MDABench: Customized benchmark generation using MDA Liming Zhu a,b, * , Ngoc Bao Bui c , Yan Liu a,b , Ian Gorton a,b a Empirical Software Engineering Program, National ICT Australia Ltd., School of Computer Science and Engineering, University of New South Wales, Bay 15, Locomotive Workshop, Australian Technology Park, Garden Street, Eveleigh NSW 1430, Australia b School of Computer Science and Engineering, University of New South Wales, Australia c Faculty of Information Technology, University of Technology Sydney, Australia Received 9 January 2006; received in revised form 10 October 2006; accepted 31 October 2006 Available online 11 December 2006 Abstract This paper describes an approach for generating customized benchmark suites from a software architecture description following a Model Driven Architecture (MDA) approach. The benchmark generation and performance data capture tool implementation (MDA- Bench) is based on widely used open source MDA frameworks. The benchmark application is modeled in UML and generated by taking advantage of the existing community-maintained code generation ‘‘cartridges’’ so that current component technology can be exploited. We have also tailored the UML 2.0 Testing Profile so architects can model the performance testing and data collection architecture in a standards compatible way. We then extended the MDA framework to generate a load testing suite and automatic performance measure- ment infrastructure. This greatly reduces the effort and expertise needed for benchmarking with complex component and Web service technologies while being fully MDA standard compatible. The approach complements current model-based performance prediction and analysis methods by generating the benchmark application from the same application architecture that the performance models are derived from. We illustrate the approach using two case studies based on Enterprise JavaBean component technology and Web services. Ó 2006 Elsevier Inc. All rights reserved. Keywords: MDA; Model-driven development; Performance; Testing; Code generation 1. Introduction Software technologies such as Enterprise Java Beans (EJBs), .NET and Web services have proven successful in the construction of enterprise-scale systems. However, it remains a challenging software engineering problem to ensure that an application architecture can meet its speci- fied performance requirements. Various performance analysis models with prediction capabilities have been proposed to evaluate architecture designs during early phases of the application development cycle (Balsamo et al., 2004). Utilizing these models requires two distinct activities to be carried out by the application architect. The first requires the development of specific analytical models based on the application design. The second must obtain parameter values for the performance model using measurements or simulation. Both these activ- ities require significant additional effort and specific exper- tise in performance engineering methods. Hence, we believe these are key inhibitors that have prevented performance engineering techniques from achieving wide-spread adop- tion in practice (Balsamo et al., 2004). With the growing interest in Model Driven Architecture (MDA) technologies, attempts to integrate performance analysis with MDA and UML have been made, aiming to reduce the performance modeling effort required. The OMG’s MDA standard defines a way of transforming busi- ness domain models into Platform Independent Models 0164-1212/$ - see front matter Ó 2006 Elsevier Inc. All rights reserved. doi:10.1016/j.jss.2006.10.052 * Corresponding author. Address: Empirical Software Engineering Program, National ICT Australia Ltd., School of Computer Science and Engineering, University of New South Wales, Bay 15, Locomotive Workshop, Australian Technology Park, Garden Street, Eveleigh NSW 1430, Australia. Tel.: +61 2 83745523; fax: +61 2 83745520. E-mail address: [email protected](L. Zhu). www.elsevier.com/locate/jss The Journal of Systems and Software 80 (2007) 265–282
Transcript
www.elsevier.com/locate/jss
The Journal of Systems and Software 80 (2007) 265–282
MDABench: Customized benchmark generation using MDA
Liming Zhu a,b,*, Ngoc Bao Bui c, Yan Liu a,b, Ian Gorton a,b
a Empirical Software Engineering Program, National ICT Australia Ltd., School of Computer Science and Engineering, University of New South Wales,
Bay 15, Locomotive Workshop, Australian Technology Park, Garden Street, Eveleigh NSW 1430, Australiab School of Computer Science and Engineering, University of New South Wales, Australia
c Faculty of Information Technology, University of Technology Sydney, Australia
Received 9 January 2006; received in revised form 10 October 2006; accepted 31 October 2006Available online 11 December 2006
Abstract
This paper describes an approach for generating customized benchmark suites from a software architecture description following aModel Driven Architecture (MDA) approach. The benchmark generation and performance data capture tool implementation (MDA-Bench) is based on widely used open source MDA frameworks. The benchmark application is modeled in UML and generated by takingadvantage of the existing community-maintained code generation ‘‘cartridges’’ so that current component technology can be exploited.We have also tailored the UML 2.0 Testing Profile so architects can model the performance testing and data collection architecture in astandards compatible way. We then extended the MDA framework to generate a load testing suite and automatic performance measure-ment infrastructure. This greatly reduces the effort and expertise needed for benchmarking with complex component and Web servicetechnologies while being fully MDA standard compatible. The approach complements current model-based performance predictionand analysis methods by generating the benchmark application from the same application architecture that the performance modelsare derived from. We illustrate the approach using two case studies based on Enterprise JavaBean component technology and Webservices.� 2006 Elsevier Inc. All rights reserved.
Software technologies such as Enterprise Java Beans(EJBs), .NET and Web services have proven successful inthe construction of enterprise-scale systems. However, itremains a challenging software engineering problem toensure that an application architecture can meet its speci-fied performance requirements.
Various performance analysis models with predictioncapabilities have been proposed to evaluate architecturedesigns during early phases of the application development
0164-1212/$ - see front matter � 2006 Elsevier Inc. All rights reserved.
doi:10.1016/j.jss.2006.10.052
* Corresponding author. Address: Empirical Software EngineeringProgram, National ICT Australia Ltd., School of Computer Science andEngineering, University of New South Wales, Bay 15, LocomotiveWorkshop, Australian Technology Park, Garden Street, Eveleigh NSW1430, Australia. Tel.: +61 2 83745523; fax: +61 2 83745520.
cycle (Balsamo et al., 2004). Utilizing these models requirestwo distinct activities to be carried out by the applicationarchitect. The first requires the development of specificanalytical models based on the application design. Thesecond must obtain parameter values for the performancemodel using measurements or simulation. Both these activ-ities require significant additional effort and specific exper-tise in performance engineering methods. Hence, we believethese are key inhibitors that have prevented performanceengineering techniques from achieving wide-spread adop-tion in practice (Balsamo et al., 2004).
With the growing interest in Model Driven Architecture(MDA) technologies, attempts to integrate performanceanalysis with MDA and UML have been made, aimingto reduce the performance modeling effort required. TheOMG’s MDA standard defines a way of transforming busi-ness domain models into Platform Independent Models
266 L. Zhu et al. / The Journal of Systems and Software 80 (2007) 265–282
(PIM) and then Platform Specific Models (PSM), andeventually to executable code. PSMs can also include a per-formance analysis model specific to a performance engi-neering method.
Consequently, recent work has attempted model trans-formation from UML design models to method-specificperformance analysis models. A more comprehensive andelaborate theoretical basis has been discussed in (Skeneand Emmerich, 2003b). This work has, to a large extent,improved on the earlier manually-oriented activities relatedto deriving analytical models from application designs.
Parameter values in these performance analysis modelsalso depend greatly on the underlying component andWeb service framework used to implement the application.One method to obtain and tune these parameters is to run abenchmark application on the framework. This approachhas proven to be useful (Gorton and Liu, 2003; Gortonet al., 2003; Liu, 2004) with component-based technologies.Running benchmark applications can also help in predict-ing and diagnosing performance problems, including iden-tifying bottlenecks, preliminary profiling and exploringcore application characteristics.
