49
© MariaDB. Company Confidential.
| Date post: | 06-Aug-2015 |
| Category: |
Technology |
| Upload: | kangaroot |
| View: | 113 times |
| Download: | 5 times |

© MariaDB. Company Confidential.

© MariaDB Corpora,on Ab. Company Confiden,al.
MariaDB &
CONNECT Storage Engine Serge Frezefond
[email protected] @sfrezefond

© MariaDB. Company Confidential.
MariaDB Server • RDBMS open source project based on MySQL under GPLv2 • Backed by MariaDB Founda,on • Enterprise product (MariaDB Enterprise) • Goal is to be the best DB for DevOps while remaining compa,ble with
MySQL

© MariaDB. Company Confidential.
MariaDB Versions
• MariaDB 5.1 based on MySQL CE 5.1 – MariaDB 5.2 based on MariaDB 5.1 – MariaDB 5.3 based on MariaDB 5.2
• MariaDB 5.5 based on MySQL CE 5.5 • MariaDB 10.0 based on MariaDB 5.5
– Plus features from MySQL 5.6 • MariaDB 10.1 based on MariaDB 10.0
– Plus features from MySQL 5.7

© MariaDB. Company Confidential.
MariaDB 10.0
Scalability ● Advanced parallel replication ● Sharding ● MaxScale proxy
Performance ● Enhanced optimization ● Improved and special purpose storage engines ● Carefully tuned and enhanced server internals ● Advanced performance monitoring
Availability ● HA clustering - integrating Galera cluster ● More online operations, less planned downtime
NoSQL ● Interoperable storage engines such as Cassandra and Connect ● Dynamic columns and JSON processing ● HandlerSocket API
Operations ● Comprehensive diagnostics built-in to the DB ● APIs and open architecture for easier integration
Security ● Role-based access control ● Authentication plugins ● Sophisticated auditing capabilities
© 2014, MariaDB Corp.
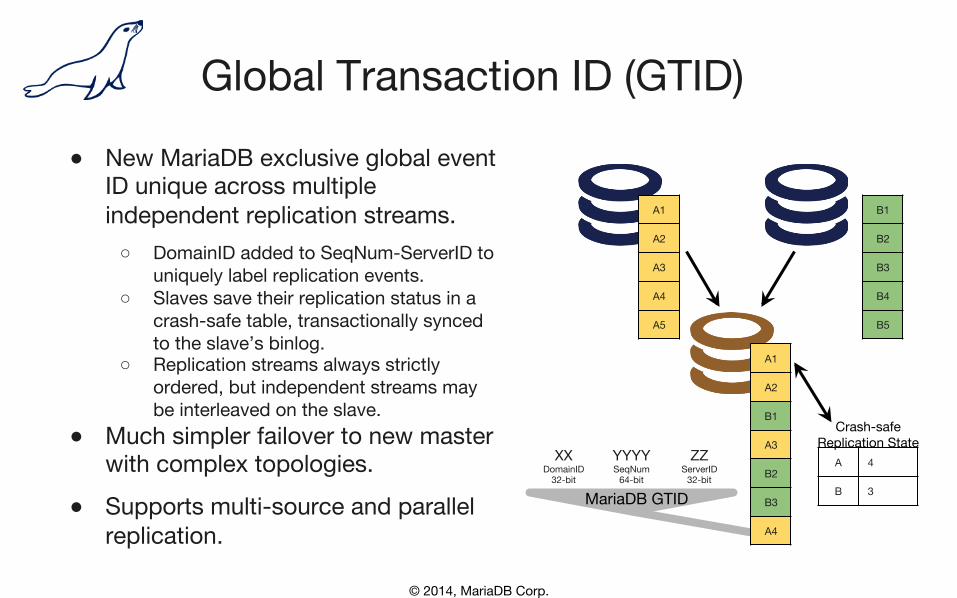
Global Transaction ID (GTID) ● New MariaDB exclusive global event
