Page 1
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 1
© 2001 D.A.Reynolds and L.P.Heck
Speaker Verification: From Research to Reality
Douglas A. Reynolds, PhDSenior Member of Technical
StaffM.I.T. Lincoln Laboratory
Larry P. Heck, PhDSpeaker Verification R&DNuance Communications
This work was sponsored by the Department of Defense under Air Force contract F19628-00-C-0002. Opinions, interpretations, conclusions, and recommendations are those of the authors and are not necessarily endorsed by the Department of Defense.
ICASSP Tutorial Salt Lake City, UT
7 May 2001
Page 2
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 2
© 2001 D.A.Reynolds and L.P.Heck
Speaker Verification: From Research to Reality
This material may not be reproduced in whole or part without written permission from the authors
This material may not be reproduced in whole or part without written permission from the authors
ICASSP Tutorial Salt Lake City, UT
7 May 2001
Page 3
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 3
© 2001 D.A.Reynolds and L.P.Heck
Tutorial Outline
• Part I : Background and Theory– Overview of area– Terminology– Theory and structure of verification systems– Channel compensation and adaptation
• Part II : Evaluation and Performance– Evaluation tools and metrics– Evaluation design– Publicly available corpora– Performance survey
• Part III : Applications and Deployments– Brief overview of commercial speaker verification systems– Design requirements for commercial verifiers– Steps to deployment– Examples of deployments
Page 4
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 4
© 2001 D.A.Reynolds and L.P.Heck
Goals of Tutorial
• Understand major concepts behind modern speaker verification systems
• Identify the key elements in evaluating performance of a speaker verification system
• Define the main issues and tasks in deploying a speaker verification system
Page 5
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 5
© 2001 D.A.Reynolds and L.P.Heck
Part I : Background and TheoryOutline
• Overview of area– Applications– Terminology
• General Theory– Features for speaker recognition– Speaker models– Verification decision
• Channel compensation
• Adaptation
• Combination of speech and speaker recognizers
Page 6
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 6
© 2001 D.A.Reynolds and L.P.Heck
Extracting Information from Speech
SpeechRecognition
LanguageRecognition
SpeakerRecognition
Words
Language Name
Speaker Name
“How are you?”
English
James Wilson
Speech Signal
Goal: Automatically extract information transmitted in speech signal
Page 7
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 7
© 2001 D.A.Reynolds and L.P.Heck
Evolution of Speaker Recognition
• This tutorial will focus on techniques and performance of state-of-the art systems
1970
Dynamic Time-Warping Vector Quantization
1980
Hidden Markov Models Gaussian Mixture Models
19902001Template matching
1960
Large databases, realistic,
unconstrained speech
Large databases, realistic,
unconstrained speech
Small databases, clean, controlled
speech
Small databases, clean, controlled
speech
Aural and spectrogram matching
1930-
Commercial application of speaker recognition technology
Commercial application of speaker recognition technology
Page 8
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 8
© 2001 D.A.Reynolds and L.P.Heck
Speaker Recognition Applications
Access Control Physical facilities
Computer networks and websites
Access Control Physical facilities
Computer networks and websites
Transaction AuthenticationTelephone banking
Remote credit card purchases
Transaction AuthenticationTelephone banking
Remote credit card purchases
Speech Data ManagementVoice mail browsing
Speech skimming
Speech Data ManagementVoice mail browsing
Speech skimming
PersonalizationIntelligent answering machine
Voice-web / device customization
PersonalizationIntelligent answering machine
Voice-web / device customization
Law EnforcementForensics
Home parole
Law EnforcementForensics
Home parole
Page 9
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 9
© 2001 D.A.Reynolds and L.P.Heck
Terminology
• The general area of speaker recognition can be divided into two fundamental tasks
VerificationVerificationIdentificationIdentificationIdentificationIdentification
Speaker recognitionSpeaker recognitionSpeaker recognitionSpeaker recognition
• Any work on speaker recognition should identify which task is being addressed
Page 10
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 10
© 2001 D.A.Reynolds and L.P.Heck
TerminologyIdentification
• Determines whom is talking from set of known voices
• No identity claim from user (one to many mapping)
• Often assumed that unknown voice must come from set of known speakers - referred to as closed-set identification
?
?
?
?
Whose voice is this?Whose voice is this?
Page 11
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 11
© 2001 D.A.Reynolds and L.P.Heck
Terminology Verification/Authentication/Detection
• Determine whether person is who they claim to be
• User makes identity claim (one to one mapping)
• Unknown voice could come from large set of unknown speakers - referred to as open-set verification
• Adding “none-of-the-above” option to closed-set identification gives open-set identification
?
Is this Bob’s voice?Is this Bob’s voice?
Page 12
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 12
© 2001 D.A.Reynolds and L.P.Heck
Terminology Segmentation and Clustering
• Determine when speaker change has occurred in speech signal (segmentation)
• Group together speech segments from same speaker (clustering)
• Prior speaker information may or may not be available
Speaker B
Speaker A
Which segments are from the same speaker?Which segments are from the same speaker?
Where are speaker changes?Where are speaker changes?
Page 13
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 13
© 2001 D.A.Reynolds and L.P.Heck
TerminologySpeech Modalities
• Text-dependent recognition
– Recognition system knows text spoken by person
– Examples: fixed phrase, prompted phrase
– Used for applications with strong control over user input
– Knowledge of spoken text can improve system performance
Application dictates different speech modalities:
• Text-independent recognition
– Recognition system does not know text spoken by person
– Examples: User selected phrase, conversational speech
– Used for applications with less control over user input
– More flexible system but also more difficult problem
– Speech recognition can provide knowledge of spoken text
Page 14
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 14
© 2001 D.A.Reynolds and L.P.Heck
TerminologyVoice Biometric
Strongest security
• Speaker verification is often referred to as a voice biometric
• Biometric: a human generated signal or attribute for authenticating a person’s identity
• Voice is a popular biometric:
– natural signal to produce
– does not require a specialized input device
– ubiquitous: telephones and microphone equipped PC
• Voice biometric can be combined with other forms of security
– Something you have - e.g., badge
– Something you know - e.g., password
– Something you are - e.g., voice
HaveKnow
Are
Page 15
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 15
© 2001 D.A.Reynolds and L.P.Heck
Part I : Background and TheoryOutline
• Overview of area– Applications– Terminology
• General Theory– Features for speaker recognition– Speaker models– Verification decision
• Channel compensation
• Adaptation
• Combination of speech and speaker recognizers
Page 16
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 16
© 2001 D.A.Reynolds and L.P.Heck
General TheoryPhases of Speaker Verification System
Two distinct phases to any speaker verification system
Feature extraction
Feature extraction
Model training
Model training
Enrollment speech for each speaker
Bob
Sally
Model (voiceprint) for each speaker
Sally
Bob
Enrollment Enrollment PhasePhase
Model training
Model training
Accepted!Feature extraction
Feature extraction
Verificationdecision
Verificationdecision
Claimed identity: Sally
Verification Verification PhasePhase
Verificationdecision
Verificationdecision
Page 17
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 17
© 2001 D.A.Reynolds and L.P.Heck
General TheoryFeatures for Speaker Recognition
• Humans use several levels of perceptual cues for speaker recognition
Semantics, diction,pronunciations,idiosyncrasies
Socio-economicstatus, education,place of birth
Prosodics, rhythm,speed intonation,volume modulation
Personality type,parental influence
Acoustic aspect ofspeech, nasal,deep, breathy,rough
Anatomical structureof vocal apparatus
Semantics, diction,pronunciations,idiosyncrasies
Socio-economicstatus, education,place of birth
Prosodics, rhythm,speed intonation,volume modulation
Personality type,parental influence
Acoustic aspect ofspeech, nasal,deep, breathy,rough
Anatomical structureof vocal apparatus
High-level cues (learned traits)
Low-level cues (physical traits)
Easy to automatically extract
Difficult to automatically extract
Hierarchy of Perceptual Cues
• There are no exclusive speaker identity cues
• Low-level acoustic cues most applicable for automatic systems
Page 18
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 18
© 2001 D.A.Reynolds and L.P.Heck
General TheoryFeatures for Speaker Recognition
• Desirable attributes of features for an automatic system (Wolf ‘72)
• Occur naturally and frequently in speech
• Easily measurable
• Not change over time or be affected by speaker’s health
• Not be affected by reasonable background noise nor depend on specific transmission characteristics
• Not be subject to mimicry
• Occur naturally and frequently in speech
• Easily measurable
• Not change over time or be affected by speaker’s health
• Not be affected by reasonable background noise nor depend on specific transmission characteristics
• Not be subject to mimicry
Practical
Robust
Secure
• No feature has all these attributes
• Features derived from spectrum of speech have proven to be the most effective in automatic systems
Page 19
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 19
© 2001 D.A.Reynolds and L.P.Heck
General TheorySpeech Production
• Speech production model: source-filter interaction– Anatomical structure (vocal tract/glottis) conveyed in speech spectrum
Vocal tractGlottal pulses
Time (sec)
Speech signal
Time (sec)
Page 20
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 20
© 2001 D.A.Reynolds and L.P.Heck
General TheoryFeatures for Speaker Recognition
• Different speakers will have different spectra for similar sounds
Cross Section ofVocal Tract
/AE/
Cross Section of70605040302010
0
MaleSpeaker
FemaleSpeaker
MaleSpeaker
FemaleSpeaker14
1618
121086420
0 2000 4000 6000 00
0
1
2
3
4
123
45
2000 4000 6000
/I/
Vocal Tract
Frequency (Hz)
Ma
gn
itu
de
(d
B)
Frequency (Hz)
Ma
gn
itu
de
(d
B)
• Differences are in location and magnitude of peaks in spectrum– Peaks are known as formants and represent resonances of vocal cavity
• The spectrum captures the format location and, to some extent, pitch without explicit formant or pitch tracking
Page 21
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 21
© 2001 D.A.Reynolds and L.P.Heck
General TheoryFeatures for Speaker Recognition
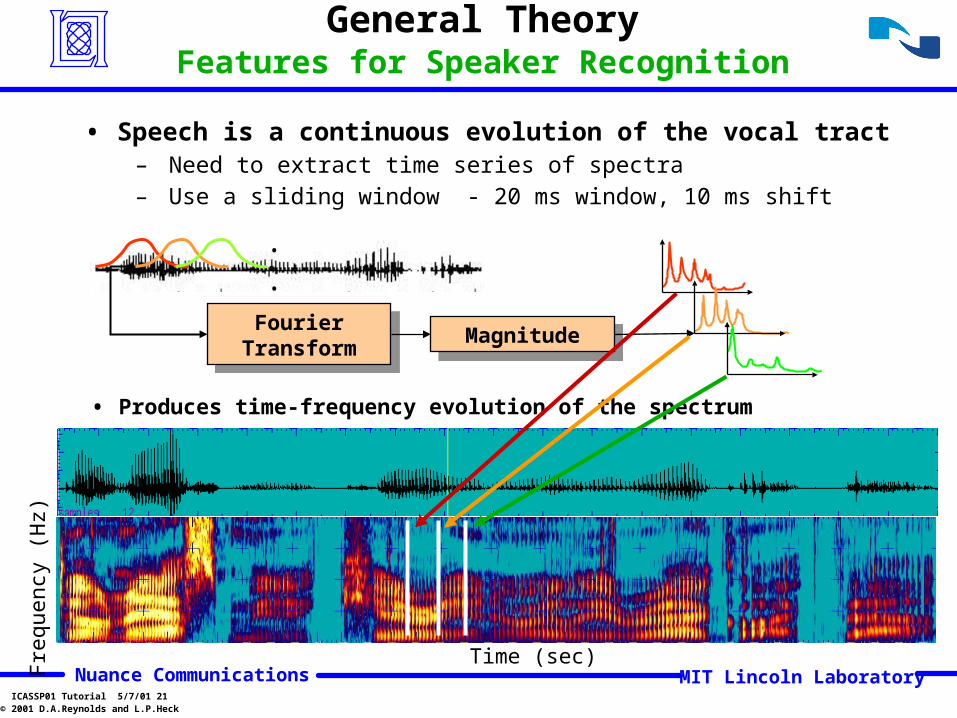
• Speech is a continuous evolution of the vocal tract – Need to extract time series of spectra– Use a sliding window - 20 ms window, 10 ms shift
...
