15
1 RBelgium Stat'Rgy RHadoop: introduction Jean-Baptiste Poullet (RBelgium Founder)
| Date post: | 15-Jul-2015 |
| Category: |
Data & Analytics |
| Upload: | jean-baptiste-poullet |
| View: | 117 times |
| Download: | 1 times |

1RBelgiumStat'Rgy
RHadoop: introductionJean-Baptiste Poullet (RBelgium Founder)

2RBelgiumStat'Rgy
Content
Intro and docsGet started with Rhadooprhdfs, rhbase, rmr, plyrmr

3RBelgiumStat'Rgy
Introduction and docs
Hadoop For Dummies - Dirk deRoosHadoop – The Definitive Guide - Tom WhiteRHadoop: make use of Hadoop framework from R
https://github.com/RevolutionAnalytics/rmr2/blob/master/docs/tutorial.md Big Data Analytics with R and Hadoop - Vignesh Prajapati

4RBelgiumStat'Rgy
Get started
Download cloudera VM http://www.cloudera.com/content/cloudera/en/documentation/DemoVMs/Cloudera-QuickStart-VM/cloudera_quickstart_vm.html
This VM runs CentOS CDH5.3R 3.xJava v1.7.x
Download RHadoophttps://github.com/RevolutionAnalytics/RHadoop/wiki/Downloads

5RBelgiumStat'Rgy
Get started with RHadoop
Make sure the packages are installed systemwise
Install Rcpp
Install rmr2

6RBelgiumStat'Rgy
Get started with RHadoop
Install rhdfs
Enable HDFS
You might also need to configure your JAVA_HOME environment variable

