53
MEGaVis: Perceptual Decisions in the Face of Explicit Costs and Benefits Michael S. Landy Julia Trommershäuser Laurence T. Maloney Ross Goutcher Pascal Mamassian
| Date post: | 21-Dec-2015 |
| Category: |
Documents |
| View: | 214 times |
| Download: | 1 times |

MEGaVis: Perceptual Decisions in the Face of Explicit Costs and
Benefits
Michael S. Landy
Julia Trommershäuser
Laurence T. Maloney
Ross Goutcher
Pascal Mamassian

Statistical/Optimal Modelsin Vision & Action
• Sequential Ideal Observer Analysis
• Statistical Models of Cue Combination
• Statistical Models of Movement Planning and Control– Minimum variance movement planning/control– MEGaMove – Maximum Expected Gain model
for Movement planning

Statistical/Optimal Modelsin Vision & Action
• MEGaMove – Maximum Expected Gain model for Movement planning– A choice of movement plan fixes the
probabilities pi of each possible outcome i with gain Gi
– The resulting expected gain EG=p1G1+p2G2+…– A movement plan is chosen to maximize EG– Uncertainty of outcome is due to both
perceptual and motor variability– Subjects are typically optimal for pointing tasks

Statistical/Optimal Modelsin Vision & Action
• MEGaMove – Maximum Expected Gain model for Movement planning
• MEGaVis – Maximum Expected Gain model for Visual estimation– Task: Orientation estimation, method of
adjustment– Do subjects remain optimal when motor
variability is minimized?– Do subjects remain optimal when visual
reliability is manipulated?

Task – Orientation Estimation

Task – Orientation Estimation

Task – Orientation Estimation
Payoff(100 points)
Penalty(0, -100 or-500 points, in separate blocks)

Task – Orientation Estimation
Payoff(100 points)
Penalty(0, -100 or-500 points, in separate blocks)

Task – Orientation Estimation

Task – Orientation Estimation

Task – Orientation Estimation

Task – Orientation Estimation

Task – Orientation Estimation

Task – Orientation Estimation

Task – Orientation Estimation

Task – Orientation Estimation
Task – Orientation Estimation
Done!

Task – Orientation Estimation

Task – Orientation Estimation

Task – Orientation Estimation
100

Task – Orientation Estimation
-400

Task – Orientation Estimation
-500

Task – Orientation Estimation
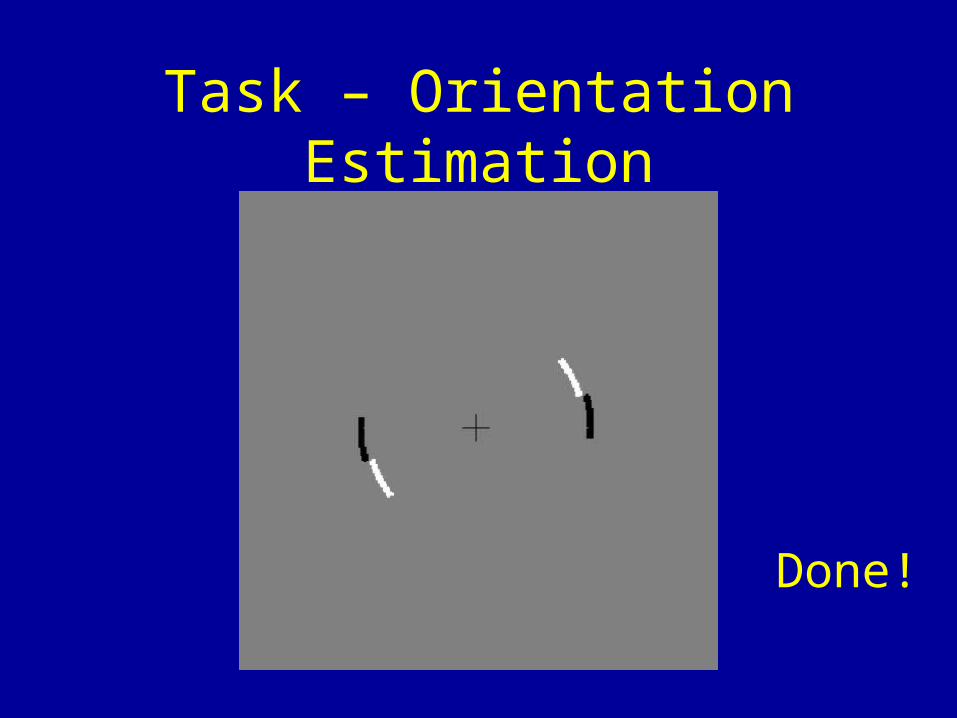
• Align the white arcs with the remembered mean orientation to earn points
• Avoid alignment with the black arcs to avoid the penalty
• Feedback provided as to whether the payoff, penalty, both or neither were awarded

