28
March 26, 2003 CS502 Web Information Sys tems 1 Web Crawling and Automatic Discovery Donna Bergmark Cornell Information Systems [email protected]
| Date post: | 21-Dec-2015 |
| Category: |
Documents |
| View: | 217 times |
| Download: | 0 times |

March 26, 2003 CS502 Web Information Systems 1
Web Crawling and Automatic Discovery
Donna Bergmark
Cornell Information [email protected]

March 26, 2003 CS502 Web Information Systems 2
Web Resource Discovery
• Finding info on the Web– Surfing (random strategy; goal is serendipity)
– Searching (inverted indices; specific info)
– Crawling (follow links; “all” the info)
• Uses for crawling– Find stuff
– Gather stuff
– Check stuff

March 26, 2003 CS502 Web Information Systems 3
Definition
Spider = robot = crawler
Crawlers are computer programs that roam the Web with the goal of automating specific tasks related to the Web.

March 26, 2003 CS502 Web Information Systems 4
Crawlers and internet history• 1991: HTTP• 1992: 26 servers• 1993: 60+ servers; self-register; archie• 1994 (early) – first crawlers• 1996 – search engines abound• 1998 – focused crawling• 1999 – web graph studies• 2002 – use for digital libraries

March 26, 2003 CS502 Web Information Systems 5
So, why not write a robot?
You’d think a crawler would be easy to write:
Pick up the next URL Connect to the server GET the URL When the page arrives, get its links (optionally do other stuff)
REPEAT

March 26, 2003 CS502 Web Information Systems 6
The Central Crawler Function
Server 2queue
Server 1queue
Server 3queue
URL -> IP
address via
DNS
Connect aSocket to
Server; sendHTTP request
Wait forthe
response:An HTML
page

March 26, 2003 CS502 Web Information Systems 7
Handling the HTTP Response
Documentseen
before?
FETCH Processthis
document
No
Extract text
Extract links
::

March 26, 2003 CS502 Web Information Systems 8
LINK Extraction
• Finding the links is easy (sequential scan)
• Need to clean them up and canonicalize them
• Need to filter them
• Need to check for robot exclusion
• Need to check for duplicates
March 26, 2003 CS502 Web Information Systems 9
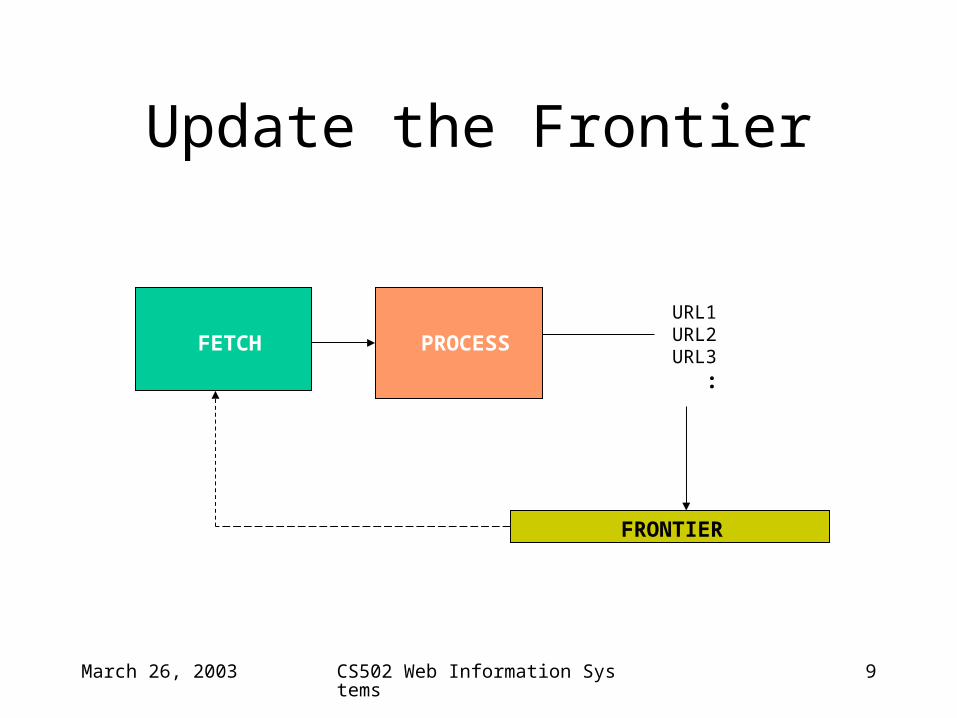
Update the Frontier
FETCH PROCESS
URL1URL2URL3 :
FRONTIER