Fourier Transform
Fourier Transform MagnitudeMagnitude
• Produces time-frequency evolution of the spectrum
Fre
quen
cy (
Hz)
Time (sec)
Page 22
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 22
© 2001 D.A.Reynolds and L.P.Heck
General TheoryFeatures for Speaker Recognition
• The number of discrete Fourier transform samples representing the spectrum is reduced by averaging frequency bins together
– Typically done by a simulated filterbank
• A perceptually based filterbank is used such as a Mel or Bark scale filterbank
– Linearly spaced filters at low frequencies– Logarithmically spaced filters at high frequencies
Frequency
Ma
gn
itu
de
Page 23
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 23
© 2001 D.A.Reynolds and L.P.Heck
General TheoryFeatures for Speaker Recognition
• Primary feature used in speaker recognition systems are cepstral feature vectors
• Log() function turns linear convolutional effects into additive biases
– Easy to remove using blind-deconvolution techniques
• Cosine transform helps decorrelate elements in feature vector
– Less burden on model and empirically better performance
...
Fourier TransformFourier Transform MagnitudeMagnitude
Log()Log() Cosine transformCosine transform 3.4 3.6 2.1 0.0-0.9 0.3 .1
3.4 3.6 2.1 0.0-0.9 0.3 .1
3.4 3.6 2.1 0.0-0.9 0.3 .1
One feature vector every 10 ms
Page 24
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 24
© 2001 D.A.Reynolds and L.P.Heck
General TheoryFeatures for Speaker Recognition
Fourier Transform
Fourier Transform MagnitudeMagnitude Log()Log() Cosine
transform
Cosine transform
Page 25
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 25
© 2001 D.A.Reynolds and L.P.Heck
General TheoryFeatures for Speaker Recognition
• Additional processing steps for speaker recognition features
• To help capture some temporal information about the spectra, delta cepstra are often computed and appended to the cepstra feature vector
– 1st order linear fit used over a 5 frame (50 ms) span
K
Kk
K
Kki
ii
k
knkcnc
t
tc
2
)()(
)(
• For telephone speech processing, only voice pass-band frequency region is used
– Use only output of filters in range 300-3300 Hz
300 3300
Page 26
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 26
© 2001 D.A.Reynolds and L.P.Heck
General TheoryFeatures for Speaker Recognition
• To help remove channel convolutional effects, cepstral mean subtraction (CMS) or RASTA filtering is applied to the cepstral vectors
|)(|*|),(| fHnfS
• Some speaker information is lost, but generally CMS is highly beneficial to performance
• RASTA filtering is like a time-varying version of CMS (Hermansky, 92)
h(t)h(t) FT()FT() |.||.| Log()Log() Cos Trans()Cos Trans()
)(),( thnts |)(|log|),(|log fHnfS
hnsnc
)()(hsncN
mn
)(
1
snsmnc
)()(
Page 27
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 27
© 2001 D.A.Reynolds and L.P.Heck
General TheoryPhases of Speaker Verification System
Two distinct phases to any speaker verification system
Feature extraction
Feature extraction
Model training
Model training
Enrollment speech for each speaker
Bob
Sally
Model (voiceprint) for each speaker
Sally
Bob
Enrollment Enrollment PhasePhase
Accepted!Feature extraction
Feature extraction
Verificationdecision
Verificationdecision
Claimed identity: Sally
Verification Verification PhasePhase
Page 28
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 28
© 2001 D.A.Reynolds and L.P.Heck
General TheorySpeaker Models
• Speaker models are used to represent the speaker-specific information conveyed in the feature vectors
• Desirable attributes of a speaker model– Theoretical underpinning– Generalizable to new data– Parsimonious representation (size and computation)
• Modern speaker verification systems employ some form of Hidden Markov Models (HMM)
– Statistical model for speech sound representation– Solid theoretical basis– Existing parameter estimation techniques
Page 29
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 29
© 2001 D.A.Reynolds and L.P.Heck
3.4 3.6 2.1 0.0-0.9 0.3 .1
1x
General TheorySpeaker Models
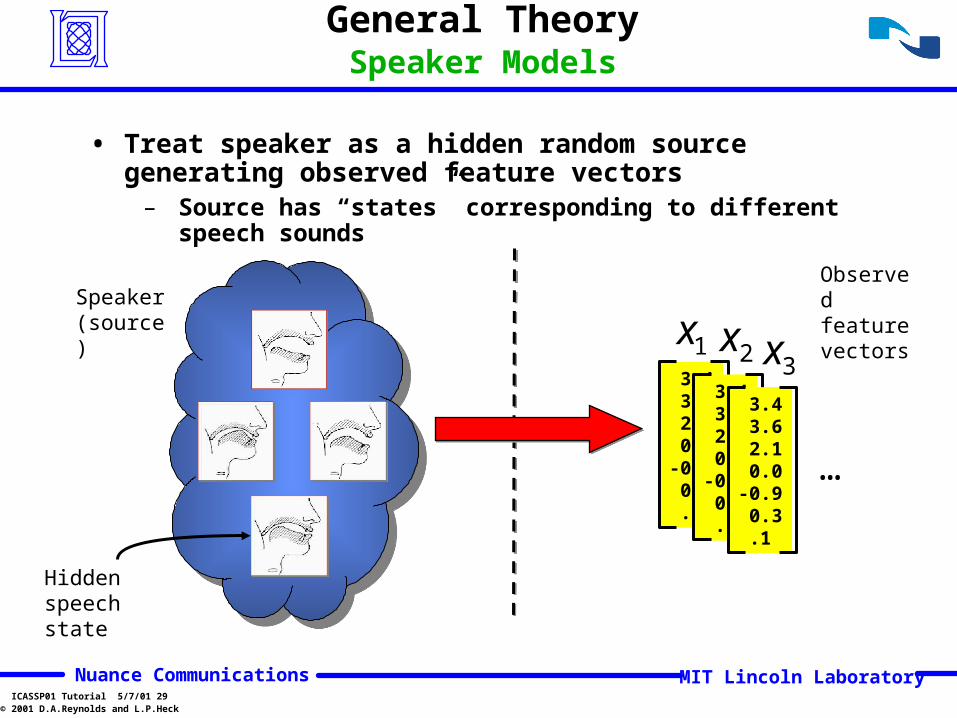
• Treat speaker as a hidden random source generating observed feature vectors
– Source has “states” corresponding to different speech sounds
Speaker (source)
Hidden speech state
3.4 3.6 2.1 0.0-0.9 0.3 .1
2x
3.4 3.6 2.1 0.0-0.9 0.3 .1
3x
…
Observed feature vectors
Page 30
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 30
© 2001 D.A.Reynolds and L.P.Heck
General TheorySpeaker Models
• Feature vectors generated from each state follow a Gaussian mixture distribution
)(|( xbpxpi
iis
),, iiis p
Transition probability
Feature distribution for state i
2,1 ss• Transition between states based on modality of speech
– Text-dependent case will have ordered states
– Text-independent case will allow all transitions
• Model parameters– Transition probabilities– State mixture parameters
• Parameters are estimated from training speech using Expectation Maximization (EM) algorithm
Page 31
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 31
© 2001 D.A.Reynolds and L.P.Heck
General TheorySpeaker Models
• HMMs encode the temporal evolution of the features (spectrum)
• HMMs represent underlying statistical variations in the speech state (e.g., phoneme) and temporal changes of speech between the states.
• This provides a statistical model of how a speaker produces sounds
• Designer needs to set– Topology (# states and
allowed transitions)– Number of mixtures
Page 32
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 32
© 2001 D.A.Reynolds and L.P.Heck
General TheorySpeaker Models
Form of HMM depends on the application
“Open sesame”
Fixed Phrase Word/phrase models
/t/ /e/ /n/
Prompted phrases/passwords Phoneme models
General speech
Text-independent single state HMM (GMM)
Page 33
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 33
© 2001 D.A.Reynolds and L.P.Heck
General TheorySpeaker Models
• The dominant model factor in speaker recognition performance is the number of mixtures used (Matsui and Furui, ICASSP92)
• Selection of mixture order is dependent on a number of factors
– Topology of HMM– Amount of training data– Desired model size
• No good theoretical technique to pick mixtures order– Usually set empirically
• Parameter tying techniques can help increase the effective number of Gaussians with limited total parameter increase
Page 34
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 34
© 2001 D.A.Reynolds and L.P.Heck
General TheorySpeaker Models
• The likelihood of a HMM given a sequence of feature vectors is computed as
,...2,1
)|)(()|)(),...,2(),1(( )()()1(SS t
tststs txpHMMTxxxp
t
tststsS
txpHMMTxxxpi
)|)((max)|)(),...,2(),1(( )()()1(
Full likelihood score
Viterbi (best-path) score
time
sta
tes
x(1) x(3)x(2) x(4)
Page 35
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 35
© 2001 D.A.Reynolds and L.P.Heck
General TheoryPhases of Speaker Verification System
Two distinct phases to any speaker verification system
Feature extraction
Feature extraction
Model training
Model training
Enrollment speech for each speaker
Bob
Sally
Model (voiceprint) for each speaker
Sally
Bob
Enrollment Enrollment PhasePhase
Accepted!Feature extraction
Feature extraction
Verificationdecision
Verificationdecision
Claimed identity: Sally
Verification Verification PhasePhase
Verificationdecision
Verificationdecision
Page 36
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 36
© 2001 D.A.Reynolds and L.P.Heck
General TheoryVerification Decision
• The verification task is fundamentally a two-class hypothesis test
– H0: the speech S is from an impostor– H1: the speech S is from the claimed speaker
• This is known as the likelihood ratio test
)1Pr(
)0Pr(
)0|(
)1|(
rule) Bayes (using )(
)0Pr()0|(
)(
)1Pr()1|(
)|0Pr()|1Pr(
H
H
HSp
HSp
Sp
HHSp
Sp
HHSp
SHSH
)0|(
)1|(
HSp
HSpLR
0Accept
1Accept
HLR
HLR
• We select the most likely hypothesis (Bayes test for minimum error)
Page 37
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 37
© 2001 D.A.Reynolds and L.P.Heck
General TheoryVerification Decision
• Usually the log-likelihood ratio is used
Front-end processing
Front-end processing
Speaker modelSpeaker model
Impostor model
Impostor model
-
+
Reject
Accept
• The H1 likelihood is computed using the claimed speaker model
• Requires an alternative or impostor model for H0 likelihood
)0|(log)1|(log HSpHSpLLR
Page 38
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 38
© 2001 D.A.Reynolds and L.P.Heck
General TheoryBackground Model
• There are two main approaches for creating an alternative model for the likelihood ratio test
Speaker model
Speaker model
Bkg 1model
Bkg 1modelBkg 2
model
Bkg 2modelBkg 3
model
Bkg 3model
Cohorts/Likelihood Sets/Background Sets (Higgins, DSPJ91)
– Use a collection of other speaker models
– The likelihood of the alternative is some function, such as average, of the individual impostor model likelihoods
),...,1 ),(|(()0|( BbbBkgSpfHSp
Speaker model
Speaker model
Universalmodel
Universalmodel
General/World/Universal Background Model (Carey, ICASSP91)
– Use a single speaker-independent model– Trained on speech from a large number
of speakers to represent general speech patterns
)|()0|( UBMSpHSp
Page 39
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 39
© 2001 D.A.Reynolds and L.P.Heck
General TheoryBackground Model
• The background model is crucial to good performance– Acts as a normalization to help minimize non-speaker
related variability in decision score
• Just using speaker model’s likelihood does not perform well
– Too unstable for setting decision thresholds– Influenced by too many non-speaker dependent factors
• The background model should be trained using speech representing the expected impostor speech
– Same type speech as speaker enrollment (modality, language, channel)
– Representation of impostor genders and microphone types to be encountered
Page 40
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 40
© 2001 D.A.Reynolds and L.P.Heck
General TheoryBackground Model
• Selected highlights of research on background models
• Near/Far cohort selection (Reynolds, SpeechComm95)– Select cohort speakers to cover the speaker space around
speaker model
• Phonetic based cohort selection (Rosenberg, ICASSP96)– Select speech and speakers to match the same speech modality
as used for speaker enrollment
• Microphone dependent background models (Heck, ICASSP97)
– Train background model using speech from same type microphone as used for speaker enrollment
• Adapting speaker model from background model (Reynolds, Eurospeech97, DSPJ00)
– Use Maximum A Posteriori (MAP) estimation to derive speaker model from a background model
Page 41
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 41
© 2001 D.A.Reynolds and L.P.Heck
ACCEPT
General TheoryComponents of Speaker Verification System
Feature extraction
Feature extraction
SpeakerModel
SpeakerModel
Bob’s model
“My Name is Bob”
ACCEPT
Bob
ImpostorModel
ImpostorModel
Identity Claim
DecisionDecision
REJECTInput Speech
Impostor model(s)
Page 42
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 42
© 2001 D.A.Reynolds and L.P.Heck
Part I : Background and TheoryOutline
• Overview of area– Applications– Terminology
• General Theory– Features for speaker recognition– Speaker models– Verification decision
• Channel compensation
• Adaptation
• Combination of speech and speaker recognizers
Page 43
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 43
© 2001 D.A.Reynolds and L.P.Heck
Channel Compensation
• Variability refers to changes in channel effects between enrollment and successive verification attempts
• Channel effects encompasses several factors– The microphones
Carbon-button, electret, hands-free, etc
– The acoustic environment Office, car, airport, etc.