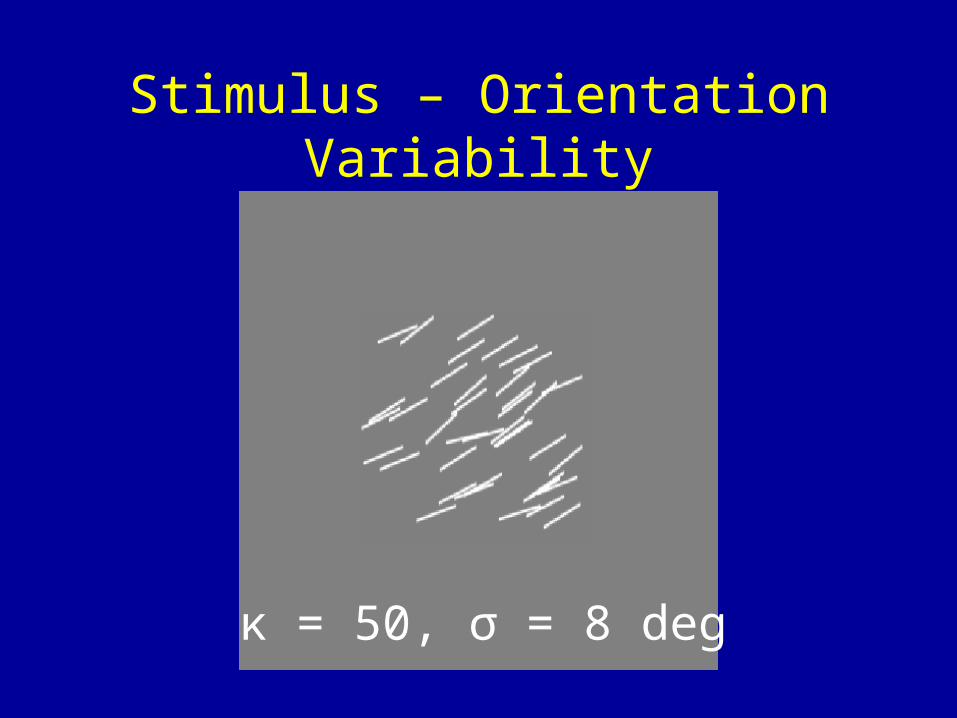
Task – Orientation Estimation• Three levels of orientation variability
– Von Mises κ values of 500, 50 and 5– Corresponding standard deviations of 2.6, 8 and
27 deg
• Two spatial configurations of white target arc and black penalty arc (abutting or half overlapped)
• Three penalty levels: 0, 100 and 500 points
• One payoff level: 100 points

Stimulus – Orientation Variability
κ = 500, σ = 2.6 deg
Stimulus – Orientation Variability
κ = 50, σ = 8 deg

Stimulus – Orientation Variability
κ = 5, σ = 27 deg

Payoff/Penalty Configurations

Payoff/Penalty Configurations

Payoff/Penalty Configurations

Payoff/Penalty Configurations

Where should you “aim”?Penalty = 0 case
Payoff(100 points)
Penalty(0 points)

Where should you “aim”?Penalty = -100 case
Payoff(100 points)
Penalty(-100 points)

Where should you “aim”?Penalty = -500 case
Payoff(100 points)
Penalty(-500 points)

Where should you “aim”?Penalty = -500, overlapped penalty case
Payoff(100 points)
Penalty(-500 points)

