22
Mean Field Inference in Dependency Networks: An Empirical Study Daniel Lowd and Arash Shamaei University of Oregon
| Date post: | 28-Dec-2015 |
| Category: |
Documents |
| Upload: | corey-wade |
| View: | 216 times |
| Download: | 0 times |

Mean Field Inference in Dependency Networks: An Empirical Study
Daniel Lowd and Arash ShamaeiUniversity of Oregon

2
Learning and Inference inGraphical Models
We want to learn a probability distribution from data and use it to answer queries.
Applications: medical diagnosis, fault diagnosis, web usage analysis, bioinformatics, collaborative filtering, etc.
A
B C
Answers!Data Model
Learning Inference

3
One-Slide Summary
1. In dependency networks, mean field inference is faster than Gibbs sampling, with similar accuracy.
2. Dependency networks are competitive with Bayesian networks.
A
B C
Answers!Data Model
Learning Inference

4
Outline
• Graphical models:Dependency networks vs. others– Representation– Learning– Inference
• Mean field inference in dependency networks• Experiments

5
Dependency NetworksRepresents a probability distribution over {X1, …, Xn} as a
set of conditional probability distributions.
Example:
€
{P1(X1|X3),P2(X2|X1,X3),P3(X3|X1,X2)}
X1
X2 X3
[Heckerman et al., 2000]