An effective benchmark suite includes a core benchmarkapplication, a load testing suite and performance monitor-ing utilities. In this regard, there are several limitations incurrent benchmarking approaches for performance analysis
1. Existing industry benchmark standards and suites (e.g.ECperf/SPECjAppServer and the TPC series) are notbroadly suitable for performance modeling and predic-tion for two reasons. First, they are mainly designedfor server vendors to showcase and improve their prod-ucts, rather than reflecting a specific application’s per-formance characteristics. The application logic in thesebenchmarks is fixed and impossible to adapt to assistin predicting performance for a specific applicationunder design. Second, these benchmark suites tend tobe expensive to acquire and complex to use.
2. Implementing a custom benchmark suite from scratch iscostly and tedious. This is largely due to the complexityof modern component containers and Web serviceframeworks. The task difficulty is exacerbated by thead hoc ways these technologies adopt for conductingperformance measurement. A benchmark implementa-tion usually requires a large amount of container andframework infrastructure-related plumbing, even for arelatively simple benchmark design. Interestingly, thischaracteristic is particularly amenable to MDA-basedcode generation, which is efficient at generating repeti-tive but complicated infrastructure code. However, onecapability that current MDA code generation frame-works lack is that they do not provide solutions to thegeneration of a load testing suite and performance datacollecting utilities.
3. The measurement data that needs to be collected for aperformance analysis model is usually complicated. Aminimal approach is typically preferred over a collect-
all approach in order to reduce measurement overhead.This requires measurement configurations to be con-stantly revised against design models and analysis mod-els which are being iteratively refined. Secondly, timeseries based correlation between measurement items(e.g. resource usage and service time) needs to be speci-fied by referring to multiple model elements. An MDAapproach enables such model element annotationsthrough UML profiles. This makes fine tuning measure-ments against design and analysis model requirementseasier.
The aim of our work is to automate the generation ofcomplete benchmark suites including monitoring utilitiesfrom a design description. The input is a UML-based setof design diagrams for the benchmark application, alongwith a load testing suite modeled in the UML 2.0 TestingProfile. The output is a deployable benchmark suite includ-ing the core benchmark application, load testing suite, per-formance data collecting utilities and configuration files forexternal container/framework specific monitoring and pro-filing utilities.
Our work complements current performance analysisapproaches as shown in Fig. 1. Existing approaches usuallystart with a PSM. The PSM is then annotated with a per-formance analysis profile for a specific performance analy-sis method. The model is then transformed to a proprietarylanguage format using XSLT. To populate the parameters,a benchmark application and associated monitoring utili-ties are built manually. In our approach, a PIM design isannotated with three types of profiles: a platform specificprofile, a performance profile and a tailored UML 2.0 Test-ing profile. Minimal references among the profiles are cap-tured using tagged values. A benchmark suite is thengenerated using all the profiles. Monitoring utilities havethe information on what to collect for what analysis modelparameters. Measurement results can then be used directlyfor populating analysis model parameters. Details of theanalysis model generation and parameter population ispresented in a separate paper (Liu et al., 2006).
To demonstrate the approach, two platforms have beenselected that represent widely used target technologies inenterprise systems. These are the Java 2 Enterprise Edition(J2EE) component framework and the Axis Web serviceplatform (Apache, 2005). By having a single platform inde-pendent model with minimal platform dependent markups,different deployable customized benchmark applicationscan be generated for different platforms, as we show in thispaper. This demonstrates one of the central benefit ofMDA, namely productivity gains through model reuse. Inaddition, executing the generated benchmark applicationproduces performance data in an analysis friendly format,along with automatically generated performance graphs.
Our approach has a number of unique benefits:
• The generated benchmark suite is based on a design thatclosely corresponds to the application of interest, and
L. Zhu et al. / The Journal of Systems and Software 80 (2007) 265–282 267
hence it captures the unique characteristics of theapplication. This should lead to the benchmark produc-ing more representative measures of the eventualapplication.
• Model driven code generation hides the complexities ofthe benchmark implementation from architects, andhelps them focus on analyzing the benchmark resultsthat are automatically produced. It also greatly reducesthe complexity behind the load testing suite and frame-work-specific performance data collecting utilities,which in many cases can take more time to understandand develop than the benchmark application itself(Grundy et al., 2005).
• The approach derives the benchmark application fromthe same application model that the performanceanalysis model is derived from. This makes it possible touse the performance measurement data for analyti-cal model validation and tuning model parameter val-ues. This essentially complements the performanceanalysis framework proposed in (Skene and Emmerich,2003b).
• Following MDA standards, including the UML 2.0Testing Profile, and using existing open source MDAframeworks significantly reduces the learning curve ofthe approach. It also takes advantage of existing codegeneration ‘‘cartridges’’ exploiting the latest componenttechnologies. The wide range of interoperable UMLmodeling tools (due to the MDA/UML compatibilitystandard) also makes the approach more amenable toadoption in practice.
• A single PIM for the application logic is used for gener-ating different platform specific infrastructures andbenchmark applications. Only minimal platform-specificproperty markup is required, and these are separatedwith the PIM.
2. Related work
2.1. Performance analysis with MDA
It has been argued that the MDA approach is a suit-able for facilitating performance analysis of large scaleenterprise systems (Skene and Emmerich, 2003a) since it‘‘permits natural and economical modeling of design and
analysis domains and relationships between them, support-
ing both manual and automatic analysis’’. Some research-ers have used MDA in performance analysis (Yilmazet al., 2004; Weis et al., 2004; Rutherford and Wolf,2003b; Marco and Inverardi, 2004), and typically focuson deriving analytical models from UML design models.A UML design model with appropriate profilesapplied can be transformed into a specific analyticaltechnique based proprietary model for further analysis.Most of these model transformations are based on XSLT.This means the mapping and transformation informationis tangled within the XML query and transformationlanguage, which has limitations for representing andvalidating mapping relationships (Czarnecki and Helsen,2003).
A more comprehensive framework has been proposed in(Skene and Emmerich, 2003b). It too advocates represent-ing analytical performance models in UML using profiles.Thus, deriving analytical models from design modelsequates to standard model transformation in MDA. Thishas various standardization, validation and tooling advan-tages over using XSLT to transform designs into proprie-tary models.
Analytical model-based performance analysis can notwork without data to populate the model parameters. Pop-ulating parameters must utilize techniques such as simula-tion or estimation based on experience or historical data.
268 L. Zhu et al. / The Journal of Systems and Software 80 (2007) 265–282
These techniques require an in-depth understanding of thebehavior of the actual system components and theyencounter difficulties if applications use black box frame-works, which is common for most applications runningon commercial component-based application servers orWeb service frameworks.
In such applications, measurements in the form ofbenchmarking and prototyping (Grundy et al., 2004) areused to obtain valuable information for architects.Comprehensive prototyping can however be expensive.To further exacerbate the problem, multiple benchmarkingapplications need to be constructed for different targetplatforms for comparison or deployment considerations.Industry standard benchmark results can not usually beused because the results are specific to the benchmarkapplication itself, making it difficult to sensibly infer usefulperformance characteristics about the application underdesign. Combining model based analysis with small scalecustomized benchmarking has been introduced to solvethis problem (Liu, 2004). This approach can work on dif-ferent levels. Benchmarking and prototyping results can becombined with model-based estimation as a way of build-ing confidence in performance predictions and ruling outpotential inaccuracy. Benchmarking and prototyping datacan also be directly fed into a performance model for moreaccurate prediction. Some recent research has producedpositive results (Liu and Gorton, 2004).
We argue that deriving a customized benchmark appli-cation from the same application architecture design asthe performance models are derived has great potentialfor validating and calibrating performance prediction mod-els. This approach integrates customized benchmark gener-ation and performance analysis model transformation intoa single MDA-based approach.