– The transmission channel Landline, cellular, VoIP, etc.
• Anything which affects the spectrum can cause problems– Speaker and channel effects are bound together in spectrum
and hence features used in speaker verifiers
• Unlike speech recognition, speaker verifiers can not “average” out these effects using large amounts of speech
– Limited enrollment speech
The largest challenge to practical use of speaker verification systems is channel variability
The largest challenge to practical use of speaker verification systems is channel variability
Page 44
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 45
© 2001 D.A.Reynolds and L.P.Heck
Channel CompensationExamples
Page 45
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 47
© 2001 D.A.Reynolds and L.P.Heck
Channel CompensationExamples
Page 46
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 48
© 2001 D.A.Reynolds and L.P.Heck
Channel Compensation
• Three areas where compensation has been applied
Feature-based approachesCMS and RASTANonlinear mappings
Model-based approachesHandset-dependent background modelsSynthetic Model Synthesis (SMS)
Score-based approachesHnorm, Tnorm
'96 '99
MatchedHandsets
MismatchedHandsets
ErrorRates
Factor of 20worse
Factor of 2.5worse
Using compensation techniques has driven down error rates in NIST evaluations
Page 47
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 49
© 2001 D.A.Reynolds and L.P.Heck
Channel CompensationFeature-based Approaches
• CMS and RASTA only address linear channel effects on features
• Several approaches have looked at non-linear effects
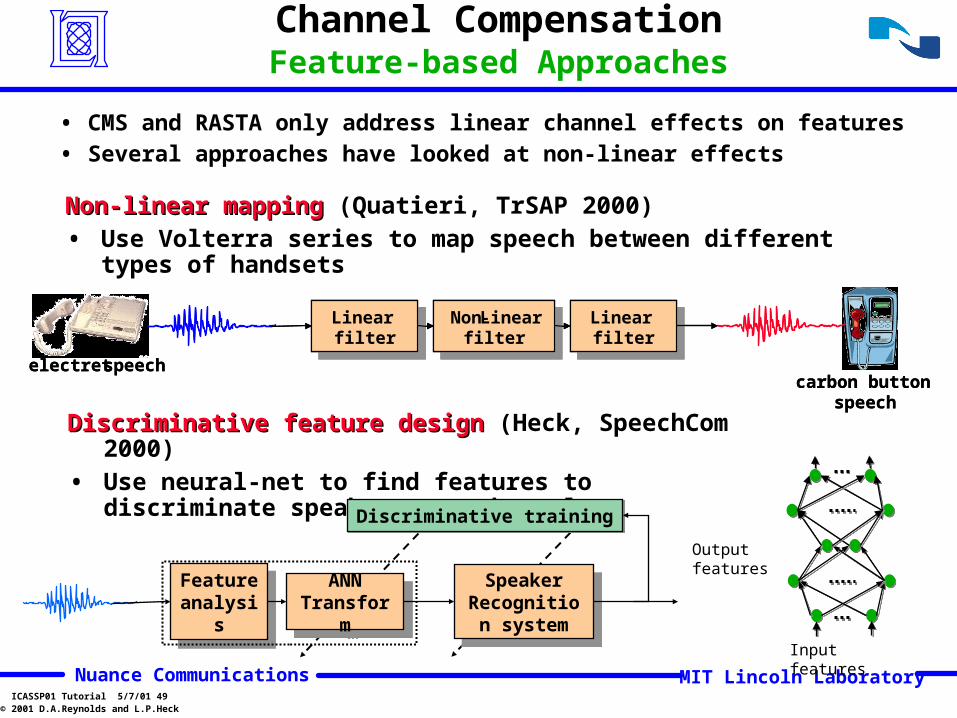
Non-linear mappingNon-linear mapping (Quatieri, TrSAP 2000)
• Use Volterra series to map speech between different types of handsets
Discriminative feature designDiscriminative feature design (Heck, SpeechCom 2000)
• Use neural-net to find features to discriminate speakers not channels
Linear filter
Linear filter
Non-Linear filter
Non-Linear filter
Linear filter
Linear filter
carbon button speech
carbon button speech
electret speechelectret speech
Linear filter
Linear filter
Non-Linear filter
Non-Linear filter
Linear filter
Linear filter
Linear filter
Linear filter
Non-Linear filter
Non-Linear filter
Linear filter
Linear filter
Feature analysis
Feature analysis
ANN Transform
ANN Transform
Speaker Recognition
system
Speaker Recognition
system
Discriminative trainingDiscriminative training
Input features
Output features
Page 48
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 50
© 2001 D.A.Reynolds and L.P.Heck
Channel CompensationModel-based Approaches
• It is generally difficult to get enrollment speech from all microphone types to be used
• The SMS approach addresses this by synthetically generating speaker models as if they came from different microphones (Teunen, ICSLP 2000)
– A mapping of model parameters between different microphone types is applied
cellular carbon buttonelectret
synthesis synthesis
Page 49
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 51
© 2001 D.A.Reynolds and L.P.Heck
Channel CompensationScore-based Approaches
• Speaker model LR scores have different biases and scales for utterances from different handset types
• Hnorm attempts to remove these bias and scale differences from the LR scores (Reynolds, NIST eval96)
elec
carb
spk1
LR scores– Estimate mean and standard-deviation of impostor, same-sex utterances from different microphone-types
elec
carb
spk2
hnorm scores
carbspk
carbspk
carbspkcarb
spk
uuH
)(
)(
– During verification normalize LR score based on microphone label of utterance
Page 50
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 52
© 2001 D.A.Reynolds and L.P.Heck
Channel CompensationScore-based Approaches
• Tnorm/HTnorm - Estimates bias and scale parameters for score normalization using “cohort” set of speaker models (Auckenthaler, DSP Journal 2000)
– Test time score normalization
– Normalizes target score relative to a non-target model ensemble
– Similar to standard cohort normalization except for standard deviation scaling
coh
cohspkspk
uuT
)(
)(Speaker model
Speaker model
Cohort model
Cohort modelCohort
model
Cohort modelCohort
model
Cohort model
), cohcoh
Tnorm score
Tnorm score
• Used cohorts of same gender and channel as speaker
• Can be used in conjunction with Hnorm
Page 51
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 53
© 2001 D.A.Reynolds and L.P.Heck
Part I : Background and TheoryOutline
• Overview of area– Applications– Terminology
• General Theory– Features for speaker recognition– Speaker models– Verification decision
• Channel compensation
• Adaptation
• Combination of speech and speaker recognizers
Page 52
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 54
© 2001 D.A.Reynolds and L.P.Heck
Adaptation
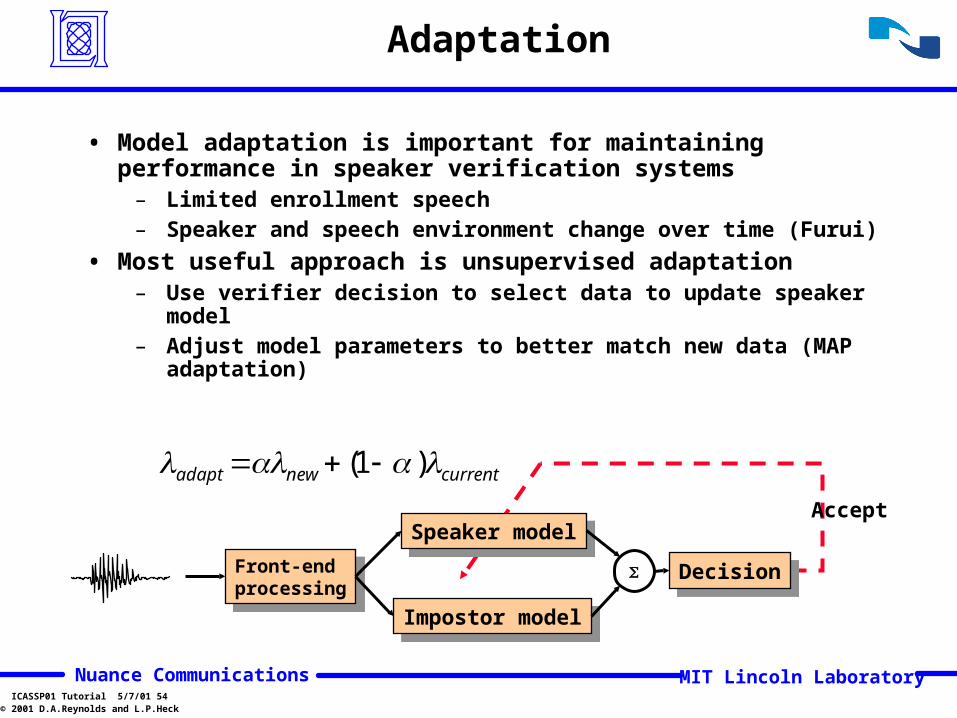
• Model adaptation is important for maintaining performance in speaker verification systems
– Limited enrollment speech– Speaker and speech environment change over time (Furui)
• Most useful approach is unsupervised adaptation– Use verifier decision to select data to update speaker model– Adjust model parameters to better match new data (MAP
adaptation)
Front-end processing
Front-end processing
Speaker modelSpeaker model
Impostor modelImpostor model
DecisionDecision
Accept
currentnewadapt )1(
Page 53
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 55
© 2001 D.A.Reynolds and L.P.Heck
Adaptation
• Adaptation parameter can be set in several ways– As a fixed value : Continuous adaptation– As a function of likelihood score : Adjust adaptation based on certainty of decision– As a function of verification sessions : Adapt aggressively early and taper off later
• Experiments have shown that adapting with N utterances produces performance comparable to having extra N utterances during initial training
• Potential problems with adaptation
– Impostor contamination– Novel channels may be
rejected and so never learnedAdaptation session
EE
R
Largest gain at start
Page 54
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 56
© 2001 D.A.Reynolds and L.P.Heck
Part I : Background and TheoryOutline
• Overview of area– Applications– Terminology
• General Theory– Features for speaker recognition– Speaker models– Verification decision
• Channel compensation
• Adaptation
• Combination of speech and speaker recognizers
Page 55
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 57
© 2001 D.A.Reynolds and L.P.Heck
Combination of Speech and Speaker Recognizers
• There are four basic ways speech recognition is used with speaker verifiers
– For front-end speech segmentation
– For prompted text verification
– For knowledge verification
– To extract idiolectal information
Page 56
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 58
© 2001 D.A.Reynolds and L.P.Heck
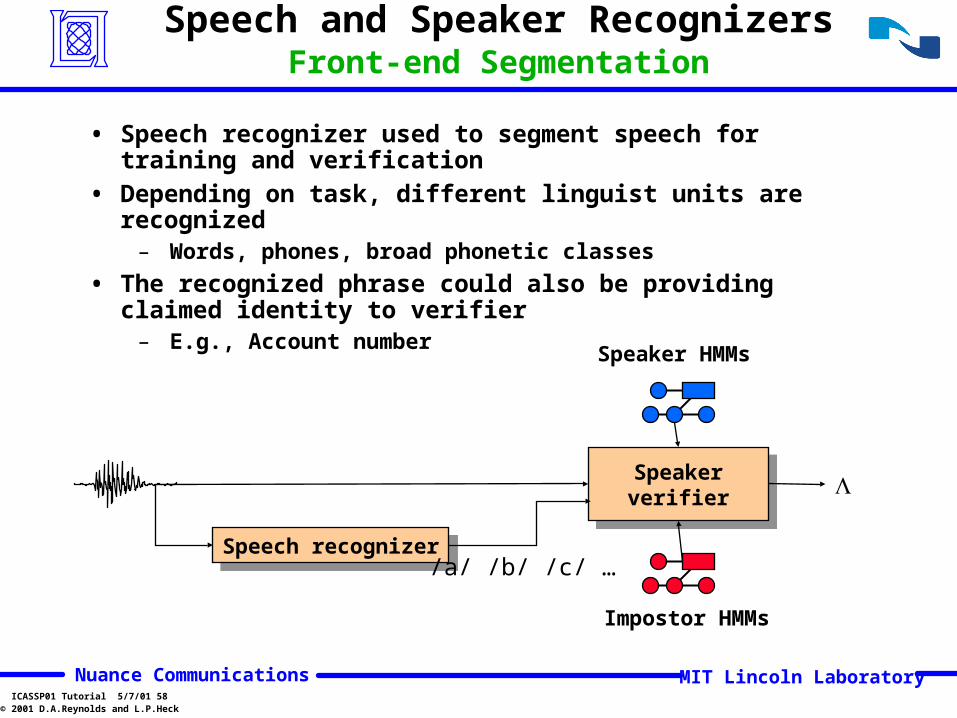
Speech and Speaker RecognizersFront-end Segmentation
• Speech recognizer used to segment speech for training and verification
• Depending on task, different linguist units are recognized– Words, phones, broad phonetic classes