Where should you “aim”?Penalty = -500, overlapped penalty,
high image noise case
Payoff(100 points)
Penalty(-500 points)
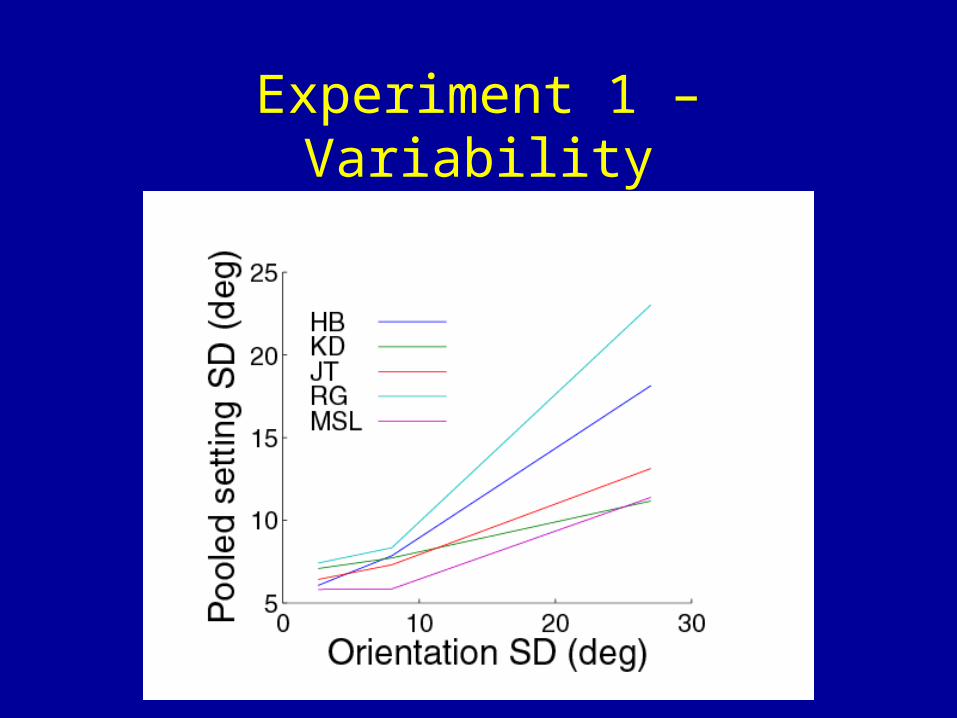
Experiment 1 – Variability
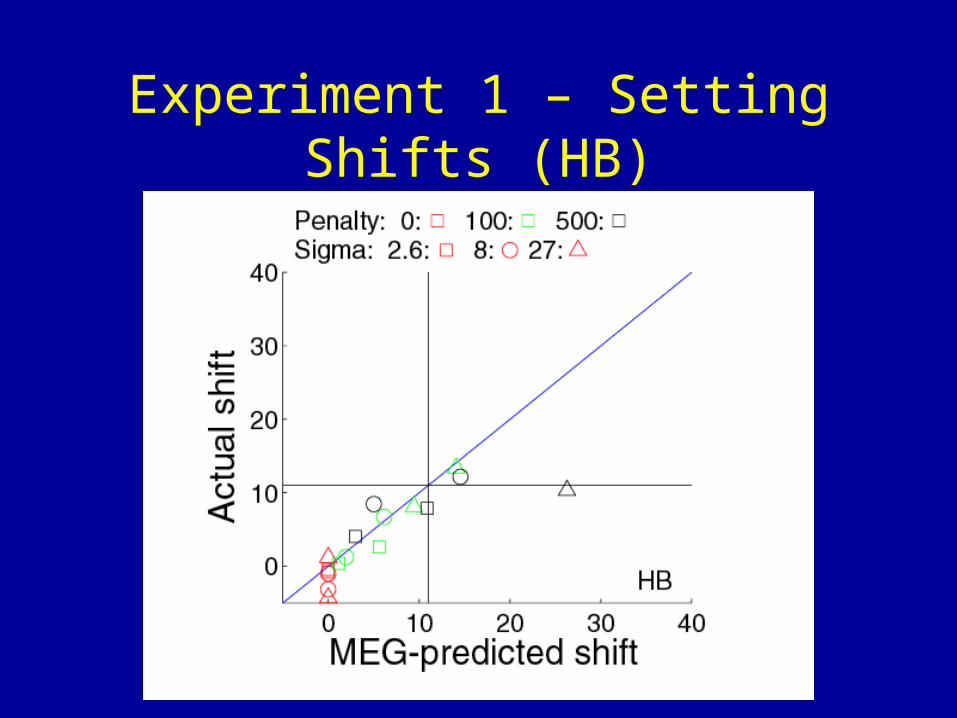
