Genome Canada Meeting Report from the Bioinformatics & Computational Biology Workshop Toronto, Ontario, Canada – December 5 & 6 2011 This workshop was made possible with the generous support of our sponsors:
Transcript
Genome Canada
Meeting Report from the Bioinformatics & Computational Biology Workshop Toronto, Ontario, Canada – December 5 & 6 2011
This workshop was made possible with the generous support of our sponsors:
Genome Canada 2011 Bioinformatics and Computational Biology Workshop
2
______________________________________________________________________________The wordle above was created by Guillaume Bourque using the text of this report. It is meant to illustrate the kind of data mining approach that is relevant to bioinformatics.
Genome Canada 2011 Bioinformatics and Computational Biology Workshop
3
Table of Contents Executive Summary ......................................................................................................................... 4
Background ..................................................................................................................................... 5 Process ............................................................................................................................................ 6 Presentations .................................................................................................................................. 7 Theme Breakout Groups and Discussion ...................................................................................... 10 Strategy Session ............................................................................................................................ 14
Recommendations ........................................................................................................................ 14 Next Steps ..................................................................................................................................... 16 Appendices
Appendix 1 – Workshop Program Appendix 2 – Final List of Participants Appendix 3 – Speaker Biographies
Organization Abbreviations
CANARIE Canada’s Advanced Research and Innovation Network (www.canarie.ca) CFI Canada Foundation for Innovation (www.innovation.ca) CIHR Canadian Institutes of Health Research (www.cihr.ca) EMBL European Molecular Biology Laboratory (www.embl.org) GC Genome Canada (www.genomecanada.ca) MITACS Mathematics of Information Technology and Complex Systems (www.mitacs.ca) NRC National Research Council (www.nrc-cnrc.gc.ca) OICR Ontario Institute for Cancer Research (www.oicr.on.ca)
Genome Canada 2011 Bioinformatics and Computational Biology Workshop
4
Executive Summary
On December 5 & 6, 2011, a workshop was held to bring together bioinformaticians and computational biologists, along with researchers from other related disciplines such as biologists, mathematicians, statisticians, application developers, informatics specialists, data visualisation experts and machine learning specialists. This workshop was convened with a view to deriving input from a broad spectrum of stakeholder communities, as a first step in the creation of a multi-year road map for bioinformatics and computational biology in Canada. Led by a selected panel of presenters, participants in the workshop were charged with commenting upon opportunities in informatics-related genome research. The principal recommendations from the workshop are (in priority order): Funding Genome Canada should take a lead-role in coordinating the development of a significant, national, multi-year funding program directed to boinformatics/computational biology. Networking Mechanisms should be established to improve coordination and promote interdisciplinary collaborations within the bioinformatics/computational biology community. Integration The Canadian bioinformatics community should develop and use data standards and best practices as necessary elements for data integration and modelling. High Quality Personnel Programs should be developed to attract, retain and train innovative individuals in the areas of bioinformatics, computational biology, and bio-statistics, who have an interest in working in the life sciences. High Performance Computing A coordinated and well-managed high-performance computing infrastructure that is targeted for life sciences should be supported. Algorithm and Software Development Algorithms and software must be developed with the end user in mind and based on established best practices. Policies The community should work closely with Genome Canada and Government agencies to ensure appropriate policies and legislation are in place to realize the full potential of Canada’s bio-economy.
Genome Canada 2011 Bioinformatics and Computational Biology Workshop
5
Background Genome Canada’s Science and Industry Advisory Committee (SIAC) identified the need to advance the area of bioinformatics/computational biology in Canada. The 2011 cross-Canada consultations in connection with Genome Canada’s strategic plan also highlighted the importance of a national effort to address the needs in this area. Therefore, SIAC undertook the planning for a bioinformatics/ computational biology workshop scheduled for the fall of 2011. For many participants, this workshop was a singular opportunity to meet with bioinformaticians, computational biologists and colleagues from other related disciplines. A decade ago, in September 2001, Genome Canada and the Canadian Institutes of Health Research held a jointly sponsored workshop on bioinformatics. At that time, bioinformatics expertise and technology in Canada were just emerging and were variable across the country. Since the 2001 meeting, Genome Canada continued to encourage research in this area, mostly through its Science & Technology Innovation Centres (STICs) and funding competitions focused on technology development. A ten-member steering committee was struck to organize the workshop. Chair:
William (Bill) Crosby, SIAC Member Professor of Biological Sciences University of Windsor
Members: Guillaume Bourque Director of Bioinformatics McGill University and Genome Quebec Innovation Centre
Francis Ouellette Associate Director, Informatics and Bio-computing Ontario Institute for Cancer Research Associate Professor, Cell and Systems Biology University of Toronto
Mark Daley Departments of Computer Science and Biology, University of Western Ontario
Gijs van Rooijen Chief Scientific Officer Genome Alberta
Stacey Gabriel, SIAC Member Director, Genetic Analysis Platform Program Co-Director, Genome Sequence Analysis Prog. Co-Director, Program in Medical and Population Genetics, Broad Institute
George Weinstock, GC Board of Directors Associate Director, The Genome Center Washington University School of Medicine
Michael Hallett, Advisor Director McGill Centre for Bioinformatics
John Yates III, SIAC Member Department of Cell Biology Scripps Research Institute
Steven Jones Associate Director and Head, Bioinformatics Genome Sciences Centre British Columbia Cancer Research Centre
Jacques Simard, SIAC Chair, Committee Observer Canada Research Chair in Oncogenetics Director, Endocrinology and Genomics Axis, CHUQ Research Centre & Dept. Molecular Medicine, Laval
Genome Canada 2011 Bioinformatics and Computational Biology Workshop
6
The Bioinformatics and Computational Biology Workshop was held on December 5 & 6, 2011 in Toronto. Sponsors included the Canadian Institutes of Health Research – Institute of Genetics and Institute for Cancer Research, and IBM Canada. Workshop Objectives Existing tools and approaches have only partially realized the information potential in existing data sets. A pan-national initiative in bioinformatics/computational biology will substantially and positively impact the life science economy in Canada, with benefits in human health, as well as non-health sectors, such as, agriculture, environment, fisheries, and forestry. An emphasis of the workshop was to assemble an interdisciplinary group of biologists, mathematicians, statisticians, application developers, informatics specialists, data visualisation experts, machine learning specialists, and computational scientists dedicated to developing novel approaches to deriving value from genomics-related data, creating user-friendly interfaces, and establishing rich learning environments for the training and development of highly qualified personnel required for this critical aspect of research. The importance of and need for infrastructure was also to be considered. An international dimension to the initiative is expected and encouraged. The specific goals of the workshop were two-fold: To inform Genome Canada during its development of a request for applications set to be
launched in 2012.