• The recognized phrase could also be providing claimed identity to verifier
– E.g., Account number
Speech recognizerSpeech recognizer
Speaker verifierSpeaker verifier
/a/ /b/ /c/ …
Impostor HMMs
Speaker HMMs
Page 57
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 59
© 2001 D.A.Reynolds and L.P.Heck
Speech and Speaker RecognizersPrompted Text Verification
• Prompted text systems used to help thwart play-back attack
• Need to verify voice and that prompted text was said
• Possible to have integrated speaker and text verification using speaker-dependent phrase decoding
Speech recognizerSpeech recognizer
/a/ /b/ /c/ …
Speaker verifierSpeaker verifier
Speaker HMMs
Impostor HMMs
Prompted phrase (e.g., 82-32-71)
Text score
Speaker score
CombineCombine
Page 58
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 60
© 2001 D.A.Reynolds and L.P.Heck
Speech and Speaker RecognizersKnowledge Verification
• Compare response to personal question to known answer– E.g., “What is your date of birth?”
• Can be used for initial enrollment speech collection– Use KV for first three accesses while collecting speech
• Can also be used as fall-back verification in case speaker verifier is unsure after some number of attempts
• Also known as Verbal Information Verification (Q. Li, ICSLP98)
Speech recognizerSpeech recognizer
Answer
KV score
Personal Info DB
Personal Info DBQuestion
Response
Speaker verifierSpeaker verifier UnsureDecisionDecision
Page 59
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 61
© 2001 D.A.Reynolds and L.P.Heck
Speech and Speaker Recognizers Idiolectal Information Extraction
• Recent work by Doddington has found significant speaker information using ngrams of recognized words (Eurospeech 2001 and NIST website)
• During training, create counts of ngrams from speaker trainng data and from a collection of background speakers
• During verification compute LR score between speaker and background ngram models
• Good example of using higher-levels of speaker information
Speech recognizerSpeech recognizer
Uh-I 0.022Uh-yeah 0.001Un-well 0.025
Bigram (n=2)
Speaker ngrams
Background ngrams
Uh-I 0.001Uh-yeah 0.049Uh-well 0.071
Bigram (n=2)
Uh I think yeah …
LR ComputationLR Computation
Page 60
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 62
© 2001 D.A.Reynolds and L.P.Heck
Speaker Verification: From Research to Reality
Part II : Evaluation and Performance
Page 61
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 63
© 2001 D.A.Reynolds and L.P.Heck
Part II : Evaluation and PerformanceOutline
• Evaluation metrics
• Evaluation design
• Publicly available corpora
• Performance survey
Page 62
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 64
© 2001 D.A.Reynolds and L.P.Heck
Evaluation metrics
• In speaker verification, there are two types of errors that can occur
False reject: incorrectly reject a speakerAlso known as a miss or a Type-I error
False accept: incorrectly accept an impostorAlso known as a Type-II error
• The performance of a verification system is a measure of the trade-off between these two errors
– The tradeoff is usually controlled by adjustment of the decision threshold
• In an evaluation, Ntrue true trials (speech from claimed speaker) and Nfalse false trials (speech from an impostor) are conducted and the probability of false reject and false accept are estimated for different thresholds
falsetrue N
scores trialfalse # )|accept falsePr(
N
scores trial true# )|reject falsePr(
Page 63
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 65
© 2001 D.A.Reynolds and L.P.Heck
Evaluation metrics
• Evaluation errors are estimates of true errors using a finite number of trials
falsetrue N
scores trialfalse # )|accept falsePr(
N
scores trial true# )|missPr(
LJ
impostor)|p( )|faPr(
speaker)|p( )|missPr(
Page 64
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 66
© 2001 D.A.Reynolds and L.P.Heck
Evaluation metricsROC and DET Curves
Plot of Pr(miss) vs. Pr(fa) shows system performanceDET plots Pr(miss) and Pr(fa) on normal deviate scale
Receiver Operator Characteristic
(ROC)
Decreasing threshold
Decreasing threshold
Better performance
Detection Error Tradeoff
(DET)
PROBABILITY OF FALSE ACCEPT (in %) PROBABILITY OF FALSE ACCEPT (in %)
PR
OB
AB
ILIT
Y O
F F
AL
SE
RE
JE
CT
(in
%)
PR
OB
AB
ILIT
Y O
F F
AL
SE
RE
JE
CT
(in
%)
Page 65
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 67
© 2001 D.A.Reynolds and L.P.Heck
Evaluation metricsDET Curve
PROBABILITY OF FALSE ACCEPT (in %)
PR
OB
AB
ILIT
Y O
F F
AL
SE
RE
JEC
T (
in %
)
Equal Error Rate (EER) = 1 %
Wire Transfer:
False acceptance is very costly
Users may tolerate rejections for security
Toll Fraud:
False rejections alienate customers
Any fraud rejection is beneficial
Equal Error Rate (EER) is often quoted as a summary performance measure
High Convenience
High Security
Balance
Application operating point depends on relative costs of the two errors
Page 66
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 68
© 2001 D.A.Reynolds and L.P.Heck
Evaluation metricsDecision Cost Function
• In addition to EER, a decision cost function (DCF) is also used to measure performance
)|p)Pr(faC(fa)Pr(im)|missPr(spkr)C(miss)Pr( )DCF(
C(miss) = cost of a miss
Pr(spkr) = prior probability of true speaker attempt
Pr(imp) = 1-Pr(spkr) = prior probability of impostor attempt
C(fa) = cost of a false alarm
• For application specific costs and priors, compare systems based on minimum value of DCF
Page 67
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 69
© 2001 D.A.Reynolds and L.P.Heck
Evaluation metricsThresholds
• Deployed verification system must make decisions – that is set and use a priori thresholds
– DET curves and EER are independent of setting thresholds
• The DCF can be used as an objective target for setting and measuring goodness of a priori thresholds
– Set threshold during development to minimize DCF– Measure how close to minimum DCF the threshold achieves
in evaluation
• For measuring system performance, speaker-independent thresholds should be used
– Pr(miss) is computed by pooling all true trial scores from all speakers in evaluation
– Pr(fa) is computed by pooling all false trial scores from all impostors in evaluation
• Using speaker-dependent threshold DETs produces very optimistic performance which can not be achieved in practice
Page 68
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 70
© 2001 D.A.Reynolds and L.P.Heck
Part II : Evaluation and PerformanceOutline
• Evaluation metrics
• Evaluation design
• Publicly available corpora
• Performance survey
Page 69
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 71
© 2001 D.A.Reynolds and L.P.Heck
Evaluation DesignData Selection Factors
• Performance numbers are only meaningful when evaluation conditions are known
Speech qualitySpeech quality – Channel and microphone characteristics– Ambient noise level and type– Variability between enrollment and verification
speech
Speech modalitySpeech modality – Fixed/prompted/user-selected phrases– Free text