ID unique across multiple independent replication streams. ○ DomainID added to SeqNum-ServerID to
uniquely label replication events. ○ Slaves save their replication status in a
crash-safe table, transactionally synced to the slave’s binlog.
○ Replication streams always strictly ordered, but independent streams may be interleaved on the slave.
● Much simpler failover to new master with complex topologies.
● Supports multi-source and parallel replication.
A1
A2
A3
A4
A5
B1
B2
B3
B4
B5
A1
A2
B1
A3
B2
B3
A4
A 4
B 3
Crash-safe Replication State
XX DomainID
32-bit
YYYY SeqNum
64-bit
ZZ ServerID
32-bit
MariaDB GTID
© 2014, MariaDB Corp.
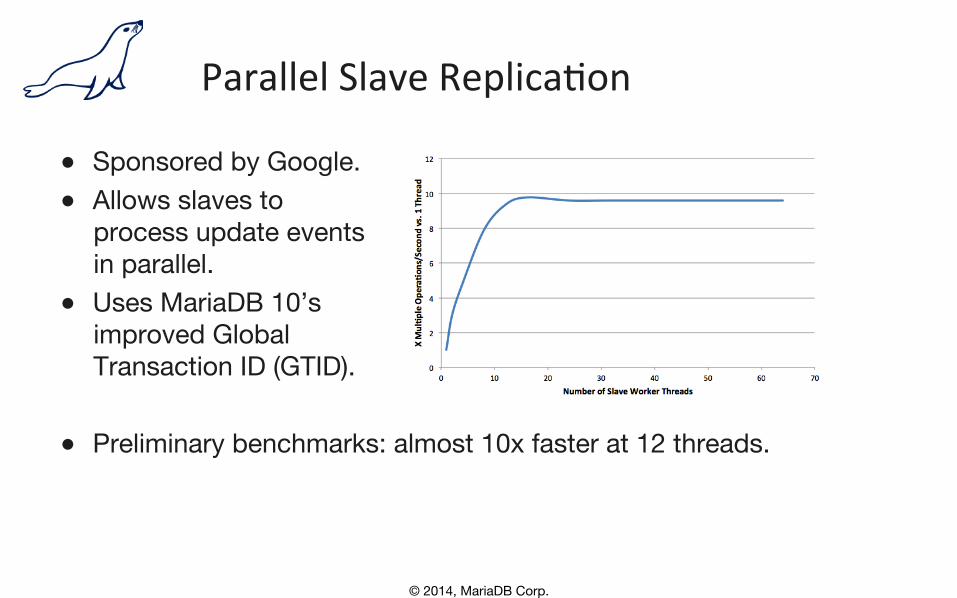
Parallel Slave Replica,on
● Sponsored by Google. ● Allows slaves to�
process update events�in parallel.
● Uses MariaDB 10’s�improved Global�Transaction ID (GTID).
● Preliminary benchmarks: almost 10x faster at 12 threads.
© 2014, MariaDB Corp.
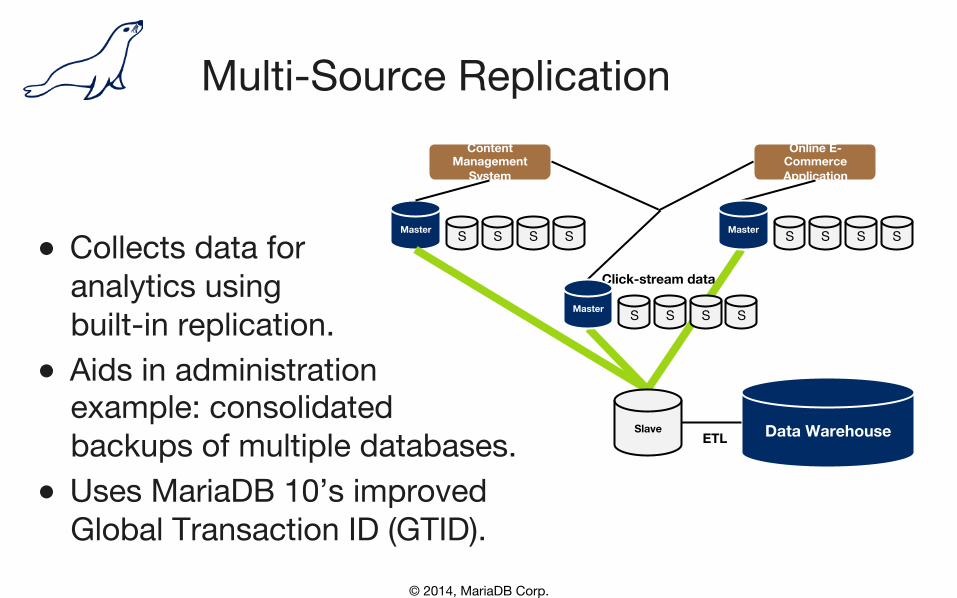
Multi-Source Replication
● Collects data for�
analytics using�built-in replication.
● Aids in administration�example: consolidated�backups of multiple databases.
● Uses MariaDB 10’s improved�Global Transaction ID (GTID).
Online E-Commerce Application
Master S S S S
Content Management
System
Click-stream data
Data Warehouse Slave ETL
Master S S S S
Master S S S S
© 2014, MariaDB Corp.
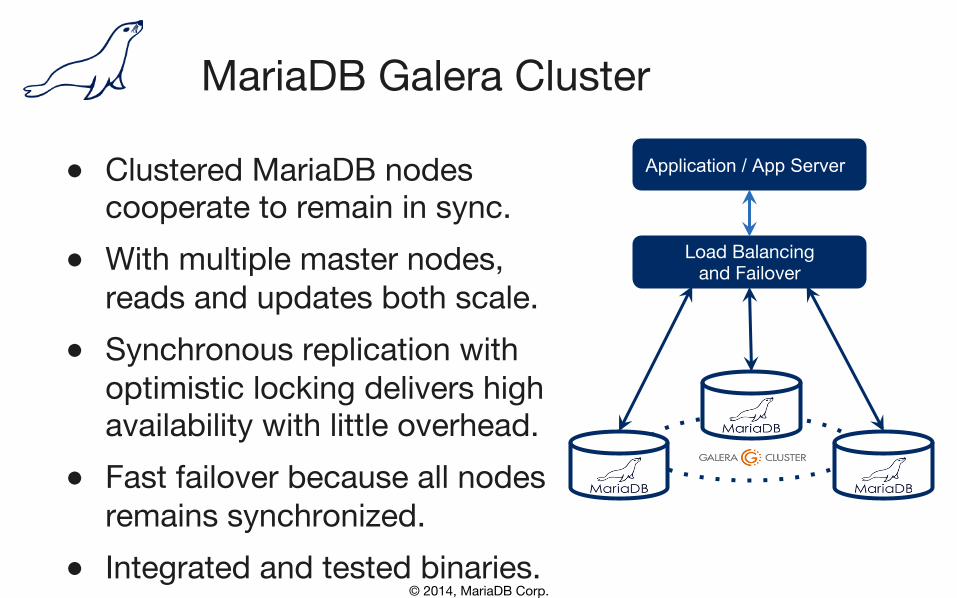
● Clustered MariaDB nodes�cooperate to remain in sync.
● With multiple master nodes,�reads and updates both scale.
● Synchronous replication with�optimistic locking delivers high�availability with little overhead.
● Fast failover because all nodes remains synchronized.
● Integrated and tested binaries.
MariaDB Galera Cluster
Load Balancing�and Failover
Application / App Server