To inform the development of a multi-year roadmap detailing the current state-of-the-art and future challenges and opportunities in bioinformatics.
Process The Workshop Steering Committee chose to divide the subject matter into seven themes. An expert speaker for each theme was asked to present to participants an overview of the outstanding issues for the theme and to list the roadblocks, challenges and opportunities. Theme Speaker Title of Talk 1 Information Theory and
Biological Computing Lila Kari, University of Western Ontario
The Many Facets of Natural Computing
2 Network and Pathway Analysis
Gary Bader, University of Toronto
Network and Pathway Analysis – Moving Towards Applications
3 Ecology and Evolution Magnus Nordborg, Gregor Mendel Institut
Genomic Approaches to Understanding Adaptation
4 Proteomics and Analysis of Data Sets
Andrew Emili, University of Toronto
Deriving Knowledge from Proteomic Data
5 Clinical Applications John McPherson, OICR The Rise of Personalized Medicine in Cancer: Implications and Challenges
6 Models for Implementation and Uptake
Lincoln Stein, OICR Breaking the Computational Bottleneck: Informatics Tools in a Transgenomic World
7 Infrastructure Requirements Ajay Royyuru, IBM Watson Research Center
Emerging Opportunities in Computational Biology Infrastructure
Genome Canada 2011 Bioinformatics and Computational Biology Workshop
7
There were opportunities for small discussion groups to consider each theme, guided by theme-specific discussion questions that were developed by the steering committee with the help of each theme’s speaker. These groups then reported on their deliberations to all participants in plenary sessions. The afternoon of the second day was reserved for facilitated discussions centered on informing the development of a long-term strategy, including the identification of priorities. Workshop recommendations were generated by asking participants to answer the following question “What needs to be done to ensure the future productivity of Canada in bioinformatics and computational biology?” At the conclusion of the workshop, members of the steering committee reviewed the recommendations and sorted them into themes.
Presentations Keynote Presentation Speaker: Peer Bork, Joint Head of Unit and Senior Scientist of the Structural and Computational
Biology Unit at EMBL in Heidelberg Title of Talk: Bioinformatics in the Age of Systems Biology: From Data Integration to Discovery Chair: Bill Crosby Summary: As the Keynote speaker, Dr. Bork was awarded an opportunity to present an overview of the role of bioinformatics and computational biology in predicting function. He noted that with quantitative data coming from all spatial scales, bioinformatics is able to reach from service to science and bridge these scales. Successful concepts and approaches in one scale can then be applied to others (e.g., Networks using co-occurrence). When tools and hardware infrastructure are coupled to biological research projects the informatics and data infrastructure in biology is advanced and hence can have an impact on other disciplines. Dr. Bork also stated that bioinformatics discoveries can drive experimental studies, and that this cultural change should be encouraged and supported. Theme 1: Information Theory and Biological Computing Speaker: Lila Kari, Department of Computer Science, University of Western Ontario Title of Talk: The Many Facets of Natural Computing Chair: Mark Daley Summary: Theme 1 sought to understand, in a broad sense, what opportunities formal mathematics can provide to tackle the challenges of modelling increasingly complex systems. Dr. Kari’s talk centered around the discipline of natural computing. Natural computing is an interdisciplinary field that connects mathematical and computing sciences with the natural sciences. It investigates models and computational techniques inspired by nature and attempts to understand the world in terms of information processing. Natural computing may use nature for inspiration (e.g., neural networks, evolutionary computation); as an implementation substrate (e.g., DNA computing, quantum computing); or for computation (e.g., systems biology, synthetic biology, cellular computing).
Genome Canada 2011 Bioinformatics and Computational Biology Workshop
8
Theme 2: Network and Pathway Analysis Speaker: Gary Bader, Centre for Cellular and Biomolecular Research, University of Toronto Title of Talk: Network Pathway Analysis – Moving from Correlation to Causation in Genomics Chair: Francis Ouellette Summary: The focus of this theme was to explore the use of network pathway analysis to gain a more mechanistic understanding of cellular function extrapolated from genomics data, and how such analyses can be used in applied research areas such as clinical sciences, or plant physiology. Dr. Bader explained that understanding the cell and how it functions under normal conditions leads to a better understanding of how it fails in disease. The associated pathway information derived from Networks can and does increase the power of the information contained within primary sequence data sets, and can be used to identify potential disease mechanisms. Elucidating cellular machineries by defining the system and visualizing the networks and pathways will enhance our understanding of genomes and transcriptomes and lead to improved clinical, agricultural, and other impacts. Theme 3: Ecology and Evolution Speaker: Magnus Nordborg, Gregory Mendel Institut, Vienna Title of Talk: Genomic Approaches to Understanding Adaptation Chair: George Weinstock Summary: Dr. Nordborg presented his science with populations of the Arabidopsis plant, but the repercussions and implications are applicable to all taxa. As the technologies of molecular biology continue to get cheaper and faster, it is cost-effective and feasible to scale analysis to the population level. Many areas of ecology, population biology and evolution will be revolutionized. For example, it is now possible to study complete communities of organisms and determine how they change over time. The genetic basis of evolutionarily important traits can be elucidated, and compared across species. Gene flow and mating systems can be determined directly, rather than estimated. The opportunities are great, and, in the case of plants, could present population-level markers for how our planet is being affected by large-scale changes in the environment such as global warming. Theme 4: Proteomics and Analysis of Data Sets Speaker: Andrew Emili, Centre for Cellular and Biomolecular Research, University of Toronto Title of Talk: Deriving Knowledge from Proteomic Data: Next-Gen Data Analysis Chair: John Yates Summary: Advances in proteomic data generation have given rise to a computational bottleneck; individual labs and the broader community are constrained in their ability to annotate, analyze, interpret, manage, archive, and distribute the deluge of new proteomics data being generated. The bioinformatics challenges in proteomics include: computational analysis that lags behind technical advances, the critical need for new data analysis methods and software, the need for user-driven computational tools that are of value to biologists/clinicians, analysts, and experimentalists. Proteomics is a prominent component of the ’omics data avalanche that is poised to highly impact such important clinical areas as personalized medicine. Proteomics is an essential complement to NextGen DNA sequencing and bioinformatics tools are needed to drive the integration of genomic and proteomic data.