Speech durationSpeech duration – Duration and number of sessions of enrollment and verification speech
Speaker populationSpeaker population – Size and composition– Experience
The evaluation data and design should match the
target application domain of interest
Page 70
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 72
© 2001 D.A.Reynolds and L.P.Heck
Evaluation DesignSizing of Evaluation
• For performance goals of Pr(miss)=1% and Pr(fa)=0.1% this implies
– 3,000 true trials 0.7% < Pr(miss) < 1.3% with 90% confidence
– 30,000 impostor trials 0.07% < Pr(fa) < 0.13% with 90% confidence
• Independence of trials is still an open issue
To be 90 percent confident that the true error rate is within +/- 30% of the observed error rate, there must be at least 30 errorsTo be 90 percent confident that the true error rate is within +/- 30% of the observed error rate, there must be at least 30 errors
• The overarching concern is to design an evaluation which produces statistically significant results
– Number and composition of speakers– Number of true and false trials
• For the number of trials, we can use the “rule of 30” based on binomial distribution and independence assumption (Doddington)
Page 71
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 73
© 2001 D.A.Reynolds and L.P.Heck
Evaluation DesignTrials
• True trials are the limiting factor in evaluation design
• False trials are easily generated by scoring all speaker models against all utterances
– May not be possible for speaker specific fixed phrases
Speaker 1 Speaker 2 Speaker 3
Utterance 1 True trial False trial False trial
Utterance 2 False trial True trial False trial
Utterance 3 False trial False trial True trial
Speaker models
Tes
t u
tts
• Important that each trial only uses utterance and model under test
– Otherwise system is using “known” impostors (closed set)
• Can design trials to examine performance on sub-conditions
– E.g., train on electret and test on carbon-button
Page 72
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 74
© 2001 D.A.Reynolds and L.P.Heck
Part II : Evaluation and PerformanceOutline
• Evaluation metrics
• Evaluation design
• Publicly available corpora
• Performance survey
Page 73
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 75
© 2001 D.A.Reynolds and L.P.Heck
Publicly Available CorporaData Providers
• Linguistic Data Consortiumhttp://www.ldc.upenn.edu/
• Linguistic Data Consortiumhttp://www.ldc.upenn.edu/
• European Language Resources Associationhttp://www.icp.inpg.fr/ELRA/
home.html
• European Language Resources Associationhttp://www.icp.inpg.fr/ELRA/
home.html
Page 74
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 76
© 2001 D.A.Reynolds and L.P.Heck
Publicly Available CorporaPartial Listing
• TIMIT, et. al (LDC) - Not particularly good for evaluations
• SIVA (ELRA) – Italian telephone prompted speech
• PolyVar (ELRA) – French telephone prompted and spontaneous speech
• POLYCOST (ELRA) – European languages prompted and spontaneous speech
• KING (LDC) – Dual wideband and telephone monologs
• YOHO (LDC) – Office environment combination lock phrases
• Switchboard I-II & NIST Eval Subsets (LDC) – Telephone conversational speech
• Tactical Speaker Identification, TSID (LDC) – Military radio communications
• Speaker Recognition Corpus (OGI) – Long term telephone prompted and spontaneous speech
Summary of corpora characteristics can be found athttp://www.apl.jhu.edu/Classes/Notes/Campbell/SpkrRec/Summary of corpora characteristics can be found athttp://www.apl.jhu.edu/Classes/Notes/Campbell/SpkrRec/
Page 75
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 77
© 2001 D.A.Reynolds and L.P.Heck
Part II : Evaluation and PerformanceOutline
• Evaluation metrics
• Evaluation design
• Publicly available corpora
• Performance survey
Page 76
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 78
© 2001 D.A.Reynolds and L.P.Heck
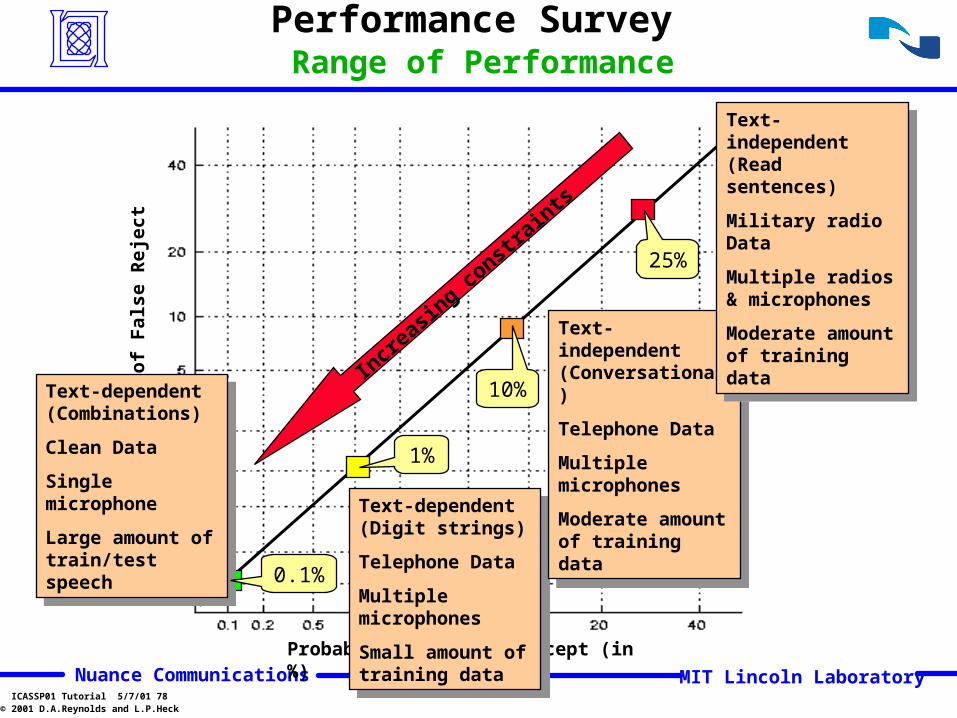
Performance Survey Range of Performance
Probability of False Accept (in %)
Pro
bab
ilit
y o
f F
alse
Rej
ect
(in
%)
Incre
asing constra
ints
Text-dependent (Combinations)
Clean Data
Single microphone
Large amount of train/test speech
Text-dependent (Combinations)
Clean Data
Single microphone
Large amount of train/test speech
0.1%
Text-dependent (Digit strings)
Telephone Data
Multiple microphones
Small amount of training data
Text-dependent (Digit strings)
Telephone Data
Multiple microphones
Small amount of training data
1%
Text-independent (Conversational)
Telephone Data
Multiple microphones
Moderate amount of training data
Text-independent (Conversational)
Telephone Data
Multiple microphones
Moderate amount of training data
10%
Text-independent (Read sentences)
Military radio Data
Multiple radios & microphones
Moderate amount of training data
Text-independent (Read sentences)
Military radio Data
Multiple radios & microphones
Moderate amount of training data
25%
Page 77
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 79
© 2001 D.A.Reynolds and L.P.Heck
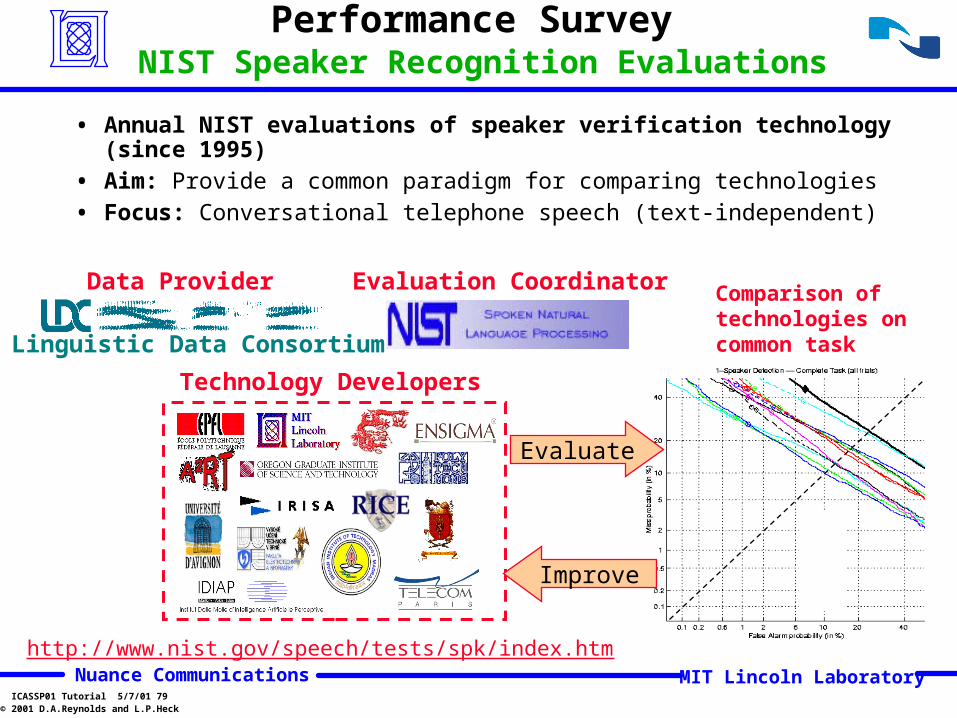
Performance Survey NIST Speaker Recognition Evaluations
• Annual NIST evaluations of speaker verification technology (since 1995)
• Aim: Provide a common paradigm for comparing technologies
• Focus: Conversational telephone speech (text-independent)
Evaluation Coordinator
Linguistic Data Consortium
Data Provider
Technology Developers
Comparison of technologies on common task
Evaluate
Improve
http://www.nist.gov/speech/tests/spk/index.htm
Page 78
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 80
© 2001 D.A.Reynolds and L.P.Heck
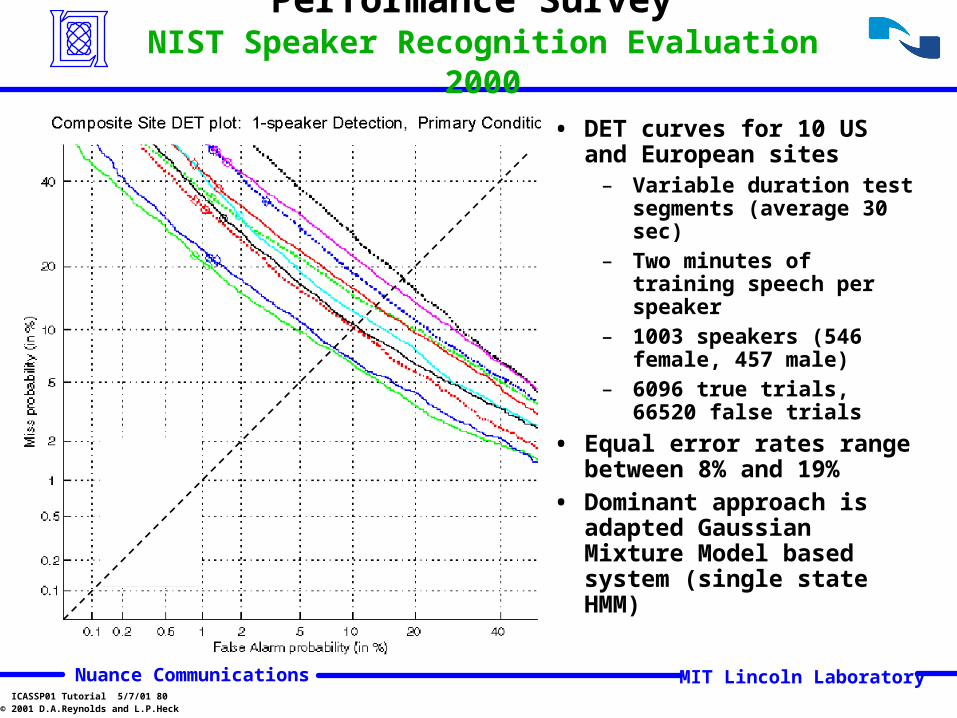
Performance Survey NIST Speaker Recognition Evaluation 2000
• DET curves for 10 US and European sites
– Variable duration test segments (average 30 sec)
– Two minutes of training speech per speaker
– 1003 speakers (546 female, 457 male)
– 6096 true trials, 66520 false trials
• Equal error rates range between 8% and 19%
• Dominant approach is adapted Gaussian Mixture Model based system (single state HMM)
Page 79
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 81
© 2001 D.A.Reynolds and L.P.Heck
Performance Survey Effect of Training and Testing Duration
• Results from 1998 NIST evaluation
Increasing training data Increasing testing data
Page 80
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 82
© 2001 D.A.Reynolds and L.P.Heck
Performance Survey Effect of Microphone Mismatch
• In the NIST evaluation, performance was measured when speakers used the same and different telephone handset microphone types (carbon-button vs electret)
• With microphone mismatch, equal error rate increases by over a factor of 2
Using different handset types
Using same handset types 2.5 X
Page 81
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 83
© 2001 D.A.Reynolds and L.P.Heck
Performance Survey Effect of Speech Coding
• Recognition from reconstructed speech
• Error rate increases as bit rate decreases
– GSM speech performs as well as uncoded speech
0
5
10
15
EE
R (
%)
Tel.