2.2. Benchmark generation
There are a large number of code generation techniquesand generator frameworks (Czarnecki and Helsen, 2003)that can be used in benchmark suite generation. We choosea model driven approach because code can be generatedfrom architecture designs directly. This creates semanticlinks between our generated benchmark suite code and per-formance analysis models since they derive from the sameapplication design model. Some pioneering work has beendone on generating benchmark and prototyping applica-tions using models, as in (Grundy et al., 2001, 2004) (Liuet al., 2002; Rutherford and Wolf, 2003a). However, thesehave several limitations:
• The code generators for the chosen technologies arebuilt from scratch by the researchers. They do not utilizeany extensible generator frameworks, or draw upon thelarge pool of existing code generation ‘‘cartridges’’ forthe latest technologies that are maintained by an activecommunity. When code generation cartridges are notexploited, any change to the chosen target technology
or the introduction of a new technology requires signif-icant extra work from the researchers.
• These methods do not follow MDA standards. Most ofthem are built as proprietary modeling tools. Althoughsome have used generic UML modeling tools, they usethem to model proprietary modeling concepts. Themodels derived in this way are very different fromUML architecture models in practice, and thus becomethrow-away artifacts. Consequently, existing industryexperience with UML and code generation is not lever-aged, making the code generation tasks for performanceengineering an additional activity for developers to carryout, rather than a step in an incremental developmentprocess. Not following MDA may also compromisetool interoperability and semantic model traceabilitybetween derived models.
• The load testing part of the benchmark suite can not becomprehensively modeled compared to using the UML2.0 Testing Profile. The latter distinguishes different test-ing elements (e.g. test context, test cases, data pool, datapartition) within a testing environment. This makes loadtest suite modeling more modular, reusable and modifi-able. Above all, it is standards-based.
Our approach directly addresses these limitations, as theremainder of the paper explains.
2.3. Performance measurement
Performance measurement for a benchmark suiteincludes end to end response time, throughput measure-ment and application server related performance measure-ment. For end to end performance data, the applicationneeds to be instrumented or a profiler used. Both take sig-nificant software engineering effort.
In our approach, the load testing suite is modeled in theUML 2.0 Testing Profile. A deployable implementation ofperformance data collection utilities for response time andthroughput are automatically generated in the load testingclient. Executing the application causes performance datato be collected as part of the test execution, with perfor-mance data displayed in generated graphs.
Server-side performance related data can typically onlybe obtained using the particular component container’smanagement tools. These are currently mostly proprietary.However, this is changing as containers expose perfor-mance related information through programmaticallyaccessible management components. For example, inJ2EE, JMX-based (Java Management Extension) resourcemonitoring is becoming widely used and standardized. Asimilar approach is starting to be adopted in container-based Web service technologies (e.g. Enterprise ServiceBus (ESB)) and standardized through Web Service Distrib-uted Management, (WSDM) (OASIS, 2005) though theyare still in a very early stage. In our approach, we exploitthis new capability with the J2EE WebLogic applicationserver in one case study. We use either configuration files
L. Zhu et al. / The Journal of Systems and Software 80 (2007) 265–282 269
or scripts generated from UML design models using MDAto monitor application server related performance data.
3. Customized benchmark generation using MDA
The overall structure of the benchmark generation sys-tem and related process workflow is presented in the boxedarea in Fig. 2. It also shows on the left side of the diagramthe relationship with model-based performance prediction.
An application design in UML must be transformedmanually or with tool assistance into a customized bench-mark UML design model. This design usually representsthe core characteristics of the application that are deemedby the architect to be the most performance critical. Thecriteria for this transformation are beyond the scope of thispaper, as they depend on specific needs and characteristicsof the project and performance analysis techniques.
The benchmark UML design model begins with a PIMwhich reflects the application logic. The benchmark UMLdesign model is then annotated with UML profiles for codegeneration, and a load testing suite is modeled using theUML 2.0 Testing Profile. This UML model is thenexported using XMI and becomes an input to theAndroMDA tool framework. We have extended theAndroMDA framework with a new cartridge to generatea load testing suite and associated performance monitoringfunctionality. A cartridge is a collection of meta-model def-initions (XML files), code generation handlers (codelibraries) and templates. It can process model elements that
Fig. 2. Model driven bench
have specified stereotypes and tagged values or model ele-ments that meet certain conditions.
Along with exploiting existing cartridges, a completedeployable customized benchmark suite can be generatedthat has the capability for extensive performance measure-ments. The same application design can also be trans-formed into an analytical performance model. Themeasurements obtained by the benchmark suite can beintegrated with the performance model and used to vali-date or improve its results. Semantic mappings and explicitmodel transformation rules provided by the MDAapproach make such integration straightforward and sys-tematic. However, integration with analytical models isbeyond the scope of this paper.
3.1. Development environment
We use an open source extensible framework, forMDA based code generation. The reasons for this aretwofold:
• The success of any code generation framework dependson the range of generation capabilities available, alongwith the extensibility of the framework itself.AndroMDA satisfies both of these requirements. Exist-ing cartridges are maintained by a community of activedevelopers. It also has no intrinsic limitations on extend-ing it to platforms other than the current J2EE and Web(service) platforms.
mark suite generation.
270 L. Zhu et al. / The Journal of Systems and Software 80 (2007) 265–282
• For a model driven approach to generate deployablecomponents, some implementation details need to becaptured at the model level. This makes abstract model-ing harder and models cluttered, as models should be areasonable abstraction devoid of as many details as pos-sible. AndroMDA separates UML and generated codefrom the manually provided business logic implementa-tion in different directories. This allows us to have botha code generation capability and abstract modeling atthe same time. This separation also makes iterativedevelopment possible, which is essential in practicalmodel-driven development.
We consequently have extended AndroMDA to supporta subset of the UML 2.0 Testing Profile for load test suitegeneration. Based on the extended AndroMDA, bench-mark designers can model their own benchmark applica-tion along with a load testing suite in UML. AndroMDAtakes XMI outputs representing the UML design and gen-erates deployable code using available code generation car-tridges and our cartridge extensions.
3.2. Benchmark application generation
The core benchmark application generation simplyexploits MDA development techniques using AndroMDA.The principle behind AndroMDA is to generate as muchcode as possible from marked PIMs. PIMs are modeledin a UML profile with platform independent stereotypeslike ‘‘Entity’’, ‘‘Service’’ and any necessary persistenceinformation. PIMs can also be annotated with platformspecific tagged values.
After modeling, AndroMDA generates all necessarysource files including business method interfaces and imple-mentation skeletons. The implementation skeletons arestored in a separate directory so future code re-generationwill not override the skeletons.
Modeling and generating the benchmark application isnot therefore a distinct engineering step from normal devel-opment activities. It can be considered as one of the steps inan incremental development process instead of a throwaway performance prototyping activity. One PIM modelcan also be used to generate different deployable applica-tions for different platforms with little modification. Thiscan greatly reduce the cost and consequently the hurdleof performing performance engineering in practice.
3.3. Load test suite generation
We model the load testing behavior using the UML 2.0Testing Profile. This profile is an OMG standard, represent-ing a comprehensive superset of existing widely used testingframeworks such as JUnit. Currently however, there is notest generator available based on the UML Testing Profile.1
1 The Eclipse Hyades project, which will eventually fully support it interms of modeling (not automatic generation), remains in a nascent state.
To develop a full test generation framework according tothe profile is a major effort, and beyond our availableresources. Hence we focused merely on modeling load testsusing a subset of the profile and producing a default imple-mentation of the model including both test logic and testdata.
To this end, we have implemented the following stereo-types in the UML 2.0 Testing Profile through extendingAndroMDA:
• SUT (System under Test): This represents the applica-tion to be tested. It consists of one or more objects.The SUT is exercised via its public interface by TestComponents. In our approach, the SUT is the entrypoint for the system (e.g. a remote session bean inJ2EE) which will be exercised for load testing purposesonly.