Experiment 1 – Setting Shifts (HB)
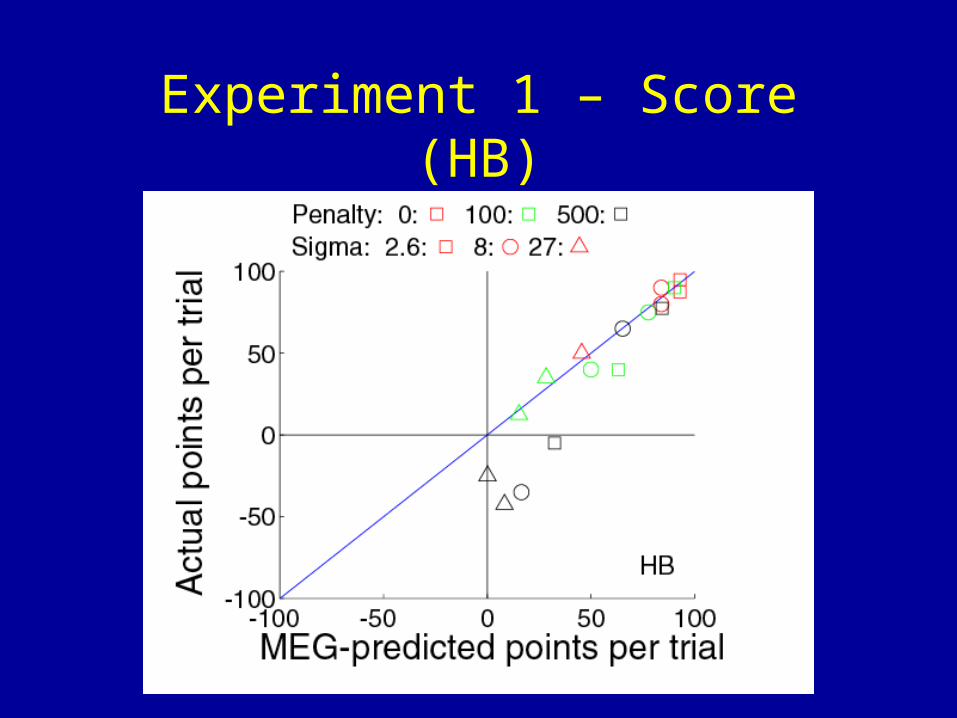
Experiment 1 – Score (HB)
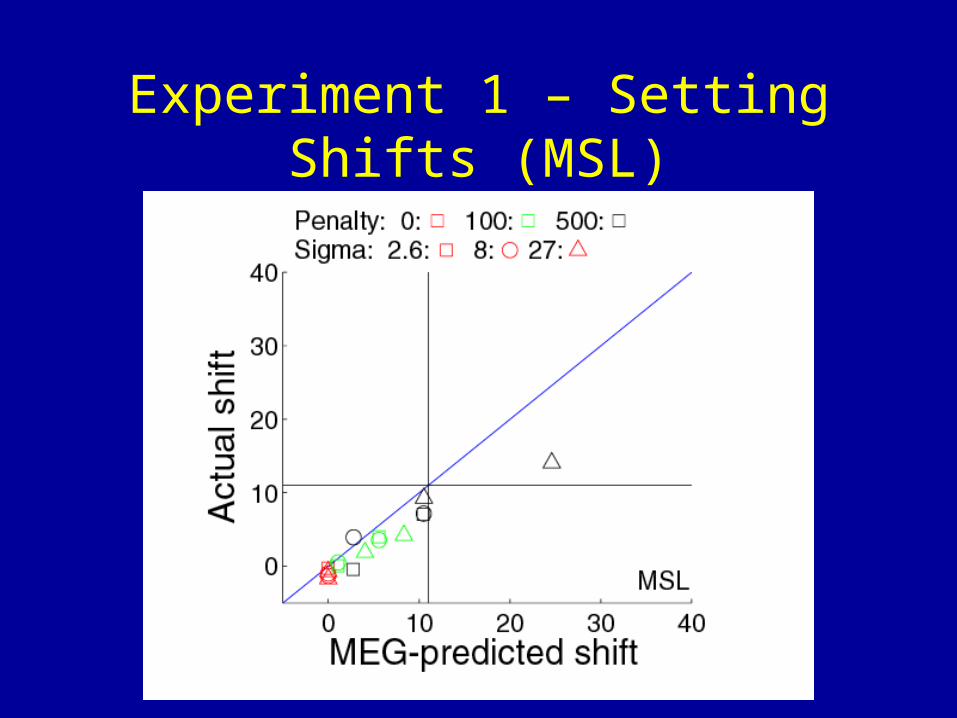
Experiment 1 – Setting Shifts (MSL)
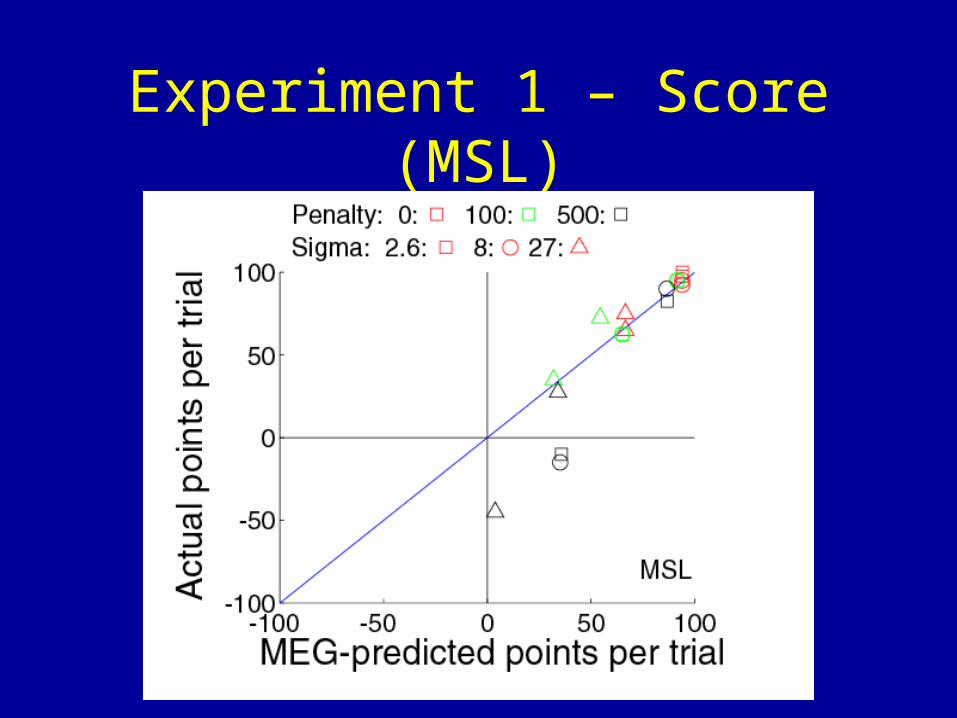
Experiment 1 – Score (MSL)