6
Comparison of Graphical Models
Bayesian Network
Markov Network
Dependency Network
Allow cycles? N Y YEasy to learn? Y N YConsistent distribution?
Y Y N
Inferencealgorithms
…lots… …lots… Gibbs,MF (new!)
7
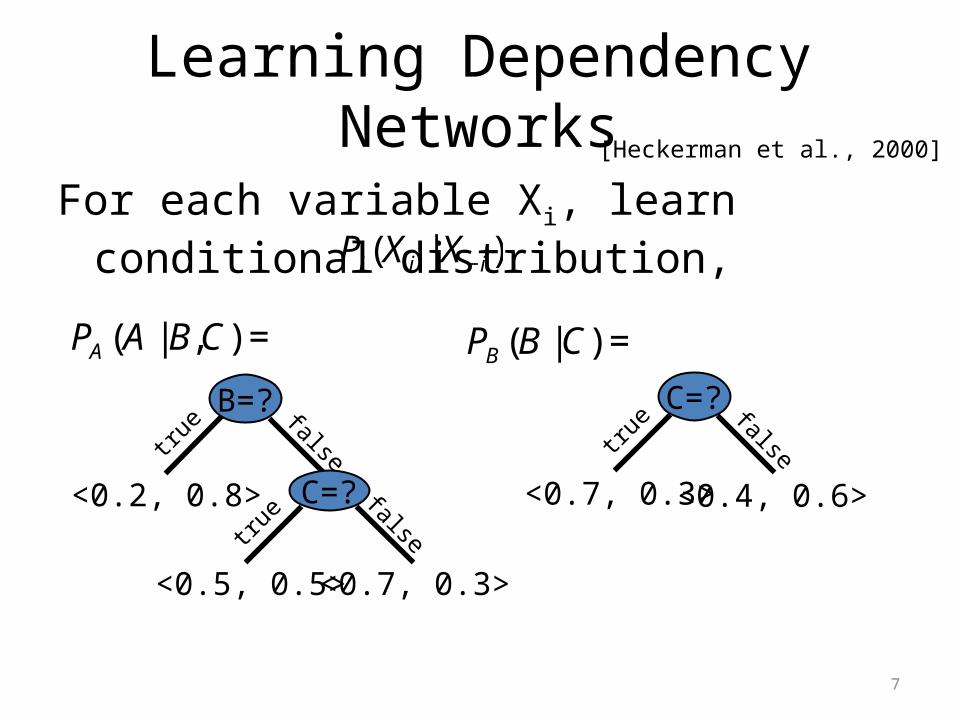
Learning Dependency Networks
For each variable Xi, learn conditional distribution,
€
Pi(X i | X−i)
B=?
<0.2, 0.8>
<0.5, 0.5> <0.7, 0.3>
false
falseC=?
true
true
€
PA (A |B,C) =
C=?
<0.7, 0.3> <0.4, 0.6>
falsetrue
€
PB (B |C) =
[Heckerman et al., 2000]
8
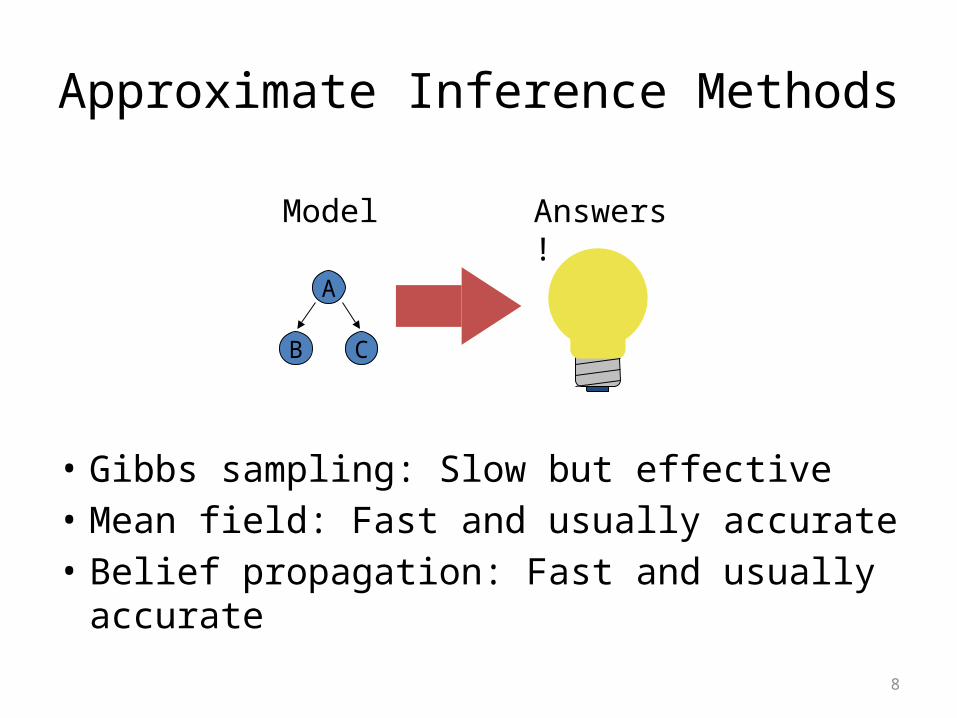
Approximate Inference Methods
• Gibbs sampling: Slow but effective• Mean field: Fast and usually accurate• Belief propagation: Fast and usually accurate
A
B C
Answers!Model

9
Gibbs SamplingResample each variable in turn, given its neighbors:
Use set of samples to answer queries. e.g.,
Converges to true distribution, given enough samples (assuming positive distribution).
€
x i(t+1) ~ P X i | X−i = x−i
( t )( )
€
P(B = True) =# of samples where B = True
total # of samples
Previously, the only method used to compute probabilities in DNs.

10
Mean FieldApproximate P with simpler distribution Q:
To find best Q, optimize reverse K-L divergence:
Mean field updates converge to local optimum:
€
P(X1,X2,...,Xn ) ≈Q(X1)Q(X2) L Q(Xn )
€
KL(Q ||P) = Q(X = x)logP(X = x)
Q(X = x)x
∑
€
Q(t )(X i) ∝ exp EX − i ~Q ( t−1) (X − i )
logP(X i | X−i)[ ]( )
Works for DNs! Never before tested!

11
Mean Field in Dependency Networks
1. Initialize each Q(Xi) to a uniform distribution.
2. Update each Q(Xi) in turn:
3. Stop when marginals Q(Xi) converge.
€
Q(t )(X i) ∝ exp EX − i ~Q ( t−1) (X − i )
logPi(X i | X−i)[ ]( )
If consistent, this is guaranteed to converge.If inconsistent, this always seems to converge in practice.

