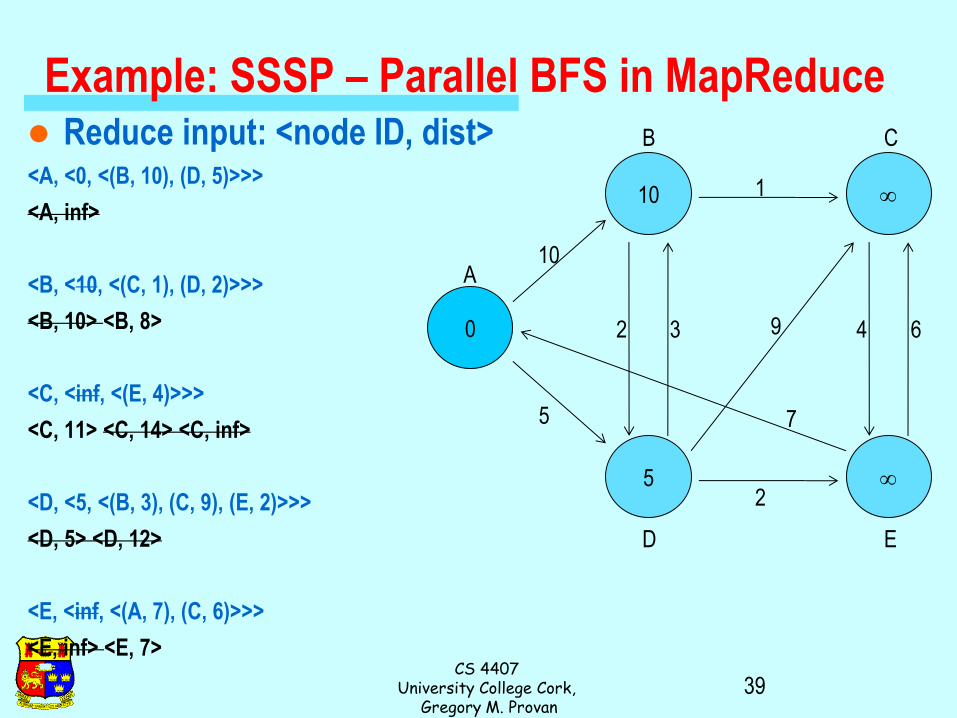
Data representation: – Key: node n
– Value: d (distance from start), adjacency list (list of nodes reachable from n)
– Initialization: for all nodes except for start node, d =
Mapper: – m adjacency list: emit (m, d + 1)
Sort/Shuffle – Groups distances by reachable nodes
Reducer: – Selects minimum distance path for each reachable node
– Additional bookkeeping needed to keep track of actual path
CS 4407 University College Cork,
Gregory M. Provan
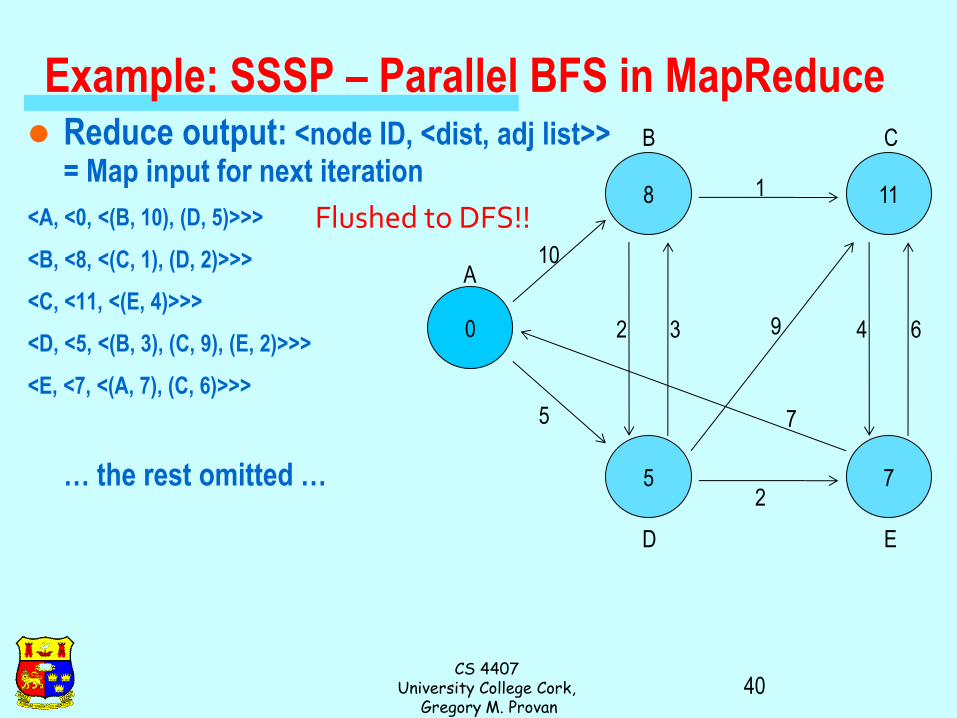
Multiple Iterations Needed
Each MapReduce iteration advances the “known frontier” by
one hop
– Subsequent iterations include more and more reachable nodes as
frontier expands
– Multiple iterations are needed to explore entire graph
Preserving graph structure:
– Problem: Where did the adjacency list go?