• Test Context: This is a collection of test cases. In ourapproach, it consists of load test cases with a defaultimplementation of loadTestAll(), which exercises allthe business methods on the SUT.
• Test Component: Test components are classes of a testsystem. A test component has a set of interfaces viawhich it communicates with the SUT. Since we providea default implementation of load test cases, users do nothave to model their own Test Components. These TestComponents are manifested as default method imple-mentations within the loadTestAll() method. Userscan choose to model their own Test Components, whichwill be treated as any normal class communicating withthe SUT.
• Data Pool: A data pool is a collection of explicit valuesthat are used by a test context or test components duringtesting. We use a data pool to model the load testingdata used when calling each method on the SUT. Thesystem will automatically generate random test databased on the data type and range specified. The datapool can also be used to specify the transaction percent-age mix for all business methods by using tagged valuesassociated with the stereotype. These configurationcapabilities allow users to accurately and easily modelthe anticipated work load.
• Data Partition: Data partitions are logical values for amethod parameter used in testing. It typically definesan equivalence class for a set of values. We use a DataPartition to partition the Data Pool into specific sectionsfor load testing. A Data Pool is general enough for othertesting purposes, including functional testing.
• Test Case: A test case is a specification of one or moretest scenarios for the system. It includes what to testwith which inputs and the results expected under variousconditions. Test cases are modeled within a Test Contextthat consists of multiple test cases. In our approach, aloadTestAll() test case is implemented by default. Itexercises all public methods on the SUT using randomlygenerated data modeled in a Data Pool and a selectedData Partition.
Fig. 3. Extending AndroMDA to support UML 2.0 Testing Profile.
L. Zhu et al. / The Journal of Systems and Software 80 (2007) 265–282 271
Fig. 3 illustrates the subset of the UML 2.0 Testing Pro-file modeled in MagicDraw 8.0 as metafacade extensions inAndroMDA. They all extend the existing AndroMDAmetafacade to take advantage of the underlying frame-work. Each metafacade also includes a set of associatedtagged values to specify detailed configurations (we omitthe details of these extensions for clarity). The UML modelcan be exported as a profile which can be later used in aload testing suite modeled along with the benchmark appli-cation business logic.
3.4. Incremental and spike load simulation
The initial set of test data is modeled rather simplisti-cally. For example, users can only indicate an averagetransaction mix in the Data Pool. This is usually enoughfor normal load scenarios. However, many performanceproblems occur when a sudden request spike hits theapplication or the request load gradually increases over aperiod of time. To explore such scenarios, our cartridgesupports a set of tagged values to reflect the common prac-tice and terminology used in the performance engineeringcommunity (Gomez et al., 2005; TPC, 2004). Some exam-ples are:
• config.processes: The number of processes the load gen-erator should start.
• config.threads: The number of threads that each processspawns.
• configr.runs: The number of runs of the test each threadperforms.
• config.duration: The maximum length of time in milli-seconds that each process should run for.
• config.initialProcesses: The initial number of processesto start with.
• config.processIncrement: The number of processes toincrease or decrease for an incremental time interval.
• config.processIncrementInterval: The time intervalbetween starting up or stopping new processes.
• config.stabilizationperiod: An estimated time before asteady state period is reached. How to estimate the start-ing time of the steady state period is specific to the test-ing environment. Performance data collection onlycommences after the stabilization periods.
Such values are directly configured on the modelthrough tagged values. A configuration file is then gener-ated on the first round of code generation. Subsequently,if only the configuration needs to be changed, it is possibleto either change the configuration file directly or let thecode generator re-generate the file without affecting the restof the application.
The AndroMDA extension for load test modeling andgeneration results in a new cartridge that can be put intothe AndroMDA cartridge repository. It works with allother existing server-side generation cartridges. Our car-tridge includes some supporting facilities and a libraryof handlers for code generation written in Java. Thisfacilitates the reuse of existing cartridges and frameworkfacilities. It also enables template writers to access themetafacades in templates using tags. The separation ofOO based metamodeling with template based code genera-tion provides flexibility and ease of use.
We provide a complete template for generating a defaultimplementation of the loadTestAll() test case with ran-domly generated data based on a data pool model. A data-base seeder is also generated to repopulate the databasebefore a new test. These capabilities greatly reduce theextra effort involved in using the suite in load testing activ-ities, in which performance testing is the main interests ofthe software engineer.
3.5. Performance data collection
In the above two sections, we have explained how wehave used MDA principles to generate a benchmark suiteincluding a core benchmark application and a load test-ing client. We also need to collect performance data foreither informal analysis or to feed in to a performance anal-ysis model. The data we need falls into two categories,namely:
3.5.1. Application related profiling informationThis includes end to end timings for requests and counts
on method calls, CPU workload and memory status, gar-bage collection counts and so on. Much of this data mustbe obtained through running a profiler and system utilities.In our default load testing implementation, the end to endresponse time distribution, average response time andthroughput are automatically recorded by the client. Aresponse time distribution graph for each run is also auto-matically generated. This data is crucial for performanceanalysis, and is easy to obtain if the default implementationis used.
#Get Runtime info for Session Bean and MDB ls /EJBPoolRuntime ejbpool = $LAST for $ejb in $ejbpool do sb1 = get /EJBPoolRuntime/$ejb/AccessTotalCount sb2 = get /EJBPoolRuntime/$ejb/IdleBeansCount sb3 = get /EJBPoolRuntime/$ejb/BeansInUseCurrentCount end
Fig. 5. JMX-based server side monitoring using scripts.
272 L. Zhu et al. / The Journal of Systems and Software 80 (2007) 265–282
3.5.2. Application server (middleware and framework)
related information
This includes health indicators of the application serveror framework itself and component related informationthat may have performance implications. For example,when testing EJBs, the component pool, runtime cache sta-tus and data source pool usage can be inspected. Thisinformation is typically collected through an EJB con-tainer-proprietary user interface and with logging andexport functions, and the effort required varies immenselybetween different EJB platform implementations.
As mentioned in Section 2.3, several J2EE containershave recently exposed container related information usingJMX MBeans for both API based and scripting access.With the help of JMX based container monitoring, wecan automate the container performance monitoring usingscript and configuration file generation. Importantly, thegeneration templates only need to be written once for eachcontainer and can be reused for different applicationdesigns.
In our approach, two styles of accessing the informationare available for the J2EE platform:
• We can use the JMX Java API to query the MBeans
directly. A generic MBean information query and collec-tion program runs independently of the benchmarkapplication, and reads a generated configuration file.The configuration file includes the name of the MBean
providing the performance information, methods to becalled and all necessary parameters. The data collectingprogram is J2EE container specific and needs to bedeveloped once for each container. With MDA, thisrequires a generation template. The configuration filecan then be automatically generated from the UMLmodel for different application designs. Fig. 4 is a snip-pet of such a generation template.
• A more convenient solution is to leverage the scriptingshell provided by some J2EE containers. In this case,no JMX-based data collection program is involved.All that needs to be generated is appropriate scriptsfor collecting the measurement of interests. For exam-ple, third party applications like wlshell for WeblogicJMX and the newly integrated WLST (BEA, 2004) forWeblogic 9.0 provide a scripting shell for accessing theinformation in MBeans. Fig. 5 is an example of the gen-
# methods for Session and MDB Pool <XDtMethod:forAllMethods> <XDtMethod:methodName/>:<XDtMethod:methodNameWithoutPrefix/> </XDtMethod:forAllMethods> </XDtClass:forAllClass> … <XDtEjbSession:forAllBeans> EjbPoolRuntime:<XDtEjbSession:concreteFullClassName/> </XDtEjbSession:forAllBeans>
Fig. 4. A (partial) configuration generation template.
erated scripts for collecting EJBPoolRuntime perfor-mance information.