Genome Canada 2011 Bioinformatics and Computational Biology Workshop
9
Theme 5: Clinical Applications Speaker: John McPherson, Director Genome Technologies, Ontario Institute for Cancer Research Title of Talk: The Rise of Personalized Medicine in Cancer: Implications and Challenges Chair: Stacey Gabriel Summary: Personalized medicine has the potential to apply human genetic information to the prediction of disease risk, optimize screening programs and to identify disease(s) at earlier stages where therapeutic intervention is generally more effective and less costly. The opportunity for mitigating health care costs and providing more accurate prognostic information leading to more effective treatment interventions is significant. So far there have been a few successes but the full potential has yet to be realized. The International Cancer Genome Consortium is an example of a large-scale project in cancer, where 25,000 cancer genomes, epigenomes and transcriptomes will be sequenced, which will generate large amounts of data required to find valuable biomarkers of disease. The project embodies many technical and ethical considerations that will require significant effort to resolve and integrate. Theme 6: Models for Implementation and Uptake Speaker: Lincoln Stein, Ontario Institute for Cancer Research Title of Talk: Breaking the Computational Bottleneck: Informatics Tools in a Trans-genomic World Chair: Francis Ouellette Summary: Three challenges currently confront researchers in the area of bioinformatics and computational biology: 1) encouraging the creation, development, distribution and maintenance of bioinformatics software, 2) training biologists and clinicians to use these tools, and, 3) facilitating the sharing of the extremely large data sets that currently typify the genome sciences. It should be noted that genomics software is largely developed by academics and that the quality and functionality of this software is variable. Several large bioinformatics software development initiatives have been undertaken in recent years and we should derive important lessons from the experience of these projects. A key to the success of software development is community involvement; there must be a review mechanism to eliminate projects that either do not work or for which there is little identifiable need within the user community. It is generally true that no project is too big to fail. Dr. Stein also observed that modest investments in open source software development can yield big returns. In many cases, relatively short-term entrepreneurial projects may be a safer bet than a few mega-projects and that cloud-based data-repositories and analytical frameworks may increasingly facilitate genome data sharing analysis by the broader user community.
Genome Canada 2011 Bioinformatics and Computational Biology Workshop
10
Theme 7: Infrastructure Requirements Speaker: Ajay Royyuru, IBM Watson Research Center, New York Title of Talk: Are We There Yet? - Emerging Opportunities in Computational Biology Infrastructure Chair: Bill Crosby Summary: Arising from the technology-driven rapid growth of genomics and systems biology data sets, information science has now become a critical component of the life sciences. The sheer size of existing and future data sets presents formidable challenges in computational capacity that are orders of magnitude beyond current capabilities. In parallel with the accelerated growth of biological data sets, there is the need for high performance computing resources at a peta to exa scale. Indeed, the past few years have seen the life sciences surpass all other disciplines as the principal demand-based application of high-performance computational resources. Cloud computing is a promising new strategy to manage data collection, dissemination and analysis, but is not without challenges. Bioinformatics can anticipate data management models where data are moved on a one-time basis to a cloud-based analytical framework where scalable computational resources can be applied for a comprehensive analysis. The community can also anticipate the need for technology development related to cloud configuration where, for example, issues of geographic distribution and confidentiality of clinical data sets can be appropriately safeguarded.
Theme Breakout Groups and Discussion Theme 1: Information Theory and Biological Computing Discussion Questions 1. How can we identify areas of modern mathematics which have a high probability of bringing value
to biological modeling, but are currently unexploited? 2. How can we interest biologists to work with mathematicians who research abstract topics? How can
we interest mathematicians to work with biologists? Most significantly: how can we facilitate communication between two disciplines each having a rich history, a huge quantity of assumed "base knowledge" and formidable lexicons and concept inventories?
3. Should we support high-risk/high-reward research attempting to apply completely new areas of mathematics to biological problems or should we focus instead on less aggressive extensions of existing lines of collaboration?
Discussion Highlights: The key concept that emerged from the breakout group discussions was the need to aggressively pursue the exploitation of fields of mathematics which have not yet been explored for potential application to biological problems. The challenge here is that – almost by definition – these will be the most difficult collaborations to facilitate as there will be no common language and no history of cross disciplinary work. The long-term goal would be to mentor more cross-trained researchers, which will in turn require the coordinated support of funders and educational institutions to devise and deploy innovative new training programs. In the short-term, it would be beneficial to find ways to attract mathematics researchers to work on biology questions. Targeted funding from Genome Canada to encourage the application of current mathematical tools and techniques to solve biological questions, along with additional opportunities for these disparate groups to meet would help develop the linkages needed. It was generally agreed that a balance between high-risk/high-reward projects and those that
Genome Canada 2011 Bioinformatics and Computational Biology Workshop
11
are logical extensions of previously funded work is needed. However, funding for trainees was seen to be the most pressing need.
Theme 2: Network and Pathway Analysis Discussion Questions 1. How can network and pathway analysis be used to gain a more mechanistic understanding of the
cell using genomics data? How can genomics data be used to update a model of a pathway e.g., find a new pathway member?
2. How can network and pathway information be used to answer applied research questions (e.g., clinical)?
3. How can population genetic variation or personalized human genome information be combined with network and pathway information to interpret the functional consequences of mutations?
4. How can chemi-informatics data (e.g., drug targets) be combined with network and pathway information to help with drug combination or chemical probe discovery?