© 2014, MariaDB Corp.
Optimizer Improvements
● Enhancements include:
○ Disk access optimizations. ○ JOIN optimizations. ○ Subquery optimizations. ○ Optimized derived tables and views. ○ Execution control. ○ Optimizer control. ○ EXPLAIN improvements.
Less I/O, CPU, memory requirements. Faster execution.
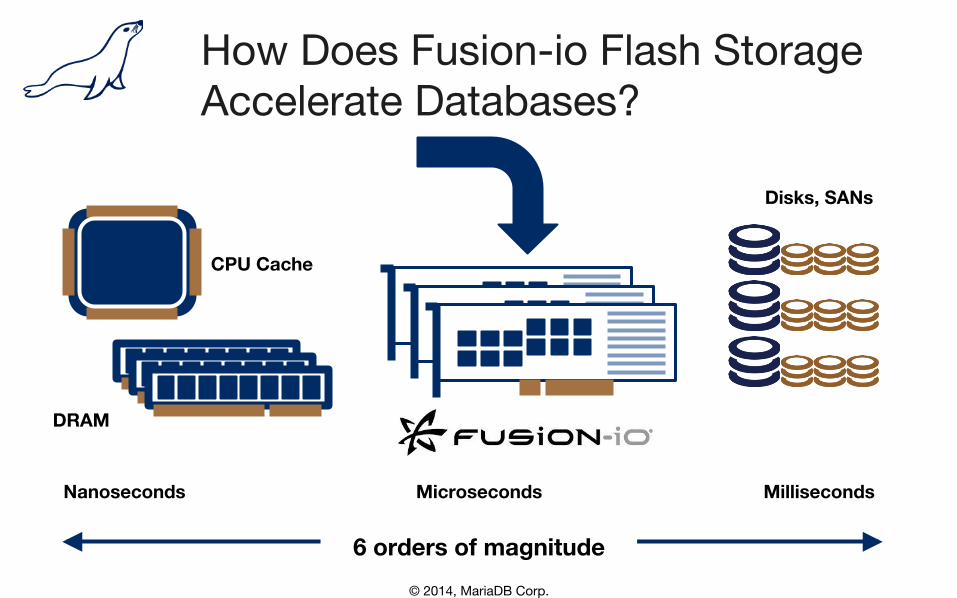
© 2014, MariaDB Corp.
CPU Cache
DRAM
Disks, SANs
Nanoseconds Microseconds Milliseconds
6 orders of magnitude
How Does Fusion-io Flash Storage Accelerate Databases?