– Solution: mapper emits (n, adjacency list) as well
CS 4407 University College Cork,
Gregory M. Provan
BFS Pseudo-Code
CS 4407 University College Cork,
Gregory M. Provan
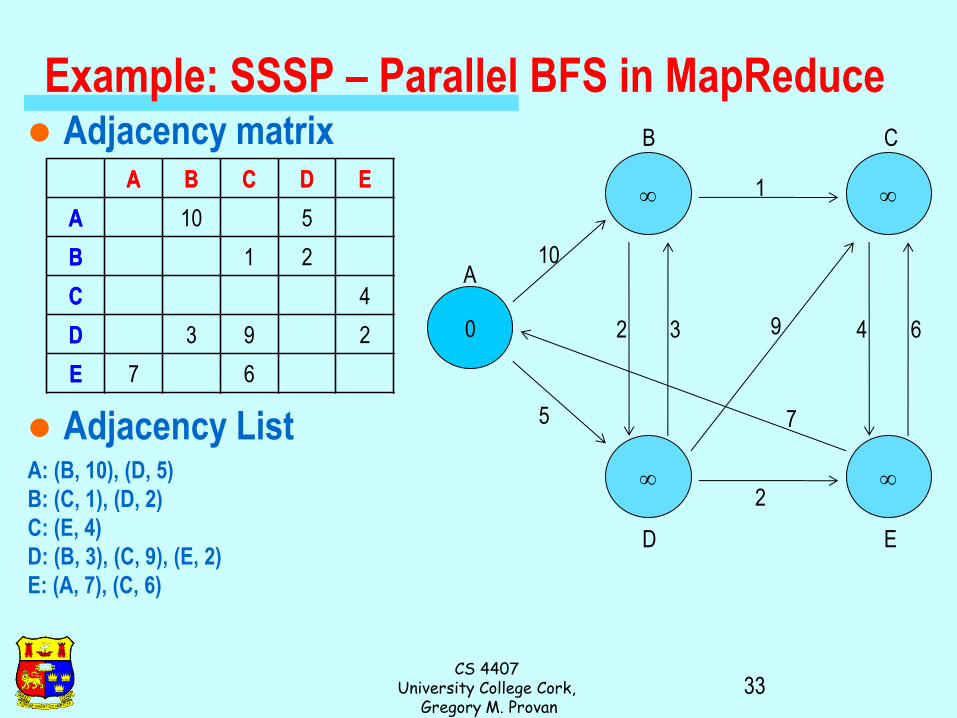
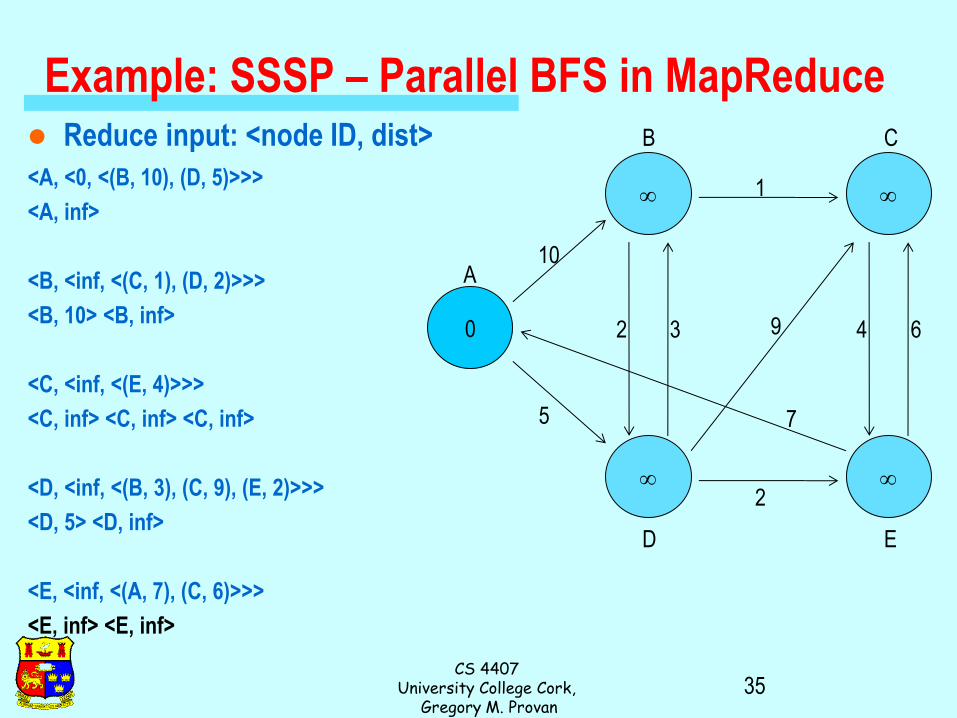
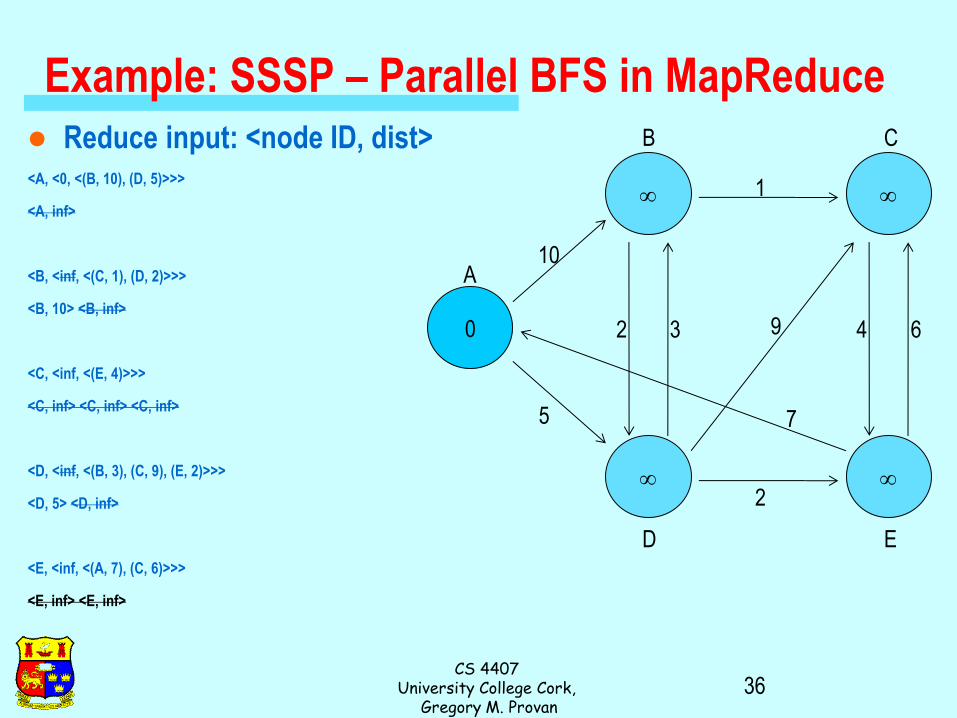