GSM
G.7
29
G.7
23
MELP
Detection forVarious Coders
Coder Rates:T1 - 64.0 kb/sGSM - 12.2 kb/sG.729 - 8.0 kb/sG.723 - 5.3 kb/sMELP - 2.4 kb/s
• Recognition from speech coder parameters
• Negligible increase in EER with increased computational efficiency
0
5
10
15
EE
R (
%)
Detection fromG.729 Parameters
Page 82
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 84
© 2001 D.A.Reynolds and L.P.Heck
Performance Survey Human vs. Machine
• Motivation for comparing human to machine
– Evaluating speech coders and potential forensic applications
• Schmidt-Nielsen and Crystal used NIST evaluation (DSP Journal, January 2000)
– Same amount of training data
– Matched Handset-type tests
– Mismatched Handset-type tests
– Used 3-sec conversational utterances from telephone speech
• Humans have more robustness to channel variabilities
– Use different levels of information
Humans44%
betterHumans
15%worse
ErrorRates
Computer
Human
Page 83
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 85
© 2001 D.A.Reynolds and L.P.Heck
Performance Survey Human Forensic Performance
• In 1986, the Federal Bureau of Investigation published a survey of two thousand voice identification comparisons made by FBI examiners
– Forensic comparisons completed over a period of fifteen years, under actual law enforcement conditions
– The examiners had a minimum of two years experience, and had completed over 100 actual cases
– The examiners used both aural and spectrographic methods– http://www.owlinvestigations.com/forensic_articles/aural_sp
ecetrographic/fulltext.html#research
No decision 65.2% (1304)
Non-match 18.8% (378) FR = 0.53% (2)
Match 15.9% (318) FA = 0.31% (1)
SuspectRecorded threat
From “Spectrographic voice identification: A forensic survey ,” J. Acoust. Soc. Am, 79(6) June 1986, Bruce E. Koenig
Page 84
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 86
© 2001 D.A.Reynolds and L.P.Heck
Performance Survey Comparison to Other Biometrics
• Raw accuracy is generally not a good way to compare different biometric techniques
– The application will dictate other important factors – See “Fundamentals of Biometric Technology” at
http://www.engr.sjsu.edu/biometrics/publications_tech.html for good discussion and comparison of biometrics
Characteristic
Finger-prints
Hand Geometry Retina Iris Face Signature Voice
Ease of use High High Low Medium Medium High High
Error incidence
Dryness, dirt, age
Hand injury, age
Glasses Poor lighting
Lighting, hair, glasses, age
Changing signatures
Microphones,channels, noise, colds
Accuracy High High Very high
Very high High High High
User acceptance Medium Medium Medium Medium Medium Medium High
Long-term stability High Medium High High Medium Medium Medium
From “A Practical Guide to Biometric Security Technology ,” IEEE Computer Society, IT Pro - Security, Jan-Feb 2001, Simon Liu and Mark Silverman
Page 85
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 87
© 2001 D.A.Reynolds and L.P.Heck
Performance Survey Comparison to Other Biometrics
From CESG Biometric Test Programme Report (http://www.cesg.gov.uk/biometrics/)
Page 86
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 88
© 2001 D.A.Reynolds and L.P.Heck
Speaker Verification: From Research to Reality
Part III : Applications and Deployments
Page 87
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 89
© 2001 D.A.Reynolds and L.P.Heck
Part III : Applications and DeploymentsOutline
• Brief overview of commercial speaker verification systems
• Design requirements for commercial verification systems – General considerations– Dialog design
• Steps to deploying speaker verification systems– Initial data collection– Tuning– Limited Deployment and Final Rollout
• Examples of real deployments
Page 88
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 90
© 2001 D.A.Reynolds and L.P.Heck
Part III : Applications and DeploymentsOutline
• Brief overview of commercial speaker verification systems
• Design requirements for commercial verification systems – General considerations– Dialog design
• Steps to deploying speaker verification systems– Initial data collection– Tuning– Limited Deployment and Final Rollout
• Examples of real deployments
Page 89
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 91
© 2001 D.A.Reynolds and L.P.Heck
Commercial Speaker Verification
1985
Access ControlTI Corporate Facility(Texas Instruments)
1980
Large-Scale Deployments (1M+)
Large-Scale Deployments (1M+)
Small Scale Deployments (100s)
Small Scale Deployments (100s)
1990
Law EnforcementHome Incarceration
(ITT Industries)
TelecomSprint’s Voice FONCARD
(Texas Instruments)
19952001
Law EnforcementPrison Call Monitoring
(T-Netix)
CommerceHome Shopping Network
(Nuance)
FinancialCharles Schwab
(Nuance)
TelecomSwisscom(Nuance)
Access ControlMac OS9(Apple)
Page 90
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 92
© 2001 D.A.Reynolds and L.P.Heck
Applications and Deployments Commercial Speaker Verification Systems
NUANCE
VERIFIER
Page 91
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 93
© 2001 D.A.Reynolds and L.P.Heck
Part III : Applications and DeploymentsOutline
• Brief overview of commercial speaker verification systems
• Design requirements for commercial verification systems – General considerations– Dialog design
• Steps to deploying speaker verification systems– Initial data collection– Tuning– Limited Deployment and Final Rollout
• Examples of real deployments
Page 92
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 94
© 2001 D.A.Reynolds and L.P.Heck
Applications and Deployments Design Requirements in Commercial Verifiers
• Fast– Example: 50 simultaneous verifications on single PIII 500MHz processor
• Accurate– < 0.1% FAR @ < 5% FRR with ~1-5% reprompt rate
• Robust (channel/noise variability)
• Compact Storage of Speaker Models – < 100KB/model with support for 1M+ users on standard DBs (e.g., Oracle)
• Scalable (1 Million+ users with standard DBs)
• Easy to deploy
• International language/region support
• Variety of operating modes:– Text-independent, text-prompted, text-dependent
• Fully Integrated with state-of-the-art speech recognizer
Biggest challenge Robustness to channel variabilityBiggest challenge Robustness to channel variability
Requirements:
Page 93
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 95
© 2001 D.A.Reynolds and L.P.Heck
Applications and Deployments Design Requirements: Online Adaptation
Online Unsupervised AdaptationOnline Unsupervised Adaptation• Adaptation is one of the most powerful technologies to address robustness
& ease of deployment
• Additional requirements:– Minimizes cross channel corruption
Adapting on cellular improves performance on office phone
– Minimizes cross-channel effects w/ no growth in storageSaves new information from addition channels in 1 channel
– Minimizes model corruption from impostor attack
• SMS with online adaptation (Heck, ICSLP 2000):– Addresses above requirements
– 5222 speakers, 8 calls @ 12.5% impostor attack rate 61% reduction in EER (unsupervised)
Page 94
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 97
© 2001 D.A.Reynolds and L.P.Heck
Applications and Deployments Dialog Design: General Principles
• Dialog should be designed to be secure and convenient– Security often compromised by users if dialog not convenient
Example: 4-digit PIN Security = 1 out of 10,000 false accepts? NO!
Users compromise security of PINs to make them easier to remember (writing down in wallet, on-line, etc.)
• Dialog should be maximally constrained but flexible– More constraints better accuracy for fixed length training
– Example: balance between constraints on acoustic space while maintaining flexibility digit sequences
Dialog Design Goal Constrained but flexible dialog to maximize security while maintaining convenience
Dialog Design Goal Constrained but flexible dialog to maximize security while maintaining convenience
Page 95
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 98
© 2001 D.A.Reynolds and L.P.Heck
Applications and Deployments Dialog Design: Rules of Thumb
• Enrollment:– must be secure (e.g., rely on knowledge)– should be completed in single session
• Identity claim should be:– unique (but perhaps not unique for multi-user accounts)– easy to recognize over large populations– useful for simultaneous verification
• Verification utterances should be:– easy to remember
YES: SSN, DOB, home telephone number NO: PIN, password
– easy to recognize (both recognizer and verifier)– perceived as short, but contain lots of speech
Names: “Smith S M I T H” Digits: “3 5 6 7, 3 5 6 7”
– known only by user– widely accepted by user population (e.g., not too private)– difficult to record/synthesize
Page 96
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 99
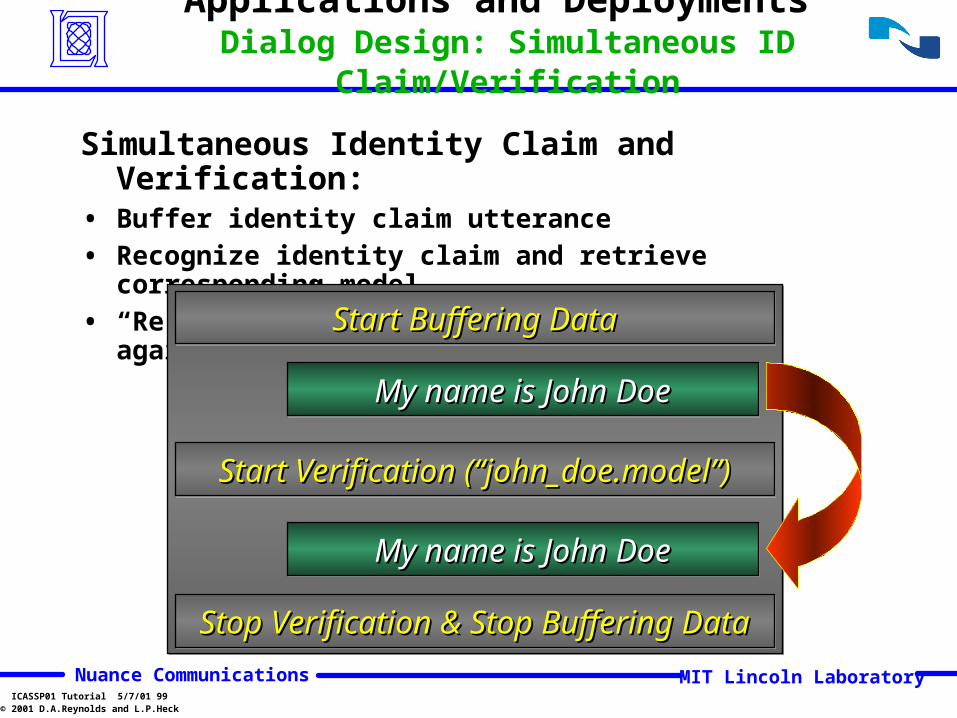
© 2001 D.A.Reynolds and L.P.Heck
Simultaneous Identity Claim and Verification:• Buffer identity claim utterance
• Recognize identity claim and retrieve corresponding model
• “Re-process” data by verifying same utt. against model
Applications and Deployments Dialog Design: Simultaneous ID Claim/Verification
Start Buffering DataStart Buffering DataStart Buffering DataStart Buffering Data
My name is John DoeMy name is John DoeMy name is John DoeMy name is John Doe
Start Verification (“john_doe.model”)Start Verification (“john_doe.model”)Start Verification (“john_doe.model”)Start Verification (“john_doe.model”)
Stop Verification & Stop Buffering DataStop Verification & Stop Buffering DataStop Verification & Stop Buffering DataStop Verification & Stop Buffering Data