© 2014, MariaDB Corp.
How Much Faster Is MariaDB 10 With Fusion-io?
12 hours 24 hours
/ sec
Fusion-‐io fills the buffer pool in less than an hour
All the data does not fit in the buffer pool, So performance dips
Never dips below 25,000 tx / sec
HDD performance rises for much longer as takes a LOT longer to fill buffer pool
1 hour
HDD : Performance dips as IO increases
About 24 times faster
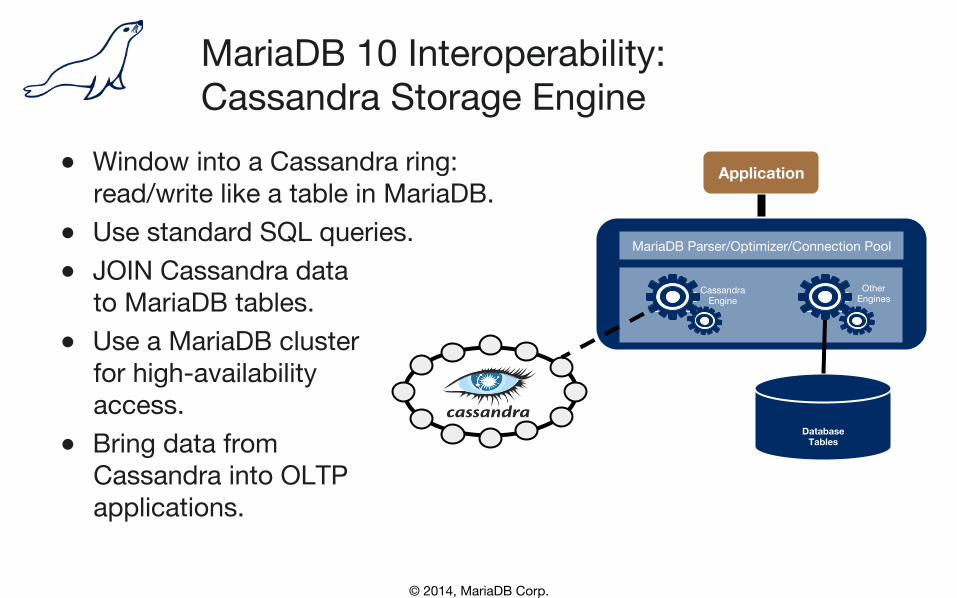
© 2014, MariaDB Corp.
MariaDB 10 Interoperability: Cassandra Storage Engine
● Window into a Cassandra ring:�read/write like a table in MariaDB.
● Use standard SQL queries. ● JOIN Cassandra data�
to MariaDB tables. ● Use a MariaDB cluster�
for high-availability�access.
● Bring data from�Cassandra into OLTP�applications.
Application
Spider
Database Tables
MariaDB Parser/Optimizer/Connection Pool
Cassandra Engine
Other Engines
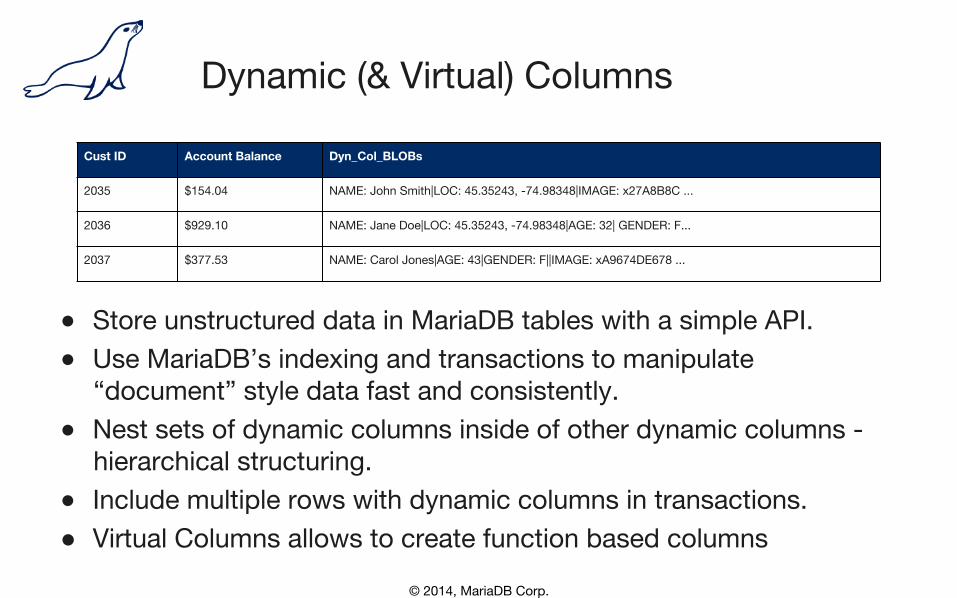
© 2014, MariaDB Corp.
Dynamic (& Virtual) Columns
● Store unstructured data in MariaDB tables with a simple API. ● Use MariaDB’s indexing and transactions to manipulate�
“document” style data fast and consistently. ● Nest sets of dynamic columns inside of other dynamic columns -
hierarchical structuring. ● Include multiple rows with dynamic columns in transactions. ● Virtual Columns allows to create function based columns
Cust ID Account Balance Dyn_Col_BLOBs
2035 $154.04 NAME: John Smith|LOC: 45.35243, -74.98348|IMAGE: x27A8B8C ...
2036 $929.10 NAME: Jane Doe|LOC: 45.35243, -74.98348|AGE: 32| GENDER: F...
2037 $377.53 NAME: Carol Jones|AGE: 43|GENDER: F||IMAGE: xA9674DE678 ...
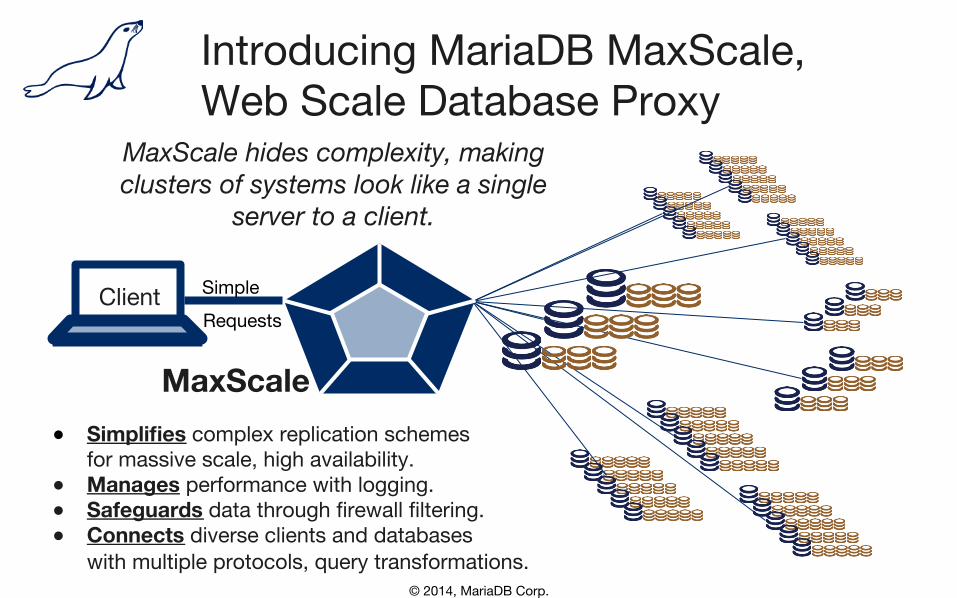
© 2014, MariaDB Corp.
Introducing MariaDB MaxScale, Web Scale Database Proxy
MaxScale hides complexity, making clusters of systems look like a single
server to a client.
● Simplifies complex replication schemes�for massive scale, high availability.
● Manages performance with logging. ● Safeguards data through firewall filtering. ● Connects diverse clients and databases�
with multiple protocols, query transformations.
Client Simple Requests
MaxScale