Discussion Highlights: Research in network and pathway analysis holds promise in many areas including personalized medicine, for example by enhancing our understanding of drug interactions and the reduction of drug side effects. Several challenges were brought forward during the discussions including: the lack of integration of pathway data from different sources (e.g., GWAS, expression studies, protein/protein interactions); the need for more communication between biologists and bioinformatics user groups; the need for context-specific databases; privacy issues; the need for simple decision models for clinical (or other) applications; the need for more curation of pathway data; and the lack of accessibility to some databases. The theme discussion also raised the importance of striking an optimal balance between the mining of existing data and the generation of new data sets. Theme 3: Ecology and Evolution Discussion Questions 1. What is limiting technological revolution in ecology and evolution? Is it fundamental problems,
technological limitations, bioinformatics, or simply funding? 2. To what extent can studies of natural variation inform other fields? 3. What areas are likely to be most productive / change the most? Discussion Highlights: The limiting factor in ecology and evolution research is funding, including the fact that this funding must be sought from different sources for different aspects of what is, in fact, an integrated research theme. Basic research, algorithm development, infrastructure and software development are all requirements of the ecology and evolutionary genomics community. Another important challenge is the lack of bioinformatics trainees; there is intense competition from industry for these people such that genuinely attractive positions and opportunities in the basic and applied research realms need to be fostered. Promising areas in this theme include: 1) characterizing ecological diversity, 2) the development of bio-renewable energy policy and practice and 3) the inclusion of viral and phage genomes as a tractable and critical issue in environmental genomics and health, since rapid shifts in microorganism and viral communities will most likely be the source of future pandemic disease outbreaks.
Genome Canada 2011 Bioinformatics and Computational Biology Workshop
12
Theme 4: Proteomics and Analysis of Data Sets Discussion Questions 1. Can innovative computational strategies link together diverse proteomics data types (e.g.,
expression profiles, PTMs, PPI, dynamic networks, clinical biomarkers)? 2. Can bioinformatics tools bridge proteomics data with functional genomics evidence and clinical
genomics information, thereby forging synergies? 3. Should the emphasis be focused on addressing the needs of new instrumentation and methods, or
on important biological questions and applications? Discussion Highlights: Participants saw data integration as the biggest challenge in the area of proteomics. There is a need to develop and adopt standards for data linkage and to enable effective sharing of the data. There was agreement on the need to adopt Canada-wide standards for proteomics data, and to integrate them with standards under development by the wider global research community. Funding for a long-term, high quality proteomics data repository would be an important international contribution for which Canada could take a lead role. Theme 5: Clinical Applications Discussion Questions 1. How could we computationally predict from the genotype of a cancer what therapeutics it would be
most susceptible too? Likewise, could software be developed to identify adverse reactions by the patient to therapeutics?
2. What kind of computational models of cell function/systems biology could be created to aid in making clinical inferences?
3. How do we convey to the clinician the logic that is being invoked to make such a prediction? Discussion Highlights: A limiting factor in this area is the challenge in the management and analysis of large data sets. This is also exacerbated by the need for more data! Another important consideration is protection of patient information and identifiable (genetic) data. There is still much work ahead before genomic data can be used routinely for clinical diagnosis/prognosis or the identification of potential adverse drug reactions. Canadian researchers are well positioned to develop the required tools to ensure that we are ready to implement these technologies on behalf of the Canadian health care system. Better repositories for proteomic data and standardization would be helpful in this regard, and complement the outputs from the Theme 4 discussion. Proactive work on the integration of phenotypic and other clinical data is needed, as well as the development of tools that will facilitate the use of genomics data by clinicians in the pursuit of an improved patient outcome.
Genome Canada 2011 Bioinformatics and Computational Biology Workshop
13
Theme 6: Models for Implementation and Uptake Discussion Questions 1. What are the best ways to encourage the development, distribution and maintenance of genome
analysis tools? 2. Who pays for long-term maintenance of software and databases? 3. What is the best way to train biologists and clinicians to use genome analysis tools and other
resources? Discussion Highlights: To encourage the further development of analysis tools, a scheme targeted to polishing, releasing, and supporting existing software is needed. This program should include the development of appropriate documentation and user-support so as to maximize the uptake of tools by the broader research community. The development of software engineering best practices would help speed development and uptake, as well as provide guidelines for standards of communication, METADATA, file formats and distribution strategies. The development framework should also foster the convening of workshops and other forums to discuss results and best practices. Funding stakeholders should recognize that it is usually easier to find funds for the creation of new tools, but it is challenging to find funding for the continued maintenance of existing and valuable tools. It is important to establish a business model for software sustainability and to clearly differentiate between maintaining software and maintaining a database. That said, the maintenance of databases is another important problem that also needs to be addressed. Canada (and many other jurisdictions) has a poor track record for long term maintenance of databases. The group felt there is a general lack of bioinformatics uptake in Canada and the distribution of expertise across the country varies greatly. Because of the shortage of people, bioinformaticians often feel pressured to provide service and may find themselves supporting too many projects. More training is required; hands-on workshops, co-op and summer programs as well as industry/platform placements are all examples of initiatives that could work well in this regard. Theme 7: Infrastructure Requirements Discussion Questions 1. To what extent would ‘cloud-based’ data aggregation and management strategies benefit the
computational biology community? What problems or impediments exist to the implementation of such strategies?
2. What is the perception of the existing and future needs for High Performance Computing resources by the computational biology community? To what extent can the community anticipate needs in the medium term, and what is their assessment of capacity needs?
Discussion Highlights: The idea of using cloud-based data distribution, analysis and management strategies caught the imagination of the participants, resulting in a lively and broad-based discussion. The use of scalable cloud-based resources would provide more in the way of on-demand data analysis capacity and thus accelerate research outputs involving bioinformatics. The sharing of data would also be facilitated. It was agreed that future data sets will likely become so large that use of cloud resources will be necessary; however, this is still a fairly new technology with many details left to be worked out. Some of these challenges include: establishment of fair and appropriate fee structures, acceptance by the research and research-funding community, country-specific regulations governing the geographic location of data, privacy concerns for clinical data, and software availability. It was suggested that Genome Canada and other national research funders take a lead role in the transition to this new technology.
