Methods for Understanding How Deep Neural Networks Work Dr. Wojciech Samek Head of Machine Learning Group Fraunhofer Heinrich Hertz Institute Vision Industry and Technology Forum 6th Sep 2017, Hamburg, Germany
Transcript
Methods for Understanding How
Deep Neural Networks Work
Dr. Wojciech Samek
Head of Machine Learning Group
Fraunhofer Heinrich Hertz Institute
Vision Industry and Technology Forum 6th Sep 2017, Hamburg, Germany
Unbeatable AI Systems
AlphaGo beats Go
human champ
Deep Net outperforms humans
in image classification
Deep Net beats human at
recognizing traffic signs
DeepStack beats
professional poker players
Computer out-plays
humans in "doom"
Autonomous search-and-rescue
drones outperform humans
IBM's Watson destroys
humans in jeopardy
Elon Musk (2017): “AI will be able to beat humans at
EVERYTHING by 2030.”
Unbeatable AI Systems
You may heard such promises before
H. A. Simon (1965): "Machines will be capable, within
twenty years, of doing any work a man can do."
M. Minsky (1970): "In from three to eight years we will
have a machine with the general intelligence of an
average human being."
Computing power
Very large deep neural networks Information (implicit)
Solve task
Huge volumes of data
Past promises did not become reality, but today …
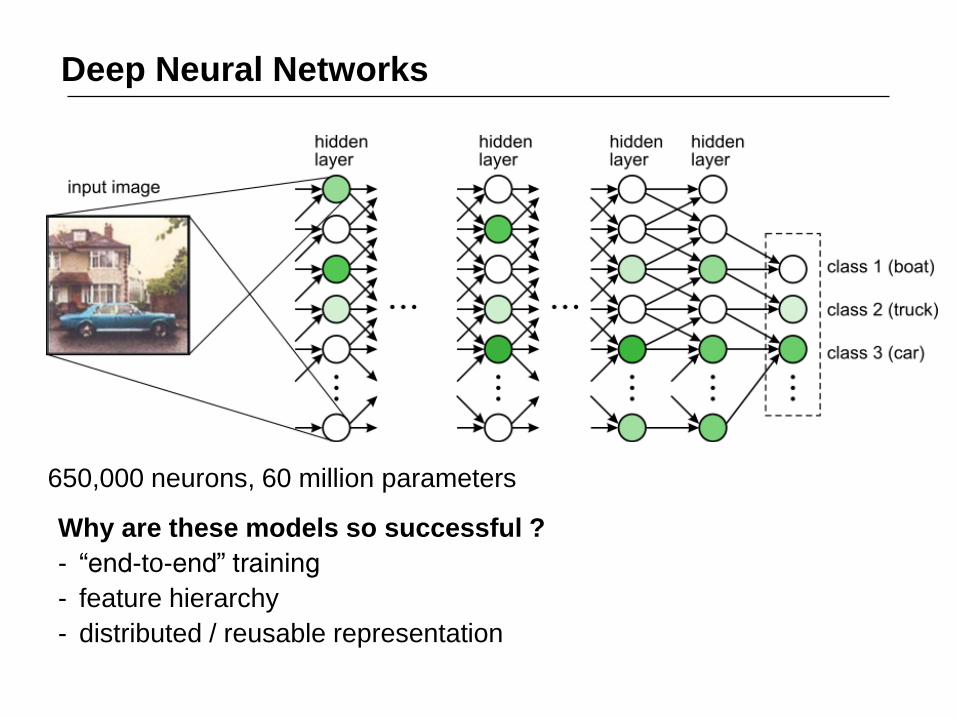
650,000 neurons, 60 million parameters
Deep Neural Networks
Why are these models so successful ?
- “end-to-end” training
- feature hierarchy
- distributed / reusable representation
Deep Neural Networks: “End-to-End” Training
“Slippery road”
Traditional Approaches
input feature extraction classification output
Deep Learning
“Slippery road”
input feature extraction + classification output
(Source: Yann LeCun
Deep Neural Networks: Feature Hierarchy
Low level
features
Mid level
features
High level
featuresClassifier
“Car”
Hierarchical information processing in the brain
Deep Neural Networks: Feature Hierarchy
(Source: Simon Thorpe)
Deep Neural Networks: Reusable Representation
Features extracted from “car” images can be used for
other tasks / classification of other objects.
objects with
roundish shape
Very large deep neural networks Information (implicit)
What did the neural network learn ?
How does it solve the problem ?
Can we extract human interpretable information ?
Do we understand the AI ?
Can we trust these “end-to-end” trained black box algorithms ?












































![Do Deep Neural Networks Suffer from Crowding? - CBMM · Do Deep Neural Networks Suffer from ... Despite stunning successes in many computer vision problems [1–5], Deep Neural Networks](https://static.documents.pub/doc/80x56/5ac1231e7f8b9aca388cb550/do-deep-neural-networks-suffer-from-crowding-cbmm-deep-neural-networks-suffer.jpg)