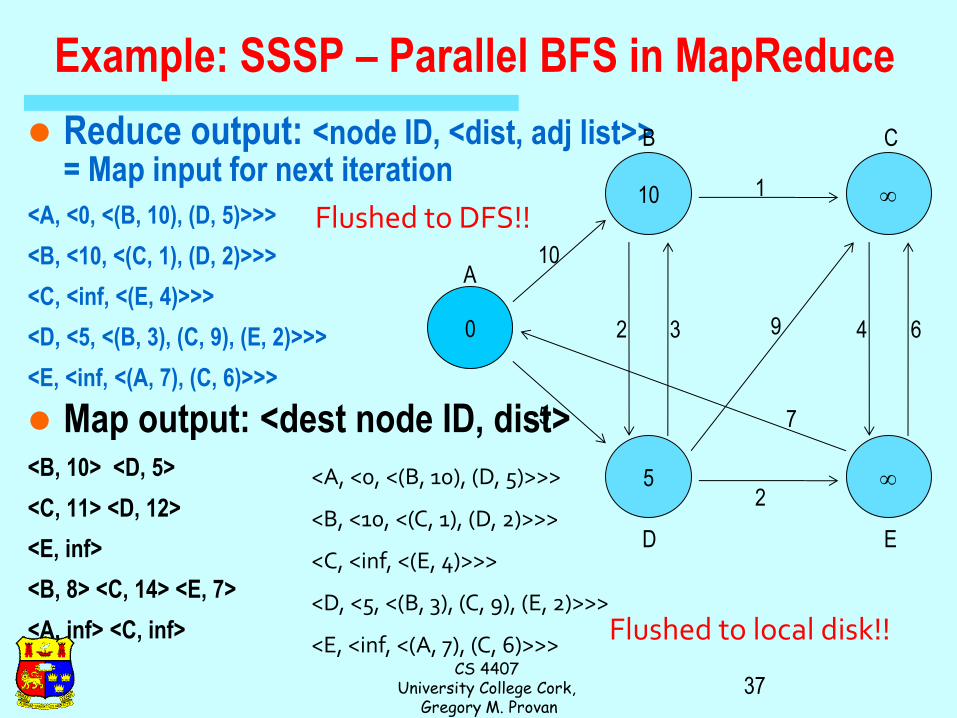
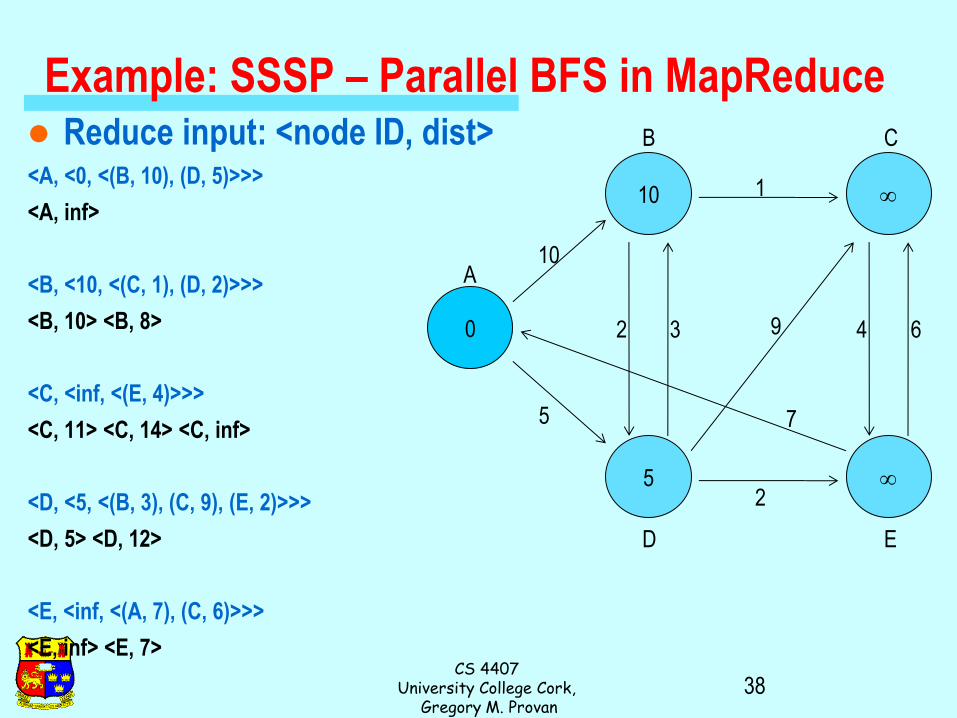
Example: SSSP – Parallel BFS in MapReduce Adjacency matrix