We provide both shell script and configuration file gen-eration templates for the Weblogic platform. We assumeby default the target of the performance measurement willbe all the beans in the container and business methods sup-ported. Architects can tailor this by commenting outunwanted parts in the generated files.
4. Case studies
We use the Stock-Online system (Gorton, 2000) as acase study to illustrate our approach. Stock-Online is aproven benchmark for evaluating various middleware plat-forms. The original system was developed for differentJ2EE platforms. Due to platform differences, there was sig-nificant effort involved in implementing the same design fordifferent platforms, and keeping the benchmark applicationin line with component technology advancements requiredsignificant ongoing effort. Hence, it makes sense to useStock-Online as a case study to demonstrate the amountof effort that can be saved utilizing MDA developmentand code generation.
The case study’s aim is to generate the Stock-Online sys-tem, including a load testing suite, purely from UML mod-els. To this end, two variations are generated using twoJ2EE platforms, for the WebLogic and JBoss platformsrespectively, both using the same Oracle database backend.To demonstrate the effectiveness of our approach, the sameUML model with minimal change is then used to generatea benchmark application for a Web services platform. Theresult demonstrates the amount of effort saved across ven-dor implementations in the same standard (two differentJ2EE application servers) and across totally different plat-forms (J2EE and Web services platforms).
4.1. Benchmark application modeling for J2EE
The server side logic is modeled using the UML andAndroMDA profiles shown in Fig. 6. Domain componentscorresponding to persistent entities are marked using thestereotype �Entity�. Components which act as businessprocess facades are marked using the stereotype�Service�.There are also tagged values associated witheach stereotype for component attributes such as persis-tence, remote/local interface and other configuration
Fig. 6. Stock-Online benchmark application server side modelling.
L. Zhu et al. / The Journal of Systems and Software 80 (2007) 265–282 273
settings. Dependencies among �Entity� and �Service�elements are marked using �EntityRef� if a referenceexists between them. All of these values are J2EE platformindependent. �ValueRef� and �ValueObject� are ste-reotypes designed for a common J2EE pattern, namelythe Value Object pattern. This is currently incorporatedinto the J2EE cartridges.
We omit these tagged values in the presentation toreduce cluttering. In this case study, we do not use anyplatform specific features, so no platform specific annota-tions need to be included on the UML model. Hence thesame design model is used for the both target platforms.
4.2. Modeling the load testing suite for J2EE
The load testing suite for Stock-Online is modeled usinga subset of the UML 2.0 Testing Profile with support fromour extensions to AndroMDA. The load testing suitemodel for Stock-Online is shown in Fig. 7.
The load testing entry point is the Broker bean. It is thefront end component of the system under test, which ismarked using �SUT�. ClientDemo is the �TestCon-text� which consists of test cases. Only the default loadTe-stAll() test case is included with its default implementationto be generated. For simplification, all the test data is mod-
eled in TrxnData from which �DataPartition� Load-
TestingTrxnData is derived. In more complicatedsituations, several test data classes may exist. In�DataPool� TranDeck, we can also indicate the transac-tion mix percentage as tagged values shown in Fig. 8. Forexample, queryStock represents 34.9% of all transactionsand getHolding represents 11.7%. This data will be usedin randomly generating test data which simulates the realwork load.
We then export both the core benchmark applicationand load testing suite UML diagrams into XMI compatibleformats. Since we are not using any application server spe-cific modeling information in our model, the exportedUML model will be used for both WebLogic and JBosscode generation.
4.3. Customized benchmark generation, deployment and
execution
By running the AndroMDA wizard, two EJB projectdirectory structures are generated for WebLogic and JBoss,respectively. These consist of a MDA directory for storingthe exported UML model, and directories for storingsource code and the future deployable application. Projectproperty files for specifying dependencies on the targeted
Fig. 7. Stock-Online benchmark load test model.
Fig. 8. Transaction type and percentage mix modeled using �DataPool�.
274 L. Zhu et al. / The Journal of Systems and Software 80 (2007) 265–282
platforms and other deployment configurations are alsogenerated. We then copy the exported UML model intothe designated MDA directory and run the code generationengine.
Source code is generated based on the UML model. Forthe client side, the complete load testing suite is generatedwithout the need for further modification. The load testinglogic and random test data is derived from the load testingUML model and method signatures of the server-side com-ponent interface.
The server-side component code is generated followingEJB best practices, including value objects. Business logicinside each component method needs to be manually addedby placing implementation code into a separate directory.This prevents overriding manual modification by subse-quent code generation iterations. It also separates theimplementation from the specifications (interfaces) which
derive from the UML design. After adding the server sidebusiness logic code, the AndroMDA framework generatesthe deployable package. The generated application isalmost a carbon copy of the manually written Stock-Onlinesystem (Gorton, 2000). The application is then deployed inthe following environment (Table 1).
4.4. Performance output for two J2EE platforms
The benchmark test workload, defined by the number ofconcurrent requests, is specified in the workload generator.We then run load tests and obtain the following perfor-mance results automatically:
• Response time distributions in both log files and chartbased graphs.
• Average response time for each request.
Table 1Hardware and software configuration
Machine Hardware Software
Client Pentium 4 CPU 2.80 GHz, 512M RAM Windows XP, JDK1.4Application and
WindowsXP Prof. JDK1.4 with settings –hotspot, –Xms512m and–Xmx1024m, Oracle 9i and thin JDBC driver
L. Zhu et al. / The Journal of Systems and Software 80 (2007) 265–282 275
• Application throughput in terms of transactions persecond.
Fig. 9 shows example response time distribution chartsfor two application servers under a workload of 100 con-current clients.
By utilizing the JMX-based monitoring and data collec-tion techniques described in Section 3.3, many server sideinternal parameters can be obtained. For example,Fig. 10 shows the performance parameters automaticallycollected from benchmark execution for 100 clients onWebLogic application server with 20 server threads and20 database connections.
The performance data collected in this example is thesame as we have been collecting in conducting variousempirical studies on evaluating architecture candidates
Fig. 9. Samples of response time distribut
and platforms. Interested readers can refer to (Liu,2004) for the details of the type of data collected andhow to interpret the data for performance compari-sons. Using the technology described in this paper, wenow have a tool for automatically generating the coreapplication and load testing components of benchmarksfollowing MDA, and efficiently capturing the performancedata.
4.5. Benchmark application modeling for Web services
For simplicity, we present only the different model partsfrom the J2EE case study since the majority of the modelspresented to the end users are identical.
Fig. 10 shows the load test modeling and the systemunder test (SUT) entry component (Broker).
ion on two J2EE application servers.
Fig. 10. Parameters collected based on automatically generated JMXmonitoring configurations.
276 L. Zhu et al. / The Journal of Systems and Software 80 (2007) 265–282
On server side, an extra �WebService� stereotype isused to annotate the Web service class. By default, all theoperations can be assessed as Web services. If only selectedmethods need to be exposed as Web services, a methodlevel stereotype �WebServiceOperation� can be used.In Web service modeling, many performance parameterscan be made through configurations on the model directly,such as WSDL binding styles (RPC/Document) and bind-ing use styles (Encoded/Literal). As annotated on the dia-gram through tagged values on the Broker class, we usethe doc/literal wrapped pattern. The wrapped pattern is aslightly improved variation of the commonly used doc/lit-eral style. This is considered the best configuration for per-formance. Such tuning largely depends on the server sidecartridge. However, the values can be queried by the loadtesting client to conduct necessary style-specific testingand performance measurement.
There is virtually no change on the client side modelingexcept the configuration of the endpoint through a taggedvalue. All the extra changes involved are encapsulated inthe client cartridge. If a Web service targeted model isdetected, the cartridge will generate Web service specificlook-ups and a Web service client while the rest of the test-ing logic and data is untouched.