My name is John DoeMy name is John DoeMy name is John DoeMy name is John Doe
Page 97
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 100
© 2001 D.A.Reynolds and L.P.Heck
Initial positivescore threshold
Initial negativescore threshold
FRR1
FRR2
FAR1 FAR2
score threshold
Applications and Deployments Dialog Design: Confidence-based Reprompting
Confidence-based reprompting:• minimize average length of authentication process
• Improve effective FAR/FRR by reprompting when unsure
• “reprompt rate (RPR)” controlled by two new thresholds
RPR = Pr(spkr) (FRR1 – FRR2) + Pr(imp) (FAR2 – FAR1)
1st Utterance:• FAR = 0.07%• FRR = 0.2%• RPR = 5.7%
Page 98
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 101
© 2001 D.A.Reynolds and L.P.Heck
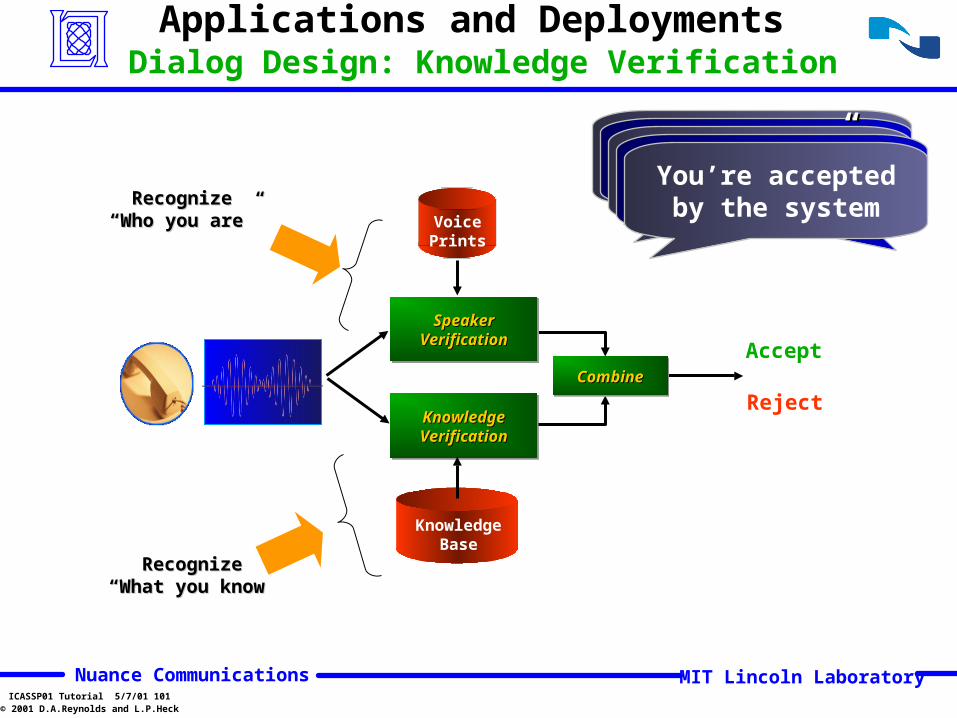
Please enter your account number““5551234”5551234”Say your date of
birth““October 13, October 13,
1964”1964”You’re accepted by the system
Applications and Deployments Dialog Design: Knowledge Verification
KnowledgeKnowledgeVerificationVerificationKnowledgeKnowledgeVerificationVerification
KnowledgeBase
CombineCombineCombineCombine
Accept
Reject
RecognizeRecognize“What you know”“What you know”
SpeakerSpeakerVerificationVerification
SpeakerSpeakerVerificationVerification
VoicePrints
RecognizeRecognize“Who you are”“Who you are”
Page 99
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 102
© 2001 D.A.Reynolds and L.P.Heck
Applications and Deployments Dialog Design: Knowledge Verification
• Parallel (“or” of decisions)
• Weighted Scores
FAR = FAR(sv) * FAR(kv)FRR = FRR(kv) + (1-FRR(kv)) * FRR(sv)
SpeakerSpeakerVerificationVerification
SpeakerSpeakerVerificationVerification
KnowledgeKnowledgeVerificationVerificationKnowledgeKnowledgeVerificationVerification
Methods to Combine Knowledge:• Sequential (“and” of decisions)
KnowledgeKnowledgeVerificationVerificationKnowledgeKnowledgeVerificationVerification
SpeakerSpeakerVerificationVerification
SpeakerSpeakerVerificationVerification
FAR = FAR(sv) + FAR(kv)FRR = FRR(sv) * FRR(kv)
KnowledgeKnowledgeVerificationVerificationKnowledgeKnowledgeVerificationVerification
SpeakerSpeakerVerificationVerification
SpeakerSpeakerVerificationVerification
CombineCombineScoresScores
CombineCombineScoresScores
Page 100
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 103
© 2001 D.A.Reynolds and L.P.Heck
Applications and Deployments Dialog Design: Knowledge Verification
KnowledgeKnowledgeVerificationVerificationKnowledgeKnowledgeVerificationVerification
KnowledgeBase
CombineCombineCombineCombineAccept
Reject
RecognizeRecognize“What you know”“What you know”
SpeakerSpeakerVerificationVerification
SpeakerSpeakerVerificationVerification
VoicePrints
RecognizeRecognize“Who you are”“Who you are”
Example: Sequential Combination of Decisions• Easy to implement, focuses on improving overall security
Example: Sequential Combination of Decisions• Easy to implement, focuses on improving overall security
FAR = FAR(sv) * FAR(kv)0.01% = 0.1% * 10%
FRR = FRR(kv) + (1-FRR(kv)) * FRR(sv) 1.1% = 0.1% + (1 - 0.1%) * 1%
Page 101
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 104
© 2001 D.A.Reynolds and L.P.Heck
Applications and Deployments Dialog Design: Security Against Recordings
Prompted Text Verification:• Prompt user to repeat random phrase
– Example: “Please say 82-32-71, 82-32-71”– Serves as “liveness” test
• Requires modification of enrollment dialog– (typically) longer enrollment to adequately cover acoustics
Speech recognizerSpeech recognizer
/a/ /b/ /c/ …
Speaker verifierSpeaker verifier
Speaker HMMs
Impostor HMMs
Prompted phrase (e.g., 82-32-71)
Text score
Speaker score
CombineCombine
Page 102
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 105
© 2001 D.A.Reynolds and L.P.Heck
Part III : Applications and DeploymentsOutline
• Brief overview of commercial speaker verification systems
• Design requirements for commercial verification systems – General considerations– Dialog design
• Steps to deploying speaker verification systems– Initial data collection– Tuning– Limited Deployment and Final Rollout
• Examples of real deployments
Page 103
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 106
© 2001 D.A.Reynolds and L.P.Heck
RolloutRolloutRolloutRollout
TuneTune
Limited DeploymentLimited DeploymentLimited DeploymentLimited Deployment
TuneTune
Initial Data CollectionInitial Data CollectionInitial Data CollectionInitial Data Collection
Applications and Deployments Deployment Steps
Page 104
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 107
© 2001 D.A.Reynolds and L.P.Heck
• “Probing/sampling” approach?
– Employ persons to call app. under supervision
– Not widely used (too difficult to collect enough data)
• Assessment from actual in-field data?
– Much easier to get volumes of data and more realistic
– Impostor trials: common enrollment utterance for impostor trials
– True Speaker Trials: Sort scores. Manually transcribe poor-scoring utts.
• Need ~50 callers/gender
• Need to observe 30 errors of each type/condition (“rule of 30”)
• Each speaker enroll/verifies several times (across multiple channels)
Applications and Deployments Deployment Steps: Initial Data Collection
How do you collect the data?
RolloutRolloutRolloutRollout
TuneTuneTuneTune
TuneTuneTuneTune
Initial Data CollectionInitial Data CollectionInitial Data CollectionInitial Data Collection
LimitedLimited DeploymentDeploymentLimitedLimited DeploymentDeployment
Page 105
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 108
© 2001 D.A.Reynolds and L.P.Heck
RolloutRolloutRolloutRollout
TuneTuneTuneTune
TuneTuneTuneTune
Initial Data CollectionInitial Data CollectionInitial Data CollectionInitial Data Collection
LimitedLimited DeploymentDeploymentLimitedLimited DeploymentDeployment
• Operating point (threshold)
– Setting operating point a Priori is very difficult!
– Speaker-independent and/or speaker-dependent thresholds?
– Picking correct operating point is key to a successful deployment!
• Dialog Design
–Customer feedback and/or usage patterns can be used to simplify dialog design (e.g., removing confirmation steps, reducing reprompt rate)
• Impostor Models (Acoustic)
–Training with real application data results in more competitive impostor models with better representation
of linguistics & noise & channels.
What components can be tuned?
Applications and Deployments Deployment: Tuning
Page 106
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 109
© 2001 D.A.Reynolds and L.P.Heck
• Begin with limited set of actual users– Representative of entire caller population
– Representative sampling of (telephone) network
– Representative of noise and channel mismatch conditions
• After rollout, track the following statistics:– Successful enrollment sessions (# of speaker models)
– Successful verification sessions
– In-grammar/Out-of-grammar analysis (recognition)
– Verification rejects (correct & false) for each speaker
– Duration of sessions
LimitedLimited DeploymentDeploymentLimitedLimited DeploymentDeployment
Initial Data CollectionInitial Data CollectionInitial Data CollectionInitial Data Collection
RolloutRolloutRolloutRollout
TuneTuneTuneTune
TuneTuneTuneTune
Applications and Deployments Deployment Steps: Limited Deployment/Rollout
What steps are there to deployment?
Page 107
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 110
© 2001 D.A.Reynolds and L.P.Heck
Part III : Applications and DeploymentsOutline
• Brief overview of commercial speaker verification systems
• Design requirements for commercial verification systems – General considerations– Dialog design
• Steps to deploying speaker verification systems– Initial data collection– Tuning– Limited Deployment and Final Rollout
• Examples of real deployments
Page 108
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 111
© 2001 D.A.Reynolds and L.P.Heck
Applications and Deployments First High-Volume Deployment
ApplicationApplication• Speaker verification and Speaker verification and
identification based on identification based on home phone numberhome phone number
• Provides secure access to Provides secure access to customer record & credit customer record & credit card informationcard information
ImplementationImplementation• Nuance VerifierNuance VerifierTMTM
• Edify telephony platformEdify telephony platform• Deployed July 1999Deployed July 1999
BenefitsBenefits• SecuritySecurity• PersonalizationPersonalization
Size & VolumeSize & Volume• 600k customers 600k customers
enrolled currentlyenrolled currently@20K calls/day@20K calls/day
• Full deployment:Full deployment:5 million customers 5 million customers @170K calls/day@170K calls/day
Page 109
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 112
© 2001 D.A.Reynolds and L.P.Heck
Successful EnrollmentSuccessful EnrollmentSuccessful AuthenticationSuccessful Authentication
Applications and Deployments First High-Volume Deployment
Page 110
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 113
© 2001 D.A.Reynolds and L.P.Heck
• Toll fraud prevention
• Telephone credit card purchases
• Telephone brokerage (e.g., stock trading)
Applications and Deployments Transaction Authentication
Page 111
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 114
© 2001 D.A.Reynolds and L.P.Heck
• Charles Schwab “Service Broker” “No PIN to remember, no PIN to forget”
– Built on Nuance Verifier pilot (2000): 10,000 users (SF bay area, NY) deployment: ~3 million users
– National rollout beginning Q3, 2001
Account Number
Account Number
Random phrase
(4-digits)
Random phrase
(4-digits)Confident?Confident?