March 26, 2003 CS502 Web Information Systems 10
Crawler Issues
• System Considerations
• The URL itself
• Politeness
• Visit Order
• Robot Traps
• The hidden web

March 26, 2003 CS502 Web Information Systems 11
Standard for Robot Exclusion
• Martin Koster (1994)
• http://any-server:80/robots.txt
• Maintained by the webmaster
• Forbid access to pages, directories
• Commonly excluded: /cgi-bin/
• Adherence is voluntary for the crawler

March 26, 2003 CS502 Web Information Systems 12
Visit Order
• The frontier
• Breadth-first: FIFO queue
• Depth-first: LIFO queue
• Best-first: Priority queue
• Random
• Refresh rate

March 26, 2003 CS502 Web Information Systems 13
Robot Traps
• Cycles in the Web graph
• Infinite links on a page
• Traps set out by the Webmaster

March 26, 2003 CS502 Web Information Systems 14
The Hidden Web
• Dynamic pages increasing
• Subscription pages
• Username and password pages
• Research in progress on how crawlers can “get into” the hidden web

15CS502 Web Information SystemsMarch 26, 2003
MERCATOR

March 26, 2003 CS502 Web Information Systems 16
Mercator Features
• One file configures a crawl• Written in Java• Can add your own code
– Extend one or more of M’s base classes– Add totally new classes called by your own
• Industrial-strength crawler:– uses its own DNS and java.net package

March 26, 2003 CS502 Web Information Systems 17
The Web is a BIG Graph
• “Diameter” of the Web
• Cannot crawl even the static part, completely
• New technology: the focused crawl

March 26, 2003 CS502 Web Information Systems 18
Crawling and Crawlers
• Web overlays the internet
• A crawl overlays the webseed

March 26, 2003 CS502 Web Information Systems 19
Focused Crawling

March 26, 2003 CS502 Web Information Systems 20
Focused Crawling
432
765
1
1
R
Breadth-first crawl
1
432
5R
X X
Focused crawl

March 26, 2003 CS502 Web Information Systems 21
Focused Crawling• Recall the cartoon for a focused crawl:
• A simple way to do it is with 2 “knobs”
1
432
5R
X X

March 26, 2003 CS502 Web Information Systems 22
Focusing the Crawl
• Threshold: page is on-topic if correlation to the closest centroid is above this value
• Cutoff: follow links from pages whose “distance” from closest on-topic ancestor is less than this value

March 26, 2003 CS502 Web Information Systems 23
Illustration
2 3
4
6
7
1
5555
Cutoff = 1
Corr >= threshold

March 26, 2003 CS502 Web Information Systems 24
Min-avg-max correlation vs. crawl length
00.10.2
0.30.40.50.6
0.70.8
0 20000 40000 60000 80000 100000 120000
No. documents downloaded
corr
elat
ion Maximum
Average
Minimum
Closest
Furthest

March 26, 2003 CS502 Web Information Systems 25
Correlation vs. Crawl Length

March 26, 2003 CS502 Web Information Systems 26
Fall 2002 Student Project
Query
Mercator
Centroid Collection Description
Term vectors
Centroids,Dictionary
CollectionURLs
Chebyshev P.s HTML

March 26, 2003 CS502 Web Information Systems 27
Conclusion
• We covered crawling – history, technology, deployment
• Focused crawling with tunneling
• We have a good experimental setup for exploring automatic collection synthesis

March 26, 2003 CS502 Web Information Systems 28
http://mercator.comm.nsdlib.org

