Experiment 1 – Setting Shifts(3 more subjects)
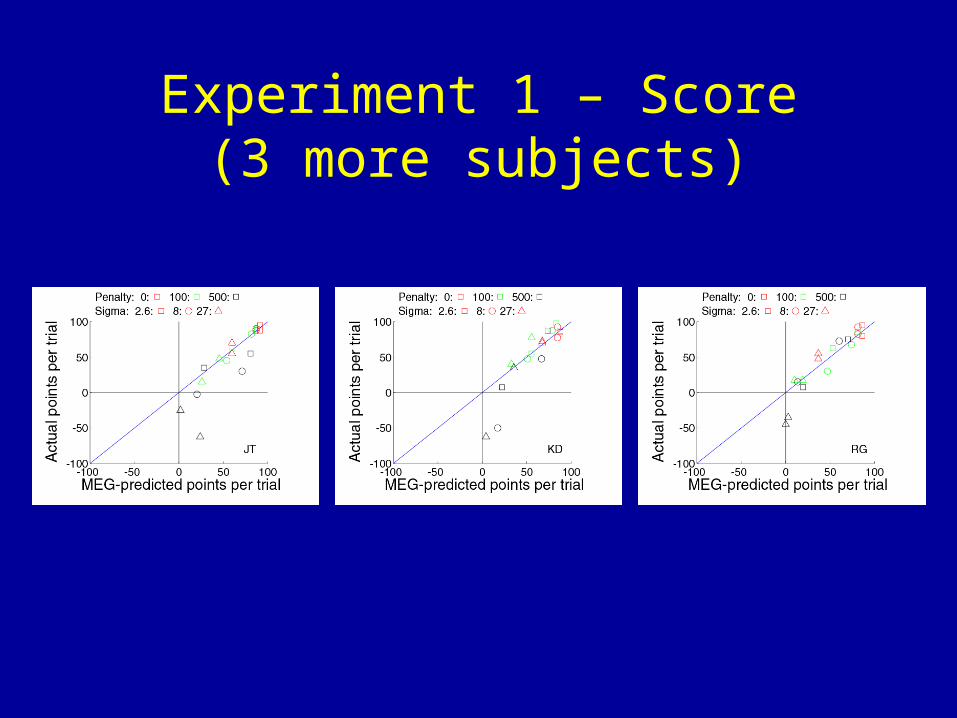
Experiment 1 – Score(3 more subjects)
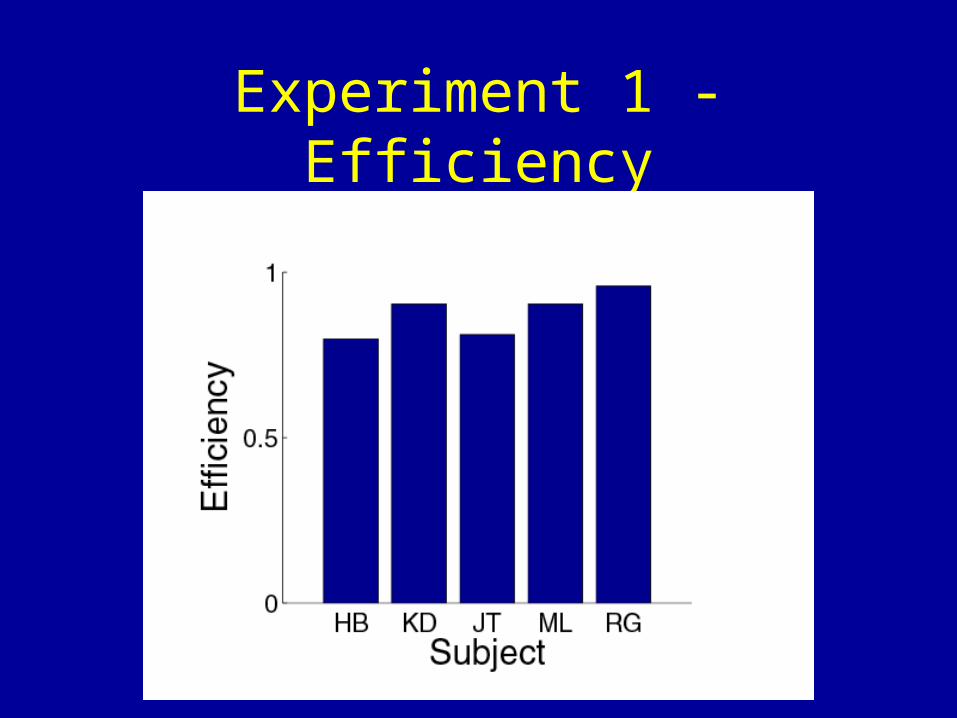
Experiment 1 - Efficiency