NoNo
22ndnd Utt? Utt?NoNo
YesYesMake
Decision
Make Decision
YesYesPIN?PIN?
Applications and Deployments 1st Large-Scale High Security Deployment
Page 112
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 115
© 2001 D.A.Reynolds and L.P.Heck
Applications and Deployments Law Enforcement
• Monitoring– Remote time and attendance logging– Home parole verification– Prison telephone usage
ITT: ITT:
• SpeakerKey - telephone based home incarceration service
• Deployed at 10 sites in Wisconsin, Ohio, Pennsylvania, Georgia, and California
• More than 12,000 home incarceration sessions in June, 1995
• 0.66% false acceptance 4.3% false rejection
T-Netix: T-Netix:
• Contain - validating the identity and location of a parolee
• PIN-LOCK - validating the identity of an inmate prior to allowing an outbound prison call
• Deployed in Arizona,Colorado and Maryland
• 10K inmates using PIN-LOCK
• Roughly 25,000 - 30,000 verifications performed daily
Page 113
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 116
© 2001 D.A.Reynolds and L.P.Heck
Applications and Deployments Demonstrations
• Nuance 1-888-NUANCE-8 – http://www.nuance.com/demos/demo-shoppingnetwork.html
• T-Netix 1-800-443-2748– http://www.t-netix.com/SpeakEZ/SpeakEZDemo.html
• ITT– http://www.buytel.com/WebKey/index.asp
• Voice Security– http://www.Voice-Security.com/KeyPad.html
Page 114
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 117
© 2001 D.A.Reynolds and L.P.Heck
Speaker Verification: From Research to RealityRecap
• Part I : Background and Theory– Major concepts behind theory and operation of modern
speaker verification systems
• Part II : Evaluation and Performance– Key elements in evaluating performance of a speaker
verification system
• Part III : Applications and Deployments– Main issues and tasks in deploying a speaker verification
system
Page 115
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 118
© 2001 D.A.Reynolds and L.P.Heck
Conclusions
Speaker recognition is one of the few recognition areas where machines can outperform humans
Speaker recognition technology is a viable technique currently available for applications
Speaker recognition can be augmented with other authentication techniques to increase security
Page 116
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 119
© 2001 D.A.Reynolds and L.P.Heck
Speaker recognition technology will become an
integral part of speech interfaces
Research will focus on using speaker recognitionfor more unconstrained, uncontrolled situations
Future Directions
– Audio search and retrieval– Increasing robustness to channel variability– Incorporating higher-levels of knowledge into decisions
– Personalization of services and devices– Unobtrusive protection of transactions and information
Page 117
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 120
© 2001 D.A.Reynolds and L.P.Heck
To Probe Further General Resources
Conferences and Workshops:1) 2001: A Speaker Odyssey - The Speaker
Recognition Workshop, Crete, Greece, 2001 http://www.odyssey.westhost.com/
2) Reconnaissance du Locuteur et ses Applications Commerciales et Criminalistiques (RLA2C), Avignon, France, 1998 [proceedings in English]
3) ESCA Workshop on Automatic Speaker Recognition, Identification, and Verification, Martigny, Switzerland 1994 http://www.isca-speech.org/workshops.html
4) Audio and Visual Based Person Authentication (AVBPA) 1997, 1999, 2001 http://www.hh.se/avbpa/
5) International Conference on Acoustics Speech and Signal Processing (ICASSP), annual [sessions on speaker recognition] http://www.icassp2001.org/
6) European Conference on Speech Communication and Technology (Eurospeech), biennial [sessions on speaker recognition] http://eurospeech2001.org/
7) International Conference on Spoken Language Processing (ICSLP), biennial [sessions on speaker recognition] http://www.icslp2000.org/
Journals:1) IEEE Transactions on Speech and Audio
Processing http://www.ieee.org/organizations/society/sp/tsa.html
2) Speech Communication http://www.elsevier.nl/locate/specom
3) Computer, Speech & Language http://www.academicpress.com/www/journal/0/@/0/la.htm
Web:1) The Linguistic Data Consortium,
http://www.ldc.upenn.edu/2) European Language Resources Association
http://www.icp.inpg.fr/ELRA/home.html3) NIST Speaker Recognition Benchmarks
http://www.nist.gov/speech/tests/spk/index.htm4) Joe Campbell’s Site for Speaker Recognition
Speech Corpora http://www.apl.jhu.edu/Classes/Notes/Campbell/SpkrRec/
5) The Biometric Consortium http://www.biometrics.org/
6) Comp.Speech FAQ on speaker recognition http://www.speech.cs.cmu.edu/comp.speech/Section6/Q6.6.html
7) Search for “speaker verification” in Goggle search engine http://www.google.com/
Page 118
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 121
© 2001 D.A.Reynolds and L.P.Heck
To Probe Further Selected References
Tutorials:1) B. Atal, ``Automatic recognition of speakers from
their voices,'' Proceedings of the IEEE, vol. 64, pp.~460--475, April 1976.
2) A. Rosenberg, ``Automatic speaker verification: a review,'' Proceedings of the IEEE, vol. 64, pp. 475--487, April 1976.
3) G. Doddington, ``Speaker recognition---identifying people by their voices,'‘ Proceedings of the IEEE}, vol. 73, pp. 1651--1664, November 1985.
4) D. O'Shaughnessy, ``Speaker recognition,'' {IEEE ASSP Magazine, vol. 3, pp. 4--17, October 1986.
5) J. Naik, ``Speaker verification: a tutorial,'' IEEE Communications Magazine, vol. 28, pp. 42--48, January 1990.
6) H. Gish and M. Schmidt, ``Text-independent speaker identification,'' IEEE Signal Processing Magazine, vol. 11, pp. 18--32, October 1994.
7) S. Furui, ``An overview of speaker recognition technology,'' in Automatic Speech and Speaker Recognition (C.-H. Lee, F.K. Soong, ed.), pp.~31--56, Kluwer Academic, 1996.
8) J. P. Campbell, ``Speaker recognition: A tutorial,'' Proceedings of the IEEE , vol. 85, pp. 1437--1462, September 1997.
9) Special Issue on Speaker Recognition, Digital Signal Processing, vol. 10, January 2000. http://www.idealibrary.com/links/toc/dspr/10/1/0
Technology:1) M. Carey, E. Parris, and J. Bridle, ``A speaker
verification system using alphanets,'' in Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, pp. 397--400, May 1991.
2) G. Doddington, ``Speaker recognition based on idiolectal differences between speakers,'' in Proceedings of the European Conference on Speech Communication and Technology, 2001.
3) C. Fredouille, J. Mariethoz, C. Jaboulet, J. Hennebert, J.-F. Bonastre, C. Mokbel, and F. Bimbot, ``Behavious of a Bayesian adaptation method for incremental enrollment in speaker verification,'' in Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, 2000.
4) L. P. Heck and M. Weintraub, ``Handset-dependent background models for robust text-independent speaker recognition,'' in Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, pp. 1071--1073, April 1997.
10) G. Doddington, M. Przybocki, A. Martin, and D. A. Reynolds, ``The NIST speaker recognition evaluation - overview, methodology, systems, results, perspective,'‘ Speech Communication}, vol. 31, pp. 225-254,March 2000.
Page 119
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 122
© 2001 D.A.Reynolds and L.P.Heck
To Probe Further Selected References
5) L. Heck and N. Mirghafori, ``On-line unsupervised adaptation for speaker verification,'' in Proceedings of the International Conference on Spoken Language Processing, 2000.
6) L. Heck, Y. Konig, M.K. Sonmez, and M. Weintraub, ``Robustness to Telephone Handset Distortion in Speaker Recognition by Discriminative Feature Design,'' Speech Communication, Vol. 31, 2000, pp. 181-192.
7) H. Hermansky, N. Morgan, A. Bayya, and P. Kohn, ``RASTA-PLP speech analysis technique,'' in Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, pp. I.121--I.124, March 1992.
8) A. Higgins, L. Bahler, and J. Porter, ``Speaker verification using randomized phrase prompting,'' Digital Signal Processing, vol. 1, pp. 89--106,1991.
9) B. Koenig, ``Spectrographic voice identification: A forensic survey,'‘ Journal of the Acoustical Society of America, vol. 79, pp. 2088--2090, June 1986.
10) Q. Li and B.-H. Juang, ``Speaker verification using verbal information verification for automatic enrollment,'' in Proceedings of the International Conference on Spoken Language Processing, 1998.
11) A. Martin, G. Doddington, T. Kamm, M. Ordowski, and M. Przybocki, ``The DET curve in assessment of detection task performance,'' in Proceedings of the European Conference on Speech Communication and Technology, pp. 1895--1898, 1997.
12) T. Matsui and S. Furui, ``Comparison of text-independent speaker recognition methods using VQ-distortion and discrete/continuous HMMs,'' in Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, pp. II--157--II--164, March 1992.
13) M. Newman, L. Gillick, Y. Ito, D. McAllaster, and B. Peskin, ``Speaker verification through large vocabulary continuous speech recognition,'' in Proceedings of the International Conference on Spoken Language Processing, pp. 2419--2422, 1996.
14) T.F. Quatieri, D.A. Reynolds and G.C. O'Leary, “Estimation of Handset Nonlinearity with Application to Speaker Recognition,” IEEE Transactions on Speech and Audio Processing, August 2000
15) D. A. Reynolds, ``Speaker identification and verification using Gaussian mixture speaker models,'' Speech Communication, vol. 17, pp. 91--108, August 1995.
Page 120
MIT Lincoln Laboratory Nuance Communications ICASSP01 Tutorial 5/7/01 123
© 2001 D.A.Reynolds and L.P.Heck
To Probe Further Selected References
16) D. A. Reynolds, ``HTIMIT and LLHDB: Speech corpora for the study of handset transducer effects,'' in Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, pp. 1535--1538, April 1997.
17) D. A. Reynolds, ``Comparison of background normalization methods for text-independent speaker verification,'' in Proceedings of the European Conference on Speech Communication and Technology, pp. 963--967, September 1997.
18) D.Reynolds, M.Zissman, T.Quateri, G.O'Leary, and B.Carlson, ``The effects of telephone transmission degradations on speaker recognition performance,'‘ in Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, pp.329--332, May 1995
19) D.A. Reynolds and B.A. Carlson, ``Text-dependent speaker verification using decoupled and integrated speaker and speech recognizers,'' in Proceedings of the European Conference on Speech Communication and Technology, pp.647--650, September 1995.
20) D.A. Reynolds, ``The effects of handset variability on speaker recognition performance: Experiments on the Switchboard corpus,'' in Proceedings of the International Conference on Acoustics, Speech, and Signal Processing pp.113--116, May 1996.
21) A.E. Rosenberg, C.-H. Lee, ``Connected word talker verification using whole word hidden markov models,'' in Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, pp. 381--384, 1991.
22) A. E. Rosenberg and S. Parthasarathy, ``Speaker background models for connected digit password speaker verification,'' in Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, pp. 81--84, May 1996.
23) F. Soong and A. Rosenberg, ``On the use of instantaneous and transitional spectral information in speaker recognition,'' in Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, pp. 877--880, 1986.
24) R. Teunen, B. Shahshahani, and L. Heck, ``A model-based transformational approach to robust speaker recognition,'' in Proceedings of the International Conference on Spoken Language Processing, 2000.