© 2014, MariaDB Corp.
MaxScale Use Case 1: Read Scalability
19.06.2014
MaxScae
MySQL Replica.on + Connec.on Load Balancing
Each application server uses 2 connections: 1 R/W, 1 R
MaxScale connects the R/W client connections to the master and the R connections are load-balanced to all
slaves
© 2014, MariaDB Corp.
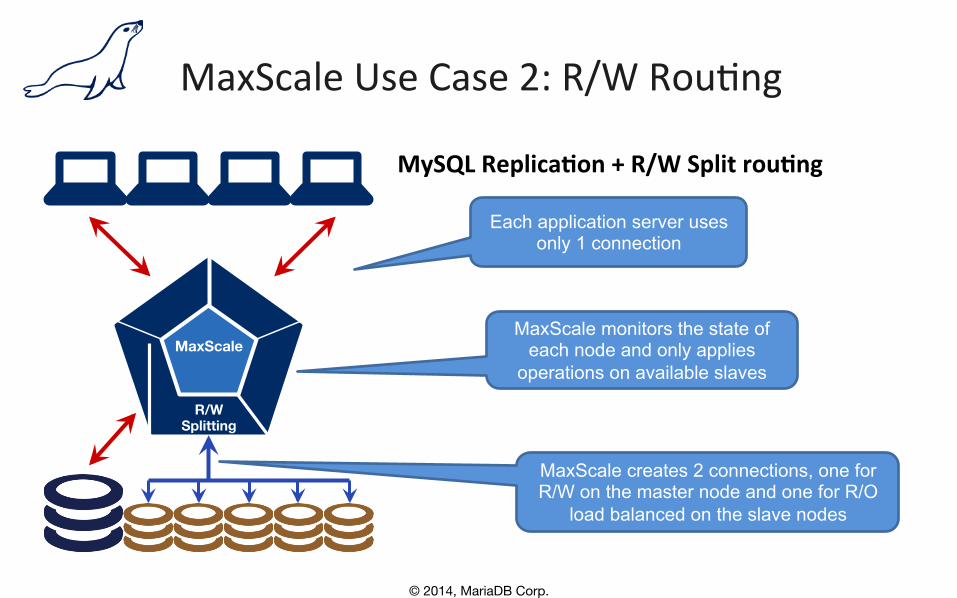
MaxScale Use Case 2: R/W Rou,ng
MySQL Replica.on + R/W Split rou.ng
Each application server uses only 1 connection
MaxScale creates 2 connections, one for R/W on the master node and one for R/O
load balanced on the slave nodes
MaxScale
R/W�Splitting
MaxScale monitors the state of each node and only applies
operations on available slaves
© 2014, MariaDB Corp.
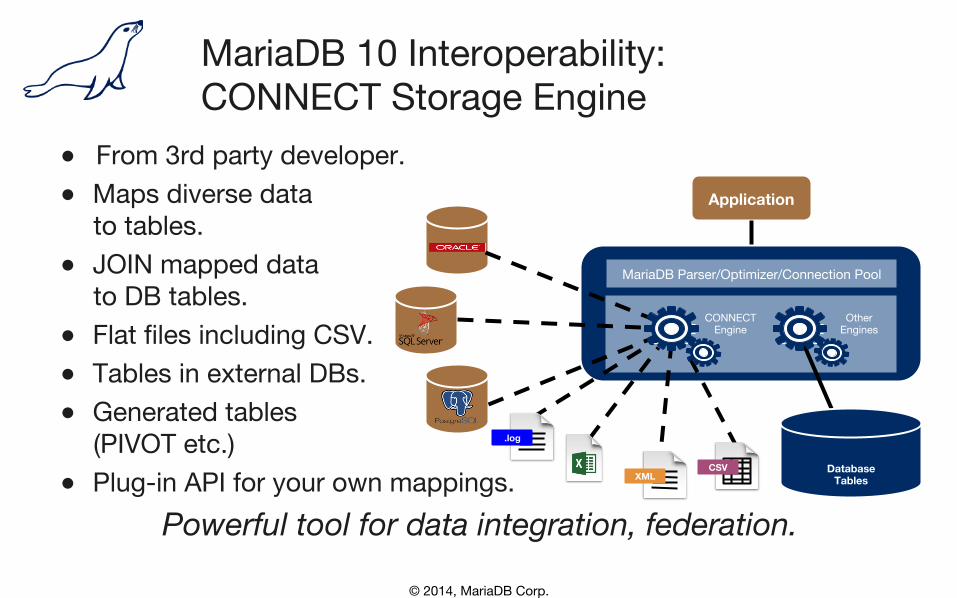
MariaDB 10 Interoperability: CONNECT Storage Engine
● From 3rd party developer. ● Maps diverse data�
to tables. ● JOIN mapped data�
to DB tables. ● Flat files including CSV. ● Tables in external DBs. ● Generated tables�
(PIVOT etc.) ● Plug-in API for your own mappings.
Powerful tool for data integration, federation.
Application
Spider
MariaDB Parser/Optimizer/Connection Pool
CONNECT Engine
Other Engines
Database Tables
.log
XML CSV
© 2014, MariaDB Corp.
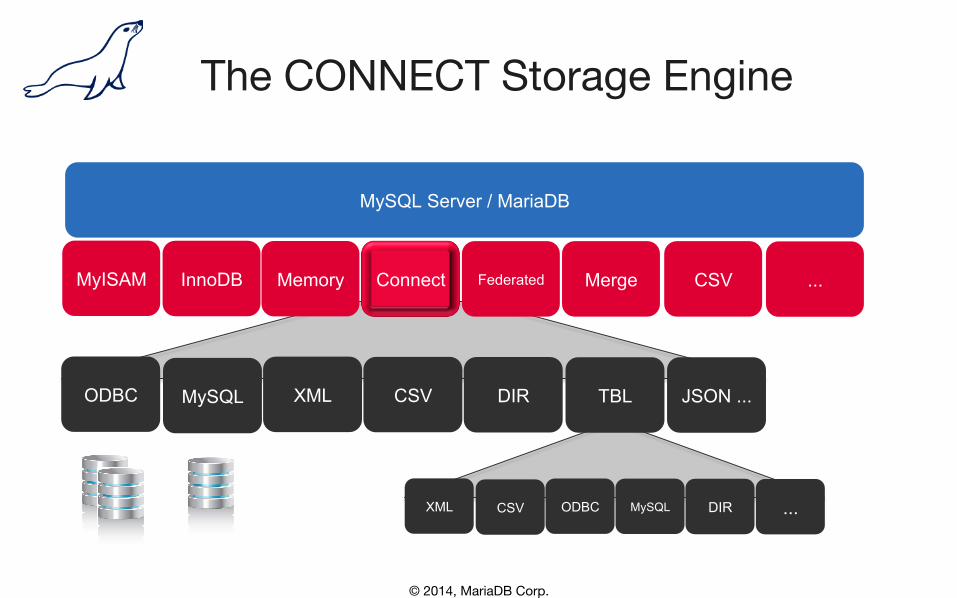
The CONNECT Storage Engine
MySQL Server / MariaDB
MyISAM InnoDB Memory Connect Federated Merge CSV ...
ODBC MySQL XML CSV DIR TBL JSON ...
XML CSV ODBC MySQL DIR ...