4.6. Performance output for Axis Web service platform
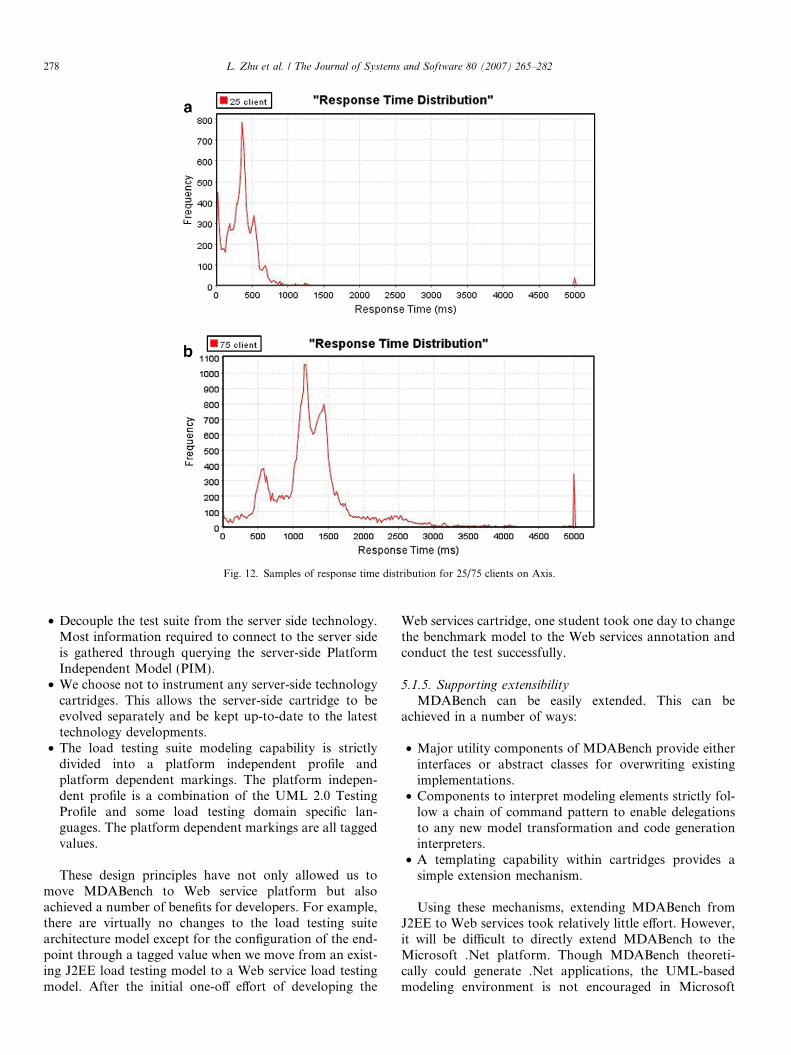
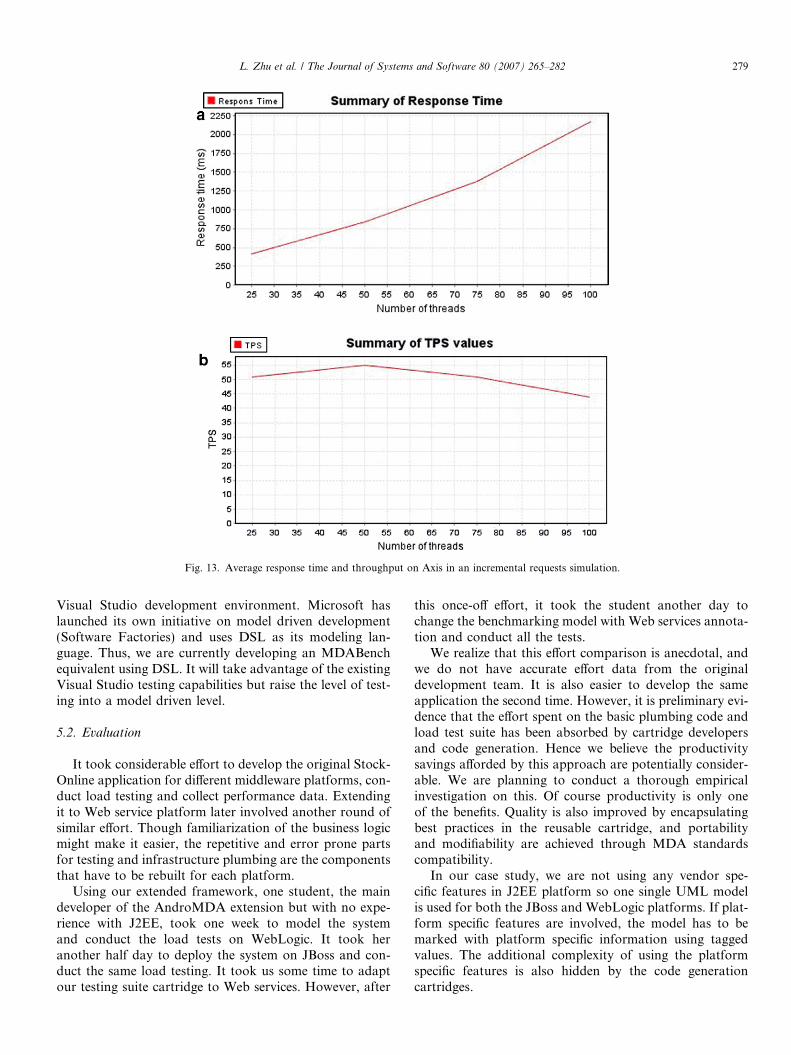
The same set of performance data is collected for theWeb service benchmark application. Fig. 11 shows theresponse time for 25 and 50 clients, respectively. The spikesat the end of the 5000 ms indicate all response times longerthan 5000 ms.2 Fig. 12 shows the average response timeand TPS in terms of number of threads in an incrementalrequests simulation scenario (Fig. 13).
Comparisons between different platforms are beyondthe scope this paper.
Note that MDABench generates metrics such as timingdetails and distribution statistics. Distribution statisticsallows a more in-depth view of the performance resultscompared to average response time and throughput. Theseenable us to identify critical irregularities and their causesduring test runs of the benchmark. We also provide facili-
2 The range can be easily changed, and all raw response times arecollected in text files for possible further analysis.
ties to store the timing details. Timing details capture thetime to execute each individual operation and are recordedin the results repository. This does of course incur perfor-mance and storage overhead. However, the timing infor-mation allows further correlation with other internal orexternal events which may have significant performanceimpacts. Performance collection utilities are based on ourown extensive experience on performance testing.
There are no JMX equivalents and performance APIs inAxis for internal performance or service performance mon-itoring. Thus we did not generate performance monitoringconfigurations files for obtaining such data as we did forJ2EE platforms.
4.7. Applying MDABench in the real world
We recently had the opportunity to test MDABench in aWeb service-based e-Government project. The systemallowed Australian tax payers to retrieve their medicalcosts for a given tax year directly from a Web service forlodging a tax return. Our aim was to assess the perfor-mance potential of the Web services involved.
We were able to use the MDABench prototype in themeasurement planning phase. We created test data modelsalong with transaction mix and exception mix requirementsusing the UML 2.0 Testing profile as shown in Fig. 14. Wethen used the model to communicate the essential measure-ments to system’s software engineers. Although we werenot be able to deploy MDABench in the production envi-ronment due to security reasons, this exercise has givenus considerable insights into using such a tool in real world.The lesson learned will be discussed in the next section. Thefull experience of this project is reported in Liu et al. (sub-mitted for publication).