12
Empirical Questions
Q1. In DNs, how does MF compare to Gibbs sampling in speed and accuracy?
Q2. How do DNs compare to BNs in inference speed and accuracy?

13
Experiments
• Learned DNs and BNs on 12 datasets• Generated queries from test data– Varied evidence variables from 10% to 90%– Score using average CMLL per variable
(conditional marginal log-likelihood):
€
CMLL(x,e) =1
| X |logP(X i = x i | E = e)
i
∑

14
Results: Accuracy in DNs
NLTCS
MSNBC
KDDCup 2000Plan
tsAudio
Netflix
Jester
MSWeb
Book
Web
KB
Reuter
s-52
20 New
sgroups
0
0.1
0.2
0.3
0.4
0.5
0.6
DN.MF DN.Gibbs
Neg
ative
CM
LLN
egati
ve C
MLL

15
Results: Timing in DNs (log scale)
NLTCS
MSNBC
KDDCup 2000Plan
tsAudio
Netflix
Jester
MSWeb
Book
Web
KB
Reuter
s-52
20 New
sgroups
0.01
0.1
1
10
100
DN.MF DN.Gibbs
Infe
renc
e Ti
me
(s)

16
MF vs. Gibbs in DNs,run for equal time
Evidence # of MF wins % wins
10% 9 75%
20% 10 83%
30% 10 83%
40% 9 75%
50% 10 83%
60% 10 83%
70% 11 92%
80% 11 92%
90% 12 100%
Average 10.2 85%
In DNs, MF usually more accurate, given equal time.
17
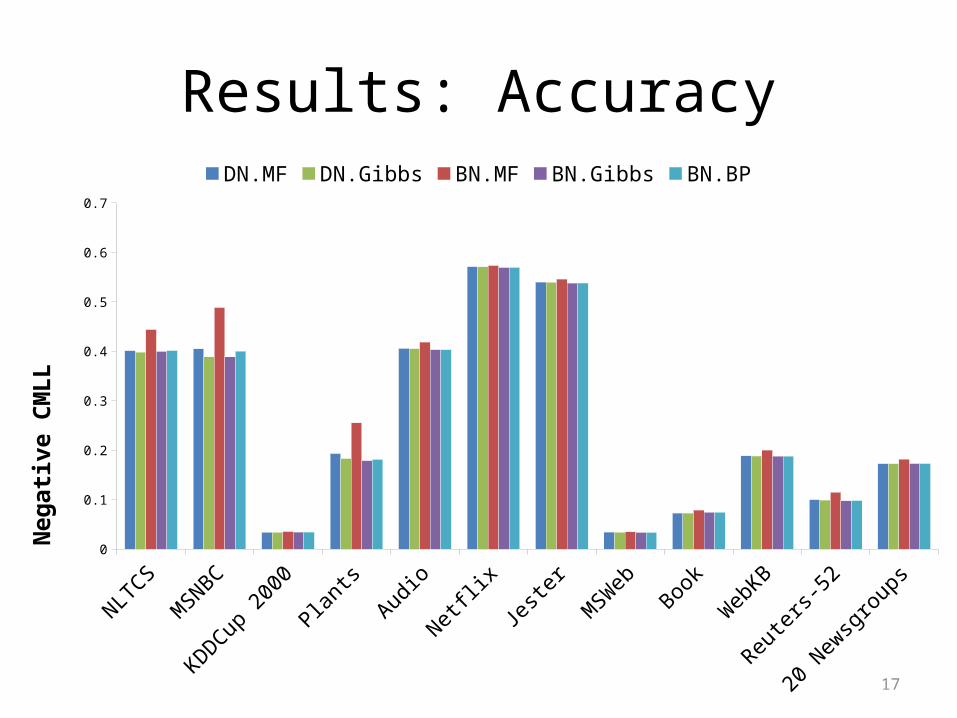
Results: Accuracy
NLTCS
MSNBC
KDDCup 2000Plan
tsAudio
Netflix
Jester
MSWeb
Book
Web
KB
Reuter
s-52
20 New
sgroups
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