© 2014, MariaDB Corp.
CONNECT Storage Engine ODBC table type
● Allow to access to any ODBC data source. – Excel, Access, Firebird, SQLite – SQL Server, Oracle, DB2
● Supports insert, update, delete and any other commands J
● Multi files ODBC: consolidated monthly excel datasheet ● On Linux access to ODBC and UnixODBC data sources ● WHERE conditions are push to the ODBC source

© 2014, MariaDB Corp.
DSN for ODBC target
● Standard DSN syntax used ● Auto discovery of columns takes place ● If specified the columns set can be a subset
of target table create table toto ENGINE=CONNECT TABLE_TYPE=ODBC tabname='EMP' CONNECTION='DSN=orcl;UID=scott;PWD=manager1';

© 2014, MariaDB Corp.
Remote execution of SQL on ODBC target
To execute non MySQL syntax To compute agregate remotely
create table emp_hierarchy ENGINE=CONNECT TABLE_TYPE=ODBC tabname='EMP' CONNECTION='DSN=orcl;UID=scott;PWD=manager' srcdef='SELECT empno, ename, mgr, LEVEL FROM emp CONNECT BY PRIOR empno = mgr;';

© 2014, MariaDB Corp.
Any command on the ODBC target create table crlite (
command varchar(128) not null, number int(5) not null flag=1, message varchar(255) flag=2)
engine=connect table_type=odbc connection='Driver=SQLite3 ODBC Driver;Database=test.sqlite3;NoWCHAR=yes' option_list='Execsrc=1';
select * from crlite where command = 'CREATE TABLE lite (ID integer primary key, …)';

© 2014, MariaDB Corp.
JSON is cool for developers so ...
● Hierarchical, simple types ● JSON is used as storage format for document
stores: CouchBase, MongoDB(BSON) ● Used by rest API : FB, AWS, AZURE … ● JSON is at the heart of JavaScript ● Used by many cool dev framework : AngulaJS
…

© 2014, MariaDB Corp.
Not much so far for JSON & MySQL ● JSON udfs to do basic operations: ○ To manipulate JSON (search, contains, extract, set, append, remove, replace ..) ○ To generate JSON (value, object, arrays, member…) ○ It is udf so do not expect top performance L
● Import / export in JSON ○ Mysql2json ○ Mysqljson
● Explain output in JSON

© 2014, MariaDB Corp.
JSON output of MariaDB Dynamic column
MariaDB JSON export of dynamic columns
> select item_name, COLUMN_JSON(dynamic_cols) from assets; +-----------------------+------------------------------------------------+ | item_name | COLUMN_JSON(dynamic_cols) | +-----------------------+------------------------------------------------+ | MariaDB T-shirt | {"size":”XL","color":"blue"} | | Thinkpad Laptop | {"color":"black","warranty":"3 years"} | +-----------------------+------------------------------------------------+

© 2014, MariaDB Corp.
Not much so far for JSON and MySQL but ..
● A native JSON type with content indexing and compact format would be great JNow it is coming ! : ○ Facebook introduces DOCstore with Native JSON
support ■ Indexing on mixed col + document path
○ MySQL 5.7 lab release with native JSON support : ■ Validation, fast access ■ index through virtual columns
● It was time to do it, PostgreSQL already got it ( JSONB, index, functions …)

© 2014, MariaDB Corp.
JSON is simple {! "ISBN": "9782212090819",!…! "AUTHOR": [! {! "FIRSTNAME": "Jean-Christophe",! "LASTNAME": "Bernadac"! },!..! ],! "TITLE": "Construire une application XML",! "PUBLISHER": {! "NAME": "Eyrolles", ...! },! }!