Intermediate Conclusions
• Subjects are by and large near-optimal in this task• That means they take into account their own
variability in each condition as well as the penalty level and payoff/penalty configuration
• Can they respond to changing variability on a trial-by-trial basis?
• → Re-run using a mixed-list design (all noise levels mixed together in a block; only penalty level is blocked)
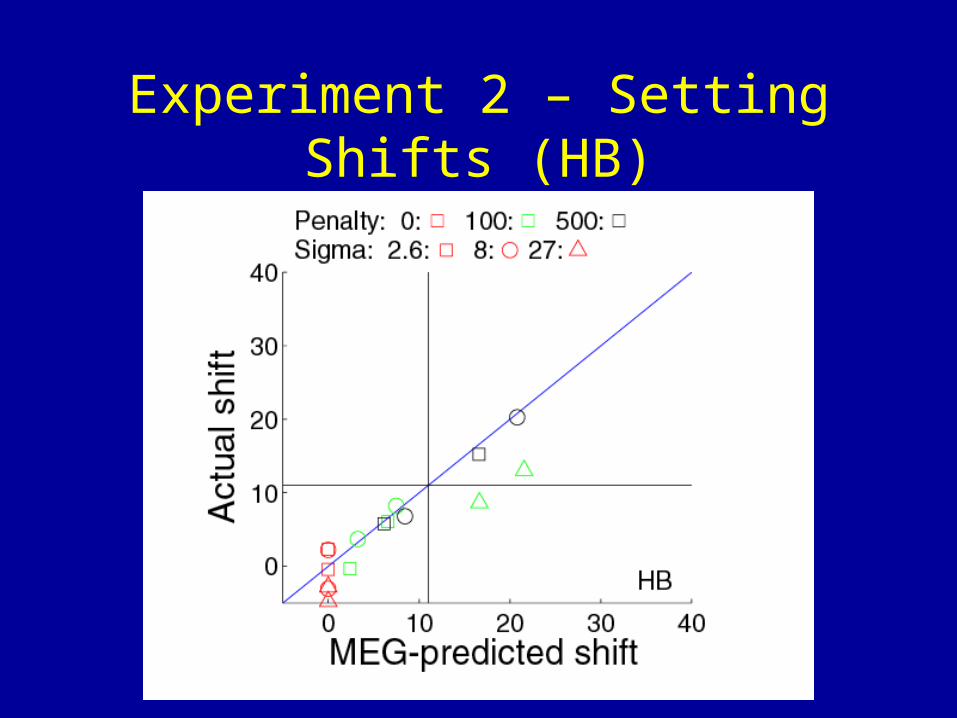