DN.MF DN.Gibbs BN.MF BN.Gibbs BN.BP
Neg
ative
CM
LL
18
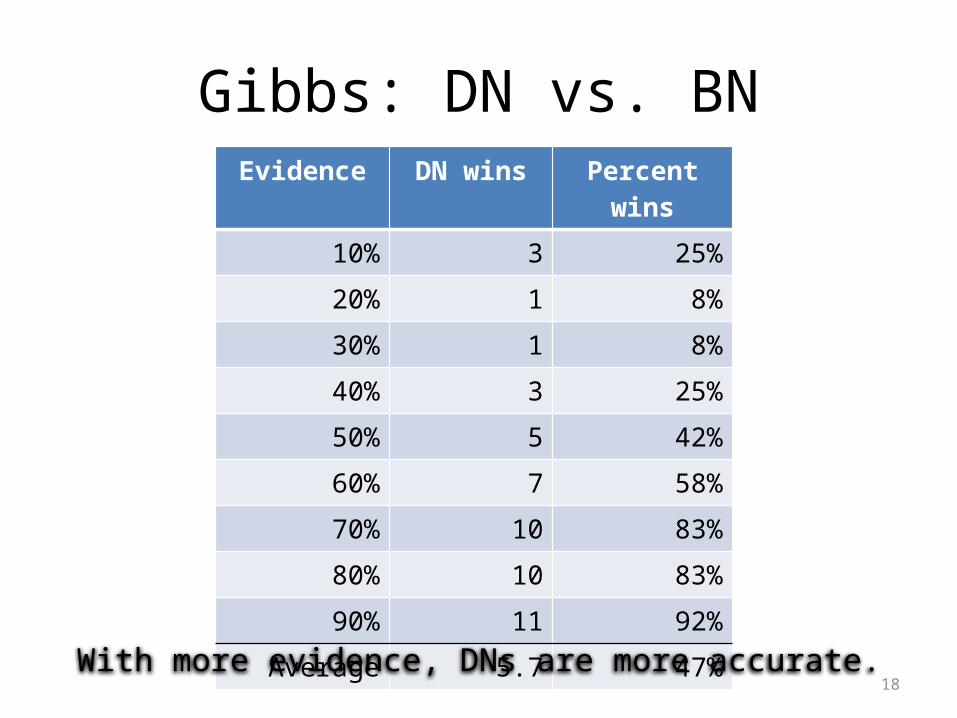
Gibbs: DN vs. BNEvidence DN wins Percent wins
10% 3 25%20% 1 8%30% 1 8%40% 3 25%50% 5 42%60% 7 58%70% 10 83%80% 10 83%90% 11 92%
Average 5.7 47%
With more evidence, DNs are more accurate.

19
Experimental Results
Q1. In DNs, how does MF compare to Gibbs sampling in speed and accuracy?
A1. MF is consistently faster with similar accuracy, or more accurate with similar speed.
Q2. How do DNs compare to BNs in inference speed and accuracy?
A2. DNs are competitive with BNs – better with more evidence, worse with less evidence.

20
Conclusion
• MF inference in DNs is fast and accurate, especially with more evidence.
• Future work:– Relational dependency networks
(Neville & Jensen, 2007)
– More powerful approximations
Source code available: http://libra.cs.uoregon.edu/

21
Results: Timing (log scale)
NLTCS
MSNBC
KDDCup 2000Plan
tsAudio
Netflix
Jester
MSWeb
Book
Web
KB
Reuter
s-52
20 New
sgroups
0.01
0.1
1
10
100
1000
DN.MF DN.Gibbs BN.MF BN.Gibbs BN.BP
Infe
renc
e Ti
me
(s)

22
Learned Models
1. Learning time is comparable.2. DNs usually have higher pseudo-likelihood (PLL)3. DNs sometimes have higher log-likelihood (LL)

