© 2014, MariaDB Corp.
Create a table on JSON file ● JSON Path used to map column names to JSON
properties create table jsampall (!ISBN char(15),!…!Author char(128) field_format='AUTHOR:[" and "]',!Title char(32) field_format='TITLE',!Publisher char(20) field_format='PUBLISHER:NAME',!)!engine=CONNECT table_type=JSON File_name='biblio3.jsn';!

© 2014, MariaDB Corp.
JSON Table Type Query Result
The result is: Title author publisher location Construire application XML Jean Bernadac and François Knab Eyrolles Paris XML en Action William J. Pardi Microsoft Press Paris
select title, author, publisher, location from jsampall;!

© 2014, MariaDB Corp.
Create a table on JSON file ● Possibility to define the starting point ● For example with this Facebook JSON file : { "data": [ { "id": "X999_Y999", "from": { "name": "Tom Brady", "id": "X12" }, "message": "Looking forward to 2010!", "actions": [ { "name": "Comment", "link": "http://www.facebook.com/X999/posts/Y999"

© 2014, MariaDB Corp.
Create a table on JSON file
● Possibility to define the starting point
create table jfacebook ( `ID` char(10) field_format='id', `Name` char(32) field_format='from:name', `Action` char(16) field_format='actions::name', `Link` varchar(256) field_format='actions::link', engine=connect table_type=JSON file_name='facebook.json' option_list='Object=data,Expand=actions';

© 2014, MariaDB Corp.
JSON file formats supported ● 2 JSON file formats supported ● format of exported MongoDB files :
33
{ "_id" : "01001", "city" : "AGAWAM", "loc" : [ -72.622739, 42.070206 ], "pop" : 15338, "state" : "MA" } { "_id" : "01002", "city" : "CUSHMAN", "loc" : [ -72.51564999999999, 42.377017 ], "pop" : 36963, "state" : "MA" } …
create table cities ( `_id` char(5) key, `city` char(32), `long` double(12,6) field_format='loc:[1]', `lat` double(12,6) field_format='loc:[2]’ ) engine=CONNECT table_type=JSON file_name='cities.json' lrecl=128 option_list='pretty=0';

© 2014, MariaDB Corp.
JSON Table Type : The Jpath Specification
Specification Array Type Description [n] All Take the nth value of the array. Ignore it if n is 0. [X] or [x] All Expand. Generate one row for each array value. ["string”] String Concatenate all values separated by specified string. [+] Numeric Make the sum of all the array values. [*] Numeric Make the product of all array values. [!] Numeric Make the average of all the array values. [>] or [<] All Return the greatest or least value of the array. [#] All Return the number of values in the array. [] All Sum if numeric, else concatenation separated by “, “.
All Take the first value if an array.

© 2014, MariaDB Corp.
JSON facts table Aggregation of property values
The result is:
[ { "WHO": "Joe", "WEEK": 3, "EXPENSE": [ { "WHAT": "Beer", "AMOUNT": 18.00 }, … ] }, { "WHO": "Joe", "WEEK": 4, "EXPENSE": …

© 2014, MariaDB Corp.
Aggregation through SQL/JSON Path
The result is:
create table jexpw ( WHO char(12) not null, WEEK int(2) not null field_format='WEEK:[x]:NUMBER', WHAT char(32) not null field_format='WEEK::EXPENSE:[", "]:WHAT', SUM double(8,2) not null field_format='WEEK::EXPENSE:[+]:AMOUNT', AVERAGE double(8,2) not null field_format='WEEK::EXPENSE:[!]:AMOUNT') engine=CONNECT table_type=JSON File_name='expense.json’;
WHO WEEK WHAT SUM AVERAGE Joe 3 Beer, Food, Food, Car 69.00 17.25 Joe 4 Beer, Beer, Food, Food, Beer 83.00 16.60

© 2014, MariaDB Corp.
JSON facts table Aggregation through SQL
The result is:
CREATE TABLE `jexpall` ( `WHO` char(12) DEFAULT NULL, `WEEK` int(2) DEFAULT NULL `field_format`='WEEK:[x]:NUMBER', `WHAT` char(32) DEFAULT NULL `field_format`='WEEK:[x]:EXPENSE:[x]:WHAT', `AMOUNT` double(8,2) DEFAULT NULL `field_format`='WEEK:[x]:EXPENSE:[x]:AMOUNT' ) ENGINE=CONNECT DEFAULT CHARSET=latin1 `table_type`=JSON `File_name`='/var/lib/mysql/json/expense.jsn’
select who,week, ! group_concat(what),! sum(amount), ! avg(amount) !from jexpall group by who,week;!

© 2014, MariaDB Corp.
Simple JSON creation with autodiscovery
● CONNECT will automatically discover the structure of a JSON file (like with ODBC) ○ Automatic column naming ■ Column name =
propertyname1_..._propertyname5 ● Use a depth argument for flattening hierarchy ○ Deeper will remain JSON
● Will return 1rst array element (as do not now what to do with array elements)

© 2014, MariaDB Corp.
Simple creation with autodiscovery
● Show create table will show what has been autodiscovered
39
create table jsampall2 engine=connect table_type=JSON file_name='biblio3.json' option_list='level=1';
CREATE TABLE `jsampall2` ( `ISBN` char(13) NOT NULL, `AUTHOR_FIRSTNAME` char(15) NOT NULL `FIELD_FORMAT`='AUTHOR::FIRSTNAME', … ) ENGINE=CONNECT `TABLE_TYPE`='JSON' `FILE_NAME`='biblio3.json' `OPTION_LIST`='level=1';

