The competition identified a “probe set” of ratings, about 1.4 million ofthe entries, for testing purposes. These were not a random draw, rather moviesthat had appeared chronologically later than most. Figure 7.2 shows the rootmean squared error over the training and test sets as the rank of the SVDwas varied. Also shown are the results from an estimator based on nuclearnorm regularization, discussed in the next section. Here we double centeredthe training data, by removing row and column means. This amounts to fittingthe model
zij = αi + βj +r∑
`=1ci`gj` + wij ; (7.8)
However, the row and column means can be estimated separately, using asimple two-way ANOVA regression model (on unbalanced data).
0 50 100 150 200
0.7
0.8
0.9
1.0
Rank
RM
SE
Train
Test
0.65 0.70 0.75 0.80 0.85 0.90
0.9
50.9
60.9
70.9
80.9
91.0
0
Training RMSE
Test R
MS
E
Hard−Impute
Soft−Impute
Netflix Competition Data
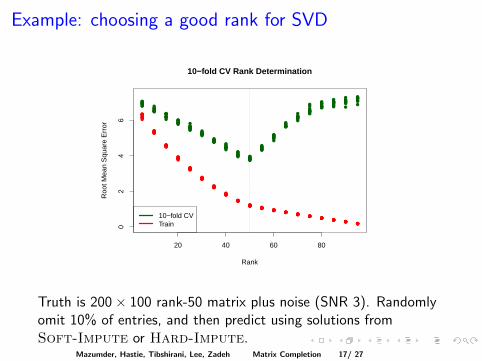
Figure 7.2 Left: Root-mean-squared error for the Netflix training and test data forthe iterated-SVD (Hard-Impute) and the convex spectral-regularization algorithm(Soft-Impute). Each is plotted against the rank of the solution, an imperfect cal-ibrator for the regularized solution. Right: Test error only, plotted against trainingerror, for the two methods. The training error captures the amount of fitting thateach method performs. The dotted line represents the baseline “Cinematch” score.
While the iterated-SVD method is quite effective, it is not guaranteed tofind the optimal solution for each rank. It also tends to overfit in this example,when compared to the regularized solution. In the next section, we presenta convex relaxation of this setup that leads to an algorithm with guaranteedconvergence properties.
Consequences of new nuclear-norm / ALS connections
For SVD of fully observed matrix:
I Can solve reduced-rank SVD by alternating ridge regressions.
I At each iteration, re-orthogonalization as in usual QRiterations (for reduced-rank SVD) means ridge regression is asimple matrix multiply, followed by column scaling.
I Ridging speeds up convergence, and focuses accuracy onleading dimensions.
I Solution delivers a reduced-rank SVD.
For matrix completion:
I Combine SVD calculation and imputation in Soft-Impute.
I Leads to a faster algorithm that can be distributed to multiplecores for storage and computation efficiency.
Consequences of new nuclear-norm / ALS connections
For SVD of fully observed matrix:
I Can solve reduced-rank SVD by alternating ridge regressions.
I At each iteration, re-orthogonalization as in usual QRiterations (for reduced-rank SVD) means ridge regression is asimple matrix multiply, followed by column scaling.
I Ridging speeds up convergence, and focuses accuracy onleading dimensions.
I Solution delivers a reduced-rank SVD.
For matrix completion:
I Combine SVD calculation and imputation in Soft-Impute.
I Leads to a faster algorithm that can be distributed to multiplecores for storage and computation efficiency.
Timing Comparisonsof computing on a Linux cluster with 300Gb of ram (with a fairly liberalrelative convergence criterion of 0.001), using the softImpute package in R.
0 5 10 15
2e−
041e
−03
5e−
035e
−02
5e−
01
Time in Hours
Rel
ativ
e O
bjec
tive
(log
scal
e)
Netflix (480K, 18K) λ=100 r=100
ALSsoftImpute−ALS
0 10 20 30 40 50 60
5e−
055e
−04
5e−
035e
−02
5e−
01Time in Minutes
Rel
ativ
e O
bjec
tive
(log
scal
e)
MovieLens 10M (72K, 10K) λ=50 r=100
Figure 3: Left: timing results on the Netflix matrix, comparing ALS withsoftImpute-ALS. Right: timing on the MovieLens 10M matrix. In bothcases we see that while ALS makes bigger gains per iteration, each iterationis much more costly.
Figure 3 (left panel) gives timing comparison results for one of the Netflixfits, this time implemented in Matlab. The right panel gives timing resultson the smaller MovieLens 10M matrix. In these applications we need notget a very accurate solution, and so early stopping is an attractive option.softImpute-ALS reaches a solution close to the minimum in about 1/4 thetime it takes ALS.
6 R Package softImpute
We have developed an R package softImpute for fitting these models [3],which is available on CRAN. The package implements both softImpute andsoftImpute-ALS. It can accommodate large matrices if the number of missingentries is correspondingly large, by making use of sparse-matrix formats.There are functions for centering and scaling (see Section 8), and for making
I softImpute package in R. Can deal with large sparsecomplete matrices, or large matrices with many missingentires (ie Netflix or bigger). Includes row and columncentering and scaling options.
I Spark cluster-programming. Uses distributed computing andchunking. Can deal with very large problems (e.g. 107 × 107,139 secs per iteration). See http://git.io/sparkfastals
I softImpute package in R. Can deal with large sparsecomplete matrices, or large matrices with many missingentires (ie Netflix or bigger). Includes row and columncentering and scaling options.
I Spark cluster-programming. Uses distributed computing andchunking. Can deal with very large problems (e.g. 107 × 107,139 secs per iteration). See http://git.io/sparkfastals