Micro-Pages: Increasing DRAM Efficiency with Locality-Aware Data Placement Kshitij Sudan, Niladrish Chatterjee, David Nellans, Manu Awasthi, Rajeev Balasubramonian, Al Davis School of Computing, University of Utah ASPLOS-2010
Transcript
Micro-Pages: Increasing DRAM Efficiency with Locality-Aware Data
Placement
Kshitij Sudan, Niladrish Chatterjee, David Nellans, Manu Awasthi, Rajeev Balasubramonian, Al Davis
School of Computing, University of Utah
ASPLOS-2010
2
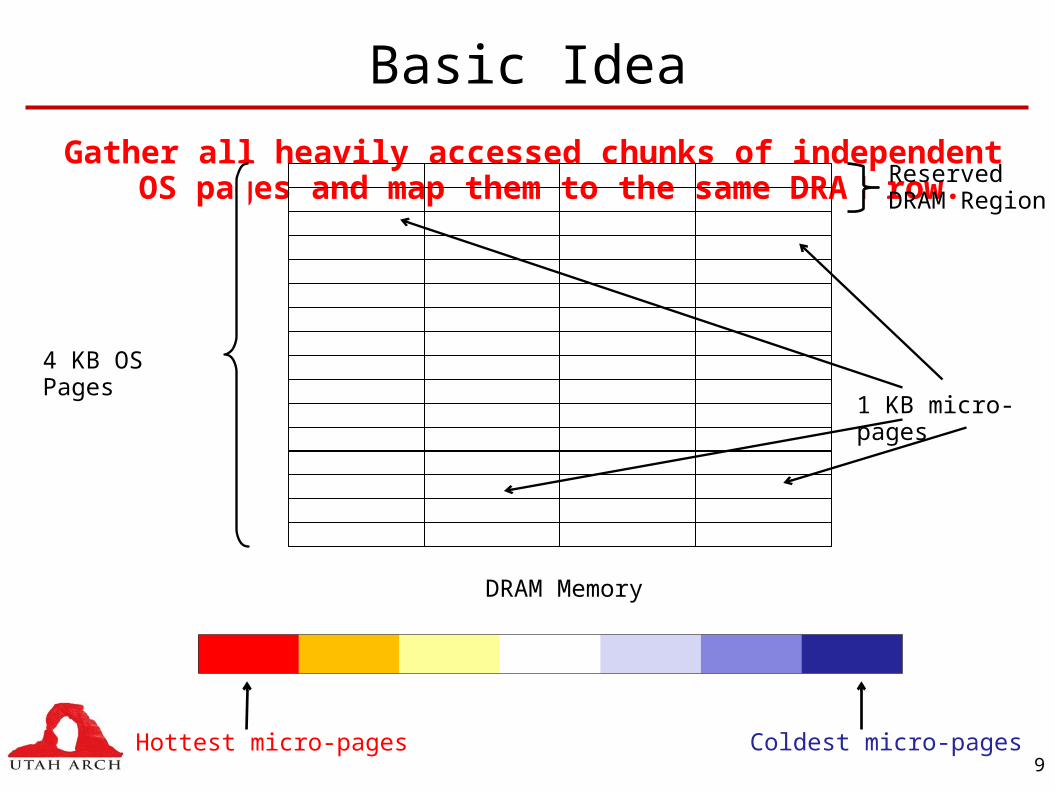
DRAM Memory Constraints
• Modern machines spend nearly 25% - 40% of total system power for memory.• Some commercial servers already have larger power budgets for
memory than CPU.
• Main memory access is one of the largest performance bottlenecks.
We address both performance and power concerns for DRAM memory accesses.
3
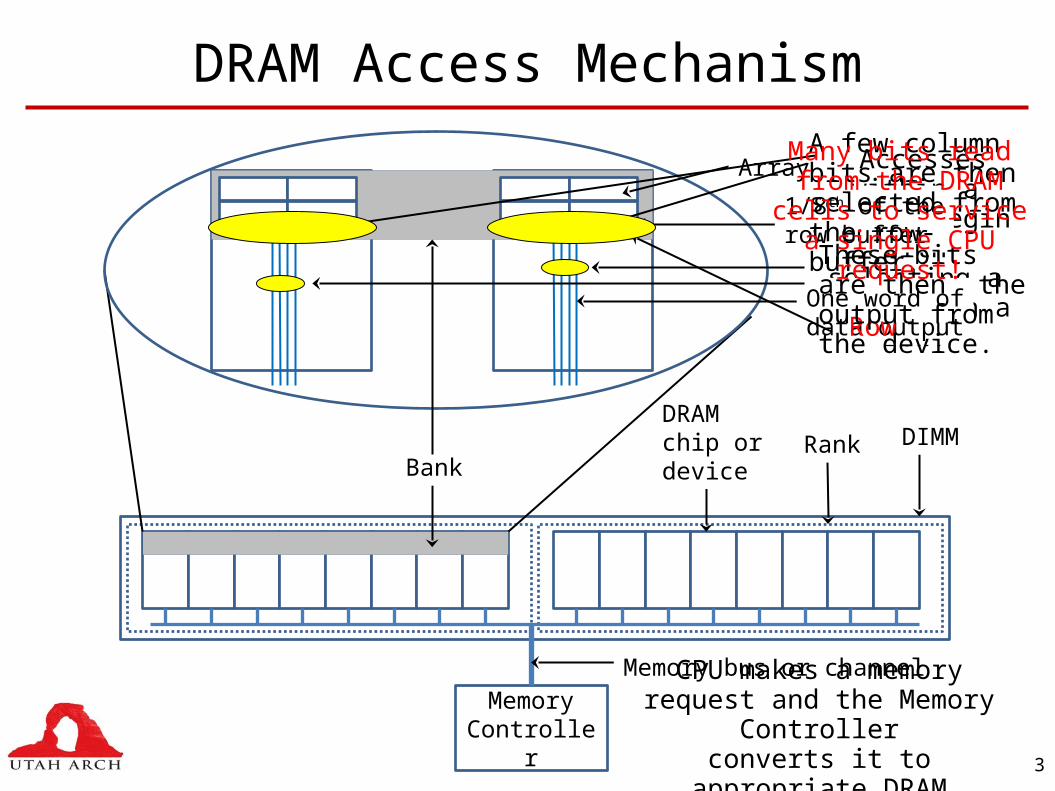
DRAM Access Mechanism
…
Memory Controller
Memory bus or channel
RankDRAMchip ordeviceBank
Array
DIMM
CPU makes a memory request and the Memory Controller
converts it to appropriate DRAM commands.
Accesses within a device begin with selecting a bank,
then a row.
1/8th of therow buffer
One word ofdata outputRow
A few column bits are then selected from the row-buffer. These bits are then the output from the device.
Many bits read from the DRAM cells to service a
single CPU request!
4
DRAM Access Inefficiencies - I
• Over fetch due to large row-buffers.• 8 KB read into row buffer for a 64 byte cache line.
• Row-buffer utilization for a single request < 1%.
• Why are row buffers so large?• Large arrays minimize cost-per-bit.
• Striping a cache line across multiple chips (arrays) improves data transfer bandwidth.
5
DRAM Access Inefficiencies - II
• Open page policy• Row buffers kept open with the hope that subsequent requests will be
row buffer hits.
• FR-FCFS request scheduling (First-Ready FCFS)• Memory controller schedules requests to open row-buffers first.