© 2014, MariaDB Corp.
Catalog of a JSON File create table bibcol engine=connect table_type=JSON file_name='biblio3.json' option_list='level=2' catfunc=columns;
select column_name, type_name type, column_size size, jpath from bibcol; column_name type size jpath ISBN CHAR 13 TITLE CHAR 30 ... TRANSLATED_TRANSLATOR_FIRSTNAME CHAR 5 TRANSLATED:TRANSLATOR:FIRSTNAME

© 2014, MariaDB Corp.
JSON representation of an existing table
● With CONNECT it is very easy to get the JSON representation of a table ● Create like or Create Select works fine ● Insert … Select json_object(…) from create table xj1 ( row varchar(500) field_format='*’ ) engine=connect table_type=JSON file_name='biblio3.json' option_list='jmode=2’;

© 2014, MariaDB Corp.
Build JSON to populate file ● Udf used to build the JSON representation of
the table insert into xj1 select json_object_nonull(ISBN, language LANG, SUBJECT, json_array_grp(json_object(authorfn FIRSTNAME, authorln LASTNAME)) json_AUTHOR, TITLE, json_object(translated PREFIX, json_object(tranfn FIRSTNAME, tranln LASTNAME) json_TRANSLATOR) json_TRANSLATED, json_object(publisher NAME, location PLACE) json_PUBLISHER, date DATEPUB) from xsampall2 group by isbn;

© 2014, MariaDB Corp.
JSON representation of existing tables
What about master-detail table based on Foreign Key ? - You can create view to hide the join - use udf to build the hierarchical JSON structure
Classic impedance mismatch between a hierarchical(object model) and

© 2014, MariaDB Corp.
Modify JSON File ● Update a JSON table
update jsampex set authorfn = 'John' where authorln = 'Knab';
update jsample2 set json_author = json_array_add(json_author, json_object('Charles' FIRSTNAME, 'Dickens' LASTNAME)) where isbn = '9782840825685’;
© 2014, MariaDB Corp.
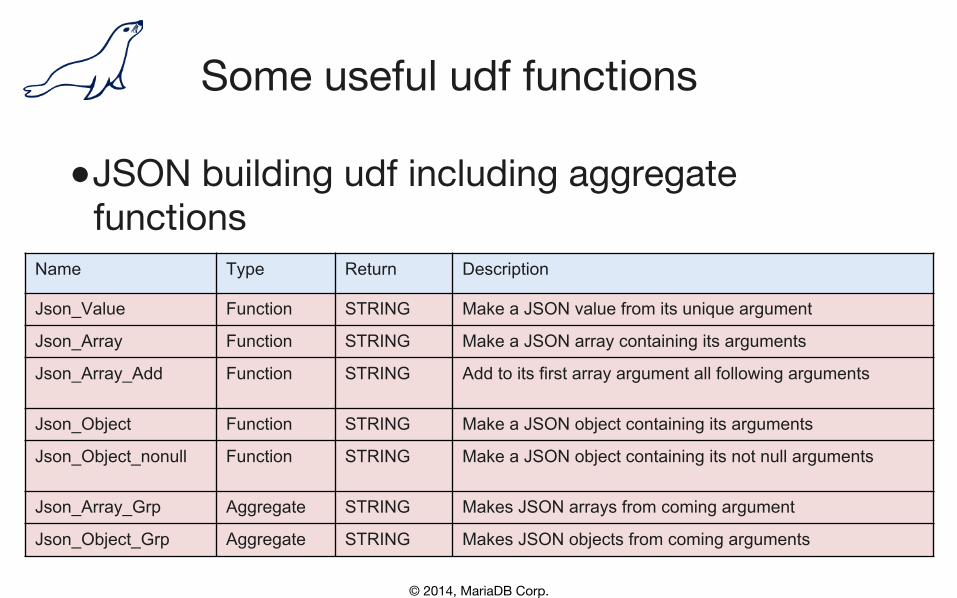
Some useful udf functions
● JSON building udf including aggregate functions
Name Type Return Description
Json_Value Function STRING Make a JSON value from its unique argument
Json_Array Function STRING Make a JSON array containing its arguments
Json_Array_Add Function STRING Add to its first array argument all following arguments
Json_Object Function STRING Make a JSON object containing its arguments
Json_Object_nonull Function STRING Make a JSON object containing its not null arguments
Json_Array_Grp Aggregate STRING Makes JSON arrays from coming argument
Json_Object_Grp Aggregate STRING Makes JSON objects from coming arguments

© 2014, MariaDB Corp.
What is next ? Evolutions
● It would be great to be able to query through http a rest API as if it was a JSON file
create table jsampall (!…!)!engine=CONNECT table_type=JSON !File_name=’https://../RESTAPI';!

© 2014, MariaDB Corp.
Take aways
● CONNECT storage Engine can make you life simpler for heterogeneous datasources
● CONNECT offers JSON complementary technology ○ CONNECT/JSON to read, produce, modify JSON file ○ Native JSON for strict efficient JSON ○ JSON udf to manipulate JSON stored as text

© 2014, MariaDB Corp.
Resources
● bugs: mariadb.org/jira ● mailing lists:
○ [email protected] ○ [email protected]
● fb.com/MariaDB.dbms ● twitter: @mariadb ● #maria on irc.freenode.net ● https://mariadb.com/kb/en ● downloads: https://downloads.mariadb.org
○ apt,yum repositoriies available ● Default in RHEL7, SuSE 12, Fedora, Slackware, Archlinux etc etc

© MariaDB Corpora,on Ab. Company Confiden,al.
Ques,ons ? Serge Frezefond
[email protected] @sfrezefond

