Genome Canada 2011 Bioinformatics and Computational Biology Workshop
14
Strategy Session The afternoon of the second day was reserved for facilitated discussions centered on the development of a long-term strategy, including the identification of priorities. After having explored the seven themes over 1 ½ days of talks and discussions in breakout groups and in plenary, participants were asked to answer the following question “What needs to be done to ensure the future productivity of Canada in bioinformatics and computational biology?” Working in six breakout groups, and with the help of group facilitators, participants held wide-ranging discussions and each group created a list of ten specific actions that should be taken. At the conclusion of the workshop, members of the steering committee reviewed the recommendations of the individual breakout groups and sorted them into themes. The following are the recommendations by theme in order of importance (importance being defined as the number of groups that identified the need).
Recommendations Funding Genome Canada should take a lead-role in coordinating the development of a significant, national, multi-year funding program directed to bioinformatics/computational biology.
The program should include funding for basic research and capacity building and include support to relatively short term, high-risk/high-reward projects that develop “disruptive” ideas, methods and approaches that will have demonstrable impact on the life sciences. The program should also include a component designed to address pressing problems of national socio-economic concern. The initiative would logically embrace a wide range of underlying bioinformatics-related activities including software and algorithm (tool) development and support, together with the situational training of the necessary human resources. Genome Canada should take the lead in the fostering of partnerships with public and private organizations such as the federal granting councils, CFI, NRC, industry, MITACS, Compute Canada, and CANARIE in order to leverage Government investments and maximize resources among key stakeholders. The program should promote cross-disciplinary collaboration e.g., between bioinformaticians, mathematicians, physicists, biologists, genomics specialists and biostatisticians in order that maximum innovation and value capture can be realized.
Networking Mechanisms should be established to improve coordination and promote interdisciplinary collaborations within the bioinformatics/computational biology community.
The bioinformatics and computational biology community in Canada is ready for the establishment of a pan-national organizational body under which it can establish a strategic vision for the importance of bioinformatics and computational biology to the Canadian life science economy. This would include activities related to advocacy as well as the coordination of scientific exchanges via national annual meetings – logically under the aegis of a newly established Canadian Bioinformatics Society. While not directly the responsibility of Genome Canada, the community appreciates that Genome Canada could
Genome Canada 2011 Bioinformatics and Computational Biology Workshop
15
serve as a valuable catalyst to these developments, with significant positive impacts on the wider genomics community in Canada.
Integration The Canadian bioinformatics community should develop and use data standards and best practices as necessary elements for data integration and modelling.
As part of a larger pan-national strategy involving national and international stakeholders, Genome Canada is encouraged to advocate for research and development leading to the establishment of useful and sustainable data standards. This would not only allow the community to leverage existing datasets and current knowledge across disciplines, but will drive outcomes and decision making in both the health and non-health sectors. Genome Canada, in partnership with the wider research community, could serve a key role in coordinating the efforts of the relevant players directed to improving the regulatory landscape in order to facilitate data sharing, data transfer, data maintenance and data storage.
High Quality Personnel Programs should be developed to attract, retain and train innovative individuals in the areas of bioinformatics, computational biology and bio-statistics who have an interest in working in the life sciences.
Funding agencies should work in partnership with universities to establish cross-disciplinary training programs and support bioinformatics career paths. Genome Canada should develop mechanisms by which bioinformaticians and computational biologists become immersed directly in biology programs - for example through targeted competitions aimed at projects that cut across different disciplines, or embedding bioinformatics training programs in the Genome Canada-supported Science and Technology Innovation Centres.
High Performance Computing A coordinated and well-managed high-performance computing infrastructure that is targeted for life sciences should be supported.
The Canadian stakeholders that fund and manage research and computing infrastructure should continue to work with the bioinformatics, computational biology and genomics communities in support of a coordinated and well-managed pan Canadian computing infrastructure. Cloud computing was viewed as the tool of the future, but it must be tailored to the needs of the Canadian “omics” community, be economically sustainable and supported by effective policies to facilitate the secure sharing of data, in particular clinical data for which government policies governing distribution and housing are in effect.
Algorithm and Software Development Algorithms and software must be developed with the end user in mind and based on established best practices.
A Genome Canada initiative in bioinformatics/computational biology must support the development of robust, user-friendly algorithms and software which are open source, portable and aligned with software development best practises in bioinformatics (note that these best practices remain to be
Genome Canada 2011 Bioinformatics and Computational Biology Workshop
16
developed). It was felt that new and innovative mechanisms should be used to attract non-traditional, but creative problem solvers to this area of development and to support the conversion of community supported prototype software into production-quality software of broad utility to the life science user community.
Policies The community should work closely with Genome Canada and Government agencies to ensure appropriate policies and legislation are in place to realize the full potential of Canada’s bio-economy. It is essential to educate legislators and decision makers about the important role of bioinformatics and computational biology in realizing the full socio-economic potential of the Canadian life science economy. Doing so will ensure that program expenditures support the development of policies and legislation that will facilitate securing benefits from research. For example, future “cloud computing” technology may conflict with current Canadian law prohibiting the exportation of personal health information.
Next Steps Shortly after the workshop a small Task Force on Bioinformatics & Computational Biology was put in place to help Genome Canada move forward in this important area and to ensure that intelligence from the workshop is fully exploited.
The Task Force is led by Bill Crosby, who chaired the 2011 Genome Canada Workshop Steering Committee, and is specifically mandated to:
Make recommendations about the scope of a proposed Genome Canada Request for Applications (RFA) in the area of bioinformatics and computational biology.
Propose a framework to develop a multi-year, national strategy to ensure the future productivity of Canada in bioinformatics and computational biology.
The target for completion of these activities is spring 2012.