5. Discussions
5.1. Lessons learned
5.1.1. Tailoring UML is not always the best way
UML profiles or Domain Specific Languages (DSL) areoften used to serve very different purposes. That includesinventing new notations, facilitating task automation,adopting product lines, constructing GUIs, data structuretraversal and so on. A different purpose requires a differentdesign strategy. We identified the goals of our UML profileas the following:
• Add new visual notations for the performance testingdomain.
• Transform visual notations to code for task automation.• Adopting a product line for performance testing for dif-
ferent platforms.
These goals require a strategy based upon abstractingconcepts from existing infrastructures and best practices,and mapping them to modeling elements (stereotypes and
Fig. 11. Benchmark modeling for the Axis Web service platform.
L. Zhu et al. / The Journal of Systems and Software 80 (2007) 265–282 277
tagged values). Since we are tailoring UML 2.0 Testingprofile to achieve this, the mapping was not always smooth.The UML 2.0 Testing profile is modeled upon a unit testingmindset in a local environment. It lacks some of the con-cepts in distributed testing coordination and data collec-tion. We therefore had to insert these concepts ‘behindthe scenes’ in templates rather than using explicit modelelements. We are currently exploring Microsoft’s DSL tomodel these concepts explicitly.
5.1.2. A flexible test data modeling and generation
tool is very valuable
Existing performance tools have scripting and testrecording features, but they lack test data modeling capa-bilities and are extremely limited in features for test datageneration. During our projects, gaining full access toany real data for measurement was either prohibited orinfeasible. Using generated test data is therefore the onlyoption. To represent the system as realistically as possibleand reduce testing effort, we need flexible test data
modeling and generation tools to produce high qualitydata for a large number of requests types and theircombinations.
5.1.3. A distributed unified measurement utility
is very valuable
During our projects, we found most ad hoc measure-ments were performed at different times, under differentruntime conditions and using different tools. Correlatingbetween these measurements was consequently very diffi-cult. A unified measurement utility that can collect all nec-essary measurements at the same time would significantlyincrease the usability of the collected data. MDABenchhas the capability to conduct such distributed measure-ments in a unified framework.
5.1.4. Supporting reusability
When we first developed MDABench, we focused ourattention on the J2EE platform. This implementationadhered to three design principles:
Fig. 12. Samples of response time distribution for 25/75 clients on Axis.
278 L. Zhu et al. / The Journal of Systems and Software 80 (2007) 265–282
• Decouple the test suite from the server side technology.Most information required to connect to the server sideis gathered through querying the server-side PlatformIndependent Model (PIM).
• We choose not to instrument any server-side technologycartridges. This allows the server-side cartridge to beevolved separately and be kept up-to-date to the latesttechnology developments.
• The load testing suite modeling capability is strictlydivided into a platform independent profile andplatform dependent markings. The platform indepen-dent profile is a combination of the UML 2.0 TestingProfile and some load testing domain specific lan-guages. The platform dependent markings are all taggedvalues.
These design principles have not only allowed us tomove MDABench to Web service platform but alsoachieved a number of benefits for developers. For example,there are virtually no changes to the load testing suitearchitecture model except for the configuration of the end-point through a tagged value when we move from an exist-ing J2EE load testing model to a Web service load testingmodel. After the initial one-off effort of developing the
Web services cartridge, one student took one day to changethe benchmark model to the Web services annotation andconduct the test successfully.
5.1.5. Supporting extensibility
MDABench can be easily extended. This can beachieved in a number of ways:
• Major utility components of MDABench provide eitherinterfaces or abstract classes for overwriting existingimplementations.
• Components to interpret modeling elements strictly fol-low a chain of command pattern to enable delegationsto any new model transformation and code generationinterpreters.
• A templating capability within cartridges provides asimple extension mechanism.
Using these mechanisms, extending MDABench fromJ2EE to Web services took relatively little effort. However,it will be difficult to directly extend MDABench to theMicrosoft .Net platform. Though MDABench theoreti-cally could generate .Net applications, the UML-basedmodeling environment is not encouraged in Microsoft
Fig. 13. Average response time and throughput on Axis in an incremental requests simulation.
L. Zhu et al. / The Journal of Systems and Software 80 (2007) 265–282 279
Visual Studio development environment. Microsoft haslaunched its own initiative on model driven development(Software Factories) and uses DSL as its modeling lan-guage. Thus, we are currently developing an MDABenchequivalent using DSL. It will take advantage of the existingVisual Studio testing capabilities but raise the level of test-ing into a model driven level.
5.2. Evaluation
It took considerable effort to develop the original Stock-Online application for different middleware platforms, con-duct load testing and collect performance data. Extendingit to Web service platform later involved another round ofsimilar effort. Though familiarization of the business logicmight make it easier, the repetitive and error prone partsfor testing and infrastructure plumbing are the componentsthat have to be rebuilt for each platform.
Using our extended framework, one student, the maindeveloper of the AndroMDA extension but with no expe-rience with J2EE, took one week to model the systemand conduct the load tests on WebLogic. It took heranother half day to deploy the system on JBoss and con-duct the same load testing. It took us some time to adaptour testing suite cartridge to Web services. However, after
this once-off effort, it took the student another day tochange the benchmarking model with Web services annota-tion and conduct all the tests.
We realize that this effort comparison is anecdotal, andwe do not have accurate effort data from the originaldevelopment team. It is also easier to develop the sameapplication the second time. However, it is preliminary evi-dence that the effort spent on the basic plumbing code andload test suite has been absorbed by cartridge developersand code generation. Hence we believe the productivitysavings afforded by this approach are potentially consider-able. We are planning to conduct a thorough empiricalinvestigation on this. Of course productivity is only oneof the benefits. Quality is also improved by encapsulatingbest practices in the reusable cartridge, and portabilityand modifiability are achieved through MDA standardscompatibility.
In our case study, we are not using any vendor spe-cific features in J2EE platform so one single UML modelis used for both the JBoss and WebLogic platforms. If plat-form specific features are involved, the model has to bemarked with platform specific information using taggedvalues. The additional complexity of using the platformspecific features is also hidden by the code generationcartridges.
Fig. 14. MDABench model for e-Government project.
280 L. Zhu et al. / The Journal of Systems and Software 80 (2007) 265–282
For the Web service platform, we have only collected thebasic response time and throughput data. The cartridge isalso capable of doing spike and incremental load simula-tion. Extra Web services specific performance data suchas message sizes can also be collected. There are no sophis-ticated APIs as in the J2EE component technologies forquerying platform internal performance related or servicerelated indicators. However, with the maturing of ESBplatforms and the adoption of WSDM standards, suchAPIs or configuration-based performance monitor areappearing. We are investigating how to further adapt ourcartridge to collect a more complete set of performancedata for Web service platforms.
Making changes to the design to generate a new versionof the benchmark is also simpler. If new business compo-nents and methods are introduced, new implementationcode needs to be added to the generated skeleton on theserver side. No change needs to be made on the client loadtesting part. Changing design elements like stateful/state-less beans or Web service binding styles are simply a matterof changing the UML model. All the changes will be prop-agated in the source code and deployment information.
In the process of developing our approach and imple-mentation, we integrated performance engineering best
practices from the various leading technologies andour own experience. The internal structured design ofthe load testing client is inspired by ECperf/SPECjAppser(ECperf, 2001). Performance metrics are based onindustry standards such as TPC-W (TPC, 2004). Perfor-mance collecting utilities are based on our own long expe-rience on performance testing. Incremental and spikesimulation are inspired by Grinder 3 (Gomez et al.,2005). All these best practices are essentially encapsulatedin the cartridge, and its use automatically supports thesebest practices through generated code structures andutilities. This is one of the main motivations behindMDABench.