Experiment 2 – Setting Shifts (HB)
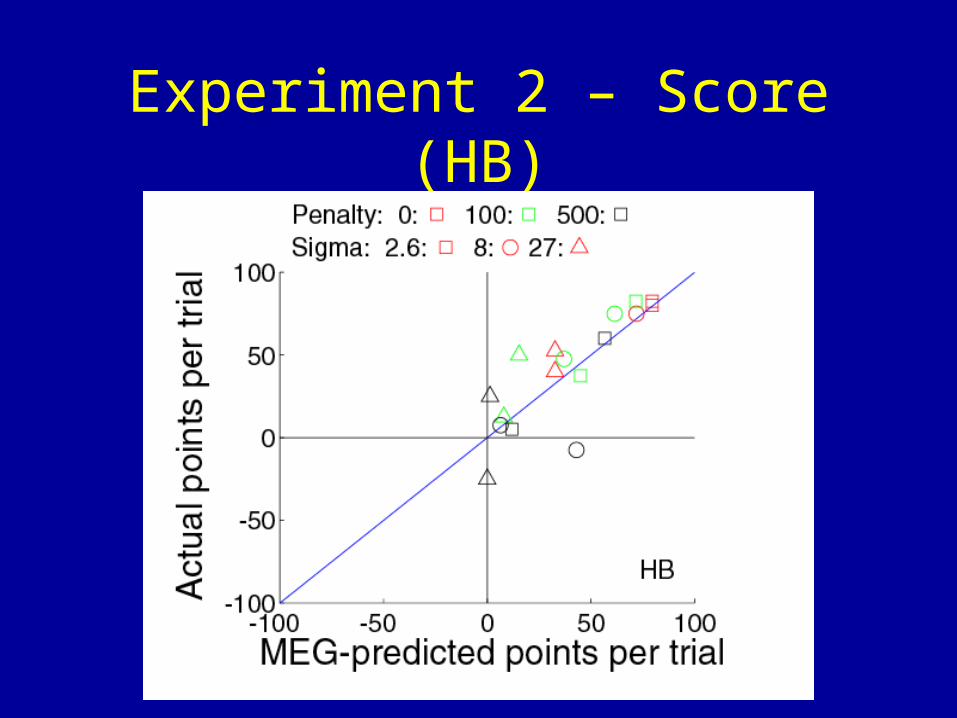
Experiment 2 – Score (HB)
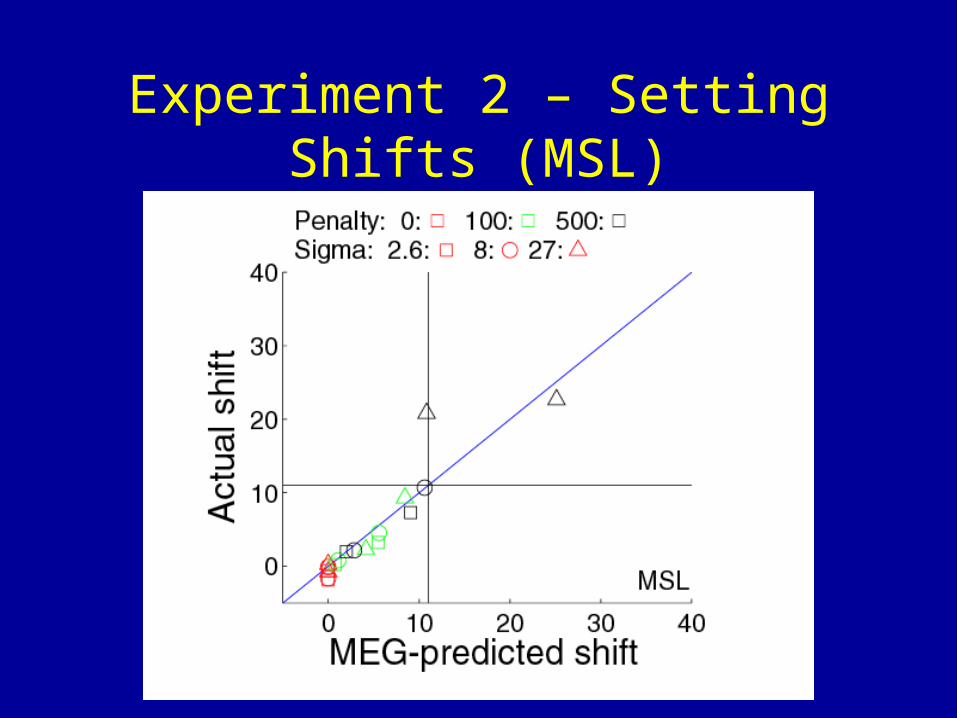
Experiment 2 – Setting Shifts (MSL)
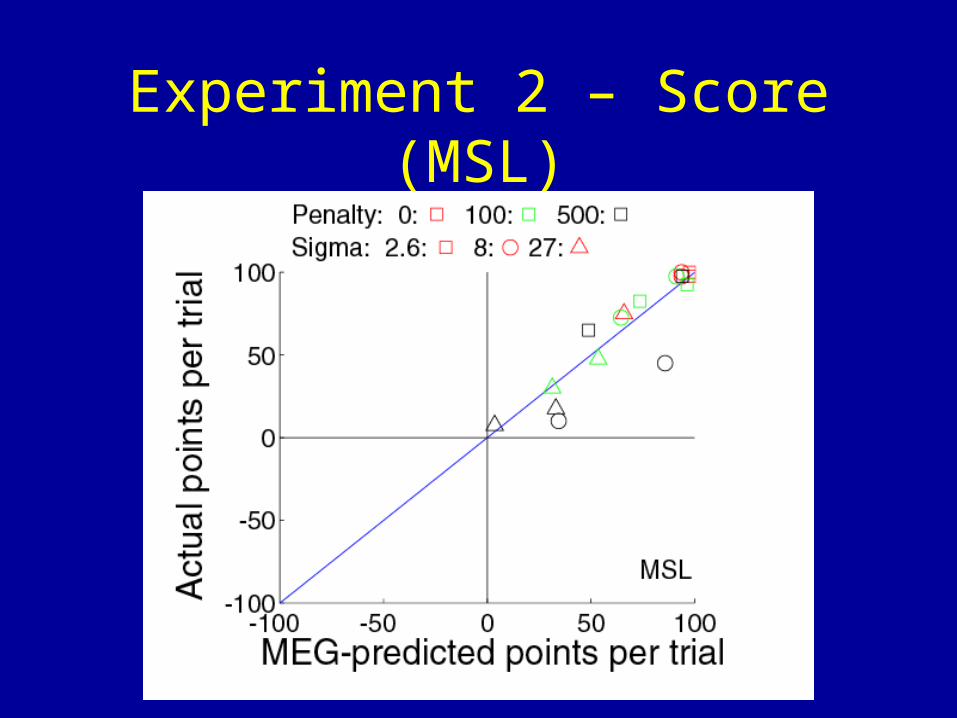
Experiment 2 – Score (MSL)
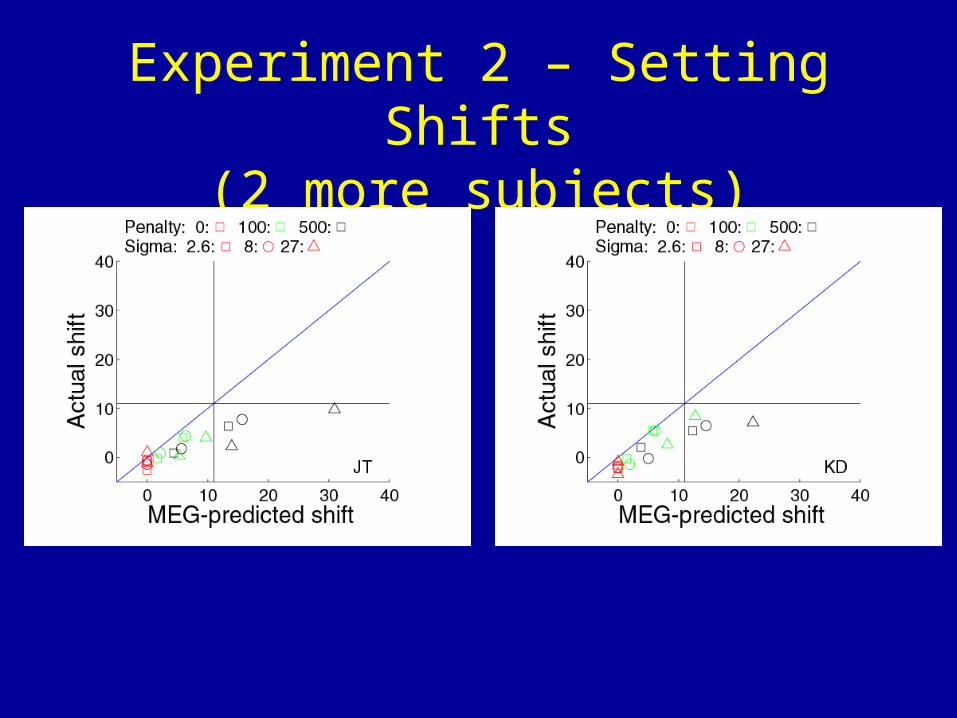
Experiment 2 – Setting Shifts(2 more subjects)
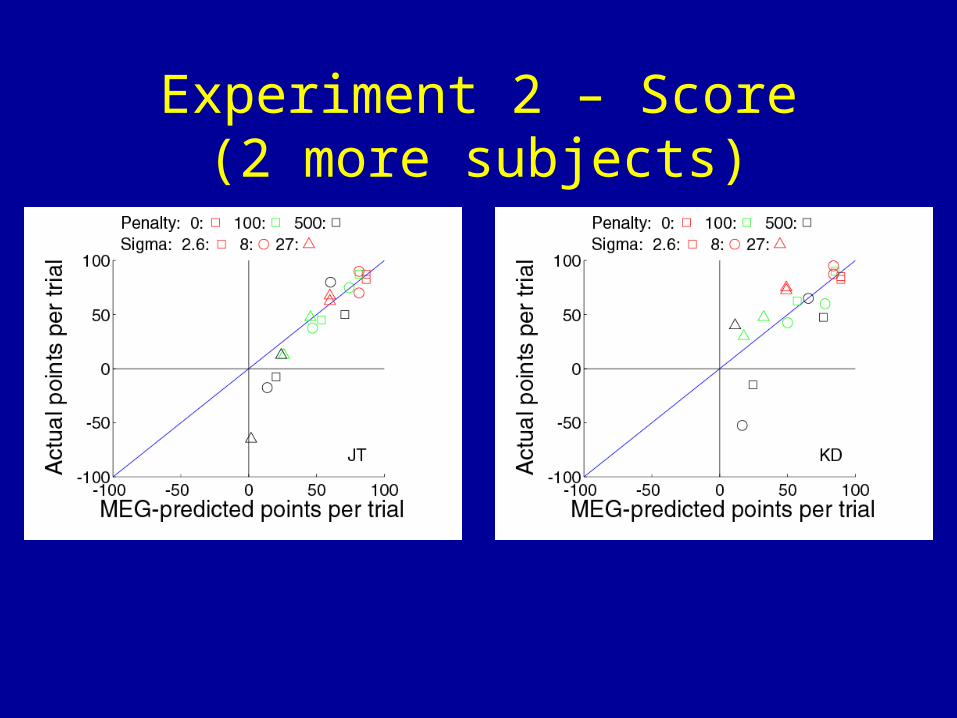
Experiment 2 – Score(2 more subjects)
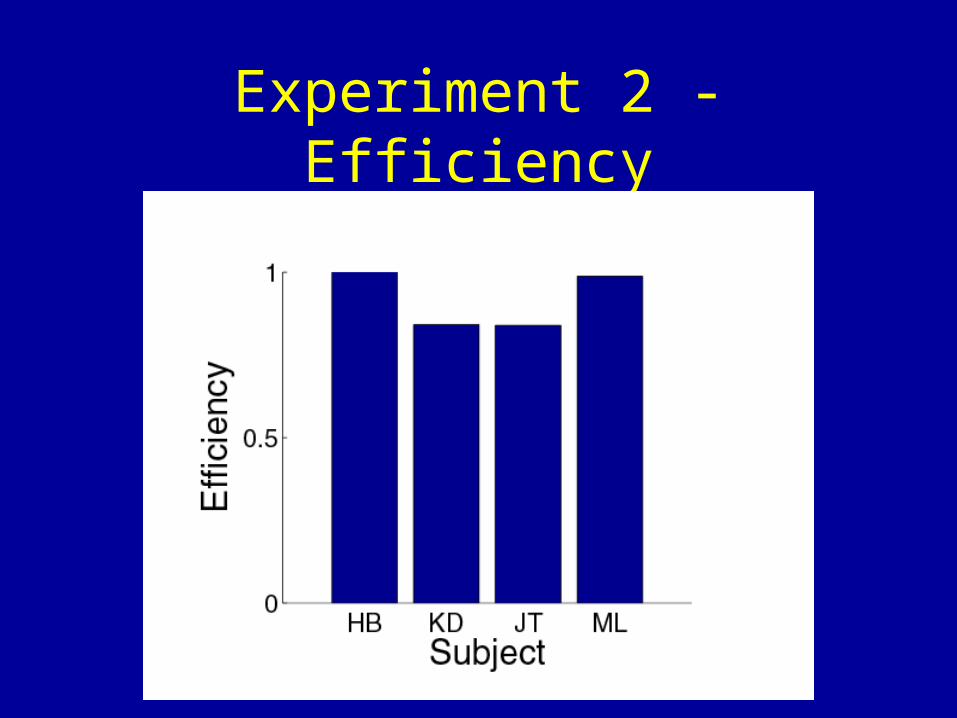
Experiment 2 - Efficiency

Conclusion
• Subjects are nearly optimal in all conditions
• Thus, effectively they are able to calculate and maximize effective gain across a variety of target/penalty configurations, penalty values and stimulus uncertainties
• The main sub-optimality is an unwillingness to “aim” outside of the target
• This is “risk-seeking” behavior, unlike what is seen in paper-and-pencil decision tasks