Bioinformatics & Computational Biology Workshop InterContinental Hotel, 225 Front Street W., Toronto, Ontario
InterContinental Hotel, 225 Front Street W., Toronto, Ontario December 5 & 6, 2011
Program
Monday, December 5, 2011 Breakfast (Foyer of Ontario/Niagara Room) 7:30 - 8:30 Plenary Session (Ontario/Niagara Room)
Opening Remarks – Cindy Bell & Bill Crosby 8:30 - 8:45
Chair: Bill Crosby Keynote Speaker: Peer Bork, EMBL Heidelberg Title: Bioinformatics in the Age of Systems Biology: From Data Integration to Discovery
8:45 - 9:20
Review of Expected Outcomes – George Weinstock & Francis Ouellette, Moderators for Plenary Sessions Approach for the Day – Bruce Withrow, Workshop Facilitator
9:20 – 9:40
THEME 1: Information Theory and Biological Computing Chair: Mark Daley Speaker: Lila Kari, University of Western Ontario Title: The Many Facets of Natural Computing
9:40 –10:05
THEME 2: Network and Pathway Analysis Chair: Francis Ouellette Speaker presentation: Gary Bader, University of Toronto Title: Network and Pathway Analysis – Moving Towards Applications
10:05 - 10:30
Functioning of breakout groups; how to find your table, etc. – Bruce Withrow 10:30 – 10:35
Coffee Break (Foyer) 10:35 - 10:50
Breakout Sessions Move to breakout groups - Half of the groups to discuss Theme 1, half to discuss Theme 2
10:50 - 11:45
Plenary Session - Moderators: George Weinstock & Francis Ouellette Theme 1 Breakout groups report back on their deliberations (5 minutes each) Theme 2 breakout groups report back on their deliberations (5 minutes each)
11:45 - 12:45
Lunch (Foyer) 12:45 - 13:45 THEME 3: Ecology and Evolution Chair: George Weinstock Speaker: Magnus Nordborg, Gregor Mendel Institut , Vienna Title: Genomic Approaches to Understanding Adaptation
13:45 - 14:10
THEME 4: Proteomics and Analysis of Data Sets Chair: John Yates Speaker: Andrew Emili, University of Toronto Title: Deriving Knowledge from Proteomic Data
14:10 - 14:35
Breakout Sessions Move to breakout groups -Half of the groups to discuss Theme 3, half to discuss Theme 4
14:35 - 15:40
Coffee Break (Foyer) 15:40 - 16:10
Plenary Session – Moderators: George Weinstock & Francis Ouellette Theme 3 breakout groups report back on their deliberations (5 minutes each) Theme 4 breakout groups report back on their deliberations (5 minutes each)
16:10 - 17:10
Wrap-up of day 1 – Bill Crosby 17:10 - 17:25 Free time 17:25 - 18:00
Networking Reception (Foyer of Ballroom A) & International Food Stations Dinner (Ballroom A) 18:00 Reception 18:30 Dinner
Tuesday, December 6, 2011
Breakfast (Foyer of Ontario/Niagara Room) 7:30 - 8:30 Plenary Session (Ontario/Niagara Room) Approach for the day – Bruce Withrow 8:30 - 8:40 THEME 5: Clinical Applications Chair: Stacey Gabriel Speaker: Tom Hudson, Ontario Institute for Cancer Research Title: The Rise of Personalized Medicine in Cancer: Implications and Challenges Note: John McPherson replaced Thomas Hudson for this talk
8:40 –9:05
THEME 6: Models for Implementation and Uptake Chair: Francis Ouellette Speaker: Lincoln Stein, Ontario Institute for Cancer Research Title: Breaking the Computational Bottleneck: Informatics Tools in a Transgenomic World
9:05 – 9:30
THEME 7:Infrastructure Requirements Chair: Bill Crosby Speaker: Ajay Royyuru, IBM, Watson Research Center Title: Emerging Opportunities in Computational Biology Infrastructure
9:30 – 9:55
Coffee Break (Foyer) 9:55 – 10:25 Breakout Sessions Move to breakout groups. Themes 5, 6 & 7 assigned to groups for discussion
10:30 – 11:30
Plenary Session Theme 5 breakout groups report back on their deliberations (5 minutes each) Theme 6 breakout groups report back on their deliberations (5 minutes each) Theme 7 breakout groups report back on their deliberations (5 minutes each)
11:30 – 12:45
Lunch (Foyer) 12:45 - 14:00 Plenary Session – Introduction by Jacques Simard, Chair of GC’s SIAC Strategy Session 1 Facilitated discussion of the development of a long-term strategy, including the identification of priorities Strategy Session 2 Facilitated discussion on the development of an outline of a Genome Canada RFA
14:00 – 16:15
Wrap up and Next Steps: Bill Crosby 16:15 – 16:30 Adjournment 16:30
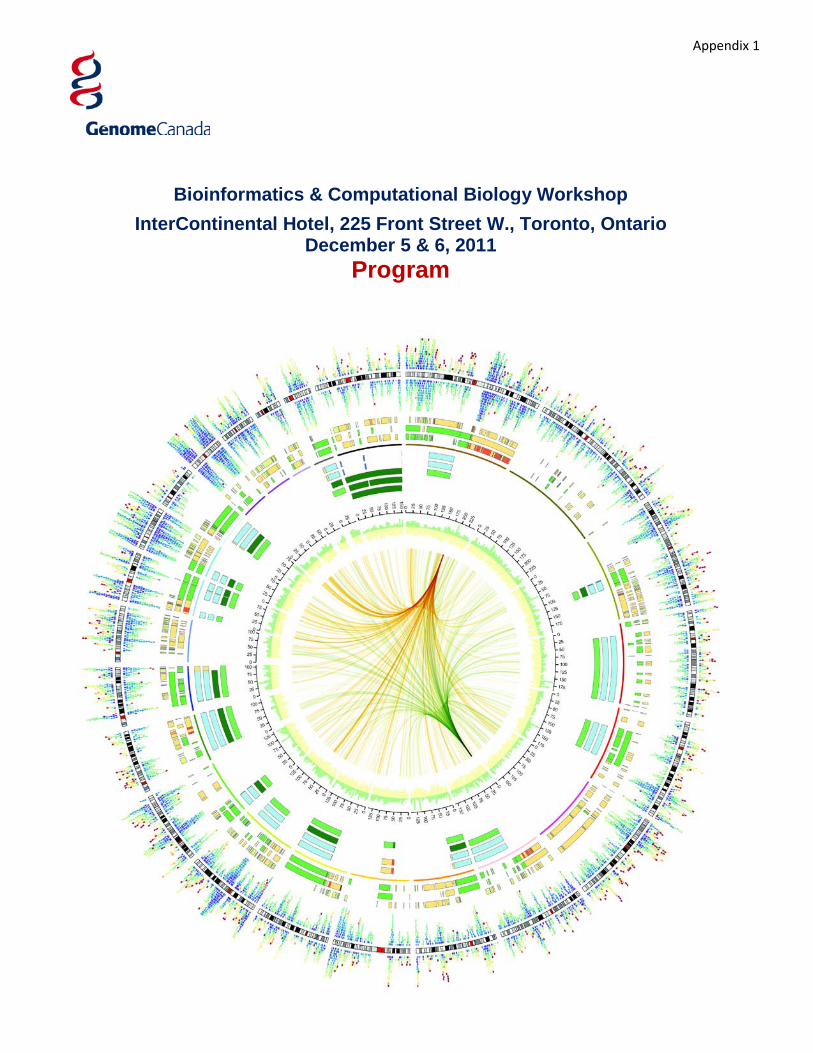
Cover image: This image is known as a Circos plot; reproduced with permission from Martin Krzywinski of the BC Cancer Agency’s Genome Sciences Centre who created the Circos software. Find out more about Circos at www.circos.ca. Chromosomes are composited circularly and data tracks are shown as concentric rings. It is based on data from the paper “Evolution of an adenocarcinoma in response to selection by targeted kinase inhibitors" published in Genome Biology in 2010 by Jones S.J., et al (http://www.ncbi.nlm.nih.gov/pubmed/20696054) and shows the changes in the genome of an adenocarcinoma lung metastasis, before and after treatment. Data in the image shows copy number variation, loss of heterozygosity in pre- and post- treatment tumour samples and matched normal DNA, as well as relative gene expression in tumour and reference tissue. NOTES:
InterContinental Hotel, 225 Front Street W., Toronto, Ontario
December 5 & 6, 2011
SPEAKER BIOGRAPHIES
k
Andrew Emili Thomas Hudson Lincoln Stein Ajay Royyuru
Peer Bork Lila Kari Gary Bader Magnus Nordborg
Appendix 3