Generating a benchmark application is essentially notdifferent from generating any software application. Abenchmark application usually either captures the perfor-mance critical parts of the full application or acts as away of exercising off-the-shelf component frameworkservices which you are interested in. By unifying bench-mark related performance work with normal applicationdevelopment in a single consistent environment, we facili-tate incremental design and development. This helps toincorporate performance engineering tasks into the SDLCwith minimal cost.
L. Zhu et al. / The Journal of Systems and Software 80 (2007) 265–282 281
5.3. Limitations
There are still several limitations of this approach:
• AndroMDA is generic enough to support platformsother than the existing J2EE and Web service platforms.Still, the existing cartridges are limited to these two dif-ferent types of platforms. The lack of .NET platformsupport has limited us from applying our approach toa wider collection of platforms. However, new thirdparty vendors such as ArcStyler have successfully pro-vided MDA support for .NET. On the other hand,Microsoft has integrated a model based modeling capa-bility (Domain Specific Modeling) in its new Visual Stu-dio, along with potential interoperability with UML.Because our philosophy is to integrate architecture dri-ven performance engineering into practical developmentenvironments, we are currently applying the same con-cepts presented in this paper to Microsoft DSLenvironment.
• The default implementation of the load testing suite isstill relatively simple. It covers only successful testingscenario generation. In real applications, performanceof exception handling and transaction rollback is alsoa major concern. Currently, users have to implementsuch scenarios manually. We are considering integratingthese both at the modeling level and in the default imple-mentation in future versions. We will also take advan-tage of some other interesting concepts in UML 2.0Testing Profile such as Arbiter and Verdict stereotypesfor determining the success of the test run.
6. Conclusion and future work
This paper has presented an approach to generate a cus-tomized benchmark application from architecture designsbased on the J2EE and Web service platform usingMDA. An implementation of this approach based onextending an open source MDA framework has beendescribed and demonstrated.
A benchmark design is modeled with platform indepen-dent models in UML. A corresponding load testing suite ismodeled following a subset of the UML 2.0 Testing Profile.Deployable code is then generated for both the core bench-mark design and its associated load testing suite. The coreapplication is generated by taking advantage of existing codegeneration cartridges maintained by the open source com-munity. The load test suite generator has been developedby the authors, and fully integrates with the core applicationgeneration. Case studies using EJB component technology(Weblogic/JBoss) and the Axis Web services platform forthe Stock-Online benchmark suite have demonstrated thetools and the generated outputs from load tests.
This approach has several significant advantages overproprietary model-based CASE tool environments forbenchmark generation. Using MDA and exiting open
source MDA frameworks reduces the learning curve andtraining effort required, and improves model traceabilityand tool interoperability. The default implementation andtest data generation saves a large amount of load testingeffort. The approach also complements existing model-based performance prediction methods by providing thepotential to use the benchmark results for calibrating andvalidating analytical performance models. The semantictraceability achieved through MDA makes this integrationeasier, and this remains a major objective of our futurework.
Acknowledgment
National ICT Australia is funded through the Austra-lian Government’s Backing Australia’s Ability initiative,in part through the Australian Research Council.
References
Apache, 2005. Apache Axis 1.3 Final. <http://ws.apache.org/axis/>.Balsamo, S., Di Marco, A., Inverardi, P., Simeoni, M., 2004. Model-based
performance prediction in software development: a survey. IEEETransactions on Software Engineering 30 (5), 295–310.
Czarnecki, K., Helsen, S., 2003. Classification of model transformationapproaches. In: Proceedings of the OOPSLA’03 Workshop onGenerative Techniques in the Context of Model-Driven Architectures.
ECperf, 2001. ECperf v1.1. <http://java.sun.com/j2ee/ecperf/index.jsp>.Gomez, P., Aston, P., et al., 2005. The Grinder V3.0-beta23. <http://
grinder.sourceforge.net/>.Gorton, I., 2000. Enterprise Transaction Processing Systems: Putting the
CORBA OTS, Encina++ and OrbixOTM to Work, Addison-Wesley.Gorton, I., Liu, A., 2003. Evaluating the performance of EJB components.
IEEE Internet Computing 7 (3), 18–23.Gorton, I., Liu, A., Brebner, P., 2003. Rigorous evaluation of COTS
middleware technology. IEEE Computer 36 (3), 50–55.Grundy, J., Cai, Y., Liu, A., 2001. Generation of distributed system test-
beds from high-level software architecture descriptions. In: Proceed-ings of the 16th Annual International Conference on AutomatedSoftware Engineering (ASE).
Grundy, J., Wei, Z., Nicolescu, R., Cai, Y., 2004. An environment forautomated performance evaluation of J2EE and ASP.NET thin-clientarchitectures. In: Proceedings of the Australian Software EngineeringConference (ASWEC).
Grundy, J.C., Cai, Y., Liu, A., 2005. SoftArch/MTE: generating distrib-uted system test-beds from high-level software architecture descrip-tions. Automated Software Engineering 12 (1), 5–39.
Liu, Y., 2004. In School of Information Technologies University ofSydney, PhD Dissertation.
Liu, Y., Gorton, I., 2004. Accuracy of performance prediction for EJBapplications: a statistical analysis. In: Proceedings of the SoftwareEngineering for Middleware (SEM).
Liu, Y., Gorton, I., Liu, A., Jiang, N., Chen, S., 2002. Design a test suitefor empirically-based middleware performance prediction. In: Pro-ceedings of the TOOLS Pacific.
Liu, Y., Zhu, L., Gorton, I., 2006. Model driven capacity planning:methods and tools. In: Proceedings of the Computer ManagementGroup Australia (CMGA), Sydney.
Liu, Y., Zhu, L., Gorton, I., 2007. Performance assessment for e-government services applications: an experience report. In: Interna-tional Conference on Software Engineering (ICSE), submitted forpublication.
282 L. Zhu et al. / The Journal of Systems and Software 80 (2007) 265–282
Marco, A.D., Inverardi, P., 2004. Compositional generation of softwarearchitecture performance QN models. In: Proceedings of the 4thWorking IEEE/IFIP Conference on Software Architecture (WICSA).
OASIS, 2005. OASIS Web Services Distributed Management (WSDM).<http://www.oasis-open.org/committees/tc_home.php?wg_abbrev=wsdm>.
Rutherford, M.J., Wolf, A.L., 2003a. A case for test-code generation inmodel-driven systems. In: Proceedings of the Second InternationalConference on Generative Programming and Component Engineering,Erfurt, Germany.
Rutherford, M.J., Wolf, A.L., 2003b. Integrating a performance analysiskit into model-driven development. In: Proceedings of the 5th GPCEYoung Researchers Workshop 2003, Erfurt, Germany.
Skene, J., Emmerich, W., 2003a. A model-driven approach to non-functional analysis of software architectures. In: Proceedings of the
18th IEEE International Conference on Automated Software Engi-neering (ASE).
Skene, J., Emmerich, W., 2003b. Model driven performance analysis ofenterprise information systems. Electronic Notes in TheoreticalComputer Science 82 (6), 1–11.
TPC, 2004. TPC Benchmark W (TPC-W). <http://www.tpc.org/tpcw/spec/TPCWV2.pdf>.
Weis, T., Ulbrich, A., Geihs, K., Becker, C., 2004. Quality of service inmiddleware and applications: a model-driven approach. In: Proceed-ings of the Eighth IEEE International Enterprise Distributed ObjectComputing Conference (EDOC).



























![UML and MDA for Transactional Level Modeling - …1].pdf · UML and MDA for Transactional Level Modeling S. Bocchio, ... UML and MDA for TLM 6 ... executable. UML and MDA for TLM](https://static.documents.pub/doc/80x56/5b64578d7f8b9a687e8d318d/uml-and-mda-for-transactional-level-modeling-1pdf-uml-and-mda-for-transactional.jpg)