8RBelgiumStat'Rgy
RHadoop

9RBelgiumStat'Rgy
rhdfs
/home/jpoullet/Rscript/testing/config.R

10RBelgiumStat'Rgy
rhbase

11RBelgiumStat'Rgy
rmr2

12RBelgiumStat'Rgy
plyrmr
bind.cols , transmute and where instead of transform , summarize and subset
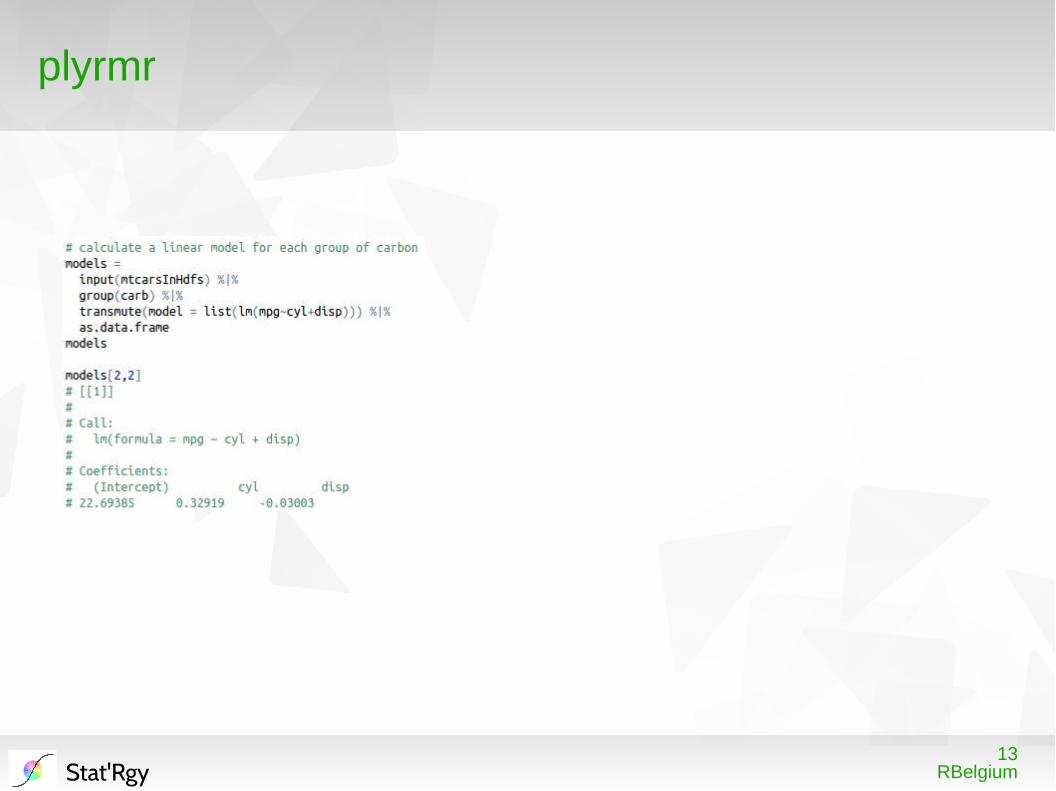
13RBelgiumStat'Rgy
plyrmr
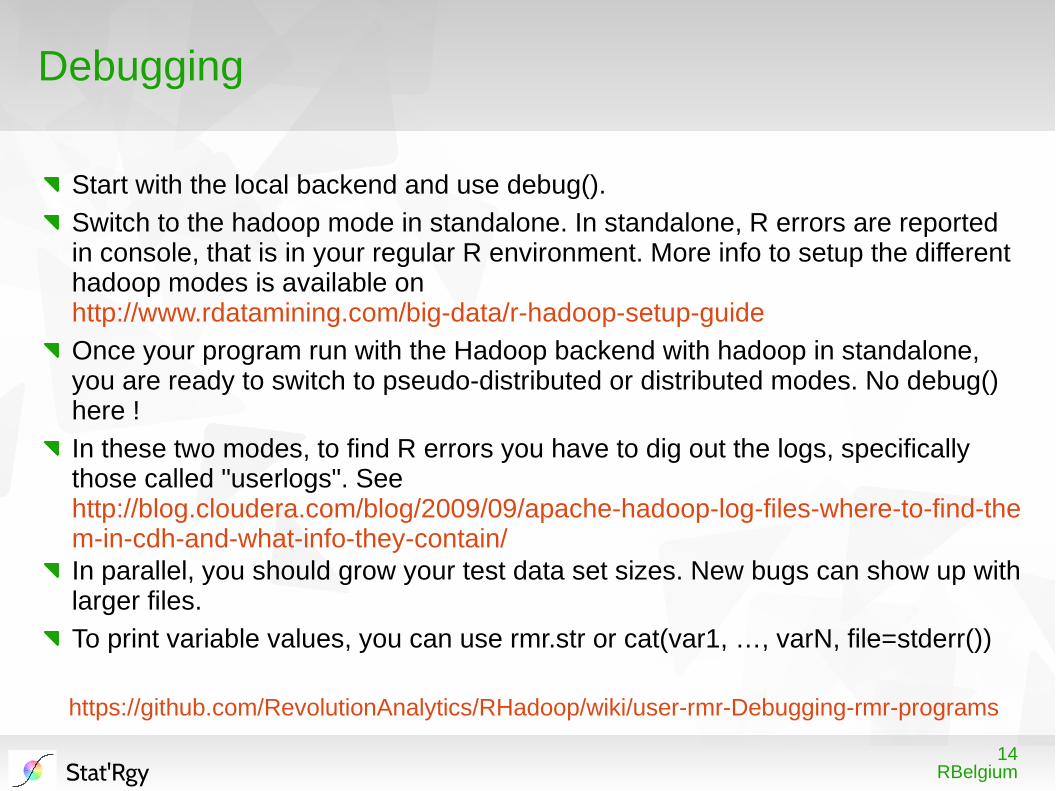
14RBelgiumStat'Rgy
Debugging
Start with the local backend and use debug().
Switch to the hadoop mode in standalone. In standalone, R errors are reported in console, that is in your regular R environment. More info to setup the different hadoop modes is available on http://www.rdatamining.com/big-data/r-hadoop-setup-guide
Once your program run with the Hadoop backend with hadoop in standalone, you are ready to switch to pseudo-distributed or distributed modes. No debug() here !
In these two modes, to find R errors you have to dig out the logs, specifically those called "userlogs". See http://blog.cloudera.com/blog/2009/09/apache-hadoop-log-files-where-to-find-them-in-cdh-and-what-info-they-contain/In parallel, you should grow your test data set sizes. New bugs can show up with larger files.
To print variable values, you can use rmr.str or cat(var1, …, varN, file=stderr())
https://github.com/RevolutionAnalytics/RHadoop/wiki/user-rmr-Debugging-rmr-programs

15RBelgiumStat'Rgy
Debugging

16RBelgiumStat'Rgy
Thanks !

