Peer Bork Joint Head of Unit and Senior Scientist Structural and Computational Biology Unit EMBL Heidelberg, Germany
Peer Bork, PhD, is senior group leader and joint head of the Structural and Computational Biology unit at EMBL, a European research organization with headquarters in Heidelberg. He also holds an appointment at the Max-Delbrueck-Center for Molecular Medicine in Berlin. Dr. Bork received his PhD in Biochemistry (1990) and his Habilitation in Theoretical Biophysics (1995). He works in various areas of computational biology and systems analysis with a focus on function prediction, comparative analysis and data integration. His group has published more than 500 research articles in international, peer-reviewed journals, among them more than 50 in Nature, Science and Cell. According to ISI (analyzing the last 10 years), Dr. Bork is currently the most cited European researcher in Molecular Biology and Genetics. He is on the editorial board of a number of journals including Science and PloS Biology, and functions as senior editor of the journal Molecular Systems Biology. Dr. Bork co-founded four biotech companies, two of which went public. More than 25 of his former associates now hold professorships or other group leader positions in prominent institutions all over the world. He received the "Nature award for creative mentoring" for his achievements in nurturing and stimulating young scientists. He was also the recipient of the prestigious Royal Society and Academie des Sciences Microsoft Award for the advancement of science using computational methods and obtained a competitive "ERC advanced investigator grant".
Lila Kari Professor & Canada Research Chair in Biocomputing Department of Computer Science University of Western Ontario
Lila Kari is Professor and Canada Research Chair in Biocomputing at the University of Western Ontario. She received her M.Sc. in 1987 from the Univesity of Bucharest, Romania, and her Ph.D. in 1991 for her thesis "On Insertions and Deletions in Formal Languages", for which she received the Nevanlinna Prize for the best mathematics thesis in Finland. Author of more than 170 peer reviewed articles, Professor Kari is widely regarded as one of the world's leading experts in the area of biomolecular computation, that is using biological, chemical and other natural systems to perform computations. She has served as Steering Committee Chair for the DNA Computing conference series, as Steering Committee member for the Unconventional Computation conference series, as well as on the Scientific Advisory Committee of the International Society for Nano-Scale Science and Engineering. She serves on the editorial boards of the journals Theoretical Computer Science, Natural Computing and Universal Computer Science, and as section editor for molecular computing for the upcoming Natural Computing Handbook. She has additionally served as a member of the Board of Directors of the FIELDS Institute for Research in Mathematical Sciences, the UK EPSRC peer review college, on the NSERC grant selection committee on computing and information systems and the NSERC Herzberg-Brockhouse-Polanyi Prize joint selection committee. At the University of Western Ontario she has received numerous awards, including the Florence Bucke Science Prize and the Faculty of Science Award for Excellence in Undergraduate Teaching. Professor Kari's current research focuses on theoretical aspects of bioinformation and biocomputation, including models of cellular computation, nanocomputation by DNA self-assembly and Watson-Crick complementarity in formal languages.
Gary Bader Assistant Professor Banting and Best Department of Medical Research Terrence Donnelly Centre for Cellular and Biomolecular Research
Gary Bader works on biological network analysis and pathway information resources as an Associate Professor at The Donnelly Centre at the University of Toronto. He completed post-doctoral work in the group of Chris Sander in the Computational Biology Center (cBio) at Memorial Sloan-Kettering Cancer Center in New York. Gary developed the Biomolecular Interaction Network Database (BIND) during his Ph.D. in the lab of Christopher Hogue in the Department of Biochemistry at the University of Toronto and the Samuel Lunenfeld Research Institute at Mount Sinai Hospital in Toronto. He completed a B.Sc. in Biochemistry at McGill University in Montreal. The Bader lab collects information about how the parts of the cell fit together and organizes it into a cellular map that can be used to predict gene function, molecular interactions and the effects of mutations that cause disease. By computationally modeling processes at the molecular and physiological level, the team will be able to better understand how they work under normal conditions and how they fail in disease, including complex diseases such as cancer. They are working with teams of scientists internationally to collect the world’s largest resource of known molecular interaction and cellular pathway information in various organisms, including human, so that they may better understand how biological processes in our cells are active under different regulatory contexts. This research promises to improve diagnosis, prognosis and therapy and reduce the cost of medical care in Canada and the world.
Magnus Nordborg
Magnus Nordborg is the Science Director of the Gregor Mendel Institute (GMI), Vienna. In addition he is a Senior Group Leader investigating patterns of genetic and natural variation.
Dr. Nordborg joined the GMI as Science Director in 2009. Previously he was a tenured Associate Professor at the University of Southern California in Los Angeles, USA. He is internationally recognized as a pioneer in the use of genome wide association studies to study patterns of natural variation in non-human organisms. In 2010 he was elected a Fellow of the American Association for the Advancement of Science. Also in 2010 he was awarded a prestigious European Research Council Advanced Grant.
Dr. Nordborg received a BSc in 1989 from Lund University and a PhD in Biological Sciences from Stanford University in 1994.
Andrew Emili, PhD Professor Banting and Best Department of Medical Research, Donnelly Centre for Cellular and Biomolecular Research, University of Toronto
Andrew Emili received a PhD from the University of Toronto in 1997 in Molecular and Medical Genetics. From 1997 to 2000, he pursued post-doctoral studies in the Division of Human Biology with the Nobel laureate Dr. Leland Hartwell at the Fred Hutchison Cancer Research Center in Seattle. Since establishing his Toronto laboratory in 2000, Dr. Emili has developed and applied advanced proteomic, functional genomic and bioinformatic methods to investigate the biological roles and molecular associations of the different proteins and genes expressed in a typical organism or cell. His research team has outstanding skills in state-of-the-art experimental techniques for investigating protein and gene function in an unbiased, high-throughput and genome-wide manner. The team performs comprehensive 'global' studies of the complete set of the protein products (the proteome) expressed by the genes/genomes of model organisms, including microbes such as budding yeast and the bacterium E. coli, and more complex mammalian systems. The group aims to contribute breakthrough mechanistic insights into how cells and tissues function at a molecular level, and to translate this basic knowledge to enhance the clinical application of protein biomarkers as novel diagnostic and therapeutic targets.
Tom Hudson President and Scientific Director Ontario Institute for Cancer Research (OICR)
Dr. Thomas J. Hudson is President and Scientific Director of the Ontario Institute for Cancer Research (OICR), an Institute created to support multidisciplinary teams needed to effectively translate research discoveries into interventions for better prevention, detection, diagnosis and treatment of cancer. Since its inception, OICR has launched several large-scale programs including the Ontario Health Study, the One Millimetre Cancer Challenge, the Cancer Stem Cell Program, the Pancreatic Cancer Genome Project (which is part of the International Cancer Genome Consortium), the Terry Fox Research Institute/OICR Selective Therapies Program and High Impact Clinical Trials. Dr. Hudson is internationally renowned for his work in genomics and human genome variation. Past positions include leadership roles as Director of the McGill University and Genome Quebec Innovation Centre and Assistant-Director of the Whitehead/MIT Center for Genome Research, where he led a team that generated physical and gene maps of the human and mouse genomes. Dr. Hudson has been a founding member of the International Haplotype Map Consortium, the Public Population Project in Genomics (P3G) and the International Cancer Genome Consortium. Dr. Hudson's laboratory at OICR is involved in the study of genome variation that affects cancer predisposition, progression, and response to therapy. His main project focuses on the genetic architecture of loci associated with risk to colorectal cancer. In 2007, Dr. Hudson was appointed to the rank of Professor in the Department of Molecular Genetics at the University of Toronto. Dr. Hudson is a fellow of the Royal Society of Canada. He is editor-in-chief of the journal Human Genetics. Dr. Hudson has co-authored over 200 peer-reviewed scientific publications.
John McPherson replaced Thomas Hudson for Presentation of Theme 5 – Clinical Applications
John McPherson Genome Technologies Director Ontario Institute for Cancer Research
Dr. John McPherson is the Director of Genome Technologies at the Ontario Institute for Cancer Research in Toronto. The Genome Technologies Platform is cataloguing genetic alterations that occur in different types of cancers to better classify tumours and refine and develop new targeted treatments and diagnostic tools. Dr. McPherson received his PhD in Biochemistry from Queen’s University in 1989. He then moved to the United States where he contributed to the Human Genome Sequencing Project, first at the National Human Genome Research Center at the University of California, Irvine, then moving to the Genome Sequencing Center at Washington University’s School of Medicine. In addition to serving as Chair of iBOL’s Technology Development Advisory Group, Dr. McPherson also serves as a member of the Scientific Advisory Board for the U.S. National Science Foundation’s Medicago Hapmap Project.
Lincoln Stein Platform Leader, Informatics and Bio-computing Ontario Institute for Cancer Research (OICR)
Lincoln Stein is an MD/PhD who works on biological data integration and visualization. After his training at Harvard Medical School, where he became a board-certified pathologist, he worked at the Whitehead Institute/MIT Center for Genome Research developing databases used for the mouse and human genome maps. From 1998-2008 he worked at Cold Spring Harbor Laboratory on a variety of genome-scale databases including WormBase, the database of the C. elegans genome, Gramene, a comparative genome mapping database for rice and other monocots, the International HapMap Project Database, and a human biological pathways database called Reactome. He is now Director of Informatics and Biocomputing at the Ontario Institute for Cancer Research in Toronto, where he works on the International Cancer Genome Consortium and other large-scale genomic data integration projects.
Ajay Royyuru
Senior Manager, Computational Biology Center Thomas J. Watson Research Center, Yorktown Heights, NY
Ajay Royyuru heads the Computational Biology Center at IBM Research, with research groups engaged in various projects including bioinformatics, protein science, functional genomics, systems biology, and computational neuroscience. Dr. Royyuru joined IBM Research in 1998, initiating research in structural biology. He is a member of IBM Academy of Technology. Dr. Royyuru obtained his PhD in Molecular Biology from Tata Institute of Fundamental Research, Mumbai, a BSc (Hons.) in Human Biology and an MSc in Biophysics from All India Institute of Medical Sciences, New Delhi. He did post-doctoral work in structural biology at Memorial Sloan-Kettering Cancer Center, New York. Working with biologists and institutions around the world, he is engaged in research that will advance personalized, information-based medicine. Ajay Royyuru leads the IBM Research team working with the National Geographic Society on the Genographic Project. He has authored numerous research publications and several patents in structural and computational biology.